Поделиться

ЗАДАНИЕ
Для дистанционного обучения
Группа ТО-102
17.09.2021 первая пара
Тема лекции «Кодирование информации»
Кодирование информации — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
В процессах восприятия, передачи и хранения информации живыми организмами, человеком и техническими устройствами происходит кодирование информации. В этом случае информация, представленная в одной знаковой системе, преобразуется в другую.
При кодировании каждый символ исходного алфавита представляется конечной последовательностью символов кодового алфавита. Эта результирующая последовательность называется информационным кодом (кодовым словом, или просто кодом).
Примерами кодов являются последовательность букв в тексте, цифр в числе, двоичный компьютерный код и др.
Код состоит из определенного количества знаков (имеет определенную длину), которое называется длиной кода.
Например, текстовое сообщение состоит из определенного количества букв, число — из определенного количества цифр. Преобразование знаков или групп знаков одной знаковой системы в знаки или группы знаков другой знаковой системы называется перекодированием. При кодировании один символ исходного сообщения может заменяться одним или несколькими символами нового кода, и наоборот — несколько символов исходного сообщения могут быть заменены одним символом в новом коде.
Примером такой замены служат китайские иероглифы, которые обозначают целые слова и понятия. Кодирование может быть равномерным и неравномерным.
При равномерном кодировании все символы заменяются кодами равной длины; при неравномерном кодировании разные символы могут кодироваться кодами разной длины (это затрудняет декодирование). Неравномерный код называют еще кодом переменной длины.
Примером неравномерного кодирования является код азбуки Морзе. Длительное время он использовался для передачи сообщений по телеграфу. Кодовый алфавит включал точку, тире и паузу. При передаче по телеграфу точка означала кратковременный сигнал, тире — сигнал в 3 раза длиннее. Между сигналами букв одного слова делалась пауза длительностью одной точки, между словами — длительностью трех точек, между предложениями — длительностью семи точек. Вначале код Морзе был создан для букв английского алфавита, цифр и знаков препинания. Принцип этого кода заключался в том, что часто встречающиеся буквы кодировались более простыми сочетаниями точек и тире. Это делало код компактным. Позже код был разработан и для символов других алфавитов, включая русский. Коды Морзе для некоторых букв. Чтобы избежать неоднозначности, код Морзе включает также паузы между кодами разных символов. Декодирование информации
■ Декодирование — обратный процесс восстановления информации из закодированного представления.
В зависимости от системы кодирования информационный код может или не может быть декодирован однозначно.
Равномерные коды всегда могут быть декодированы однозначно. Для однозначного декодирования неравномерного кода важно, имеются ли в нем кодовые слова, которые являются одновременно началом других, более длинных кодовых слов.
Закодированное сообщение можно однозначно декодировать с начала, если выполняется условие Фано: никакое кодовое слово не является началом другого кодового слова. Закодированное сообщение можно однозначно декодировать с конца, если выполняется обратное условие Фано: никакое кодовое слово не является окончанием другого кодового слова.
Неравномерные коды, для которых выполняется условие Фано, называются префиксными. Префиксный код — такой неравномерный код, в котором ни одно кодовое слово не является началом другого, более длинного слова. В таком случае кодовые слова можно записывать друг за другом без разделительного символа между ними. Например, код Морзе не является префиксным — для него не выполняется условие Фано. Поэтому в кодовый алфавит Морзе, кроме точки и тире, входит также символ–разделитель — пауза длиной в тире. Без разделителя однозначно декодировать код Морзе в общем случае нельзя.
Кодирование русских и латинских букв заключается в том, что каждому символу ставится в соответствие уникальный десятичный код от 0 до 255 или соответствующий ему двоичный код от 00000000 до 11111111. Таким образом, человек различает символы по их начертанию, а компьютер - по их коду.
Виды таблиц кодировок
Таблица, в которой всем символам компьютерного алфавита поставлены в соответствие порядковые номера, называется таблицей кодировки.
Для разных типов ЭВМ используются различные таблицы кодировки.
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange - Американский стандартный код для информационного обмена), кодирующая первую половину символов с числовыми кодами от 0 до 127 ( коды от 0 до 32 отведены не символам, а функциональным клавишам).
Таблица кодов ASCII делится на две части.
Международным стандартом является лишь первая половина таблицы, т.е. символы с номерами от 0 (00000000), до 127 (01111111).
Структура таблицы кодировки ASCII
|
Порядковый номер |
Код |
Символ |
|
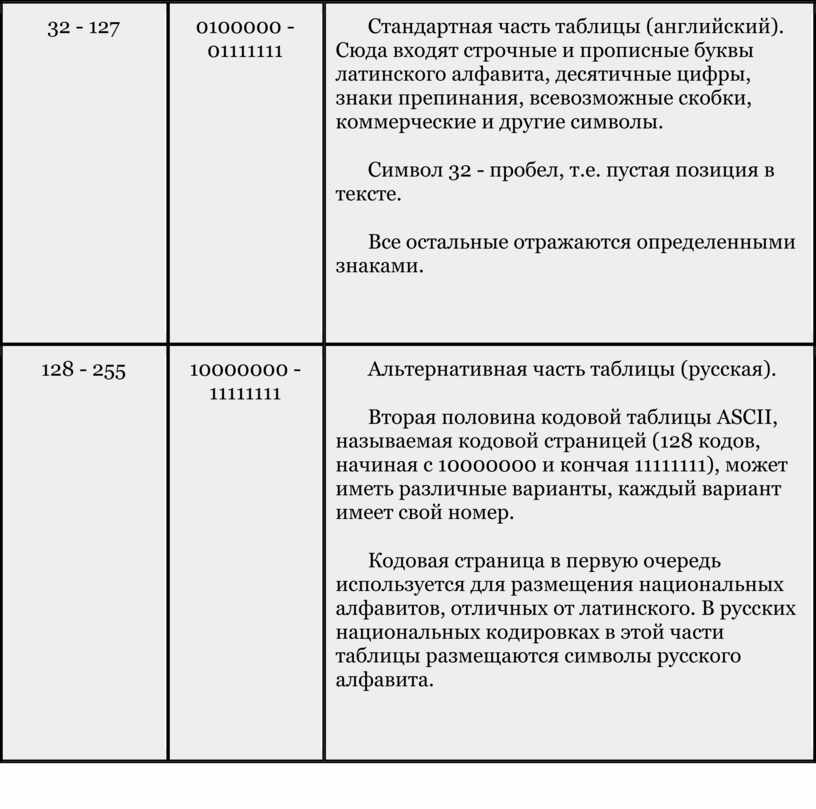
0 - 31 |
00000000 - 00011111 |
Символы с номерами от 0 до 31 принято называть управляющими. Их функция – управление процессом вывода текста на экран или печать, подача звукового сигнала, разметка текста и т.п. |
|
32 - 127 |
0100000 - 01111111 |
Стандартная часть таблицы (английский). Сюда входят строчные и прописные буквы латинского алфавита, десятичные цифры, знаки препинания, всевозможные скобки, коммерческие и другие символы. Символ 32 - пробел, т.е. пустая позиция в тексте. Все остальные отражаются определенными знаками. |
|
128 - 255 |
10000000 - 11111111 |
Альтернативная часть таблицы (русская). Вторая половина кодовой таблицы ASCII, называемая кодовой страницей (128 кодов, начиная с 10000000 и кончая 11111111), может иметь различные варианты, каждый вариант имеет свой номер. Кодовая страница в первую очередь используется для размещения национальных алфавитов, отличных от латинского. В русских национальных кодировках в этой части таблицы размещаются символы русского алфавита. |
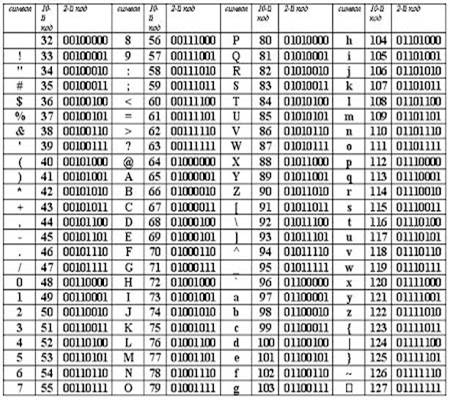
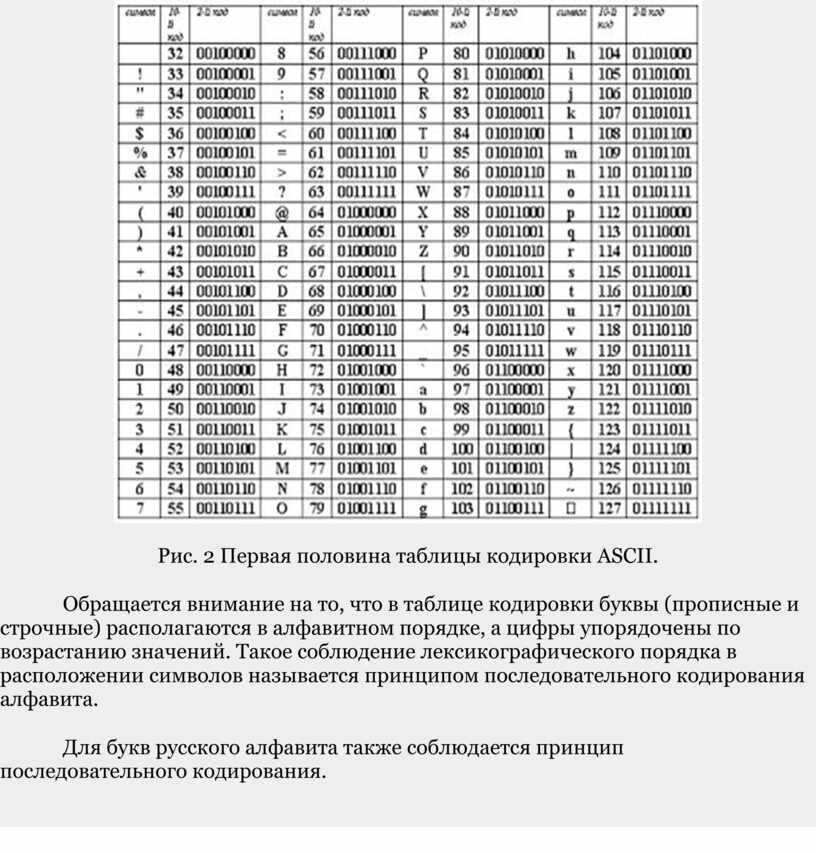
Рис. 2 Первая половина таблицы кодировки ASCII.
Обращается внимание на то, что в таблице кодировки буквы (прописные и строчные) располагаются в алфавитном порядке, а цифры упорядочены по возрастанию значений. Такое соблюдение лексикографического порядка в расположении символов называется принципом последовательного кодирования алфавита.
Для букв русского алфавита также соблюдается принцип последовательного кодирования.
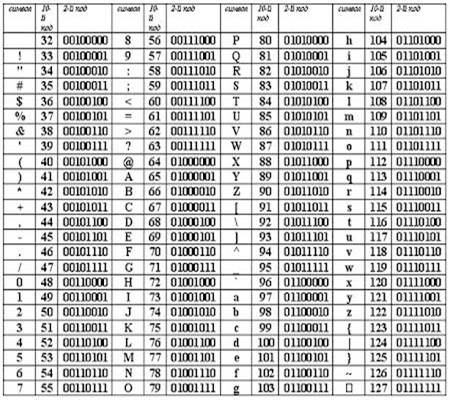
Рис.3 Вторая половина таблицы кодировки ASCII.
Внутреннее представление слов в памяти компьютера
с помощью таблицы ASCII
|
Слова |
Память |
|
file |
01100110 01101001 01101100 01100101 |
|
disk |
01100100 01101001 01110011 01101011 |
Задание
1. Прочитайте конспект лекции.
2. Выпишите в рабочую тетрадь по информатике текст выделенный красным цветом.
3. Закодируйте в таблице ASCII свою фамилию.
4. Закодируйте в таблице ASCII своё имя записанное латинскими буквами.
5. Скачано с www.znanio.ru





Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.