Поделиться

Практическая работа №2
Тема: Сценарии
Теоретические сведения
В Deductor Studio для аналитика основополагающим понятием является сценарий. Сценарий представляет собой последовательность операций с данными, представленную в виде иерархического дерева. В дереве каждая операция образует узел, заголовок которого содержит: имя источника данных, наименование применяемого метода обработки, используемые при этом поля и т.д. Кроме этого, слева от наименования узла стоит значок, соответствующий типу операции.
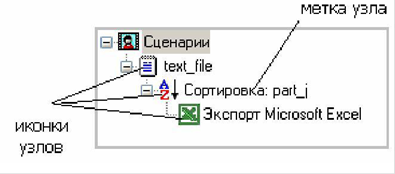
Если узел имеет подчиненные узлы, то слева от его названия будет расположен значок «+», щелчок по которому позволит развернуть узел, т.е. сделать видимыми все его подчиненные узлы, при этом значок «+» поменяется на «–». Щелчок по значку «–», наоборот, сворачивает все подчиненные узлы.
С помощью клавиш Ctrl+^ и Ctrl+v можно перемещать узлы по дереву вверх-вниз в пределах подчинения родительскому узлу.
Сценарий состоит из ветвей. Deductor не имеет собственных средств для ввода данных, поэтому сценарий всегда начинается с узла импорта из какого-либо источника. Любой вновь создаваемый узел импорта будет находиться на верхнем уровне (подчиненном главному узлу «Сценарии»).
Создание нового узла импорта осуществляется с помощью мастера импорта. Вызвать мастер можно следующими способами:
-
кнопка
на панели инструментов закладки Сценарии ![]() ;
;
- клавиша F6;
- контекстное меню Мастер импорта...
При вызове мастера импорта откроется окно первого шага мастера.
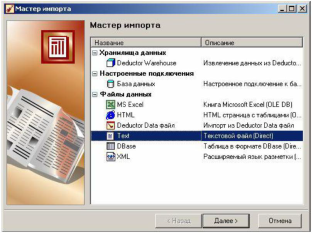
В нем все источники данных сгруппированы по следующим четырем категориям:
- хранилища данных;
- настроенные подключения;
- файлы данных;
- бизнес-подключения.
Некоторые категории могут отсутствовать в списке. Причинами этого может быть следующее:
Версия Deductor. Например, категории Настроенные подключения и Бизнес-подключения отсутствуют в версии Academic. В дереве подключений (вкладка Подключения) не зарегистрировано ни одного объекта из данной категории. Например, если не настроено ни одного подключения к хранилищу данных, то категория Хранилища данных будет отсутствовать. Отключена «видимость» объекта или категории объекта.
Дальнейшие шаги мастера импорта будут зависеть от того, какой объект дерева категорий был выбран аналитиком.
К любому узлу импорта можно добавить узел обработки или узел экспорта, предварительно выделив узел импорта мышью. Новый узел будет добавлен как подчиненный к узлу импорта.
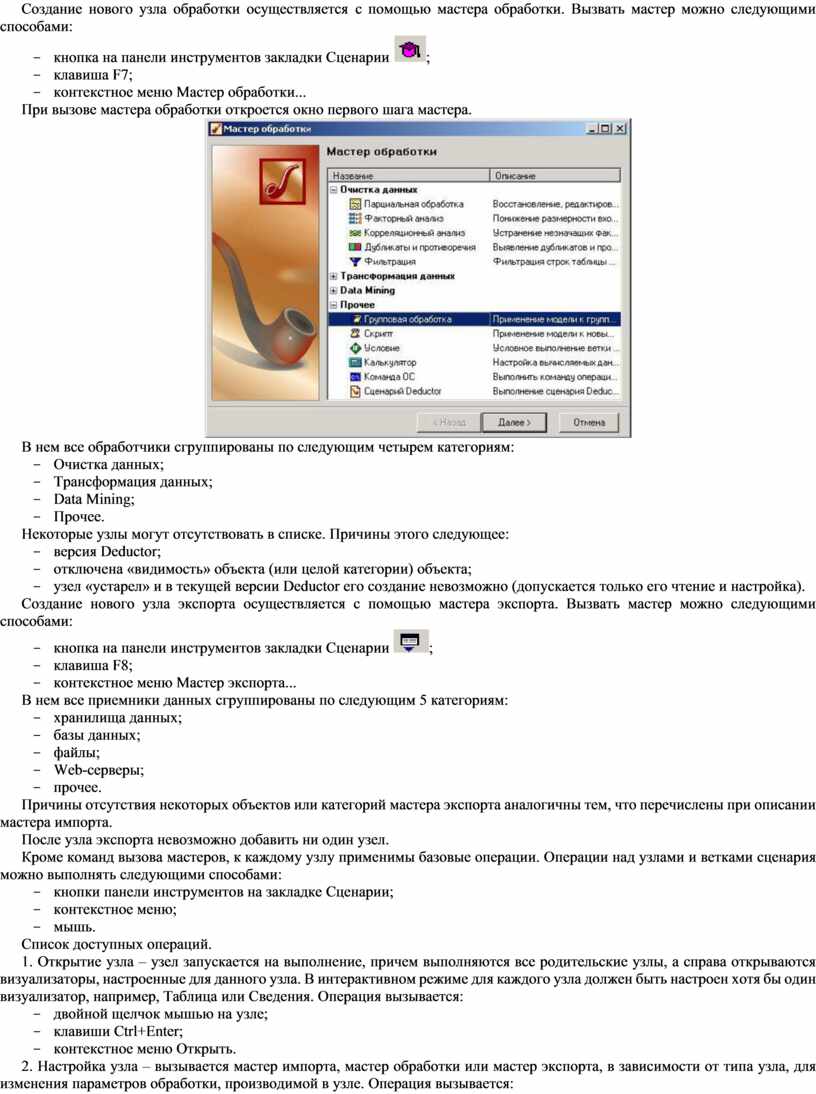
Создание нового узла обработки осуществляется с помощью мастера обработки. Вызвать мастер можно следующими способами:
-
кнопка
на панели инструментов закладки Сценарии ![]() ;
;
- клавиша F7;
- контекстное меню Мастер обработки...
При вызове мастера обработки откроется окно первого шага мастера.
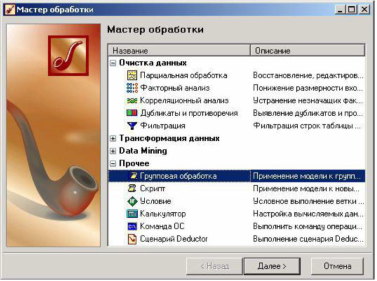
В нем все обработчики сгруппированы по следующим четырем категориям:
- Очистка данных;
- Трансформация данных;
- Data Mining;
- Прочее.
Некоторые узлы могут отсутствовать в списке. Причины этого следующее:
- версия Deductor;
- отключена «видимость» объекта (или целой категории) объекта;
- узел «устарел» и в текущей версии Deductor его создание невозможно (допускается только его чтение и настройка).
Создание нового узла экспорта осуществляется с помощью мастера экспорта. Вызвать мастер можно следующими способами:
-
кнопка
на панели инструментов закладки Сценарии ![]() ;
;
- клавиша F8;
- контекстное меню Мастер экспорта...
В нем все приемники данных сгруппированы по следующим 5 категориям:
- хранилища данных;
- базы данных;
- файлы;
- Web-серверы;
- прочее.
Причины отсутствия некоторых объектов или категорий мастера экспорта аналогичны тем, что перечислены при описании мастера импорта.
После узла экспорта невозможно добавить ни один узел.
Кроме команд вызова мастеров, к каждому узлу применимы базовые операции. Операции над узлами и ветками сценария можно выполнять следующими способами:
- кнопки панели инструментов на закладке Сценарии;
- контекстное меню;
- мышь.
Список доступных операций.
1. Открытие узла – узел запускается на выполнение, причем выполняются все родительские узлы, а справа открываются визуализаторы, настроенные для данного узла. В интерактивном режиме для каждого узла должен быть настроен хотя бы один визуализатор, например, Таблица или Сведения. Операция вызывается:
- двойной щелчок мышью на узле;
- клавиши Ctrl+Enter;
- контекстное меню Открыть.
2. Настройка узла – вызывается мастер импорта, мастер обработки или мастер экспорта, в зависимости от типа узла, для изменения параметров обработки, производимой в узле. Операция вызывается:
-
кнопка
![]() ;
;
- клавиши Alt+Enter;
- контекстное меню Настроить….
3. Активация/деактивация узла – узел может быть либо активным, либо неактивным. Если узел неактивный, то, сделав его активным, выполнится сценарий для этого узла, но визуализаторы отображены не будут. Делая узел неактивным, закрываются все визуализаторы для него и для всех подчиненных узлов, а сам узел и подчиненные узлы превращаются в неактивные. Эта операция может быть использована для освобождения памяти. Операция активации/деактивации вызывается:
- клавиши Shift+Enter;
- контекстное меню Активный…
4. Перечитать данные узла – все узлы до корневого включительно будут закрыты, а затем выполнена ветка сценария от корневого до текущего узла. Операция вызывается: контекстное меню Перечитать данные…
5. Вырезать узел – удаляет текущий узел из сценария обработки. Все его потомки при этом перемещаются на один уровень вверх и начинают подчиняться родителю удаленного узла. Операция вызывается:
-
кнопка
![]() ;
;
- контекстное меню Вырезать узел.
6. Вставить узел – вставляет перед текущим узлом сценария новый узел и вызывает для него мастер обработки. Вставить узел перед узлом импорта данных нельзя. Операция вызывается:
-
кнопка
![]() ;
;
- контекстное меню Вставить узел.
После вставки нового узла или удаления существующего узлы-потомки могут стать неработоспособными, в зависимости от обработки, выполняемой новым узлом.
7. Копировать ветвь – копирует ветвь сценария, начиная с текущего узла и включая все его потомки. Операция вызывается:
-
кнопка
![]() ;
;
- контекстное меню Копировать ветвь;
- при помощи механизма drag & drop – выделив узел и удерживая нажатой клавишу Ctrl, указать курсором мыши на новый узел, ко-торый должен стать родителем старого. При этом переносимая ветка целиком скопируется в новое место.
8. Удалить ветвь – удаляет узел сценария и все его подузлы. Удаленная ветвь восстановлению не подлежит, поэтому к данной операции необходимо подходить с осторожностью. Операция вызывается:
-
кнопка
![]() ;
;
- клавиши Ctrl+Del;
- контекстное меню Удалить ветвь.
9. Перенос ветви – переносит ветку сценария к новому узлу. Операция производится аналогично копированию ветви с помощью drag & drop без удерживания клавиши Ctrl.
Переименовать – позволяет изменить метку текущего узла. Операция вызывается:
- клавиша F2;
- контекстное меню Переименовать...
10. Сведения – открывает диалоговое окно Сведения для текущего узла. В нем редактируется имя, метка и описание к узлу. Операция вызывается:
- контекстное меню Сведения ...;
-
открыв
скрытую панель узла с помощью кнопки ![]() и нажать там одну из кнопок: Имя, Метка
или Описание.
и нажать там одну из кнопок: Имя, Метка
или Описание.
Имя узла может быть задано только латинскими символами, тогда как метка – любыми. Кроме того, имя узла должно быть уникально в пределах одного сценария. Как правило, необходимости в переименовании имен узлов не возникает.
11. Статус пакетной обработки – устанавливает статус пакетной обработки для узла.
12. Добавить в Избранное – текущий узел добавляется в список избранных узлов.
13. Сохранение ветви – вызывается стандартный диалог Сохранение, в котором можно указать путь и имя файла для сохранения ветви сценария, начинающейся с текущего узла. Операция вызывается: контекстное меню Сохранить ветвь.
14. Загрузка ветви – вызывает стандартный диалог Открытие файла, в котором можно указать путь и имя файла, хранящего ветвь сценария.
Загруженная ветвь сценария станет потомком текущего узла. Ветвь, начинающаяся с узла импорта данных, будет добавлена в проект как новая корневая ветвь. Операция вызывается: контекстное меню Загрузить ветвь. По умолчанию ветвь сценария имеет расширение *.deb.
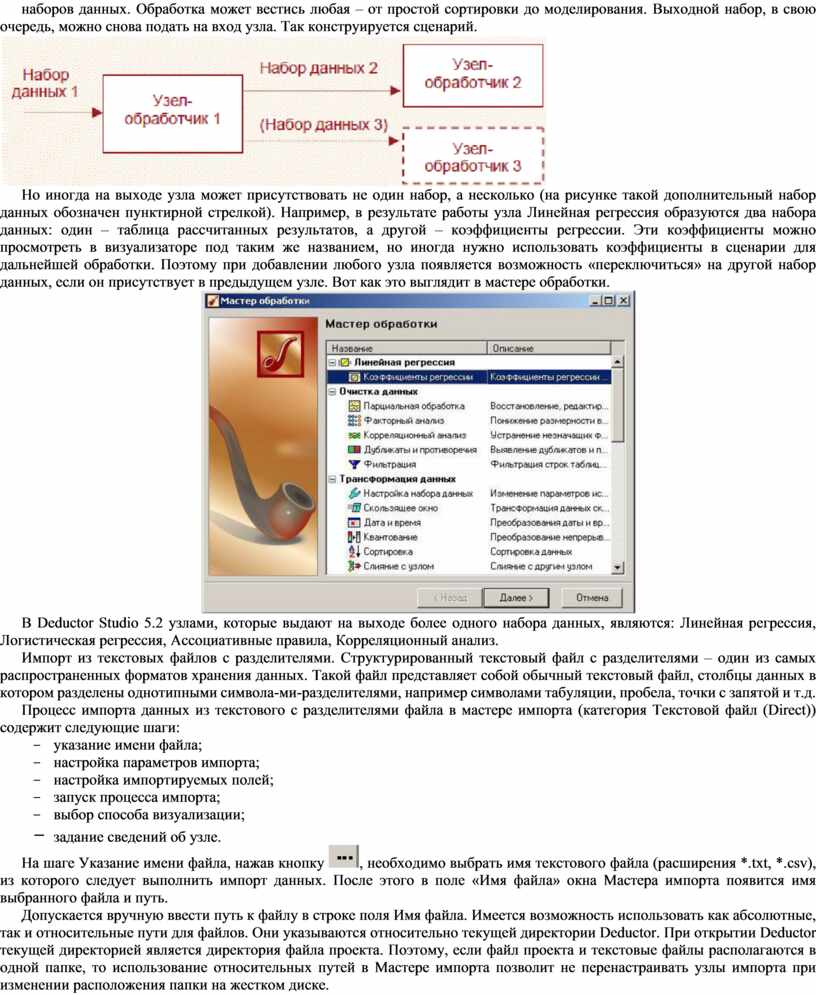
В Deductor взаимодействие узлов друг с другом спроектировано на уровне программного ядра, поэтому принцип взаимодействия един и не зависит от типа узла. Каждый узел можно представить «черным ящиком», на вход которого подается структурированный набор данных с полями, а на выходе доступен один или несколько обработанных узлом наборов данных. Обработка может вестись любая – от простой сортировки до моделирования. Выходной набор, в свою очередь, можно снова подать на вход узла. Так конструируется сценарий.

Но иногда на выходе узла может присутствовать не один набор, а несколько (на рисунке такой дополнительный набор данных обозначен пунктирной стрелкой). Например, в результате работы узла Линейная регрессия образуются два набора данных: один – таблица рассчитанных результатов, а другой – коэффициенты регрессии. Эти коэффициенты можно просмотреть в визуализаторе под таким же названием, но иногда нужно использовать коэффициенты в сценарии для дальнейшей обработки. Поэтому при добавлении любого узла появляется возможность «переключиться» на другой набор данных, если он присутствует в предыдущем узле. Вот как это выглядит в мастере обработки.
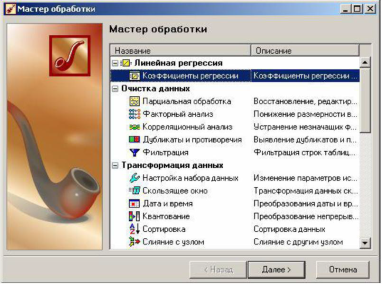
В Deductor Studio 5.2 узлами, которые выдают на выходе более одного набора данных, являются: Линейная регрессия, Логистическая регрессия, Ассоциативные правила, Корреляционный анализ.
Импорт из текстовых файлов с разделителями. Структурированный текстовый файл с разделителями – один из самых распространенных форматов хранения данных. Такой файл представляет собой обычный текстовый файл, столбцы данных в котором разделены однотипными символа-ми-разделителями, например символами табуляции, пробела, точки с запятой и т.д.
Процесс импорта данных из текстового с разделителями файла в мастере импорта (категория Текстовой файл (Direct)) содержит следующие шаги:
- указание имени файла;
- настройка параметров импорта;
- настройка импортируемых полей;
- запуск процесса импорта;
- выбор способа визуализации;
- задание сведений об узле.
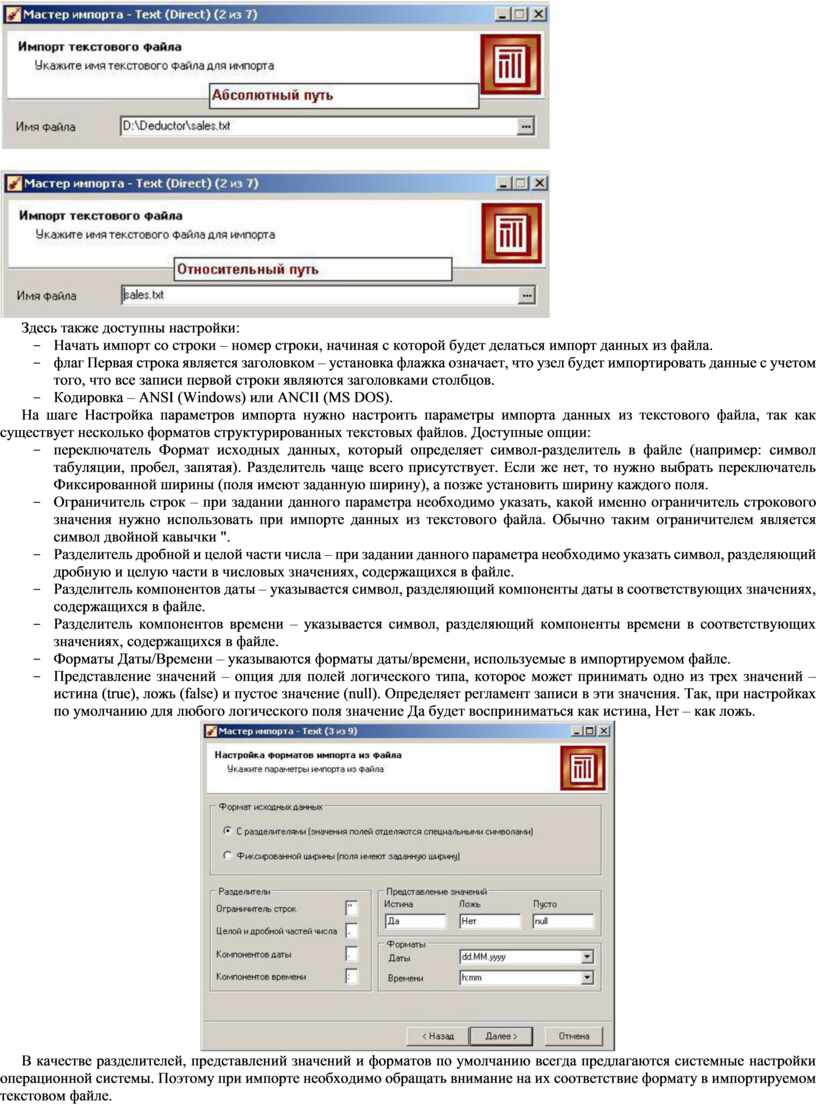
На
шаге Указание имени файла, нажав кнопку ![]() , необходимо выбрать имя текстового файла
(расширения *.txt, *.csv), из которого следует выполнить импорт данных. После
этого в поле «Имя файла» окна Мастера импорта появится имя выбранного файла и
путь.
, необходимо выбрать имя текстового файла
(расширения *.txt, *.csv), из которого следует выполнить импорт данных. После
этого в поле «Имя файла» окна Мастера импорта появится имя выбранного файла и
путь.
Допускается вручную ввести путь к файлу в строке поля Имя файла. Имеется возможность использовать как абсолютные, так и относительные пути для файлов. Они указываются относительно текущей директории Deductor. При открытии Deductor текущей директорией является директория файла проекта. Поэтому, если файл проекта и текстовые файлы располагаются в одной папке, то использование относительных путей в Мастере импорта позволит не перенастраивать узлы импорта при изменении расположения папки на жестком диске.
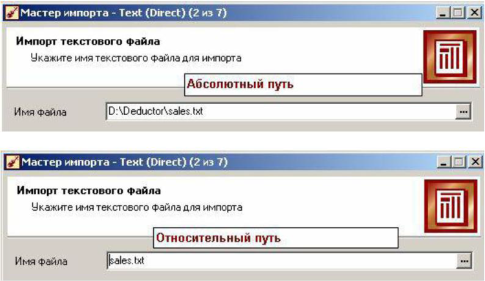
Здесь также доступны настройки:
- Начать импорт со строки – номер строки, начиная с которой будет делаться импорт данных из файла.
- флаг Первая строка является заголовком – установка флажка означает, что узел будет импортировать данные с учетом того, что все записи первой строки являются заголовками столбцов.
- Кодировка – ANSI (Windows) или ANCII (MS DOS).
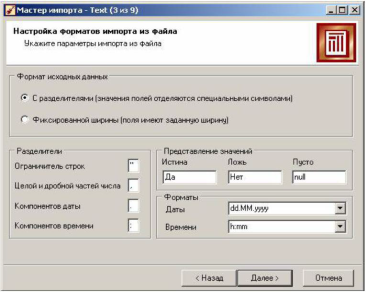
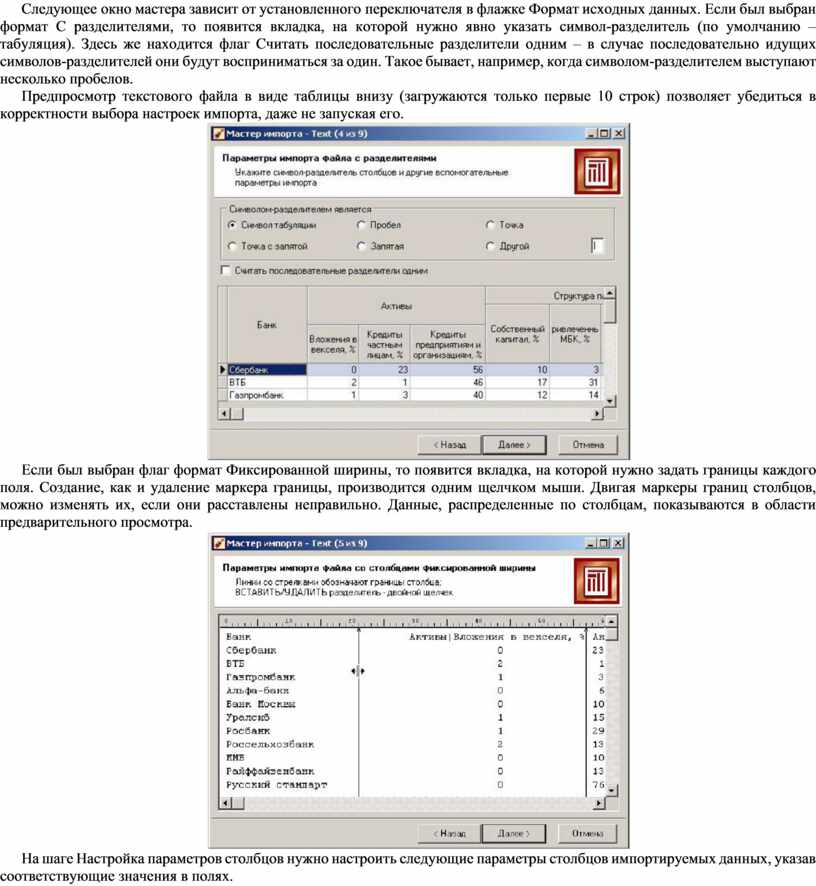
На шаге Настройка параметров импорта нужно настроить параметры импорта данных из текстового файла, так как существует несколько форматов структурированных текстовых файлов. Доступные опции:
- переключатель Формат исходных данных, который определяет символ-разделитель в файле (например: символ табуляции, пробел, запятая). Разделитель чаще всего присутствует. Если же нет, то нужно выбрать переключатель Фиксированной ширины (поля имеют заданную ширину), а позже установить ширину каждого поля.
- Ограничитель строк – при задании данного параметра необходимо указать, какой именно ограничитель строкового значения нужно использовать при импорте данных из текстового файла. Обычно таким ограничителем является символ двойной кавычки ".
- Разделитель дробной и целой части числа – при задании данного параметра необходимо указать символ, разделяющий дробную и целую части в числовых значениях, содержащихся в файле.
- Разделитель компонентов даты – указывается символ, разделяющий компоненты даты в соответствующих значениях, содержащихся в файле.
- Разделитель компонентов времени – указывается символ, разделяющий компоненты времени в соответствующих значениях, содержащихся в файле.
- Форматы Даты/Времени – указываются форматы даты/времени, используемые в импортируемом файле.
- Представление значений – опция для полей логического типа, которое может принимать одно из трех значений – истина (true), ложь (false) и пустое значение (null). Определяет регламент записи в эти значения. Так, при настройках по умолчанию для любого логического поля значение Да будет восприниматься как истина, Нет – как ложь.
В качестве разделителей, представлений значений и форматов по умолчанию всегда предлагаются системные настройки операционной системы. Поэтому при импорте необходимо обращать внимание на их соответствие формату в импортируемом текстовом файле.
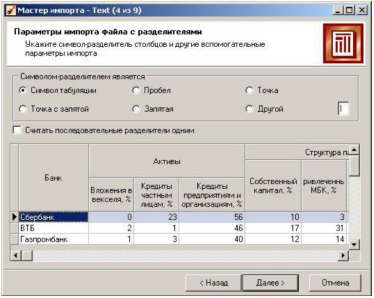
Следующее окно мастера зависит от установленного переключателя в флажке Формат исходных данных. Если был выбран формат С разделителями, то появится вкладка, на которой нужно явно указать символ-разделитель (по умолчанию – табуляция). Здесь же находится флаг Считать последовательные разделители одним – в случае последовательно идущих символов-разделителей они будут восприниматься за один. Такое бывает, например, когда символом-разделителем выступают несколько пробелов.
Предпросмотр текстового файла в виде таблицы внизу (загружаются только первые 10 строк) позволяет убедиться в корректности выбора настроек импорта, даже не запуская его.
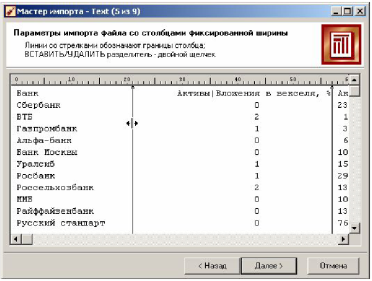
Если был выбран флаг формат Фиксированной ширины, то появится вкладка, на которой нужно задать границы каждого поля. Создание, как и удаление маркера границы, производится одним щелчком мыши. Двигая маркеры границ столбцов, можно изменять их, если они расставлены неправильно. Данные, распределенные по столбцам, показываются в области предварительного просмотра.
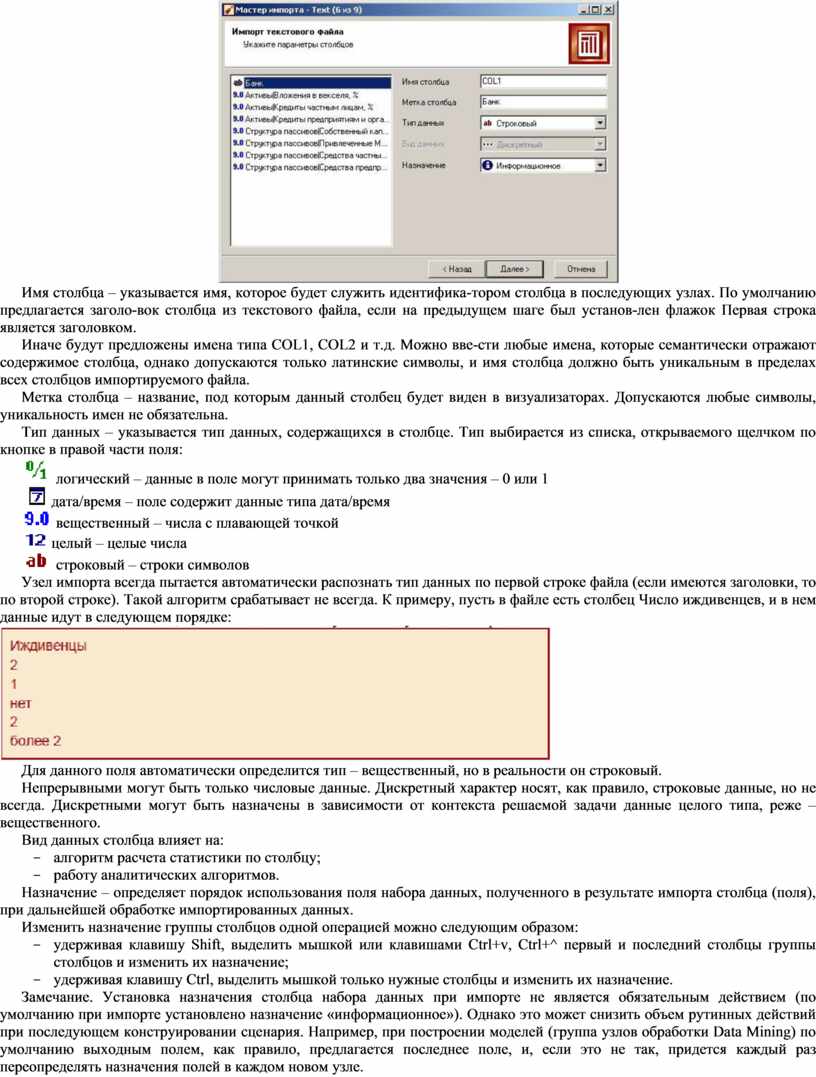
На шаге Настройка параметров столбцов нужно настроить следующие параметры столбцов импортируемых данных, указав соответствующие значения в полях.
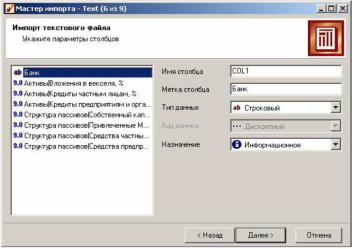
Имя столбца – указывается имя, которое будет служить идентифика-тором столбца в последующих узлах. По умолчанию предлагается заголо-вок столбца из текстового файла, если на предыдущем шаге был установ-лен флажок Первая строка является заголовком.
Иначе будут предложены имена типа COL1, COL2 и т.д. Можно вве-сти любые имена, которые семантически отражают содержимое столбца, однако допускаются только латинские символы, и имя столбца должно быть уникальным в пределах всех столбцов импортируемого файла.
Метка столбца – название, под которым данный столбец будет виден в визуализаторах. Допускаются любые символы, уникальность имен не обязательна.
Тип данных – указывается тип данных, содержащихся в столбце. Тип выбирается из списка, открываемого щелчком по кнопке в правой части поля:
![]() логический – данные в
поле могут принимать только два значения – 0 или 1
логический – данные в
поле могут принимать только два значения – 0 или 1
![]() дата/время –
поле содержит данные типа дата/время
дата/время –
поле содержит данные типа дата/время
![]() вещественный –
числа с плавающей точкой
вещественный –
числа с плавающей точкой
![]() целый – целые
числа
целый – целые
числа
![]() строковый –
строки символов
строковый –
строки символов
Узел импорта всегда пытается автоматически распознать тип данных по первой строке файла (если имеются заголовки, то по второй строке). Такой алгоритм срабатывает не всегда. К примеру, пусть в файле есть столбец Число иждивенцев, и в нем данные идут в следующем порядке:

Для данного поля автоматически определится тип – вещественный, но в реальности он строковый.
Непрерывными могут быть только числовые данные. Дискретный характер носят, как правило, строковые данные, но не всегда. Дискретными могут быть назначены в зависимости от контекста решаемой задачи данные целого типа, реже – вещественного.
Вид данных столбца влияет на:
- алгоритм расчета статистики по столбцу;
- работу аналитических алгоритмов.
Назначение – определяет порядок использования поля набора данных, полученного в результате импорта столбца (поля), при дальнейшей обработке импортированных данных.
Изменить назначение группы столбцов одной операцией можно следующим образом:
- удерживая клавишу Shift, выделить мышкой или клавишами Ctrl+v, Ctrl+^ первый и последний столбцы группы столбцов и изменить их назначение;
- удерживая клавишу Ctrl, выделить мышкой только нужные столбцы и изменить их назначение.
Замечание. Установка назначения столбца набора данных при импорте не является обязательным действием (по умолчанию при импорте установлено назначение «информационное»). Однако это может снизить объем рутинных действий при последующем конструировании сценария. Например, при построении моделей (группа узлов обработки Data Mining) по умолчанию выходным полем, как правило, предлагается последнее поле, и, если это не так, придется каждый раз переопределять назначения полей в каждом новом узле.
На шаге Запуск процесса импорта стартует сам процесс импорта данных с ранее настроенными параметрами. Ход процесса импорта отображается с помощью индикатора. Если процесс импорта остановился, это сигнализирует о возможных ошибок при чтении данных. В этом случае появляется окно с сообщением об ошибке.
В случае возникновения ошибок несоответствия типов процесс импорта будет продолжен, но после его окончания будет отображен журнал регистрации ошибок с информацией о месте и причине их появления:
************************************************************
Deductor Studio Enterprise 5.2.0.50
************************************************************
22.11.2012 11:22:33 TBGTextFile: При разборе строки 2 возникла
ошибка: В колонке "Группа.Код" значение "33" не удалось преобразовать к
дате/времени.
22.11.2012 11:22:33 TBGTextFile: При разборе строки 3 возникла
ошибка: В колонке "Группа.Код" значение "48" не удалось преобразовать к
дате/времени.
22.11.2012 11:22:33 TBGTextFile: При разборе строки 4 возникла
ошибка: В колонке "Группа.Код" значение "50" не удалось преобразовать к
дате/времени.
22.11.2012 11:22:33 TBGTextFile: При разборе строки 5 возникла
ошибка: В колонке "Группа.Код" значение "108" не удалось преобразовать к
дате/времени.
Для управления процессом импорта предусмотрены следующие кнопки:
- Пуск – запускает процесс в первый раз или возобновляет после паузы.
- Пауза – временно приостанавливает импорт.
- Стоп – останавливает процесс без возможности его продолжения.
На оставшихся двух шагах мастера импорта будет предложено выбрать визуализатор набора данных (по умолчанию предлагается Таблица) и задать сведения об узле.
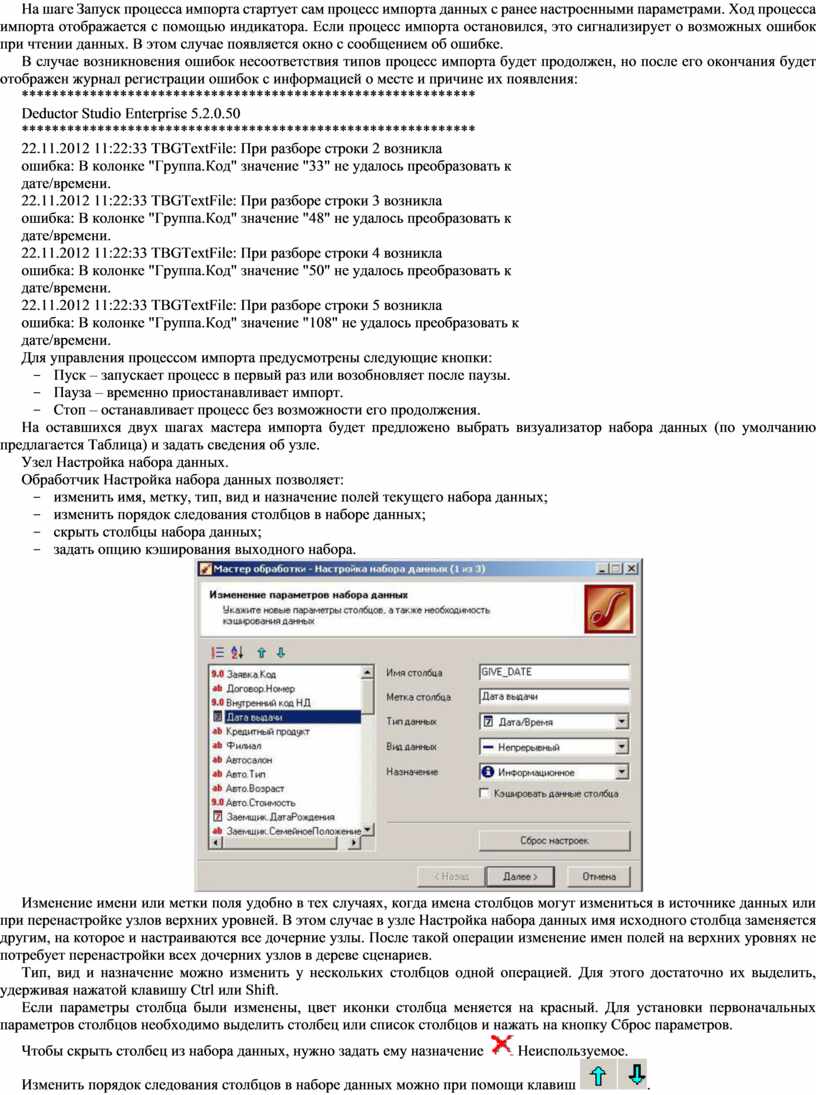
Узел Настройка набора данных.
Обработчик Настройка набора данных позволяет:
- изменить имя, метку, тип, вид и назначение полей текущего набора данных;
- изменить порядок следования столбцов в наборе данных;
- скрыть столбцы набора данных;
- задать опцию кэширования выходного набора.

Изменение имени или метки поля удобно в тех случаях, когда имена столбцов могут измениться в источнике данных или при перенастройке узлов верхних уровней. В этом случае в узле Настройка набора данных имя исходного столбца заменяется другим, на которое и настраиваются все дочерние узлы. После такой операции изменение имен полей на верхних уровнях не потребует перенастройки всех дочерних узлов в дереве сценариев.
Тип, вид и назначение можно изменить у нескольких столбцов одной операцией. Для этого достаточно их выделить, удерживая нажатой клавишу Ctrl или Shift.
Если параметры столбца были изменены, цвет иконки столбца меняется на красный. Для установки первоначальных параметров столбцов необходимо выделить столбец или список столбцов и нажать на кнопку Сброс параметров.
Чтобы
скрыть столбец из набора данных, нужно задать ему назначение ![]() Неиспользуемое.
Неиспользуемое.
Изменить
порядок следования столбцов в наборе данных можно при помощи клавиш ![]() .
.
Кэширование – это загрузка часто используемой информации в оперативную память для быстрого доступа к ней, минуя многократные считывания с жесткого диска. Кэширование может заметно повысить скорость работы сценария в ряде случаев (использование кэширования не входит в базовые навыки работы с Deductor).
Экспорт в текстовый файл. Выполняется при помощи мастера экспорта. В нем процесс экспорта данных в текстовый файл с разделителями (категория Файлы) содержит следующие шаги:
- настройка форматов экспорта;
- указание символа-разделителя столбцов;
- выбор экспортируемых полей;
- запуск процесса экспорта;
- выбор способа визуализации;
- задание сведений об узле.
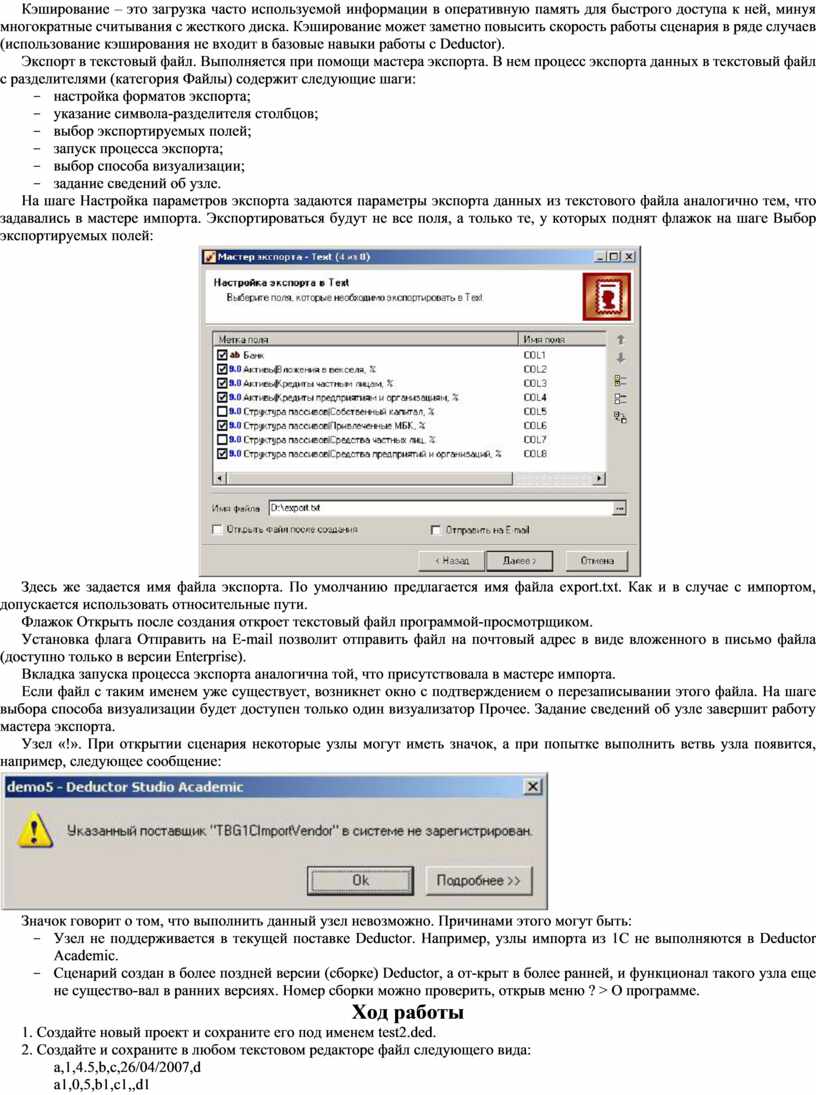
На шаге Настройка параметров экспорта задаются параметры экспорта данных из текстового файла аналогично тем, что задавались в мастере импорта. Экспортироваться будут не все поля, а только те, у которых поднят флажок на шаге Выбор экспортируемых полей:
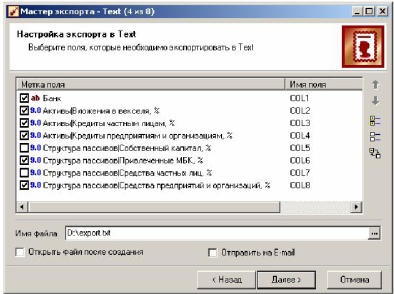
Здесь же задается имя файла экспорта. По умолчанию предлагается имя файла export.txt. Как и в случае с импортом, допускается использовать относительные пути.
Флажок Открыть после создания откроет текстовый файл программой-просмотрщиком.
Установка флага Отправить на E-mail позволит отправить файл на почтовый адрес в виде вложенного в письмо файла (доступно только в версии Enterprise).
Вкладка запуска процесса экспорта аналогична той, что присутствовала в мастере импорта.
Если файл с таким именем уже существует, возникнет окно с подтверждением о перезаписывании этого файла. На шаге выбора способа визуализации будет доступен только один визуализатор Прочее. Задание сведений об узле завершит работу мастера экспорта.
Узел «!». При открытии сценария некоторые узлы могут иметь значок, а при попытке выполнить ветвь узла появится, например, следующее сообщение:
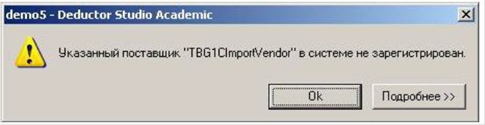
Значок говорит о том, что выполнить данный узел невозможно. Причинами этого могут быть:
- Узел не поддерживается в текущей поставке Deductor. Например, узлы импорта из 1С не выполняются в Deductor Academic.
- Сценарий создан в более поздней версии (сборке) Deductor, а от-крыт в более ранней, и функционал такого узла еще не существо-вал в ранних версиях. Номер сборки можно проверить, открыв меню ? > О программе.
Ход работы
1. Создайте новый проект и сохраните его под именем test2.ded.
2. Создайте и сохраните в любом текстовом редакторе файл следующего вида:
a,1,4.5,b,c,26/04/2007,d
a1,0,5,b1,c1,,d1
3. Импортируйте его в Deductor, корректно настроив параметры импорта. Используйте относительный путь для файла. Метку узла переименуйте в Пример импорта файла. В комментарии к узлу впишите: Текстовый файл с разделителями-запятыми.
4. Добавьте к узлу узел Настройка набора данных и задайте следующие метки к столбцам:
Поле1, Поле2, Поле3 и т.д.
5. Экспортируйте набор данных в текстовый файл с настройками, предлагаемыми по умолчанию.
6. Импортируйте только что экспортированный файл в Deductor.
7. Присоедините к новому узлу импорта (путем копирования) предыдущую ветвь, начиная с узла Настройка набора данных.
8. Между экспортом и настройкой набора данных вставьте еще один узел настройки, в котором измените тип столбца Поле2 на логический.
9. Удалите только что вставленный узел.
10. Сохраните проект.


Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.
