Поделиться

ЛЕКЦИЯ 6. ВОССТАНОВЛЕНИЕ ИНФОРМАЦИИ
Системы хранения данных СХД — это аппаратные или программные средства, которые применяются для хранения и обработки информационных ресурсов, оптимизации процессов хранения, передачи и управления файлами (информацией) в компьютерных сетях.
Ключевые компоненты таких решений: накопители, серверы, инструменты управления данными и обеспечения связи между серверами.
Задачи СХД:
- Хранение данных. Главная задача любой системы — надежно сохранять информацию. Это включает защиту от физических повреждений оборудования, сбоев в работе или случайного удаления файлов.
- Обеспечение доступа. СХД предоставляют быстрый и удобный доступ к данным, будь то локальное устройство или удаленный сервер. Это особенно важно для приложений, которым требуется мгновенная обработка информации.
- Управление данными. Современные СХД оснащены инструментами для структурирования информации, создания резервных копий, архивирования устаревших данных и восстановления в случае потерь.
- Масштабируемость. СХД позволяют увеличивать объем хранилища по мере роста потребностей, что делает их гибкими для использования как частными лицами, так и крупными организациями.
- Оптимизация ресурсов. Некоторые продвинутые системы автоматически распределяют данные между различными носителями, чтобы повысить производительность и снизить затраты.
Где используются СХД?
Системы хранения данных находят применение практически во всех областях современной жизни. Их универсальность обусловлена широким спектром доступных решений, от простых накопителей до сложных сетевых инфраструктур. Рассмотрим подробнее, где и как используются СХД:
- Личное использование. Для частных пользователей СХД необходимы для хранения личных данных: семейных фотографий, видео, музыкальных коллекций, документов и резервных копий важных файлов. В домашних условиях чаще всего применяются внешние жесткие диски, флеш-накопители или облачные сервисы, такие как Google Drive, Яндекс.Диск или iCloud. Эти решения просты в использовании и доступны по цене.
- Малый и средний бизнес. Небольшие компании используют СХД для управления клиентскими базами, финансовыми отчетами, проектной документацией и резервными копиями рабочих данных. Здесь популярны сетевые хранилища (NAS), которые позволяют нескольким сотрудникам работать с информацией одновременно, а также локальные системы с функцией RAID для повышения надежности.
- Крупные корпорации. Крупные корпорации пользуются СХД с целью обработки обширных объемов информации. Это может быть аналитика больших данных, управление цепочками поставок или поддержка сложных ИТ-инфраструктур.
- Научные исследования. Ученые и исследователи применяют СХД для хранения результатов экспериментов, симуляций, геномных данных или астрономических наблюдений. Например, в проектах по изучению космоса или климата ежедневно генерируются терабайты информации, которые нужно надежно сохранять и анализировать.
- Медицина. В медицинской сфере СХД используются для ведения электронных карт пациентов, хранения диагностических изображений (рентгеновских снимков, МРТ, КТ) и обеспечения доступа к ним для врачей.
- ИТ-инфраструктура и дата-центры. Крупные облачные провайдеры, такие как Amazon, Microsoft или Google, используют мощные СХД для поддержки веб-сайтов, приложений, потокового видео и других сервисов, доступных миллионам пользователей по всему миру. Здесь применяются сложные системы с высокой степенью автоматизации и отказоустойчивости.
- Творческие индустрии. Фотографы, видеографы, дизайнеры и студии монтажа используют СХД для работы с большими файлами высокого разрешения, требующими быстрого доступа и надежного хранения.
СХД стали универсальным инструментом, который подстраивается под любые задачи — от простого сохранения семейных воспоминаний до обеспечения работы глобальных технологических экосистем. Их разнообразие позволяет каждому пользователю найти подходящее решение в зависимости от потребностей и бюджета.
Компоненты системы хранения данных
Роль СХД в современном бизнесе связана с непрерывным изменением ландшафта ИТ-инфраструктуры.
- Аппаратное обеспечение (железо) включает в себя твердотельные накопители (SSD) и жесткие диски, контроллеры и инновационные технологии, например, NAS (сетевые устройства хранения данных) и SAN сети хранения данных.
- Операционная система, то есть особое программное обеспечение для хранения данных и управления информацией. Она обеспечивает не только производительность и доступность данных, но и надежность всей системы.
- ПО для управления данными, то есть специализированный софт для управления данными, организации и классификации, а также для защиты данных. В функции этого специализированного программного обеспечения заложены мгновенные снимки и компрессия, шифрование, дедупликация и резервное копирование.
- Сетевое подключение. Для СХД необходимы еще и сетевые интерфейсы, чтобы иметь возможность подключения к более крупной ИТ-инфраструктуре. Это требование нужно для доступа к авторизованным пользователям в локальной сети.
Как устроена система хранения данных
С точки зрения аппаратного устройства системы хранения данных имеют сложную структуру, включающую различные компоненты.
Каждый из этих компонентов выполняет важные функции в СХД, обеспечивая сохранность и доступность данных. Они могут быть настроены и адаптированы в соответствии с требованиями организации и конкретным сценарием использования.
· Массив жестких дисков (HDD или SSD). Представляет собой группу физических дисков, которые используются для хранения данных. HDD используются для долгосрочного хранения информации, а SSD обеспечивают более высокую скорость чтения и записи.
· Кэш-память (или кэш-накопитель). Здесь временно хранятся наиболее часто используемые данные, к которым можно получить быстрый доступ.
· Контроллер дискового массива (RAID-контроллер). Управляет работой массива жестких дисков. Он обеспечивает объединение нескольких дисков в логические группы, резервирование данных, контроль целостности данных и управление доступом к данным.
· Внешний корпус. Представляет собой физическую оболочку, в которой размещаются компоненты СХД, включая массив жестких дисков, кэш-память и контроллер дискового массива. Обеспечивает физическую защиту и организацию компонентов СХД.
· Блоки питания. Обеспечивают электропитание для всех компонентов СХД и гарантируют их непрерывную работу.
Типы систем хранения данных:
- По принципу развертывания, организации доступа и функционирования СХД условно делятся на четыре категории.
1. Локальные системы хранения данных
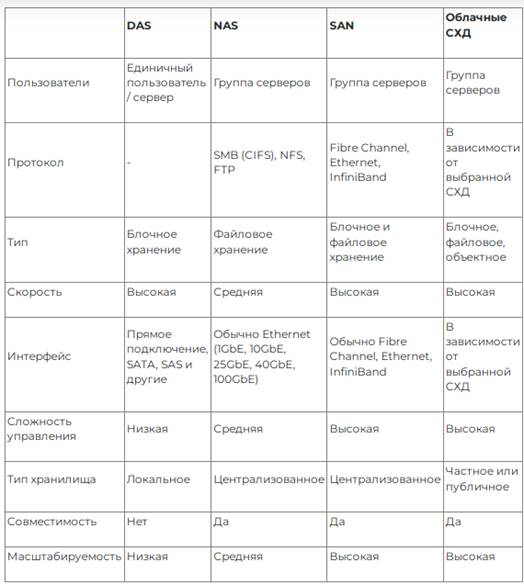
DAS (Direct Attached Storage) — решения, которые подключаются напрямую к устройствам — серверам или компьютерам. Подключение осуществляется не по сети, а «проводным» способом.
Это хранилище представляет собой набор жестких дисков, который подключается к компьютеру или серверу без использования сети через USB, Thunderbolt, eSATA или SCSI. За счет этого DAS обеспечивает более высокую скорость передачи данных, чем, например сетевые хранилища вроде Network Attached Storage (NAS) или Storage Area Network (SAN).
Особенности:
- Подключение осуществляется напрямую, без использования сети.
- Управление системой обычно выполняется через интерфейс операционной системы основного устройства.
- Объем хранения ограничен возможностями конкретного устройства.
Плюсы такой СХД:
· Отсутствие сложных настроек.
· Хорошая скорость передачи информации благодаря тому, что процесс не зависит от качества сети.
· Невысокая стоимость.
· Независимость от сети, что делает их удобными для мобильного использования.
Минусы:
· Ограниченная масштабируемость, из-за чего локальная система хранения данных подойдет только для небольших офисов.
· Остановка работы, если устройство, к которому подключена СХД, выйдет из строя.
· Невозможность организовать удаленный и общий доступ к файлам.
2. Сетевые системы хранения данных
NAS (Network Attached Storage) — устройства, подключаемые к локальной сети и предоставляющие доступ к информационным ресурсам с помощью распространенных сетевых протоколов. Такие решения оптимальны для небольших и средних компаний, для крупных у них не хватит производительности.
Устройство предоставляет централизованное хранилище для файлов и данных, доступное для всех устройств в сети. NAS управляется специальным программным обеспечением, которое обеспечивает доступ к информации через протоколы сетевой передачи данных, такие как FTP, SMB, NFS и другие.
Пользователи могут создавать различные каталоги и разделять доступ к ним с помощью учетных записей и прав доступа. Некоторые устройства NAS предлагают дополнительные функции: резервное копирование, потоковое воспроизведение мультимедиа, доступ к файлам через интернет и т. д. Среди других преимуществ NAS — удобство централизованного хранения данных, возможность резервного копирования, легкость расширения хранилища и доступ к файлам из любой точки сети.
Особенности:
- Доступ к данным осуществляется через сеть (Ethernet или Wi-Fi).
- Поддерживает работу с несколькими пользователями одновременно.
- Часто включает дополнительные функции: медиасервер, резервное копирование, интеграция с облаком.
Сильные стороны NAS:
· Поддержка совместного доступа к информационным ресурсам.
· Возможность добавлять новые диски для наращивания объемов хранения.
· Наличие дополнительных функций, таких как резервное копирование, распределение данных и др.
Недостатки:
· Низкая производительность по сравнению с другими видами СХД.
· Зависимость от стабильности сетевого соединения.
SAN (Storage Area Network) — системы хранения данных, позволяющие объединять устройства в единую сеть. Они поддерживают работу со значительными объемами информации, поэтому идеальны для крупного бизнеса с высокими требованиями к информационной безопасности и скорости передачи файлов.
Это специализированная высокоскоростная сеть, обеспечивающая сетевой доступ к устройствам хранения данных. Она обычно состоит из хостов, коммутаторов, элементов и устройств хранения, которые соединены между собой. SAN представляет устройства хранения данных хосту таким образом, что они кажутся локально подключенными. Такое упрощенное представление хранилища хосту достигается за счет использования виртуализации ресурсов.
Особенности:
- Высокая скорость передачи данных благодаря выделенной сети.
- Архитектура ориентирована на крупные инфраструктуры.
- Поддерживает виртуализацию и работу с большими массивами данных.
Преимущества SAN:
· Высокая производительность и скорость передачи информации благодаря выделенной сети.
· Поддержка виртуализации.
· Гибкость за счет возможности подключения сотни накопителей.
· Устойчивость к сбоям.
Слабые стороны:
· Высокая стоимость специального оборудования и лицензий на использование.
· Потребность в специалистах, которые будут обслуживать СХД.
· Необходимость выделять значительные ресурсы для интеграции SAN в ИТ-инфраструктуру.
3. Облачные системы хранения данных
Это виртуальные СХД, которые предоставляются клиенту в качестве услуги от провайдера через интернет. Доступ к таким системам пользователи получают через API, специальные приложения или веб-интерфейсы. Благодаря простоте использования и неограниченной масштабируемости облачные СХД удобны для крупного бизнеса.
Особенности:
- Физическое оборудование находится у провайдера.
- Доступ возможен из любой точки мира при наличии интернета.
- Оплата обычно осуществляется по модели подписки.
Плюсы облачных систем хранения данных:
· Отсутствие необходимости покупать физическое оборудование — оно находится у провайдера.
· Удаленный доступ из любых регионов/стран.
· Возможность без проблем наращивать объемы хранения данных.
· Разные тарифы в зависимости от потребностей заказчика.
· Многообразие вариантов СХД под разные бизнес-требования.
Минусы:
· Зависимость работы системы хранения данных от стабильности интернета.
· Риски утечки информации из-за отсутствия полного контроля.
Виды СХД в зависимости от формата хранения данных, по типу работы с данными:
В рамках этой классификации выделяют четыре вида систем хранения данных:
· Блок-ориентированные — системы, разделяющие данные на одинаковые блоки, нумерующие их и сохраняющие в физических хранилищах.
Блочные хранилища работают на более низком уровне и предоставляют доступ к данным в виде блоков фиксированного размера. Они используются для хранения и передачи данных в виде блоков, например по протоколам Fibre Channel, iSCSI или SCSI. Блочные устройства обычно используются для хранения информации, требующей высокой производительности и низкой задержки, такой как базы данных, и виртуализации.
· Файловые системы — решения, позволяющие хранить сведения в формате файлов в специальных каталогах и папках, называемых директориями.
Файловые хранилища используются для хранения и управления файлами и папками. Они предоставляют доступ к данным через протоколы NFS (Network File System) для UNIX/Linux-систем и CIFS (Common Internet File System) для систем Windows. Файловые системы, например NAS, обеспечивают общий доступ к данным и удобство в работе с файлами.
· Объектные хранилища — СХД, которые подразумевают хранение информационных ресурсов в виде объектов с уникальными идентификаторами и метаданными.
Объектные хранилища организуют данные в виде объектов, которые содержат сами данные, метаданные и уникальный идентификатор. Это позволяет эффективно управлять большими объемами информации, такими как big data, а также обеспечивает гибкость и масштабируемость хранения. Объектные хранилища часто используются для хранения данных в облаке и для распределенных систем.
· Гибридные решения — СХД, которые поддерживают несколько форматов хранения данных.
Выбор следует делать в зависимости от того, какие объемы данных есть в компании, какие требования она предъявляет к скорости обработки информации. Наиболее распространены файловые системы, поскольку они отвечают нуждам большинства организаций.
В какой бы системе ни хранились данные, провайдер обязан следить за отказоустойчивостью инфраструктуры. Резервное копирование, репликация, распределение нагрузки, защита от атак и другие услуги помогают сделать СХД более устойчивой.
А если сбой все же произойдет — минимизировать его последствия и максимально быстро восстановить систему.
Для оценки способности СХД восстанавливаться после сбоев используются два показателя: RPO и RTO.
RPO (Recovery Point Objective). Определяет максимально допустимую потерю данных в случае сбоя. Этот показатель указывает, насколько близко к моменту сбоя должны быть восстановлены данные. Чем меньше RPO, тем меньше потеря данных при восстановлении.
RTO (Recovery Time Objective). Определяет максимально допустимое время восстановления после сбоя. Этот показатель указывает, сколько времени требуется для восстановления работы системы после сбоя. Чем меньше RTO, тем быстрее система восстанавливается и снова становится доступной.
## 1. Сохранение и восстановление информации
Поскольку данные, хранимые компьютерными средствами, подвержены потерям и повреждениям, вызываемым разными событиями, важно обеспечить средства восстановления данных.
Приведение базы данных точно в то состояние, которое существовало перед отказом, не всегда возможно, но процедуры восстановления базы данных могут привести ее в состояние, существовавшее незадолго до отказа.
Виды неисправностей систем хранения данных
В процессе эксплуатации информационных систем может происходить потеря или повреждение информации по множеству причин. Все неисправности можно систематизировать по следующим категориям:
1. Аппаратные неисправности - это физические поломки компонентов оборудования, являющиеся одной из самых частых причин сбоев.
- Неисправности накопителей: Отказы жестких дисков (bad-сектора, механические повреждения), деградация и износ SSD-накопителей, полный выход из строя дисковых устройств
- Проблемы с контроллерами: Сбои RAID-контроллеров (выход из строя процессора, памяти), неисправности кэш-памяти (особенно при использовании кэша без батарейного резервирования), ошибки в работе процессоров управления.
- Неполадки в системе питания: Отказы блоков питания (БП), перебои электропитания (скачки, провалы напряжения), неисправности систем охлаждения (выход из строя вентиляторов, засорение систем охлаждения пылью).
- Проблемы с подключением: Повреждение кабелей (физический излом, помехи), неисправности сетевых адаптеров (HBA, NIC), сбои в работе коммутаторов (как сетевых, так и SAN).
- Отказы
компонентов серверов: Неисправности оперативной памяти (битые
ячейки), проблемы с материнскими платами (выход из строя чипсета, слотов
расширения).
2. Программные неисправности - Сбои на уровне программного обеспечения, микропрограмм и виртуализации.
Ошибки операционной системы: Сбои драйверов устройств, проблемы с файловыми системами (повреждение структур, "зависание" операций ввода-вывода), конфликты программного обеспечения (например, антивирусов и фильтров файловой системы).
- Неисправности firmware: Устаревшие версии микропрограмм, содержащие известные ошибки; поврежденные (corrupted) прошивки в результате некорректного обновления или сбоя питания; несовместимость версий прошивок между различными компонентами СХД.
. Firmware — это встроенное программное обеспечение, которое обеспечивает базовое управление аппаратными компонентами устройства. Если представить устройство как тело, то firmware — это его "мозг" и "нервная система", которые заставляют железо работать.
- Проблемы виртуализации: Сбои гипервизора, ошибки в работе виртуальных машин (ВМ), конфликты ресурсов между ВМ за доступ к дисковому пространству.
3. Неисправности целостности данных - Повреждение самих данных или информации о их структуре.
- Повреждение данных: Битые сектора на дисках, corrupted файлы (когда содержимое файла изменено или повреждено), ошибки контрольных сумм (когда данные при чтении не соответствуют сохраненной хеш-сумме).
- Проблемы метаданных: Повреждение таблиц разделов (MBR, GPT), ошибки в структурах файловых систем (суперблок в UNIX/Linux, MFT в NTFS).
- Синхронизационные ошибки: Расхождения данных в репликах (при асинхронной репликации), проблемы с согласованностью копий (например, при создании снэпшотов активно изменяющихся данных).
4. Неисправности производительности и доступности - Система работает, но не удовлетворяет требованиям по скорости или времени доступности.
- Деградация производительности: Чрезмерная нагрузка на дисковую подсистему (высокий IOPS, латентность), неоптимальная конфигурация RAID (например, использование RAID 5 для нагрузок с интенсивной записью).
- Проблемы доступности: Потеря связи с хранилищем из-за сетевых проблем, недоступность сетевых ресурсов (шар).
- Ресурсные ограничения: Исчерпание дискового пространства, нехватка оперативной памяти для кэширования.
5. Сетевые неисправности - Проблемы в сетевой инфраструктуре, обеспечивающей доступ к СХД.
- Проблемы подключения: Обрывы сетевых соединений, неправильная настройка сетевых интерфейсов (неверные MTU, дуплексы).
- Неисправности SAN: Сбои Fibre Channel (потеря синхронизации с портом), проблемы с зонированием (incorrect zoning), ошибки iSCSI-подключений (неудачная аутентификация CHAP, сбои сессий).
- DNS и разрешение имен: Проблемы с сетевыми именами, ошибки разрешения адресов, ведущие к недоступности ресурсов.
6. Неисправности конфигурации - Ошибки, допущенные на этапе настройки системы.
- Ошибки настройки RAID: Неправильный выбор уровня RAID, ошибочная конфигурация массивов (неверный размер страйпа).
- Проблемы контроля доступа: Некорректные права доступа (ACL), ошибки аутентификации и авторизации.
- Ошибочные настройки: Неоптимальные параметры производительности, неправильные лимиты ресурсов (квоты).
7. Неисправности безопасности - Угрозы, ведущие к утечке, шифрованию или уничтожению данных.
- Атаки и вредоносное ПО: Рансомвер-атаки (шифрование данных), вирусное заражение, несанкционированный доступ.
- Проблемы шифрования: Потеря ключей шифрования, ошибки криптографических алгоритмов, уязвимости в реализации.
- Нарушения политик безопасности: Несоответствие требованиям compliance, пробелы в политиках доступа.
8. Экологические и внешние факторы - Внешние воздействия на инфраструктуру.
- Температурные проблемы: Перегрев оборудования, недостаточное охлаждение
- Внешние воздействия: Скачки напряжения в электросети, физические повреждения (затопления, пожар), природные катаклизмы
9. Человеческий фактор
- Ошибочные действия: Случайное удаление данных, неправильное обслуживание (например, извлечение не того диска из массива).
- Недостаток компетенции: Ошибки в управлении, неправильная диагностика проблем, несвоевременное реагирование на инциденты.
10. Логические неисправности - это сбои, при которых физические компоненты системы исправны, но данные оказываются поврежденными, недоступными или семантически некорректными на уровне их структуры, формата или взаимосвязей. Это самый коварный тип неисправностей, так как система может оставаться работоспособной, выдавая при этом неверные результаты.
10. 1. Неисправности целостности данных
o Потеря инодов (inode loss) - файлы существуют, но файловая система их "не видит"
o Повреждение журналирования (Journal Corruption) - метаданные в противоречивом состоянии
o "Зацикливание" директорий - логические петли в структуре каталогов
o Повреждение MFT (Master File Table) в NTFS или суперблока в Ext4
o Corrupted файлы - нарушение формата файлов (JPEG, DOCX, баз данных)
o Частично записанные данные - прерванные операции записи
o "Тихие" повреждения данных (Silent Data Corruption) - данные изменены без фиксации ошибки
10.2. Неисправности метаданных и разделов
o MBR/GPT corruption - ОС не может определить структуру диска
o Пересекающиеся разделы - логические конфликты размещения данных
o Неправильные размеры разделов - расхождение фактических и записанных размеров
o Потеря информации о точках монтирования
o Повреждение каталогов и атрибутов файлов
o Нарушение временных меток и прав доступа
10. 3. Неисправности репликации и синхронизации
o "Расщепление мозга" (Split-Brain) - конфликтующие записи с разных узлов
o Потеря кворума - невозможность принятия согласованных решений
o Рассинхронизация реплик - накопление расхождений между копиями
o Неправильный порядок применения транзакций
o Потеря промежуточных изменений при асинхронной репликации
o Конфликты одновременного доступа на разных узлах
10.4. Неисправности виртуальных сред
o Повреждение цепочки снапшотов - зависимость от неработоспособного родителя
o Долгосрочное хранение снапшотов - деградация производительности
o Расхождение состояния снапшота и текущих данных
o Неполная миграция виртуальных машин
o Повреждение конфигурационных файлов ВМ (VMX, VMDK)
o Конфликты доступа к общим ресурсам хранения
10. 5. Неисправности баз данных
o Битые индексы - несоответствие индексов и данных таблиц
o Повреждение страниц данных (Page Corruption)
o Нарушение целостности связей (Foreign Key constraints)
o "Подвешенные" транзакции - незавершенные операции
o Нарушение ACID-свойств
o Неправильная работа механизмов блокировок
10.6. Человеческий фактор
o Случайное массовое удаление/изменение данных
o Некорректные SQL-запросы (особенно без условия WHERE)
o Ошибочное редактирование конфигурационных файлов
o Неправильные настройки кэширования
o Ошибочные операции обслуживания (например, неверная замена диска в RAID)
o Несвоевременное обновление ПО и прошивок
10. 7. Программно-конфигурационные неисправности
o Ошибки в драйверах файловых систем
o Проблемы дисковых фильтров и антивирусного ПО
o Конфликты версий библиотек и компонентов
o Неоптимальные параметры производительности
o Ошибочные настройки контроля доступа
o Неправильная конфигурация сетевых протоколов
Методы обнаружения и диагностики
Исходя из этого обязательным элементом любых ИС являются процедуры сохранения и восстановления информации как защитная мера от разрушения (потери) данных.
Сохранение информации— это процедура получения резервной копии с целью ее последующего использования для восстановления после уничтожения, повреждения или утери оригинальной информации, с целью их последующего использования
При сохранении информации используют термины *копирование, дублирование, доминирование, выгрузка*.
1. Копирование (Backup) – Базовый процесс создания точной реплики данных на дополнительном носителе. Обеспечение возможности восстановления данных при их утере или повреждении.
2. Дублирование (Replication) – Создание и поддержание идентичных копий данных в реальном времени или near-real-time на раздельных системах хранения. Непрерывная синхронизация изменений между оригиналами и копиями.
3. Архивирование (Archiving) – Долгосрочное сохранение редко используемых данных с возможностью их последующего извлечения. Перенос данных на медленные, но экономичные носители с организацией корректного каталогизированного доступа.
4. Выгрузка (Export) – Извлечение данных из системы или приложения в стандартизированном формате для последующего использования в других системах. Обеспечение совместимости и переносимости данных.
5. Снапшот (Snapshot) – Моментальный снимок состояния данных или системы в конкретный момент времени. Создается практически мгновенно, часто использует механизмы дифференциального сохранения (только изменения).
6. Тирирование (Tiering) – Автоматическое распределение данных между различными уровнями хранения в зависимости от частоты использования и критичности. Оптимизация стоимости хранения при обеспечении требуемой производительности.
Копирование (сохранение) информации выполняется периодически по графику. Между точками снятия копий сохраняются все данные, которые использовались для внесения изменений в файлы (базы данных). Копирование проводится по схеме «отец — сын», что означает хранение двух копий для двух последовательных процедур копирования.
При файловой обработке между точками снятия копий сохраняют исходные файлы корректур. При работе с базами данных в режиме онлайн используют системный журнал и процедуру накопления изменений информации. Системный журнал — это файл, в который вносится информация (протоколируется) о ходе работы информационной системы, включая все изменения баз данных.
Восстановление информации — это комплексная процедура ликвидации разрушений данных с использованием сохраненной информации на некоторый момент времени (копии) и возможной корректуры с момента создания копии.
Восстановление базы данных — функция СУБД, которая в случае логических и физических сбоев приводит базу данных в актуальное и консистентное состояние.
Восстановление задействует:
- Сохраненную резервную копию на определенный момент времени
- Дополнительные механизмы коррекции (транзакционные логи, журналы изменений) для приведения данных в актуальное состояние на момент сбоя
Уровни восстановления информации
– **оперативное восстановление. - Ликвидация локальных инцидентов без остановки основных бизнес-процессов. Оперативное восстановление используется, когда отдельные изменения в базах данных могут быть отменены при обнаружении ошибок в программах, аргументах поиска данных и т. д.;
Объем восстанавливаемых данных – отдельные файлы, папки, записи БД
Типичные сценарии:
- восстановление случайно удаленных документов
- возврат к предыдущей версии файла после ошибочного изменения
- восстановление отдельных таблиц базы данных
Технологии:
- Файловые бэкапы
- снапшоты
- версионирование
– **промежуточное восстановление – Восстановление функциональности ключевых систем после серьезных сбоев.
Для
целей промежуточного восстановления используется метод контрольной
точки.
Контрольная точка — это дамп оперативной памяти и (или) областей баз данных, сохраняемый в системном журнале в процессе работы информационной системы в определенный момент времени для возможного последующего восстановления работоспособности системы и баз данных на этот момент времени. Контрольная точка создается через заданный интервал времени, через определенное количество изменений в базах данных, при выполнении определенных условий в системе;
Объем восстанавливаемых данных – Целиком системы или приложения
Типичные сценарии:
- Восстановление сервера после аппаратного сбоя
- Восстановление виртуальной машины из образа
- Восстановление базы данных до момента сбоя с применением транзакционных логов
Технологии:
- Образы систем
- резервные копии приложений
- репликация
– **длительное восстановление - масштабное восстановление ИТ-инфраструктуры после катастрофических событий Используются копии баз данных для восстановления информации и массивы корректур (накопленных изменений).
Объем восстанавливаемых данных – вся инфраструктура организации
Типичные сценарии:
- Восстановление работы ЦОД после пожара/наводнения
- Запуск резервного дата-центра при полном отказе основного
- Восстановление после масштабной кибератаки
Технологии:
- Географически распределенные ЦОД
- облачные решения аварийного восстановления
- полные резервные копии инфраструктуры
При проектировании ИС и создании рабочей документации следует процедуры сохранения и восстановления информации выделять особо. Указанные процедуры входят также в состав функций по ведению баз данных.
Ведение базы данных — это комплекс мероприятий по поддержанию данных в актуальном и достоверном состоянии.
|
Аспект ведения БД |
Процедура сохранения (Резервное копирование) |
Процедура восстановления |
|
Поддержание актуальности |
Создание копий, отражающих актуальное состояние на определенный момент времени (снапшоты, транзакционные логи). |
Восстановление последней актуальной версии данных или приведение данных в актуальное состояние с помощью логов. |
|
Поддержание достоверности |
Обеспечение целостности резервной копии (проверка контрольных сумм, валидация после создания). |
Восстановление данных до состояния, предшествующего их повреждению или несанкционированному изменению. |
|
Управление доступом |
Резервное копирование метаданных, прав доступа, ролей пользователей. |
Восстановление не только самих данных, но и системы их защиты, чтобы исключить несанкционированный доступ после восстановления. |
|
Архивирование и очистка |
Перенос устаревших, но требуемых по регламенту данных в архивные хранилища. |
Возможность извлечения архивных данных для аудита |
2. Журнал транзакций. Восстановление через откат
Реализация в СУБД принципа сохранения промежуточных состояний, подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается некоторая системная структура, называемая журналом транзакций.
Журнал транзакций содержит дополнительную информацию об изменениях базы данных и предназначен для обеспечения надежного хранения данных в БД.
Целью журнализации изменений баз данных является обеспечение возможности восстановления согласованного состояния БД после любого рода сбоев (аппаратных и программных). Основой поддержания целостного состояния БД является механизм транзакций.
Транзакция — последовательность операций над базой данных, отслеживаемая системой управления БД от начала до завершения как единое целое.
Выделят следующие типы транзакций:
1) плоские или классические (традиционные);
2) цепочечные;
3) вложенные.
Плоские или традиционные транзакции характеризуются следующими свойствами:
– *атомарности* — выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе;
– *согласованности* — гарантирует, что по мере выполнения транзакций данные переходят из одного согласованного состояния в другой — транзакция не разрушает взаимной согласованности данных;
– *изолированности* — означает, что конкурирующие за доступ к базе данных транзакции физически обрабатываются последовательно, изолированно друг от друга, но для пользователей это выглядит так, как будто они выполняются параллельно;
– *долговечности* — означает, что если транзакция завершена успешно, то те изменения данных, которые были ею произведены, не могут быть потеряны ни при каких обстоятельствах.
Общими принципами восстановления являются следующие:
1) результаты зафиксированных транзакций должны быть сохранены в восстановленном состоянии базы данных;
2) результаты незафиксированных транзакций должны отсутствовать в восстановленном состоянии базы данных.
К ситуациям, при которых требуется восстановление базы данных, относятся:
– индивидуальный откат транзакции (аварийное завершение работы и т. д.);
– восстановление после внезапной потери содержимого оперативной памяти (аварийное выключение электропитания, неустранимый сбой процессора и т. д.);
– восстановление после поломки основного внешнего носителя базы данных.
Возможны два основных варианта ведения журнальной информации:
1) отдельный локальный журнал, который поддерживается для каждой транзакции и используется для индивидуальных откатов транзакций;
2) общий журнал изменений базы данных, используемый для восстановления состояния базы данных после мягких и жестких сбоев.
Структура журнала условно может быть представлена в виде последовательного файла, в котором фиксируется каждое изменение базы данных. Каждая запись в журнале транзакций помечается номером транзакции, к которой она относится, и значениями атрибутов, которые она меняет.
Откат транзакции (возможность для незаконченных транзакций) выполняется следующим образом:
– выбирается очередная запись из списка данной транзакции;
– выполняется противоположная по смыслу операция, восстанавливающая предыдущее состояние объекта базы данных;
– любая из обратных операций также заносится в журнал;
– при успешном завершении отката в журнал заносится запись о конце транзакции.
При восстановлении базы данных после мягкого сбоя в журнале отмечаются точки физической согласованности базы данных — моменты времени, в которые во внешней памяти содержатся согласованные результаты операций, завершившихся до соответствующего момента времени, и отсутствуют результаты операций, которые не завершились.
Основой восстановления базы данных после жесткого сбоя являются журнал и архивная копия БД. Восстановление начинается с обратного копирования БД из архивной копии. Затем для всех закончившихся транзакций по журналу в прямом направлении выполняются все операции, для транзакций, которые не закончились к моменту сбоя, выполняется откат.
В случае логического отказа или сигнала отката одной транзакции журнал изменений сканируется в обратном направлении и все записи отменяемой транзакции извлекаются из журнала вплоть до отметки начала транзакции. Согласно извлеченной информации выполняются действия, отменяющие действия транзакции. Этот процесс называется «откат» (rollback).
В случае физического отказа, если ни журнал изменений, ни сама база данных не повреждены, выполняется процесс протонки (rollforward). Журнал сканируется в прямом направлении, начиная от предыдущей контрольной точки. Все записи извлекаются из журнала вплоть до конца журнала. Извлеченная из журнала информация вносится в блоки данных внешней памяти, у которых отметка номера изменений меньше, чем записанная в журнале. Если в процессе протонки снова возникает сбой, то сканирование журнала вновь начнется с начала, но восстановление фактически продолжится с той точки, где оно прервалось.
В случае физического отказа, если журнал изменений доступен, но сама база данных повреждена, должен быть выполнен процесс восстановления базы из резервной копии. После восстановления база будет находиться в состоянии на момент выполнения резервной копии. Для восстановления базы данных на момент отказа необходимо выполнить протонку всех изменений, используя журнал изменений.
В случае физического отказа, если журнал изменений недоступен, но сама база данных не повреждена, восстановление возможно только на момент предыдущей контрольной точки.
В случае физического отказа, если повреждены как журнал изменений, так и сама база данных, восстановление возможно только на момент выполнения резервной копии.
3. Восстановление поврежденной базы данных
Всегда существует вероятность того, что любое информационное хранилище будет повреждено и часть информации из него потеряна. Базы данных не являются исключением из этого правила. Обычно базу данных называют поврежденной, если при попытке извлечь или модифицировать содержащуюся в ней информацию возникают ошибки и (или) извлекаемая информация оказывается утерянной, неполной или вообще неправильной. Порой повреждения базы данных скрыты и обнаруживаются только при проверке специальными средствами, но бывают и явные поломки базы данных, когда к базе невозможно подключиться, отлаженные программы-клиенты выдают нестандартные странные ошибки (в то время как никаких манипуляций над базой данных не производилось) или когда невозможно восстановить базу данных из резервной копии.
Основными причинами повреждения баз данных являются следующие.
1.
Аварийное завершение работы серверного компьютера, особенно внезапное
отключение электропитания. Поэтому необходимо иметь на сервере источник
бесперебойного
питания.
При отключении питания на компьютере-сервере все процессы обработки данных резко прерываются. В результате информация в базе данных может исказиться или пропасть. После восстановления питания сервер просматривает данные, отслеживает незавершенные транзакции, не ассоциируемые ни с одним из клиентов, и «откатывает» все изменения, проведенные в рамках этих прерванных транзакций. Однако отключение питания не всегда сопровождается лишь такими незначительными потерями. Если сервер в момент отключения питания производил расширение базы данных, то велик риск получить «потерянные» страницы в файле базы данных (orphan pages), т. е. такие страницы, которые физически распределены и зарегистрированы на страницах учета страниц, но запись данных на которые невозможна. Бороться с потерянными страницами в файле базы данных умеет только инструмент починки и модификации BackUtil или gfix (стандартная утилита FireBird). Потерянные страницы приводят только к излишнему расходу дискового пространства и как таковые не служат причиной потери или порчи данных. Но отключение питания может приводить и к более серьезным повреждениям. После отключения питания и повторного включения может пропасть большое количество данных, в том числе и подтвержденных. Это происходит из-за того, что подтвержденные данные записываются не напрямую в файл базы данных на диске, а используют для этой цели файловый кэш операционной системы. То есть серверный процесс передает операционной системе команду на запись данных на диск, операционная система, в свою очередь, отправляет подтверждение на сервер, что данные сохранены на диске, а на самом деле данные находятся в файловом кэше. Операционная система не сбрасывает эти данные на диск, так как оценивает, что оперативной памяти еще много, и откладывает медленные операции записи на диск до тех пор, пока не закончится свободная оперативная память.
2. Дефекты и неисправности серверного компьютера, особенно дисков, дисковых контроллеров, оперативной памяти компьютера и кэш-памяти RAID-контроллеров.
3. Файловое копирование или другой файловый доступ к базе данных при запущенном сервере. Выполнение команды shutdown или отключение пользователей обычным порядком не является гарантией того, что сервер ничего не делает с базой; если sweep interval не установлен в 0, может выполняться sweep. Кроме того, после отключения последнего пользователя сервер убирает лишнюю информацию. Обычно эта процедура занимает 1–2 мин, но если перед этим выполнялось много операций delete или update, то процесс может быть более длительным.
4. Исчерпывание свободного дискового пространства во время работы с базой.
5. Для всех серверов Borland FireBird превышение допустимого количества транзакций без выполнения backup/restore.
Во избежание подобных ситуаций, начиная с версии 1.0.12, предусмотрена работа программы «Планировщик резервного копирования данных» с расширенным набором функций архивации данных.
Программа предназначена для выполнения операций резервного копирования, восстановления, починки данных и копирования данных за выбранный период в автономном режиме. После старта она выполняет свои функции согласно заданному расписанию без привлечения к себе внимания со стороны пользователя. Лог работы программы ведется в журнале событий ОС Windows.
В отличие от программ, которые работают как сервисы Windows и могут запускаться до логина пользователя в ОС, «Планировщик резервного копирования данных» останется не запущенным пока пользователь не пройдет регистрацию в ОС. Поэтому для запуска программы необходимо произвести вход в Windows. Так как программа поставляется в дистрибутиве серверной части системы, то такой пользователь должен обладать правами администратора ОС.
Важно отметить, что:
1) планировщик резервного копирования можно закрыть только через меню пиктограммы из системного трея;
2) если он выполняет какие-либо действия, то закрыть программу нельзя пока процесс не завершится;
3) если в процессе выполнения архивирования, профилактики попытаться выключить компьютер, то программа не даст этого сделать.
Лог работы программы ведется в журнале событий ОС Windows.
Перед выполнением операций резервного копирования (BackUp) и восстановления базы данных (Restore) происходит анализ свободного места на диске.
При этом:
1) свободного места на диске, где находится БД должно быть достаточно для хранения самой БД и ее копии, которая создается при восстановлении БД (Restore). Если БД состоит из нескольких файлов, то при оценке места на диске учитывается их общий размер;
2) свободного места на диске, где находятся файлы архивной копии БД, должно быть не меньше общего размера самой БД.
При отсутствии свободного места выполнение функций будет остановлено.
Программа «Планировщик резервного копирования данных» реализует следующие функции:
Регулярное резервное копирование данных — позволяет создать архивную копию всей базы данных (Backup). При этом могут создаваться многофайловые архивы, что определяется настройкой программы.
Профилактика
базы данных (Backup/Restore) — включает в себя
выполнение сразу двух операций: резервного копирования данных (Backup) и
восстановления
данных (Restore).
Профилактика выполняется как для получения резервной копии базы данных, так и для очистки базы данных от временных записей, что позволяет уменьшить размер БД. На этапе восстановления могут создаваться многофайловые БД, что определяется настройкой программы. При восстановлении все БД отключаются немедленно, а также происходит перезапуск сервера БД. Восстановление по этой причине возможно только на сервере БД. Следует отметить, что функция профилактики БД имеет приоритет выполнения перед функцией регулярного резервного копирования данных. В случае, когда в расписании для этих функций указаны одинаковые параметры запуска (например, совпадает день и время запуска), будет выполнена только профилактика БД. Это обусловлено тем, что профилактика уже включает в себя операцию резервного копирования данных (BackUp).
Перед выполнением восстановления БД (Restore) создается копия текущей БД с расширением docpoint2.__b. Копия БД необходима для быстрого отката при возникновении нештатных ситуаций. Для восстановления работоспособности системы достаточно переименовать файл(si) копии БД.
Например, копия БД docpoint2.__b переименовывается в docpoint2.gdb. При каждом запуске «Планировщика резервного копирования» проверяется, есть ли файл БД docpoint2.gdb. В случае если файл не найден (такое может произойти, например, в случае если во время выполнения профилактики БД произошло отключение сервера), то выдается текстовое сообщение о том, что файл БД отсутствует и администратору системы предлагается восстановить базу из копии (автоматически переименовать docpoint2.__b в docpoint2.gdb).
Починка БД — при выполнении починки БД происходит также и проверка целостности БД. При починке БД происходит отключение всех подключенных на момент проверки пользователей и включение БД при завершении операции. При этом починка БД происходит в два этапа, сначала БД проверяется на наличие ошибок, после чего выдается запрос о том, были ли обнаружены ошибки в БД и нужно ли выполнять исправление БД (дело в том, что в некоторых случаях рекомендуется сделать резервную копию файла, поскольку процесс восстановления будет вносить в БД изменения). В случае же если ошибки не найдены, то проверку нужно прекращать. Сама проверка должна производиться только в случае повреждения БД. Следует четко различать ошибки повреждения БД и, например, ошибки подключения к БД по причине отсутствия соединения. Обычно ошибки в БД могут возникать по причине нестандартного отключения электропитания.
Восстановление БД — восстановление БД из резервной копии происходит автоматически при выполнении функции «Профилактика БД», однако эта операция может быть сделана по запросу пользователя. Для этого необходимо в меню «Операции» выбрать пункт меню «Восстановить БД». Резервная копия БД находится в каталоге, определенном в настройках программы.
Удаление документов по указанную дату — используется для удаления «устаревших» документов и уменьшения размера БД. Пользователь может выбрать дату и время, на которую требуется удалить документы. Удаление документов происходит от самой ранней даты изменения документа, найденной в БД, до даты, выбранной пользователем. По умолчанию дата устанавливается из расчета: текущая дата минус один год. Периодически необходимо выполнять ревизию документов, для того чтобы те документы которые необходимо отставить, имели относительно свежую дату их изменения. Для этого, например, можно иметь некий переход в технологической схеме, прохождение через который меняло бы дату изменения документа. Информация о количестве удаленных документов сохраняется в лог-файле BackUtil.log.
Очистка BODY_LOG — удаление в каталоге BODY_LOG временных файлов, не связанных ни с одним документом БД.
При откате (RollBack) транзакции, например, когда пользователь отказывается от сохранения изменений в документе, работая в ПЗ «Модуль обработки документов», в каталоге каталога BODY_LOG формируются временные файлы. Удаление таких файлов, не связанных ни с одним из документов, выполняется автоматически при выполнении функций регулярного резервного копирования и профилактике БД. Однако очистка каталога может быть выполнена по запросу пользователя. Для этого следует выбрать в меню «Операции» пункт «Очистить BODY_LOG». Эта операция, а также период, за который будет произведена очистка, возможны при соответствующей настройке программы.
*Физическое копирование БД* — при выполнении этой операции происходит только копирование БД, без проведения процедуры backup/restore. Копирование производится в каталог для резервных копий БД.
Возврат состояния до последней операции — при выполнении этой операции происходит переименование копии базы, оставшейся после последнего выполнения операции «Профилактика БД». Важно запомнить, что при выполнении этой операции текущий вариант базы будет перезаписан более старой ее копией, без возможности возврата к нему.
Как происходит восстановление уже поврежденной БД в случае внезапного отключения электропитания? Для понимания этого сравним БД с файловой системой FAT.
Для того чтобы восстановить конкретный файл в файловой системе, выполняются два действия:
1) проверка файловой системы на целостность (логическую), например утилитой scandisk;
2) проверка, остался ли этот файл без изменений (например, специальной программой, работающей с файлом).
Аналогичные действия необходимо произвести и над неисправной БД.
1. Проверить целостность БД. База данных, как и файловая система, построена на страницах, которые выделяются в одном пространстве по мере необходимости.
2. Выполнить одну за другой функции «Выполнить резервное копирование» (Backup) и «Выполнить восстановление БД» (Restore).
Эти операции позволят выяснить, удачно ли прошло логическое восстановление БД. Если в ходе этих операций не возникло никаких ошибок, то база данных логически цела и может использоваться для работы. Исключением может быть «потеря» нескольких документов по причине того, что они в момент выключения находились в памяти операционной системы и не были сохранены (или были сохранены частично) на диске. Если базу восстановить не удается, то при наличии резервной копии (если она создается регулярно) есть возможность просто восстановить данные на момент последнего резервного копирования, при этом вся работа, происходившая после создания резервной копии, будет утеряна, но будут восстановлены в полном объеме данных за весь период до резервного копирования.
Для восстановления БД в случае ее поломки (повреждения), не связанной с отключением электропитания, существует другой алгоритм.
Важно запомнить, что ввиду особой сложности этой процедуры, ее может выполнять только вручную администратор системы. При этом восстановление выполняется только для одной конкретной БД. Восстановление требует остановки работы подразделения, так как во время операции производится остановка сервиса СУБД.
КОНТРОЛЬНЫЕ ВОПРОСЫ:
1. Дайте определение системе хранения данных (СХД).
2. Перечислите пять ключевых задач, которые решают современные СХД.
3. Назовите три ключевых компонента системы хранения данных.
4. Где чаще всего используются системы класса NAS (Network Attached Storage)?
5. В чем заключается основное преимущество систем класса SAN (Storage Area Network) перед NAS?
6. Назовите главный недостаток облачных систем хранения данных.
7. Чем отличается подход к хранению данных в блочных системах от файловых?
8. Что такое объектное хранилище и для каких задач оно оптимально?
9. Каковы два основных показателя для оценки способности СХД к восстановлению? Дайте их краткую расшифровку.
10. Объясните разницу между RPO (Recovery Point Objective) и RTO (Recovery Time Objective) на простом примере.
11. Дайте определение процедуре «Сохранение информации».
12. Чем отличается «Дублирование» (Replication) от «Копирования» (Backup)?
13. Что такое «Снапшот» (Snapshot) и каков его основной принцип работы?
14. Назовите три уровня восстановления информации и опишите объем данных для каждого.
15. Что такое «контрольная точка» (Checkpoint) в контексте промежуточного восстановления?
16. Какую роль в процедурах сохранения и восстановления играет системный журнал?
17. Какая связь существует между процедурами сохранения/восстановления и функцией «Ведение базы данных»?
18. Что такое «транзакция» в контексте СУБД?
19. Перечислите и расшифруйте четыре свойства классической (плоской) транзакции (ACID).
20. Какова основная цель ведения журнала транзакций?
21. Сформулируйте два общих принципа восстановления базы данных после сбоев.
22. Что происходит в процессе «отката» (Rollback) транзакции?
23. В чем заключается процесс «протонки» (Rollforward)?
24. В каком направлении (прямом или обратном) просматривается журнал транзакций при откате, а в каком — при протонке?
25. Опишите процедуру восстановления после «жесткого сбоя», когда доступны и архивная копия, и журнал транзакций.
26. Назовите три основные категории неисправностей систем хранения данных.
27. Что такое «логические неисправности» и почему их считают особенно коварными?
28. Приведите пример неисправности целостности данных.
29. Что такое «расщепление мозга» (Split-Brain) в кластерных конфигурациях?
30. Назовите не менее пяти основных причин повреждения баз данных.
31. Почему аварийное завершение работы сервера (отключение питания) опасно для базы данных, даже если СУБД использует журнал транзакций?
32. Какую функцию в программе «Планировщик резервного копирования данных» выполняет операция «Профилактика БД» (Backup/Restore) и какие две основные задачи она решает?
33. Что происходит с базой данных при выполнении операции «Починка БД»?
34. Каков основной алгоритм восстановления БД, поврежденной в результате внезапного отключения электропитания?
35. Что такое «потерянные» страницы (orphan pages) в файле базы данных и к каким последствиям они приводят?
36. Сравните системы DAS, NAS и SAN по ключевым параметрам: способ подключения, масштабируемость, производительность и стоимость.
37. Объясните, почему неправильный выбор уровня RAID (например, использование RAID 5 для высоконагруженных систем записи) можно отнести к неисправностям производительности.
38. Какой тип хранилища (блочное, файловое, объектное) вы бы выбрали для хранения миллионов фотографий пользователей в социальной сети и почему?
39. Что такое «тихие» повреждения данных (Silent Data Corruption) и почему они опасны?
40. Каков порядок действий администратора при невозможности восстановить базу данных стандартными средствами (через Backup/Restore), но при наличии актуальной резервной копии?
ДОПОЛНИТЕЛЬНО
41. Что означает аббревиатура DAS и каков основной сценарий ее использования?
42. Опишите принцип работы кэш-памяти в системе хранения данных и ее влияние на производительность.
43. Какие дополнительные функции, помимо хранения данных, часто предоставляют устройства NAS?
44. В чем ключевое различие между сетевым подключением в системах NAS и SAN?
45. Назовите основную причину, по которой облачные СХД считаются высокомасштабируемыми.
46. Что такое дедупликация данных и какую пользу она приносит в системах хранения?
47. Каковы роли контроллера дискового массива в СХД?
48. Для каких типов рабочих нагрузок оптимально использование блочных хранилищ и почему?
49. Что такое гибридное хранилище и какие преимущества оно дает?
50. Какую роль в отказоустойчивости СХД играют репликация и распределение нагрузки?
51. Какие два основных технологических подхода используются для создания резервных копий информации?
52. В чем заключается основное различие между Архивированием (Archiving) и Резервным копированием (Backup)?
53. Что такое "моментальный снимок" (Snapshot) и каков его главный недостаток по сравнению с полной копией?
54. Какую цель преследует процедура "тирирования" (Tiering) данных?
55. Что такое "системный журнал" и какова его роль в процессе восстановления базы данных?
56. Опишите, как используется схема «отец — сын» при резервном копировании.
57. Какие данные используются для коррекции состояния БД при восстановлении после создания резервной копии?
58. Что такое "ведение базы данных" и как оно связано с процедурами сохранения и восстановления?
59. Какие три типа транзакций выделяются в лекции?
60. Какое свойство транзакции (ACID) гарантирует, что результаты завершенной транзакции не будут утеряны?
61. Какова основная функция журнала транзакций в СУБД?
62. Что такое "контрольная точка" (Checkpoint) в контексте ведения журнала транзакций?
63. В каком случае при восстановлении используется метод "отката" (Rollback), а в каком — "протонки" (Rollforward)?
64. Что происходит с незавершенными транзакциями при восстановлении базы данных после "жесткого сбоя"?
65. Опишите сценарий, при котором для восстановления БД достаточно только резервной копии, без журнала транзакций.
66. К каким последствиям может привести исчерпание свободного дискового пространства на сервере баз данных?
67. Почему файловое копирование базы данных при запущенном сервере считается опасной операцией?
68. Какая основная цель выполнения операции "Профилактика БД" (Backup/Restore) в Планировщике резервного копирования?
69. Что происходит на этапе "Починки БД" и почему она должна выполняться с осторожностью?
70. Какую практическую задачу решает операция "Очистка BODY_LOG"?
71. В чем заключается риск использования операции "Возврат состояния до последней операции" в Планировщике?
72. Каков был основной метод борьбы с "потерянными страницами" в базах данных FireBird согласно лекции?
73. Почему простое наличие резервной копии не гарантирует успешного восстановления после сбоя?
74. Какую роль в контексте СХД играет микропрограмма (firmware) контроллера?
75. Что такое "неисправности конфигурации" и приведите один пример из лекции.
76. Какие внешние факторы, помимо отключения электричества, могут привести к повреждению СХД?
77. Что такое "логическая неисправность" и почему ее сложнее обнаружить, чем аппаратную?
78. Как ошибка администратора может привести к "расщеплению мозга" (Split-Brain) в кластере?
79. Какие превентивные меры можно принять для защиты от "тихих повреждений данных" (Silent Data Corruption)?
80. Почему при проектировании ИС процедуры сохранения и восстановления информации должны выделяться особо?
ЗАДАНИЯ К ЛЕКЦИИ:
Раздел: Архитектура СХД и выбор решений
1. Задание: Компания активно развивается, и ее файловое хранилище на базе NAS перестало справляться с нагрузкой от СУБД. При этом у компании есть значительные инвестиции в эту NAS-систему. Предложите гибридное архитектурное решение, которое позволит сохранить существующие инвестиции, но решить проблему производительности для критически важных баз данных. Обоснуйте каждый компонент вашего решения.
2. Задание: Вы — архитектор в крупном научном проекте. Ежедневно генерируется 50 ТБ неструктурированных данных (результаты экспериментов, изображения). Требуется долгосрочное (10+ лет), экономичное хранение с возможностью быстрого доступа к произвольным наборам данных для анализа. Какой тип хранилища (файловое, блочное, объектное) вы выберете и почему? Детально опишите архитектуру хранения и обоснуйте ее соответствие требованиям.
3. Задание: К вам обратился стартап с ограниченным бюджетом, который разрабатывает мобильное приложение для обмена видео. Они ожидают взрывной рост пользователей и данных. Им необходимо надежное, масштабируемое и не требующее больших первоначальных затрат хранилище. Облако vs on-premise? Какую облачную модель (IaaS, PaaS, SaaS) для СХД вы порекомендуете и почему? Распишите плюсы и минусы каждого варианта для данного кейса.
4. Задание: В компании используется SAN на базе Fibre Channel. После модернизации сети часть серверов была перенесена в новый ЦОД, физически удаленный на 50 км. Инженеры столкнулись с неприемлемо высокой латентностью при доступе к SAN. В чем фундаментальная причина проблемы? Какие технологии или изменения в архитектуре СХД вы предложите для решения этой задачи?
5. Задание: Ваша компания купила мощную SSD-систему для высокопроизводительной базы данных, но производительность оказалась ниже ожидаемой. Анализ показал, что сетевые адаптеры на серверах являются узким местом (1 GbE). Какие конкретные действия вы предпримете для устранения этого "бутылочного горлышка"? Укажите конкретные технологии (например, 25 GbE, NVMe over Fabrics) и обоснуйте их выбор.
Раздел: Неисправности и диагностика
6. Задание: Сервер баз данных начал "зависать" на 30-60 секунд с периодичностью раз в несколько часов. При этом мониторинг CPU, RAM и дискового пространства не показывает аномалий. Сформулируйте гипотезы о возможных "скрытых" причинах и опишите пошаговый план углубленной диагностики, который позволит найти корневую причину.
7. Задание: После планового обновления прошивки (firmware) на контроллере дискового массива несколько виртуальных машин начали испытывать критические падения производительности ввода-вывода. Ваши действия по локализации и устранению проблемы? Предположите, в чем может быть причина, и как вы будете проверять каждую гипотезу.
8. Задание: Вы обнаружили, что на файловом сервере с RAID 6 повреждены несколько файлов. При этом сам массив и контроллер не сообщают об ошибках. Это проявление "тихого повреждения данных" (Silent Data Corruption). Каковы возможные причины на уровне аппаратного и программного обеспечения? Какие превентивные меры можно было принять?
9. Задание: В кластерной системе с синхронной репликацией между двумя дата-центрами произошел обрыв канала связи. Возникла ситуация "расщепления мозга" (Split-Brain). Опишите последовательность действий администратора по восстановлению консистентности данных после восстановления связи. Какие решения должны быть приняты на уровне бизнеса для определения приоритетного центра?
10. Задание: Пользователи жалуются на медленную работу приложения. Вы обнаружили, что нагрузка на дисковую подсистему (IOPS) близка к максимальной. Проанализируйте, какие факторы (уровень RAID, размер страйпа, тип нагрузки — чтение/запись) влияют на производительность, и предложите конкретные шаги по оптимизации без немедленной покупки нового оборудования.
Раздел: RPO, RTO и стратегия восстановления
11. Задание: Бизнес-заказчик утверждает, что для его системы RPO должен быть равен 0, а RTO — не более 15 минут. Техническая команда заявляет, что это невыполнимо или чрезмерно дорого. Какие вопросы вы зададите бизнесу, чтобы обоснованно снизить эти требования или найти компромиссное техническое решение? Приведите примеры таких вопросов.
12. Задание: У вас есть три критических сервиса: 1) Интернет-магазин (RTO=5 мин, RPO=1 мин), 2) Внутренняя система документооборота (RTO=4 часа, RPO=24 часа), 3) Аналитическая BI-система (RTO=1 день, RPO=1 неделя). Опишите, как будет принципиально отличаться архитектура резервного копирования и восстановления для каждого из этих сервисов. Какие технологии (снэпшоты, репликация, традиционные бэкапы) будут использованы в каждом случае?
13. Задание: В результате сбоя была потеряна база данных, и восстановление из последней резервной копии заняло 2 часа (RTO=2h). Однако бизнес-процессы не могли работать еще 6 часов после этого. Объясните, почему RTO системы может не совпадать с RTO бизнес-процесса? Какие дополнительные факторы влияют на восстановление бизнеса, а не только ИТ-системы?
14. Задание: Ваша система резервного копирования успешно создает бэкапы каждую ночь. Во время плановой проверки вы обнаружили, что время восстановления полной копии базы данных составляет 8 часов, что неприемлемо для бизнеса (RTO=1 час). Какие стратегии и технологии вы примените, чтобы сократить время восстановления, не меняя кардинально аппаратную платформу?
15. Задание: Произошла масштабная ransomware-атака. Зашифрованы как производственные данные, так и часть локальных резервных копий. Однако у вас есть "неизменяемые" (immutable) снапшоты в облаке и ленты, отключенные от сети (air-gapped). Опишите пошаговый план действий в этой ситуации, учитывая, что атакующий мог находиться в системе несколько недель.
Раздел: Транзакции, журналирование и откаты
16.
Задание: Программист по ошибке запустил на производственной
базе данных скрипт с UPDATE без
условия WHERE,
что затронуло миллионы записей. Операция не была завершена и "висит"
уже 30 минут. Опишите возможные сценарии действий администратора СУБД с учетом
свойства долговечности (Durability) транзакций. Как минимизировать ущерб?
17. Задание: Системный администратор, пытаясь освободить место, удалил старый файл журнала транзакций (transaction log) базы данных. После этого СУБД отказалась запускаться. Объясните, почему удаление файла журнала привело к такой серьезной проблеме. Как теперь восстановить работоспособность системы, если полная резервная копия базы данных есть?
18. Задание: В СУБД настроено полное журналирование. Журнал транзакций растет с огромной скоростью и заполняет весь диск. Каковы могут быть причины этого? Предложите несколько решений: одно — экстренное, чтобы предотвратить остановку системы, и два — долгосрочных, чтобы проблема не повторялась.
19. Задание: После жесткого сбоя (отказа диска) у вас есть вчерашняя полная резервная копия БД и актуальный журнал транзакций. Опишите детальный процесс восстановления, который гарантирует, что будут восстановлены все зафиксированные транзакции вплоть до момента сбоя, и не будет восстановлены незафиксированные.
20. Задание: Разработана новая функция для приложения, которая должна выполнять сложную многошаговую операцию (например, перевод денег между счетами). Объясните разработчику, почему всю операцию необходимо оформлять в виде одной транзакции, а не серии независимых запросов. Используйте в объяснении свойства ACID.
Раздел: Восстановление поврежденных БД (на основе кейса с "Планировщиком")
21.
Задание: "Планировщик резервного копирования"
завершил операцию "Профилактика БД" (Backup/Restore) с ошибкой на
этапе Restore. При этом файл docpoint2.gdb был
удален, а файл docpoint2.__b не
создан. Опишите ваши действия по диагностике и восстановлению работоспособности
системы вручную, используя знания о структуре FireBird.
22.
Задание: Пользователи сообщают об ошибках "некорректная
сумма" в финансовых документах. Есть подозрение на логическое повреждение
данных (например, сбой в триггере, который должен был пересчитывать сумму).
Целостность структур БД при проверке утилитой gfix не
нарушена. Как вы будете искать и исправлять такие ошибки? Можно ли использовать
для этого стандартные механизмы СУБД?
23.
Задание: База данных после сбоя питания не открывается.
Стандартная утилита gfix не
может ее восстановить. У вас есть резервная копия недельной давности и
папка BODY_LOG с
файлами, которые скопировали сразу после сбоя. Разработайте стратегию восстановления,
которая позволит спасти максимум данных, созданных после резервной копии.
24. Задание: Вы обнаружили, что размер базы данных после проведения "Профилактики" не уменьшился, а увеличился. Каковы возможные причины этого парадоксального поведения? Проанализируйте, что могло пойти не так в процессе Backup/Restore.
25. Задание: Вам необходимо спроектировать расписание для "Планировщика" для высоконагруженной системы, где простои недопустимы. Какие функции (Резервное копирование, Профилактика, Починка) и с какой периодичностью вы будете выполнять? Обоснуйте свой выбор, учитывая нагрузку на систему и время выполнения каждой операции.
Раздел: Комплексные и критические сценарии
26. Задание: Во время плановой замены диска в массиве RAID 5 администратор по ошибке извлек не тот диск. Массив разрушился. Последняя резервная копия — 24 часа назад. Опишите порядок действий: технических, коммуникационных с бизнесом и по расследованию инцидента.
27. Задание: Вы подозреваете, что проблема с "зависаниями" СУБД связана с конфликтом антивирусного ПО и драйверов файловой системы. Разработайте план безопасного тестирования этой гипотезы на production-сервере с минимальным риском для пользователей.
28. Задание: Критический сервер приложений работает в виртуальной машине. Его диск (VMDK) расположен на SAN. Физический диск в SAN вышел из строя, данные утеряны. У вас есть снапшот этой ВМ, сделанный на уровне гипервизора 2 часа назад. Опишите процесс восстановления. Будет ли этого снапшота достаточно для полного восстановления консистентности состояния приложения? Почему?
29. Задание: После миграции базы данных на новый сервер начали возникать случайные ошибки целостности данных. Все оборудование нового сервера проходит диагностику без замечаний. Какие менее очевидные причины (например, настройки BIOS, параметры ОС, версии драйверов) могут вызывать такую проблему?
30. Задание: Разработайте чек-лист для проведения плановых работ по замене аппаратных компонентов СХД (например, контроллера), который гарантирует, что после замены не произойдет потери данных или нарушения целостности.
31. Задание: В компании внедряется политика "3-2-1" для бэкапов. Объясните, что это значит, и спроектируйте конкретную реализацию этой политики для вашей основной базы данных, используя комбинацию локального хранилища, ленточных библиотек и облачного провайдера.
32. Задание: Вы обнаружили, что злоумышленник получил доступ к системе резервного копирования и имеет возможность удалять бэкапы. Какие меры безопасности (технические и процедурные) необходимо срочно принять для защиты "последнего рубежа обороны"?
33. Задание: Приложение, работающее с базой данных, было аварийно остановлено. При перезапуске выяснилось, что таблица базы данных содержит записи, которые были только частично обновлены. Объясните, какое свойство транзакций было нарушено и как механизм восстановления СУБД должен обработать эту ситуацию при следующем запуске.
34. Задание: Вас вызвали на место, где сервер базы данных не загружается. Вы обнаружили, что файлы базы данных физически присутствуют на диске, но СУБД "не видит" их. Сформулируйте гипотезы о причинах и опишите, какие системные структуры (MBR/GPT, загрузочные записи файловой системы) необходимо проверить в первую очередь.
35. Задание: Для базы данных, которая работает в режиме 24/7, установлено RPO=5 минут. Какая технология резервного копирования (полные, инкрементальные, дифференциальные бэкапы, снапшоты, непрерывная репликация) будет основной в вашей стратегии и почему? Скомбинируйте несколько технологий в единый рабочий процесс.
36. Задание: После обновления СУБД восстановление из резервной копии, сделанной на предыдущей версии, завершается с ошибкой несовместимости. Ваши действия? Как должна быть выстроена процедура обновления СУБД, чтобы избежать такой ситуации в будущем?
37. Задание: В целях экономии было принято решение хранить резервные копии на медленных SATA-дисках. При попытке восстановления выяснилось, что RTO превышает допустимое в 4 раза. Предложите решение, которое позволит ускорить восстановление, не перенося все бэкапы на быстрые SSD.
38. Задание: Проанализируйте, как наличие "потерянных страниц" (orphan pages) в файле БД может в долгосрочной перспективе повлиять на производительность и надежность системы, даже если сейчас это не вызывает явных сбоев.
39. Задание: При мониторинге вы заметили, что операция "Удаление документов по указанную дату" выполняется аномально долго и блокирует работу пользователей. Какие оптимизации (например, создание индексов, разбиение на пакеты) вы можете предложить для этой процедуры?
40. Задание: Сформулируйте сценарий полномасштабной тренировки по аварийному восстановлению (Disaster Recovery Drill) для вашего ЦОД. Опишите, какие системы будут затронуты, как будет моделироваться авария, какие команды будут задействованы и по каким критериям будет оцениваться успешность тренировки.
Раздел: Архитектура и модели хранения
41. Задание: Компания использует DAS-систему для хранения финансовых данных. С переходом на удаленную работу сотрудникам потребовался доступ к файлам из дома. Предложите поэтапный план миграции с DAS на систему, позволяющую организовать безопасный удаленный доступ, сохранив высокую производительность для бухгалтерских приложений.
42. Задание: Объясните, в чем разница между горизонтальным и вертикальным масштабированием в контексте СХД. Для какого типа нагрузок (OLTP, OLAP) предпочтительнее каждый из подходов и почему?
43. Задание: Спроектируйте гибридную систему хранения для веб-студии, где необходимо одновременно хранить большие объемы архивного видео (холодные данные) и активно работать с текущими проектами (горячие данные). Опишите, как будет организовано автоматическое перемещение данных между уровнями хранения.
44. Задание: Выберите и обоснуйте тип хранилища (блочное, файловое, объектное) для системы IoT, которая принимает миллионы мелких сообщений от датчиков ежедневно. Ключевые требования: низкая стоимость хранения и возможность потоковой аналитики.
45. Задание: Компания решила отказаться от физических NAS в пользу облачного файлового сервиса (например, Amazon EFS). Опишите потенциальные риски такого перехода и подготовьте чек-лист для их минимизации.
Раздел: Надежность, отказоустойчивость и производительность
46. Задание: На диаграмме лекции изображена сложная структура СХД. Проанализируйте ее и предложите, как можно добавить в эту архитектуру второй контроллер для повышения отказоустойчивости. Опишите, что произойдет при отказе одного из контроллеров.
47. Задание: Рассчитайте эффективный объем полезной памяти для массива RAID 60, состоящего из 8 дисков по 4 ТБ каждый. Объясните, почему такой уровень RAID может быть выбран для высоконагруженной базы данных.
48. Задание: В системе с кэш-памятью на контроллере произошел сбой питания, и данные из кэша не успели записаться на диски. Какие механизмы защиты от потери данных должны быть предусмотрены в СХД, чтобы предотвратить эту проблему? Опишите принцип их работы.
49. Задание: Проанализируйте, как неправильно подобранный размер страйпа (stripe size) в RAID-массиве может негативно сказаться на производительности при работе с небольшими файлами и с большими последовательными потоками данных.
50. Задание: Предложите архитектурное решение для СХД, которое обеспечит непрерывную работу приложения даже в случае полного выхода из строя одного из дата-центров. Опишите все необходимые компоненты и принципы их взаимодействия.
Раздел: Резервное копирование и стратегии восстановления
51. Задание: Разработайте политику резервного копирования для университета, где необходимо ежедневно сохранять данные студенческих работ, но иметь возможность восстановить состояние системы на конец каждой сессии (раз в полгода). Используйте комбинацию полных, инкрементальных и дифференциальных бэкапов.
52. Задание: Объясните, чем отличается аварийное восстановление (Disaster Recovery) от восстановления данных (Data Restore). Приведите по два примера ситуаций, когда требуется каждая из этих процедур.
53. Задание: Вам необходимо добиться RPO ≈ 0 для критической базы данных. Какая технология резервного копирования будет основной в вашей стратегии? Опишите ее принцип работы и технические требования для реализации.
54. Задание: Сравните технологию моментальных снимков (snapshots) и традиционного резервного копирования (backup) по следующим параметрам: скорость создания, влияние на производительность, занимаемое место, скорость восстановления.
55. Задание: Спроектируйте схему хранения резервных копий по правилу «3-2-1» для базы данных объемом 10 ТБ. Укажите типы носителей (SSD, HDD, лента, облако) и их расположение.
Раздел: Транзакции и журналирование в СУБД
56. Задание: Опишите последовательность записей в журнале транзакций для простой операции «Перевод денег со счета А на счет Б». Включите в описание отметки о начале и фиксации транзакции.
57. Задание: Что произойдет, если в процессе выполнения длительной транзакции, обновляющей миллионы строк, произойдет «мягкий сбой» (например, перезагрузка сервера)? Как СУБД обеспечит свойство атомарности в этой ситуации?
58. Задание: Объясните, почему высокая степень изоляции транзакций (например, Serializable) может приводить к снижению общей производительности системы и возникновению взаимоблокировок (deadlocks).
59. Задание: Настройки СУБД требуют, чтобы журнал транзакций и файлы базы данных находились на разных физических дисках. С технической точки зрения, зачем это сделано и что произойдет, если этим требованием пренебречь?
60. Задание: Сравните механизм восстановления после сбоя с использованием UNDO- и REDO-записей в журнале транзакций. В каких сценариях используются каждый из них?
Раздел: Диагностика и устранение неисправностей
61. Задание: Дисковая подсистема сервера внезапно показывает пики latency раз в несколько часов. Составьте план диагностики, который позволит определить, связано ли это с проблемами на уровне физических дисков, контроллера RAID, операционной системы или сетевого подключения (если речь о SAN/NAS).
62. Задание: Вы обнаружили, что виртуальная машина работает крайне медленно, при этом гипервизор показывает высокую нагрузку на дисковую подсистему. Какие инструменты и метрики (IOPS, throughput, latency) вы будете использовать, чтобы локализовать проблему: гостевая ОС ВМ, настройки виртуального диска или физическая СХД?
63. Задание: Опишите пошаговый алгоритм действий администратора при обнаружении «тихого повреждения данных» (Silent Data Corruption) в файле на файловом сервере. Какие инструменты и резервные копии будут задействованы?
64. Задание: После обновления драйверов сетевого адаптера в SAN-сети несколько серверов потеряли доступ к хранилищу. Ваши гипотезы и план быстрого отката изменений для восстановления работоспособности.
65. Задание: Разработайте чек-лист ежедневного профилактического осмотра СХД, который позволит выявить потенциальные проблемы на ранней стадии (например, предупреждения SMART дисков, перегрев компонентов, заполнение места в журналах).
Раздел: Безопасность данных
66. Задание: Какие меры защиты данных на уровне СХД вы предложите для выполнения требований регулятора (например, ФЗ-152)? Рассмотрите шифрование, контроль доступа и мониторинг.
67. Задание: Опишите сценарий, при котором злоумышленник, получивший доступ к системе управления СХД, может нанести максимальный ущерб данным, даже не взламывая отдельные серверы. Какие меры помогут предотвратить такой сценарий?
68. Задание: Почему резервные копии также должны быть защищены от ransomware-атак? Предложите три метода защиты бэкапов от шифрования или удаления злоумышленниками.
69. Задание: Объясните, как технология моментальных снимков (snapshots) может быть использована не только для восстановления, но и для расследования инцидента информационной безопасности.
70. Задание: Что такое WORM-хранилище (Write Once Read Many) и в каких отраслях или для каких типов данных его использование является критически важным с точки зрения compliance?
Раздел: Оптимизация и планирование
71. Задание: Проанализируйте, какой тип нагрузки (random read, random write, sequential read, sequential write) создают следующие приложения: 1) Сервер виртуализации; 2) Веб-сервер с статическим контентом; 3) Система видеомонтажа; 4) OLTP-база данных.
72. Задание: Рассчитайте необходимый объем хранилища для системы резервного копирования на год вперед. Исходные данные: объем данных для бэкапа — 5 ТБ, ежедневное изменение — 5%, политика хранения: ежемесячные полные копии — 12 месяцев, ежедневные инкрементальные — 30 дней.
73. Задание: Предложите стратегию дедупликации данных для виртуальной инфраструктуры, где развернуто 100 виртуальных машин с однотипными ОС. На каком уровне (источник, цель) ее эффективнее применять и почему?
74. Задание: Сравните затраты на владение (TCO) для облачного объектного хранилища и для системы on-premise на основе HDD-дисков для архива в 1 ПБ данных на срок 5 лет.
75. Задание: Спроектируйте расписание для «Планировщика резервного копирования», которое минимизирует влияние на производительность основной базы данных в рабочее время. Укажите, какие операции и в какое время должны выполняться.
Раздел: Комплексные сценарии
76. Задание: Опишите процедуру плановой замены вышедшего из строя диска в работающем массиве RAID 5. Какие проверки необходимо выполнить до, во время и после замены?
77. Задание: В результате ошибки скрипта в производственной базе данных удалилась важная таблица. У вас есть полная вчерашняя копия и журналы транзакций за сегодня. Опишите процесс восстановления только этой таблицы с минимальной потерей данных.
78. Задание: Во время миграции данных в новое облачное хранилище произошел обрыв сети, и процесс прервался. Как обеспечить консистентность данных и продолжить миграцию с точки прерывания, не начиная сначала?
79. Задание: Разработайте сценарий учебной тревоги (Disaster Recovery Drill) для отработки восстановления почтового сервера после виртуального «пожара» в основном ЦОД. Опишите роли команды, критерии успеха и последовательность действий.
80. Задание: Сформулируйте техническое задание на выбор новой СХД для растущей компании. Включите в него не менее 10 ключевых требований к производительности, надежности, масштабируемости и совместимости.
Скачано с www.znanio.ru





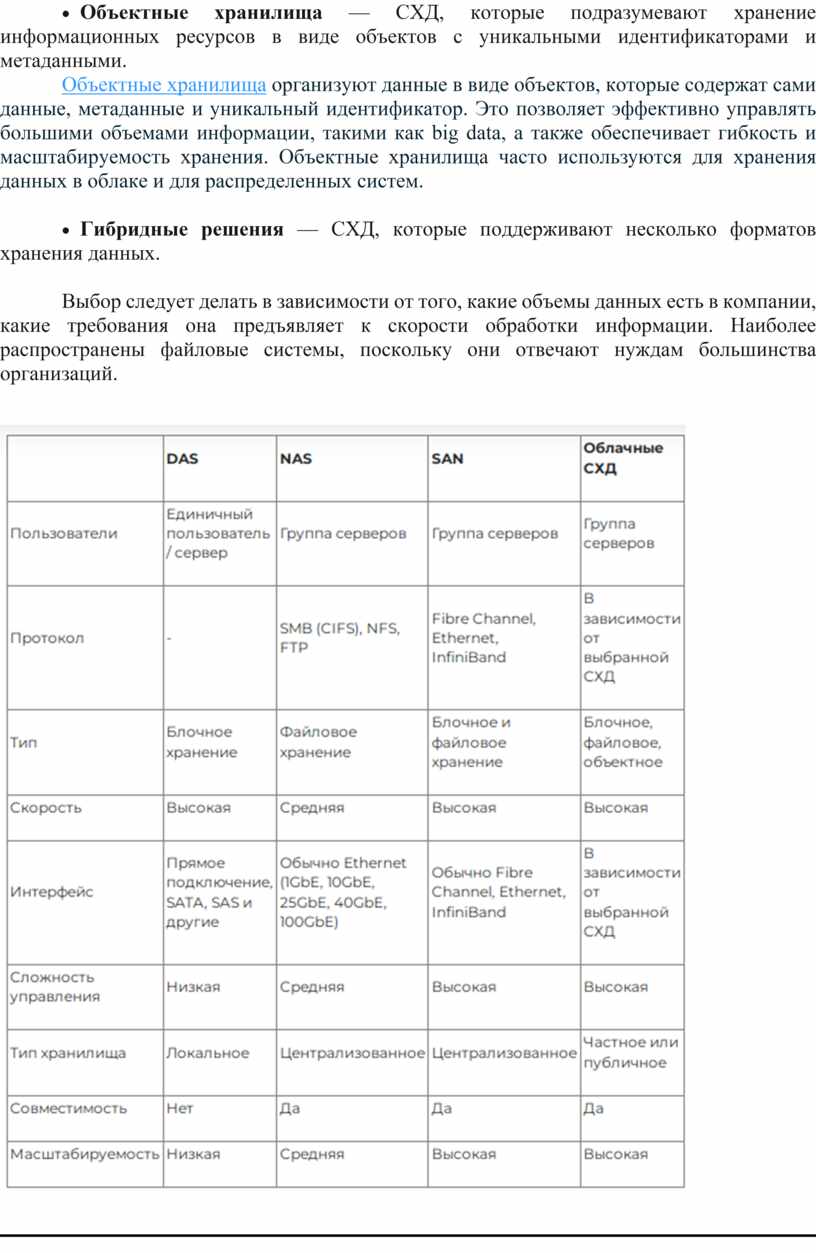
























Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.