Поделиться

Алгоритм – (арабского происхождения)предписание, однозначно задающее процесс преобразования исходной информации в виде последовательности элементарных дискретных шагов, приводящих за их конечное число к результату.
Основные свойства алгоритма:
1.Дискретность. Процесс решения протекает в виде последовательности отдельных действий, следующих друг за другом.
2.Элементарность действий. Каждое действие является настолько простым, что оно не допускает возможности неоднозначного толкования.
3.Определенность. Каждое действие определено и после выполнения каждого действия однозначно определяется, какое действие будет выполнено следующим.
4.Конечность. Алгоритм заканчивает работу после конечного числа шагов.
5.Результативность. В момент прекращения работы алгоритма известно, что является результатом.
6.Массовость. Алгоритм описывает некоторое множество процессов, применимых при различных входных данных.
Алгоритм считается правильным, если при любых допустимых данных он заканчивает работу и выдает результат, удовлетворяющий требованиям задачи. Алгоритм однозначен, если при применении к одним и тем же входным данным он дает один и тот же результат.
Схема определения алгоритма в практическом смысле выглядит так:
1. Всякий алгоритм применяется к исходным данным и выдает результирующие данные. В ходе работы алгоритма появляются промежуточные данные. Для описания данных фиксируется набор элементарных символов (алфавит данных) и даются правила построения сложных данных из простых. Примеры простых данных: целые и действительные числа, логические переменные, символьные переменные. Примеры сложных данных: массивы, строки, структуры.
2. Данные для своего размещения требуют памяти. В ЭВМ память состоит из ячеек. Единицы объема данных и памяти согласованы, и в прикладных алгоритмических моделях объем данных можно измерять числом ячеек, в которых данные размещены.
3. Элементарные шаги алгоритма состоят из базовых действий, число которых конечно. Под ними можно подразумевать машинные команды, входящие в набор команд ЭВМ. При записи алгоритмов на языках высокого уровня в качестве базовых действий могут выступать операторы языка.
Можно выделить три крупных класса алгоритма:
- Вычислительные алгоритмы, как правило, работают с простыми видами данных (числа, матрицы), но сам процесс вычисления может быть долгим и сложным.
- Информационные алгоритмы представляют собой набор сравнительно небольших процедур
(например, поиск числа, слова), но работающих с большими объемами информации (базы данных). Для того чтобы они работали эффективно, важно иметь хорошую организацию данных.
- Управляющие алгоритмы характерны тем, что данные к ним поступают от внешних процессов, которыми они управляют. Результатом работы этих алгоритмов являются различные управляющие воздействия.
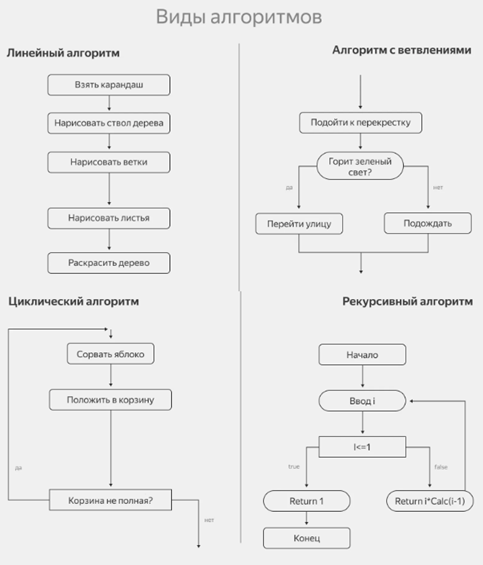
Классификация алгоритмов с примерами
Существует множество способов классификации алгоритмов, некоторые из которых показаны ниже:
1. Метод реализации
2. Метод проектирования
3. Другие классификации
1. Рекурсия или итерация
· Рекурсивный алгоритм — это алгоритм, который многократно вызывает сам себя до тех пор, пока не будет выполнено базовое условие. Это распространенный метод, используемый в функциональных языках программирования.
· Итеративные алгоритмы используют такие конструкции, как циклы, а иногда и другие структуры данных, например, стеки и очереди, для решения задач.
· Некоторые задачи подходят для рекурсивного решения, а другие — для итеративного. Например, задачу о Ханойских башнях легко понять с помощью рекурсивной реализации. Каждая рекурсивная версия имеет итеративную версию, и наоборот.
· В декларативных языках программирования мы говорим, чего хотим, не указывая, как это сделать.
· При процедурном программировании необходимо точно указать шаги для получения результата. Например, SQL более декларативен, чем процедуренен, поскольку запросы не описывают шаги для получения результата. Примерами процедурных языков являются C, PHP и PERL.
· Как правило, при обсуждении алгоритмов мы предполагаем, что компьютеры выполняют по одной инструкции за раз. Такие алгоритмы называются последовательными.
· Параллельные алгоритмы используют преимущества компьютерной архитектуры для обработки нескольких инструкций одновременно. Они делят задачу на подзадачи и передают их нескольким процессорам или потокам. Итеративные алгоритмы, как правило, распараллеливаются.
· Если параллельные алгоритмы распределены по разным машинам, то такие алгоритмы называются распределенными алгоритмами.
· Детерминированные алгоритмы решают задачу с помощью заранее определенного процесса, тогда как недетерминированные алгоритмы угадывают наилучшее решение на каждом шаге, используя эвристические методы.
· Алгоритмы, для которых мы можем найти оптимальные решения, называются точными алгоритмами. В информатике, если оптимальное решение не найдено, используются приближенные алгоритмы.
· Приближенные алгоритмы обычно связаны с NP-трудными задачами.
Ещё один способ классификации алгоритмов — по методу их проектирования.
· Жадные алгоритмы работают поэтапно.
· На каждом этапе принимается решение, которое является правильным на данный момент, без учета будущих последствий.
· Как правило, это означает, что выбирается некий локально наилучший вариант. Предполагается, что выбор локально наилучшего варианта также приводит к глобально оптимальному решению.
Стратегия «разделяй и властвуй» решает проблему следующим образом:
1. Разделение: Разбиение проблемы на подпроблемы, которые, в свою очередь, являются более мелкими примерами проблемы того же типа.
2. Рекурсия: Рекурсивное решение этих подзадач.
3. Победа: надлежащее объединение их ответов. Примеры: алгоритмы сортировки слиянием и бинарного поиска.
· Динамическое программирование (ДП) и запоминание работают вместе. Разница между ДП и методом «разделяй и властвуй» заключается в том, что в
последнем случае нет зависимости между подзадачами, тогда как в ДП происходит перекрытие подзадач. Используя запоминание [поддержание таблицы уже решенных подзадач], ДП снижает экспоненциальную сложность до полиномиальной сложности (O(nZ), O(n3) и т. д.) для многих задач.
· Разница между динамическим программированием и рекурсией заключается в запоминании рекурсивных вызовов. Когда подзадачи независимы и нет повторений, запоминание не требуется.
· Справка: следовательно, динамическое программирование не является решением всех проблем.
· Использование механизма запоминания [ведение таблицы уже решенных подзадач] позволяет динамическому программированию снизить сложность с экспоненциальной до полиномиальной.
· В линейном программировании существуют неравенства, выраженные через входные данные и максимизирующие (или минимизирующие) некоторую линейную функцию от этих входных данных.
· Многие задачи (например, задача о максимальном потоке для ориентированных графов) можно решить с помощью линейного программирования.
· В этом методе мы решаем сложную задачу, преобразуя ее в известную задачу, для которой у нас есть асимптотически оптимальные алгоритмы. Цель этого метода — найти упрощающий алгоритм, сложность которого не определяется сложностью результирующих упрощенных алгоритмов. Например, алгоритм выбора медианы в списке включает в себя сначала сортировку списка, а затем поиск среднего элемента в отсортированном списке. Эти методы также называются «преобразование и завоевание».
1. Классификация по областям исследований
В информатике каждая область имеет свои собственные проблемы и требует эффективных алгоритмов. Примеры: алгоритмы поиска, алгоритмы сортировки, алгоритмы слияния, численные алгоритмы, алгоритмы обработки графов, алгоритмы обработки строк, геометрические алгоритмы, комбинаторные алгоритмы, машинное обучение, криптография, параллельные алгоритмы, алгоритмы сжатия данных, методы синтаксического анализа и многое другое.
В этой классификации алгоритмы различаются по времени, необходимому для нахождения решения, в зависимости от размера входных данных. Некоторые алгоритмы имеют линейную временную сложность (O(n)), другие — экспоненциальную, а некоторые и вовсе никогда не останавливаются. Следует отметить, что для решения некоторых задач может существовать несколько алгоритмов с различной сложностью.
Некоторые алгоритмы принимают решения случайным образом. Для некоторых задач самые быстрые решения должны включать случайность. Пример: быстрая сортировка.
Сложность алгоритма – это мера того, насколько сильно усложняется процесс вычисления (возрастают затраты ресурсов, трудоемкость) при увеличении объема входных данных.
Пример:
У каждого алгоритма есть худший, средний и лучший сценарии работы — в зависимости от того, насколько удачно выбраны входные данные. Часто их называют случаями.
Пример: в лучшем случае сортировка пузырьком имеет O(N)сложность (когда массив уже отсортирован), в худшем - квадратичную O(N2).
Пример: Нужно найти заданный элемент в списке из N элементов. В лучшем случае этот элемент будет первым - тогда сложность будет O(1).В худшем - нужный элемент будет последним, тогда сложность будет O(N). Но в среднем придется сделать N/2сравнений, а значит усредненная сложность - O(N/2) = O(N).
Например, если мы хотим отсортировать массив по возрастанию (Ascending Order, коротко ASC), то для простых алгоритмов сортировки худшим случаем будет массив, отсортированный по убыванию (Descending Order, коротко DESC).
Для алгоритма поиска элемента в неотсортированном массиве worst case — это когда искомый элемент находится в конце массива или если элемента нет вообще (поиск элемента, которого нет в списке, или он стоит последним)
- Лучший случай (Best Case) - полная противоположность worst case, самые удачные входные данные. Минимальное время работы. Например, поиск элемента, который стоит первым в списке, правильно отсортированный массив, с которым алгоритму сортировки вообще ничего делать не нужно. В случае поиска — когда алгоритм находит нужный элемент с первого раза.
Асимптотический анализ и О-нотация
Асимптотический анализ — метод оценки эффективности алгоритмов, фокусирующийся на их поведении при больших объемах входных данных.
Этот подход абстрагируется от конкретных реализаций и машинных особенностей, концентрируясь на фундаментальном росте времени исполнения.
Ключевые принципы асимптотического анализа:
– Фокус на скорости роста — важна не абсолютная скорость, а темп её изменения с ростом входных данных
– Игнорирование констант — множители и константы становятся несущественными при больших n
– Учет наихудшего случая — обеспечивает гарантированную производительность в любых условиях
Не требуется знать точное значение сложности алгоритма.
Никому не требуется знать точное значение сложности алгоритма.
Оценка производится в асимптотических терминах с помощью O-нотации (Big O), т.е. отвечая на вопрос: Если мы до бесконечности будем увеличивать объем входных данных, как будет меняться работа нашего алгоритма? .
O-нотация (Big O) — математический инструмент для описания асимптотического поведения алгоритмов, который определяет верхнюю границу роста функции (какой функцией ограничена асимптотическая сложность алгоритма), указывая на наихудший сценарий производительности. Формально запись O(f(n)) означает, что время выполнения алгоритма растет не быстрее, чем функция f(n) при достаточно больших n.
Пример:
Сложность перебора коллекции - O(n). Это значит, что сложность алгоритма будет расти линейно. Увеличим объем данных в 10 раз - сложность вырастет в 10 раз. Увеличим в 100 - вырастет в 100.
Понимание нотации «О» большое позволяет:
· Сравнивать эффективность различных алгоритмов для решения одной и той же задачи.
· Прогнозировать поведение алгоритма при увеличении размера входных данных.
· Оптимизировать код путем идентификации и улучшения сложных алгоритмов.
· Выбирать оптимальные структуры данных и алгоритмы при решении ресурсоемких задач.
Правила работы с O-нотацией при анализе алгоритмов:
1. Игнорирование констант: Нас интересует форма кривой, а не наклон.
O(2n) = O(n), O(500) = O(1)
2. Доминирование старших членов. Самый быстрорастущий член функции "перебивает" все остальные.
O(n2 + n) = O(n2), O(n + log n) = O(n)
3. Умножение: Если действие повторяется N раз, сложности умножаются.
O(f(n) g(n)) = O(f(n)) O(g(n))
4. Сложение: Если действия выполняются последовательно, выбирается максимальная сложность
O(f(n) + g(n)) = max(O(f(n)), O(g(n)))
Однако O-нотация — лишь одна из нескольких математических нотаций, используемых для полного описания поведения алгоритмов:
· O-нотация (Big O) — верхняя граница роста функции (наихудший случай)
· Ω-нотация (Big Omega) — нижняя граница роста функции (наилучший случай)
· Θ-нотация (Big Theta) — точная характеристика роста, когда верхняя и нижняя границы совпадают
· o-нотация (Little o) — верхняя граница, которая не достигается
1 Что такое временная сложность и зачем её оценивать (Т)
Теория сложности вычислений возникла из потребности сравнивать быстродействие алгоритмов, чётко описывать их поведение (время исполнения и объём необходимой памяти) в зависимости от размера входа и выхода.
Количество элементарных операций, затраченных алгоритмом для решения конкретного экземпляра задачи, зависит не только от размера входных данных, но и от содержательных характеристик самих данных.
Например, количество операций алгоритма сортировки вставками значительно меньше в случае, если входные данные уже отсортированы.
Временная сложность алгоритма — математическая характеристика, выражающая зависимость между объемом входных данных (n) и количеством элементарных операций, необходимых для выполнения алгоритма. Фактически, она отвечает на вопрос: "Как быстро растет время выполнения с увеличением входного размера?"
Поскольку время выполнения может варьироваться для разных наборов данных одинакового размера, в теории сложности рассматривают три типа оценок:
Временная сложность алгоритма (в худшем случае) — это функция размера входных и выходных данных, равная максимальному количеству элементарных операций, проделываемых алгоритмом для решения экземпляра задачи указанного размера.
Временная сложность алгоритма (в наилучшем случае) — минимальное количество операций (как в примере с уже отсортированным массивом).
Средняя сложность алгоритма — математическое ожидание времени работы алгоритма для всех возможных входных данных данного размера.
В контексте временной сложности под размером задачи обычно понимают объем входных данных, поскольку в большинстве задач объем выхода либо не превышает объем входа, либо прямо пропорционален ему.
Оценка временной сложности критически важна по нескольким причинам:
– Предсказуемость производительности — понимание, как алгоритм масштабируется при изменении входных данных
– Сравнение алгоритмов — объективная метрика для выбора оптимального решения среди доступных
– Оптимизация ресурсов — возможность предварительно оценить требуемые вычислительные мощности
– Понимание узких мест — выявление критических участков кода до возникновения проблем в эксплуатации
Пример:
|
Размер входных данных (n) |
Линейный поиск O(n) |
Бинарный поиск O(log n) |
|
100 |
100 операций |
7 операций |
|
10,000 |
10,000 операций |
14 операций |
|
1,000,000 |
1,000,000 операций |
20 операций |
|
1,000,000,000 |
1,000,000,000 операций |
30 операций |
1. Константная O(1) - выполнения алгоритма не зависит от размера входных данных.
- извлечение первого элемента. Сколько бы элементов ни содержал массив, время выполнения операции получения элемента остаётся одинаковым.
- доступ к элементу массива по индексу
- арифметические операции между числами
- проверка логического условия;
- присвоение переменной.
2. Логарифмическая сложность O(logN) - время выполнения алгоритма растёт медленно с увеличением размера входных данных. На каждой итерации берется лишь половина элементов (алгоритмы типа «Разделяй и Властвуй» (Divide and Conquer))
- бинарный поиск в отсортированном массиве
3. Линейная O(n) - время выполнения алгоритма растет пропорционально размеру входных данных (количеству элементов). Каждый элемент обрабатывается хотя бы один раз, и общее время выполнения увеличивается вместе с объёмом входных данных.
- стандартный цикл for
- просмотр всех элементов в массиве
- линейный поиск элемента без индексации;
- обход массива, списка, коллекции;
- фильтрация, подсчёт, проверка условий;
4. Линеарифметическая или линеаризованная O(n * log n) - время выполнения алгоритма растёт быстрее, чем линейно, но медленнее, чем квадратично.
- сортировка слиянием
- быстрая сортировка (в среднем).
5. Квадратичная - O(n2) - время выполнения алгоритма зависит от квадрата размера входных данных
- двойной (вложенный) цикл
- сортировка пузырьком
6. Кубическая O(n3) - время выполнения алгоритма зависит от размера входных данных в кубе.
- алгоритмы, которые имеют три вложенных цикла, такие как некоторые методы многомерной обработки данных.
7. Экспоненциальный O(2n) - Рост настолько быстрый, что алгоритм становится непрактичным даже при небольших n.
- Рекурсивный расчет чисел Фибоначчи (наивный)
8. Факториальный - O(n!). Обладает наибольшей временной сложностью среди всех известных типов.
- Задача коммивояжера (решение полным перебором)
|
Сложность |
Название |
Описание |
Пример алгоритма |
Масштабируемость |
|
O(1) |
Константная |
Время не зависит от объема данных. |
Доступ к элементу массива по индексу. |
Превосходная |
|
O(log n) |
Логарифмическая |
Время растет очень медленно. На каждом шаге объем данных уменьшается вдвое. |
Бинарный поиск в отсортированном массиве. |
Отличная |
|
O(n) |
Линейная |
Время растет пропорционально объему данных. |
Линейный поиск, проход по массиву (один цикл for). |
Хорошая |
|
O(n log n) |
Линеарифмическая |
"Золотой стандарт" для сортировок. Растет быстрее линейной, но медленнее квадратичной. |
Сортировка слиянием, быстрая сортировка (в среднем). |
Средняя |
|
O(n²) |
Квадратичная |
Время растет пропорционально квадрату данных. |
Вложенные циклы (пузырьковая сортировка). |
Низкая |
|
O(n³) |
Кубическая |
Еще более медленные алгоритмы (тройные вложенные циклы). |
Наивное перемножение матриц. |
Очень низкая |
|
O(2ⁿ) |
Экспоненциальная |
Рост настолько быстрый, что алгоритм становится непрактичным даже при небольших n. |
Рекурсивный расчет чисел Фибоначчи (наивный). |
Критически низкая |
|
O(n!) |
Факториальная |
Наихудший вариант. |
Задача коммивояжера (решение полным перебором). |
Неприемлемая |
Сростом n временная сложность может стать настолько огромной, что это
повлияет на практическую реализуемость алгоритма. Рассмотрим таблицу, в которой сравнивается время выполнения алгоритмов разных типов при n = 106, при условии, что единицей времени для компьютера является микросекунда.
|
Тип |
Сложность |
Кол-во операций |
Время при 106 операций в сек. |
|
Постоянные |
O(1) |
1 |
1мкс |
|
Линейные |
O(n) |
106 |
1 с |
|
Квадратичные |
O(n2) |
1012 |
11.6 дн. |
|
Кубические |
O(n3) |
1018 |
32000 лет |
|
Экспоненциальные |
O(2n) |
10301030 |
в 10301006 раз больше |
Для асимптотического анализа важно выделить операцию, которая доминирует во времени исполнения.
Например, в алгоритме сортировки это обычно операция сравнения элементов. Подсчитав, сколько сравнений требуется для разных размеров входных данных, вы сможете определить зависимость и вывести асимптотическую сложность.
Метод состоит из нескольких шагов:
1. Определить параметр n — размер входных данных
2. Идентификация базовых операций в алгоритме - Выбрать базовую операцию — действие, которое выполняется чаще всего и сильнее всего влияет на время
3. Подсчитать количество операций как функцию от n
4. Упрощение функции до наиболее значимого члена
5. Удаление констант и определение класса сложности
Базовые правила расчёта
1. Если операция не зависит от объема данных и выполняется за одно и то же время, то она имеет константную сложность O(1)
Примеры:
o Извлечь первый элемент коллекции
o Сложить два числа
2. Сложение классов сложности приводит к выбору большей сложности. Если в алгоритме несколько действий выполняются последовательно, общая сложность определяется самым "медленным" из них.
o Если нужно сложить 2 числа, а затем умножить результат на 5, то сложность такой операции O(max(1, 1)) = O(1)
o Если нужно пробежаться в цикле по списку (сложность O(N)), а в конце отобрать только первый элемент (сложность O(1)), то итоговая сложность будет O(max(N, 1)) = O(N)
Примечание: на самом деле происходит не просто выбор максимальной сложности, а их сложение. Например, O(N + 1). Но при стремлении входных данных к бесконечности большая функция (N) задавит меньшую (1). Поэтому и выбирают только максимальную.
3. Сложность IF-блоков рассчитывается по формуле:
O(сложность условия) + max(O(код в if), O(код в else)).
Пример: если число больше N, возвести его в квадрат, иначе проитерировать по списку
arr длины N.
Сложность условия «если число больше N» - O(1), это простое сравнение. Сложность
«возвести его в квадрат» - O(1). Сложность «проитерировать по списку arr длины N» - O(N).
Итоговая сложность: O(1) + max(O(1), O(N)) = O(1) + O(N) = O(N).
4. При умножении классы сложности умножаются
Один цикл: O(N) × O(1) = O(N)
Вложенные циклы: O(N) × O(N) = O(N²)
Цикл с логарифмическим шагом: O(N) × O(log N) = O(N log N)
Пример:
- Если мы пробегаемся в цикле по коллекции и умножаем каждый элемент на 5, тосложность будет O(N*1), т.к. сложность умножения - O(1) и эту операцию мы повторяем N раз.
- Если мы пробегаемся в цикле по коллекции и умножаем каждый элемент на все остальные (то есть для каждого элемента пробегаемся еще в одном цикле по остальным элементам), то сложность будет O(N*1)*O(N*1) = O(N*N) = O(N^2).
Для практической оценки сложности вложенных циклов, рекурсивных функций и составных блоков кода применяются следующие техники:
// Линейная сложность O(n) for (i = 0; i < n; i++) {
// Константное время операции
}
// Квадратичная сложность O(n²) for (i = 0; i < n; i++) {
for (j = 0; j < n; j++) {
// Константное время операции
}
}
// Сложность O(n log n) for (i = 0; i < n; i++) {
for (j = 1; j < n; j = j * 2) {
// Константное время операции
}
}
При анализе рекурсивных алгоритмов часто используют метод рекуррентных соотношений. Например, для алгоритма быстрой сортировки рекуррентное соотношение имеет вид:
T(n) = 2 * T(n/2) + O(n)
Это выражение можно решить с помощью мастер-теоремы, получив итоговую оценку
O(n log n).
Важно понимать разницу между средней и наихудшей временной сложностью. Для многих алгоритмов, включая быструю сортировку, они могут существенно различаться (O(n log n) против O(nZ)), что требует дополнительного анализа для практических сценариев.
ъ
Теоретическая оценка временной сложности должна подтверждаться эмпирическими данными. Для этого используются различные практические методы измерения производительности алгоритмов.
Основные подходы к эмпирическому измерению временной сложности:
1. Профилирование кода — измерение реального времени выполнения функций
2. Подсчет операций — инструментирование кода для подсчета ключевых операций
3. Бенчмаркинг — сравнительное тестирование производительности
4. Асимптотическая верификация — проверка соответствия теоретической сложности
Для получения достоверных результатов необходимо применять следующие методики:
– Варьирование размера входных данных — измерение времени выполнения при n = 10, 100, 1000, 10000, ...
– Множественные запуски — усреднение результатов для минимизации случайных флуктуаций
– Изоляция среды выполнения — минимизация влияния внешних факторов
– Логарифмические шкалы — для наглядной визуализации зависимостей
2 Что такое пространственная сложность и зачем её оценивать (Т)
Если временная сложность отвечает на вопрос «как быстро», то пространственная сложность (или ёмкостная сложность) отвечает на вопрос «сколько памяти потребуется».
В мире, где объемы данных исчисляются терабайтами, а устройства могут быть ограничены по ресурсам (например, мобильные телефоны или встраиваемые системы), эффективность использования памяти становится критически важным фактором.
Пространственная сложность алгоритма — это математическая характеристика, выражающая зависимость объема памяти, требуемого алгоритмом для его выполнения, от размера входных данных *n*. Другими словами, она показывает, как будет расти потребление памяти при масштабировании задачи.
Важно понимать, что общая требуемая память складывается из двух частей
:
1. Входное пространство (Input Space): Память, необходимая для хранения самих входных данных. Обычно она не учитывается при оценке эффективности самого алгоритма, так как является заданной.
2. Вспомогательное пространство (Auxiliary Space): Память, которую алгоритм использует дополнительно для своей работы. Это временные переменные, динамические структуры данных (списки, словари), вызовы функций в стеке (при рекурсии) и т.д. Именно эта часть нас интересует в первую очередь при анализе.
Оценка пространственной сложности так же важна, как и временной, поскольку позволяет:
· Обеспечить выполнимость задачи: Убедиться, что алгоритму хватит доступной памяти (RAM) для обработки данных предельного размера.
· Сравнивать алгоритмы: Выбрать решение, которое не только быстрое, но и экономное, если ресурсы ограничены.
· Предсказывать узкие места: Понять, не приведет ли работа алгоритма к исчерпанию памяти (out-of-memory) при росте нагрузки.
Как и в случае со временем, объем требуемой памяти может зависеть от самих входных данных. Поэтому для пространственной сложности также рассматривают лучший, средний и худший случаи
Основные виды пространственной сложности (классификация)
Аналогично временной сложности, пространственная оценивается с помощью O-нотации, описывающей скорость роста дополнительной памяти.
1. Константная сложность — O(1). Алгоритм использует фиксированный объем дополнительной памяти, не зависящий от размера входных данных *n*. Это идеал с точки зрения экономии памяти.
o Пример: сложение двух чисел, поиск максимального элемента в массиве (требуется лишь пара переменных для хранения индекса и текущего максимума).
2. Логарифмическая сложность — O(log n). Дополнительная память растет очень медленно. Часто встречается в рекурсивных алгоритмах, где глубина рекурсии (и, соответственно, размер стека вызовов) пропорциональна log n.
o Пример: рекурсивный бинарный поиск (глубина стека вызовов равна log n).
3. Линейная сложность — O(n). Объем дополнительной памяти растет прямо пропорционально размеру входных данных. Это очень распространенный случай.
o Пример: создание копии массива, хранение результатов промежуточных вычислений для каждого элемента.
4. Квадратичная и более высокие степени — O(n²), O(n³), ... . Алгоритм требует создания структур данных, размер которых зависит от квадрата (или куба) входных данных.
o Пример: хранение матрицы смежности для графа с *n* вершинами требует O(n²) памяти. Некоторые алгоритмы динамического программирования могут использовать таблицы размером n*m.
5. Экспоненциальная сложность — O(2ⁿ), O(n!) . Потребление памяти растет катастрофически быстро. Такие алгоритмы на практике нереализуемы даже для небольших *n* из-за нехватки памяти.
Вот как это можно представить в сравнении с временной сложностью:
Пример 1: Сумма элементов
массива (O(1))
Алгоритм проходит по массиву и накапливает сумму в одной переменной sum. Размер входного массива может быть 10 или 10 миллионов,
но дополнительная память всегда будет состоять из одной переменной (плюс,
возможно, счетчик цикла). Это O(1).
text
Copy
Download
функция СуммаЭлементов(массив) сумма = 0 // O(1) — одна переменная для каждого элемента из массив сумма += элемент возврат сумма
Пример 2: Копирование
массива (O(n))
Для создания точной копии массива нам нужно выделить новый массив такого же
размера и переписать туда все элементы. Если исходный массив
занимает *n* единиц памяти, то новый массив займет
еще *n* единиц. Дополнительная память — O(n).
text
Copy
Download
функция КопироватьМассив(массив) новыйМассив = новый Массив(длина = длина(массив)) // O(n) — выделяем память под n элементов для i от 0 до длина(массив)-1 новыйМассив[i] = массив[i] возврат новыйМассив
Пример 3: Рекурсивный
расчет факториала (O(n))
Наивная рекурсивная реализация факториала требует памяти не только для
переменных, но и для хранения состояния каждого незавершенного вызова функции в
стеке вызовов.
text
Copy
Download
функция Факториал(n) если n <= 1 возврат 1 иначе возврат n * Факториал(n-1) // Перед умножением ждем результат Факториал(n-1)
Для n=5 стек вызовов будет выглядеть так: Факториал(5) -> Факториал(4) -> Факториал(3) -> Факториал(2) -> Факториал(1). Пока не выполнится самый глубокий вызов, все остальные
ждут своей очереди, каждый занимая место в стеке. Глубина стека (и,
следовательно, объем дополнительной памяти) равна *n*. Это
пространственная сложность O(n).
В реальной разработке время и память часто вступают в противоречие. Улучшение одного параметра может привести к ухудшению другого. Выбор оптимального соотношения называется пространственно-временным компромиссом (space-time tradeoff)
Суть подхода: если мы готовы использовать больше памяти, мы можем существенно ускорить работу алгоритма, и наоборот . Это фундаментальный принцип при проектировании эффективных систем.
Основные методы, использующие этот принцип:
· Динамическое программирование (Dynamic Programming): Классический пример компромисса. Вместо того чтобы многократно решать одни и те же подзадачи (что занимало бы экспоненциальное время), мы запоминаем (кэшируем) результаты их решения в таблице. Мы жертвуем памятью (пространственная сложность часто становится O(n) или O(n²)), но получаем колоссальный выигрыш во времени (часто сводя экспоненциальную сложность к полиномиальной)
· Мемоизация (Memoization): Частный случай динамического программирования для рекурсивных функций, где результаты вызовов сохраняются в кэше.
· Предварительные вычисления (Precomputation): Заранее вычисленные и сохраненные таблицы значений (например, таблицы синусов или заранее подготовленные индексы в базах данных) позволяют получать результат мгновенно за O(1), вместо того чтобы вычислять его каждый раз заново .
Пример компромисса: Рекурсивное вычисление чисел Фибоначчи.
Наивная рекурсия: Требует O(2ⁿ) времени, но O(n) памяти (стек вызовов). Время — катастрофически плохо.
Решение с мемоизацией: Требует O(n) времени и O(n) памяти. Мы ускорили алгоритм в колоссальное количество раз, но начали использовать дополнительную память для хранения результатов.
Итеративное решение: Требует O(n) времени и O(1) памяти. Это идеальный баланс, который удается достичь не всегда.
Выбор между скоростью и памятью всегда диктуется контекстом задачи:
· Если данные огромны, а память сервера ограничена, мы можем выбрать более медленный, но экономный алгоритм.
· Если нам нужна максимальная скорость отклика (например, в высоконагруженном сервисе), мы можем пойти на компромисс и загрузить все необходимые данные в оперативную память (in-memory cache).
Классы сложности алгоритмов
Класс сложности — это множество задач распознавания, для решения которых существуют алгоритмы, схожие по вычислительной сложности.
Два важных представителя:
Класс P
Класс P вмещает все те проблемы, решение которых считается «быстрым», то есть полиномиально зависящим от размера входа. Это практически решаемые задачи. Сюда относится сортировка, поиск во множестве, выяснение связности графов и многие другие.
Класс NP
Класс NP содержит задачи, которые недетерминированная машина Тьюринга в состоянии решить за полиномиальное количество времени. Следует заметить, что недерминированная машина Тьюринга является лишь абстрактной моделью, в то время как современные компьютеры соответствуют детерминированной машине Тьюринга с ограниченной памятью.
Включает задачи, для которых проверить предложенное решение можно быстро (за полиномиальное время). Классический пример — задача коммивояжёра: проверить, что маршрут короче 100 км, легко, а вот найти самый короткий — сложно.
Таким образом, класс NP включает в себя класс P, а также некоторые проблемы, для решения которых известны лишь алгоритмы, экспоненциально зависящие от размера входа (т.е. неэффективные для больших входов). В класс NP входят многие знаменитые проблемы, такие как задача коммивояжёра, задача выполнимости булевых формул, факторизация и др.
NP-полные задачи:
Это "самые сложные" задачи внутри NP. Если для любой NP-полной задачи
удастся найти быстрый алгоритм (доказать, что она лежит в P), то это будет
означать, что P = NP.
Примеры NP-полных задач:
· Задача о выполнимости булевых формул (SAT)
· Задача коммивояжёра (TSP)
· Задача о раскраске графа
· Задача о рюкзаке
· Игры в общем виде: Сапёр, Тетрис, поиск решения в «пятнашках» n×n
Проблема равенства классов P и
NP:
Это одна из главных нерешенных проблем тысячелетия (приз $1 млн). Вопрос в том,
можно ли любую задачу, решение которой легко проверить, так же легко и решить?
Большинство ученых считает, что P ≠ NP.
Задача коммивояжёра
Вы живёте в XX веке где-нибудь в США и зарабатываете тем, что ездите по городам и продаёте мультимиксеры. Чтобы сэкономить время и деньги, вам нужно придумать кратчайший маршрут, который позволит заехать в каждый город хотя бы один раз и вернуться обратно.
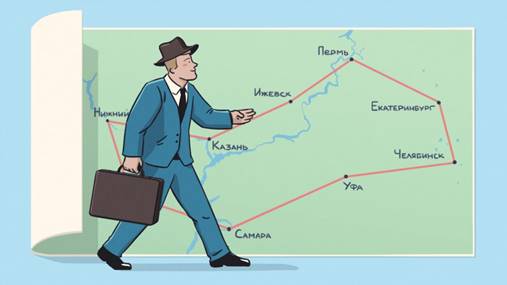
Это знаменитая задача коммивояжёра, для которой практически невозможно подобрать лучшее решение. Простой перебор здесь не поможет. Уже при 10 городах количество возможных маршрутов будет равно 3,6 млн, а при 26 — даже самым мощным компьютерам понадобится несколько миллиардов лет, чтобы перебрать все варианты.
Алгоритмически неразрешимые задачи
В отличие от сложных (NP) задач, которые разрешимы в принципе (алгоритм существует, просто он медленный), неразрешимые задачи — это задачи, для которых вообще невозможно создать алгоритм. Это доказанное свойство самой задачи.
В теории алгоритмов есть понятие «алгоритмически неразрешимой задачи», которое связано с оценкой сложности алгоритмов. Это понятие означает, что для некоторых классов задач в принципе не существует общего алгоритма решения
Алгоритмически неразрешимая задача в теории вычислимости — это задача, для которой принципиально не существует алгоритма, который бы, получив любой возможный в качестве входных данных объект, останавливался и давал правильный ответ после конечного числа шагов.
Важно: алгоритмическая неразрешимость не означает невозможность решения любой конкретной задачи из этого класса — часть из них может иметь свои решения. Но в целом данный класс задач не имеет ни общего универсального алгоритма решения, ни ветвящегося алгоритма полного разбиения класса на подклассы, к каждому из которых был бы применим свой специфический алгоритм
Рассмотрим примеры:
1. Проблема останова (Halting Problem)
«Можно ли написать программу, которая по коду другой программы и её входным данным определит, завершится ли она или будет работать бесконечно?»
Формулировка: Существует ли алгоритм H(P, x), который возвращает true, если программа P завершается на входе x, и false — если зацикливается?
Ответ: Нет, такой алгоритм невозможен.
Почему: Доказывается от противного (через диагональный аргумент Тьюринга). Если бы такая программа существовала, можно было бы построить парадоксальную программу, которая «делает наоборот» — и получается противоречие.
Java-аналог: Невозможно написать метод:
boolean willHalt(Runnable program, Object input) { ... }
который всегда правильно определял бы, завершится ли program.run().
2. Проблема эквивалентности программ
«Можно ли определить, делают ли две программы одно и то же?»
Например: «Эквивалентны ли два метода на Java при любых входных данных?»
Неразрешима, потому что если бы мы могли это проверять, то могли бы свести к этому проблему останова.
3. Проблема достижимости состояния (State Reachability)
«Достигнет ли программа определённого состояния (например, строки кода) при некотором входе?»
Пример: «Будет ли когда-нибудь вызван метод deleteAllData() в этой программе?» Эта задача неразрешима в общем случае.
4. Проблема полноты спецификации
«Покрывает ли набор тестов всё возможное поведение программы?»
Невозможно автоматически проверить, исчерпывающе ли протестирована программа.
5. Проблема вывода типов в общем виде
В некоторых очень выразительных системах типов (например, с зависимыми типами) задача вывода типов становится неразрешимой.
6. Проблема соответствия Поста (Post Correspondence Problem, PCP)
Дано конечное множество пар строк. Можно ли составить последовательность таких пар, чтобы конкатенация первых элементов равнялась конкатенации вторых?
Хотя формулировка кажется простой, задача неразрешима.
Часто используется для доказательства неразрешимости других задач.
7. Проблема разрешимости в логике первого порядка
«Истинна ли данная формула логики первого порядка во всех интерпретациях?»
Эта задача (общая проблема разрешимости — Entscheidungsproblem) была доказана неразрешимой Аланом Тьюрингом и Алонзо Чёрчем.
1. Рекурсивный факториал — O(n)
public class Factorial {
public static long factorial(int n) {
if (n <= 1) {
return 1;
}
return n * factorial(n - 1);
}
public static void main(String[] args) {
System.out.println(factorial(5)); // 120
}
}
– Каждый вызов factorial(n) делает ровно один рекурсивный вызов с n - 1.
– Глубина рекурсии: n уровней.
– На каждом уровне выполняется O(1) операций.
– Пространственная сложность (из-за стека вызовов): O(n)
public class Fibonacci {
public static long fib(int n) {
if (n <= 1) {
return n;
}
return fib(n - 1) + fib(n - 2);
}
public static void main(String[] args) {
System.out.println(fib(10)); // 55
}
}
– Каждый вызов fib(n) порождает два рекурсивных вызова: fib(n-1) и fib(n-2).
– Дерево вызовов растёт экспоненциально.
– Многие подзадачи вычисляются многократно (например, fib(3) вызывается десятки раз при n = 10).
– Количество вызовов ≈ 2ⁿ (на практике чуть меньше, но асимптотически — экспонента).
– Точная оценка: Θ(φⁿ), где φ = (1 + √5)/2 — золотое сечение.
– Пространственная сложность: O(n) — глубина рекурсии (максимальная длина ветви дерева).
Именно поэтому наивный рекурсивный Фибоначчи не используется на практике
— даже для n = 50 он работает очень медленно.
Пример №3:
// O(1)
int getFirst(int[] arr) { return arr[0]; }
// O(n)
boolean contains(int[] arr, int x) {
for (int v : arr) if (v == x) return true; return false;
}
// O(nZ)
void printPairs(int[] arr) {
for (int i = 0; i < arr.length; i++) for (int j = 0; j < arr.length; j++)
System.out.println(arr[i] + ", " + arr[j]);
}
// O(log n) — бинарный поиск
int binarySearch(int[] arr, int x) { ... }
public int getLastElement(int[] arr) {
return arr[arr.length - 1];
}
public boolean contains(int[] arr, int target) {
for (int i = 0; i < arr.length; i++) {
if (arr[i] == target) {
return true;
}
}
return false;
}
public void printAllPairs(int[] arr) {
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr.length; j++) {
System.out.println(arr[i] + ", " + arr[j]);
}
}
}
public int binarySearch(int[] arr, int target) {
int left = 0, right = arr.length - 1;
while (left <= right) {
int mid = left + (right - left) / 2;
if (arr[mid] == target) {
return mid;
} else if (arr[mid] < target) {
left = mid + 1;
} else {
right = mid - 1;
}
}
return -1;
}
Пояснение: Внутренний цикл запускается n, n-1, n-2, ..., 1 раз → сумма ≈ n(n+1)/2 →
public void printUpperTriangle(int[][] matrix) {
for (int i = 0; i < matrix.length; i++) {
for (int j = i; j < matrix[i].length; j++) {
System.out.print(matrix[i][j] + " ");
}
}
}
public int countDivisions(int n) {
int count = 0;
while (n > 1) { n /= 2; count++;
}
return count;
} Пояснение: На каждом шаге число уменьшается вдвое → количество итераций ≈
log₂ (n).
public int fib(int n) {
if (n <= 1) return n;
return fib(n - 1) + fib(n - 2);
}
Пояснение: Каждый вызов порождает два новых → дерево вызовов растёт экспоненциально → O(2ⁿ).
public void printAllTriples(int[] arr) {
for (int i = 0; i < arr.length; i++) {
for (int j = 0; j < arr.length; j++) {
for (int k = 0; k < arr.length; k++) {
System.out.println(arr[i] + ", " + arr[j] + ", " + arr[k]);
}
}
}
}
Три вложенных цикла по одному массиву → n × n × n = n3 операций.
Часто встречается в задачах перебора троек (например, в наивном решении задачи 3SUM).
public boolean isPrime(int n) {
if (n < 2) return false;
for (int i = 2; i * i <= n; i++) {
if (n % i == 0) return false;
}
return true;
}
Пояснение: Цикл выполняется до √n, потому что делители числа симметричны относительно корня. Отличный пример, показывающий, что не все алгоритмы укладываются в стандартные O(1), O(log n), O(n) и т.д.
public int countVowels(String s) {
int count = 0;
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (c == 'a' || c == 'e' || c == 'i' || c == 'o' || c == 'u') {
count++;
}
}
return count;
}
Пояснение: Проход по каждому символу строки → O(k), где k = s.length(). Важно подчеркнуть: размер входа — это длина строки, а не какое-то другое число. Можно обозначить как O(n), если договориться, что n — длина строки. Но полезно явно обсудить, от чего зависит сложность.
public boolean hasCommonElement(int[] arr1, int[] arr2) { java.util.Set<Integer> set = new java.util.HashSet<>(); for (int x : arr1) {
set.add(x); // O(n)
}
for (int x : arr2) {
if (set.contains(x)) return true; // O(1) на проверку
}
return false; // O(m)
}
Пояснение: Сначала строим хеш-таблицу за O(n), затем проверяем каждый элемент второго массива за O(m). Итого — O(n + m). Контраст с наивным решением O(n·m) — хороший повод для обсуждения оптимизации.
Скачано с www.znanio.ru

















![Пример 4 — O (1) ( константное время ) public int getLastElement ( int [] arr ) { return arr [ arr](https://fs.znanio.ru/d5af0e/96/a4/a305e869da2533e145210ceef2ef9dc985.jpg)


Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.