Поделиться

Более полувека тому назад Норберт Винер опубликовал книгу "Кибернетика, или управление и связь в животном и машине", возвестившую о становлении новой науки - кибернетики, в которой информационно-управленческая связь в явлениях материального мира выступает как его фундаментальное свойство. Это понимание дало мощный толчок развитию вычислительных систем и их применению во многих отраслях знания и бизнеса.
Сферы применения информационных технологий в современном обществе чрезвычайно велики. В таблице 2.1 приведены основные и производные сферы использования ИТ.
В современном обществе основным технологическим средством накопления, переработки и защиты информации служит корпоративный и/или персональный компьютер и программная среда, которые существенно повлияли как на концепцию построения и использования технологических процессов, так и на качество результата. Внедрение персонального компьютера в информационную сферу и применение телекоммуникационных средств связи определили новый этап развития ИТ и, как следствие, изменение названия технологии за счет присоединения одного из символов: "новая", "компьютерная" или "современная" (таблица 2.2).
|
Таблица 2.1. Сферы применения информационных технологий |
|||||
|
Экономика |
Политика |
Культура |
Наука |
||
|
Производственные отношения |
Государство |
Эпохи |
Теория |
||
|
Производство |
Власть |
Уклады |
Методы |
||
|
Финансы |
Общество |
Традиции |
Средства |
||
|
Бизнес-правила |
Международные и региональные организации и отношения |
Религия |
Систематизация |
||
|
Взаимодействие |
Партии |
Национальные ценности |
Научно-технические революции |
||
|
Продукт |
Общественные организации |
Этика |
Применение |
||
|
Услуга |
Искусство |
Результаты |
|||
|
Система |
Образование |
Последствия |
|||
|
Качество |
Спорт |
||||
|
Потребитель |
|||||
|
Таблица 2.2. |
|||||
|
Методология |
Основной признак |
Результат |
|||
|
Целенаправленные создание, хранение, передача и отображение информации |
Учет закономерностей изменения социальной среды и бизнеса. Ориентация на знания |
Новые подходы к организации производства. Смещение фокуса на потребителя |
|||
|
Новая технология обработки информации |
Целостные технологические информационные системы |
Интеграция функций специалистов и менеджеров |
|||
|
Принципиально новые средства обработки информации |
"Встраивание" в технологию управления |
Новые технологии принятия управленческих решений |
|||
Таким образом, понятие информационная технология является емким понятием, отражающим современное представление о процессах преобразования и потребления информации в информационном обществе.
Понятие обработки информации является весьма широким. Ведя речь об обработке информации, следует дать понятие инварианта обработки. Обычно им является смысл сообщения (смысл информации, заключенной в сообщении). При автоматизированной обработке информации объектом обработки служит сообщение, и здесь важно провести обработку таким образом, чтобы инварианты преобразований сообщения соответствовали инвариантам преобразования информации.
Цель обработки информации в целом определяется целью функционирования некоторой системы, с которой связан рассматриваемый информационный процесс. Однако для достижения цели всегда приходится решать ряд взаимосвязанных задач.
К примеру, начальная стадия информационного процесса - рецепция. В различных информационных системах рецепция выражается в таких конкретных процессах, как сбор и/или отбор информации (в системах научно-технической информации), преобразование физических величин в измерительный сигнал (в информационно-измерительных системах), раздражимость и ощущения (в биологических системах) и т. п.
Процесс рецепции начинается на границе, отделяющей информационную систему от внешнего мира. Здесь, на границе, сигнал внешнего мира преобразуется в форму, удобную для дальнейшей обработки. Для биологических систем и многих технических систем, например читающих автоматов, эта граница более или менее четко выражена. В остальных случаях она в значительной степени условна и даже расплывчата. Что касается внутренней границы процесса рецепции, то она практически всегда условна и выбирается в каждом конкретном случае исходя из удобства исследования информационного процесса.
Следует отметить, что, независимо от того, как "глубоко" будет отодвинута внутренняя граница, рецепцию всегда можно рассматривать как процесс классификации.
Формализованная модель обработки информации
Обратимся теперь к вопросу о том, в чем сходство и различие процессов обработки информации, связанных с различными составляющими информационного процесса, используя при этом формализованную модель обработки. Прежде всего, нельзя отрывать этот вопрос от потребителя информации (адресата), а также от семантического и прагматического аспектов информации. Наличие адресата, для которого предназначено сообщение (сигнал), определяет невозможность установления однозначного соответствия между сообщением и содержащейся в нем информацией. Совершенно очевидно, что одно и то же сообщение может иметь различный смысл для разных адресатов и различное прагматическое значение.
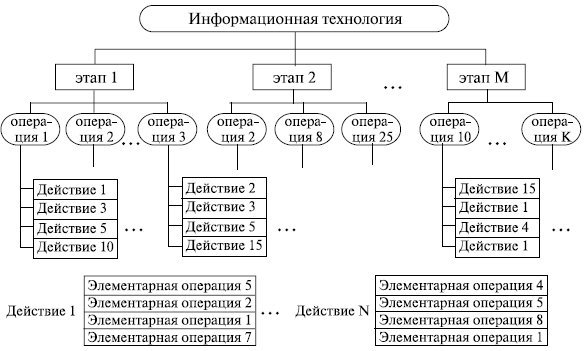
Рис. 2.1. Технологический процесс переработки информации в виде иерархической структуры по уровням
Используемые в производственной сфере такие технологические понятия, как "технологический процесс", "технологическая операция", "метрика", "норматив" и т. п. могут применяться и в ИТ. Для этого нужно начинать с определения цели. Затем следует попытаться провести структурирование всех предполагаемых действий, приводящих к намеченной цели, и выбрать необходимый программный инструментарий (рис. 2.1).
1-й уровень - этапы, где реализуются базовые технологические процессы, состоящие из операций и действий последующих уровней.
2-й уровень - операции, в результате выполнения которых будет создан конкретный объект в выбранной на 1-м уровне программной среде.
3-й уровень - действия, совокупность стандартных для каждой программной среды приемов работы, приводящих к выполнению поставленной в соответствующей операции цели.
4-й уровень - элементарные операции по управлению элементарными действиями объектов.
ИТ, как и другие технологии, должны отвечать следующим требованиям:
· обеспечивать высокую степень расчленения всего процесса обработки информации на этапы, операции, действия;
· включать весь набор элементов, необходимых для достижения поставленной цели;
· иметь регулярный и масштабируемый характер;
· этапы, действия, операции технологического процесса должны быть стандартизированы и унифицированы, что позволит более эффективно осуществлять целенаправленное управление информационными процессами.
Традиционно в процессе обработки информации используются как измерительная аппаратура, обеспечивающая входные данные, так и собственно обрабатывающие (вычислительные) системы. И те и другие прошли длинную дорогу развития вместе с человеческой цивилизацией. В следующем пункте будут перечислены основные вехи их истории.
Если раньше обрабатывающей системой был человек или какие-то механические приспособления, то для проведения процесса обработки было достаточно сформулировать набор правил (инструкций). Давно подметили, что повторяющиеся операции целесообразно автоматизировать в первую очередь и желательно перепоручить машинам. При этом человек, задавая циклическое правило работы машине, колоссально выигрывает в трудозатратах.
Предположим, вам надо сложить 1000 последовательных данных измерений. Заводим специальный счетчик-сумматор и присваиваем ему значение 0. Для каждого из данных надо получить результат измерений и добавить его к счетчику, то есть вам надо сделать 2001 операцию при "ручном" счете. Другой вариант - написать шесть инструкций для машины:
1. завести счетчик-сумматор и присвоить ему значение 0;
2. завести индекс (номер) текущей операции и присвоить ему значение 0;
3. получить новый результат измерений;
4. добавить его к счетчику-сумматору;
5. увеличить на 1 индекс текущей операции;
6. если он меньше 1000, то перейти к шагу 3.
За прошедшее время существенно усложнились задачи обработки информации, развились способы формулировки и записи правил работы машин (программ работы). Вычислительные устройства превратились в компьютеры, а правила работы - в компьютерные программы.
Программирование - процесс создания компьютерных программ с помощью языков программирования. Программирование сочетает в себе элементы искусства, науки, математики и инженерии.
В узком смысле слова программирование рассматривается как кодирование - реализация одного или нескольких взаимосвязанных алгоритмов на некотором языке программирования. Под программированием также может пониматься разработка логической схемы для интегральной микросхемы, а также процесс записи информации в микросхему ПЗУ (Постоянного Запоминающего Устройства) некоторой электронной системы. В более широком смысле программирование - процесс создания программ, то есть разработка программного обеспечения.
Составителями программ являются программисты. Большая часть работы программиста связана с написанием и отладкой исходного кода на одном из языков программирования.
Различные языки программирования поддерживают различные стили программирования (или парадигмы программирования). Отчасти искусство программирования состоит в том, чтобы на одном из языков эффективно реализовать алгоритм, наиболее полно подходящий для решения имеющейся задачи. Разные языки требуют от программиста различного уровня внимания к деталям при реализации алгоритма, результатом чего часто бывает компромисс между простотой и производительностью (или между временем программиста и временем пользователя).
Единственный язык, напрямую выполняемый процессором, - это машинный язык (также называемый машинным кодом). Изначально все программисты прорабатывали весь алгоритм в машинном коде, но сейчас эта трудная работа уже не делается. Вместо этого программисты пишут исходный код на языке высокого уровня (например, С, С++, С#, Java), а компьютер, используя компилятор или интерпретатор и уточняя все детали, транслирует его за один или несколько этапов в машинный код, готовый к исполнению на целевом процессоре. Если требуется полный низкоуровневый контроль над системой, программисты пишут программу на языке ассемблера, мнемонические инструкции которого преобразуются один к одному в соответствующие инструкции машинного языка целевого процессора.
В некоторых языках вместо машинного кода генерируется интерпретируемый двоичный код "виртуальной машины", также называемый байт-кодом (byte-code). Такой подход применяется в языке Forth, некоторых реализациях языков Lisp, Java, Perl, Python, а также в языках платформы Microsoft .NET.
Типичный процесс разработки программ состоит, в общем, из семи этапов:
· постановка задачи;
· формализация и специфицирование;
· выбор или составление алгоритма;
· программирование;
· компиляция (трансляция);
· отладка и тестирование;
· запуск в эксплуатацию.
Эксплуатируемая программа имеет дело с данными различных типов, предназначенных для решения конкретных задач.
Предметная область какой-либо деятельности - часть реального мира, подлежащая изучению с целью организации управления процессами и объектами для получения бизнес-результата. Предметная область может быть разделена (декомпозирована) на фрагменты: например, предприятие - это дирекция, плановые отделы, бухгалтерия, цеха, отделы маркетинга, логистики и продаж, клиенты, поставщики и т. д. Каждый фрагмент предметной области характеризуется множеством объектов и процессов, использующих объекты, а также множеством пользователей, характеризуемых различными взглядами на предметную область и данными, которые описывают указанные составляющие предметной области. Эти данные отражают динамичную внешнюю и внутреннюю среды предприятия, поэтому в специальных разделах информационной системы необходимо создавать динамически обновляемые модели отражения внешнего мира с использованием единого хранилища - базы данных.
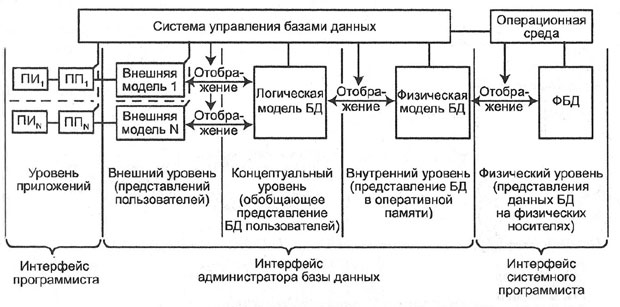
Рис. 2.2. Общая схема базы данных
База данных, БД (Data Base) - структурированный организованный набор данных, объединенных в соответствии с некоторой выбранной моделью и описывающих характеристики какой-либо физической или виртуальной системы (рис. 2.2).
Понятие "динамически обновляемая БД" означает, что соответствие базы данных текущему состоянию предметной области обеспечивается не периодически, а в режиме реального времени. При этом одни и те же данные могут быть по-разному представлены в соответствии с потребностями различных групп пользователей.
Система управления базами данных, СУБД (Data Base Management System) - специализированная программа или комплекс программ, предназначенные для манипулирования базой данных. Для создания информационной системы и управления ею СУБД необходима в той же степени, как для разработки программы на алгоритмическом языке необходим транслятор.
СУБД часто упрощенно или ошибочно называют "базой данных". Нужно различать набор данных (собственно БД) и программное обеспечение, предназначенное для организации и ведения баз данных (СУБД).
Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. Независимые от программ пользователя данные обычно называются метаданными или данными о данных. В ряде современных систем метаданные, содержащие также информацию о пользователях, форматы отображения, статистику обращения к данным и др. сведения, хранятся в специальном словаре базы данных.
Организация структуры БД формируется исходя из следующих соображений:
· адекватность описываемому объекту/системе - на уровне концептуальной и логической моделей;
· удобство использования для ведения учета и анализа данных - на уровне так называемой физической модели.
Виды концептуальных и логических моделей БД:
· картотеки;
· сетевые;
· иерархические;
· реляционные;
· дедуктивные;
· объектно-ориентированные;
· многомерные.
На уровне физической модели электронная БД представляет собой файл или набор данных в dbf-форматах приложений Excel, Access либо в специализированном формате конкретной СУБД. Также в СУБД в понятие физической модели включают специализированные виртуальные понятия, существующие в ее рамках, - "таблица", "табличное пространство", "сегмент", "куб", "кластер" и т. д.
В настоящее время наибольшее распространение получили реляционные базы данных. Картотеками пользовались до появления электронных баз данных. Сетевые и иерархические базы данных считаются устаревшими, объектно-ориентированные пока никак не стандартизированы и не получили широкого распространения.
Реляционная база данных - база данных, основанная на реляционной модели. Слово "реляционный" происходит от английского "relation" (отношение).
Теория реляционных баз данных была разработана доктором Эдгаром Коддом из компании IBM в 1970 году. В реляционных базах данных все данные представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых расположены данные. Запросы к таким таблицам возвращают таблицы, которые сами могут становиться предметом дальнейших запросов. Каждая база данных может включать несколько таблиц. Кратко особенности реляционной базы данных можно сформулировать следующим образом:
· данные хранятся в таблицах, состоящих из столбцов ("атрибутов") и строк ("записей");
· на пересечении каждого столбца и строчки стоит в точности одно значение;
· у каждого столбца есть свое имя, которое служит его названием, и все значения в одном столбце имеют один тип;
· запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов;
· строки в реляционной базе данных неупорядочены, упорядочивание производится в момент формирования ответа на запрос.
Общепринятым стандартом языка работы с реляционными базами данных в настоящее время является язык структурированных запросов (Structured Query Language - SQL). Это универсальный компьютерный язык, применяемый для создания, модификации и управления данными в реляционных базах данных. Вопреки существующим заблуждениям, SQL является информационно-логическим языком, а не языком программирования.
SQL основывается на реляционной алгебре. Язык SQL делится на три части:
· операторы определения данных;
· операторы манипуляции данными (Insert, Select, Update, Delete);
· операторы определения доступа к данным.
Основные функции системы управления базами данных:
· управление данными во внешней памяти (на различных носителях);
· управление данными в оперативной памяти;
· журналирование изменений и восстановление базы данных после сбоев;
· поддержка языков БД (язык определения данных, язык манипулирования данными, язык определения доступа к данным).
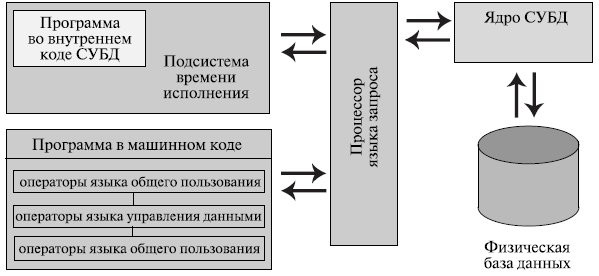
Рис. 2.3. Основные компоненты СУБД
Обычно современная СУБД содержит следующие компоненты (рис. 2.3):
· ядро, которое отвечает за управление данными во внешней и оперативной памяти и журналирование;
· процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода;
· подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД;
· сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы.
По типу управляемой базы данных СУБД разделяются на иерархические, реляционные, объектно-реляционные, объектно-ориентированные, сетевые.
По архитектуре организации хранения данных:
· локальные СУБД (все части локальной СУБД размещаются на одном компьютере);
· распределенные СУБД (части СУБД могут размещаться на двух и более компьютерах).
Классификация СУБД по способу доступа к БД:
· файл-серверные;
· клиент-серверные;
· трехзвенные;
· встраиваемые.
Файл-серверные СУБД. Архитектура "файл-сервер" не имеет сетевого разделения компонентов диалога и использует компьютер для функции отображения, что облегчает построение графического интерфейса. "Файл-сервер" только извлекает данные из файлов, так что дополнительные пользователи добавляют лишь незначительную нагрузку на центральный процессор, и каждый новый клиент добавляет вычислительную мощность сети. Минус - высокая загрузка сети. На данный момент файл-серверные СУБД считаются устаревшими. Примеры: Microsoft Access, MySQL (до версии 5.0).
Клиент-серверные СУБД. Такие СУБД состоят из клиентской части (которая входит в состав прикладной программы) и сервера. Клиент-серверные СУБД, в отличие от файл-серверных, обеспечивают разграничение доступа между пользователями и меньше загружают сеть и клиентские машины. Сервер является внешней по отношению к клиенту программой, и по мере надобности его можно заменить другим. Недостаток клиент-серверных СУБД - в самом факте существования сервера (что плохо для локальных программ - в них удобнее встраиваемые СУБД) и больших вычислительных ресурсах, потребляемых сервером. Примеры: Firebird, Interbase, MS SQL Server, Oracle, DB2, PostgreSQL, MySQL (старше версии 5.0).
Существенным недостатком клиент-серверной архитектуры является необходимость установления прямого соединения между клиентским компьютером и базой данных. При трехзвенной архитектуре пользовательское приложение (клиент) соединяется со специально выделенным сервером приложений, и только он уже соединяется с базой данных. Кроме повышения уровня безопасности трехзвенная архитектура позволяет более гибко модернизировать приложения. Как правило, в массовой клиентской части оставляют только минимальный набор функций по доступу и отображению информации, а основную бизнес-логику реализуют в программах, запускаемых на серверах приложений. При этом модернизация обычно затрагивает только сервер приложений, а на массовых клиентских местах переустанавливать ПО не приходится.
Встраиваемая СУБД - это, как правило, "библиотека", которая позволяет унифицированным образом хранить большие объемы данных на локальной машине. Доступ к данным может происходить через SQL либо через особые функции СУБД. Встраиваемые СУБД быстрее обычных клиент-серверных и не требуют установки сервера, поэтому востребованы в локальном ПО, которое имеет дело с большими объемами данных - например, геоинформационные системы (Geographic Informational System - GIS). Примеры: SQLite, BerkeleyDB, один из вариантов Firebird, один из вариантов MySQL.
В общем случае СУБД могут быть классифицированы в системе координат "Неоднородность - Автономность -Распределенность" (рис. 2.4).
Таким образом, распределенная обработка данных в обязательном порядке предполагает наличие банков и баз данных. Но база данных - это не просто место, куда складывают данные, ими нужно пользоваться, актуализировать, изменять форматы и связи, совершать множество других действий. Если бессистемно наполнять базу данных информацией, то через некоторое время ее невозможно будет использовать - времени на поиск нужных данных будет уходить все больше и больше, физическое пространство базы переполнится. Чтобы этого избежать, данные необходимо "очищать" и структурировать, а для эффективной работы с ними необходимы системы управления работой баз данных.
Индустрия создания баз данных и СУБД берет свое начало в 60-х годах прошлого века и к настоящему времени достаточно развита, однако понятие "хранилище данных" в современном понимании его появилось относительно недавно.
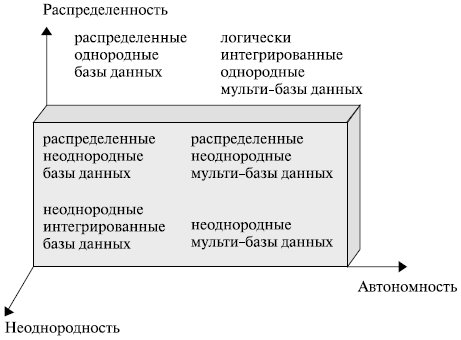
Рис. 2.4. Классификационная система координат
Идея хранилищ данных оказалась востребованной, так как во многих видах государственной, деловой, научной, социальной деятельности необходимы тематически объединенные и исторически очищенные совокупности данных, при этом постоянно возрастала потребность:
· в более дешевых данных;
· в точных и структурированных данных;
· в большей оперативности получения и обработки данных;
· в интегрированных данных.
К концу 1980-х годов, когда была в полной мере осознана необходимость интеграции корпоративной информации и надлежащего управления этой информацией, появились технические возможности для создания соответствующих систем, которые первоначально были названы "хранилищами информации" (Information Warehouse - IW). И лишь в 1990-е годы, с выходом книги Уильяма (Билла) Инмона, хранилища получили свое нынешнее наименование "хранилища данных" (Data Warehouse - DW) [Inmon W.H. Building the Data Warehouse, QED/Wiley, 1991, 312 р.].
Билл Инмон определил хранилища данных как "предметно-ориентированные, интегрированные, неизменные, поддерживающие хронологию наборы данных, организованные для целей поддержки управления, призванные выступать в роли единого и единственного источника истины, обеспечивающего менеджеров и аналитиков достоверной информацией, необходимой для оперативного анализа и принятия решений".
В основе концепции хранилищ данных лежат следующие основополагающие идеи:
· интеграция ранее разъединенных детализированных данных (исторические архивы, данные из традиционных систем обработки документов, разрозненных баз данных, данные из внешних источников) в едином хранилище данных;
· тематическое и временное структурирование, согласование и агрегирование;
· разделение наборов данных, используемых для операционной (производственной) обработки, и наборов данных, используемых для решения задач анализа.
Данные, помещаемые в хранилище, должны отвечать определенным требованиям - предметной ориентированности, интегрированности, поддержки хронологии и неизменяемости (таблица 2.3).
|
Таблица 2.3. |
|
|
Предметная ориентированность |
Все данные о некоторой сущности (бизнес-объекте, бизнес-процессе и т. д.) из некоторой предметной области собираются из множества различных источников, очищаются, согласовываются, дополняются, агрегируются и представляются в единой, удобной для их использования в бизнес-анализе форме |
|
Интегрированность |
Все данные о различных бизнес-объектах взаимно согласованы и хранятся в едином общекорпоративном хранилище |
|
Поддержка хронологии |
Данные хронологически структурированы и отражают историю за период времени, достаточный для выполнения задач бизнес-анализа, прогнозирования и подготовки принятия решения |
|
Неизменяемость |
Исходные (исторические) данные, после того как они были согласованы, верифицированы и внесены в общекорпоративное хранилище, остаются неизменными и используются исключительно в режиме чтения |
Хранилище данных выполняет множество функций, но его основное предназначение - предоставление точных данных и информации в кратчайшие сроки и с минимумом затрат.
Понятие хранилище данных в первоначальном понимании было основано на понятии распределенной витрины данных (Distributed Data Mart - DDM). Поэтому в классическом исполнении хранилище данных было прежде всего репозиторием (сквозной базой данных) данных и информации предприятия.
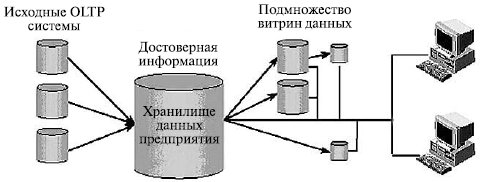
Рис. 2.5. Схема организации данных в хранилище
Среда хранилища была предназначена только для чтения и состояла из детальных и агрегированных данных, которые полностью очищены и интегрированы; кроме того, в репозитории хранилась обширная и детальная история данных на уровне транзакций. С точки зрения архитектурного решения такое хранилище данных реализует свои функции через подмножество зависимых витрин данных (рис. 2.5).
Достоинствами архитектуры классического хранилища данных являются:
· общая семантика;
· централизованная, управляемая среда;
· согласованный набор процессов извлечения и бизнес-логики использования;
· непротиворечивость содержащейся информации;
· легко создаваемые по шаблонам и наполняемые витрины данных;
· единый репозиторий метаданных;
· многообразие механизмов обработки и представления данных.
К недостаткам можно отнести большие затраты по реализации, высокую ресурсоемкость в масштабе всего предприятия, потребность в сложных сервисных системах, рискованный сценарий развития, когда все данные и метаданные находятся в одном репозитории и в неблагоприятном случае могут быть потеряны. Кроме того, при фильтрации, агрегировании и рафинировании "сырых" данных для такого хранилища обычно теряется очень много информации, которая может быть чрезвычайно полезной при бизнес-анализе. В связи с этим возникло понимание того, что хранилище, помимо механизмов размещения и извлечения данных (On Line Transactional Processing - OLTP), репозитория и витрин, должно иметь соответствующее пространство для организации "сырых" данных и их многомерного анализа в режиме реального времени (On Line Analytical Processing - OLAP).
Без преувеличения можно сказать, что период между последней третью XIX и концом ХХ веков был "колыбелью" многих больших и малых революций (рис. 2.6). Промышленная революция конца ХIХ - начала ХХ века и Первая мировая война породили волну социальных революций, которые если не перевернули, то основательно потрясли мировые устои.
Вторая мировая война и послевоенное развитие экономики, исследования в ядерной и микромолекулярной физике, электронике твердого тела и пограничных явлений, создание первых промышленных вычислительных устройств дали толчок индустриальной революции, которая за четверть века подготовила почву для бурного всплеска развития информационных технологий.
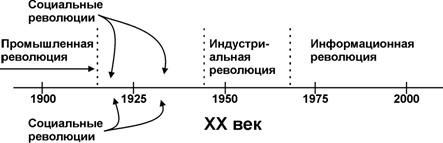
Рис. 2.6. Последовательность революций ХХ века
Качественные изменения, затронувшие последнюю часть прошлого столетия, имели под собой солидную многовековую историю. Вычислительная техника не сразу достигла современного уровня. В ее развитии отмечают предысторию и четыре поколения ЭВМ. Ниже приведены самые показательные факты предыстории.
Древнейшим счетным инструментом, который сама природа предоставила в распоряжение человека, была его собственная рука. Понятие числа и фигуры взято не откуда-то, а из действительного мира. "Десять пальцев, на которых люди учились считать (производить первую арифметическую операцию), представляют собой все что угодно, только не продукт свободного творческого разума" [http://www.junior.ru/wwwexam/history/frame.htm].
Имена числительные во многих языках указывают, что у первобытного человека орудием счета были преимущественно пальцы. Неслучайно в древнерусской нумерации единицы называются "перстами", десятки ¬- "составами", а все остальные числа - "сочинениями". Кисть же руки у многих народов называлась "пять". Например, малайское "лима" означает одновременно и "рука", и "пять".
От пальцевого счета берет начало пятеричная система счисления (одна рука), десятеричная (две руки), двадцатеричная (пальцы рук и ног). У многих народов пальцы рук остаются инструментом счета и на более высоких ступенях развития.
Хорошо был известен пальцевый счет в Риме. По свидетельству древнеримского историка Плиния-старшего, на главной римской площади Форуме была воздвигнута гигантская фигура двуликого бога Януса. Пальцами правой руки он изображал число 300, пальцами левой - 55. Вместе это составляло число дней в году в римском календаре.
 В средневековой Европе полное описание пальцевого
счета составил ирландец Беда Достопочтенный. Пальцевый счет сохранился кое-где
и поныне. Историк и математик Л. Карпинский в книге "История
арифметики" сообщает, что на крупнейшей мировой хлебной бирже в Чикаго
предложения и запросы, как и цены, объявлялись маклерами на пальцах без единого
слова.
В средневековой Европе полное описание пальцевого
счета составил ирландец Беда Достопочтенный. Пальцевый счет сохранился кое-где
и поныне. Историк и математик Л. Карпинский в книге "История
арифметики" сообщает, что на крупнейшей мировой хлебной бирже в Чикаго
предложения и запросы, как и цены, объявлялись маклерами на пальцах без единого
слова.
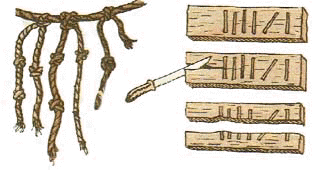 Издревле употребляется еще один вид инструментального счета
- с помощью деревянных палочек с зарубками (бирок). В средние века бирками
пользовались для учета и сбора налогов. Бирка разрезалась на две продольные
части, одна оставалась у крестьянина, другая - у сборщика налогов. По зарубкам
на обеих частях и велся счет уплаты налога, который проверяли складыванием
частей бирки. В Англии, например, этот способ записи налогов существовал до
конца XVII столетия. Другие народы - китайцы, персы, индийцы, перуанцы -
использовали для представления чисел и счета ремни или веревки с узелками.
Издревле употребляется еще один вид инструментального счета
- с помощью деревянных палочек с зарубками (бирок). В средние века бирками
пользовались для учета и сбора налогов. Бирка разрезалась на две продольные
части, одна оставалась у крестьянина, другая - у сборщика налогов. По зарубкам
на обеих частях и велся счет уплаты налога, который проверяли складыванием
частей бирки. В Англии, например, этот способ записи налогов существовал до
конца XVII столетия. Другие народы - китайцы, персы, индийцы, перуанцы -
использовали для представления чисел и счета ремни или веревки с узелками.
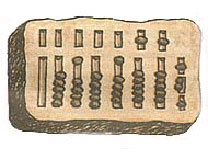 Бирки и
веревки с узелками не могли удовлетворить возраставшие в связи с развитием
торговли потребности в средствах вычисления. Развитию же письменного счета
препятствовали два обстоятельства. Во-первых, не было подходящего материала для
выполнения вычислений - глиняные и восковые таблички для этого не годились.
Во-вторых, в тогдашних системах счисления письменно выполнить все необходимые
операции было сложно. Этими обстоятельствами можно объяснить появление
специального счетного прибора, известного в древности под именем абак.
Бирки и
веревки с узелками не могли удовлетворить возраставшие в связи с развитием
торговли потребности в средствах вычисления. Развитию же письменного счета
препятствовали два обстоятельства. Во-первых, не было подходящего материала для
выполнения вычислений - глиняные и восковые таблички для этого не годились.
Во-вторых, в тогдашних системах счисления письменно выполнить все необходимые
операции было сложно. Этими обстоятельствами можно объяснить появление
специального счетного прибора, известного в древности под именем абак.
Около 500 года нашей эры: изобретение абака.
Римский абак. Абаком называлась дощечка, покрытая слоем воска, на которой острой палочкой проводились линии и какие-нибудь фигуры, размещавшиеся в полученных колонках по позиционному принципу.
В Древнем Риме абак появился, вероятно, в V-VI вв н. э. и назывался calculi или abakuli. Изготовлялся он из бронзы, камня, слоновой кости и цветного стекла. До нашего времени дошел бронзовый римский абак, на котором камешки передвигались в вертикально прорезанных желобках. Внизу помещались камешки для счета до пяти, а в верхней части имелось отделение для камешка, соответствующего пятерке.
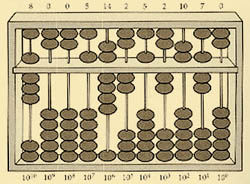 Суаньпань. Китайская разновидность абака (суаньпань)
- появилась в VI веке н. э.; современный тип этого счетного прибора был создан
позднее, по-видимому в XII столетии. Суаньпань представляет собой прямоугольную
раму, в которой параллельно друг другу протянуты проволоки или веревки числом
от девяти и более; перпендикулярно этому направлению суаньпань перегорожен на
две неравные части. В большом отделении ("земля") на каждой проволоке
нанизано по пять шариков, в меньшем ("небо") - по два. Проволоки
соответствуют десятичным разрядам. Из рисунка видно, что суаньпань является
практически точным аналогом инструмента "конторские счеты".
Суаньпань. Китайская разновидность абака (суаньпань)
- появилась в VI веке н. э.; современный тип этого счетного прибора был создан
позднее, по-видимому в XII столетии. Суаньпань представляет собой прямоугольную
раму, в которой параллельно друг другу протянуты проволоки или веревки числом
от девяти и более; перпендикулярно этому направлению суаньпань перегорожен на
две неравные части. В большом отделении ("земля") на каждой проволоке
нанизано по пять шариков, в меньшем ("небо") - по два. Проволоки
соответствуют десятичным разрядам. Из рисунка видно, что суаньпань является
практически точным аналогом инструмента "конторские счеты".
Соробан - японский абак, происходит от китайского суаньпаня, который был завезен в Японию в XV-XVI веках. Соробан проще своего предшественника, у него на "небе" на один шарик меньше, чем у суаньпаня.
Дощаный счет. Десятичный строй - довольно веское основание для того, чтобы признать временем возникновения этого прибора XVI век, когда десятичный принцип счисления был впервые применен в денежном деле в России. В это время какому-то наблюдательному человеку пришла в голову мысль заменить горизонтальные линии счета горизонтально натянутыми веревками, навесив на них, по существу, все те же "косточки-шарики".
Впрочем, в XVI веке термина "счеты" еще не существовало, и прибор именовался "дощаным счетом". Один из ранних образцов такого "счета" представлял собой два соединенных ящика, одинаково разделенных по высоте перегородками. В каждом ящике - два счетных поля с натянутыми веревками или проволочками. На верхних 10 веревках по 9 косточек (четок), на 11-й их - четыре, на остальных веревках - по одной.
Рассмотренные выше устройства (приборы) были предназначены для удобства использования и реализовывали в первую очередь наглядность счета. Расширился диапазон чисел, с которыми можно было производить простые арифметические действия. Однако механические вычислительные устройства и математические методы, предназначенные для ускорения процесса счета и его частичной автоматизации, появились лишь в XVII веке.
1614-й. Изобретение логарифмов шотландцем Джоном Непером. Вначале были составлены таблицы логарифмов, а затем, после смерти Непера, была изобретена логарифмическая линейка.
1642-й. Француз Блэз Паскаль изобрел и построил суммирующую машину - прототип арифмометра. В этой машине каждому десятичному разряду соответствовало колесико с нанесенными на него делениями от 0 до 9. Соседние колесики были механически связаны так, что избыток над 9 колесико передавало следующему, поворачивая его на 1. Этот прибор, практически без изменений, просуществовал и был в использовании более трех столетий!
1814-й. Англичанин Чарльз Бэббидж изобрел разностную машину, предназначенную для расчета и печати больших математических таблиц. В 1822 году он же сконструировал аналитическую машину, производящую вычисления по набору инструкций, записанных на перфокартах.
1890-й. Американец Герман Холлерит построил статистический табулятор с целью ускорить обработку результатов переписи населения. Машина Холлерита имела большой успех, на ее основе было создано преуспевающее предприятие, которое в 1924 году превратилась в фирму IBM - крупнейшего производителя современной вычислительной техники.
1936-й. Англичанин Алан Тьюринг опубликовал основополагающую работу "О вычислимых числах", заложив теоретические основы теории алгоритмов.
1943-й. Под руководством американца Говарда Айкена по заказу и при поддержке фирмы IBM создан Mark-1 - первый программно-управляемый компьютер. Он был построен на электромеханических реле, а программа обработки данных вводилась с перфоленты.
1945-й. Американец Джон фон Нейман в отчете "Предварительный доклад о машине Эниак" сформулировал принципы работы и компоненты современного программно-управляемого компьютера. Он определил четыре основные компоненты:
· Арифметико-Логическое Устройство (АЛУ);
· устройство управления;
· память;
· устройство ввода/вывода информации.
С тех пор архитектура подобных компьютеров (а подавляющее большинство современных компьютеров построено в соответствие с ней) называется фон-неймановской.
1946-й. Американцы Джон Преспер Экерт и Джон Уильям Мочли создали первый мощный электронно-цифровой компьютер "Эниак" (ENIAC - Electronic Numerical Integrator and Calculator), в 1000 раз более быстродействующий, чем Mark-1.
1956-й. FORTRAN - первый реализованный язык программирования высокого уровня. Создан в период с 1954 по 1957 годы группой программистов под руководством Джона Бэкуса (John Backus) в корпорации IBM (язык Планкалкюль, претендующий на пальму первенства, был изобретен еще в 1945 году, но не был реализован вплоть до 2000 года). Название FORTRAN является аббревиатурой от FORmula TRANslator, то есть переводчик формул. Язык Фортран широко используется до сих пор - в первую очередь для научных и инженерных вычислений.
1958-й. Американец Джек Килби сконструировал первую интегральную схему.
1960-й. Разработан алгоритмический язык АЛГОЛ-60.
1963-й. Профессоры Дартмутского колледжа Томас Курт (Thomas E. Kurtz) и Джон Кемени (John G. Kemeny) разработали алгоритмический язык Бейсик ( BASIC - Beginner's All-purpose Symbolic Instruction Code - универсальный код символических инструкций для начинающих; Basic - основной, базовый) - семейство высокоуровневых языков программирования. Язык предназначался для обучения программированию и получил широкое распространение в виде различных диалектов, прежде всего как язык для домашних микрокомпьютеров.
1964-й. 7 апреля фирма IBM объявила о создании семейства компьютеров System-360. Это был важнейший шаг к унификации, совместимости и стандартизации компьютеров. В этом же году в серии статей о науке и технике будущего в английском журнале "New Scientist" впервые появилось словосочетание "персональный компьютер" (Personal Computer - PC).
1970-й. Швейцарец Никлаус Вирт разработал язык программирования Паскаль, получивший впоследствии широкое распространение в обучении и программировании.
1971-й. Под руководством инженера фирмы Intel Теда Хоффа создан первый микропроцессор - 4-разрядный 4004 или, как его назвали, "компьютер в одном кристалле". Он состоял из 2250 транзисторов и выполнял все функции центрального процессора универсального компьютера.
1974-й. На компьютерном рынке появился микрокомпьютер Altair на базе Intel 8080. Мирная жизнь рынка, где царили IBM и DEC, была нарушена маленькой компанией MITS из Альбукерке, предложившей машину для каждого. Хотя Altair с большой натяжкой можно было назвать компьютером: MITS предлагала изделие типа "сделай сам" - комплект, из которого терпеливый пользователь с помощью паяльника, в конце концов, мог получить довольно сложное в эксплуатации устройство. Однако, не в последнюю очередь благодаря широкой рекламе, желающих заполучить собственный компьютер за вполне доступную (400 долл.) цену оказалось предостаточно.
1975-й. Студенты Пол Аллен и Билл Гейтс реализовали интерпретатор языка Бейсик для персонального компьютера Altair. Они же основали компанию Microsoft, являющуюся сегодня крупнейшим производителем программного обеспечения персональных компьютеров.
Создан микропроцессор MOP-technology 6502, он состоял из 4300 транзисторов и широко использовался в персональных компьютерах того времени.
Фирма IBM представила на рынок один из первых лазерных принтеров IBM 3800.
1977-й. В этом году в массовое производство были запущены три персональных компьютера: Apple-2 (Apple Computer) на базе процессора 6502, PET (Commodore) на базе процессора 8088, TRS-80 (Tendy Corporation) на базе процессора Z80.
1983-й. Фирма Apple Computer построила персональный компьютер Apple Lisa - первый компьютер, управляемый манипулятором "мышь".
В этом же году началось массовое использование гибких дисков (дискет) как стандартных носителей информации.
1985-й. Первая попытка Microsoft реализовать многозадачную операционную среду для персонального компьютера на основе графического интерфейса Windows 1.01.
1988-й. Основатель фирмы Apple Стив Джобс со своей новой фирмой Next Computer создали компьютер Next и операционную систему Next Step.
Фирмой Philips разработан стандарт записи компакт-дисков CD-I (CD-Interactive).
1989-й. Тим Бернерс-Ли (Tim Berners-Lee, Conseil Europeen pour la Recherche Nucleaire - CERN, Женева) предложил концепцию распределенной информационной системы с целью "объединения знаний человечества", которую он назвал "Всемирной паутиной" (World Wide Web - WWW). Для ее создания он объединил две существующие технологии - технологию IP-протоколов для передачи данных и технологию гипертекста (Hypertext Technology).
1991-й. Создан первый браузер (Browser) - компьютерная программа просмотра гипертекста - работавший в режиме командной строки. Его применение позволило уже в 1992 году успешно реализовать предложенный проект, который был направлен в конечном итоге на создание "бесшовного информационного пространства" (Seamless Informational Area), охватывающего всю планету.
1993-й. Фирма Intel представила микропроцессор Pentium.
Фирма Siemens представила свой нейрокомпьютер "Synapse1", мощность которого эквивалентна 8000 рабочих станций. Компьютер параллельно обрабатывает информацию от сети искусственных нейронов - идеальное устройство для решения задач по распознаванию изображений и речи.
1995-й. Главным событием в мире программного обеспечения персональных компьютеров стало создание универсальной многозадачной операционной системы Windows 95. Выпущенная в сентябре 1995 года система Windows 95 стала первой графической операционной системой для компьютеров IBM PC. Впоследствии эта операционная система получила свое развитие в Windows 98.
Производители аппаратно-программного обеспечения изготавливают узлы и устройства так, чтобы они были совместимы с Windows 95(98). Теперь можно приобретать новые устройства и устанавливать их в компьютер, рассчитывая на то, что все прочие устройства и программы будут работать нормально. Фирма Microsoft в системе Windows 95 ввела новый стандарт самоустанавливающихся устройств (Plug & Play).
1996-й. С каждым новым поколением ЭВМ увеличивались быстродействие и надежность их работы при уменьшении стоимости и размеров, совершенствовались устройства ввода/вывода информации. В соответствии с трактовкой компьютера - как технической модели информационной функции человека - устройства ввода приближаются к естественному для человека восприятию информации (зрительному, звуковому, тактильному), и, следовательно, операция по ее вводу в компьютер становится все более удобной для человека.
В последней четверти ХХ века промышленные ЭВМ, а затем персональные компьютеры стали аппаратно-вычислительной основой создания многофункциональных управляющих и информационных систем. В таблице 2.4 приведены параметры электронно-вычислительных устройств разных поколений.
|
Таблица 2.4. |
|||||
|
Поколение |
Элементная база |
Быстродействие |
Программное обеспечение |
Применение |
Примеры |
|
1-е (1946-1959) |
Электронные лампы |
10-20 тыс. операций/сек |
Машинные языки |
Расчетные задачи |
ЭНИАК (США), МЭСМ (СССР), УРАЛ (СССР) |
|
2-е (1960-1969) |
Полупроводники |
100-500 тыс. операций/сек |
Алгоритмические языки, диспетчерские системы, пакетный режим |
Инженерные, научные, экономические задачи |
IВМ 701 (США), БЭСМ-6, БЭСМ-4 (СССР), Минск-22 (СССР) |
|
3-е (1970-1979) |
Интегральные микросхемы |
Порядка 1 млн операций/сек |
Операционные системы, режим разделения времени |
АСУ, САПР, научно-технические задачи |
IBM 360 (США), ЕС 1030, 1060 (СССР) |
|
4-е (1980 - наст. время) |
СБИС, микропроцессоры |
Десятки и сотни млн. операций/сек |
Базы и банки данных |
Управление, коммуникации, АРМ, обработка текстов, графика |
ПЭВМ, серверы |
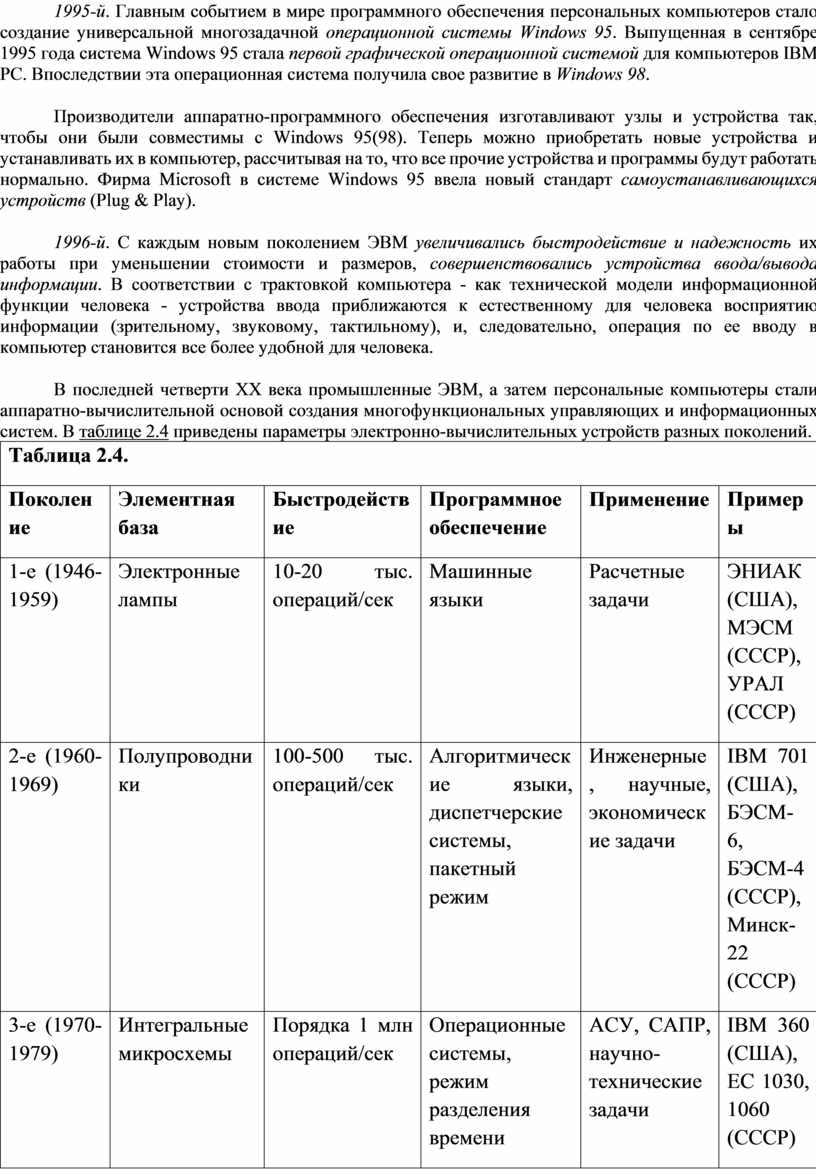
Современный компьютер принято разделять на аппаратную часть ("железо" - Hardware) и программное обеспечение (ПО - Software). На рис. 2.7 показана упрощенная схема системной ("материнской") платы персонального компьютера. В физическом исполнении на плате имеются соответствующие разъемы (слоты) для размещения процессора, модулей оперативной памяти, подключения устройств ввода/вывода.
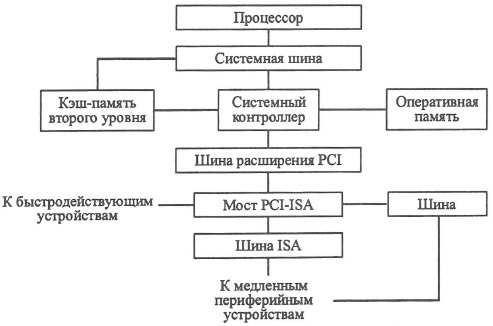
Рис. 2.7.
Интерфейс между процессором, внутренними и внешними устройствами осуществляется с помощью шин и совокупности устанавливаемых на плате специальных микросхем (Chipset). На плате размещается также специализированный блок (Basic Input/Output System -- BIOS), который предназначен для хранения параметров конфигурации персонального компьютера, аппаратных драйверов и программы POST, проверяющей при включении компьютера работоспособность его различных устройств.
Научно-технический прогресс в первую очередь влияет на развитие аппаратной части: уменьшаются геометрические размеры транзисторов, увеличивается быстродействие, растет скорость передачи данных и т. п.; но новые аппаратные возможности дают импульс созданию новых программ. Покупатель компьютера в основном платит за стоимость аппаратуры, которую, один раз купив, нельзя бесплатно много раз обновлять. "Мягкость" составной части программного обеспечения, разработанного на базе принципа "открытых систем", обеспечивается возможностью "загрузки" разных программ на одну и ту же аппаратную платформу. Это позволяет многократно увеличить скорость обновления функциональных возможностей компьютеров (скорость предоставления новых сервисов для пользователей).
Программное обеспечение обычно разделяют на системное и прикладное.
Операционная система (ОС) - базовый комплекс компьютерных программ, обеспечивающий управление аппаратными средствами компьютера, работу с файлами, ввод и вывод данных, а также выполнение прикладных программ и утилит.
При включении компьютера операционная система загружается в память раньше остальных программ и затем служит платформой и средой для их работы. Помимо вышеуказанных функций ОС может осуществлять и другие, например предоставление пользовательского интерфейса, сетевое взаимодействие и т. п. Выбор того или иного системного программного обеспечения достаточно сильно зависит от аппаратной части компьютера. В настоящее время широко используются Microsoft Windows, Mac OS и системы класса UNIX.
Назначение и функции прикладного ПО настолько разнообразны, что даже простое перечисление заняло бы слишком много места - этому разделу знаний посвящена достаточно обширная литература.
При произнесении слова "суперкомпьютеры" воображение рисует сцены, навеянные научно-фантастическими романами, - огромные помещения, которые заполнены сложными вычислительными устройствами, именуемыми "электронным мозгом". В действительности дело обстоит не совсем так. Первые экземпляры суперкомпьютеров и в самом деле были достаточно громоздкими. Успехи микроэлектроники и нанотехнологий позволили уменьшить суперкомпьютер до нескольких небольших "шкафов", находящихся в одной комнате средних размеров. Современный суперкомпьютер - это мощный компьютер с производительностью несколько миллиардов операций с плавающей точкой в секунду. Суперкомпьютер представляет собой многопроцессорный и/или многомашинный комплекс, работающий на общую память и общее поле внешних устройств.
Чаще всего авторство термина приписывается Д.Мишелю и С.Фернбачу, в конце 60-х годов XX века работавшим в Ливерморской национальной лаборатории и компании Control Data Corporation. Тем не менее, известен факт, что еще в 1920 году в газете New York World рассказывалось о "супервычислениях" (Supercomputing), выполняемых при помощи уникального мощного табулятора IBM, который был собран по заказу Колумбийского университета.

Рис. 2.8. Cray-2 - самый быстрый компьютер 90-х годов ХХ века
Термин "суперкомпьютер" вошел в общеупотребительный лексикон благодаря распространенности компьютерных систем американца Сеймура Крея - Control Data 6600, Control Data 7600, Cray-1, Cray-2, Cray-3 и Cray-4 (рис. 3.4.3). Крей разрабатывал вычислительные машины, которые, по сути, становились основными вычислительными средствами правительственных, промышленных и академических научно-технических проектов США с середины 60-х годов до 1996 года. Неслучайно в то время одним из популярных определений суперкомпьютера было следующее: "любой компьютер, который создал Сеймур Крей". Сам Крей никогда не называл свои детища суперкомпьютерами, предпочитая использовать вместо этого обычное название "компьютер".
На сегодняшний день суперкомпьютеры являются уникальными системами, создаваемыми "традиционными" лидерами компьютерного рынка, такими как IBM, Hewlett-Packard, NEC и другими, которые приобрели множество ранних компаний, вместе с их опытом и технологиями. Компания Cray Inc. по прежнему занимает достойное место в ряду производителей суперкомпьютерной техники.
Большинство суперкомпьютеров 70-х годов ХХ века оснащались векторными процессорами, К началу и середине 1980-х небольшое число (от 4 до 16) параллельно работающих векторных процессоров практически стало стандартным суперкомпьютерным решением. Типичный векторный компьютер включает в себя скалярный процессор целочисленной арифметики, функциональные блоки сложения и умножения чисел с плавающей точкой, векторный процессор и общую память. Это компьютеры, построенные по технологии "разделяемая память - один поток управления - много потоков данных" ("Shared Memory - Single Instruction - Multi Data").
Конец 1980-х и начало 1990-х годов охарактеризовались сменой магистрального направления развития суперкомпьютеров от векторно-конвейерной обработки данных к большому и сверхбольшому числу параллельно соединенных скалярных процессоров.
Массивно-параллельные системы стали объединять в себе сотни и даже тысячи отдельных процессорных элементов, причем ими могли служить не только специально разработанные, но и общеизвестные и доступные в свободной продаже процессоры. Большинство массивно-параллельных компьютеров создавалось на основе мощных процессоров с архитектурой RISC (Reduced Instruction Set Computer), наподобие Power PC или PA- RISC. Использование серийных микропроцессоров позволило не только гибко менять мощность установки в зависимости от потребностей и возможностей, но и значительно удешевить производство. Примерами суперкомпьютеров этого класса могут служить Intel Paragon, IBM SP, Сray T3D/T3E и ряд других.
В ноябре 2002 года фирма Cray Inc. анонсировала решение Cray X1 с характеристиками 52,4 Тфлопс и 65,5 Тб ОЗУ (флопс - термин от английского словосочетания Floating Point, означающего вычисления с плавающей точкой). Его стартовая цена начиналась с 2,5 миллионов долларов. Этим комплексом сразу заинтересовался испанский метеорологический центр. В это же время был опубликован список Top 500 (http://www.top500.org), в который входили вычислительные системы, официально показавшие максимальную производительность. Его возглавила "Компьютерная модель Земли" (Earth Simulator) с результатом 35,86 Тфлопс (5120 процессоров), созданная одноименным японским центром и NEC. На втором-четвертом местах со значительным отставанием расположились решения ASCI (7,7; 7,7 и 7,2 Тфлопс). Они эксплуатируются Лос-Аламосской лабораторией ядерных исследований, а созданы Hewlett-Packard (первые два насчитывают по 4096 процессоров) и IBM (8192 процессора).
Петафлопсный рубеж (тысяча триллионов операций с плавающей запятой в секунду) компания Cray Inc. обещает преодолеть к концу десятилетия. Схожие сроки сулят и японцы. В Токио в рамках соответствующего проекта GRAPE [http://grape.astron.s.u-tokyo.ac.jp/grape/] готовится модель GRAPE-6. Она объединяет 12 кластеров и 2048 процессоров и показывает производительность 2,889 Тфлопс (с потенциальными возможностями 64 Тфлопс). В перспективе в GRAPE-решение будет включено 20 тыс. процессоров, а обойдется оно всего в 10 миллионов долларов
Однако уникальные решения с рекордными характеристиками обычно недешевы, поэтому и стоимость подобных систем никак не могла быть сравнима со стоимостью систем, находящихся в массовом производстве и широко используемых в бизнесе. Прогресс в области сетевых технологий сделал свое дело: появились недорогие, но эффективные решения, основанные на коммуникационных технологиях. Это и предопределило появление кластерных вычислительных систем, фактически являющихся одним из направлений развития компьютеров с массовым параллелизмом вычислительного процесса (Massively Parallel Processing - MPP).
Вычислительный кластер - это совокупность компьютеров, объединенных в рамках некоторой сети для решения крупной вычислительной задачи. В качестве узлов обычно используются доступные однопроцессорные компьютеры, двух- или четырехпроцессорные SMP-серверы (Symmetric Multi Processor). Каждый узел работает под управлением своей копии операционной системы, в качестве которой чаще всего используются стандартные операционные системы: Linux, NT, Solaris и т. п. Рассматривая крайние точки зрения, кластером можно считать как пару персональных компьютеров, связанных локальной 10-мегабитной сетью Ethernet, так и обширную вычислительную систему, создаваемую в рамках крупного проекта. Такой проект объединяет тысячи рабочих станций на базе процессоров Alpha, связанных высокоскоростной сетью Myrinet, которая используется для поддержки параллельных приложений, а также сетями Gigabit Ethernet и Fast Ethernet для управляющих и служебных целей.
Состав и мощность узлов может меняться даже в рамках одного кластера, давая возможность создавать обширные гетерогенные (неоднородные) системы с задаваемой мощностью. Выбор конкретной коммуникационной среды определяется многими факторами: особенностями класса решаемых задач, доступным финансированием, необходимостью последующего расширения кластера и т. п. Возможно включение в конфигурацию специализированных компьютеров, например файл-сервера, и, как правило, предоставлена возможность удаленного доступа на кластер через Internet.
На современном рынке представлено не так много поставщиков готовых кластерных решений. Это связано, прежде всего, с доступностью комплектующих, легкостью построения самих систем, значительной ориентацией на свободно распространяемое программное обеспечение, а также с уникальностью задач, решаемых с помощью кластерных технологий. Среди наиболее известных поставщиков стоит отметить SGI, VALinux и Scali Computer.
Летом 2000 года Корнелльский университет (США) основал Консорциум по кластерным технологиям (Advanced Cluster Computing Consortium), основная цель которого - координация работ в области кластерных технологий и помощь в осуществлении разработок в данной области. Ведущими компаниями, обеспечивающими инфраструктуру консорциума, стали крупные производители компьютерного оборудования и программного обеспечения - Dell, Intel и Microsoft. Среди других членов консорциума можно назвать Аргоннскую национальную лабораторию, Нью-Йоркский, Корнелльский и Колумбийский университеты, компании Compaq, Giganet, IBM, Kuck & Associates и другие.
Из интересных российских проектов следует отметить решение, реализованное в Санкт-Петербургском университете на базе технологии Fast Ethernet [http://www.ptc.spbu.ru]: собранные кластеры могут использоваться и как полноценные независимые учебные классы, и как единая вычислительная установка, решающая крупную исследовательскую проблему. В Самарском научном центре пошли по пути создания неоднородного вычислительного кластера, в составе которого работают компьютеры на базе процессоров Alpha и Pentium III. В Санкт-Петербургском техническом университете собирается установка на основе процессоров Alpha и сети Myrinet без использования локальных дисков на вычислительных узлах. В Уфимском государственном авиационном техническом университете проектируется кластер на базе двенадцати Alpha-станций, сети Fast Ethernet и ОС Linux [www.osp.ru/os/2000/05-06/178019/].
Технологии суперкомпьютеров и кластеров первоначально "выросли" в основном из научных потребностей - для решения фундаментальных и прикладных задач физики, механики, астрономии, метеорологии, сопротивления материалов и т. д., где требовались огромные вычислительные мощности. В каких рыночных нишах будет востребована подобная производительность? Прежде всего, это проектирование сложных управляемых систем (самолетов, ракет, космических станций), создание синтетических лекарств с заданными свойствами, генная инженерия, предсказание погоды и природных катаклизмов, повышение эффективности и надежности атомных электростанций, прогнозирование макроэкономических эффектов и многое другое.
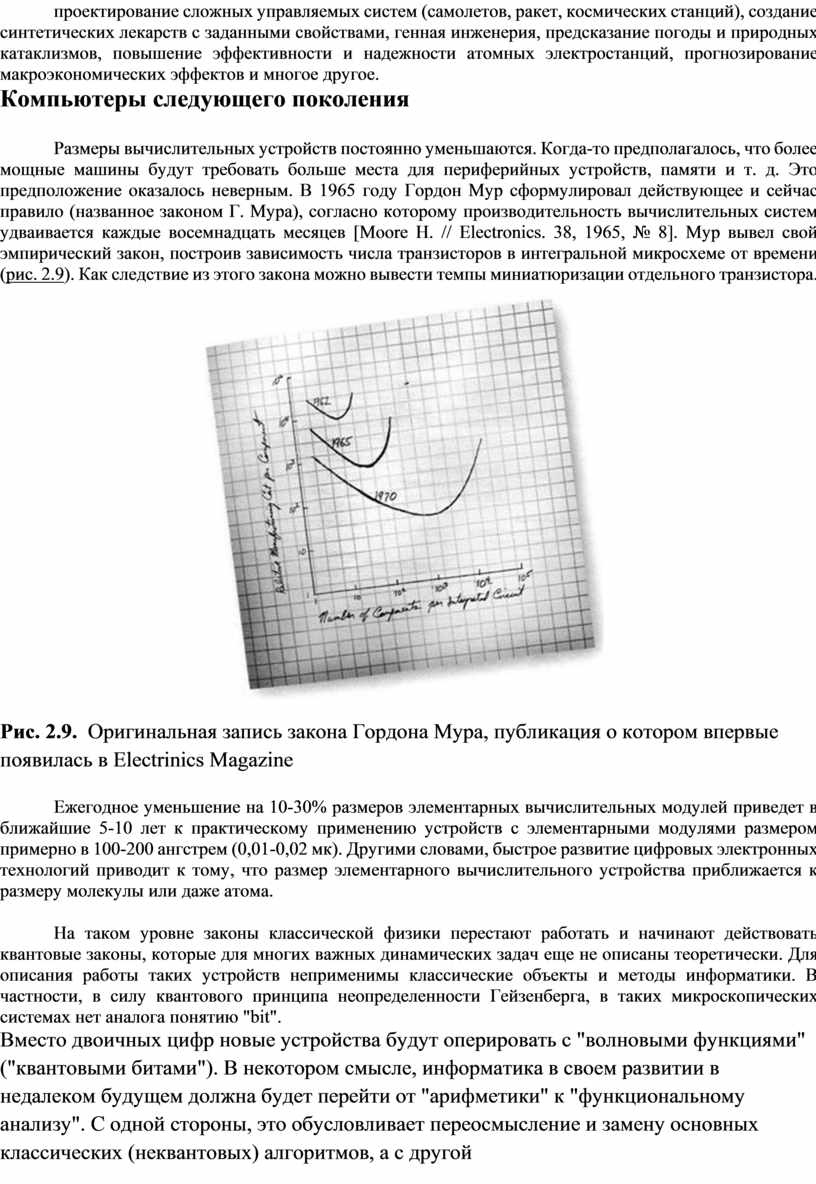
Размеры вычислительных устройств постоянно уменьшаются. Когда-то предполагалось, что более мощные машины будут требовать больше места для периферийных устройств, памяти и т. д. Это предположение оказалось неверным. В 1965 году Гордон Мур сформулировал действующее и сейчас правило (названное законом Г. Мура), согласно которому производительность вычислительных систем удваивается каждые восемнадцать месяцев [Moore H. // Electronics. 38, 1965, № 8]. Мур вывел свой эмпирический закон, построив зависимость числа транзисторов в интегральной микросхеме от времени (рис. 2.9). Как следствие из этого закона можно вывести темпы миниатюризации отдельного транзистора.
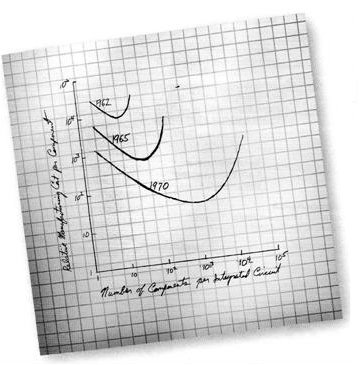
Рис. 2.9. Оригинальная запись закона Гордона Мура, публикация о котором впервые появилась в Electrinics Magazine
Ежегодное уменьшение на 10-30% размеров элементарных вычислительных модулей приведет в ближайшие 5-10 лет к практическому применению устройств с элементарными модулями размером примерно в 100-200 ангстрем (0,01-0,02 мк). Другими словами, быстрое развитие цифровых электронных технологий приводит к тому, что размер элементарного вычислительного устройства приближается к размеру молекулы или даже атома.
На таком уровне законы классической физики перестают работать и начинают действовать квантовые законы, которые для многих важных динамических задач еще не описаны теоретически. Для описания работы таких устройств неприменимы классические объекты и методы информатики. В частности, в силу квантового принципа неопределенности Гейзенберга, в таких микроскопических системах нет аналога понятию "bit".
Вместо двоичных цифр новые устройства будут оперировать с "волновыми функциями" ("квантовыми битами"). В некотором смысле, информатика в своем развитии в недалеком будущем должна будет перейти от "арифметики" к "функциональному анализу". С одной стороны, это обусловливает переосмысление и замену основных классических (неквантовых) алгоритмов, а с другой - дает возможность вплотную подступиться к решению проблем искусственного интеллекта.
В научно-исследовательских лабораториях крупнейших университетов и транснациональных ИТ-компаний рассматриваются несколько возможных основных направлений создания элементной базы нового поколения вычислительных устройств [Граничин О.Н., Молодцов С.Л. Создание гибридных сверхбыстрых компьютеров и системное программирование. СПб., 2006]:
· на принципах ядерного магнитного или электронного парамагнитного резонанса;
· на атомных ионах, помещенных в ловушки Паули или Пеннинга;
· с использованием явления сверхпроводимости;
· на квантовых точках в полупроводниковых неорганических системах;
· на основе оптической симуляции квантовой логики или на металло-биологической гибридной основе.
Многие из указанных направлений имеют существенные недостатки, которые в некоторых случаях приводят к принципиальной невозможности создания конкурентоспособного вычислительного устройства. Характерным примером является проект корпорации IBM, которая в 1999 году только на первый этап разработки молекулярной элементной базы нового поколения выделила 17 миллиардов долларов на 5 лет. В результате был создан макет, оперирующий с 5 или 7 квантовыми битами и весом около 7 тонн, способный решать только примитивные задачи типа разложения числа 15 на два множителя 5 и 3 [domino.research.ibm.com/comm/pr.nsf/-pages/rsc.quantum.html?Open&printable].
В настоящее время наиболее перспективным направлением разработки элементной базы компьютеров нового поколения представляется использование самоорганизующихся квантовых точек в твердотельных системах, которые могут выполнять функции квантовых битов и быть связанными в квантовый регистр на основе, например, электростатического или магнитного типа взаимодействия.
1. Назовите основные сферы применения ИТ.
2. Каким образом формализуется процесс обработки информации?
3. Что такое базы данных (БД) и системы управления базами данных (СУБД)?
4. Дайте определение хранилищу данных. Чем хранилище данных отличается от базы данных?
5. Приведите несколько примеров вычислительных устройств различных поколений.
6. Что такое суперкомпьютер и чем он отличается от кластера?
7. Решения каких задач ожидают от вычислительных устройства нового поколения?
Скачано с www.znanio.ru


















Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.
