Поделиться

Архитектура компьютера. Физические основы функционирования компьютера. Структура современного компьютера. Ассемблер. Программирование типовых управляющих структур.
Архитектура компьютера – это его устройство и принципы взаимодействия его основных элементов – логических узлов, среди которых основными являются процессор, внутренняя память (основная и оперативная), внешняя память и устройства ввода-вывода информации (периферийные) (Рис. 1).
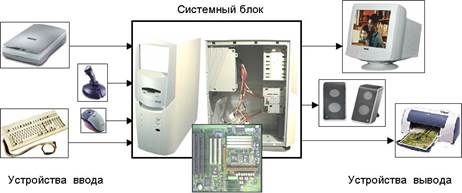
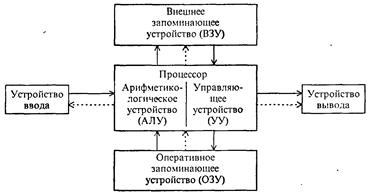
Рис. 1. Условная модель структуры архитектуры ЭВМ (Источник)
Физические основы функционирования
В основе работы запоминающего устройства может лежать любой физический эффект, обеспечивающий приведение системы к двум или более устойчивым состояниям. В современной компьютерной технике часто используются физические свойства полупроводников, когда прохождение тока через полупроводник или его отсутствие трактуются как наличие логических сигналов 0 или 1. Устойчивые состояния, определяемые направлением намагниченности, позволяют использовать для хранения данных разнообразные магнитные материалы. Наличие или отсутствие заряда в конденсаторе также может быть положено в основу системы хранения. Отражение или рассеяние света от поверхности CD, DVD или Blu-ray-диска также позволяет хранить информацию.
Структура компьютера — это некоторая модель, устанавливающая состав, порядок и принципы взаимодействия входящих в нее компонентов.
Персональный компьютер — это настольная или переносная ЭВМ, удовлетворяющая требованиям общедоступности и универсальности применения.
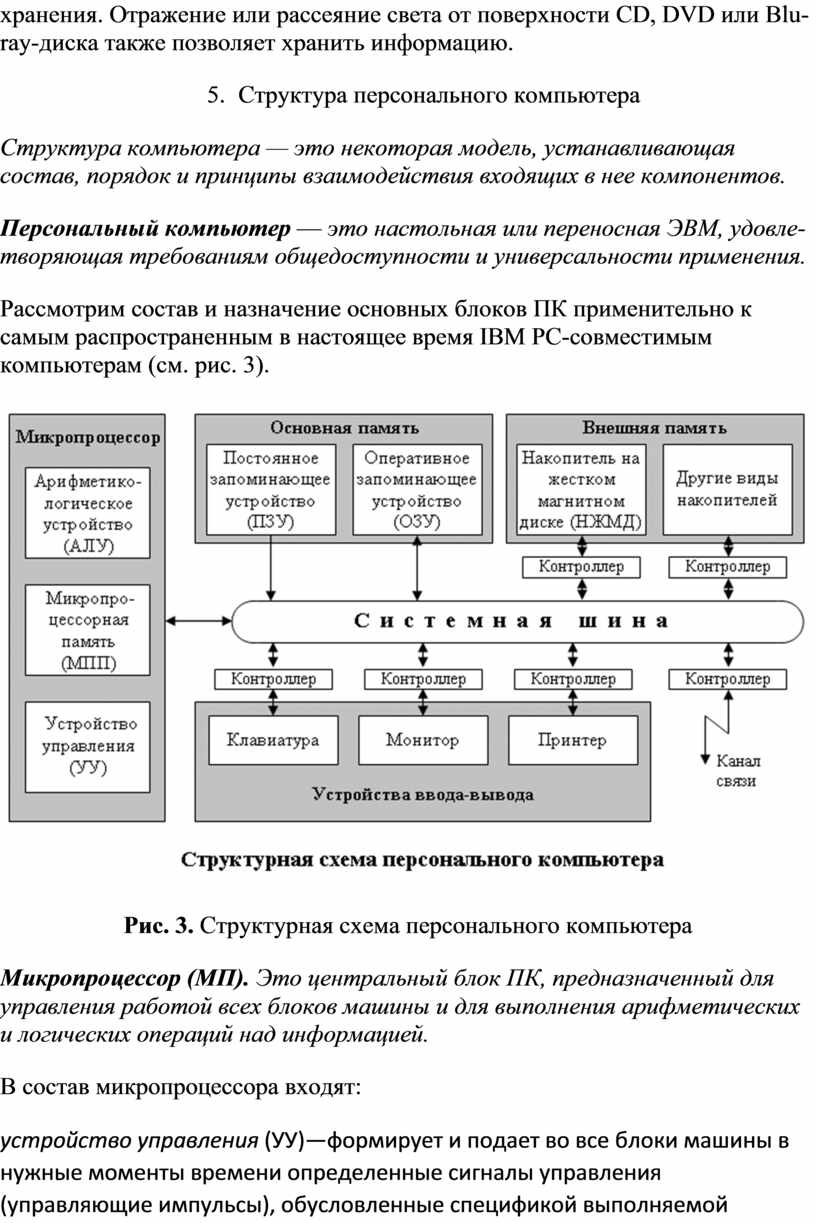
Рассмотрим состав и назначение основных блоков ПК применительно к самым распространенным в настоящее время IBM PC-совместимым компьютерам (см. рис. 3).
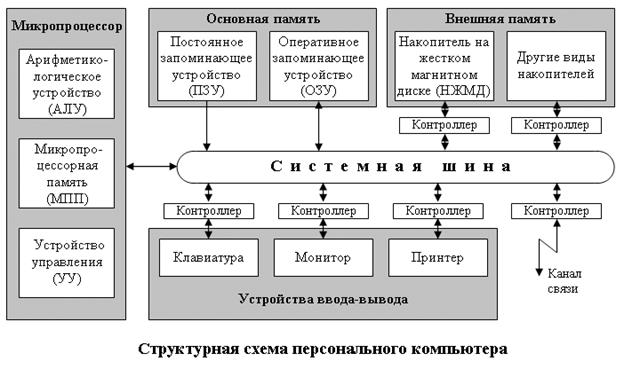
Рис. 3. Структурная схема персонального компьютера
Микропроцессор (МП). Это центральный блок ПК, предназначенный для управления работой всех блоков машины и для выполнения арифметических и логических операций над информацией.
В состав микропроцессора входят:
· устройство управления (УУ)—формирует и подает во все блоки машины в нужные моменты времени определенные сигналы управления (управляющие импульсы), обусловленные спецификой выполняемой операции и результатами предыдущих операций; формирует адреса ячеек памяти, используемых выполняемой операцией, и передает эти адреса в соответствующие блоки ЭВМ; опорную последовательность импульсов устройство управления получает от генератора тактовых импульсов;
· арифметико-логическое устройство (АЛУ)—предназначено для выполнения всех арифметических и логических операций над числовой и символьной информацией (в некоторых моделях ПК для ускорения выполнения операций к АЛУ подключается дополнительный математический сопроцессор),
· микропроцессорная память (МПП) — служит для кратковременного хранения, записи и выдачи информации, непосредственно используемой в вычислениях в ближайшие такты работы машины. МПП строится на регистрах и используется для обеспечения высокого быстродействия машины, ибо основная память (ОП) не всегда обеспечивает скорость записи, поиска и считывания информации, необходимую для эффективной работы быстродействующего микропроцессора. Регистры — быстродействующие ячейки памяти различной длины (в отличие от ячеек ОП, имеющих стандартную длину 1 байт и более низкое быстродействие); Регистровая КЭШ-память — высокоскоростная память сравнительно большой емкости, являющаяся буфером между ОП и МП и позволяющая увеличить скорость выполнения операций. Регистры КЭШ-памяти недоступны для пользователя, отсюда и название КЭШ (Cache), в переводе с английского означает "тайник".
· интерфейсная система микропроцессора —реализует сопряжение и связь с другими устройствами ПК; включает в себя внутренний интерфейс МП, буферные запоминающие регистры и схемы управления портами ввода-вывода (ПВВ) и системной шиной. Интерфейс (interface) — совокупность средств сопряжения и связи устройств компьютера, обеспечивающая их эффективное взаимодействие. Порт ввода-вывода (I/O — Input/Output port) — аппаратура сопряжения, позволяющая подключить к микропроцессору другое устройство ПК.
Микропроцессор, иначе, центральный процессор — Central Processing Unit (CPU) — функционально законченное программно-управляемое устройство обработки информации, выполненное в виде одной или нескольких больших (БИС) или сверхбольших (СБИС) интегральных схем.
Для МП на БИС или СБИС характерны: простота производства (по единой технологии); низкая стоимость (при массовом производстве); малые габариты (пластина площадью несколько квадратных сантиметров или кубик со стороной несколько миллиметров); высокая надежность; малое потребление энергии. Микропроцессор выполняет следующие функции: чтение и дешифрацию команд из основной памяти; чтение данных из ОП и регистров адаптеров внешних устройств; прием и обработку запросов и команд от адаптеров на обслуживание ВУ; обработку данных и их запись в ОП и регистры адаптеров ВУ; выработку управляющих сигналов для всех прочих узлов и блоков ПК. Разрядность шины данных микропроцессора определяет разрядность ПК в целом.
В настоящее время выпускается несколько сотен различных микропроцессоров, но наиболее популярными и распространенными являются микропроцессоры фирмы Intel. Все микропроцессоры можно разделить на три группы:
· МП типа CISC (Complex Instruction Set Computing) с полным набором команд;
· МП типа RISC (Reduced Instruction Set Computing) с сокращенным набором команд;
· МП типа MISC (Minimum Instruction Set Computing) с минимальным набором команд и весьма высоким быстродействием (в настоящее время эти модели находятся в стадии разработки).
Большинство современных IBM PC-совместимых ПК типа используют МП типа CISС - 80586 (Р5) более известных по их товарной марке Рentiuт, которая запатентована фирмой Intel (МП 80586 других фирм имеют иные обозначения: К5 у фирмы AMD, M1 у фирмы Cyrix и др.).
Генератор тактовых импульсов. Он генерирует последовательность электрических импульсов; частота генерируемых импульсов определяет тактовую частоту машины.
Промежуток времени между соседними импульсами определяет время одного такта работы машины или просто такт работы машины,
Частота генератора тактовых импульсов является одной из основных характеристик персонального компьютера и во многом определяет скорость его работы, ибо каждая операция в машине выполняется за определенное количество тактов;
Системная шина. Это основная интерфейсная система компьютера, обеспечивающая сопряжение и связь всех его устройств между собой.
Системная шина обеспечивает три направления передачи информации:
1) между микропроцессором и основной памятью;
2) между микропроцессором и портами ввода-вывода внешних устройств;
3) между основной памятью и портами ввода-вывода внешних устройств (в режиме прямого доступа к памяти).
Основная память (ОП). Она предназначена для хранения и оперативного обмена информацией с прочими блоками машины. ОП содержит два вида запоминающих устройств: постоянное запоминающее устройство (ПЗУ) и оперативное запоминающее устройство (ОЗУ).
ПЗУ (ROM — Read-Only Memory) служит для хранения неизменяемой (постоянной) программной и справочной информации, позволяет оперативно только считывать хранящуюся в нем информацию (изменить информацию в ПЗУ нельзя).
Постоянное запоминающее устройство строится на основе установленных на материнской плате модулей (кассет) и используется для хранения неизменяемой информации: загрузочных программ операционной системы, программ тестирования устройств компьютера и некоторых драйверов базовой системы ввода-вывода (BIOS — Base Input-Output System) и др.
На современных ПК используются полупостоянные, перепрограммируемые запоминающие устройства— FLASH-память. Модули или карты FLASH-памяти могут устанавливаться прямо в разъемы материнской платы и имеют следующие параметры: емкость от 32 Кбайт до 4 Мбайт, время доступа по считыванию 0,06 мкс, время записи одного байта примерно 10 мкс.
Оперативное запоминающее устройство (RAM — Random Access Memory — память с произвольным доступом) предназначено для оперативной записи, хранения и считывания информации (программ и данных), непосредственно участвующей в вычислительном процессе, выполняемом ПК в текущий период времени.
Главными достоинствами оперативной памяти являются ее высокое быстродействие и возможность обращения к каждой ячейке памяти отдельно (прямой адресный доступ к ячейке). ОЗУ — энергозависимая память: при отключении напряжения питания информация, хранящаяся в ней, теряется. Основу ОЗУ составляют большие интегральные схемы, содержащие матрицы полупроводниковых запоминающих элементов (триггеров). Запоминающие элементы расположены на пересечении вертикальных и горизонтальных шин матрицы; запись и считывание информации осуществляются подачей электрических импульсов по тем шинам матрицы, которые соединены с элементами, принадлежащими выбранной ячейке памяти.
Конструктивно элементы оперативной памяти выполняются в виде отдельных микросхем типа DIP (Dual In-line Package — двухрядное расположение выводов) или в виде модулей памяти типа SIP (Single In-line Package — однорядное расположение выводов), или, что чаще, SIMM (Single In line Memory Module — модуль памяти с одноразрядным расположением выводов), DIMM (Double In line Memory Module — модуль памяти с двухразрядным расположением выводов). Модули DIMM имеют емкость 16, 32, 64, 128 или 256 Мбайт, с контролем и без контроля четности хранимых битов. На материнскую плату можно установить несколько (четыре и более) модулей памяти.
Каждая ячейка памяти имеет свой уникальный (отличный от всех других) адрес. Основная память имеет для ОЗУ и ПЗУ единое адресное пространство.
Адресное пространство определяет максимально возможное количество непосредственно адресуемых ячеек основной памяти.
Адресное пространство зависит от разрядности адресных шин, ибо максимальное количество разных адресов определяется разнообразием двоичных чисел, которые можно отобразить в n разрядах, т.е. адресное пространство равно 2n, где п — разрядность адреса.
Для ПК характерно стандартное распределение непосредственно адресуемой памяти между ОЗУ, ПЗУ и функционально ориентированной информацией.
Основная память компьютера делится на две логические области: непосредственно адресуемую память, занимающую первые 1024 Кбайта ячеек с адресами от 0 до 1024 Кбайт и расширенную память, доступ к ячейкам которой возможен при использовании специальных программ-драйверов.
Драйвер — специальная программа, управляющая работой памяти или внешними устройствами ЭВМ и организующая обмен информацией между МП, ОП и внешними устройствами ЭВМ.
Стандартной памятью (СМА — Conventional Memory Area) называется непосредственно адресуемая память в диапазоне от 0 до 640 Кбайт. Непосредственно адресуемая память в диапазоне адресов от 640 до 1024 Кбайт называется верхней памятью (UMA — Upper Memory Area). Верхняя память зарезервирована для памяти дисплея (видеопамяти) и постоянного запоминающего устройства. Однако обычно в ней остаются свободные участки — "окна", которые могут быть использованы при помощи диспетчера памяти в качестве оперативной памяти общего назначения.
Расширенная память — это память с адресами 1024 Кбайта и выше. Непосредственный доступ к этой памяти возможен только в защищенном режиме работы микропроцессора.
В реальном режиме имеются два способа доступа к этой памяти, но только при использовании драйверов:
· по спецификации XMS (эту память называют тогда ХМА — eXtended Memory Area),
· по спецификации EMS (память называют ЕМ — Expanded Memory).
Доступ к расширенной памяти согласно спецификации XMS (eXtended Memory Specification) организуется при использовании драйверов ХММ (eXtended Memory Manager). Часто эту память называют дополнительной, учитывая, что в первых моделях персональных компьютеров эта память размещалась на отдельных дополнительных платах, хотя термин Extended почти идентичен термину Expanded и более точно переводится как расширенный, увеличенный.
Спецификация EMS (Expanded Memory Specification) является более ранней. Согласно этой спецификации доступ реализуется путем отображения по мере необходимости отдельных полей Expanded Memory в определенную область верхней памяти. При этом хранится не обрабатываемая информация, а лишь адреса, обеспечивающие доступ к этой информации. Память, организуемая по спецификации EMS, носит название отображаемой, поэтому и сочетание слов Expanded Memory (ЕМ) часто переводят как отображаемая память. Для организации отображаемой памяти необходимо воспользоваться драйвером ЕММ386.ЕХЕ (Expanded Memory Manager) или пакетом управления памятью QEMM.
Расширенная память может быть использована главным образом для хранения данных и некоторых программ ОС. Часто расширенную память используют для организации виртуальных (электронных) дисков.
Исключение составляет небольшая 64-Кбайтная область памяти с адресами от 1024 до 1088 Кбайт (так называемая высокая память, иногда ее называют старшая: НМА — High Memory Area), которая может адресоваться и непосредственно при использовании драйвера HIMEM.SYS (High Memory Manager) в соответствии со спецификацией XMS. НМА обычно используется для хранения программ и данных операционной системы.
В современных ПК существует режим виртуальной адресации (virtual — кажущийся, воображаемый). Виртуальная адресация используется для увеличения предоставляемой программам оперативной памяти за счет отображения в части адресного пространства фрагмента внешней памяти.
Источник питания. Это блок, содержащий системы автономного и сетевого энергопитания ПК.
Таймер. Это внутримашинные электронные часы, обеспечивающие при необходимости автоматический съем текущего момента времени (год, месяц, часы, минуты, секунды и доли секунд). Таймер подключается к автономному источнику питания — аккумулятору и при отключении машины от сети продолжает работать.
Ассемблер -- это не язык программирования.
Это мнемоника команд процессора. Из этого следует что, сколько существует ISA,
только и различных ассемблеров.
В курсе рассматривается только архитектура x86, потому что она очень распространенная среди PC и появилась довольно давно, что дает возможность гарантировать работу кода на разных машинах.
Сначала мы рассмотрим x86(32 bit), потом x64 (x86-64 bit)
NB) x86 - reg-mem2, cisc
eax = [32bit] = [16bit]:ax (ax -- младшие 16 бит от eax, только для e*x регистров) ax = ah:al (только для *x)
Иногда не совсем понятно, почему существуют некоторые ограничения и почему некоторые команды предпочтительнее других. Это чаще всего происходит из-за неодинакового размера кода команды, который ограничен 15 байтами, поэтому пытаются экономить.
Регистры общего назначения (General Proposal)
Регистры букв важен только в метках
Замечание: лучше всего использовать регистры той битности, что и режим процессора.
Также есть eip (instruction
pointer) - в коде мы его не можем использовать. (почти)
EFLAGS - регистр, которые содержит
различные флаги.
ZF (zero flag)
-- нулевой результат вычисления.CF (carry
flag) -- знаковое переполнение результата.SF (sign
flag) -- знак результата.OF (overflow
flag) -- знак беззнакового переполнения.DF (direction
flag) -- нужен для особых команд.mov eax, ebx
mov al, ah
mov ax, [ebx]
mov [eax + ebx * 4], ebx
Что можно писать в скобках:
[base_register32
+ index_register32 * scale_factor + offset32]esp[base_register16
+ index_register16 + offset16]Замечание: Некоторые компиляторы, например
yasm, позволяют в скобках писать 5*eax.
Они это просто сконвертируют, к верхней схеме, если смогут.
Также иногда необходимо указать размер пересылаемых данных [byte, word, dword]:
mov dword [eax], 5
mov [eax], dword 5
xchg --
"swap". Между регистрами почти бесплатный, а по памяти --
дорогая, так как является блокирующей.bswap --
меняет порядок байт (endian)movsx/movzx --
меньшее в большее, первая заполняет знаковым битом, а вторая 0.lea (load
effective address) -- вычисляет адрес и записывает его в первые операнд.push/pop --
команды работы со стеком: положить и снять.pushad/pusha --
выгрузить все общие регистры на стек (8 штук); первая для 32битных, вторая
-- для 16битных регистров. Порядок, как указано выше.popad/popaa --
снять все регистры со стека. Но esp не запишется.jmp --
прыгает на указанный адрес, можно передавать регистр. (просто меняет eip)call --
вызывает функцию. То же самое, что jmp ...+ push eip.ret/ret const --
возврат из функции. То же самое, что pop eip. Вторая команда
дополнительно снимает const байт со стека, т. е. то же что pop eip + add esp, const.j__ --
условные переход на метку, в зависимости от состояние флагов. Нельзя
передавать регистр. Работает предсказание переходов.je labeljnae
labelcmov__ --
условная загрузка. Суффикс как выше. Не предсказывается.Практически все арифметически операции меняют флаги. Подробности в документации, или здесь
add/adc --
сложение/сложение + флаг переноса. (carry flag)sub/sbb --
вычитание/вычитание - флаг переноса.mul rx --
беззнаковое умножение.mul
r8 => ah:al = ah * r8mul
r16 => dx:ax = ax * r16mul
r32 => edx:eax = eax * r32imul --
знаковое умножениеimul reg =>
как вышеimul dst,
src =>
dst *= srcimul
dst, src, const => dst = src * constdiv/idiv
arg32 => edx:eax = (edx:eax / arg32):(edx:eax
% arg32) Если результат не влезет в
eax будет ошибка переполнения.cwd/cdq --
делает регистровую пару edx:eax/dx:ax, заполняя знаковым битом.inc/dec --
инкремент/декремент. Не меняет флаги.neg -
арифметическое отрицание.and/or/xor/not/andn --
побитовые логические операцииxor eax, eax --
обнуление eax, это стандартный способ обнуления. Занимает меньше кода, но
меняет флаги.cmp/test --
соответствует sub/and, но меняет только флаги. В сочетании с условными
переходами позволяет делать условные конструкции.cmp/test + j__ --
часто это одна реальная команда, поэтому не нужно их лишний раз
разделять.test eax,
eax --
стандартный способ проверки на 0.shr/shl --
логические сдвиги (заполнение нулям), sar/sal -- арифметические сдвиги
(заполнение знаковым битом при правом сдвиге, левый сдвиг равен
логическому.)shld/shrd --
сдвиги двойной точности. (Можно делить пару)shld reg1
reg2, const --
сдвиг, но потерянные биты беруться из reg2ror/rol --
циклический сдвигrcl --
циклический сдвиг следующей штуки: (..←[31..0]←[cf]←..)rcr --
циклические сдвиг следующей штуки: (..→[31..0]→[cf]→..)int{x} --
вызвать прерывание, x = 3 -- вывалиться в отладчик.nop --
ничего не делаетud2 -- команда,
которая гарантированно отсутствует.test eax, eax
jns L1neg eax
L1: % но лучше так (нет условных переходов):cdq
xor eax, edx
sub eax, edx
cdq
shr edx, 29
add eax, edx
sar eax, 3
if(eax == 5 && ebx < 3) {
X
} else { Y}cmp eax, 5
jne LE
cmp ebx, 3
jnb LE
Xjmp LX
LE: YLX:
do ... while(eax != 0);
Некоторые конструкции языков C/C++ существуют именно в таком виде, потому что так их можно эффективно реализовать.
L1: ...test eax, eax
jnz L1
while(eax != 0)
...jz L2
L1: ...cmp eax, 0
jnz L1
L2:
switch (eax) {
case 1: X break; case 3: case 4: Y case 6: Z}cmp eax, 6
ja LE
jmp dword [eax*4 + table]
L1: Xjmp LE
L2: YL3: ZLE:...section rdata
table dd LE, L1, LE, L2, L2, LE, L3
lea eax, [eax*4 + eax]
add eax, eax
TODO
section .text
Эти секции описывают свойства процесса. Не путать с сегментами! Они про адресацию.
При написание высокоуровнего кода мы этого почти не замечаем. Но если мы хотим написать код на ассемблере и вызвать его где-то еще, то важно знать как буду вызвать наш код, и как вызвать чужой код. Для этого существуют соглашения (которые можно подкрутить компиляторозависимыми ключами)
|
cdecl |
stdcall |
pascal |
fastcall |
|
|
Куда класть аргументы? |
stack |
stack |
stack |
reg\stack |
|
Порядок загрузки аргументов? |
c, b, a |
c, b, a |
a, b, c |
? |
|
Кто снимает аргументы? |
caller |
calling |
calling |
? |
|
Где возвращается заначение? |
edx:eax/eax/ax |
⬅️ |
⬅️ |
⬅️ |
|
Сохраняемые регистры |
ebx, ebp, esi, edi |
⬅️ |
⬅️ |
Замечание: Сохранять все регистры, также как
и не сохранять ничего -- дорого.
Пояснение: Пусть мы сохраняем все регистры:
тогда в начале тела функции нужно сохранить все регистры, которые мы хотим
использовать. Если мы не будет вообще сохранять регистры, то после вызова
внешней функции нельзя пользоваться значениями в регистрах, поэтому опять надо
все сохранять.
Компилятор генерирет специальный код: выделяет необходимое количество памяти под возвращаемое значение и передает его адрес в качестве нулевого аргумента. При чем выделять память под возвращаемое значение должен вызывающий код, так как память нужно освобождать ровно так, как она выделялась.
Это нужно для методов классов. Тут тоже
пытаются класть this в
нулевой аргумент. И поэтому порядок this и *result, если оба
необходимо передавать в аргументах, является implementation behavior.
printf("%s",
p) // cdeclpush p
push fstr
call printf
add esp, 8
...section .rdata
fstr: "%s", 0
int
f(int a, int b) {return a*2 + b;} // cdecl; stack = [ret][1st arg][2nd arg]...mov eax, [esp + 4]
add eax, eax
add eax, [eax + 8]
ret
В stdcall не возможно написать printf, так как это vararg-функция. Такие функции требуют:
· Конвенция вызова должна совпадать с конвенцией фукнции. Но это неважно для локальных фукнций, которые никто не будет вызвать, кроме вас.
·
если мы хотим
сделать рефакторинг кода на Ассемблере, например, помнять логику программы и
делаем push в
середине кода, то все адреса стека, к которым обращаются ниже нужно изменить,
так как стек сдвинулся. Поэтому удобно писать адрес обращения к аргументам
функции из двух часте: mov
eax, [esp + 4 + 4], первая цифра -- номер аргумента, вторая --
сколько мы пушнули.
·
Почитать Агнер Calling
convention. TODO:
добавить ссылку.
Исторически это сопросцессор, который был сильно разнесен с CPU. Поэтому нет прямого доступа между их регистрами, только через память.
У сопроцессора есть свои регистры: 8 регистров, которые собраны в зацикленный стек.
st[0..8]fld (from
float)fild (from
integer)fbld (bcd80)fldpi/fld1/fldz (load pi/1/0)fst (first
store)fstp (fist
store and pop)При загрузке и pop стек крутиться и номера регистров меняются. Но при этом мы не можем затирать значения регистров, которые не освободили. Если это не соблюсти будет NaN.
fadd/fsub/fmul/fdiv -
общие арифметические операцииfprem -- ищет
остаток вычитанием, но не более 64 раз, после просто возвращает результат.fabs, fchs, fsqrt, fsin, fcos, fsincos (ищет
оба и кладет на стек.)fcom --
сравнение и запись во флаги сопроцессора, поэтому нельзя делать бранчи с
этой командойfcomi --
сравнение + запись в CF, ZF. OF не записывается! jne - не
работаетfinit -
помечает все регистры как доступные и устанавливает дефолтное значение.fchx
st1 (swap st1, st0)ffree --
освободить регистр.fincstp/fdecstp --
покрутить стек.fisttp --
выгружает значение из регистра и выкидывает его со стек. При этом значение
конвертится к целому числу отбрасыванием дробной части.finit перед использованием
x87.Пример: Как вызвыть функцию на asm, из кода C/C++:
// declaration// Cfloat __cdecl arctan(float x, int n);
// C++ extern "C" // for name mangling
float __cdecl arctan(float x, int n);
SIMD - single instruction, multiple data. Это идея когда мы можем одной командой
обрабатывать сразу несколько ячеек данных.
mm0..7 -
64 бита мантисы регистров FPU, можно использовать для int. И обрабатывать
сразу два int одной командойxmm0..7 -
128 битые регистрые, которые можно использовать как 4 float. Плюс, что это
никак не связано с FPU, про который пытаются забыть.xmm для
int.ymm -
256 битные регистры, но только для floatymm для
intzmm -
512 битные регистрыa*b + c для x\ymm. Фича:
округление происходит только один раз.~x
& x, -x
& x, x
& (x - 1).Так как эти регистры накладываются на
регистры x87, их нельзя использовать одновременно. Во время работы с mmx, все st помечаются
как недоступные, и в конце нужно вызвать команду emms, которая пометит
все st0..8,
как доступные к использованию.
Замечание: Эта команда сильно похожа на finit, но последнаяя
также устанавливает дефолтное значение.
·
movss - (SSE) load scalar single precision.
·
movap{s, d} - (SSE) load aligned packed single/double precision. Каждый из двух операндов может быть или
памятью, или регистром. Память должна быть выровнена до 16 байт.
·
movup{s, d} - (SSE) load unaligned packed single/double precision. Тоже что выше, но память может быть не
выровнена.
·
punpckl{bw, dq, qdq, wd} - unpack low data. {bw} - собирает word из byte, используя
младшую часть регистов. Схема
·
punpckm{bw, dq, qdq, wd} - unpack high data. {bw} - собирает word из byte, используя
старшую часть регистров. Схема
·
packss{wd, dw} - pack with signed saturation. Saturation - число конвертиться в число
меньшей битности, так чтобы значение было ближе всего к исходному. Схема
·
packus{wd, dw} - pack with unsigned saturation.
·
pmulhw - multiply packed signed integer and store high result.
·
pmullw - multiply packed signed integer and store low result.
·
pmaddwd - multiply and add packed integer. Схема
·
pcmpeq{b, w, d} - Compare packed data for equal.
·
pcmpgt{b, w, d} - Compare packed signed Integer for greater than
·
pand/por/pxor/pandn - bitwise and/or/xor/and not
·
psrl{w, d, q} - Shift packed data right logical Схема
·
psra{w, d, q} - Shift packed data right arithmetic Схема
·
psll{w, d, q} - Shift packed data left logical. Схема
·
paddus{b, w} - add packed usigned intgers with unsigned
saturation.
·
psubus{b, w} - sub packed usigned intgers with unsigned
saturation.
·
palignr dst, src, imm8 - конкатенирует dst и src, потом сдавигает
в право imm8 байт и записывает младщую часть в dst.
·
pshufw dst src imm8 - Shuffle the words in src based
on the enocoding in imm8 and store the result in imm1. Схема
·
emms -
Очищает все x87 регистры
·
movq/movd --
загрузить целочисленный qword/dword
section .data
align 16
const1: 12
alloc +
ручное выравниваниеalign_alloc(Linux)/virtual_alloc(Windows)Перед любым вызовом функции в 32 битах жилательно выравнивать стек до 16, а в 64 битности - это обязательно.
push ebp
mov ebp, esp
sub esp, n
and esp, -16
...mov esp, ebp
pop ebp
TODO
Замечание: Почему важна обратная
совместимость?
Потому, что старый код очень долго переписывать, и новые технологии внедряются
не мнговенно. При этом программная эмуляция очень сильно проседает по скорости.
Режим работы меняет коды команд.
Биос начинает работать в real mode и потом постепенно переходит в нужный.
Изначально в этом режиме работали 16 битные процессоры.
В i80186 можно адресовать 1 Мб оперативки, то есть 220
Физический
адрес = сегмент * 16
+ смещение(виртуальный
адрес)
Сегментный регистры: cs(code), ds(data), ss(stack), es(extra). Они тоже состоят из 16 бит и могут
хратить любой адрес.
Сегмент можно указывать явно,
mov al, [ebx] ; по-умолчанию
mov al, ds:[ebx]
ds: ; seg ds
mov al, [ebx]
а может выводиться по-умолчанию:
sscsbp, ebp, esp => ss (sp нет,
потому, что его не бывает в квадратным скобках.)ds.Ограничение на размер сигмента Существует ограничение на размер
сигмента 64Kb. Но его можно обойти написав сегмент ясно ds:[eax]. Важно также
заметить, то в real mode можно использовать 32битные регистры для адресов
начиная с i80386. Замечание: В "C" есть поэтому
поводу оговорка, что объект не может занимать больше места чем максимальный
размер смещения. (<
64kb)
Замечание:
mov al, [ebx + ebp] ; implementation undefined behavior
mov al, [ebx + ebp*1] ; ok, => ds
; хороший компилятор (not nasm) позволяет таким образом подавить использование ebp как базы
Может адресовать 24-битные адреса.
Добавились новые сегментные
регистры: fs, gs с неопределенным
использованием.
A20 line: в i80186 при обращении за границы
1 Мб происходило переполнение. То есть всегда использовались только последние
20 бит. А в i80286 можно адресовать большую память, поэтому переполения не
происходило и можно было адресовать 220+216−24 в real mode. Для
обратной совместимости можно влючить переполнение. Про это Bios Line 20 disable
Это режим появился в 286.
Теперь сегментный регистр содержит не базу сегмента, а селектор, который состоит из 3 частей.
[0..1] <- RPL[2] <- G/L[3..15] <- index· index - индекс дескриптора сегмента в глобальной таблице.
· g/l - global/local description table, но локальные не используется.
· rpl - права
Дескриптор сегмента состоит из 8 байт и содержит все необходимую информацию о сегменте:
Адрес таблицы дескрипторов храниться в регистре gdtr (global description table register).
Замечание: Для ускорения обращения у сегментного регистра есть теневая часть, в которую загружается дескриптор. Это имеет некоторые последствия.
Теперь у нас есть 4 уровня прав. 0 - уровень ОС. 3 - уровень пользователя.
Это позволяет:
CPL - current privilege level - уровень прав в регистре cs. Он пределяет
права кода. В этом отличие пользовательского кода, от кода OC.
RPL - request privilege level - уровень прав в остальных сегментных регистрах, который определяет права для запроса на использование своего дескриптора.
DPL - descriptor privilege level - уровень прав в дескрипторе сегмента.
Замечание: Зачем нужен RPL, если есть DPL? Когда мы передаем управление более привелегированному коду и просим его, например, изменить данные сегмента, на который у нас прав нет. Тогда вызваемая функция может записать в RPL селектора, записать наш CPL. Так как при обращении к данным сверяется с DPL не только CPL, но и RPL, данные будут защищены.
Существуют инструкции в защищенном режиме можно использовать только при нулевом CPL.
Процесс
может понизить свои права. Но как повысить?
Мы можем вызвать прерывание, у которого выше уровень привилегий. И он может
вернуть нам права.
Защита достикается повышением абстракции. Теперь адреса бывают:
В 286 база сегмента составляла 24 бита, поэтому максимальная доступная память - 224 = 16 Mb. При этом длина сегмента менялась от 1 до 216 байт.
jmp segment:offsetЭто идея обращения процесса с памятью. Она заключается в том, что память для процесса - это единое и не делимое пространство.
Это режим появился в 386. В нем увеличилась битность линейного адреса до 32 бит и появилась возможность делать сегменты с лимитом 4Gb. Это открыло доступ к Flat-module работы с памятью.
Размер дескриптора при этом не поменялся, так как в нем заранее присутствовали 2 неиспользуемых байта.
Также в
дескрипторе есть флаг, который для сегмента кода значит, какой битности
записаны команды: 16 или 32. (D-bit)
Подробнее о флагах на вики
Замечание: Теперь лимит не может принимать любые значения, так как он занимает всего 20 бит и увеличивается за счет изменения гранулярности с 1 байта на 4Кб.
Существует незадокументированная фича,
что при переходе в real
mode теневая часть не меняется. Это дает доступ к сегментам
большого размера в реальном режиме. Это называют нереальном режимом. (unreal
mode)
Так как в real mode можно использовать
32 битные регистры, то можно получить доступ к 4Gb. Это фича называется Operand Size Override Prefix и
включается отдельно(может добавляться автоматически компилятором ассемблера). И
важно отключить вентиль A20.
TODO: Проверить: Видимо лимит на размер сегмента в реальном моде даже на i80186 хранился в скрытой части сегмента(видимо тогда она уже сущетсвовала.). Но я не нашел явно упоминания.
возможно лимит не надо было хранить, так как он всегда один и тот тоже.
Режим совместимости с 8086. Адресация как в реальном режиме, но с кольцами прав.
System Management Mode - режим отладки. wiki
Это новый способ адресации, который был введен с 386.
Замечание: Почему на некоторых Win32 нельзя
выделить больше 4 ГБ?
Это лишь лицензионное ограничение. На самом деле благодаря страничной адресации
мы можем выделять довольно большое адресное пространство для программы. Так как
система сама строит адресное пространство.
AWE - другой хак, который позволяет
выделять процессу больше чем 4ГБ без страничной адресации.
Замечание: AWE(Address Windowing Extension) - суть
заключается в окне в адресном пространстве программы, которое мы можем
отображать в разные части пространства физических адрессов.
Замечание: Страничная адресация работает на уровне MMU. Но настраивается на уровне процессора.
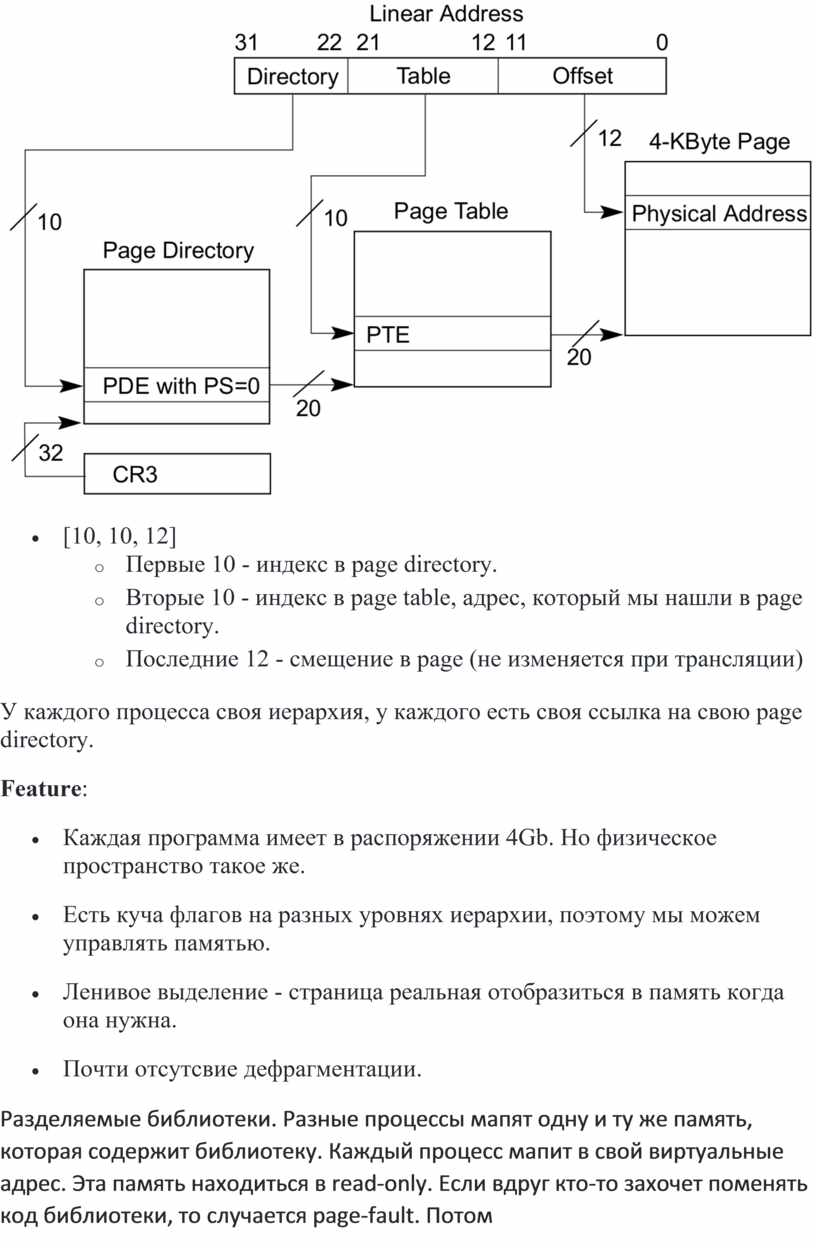
Теперь все пространство поделяно на страницы(page) по 4Kb.
Страница описывается структурой из 4 байт PTE(page table entry).
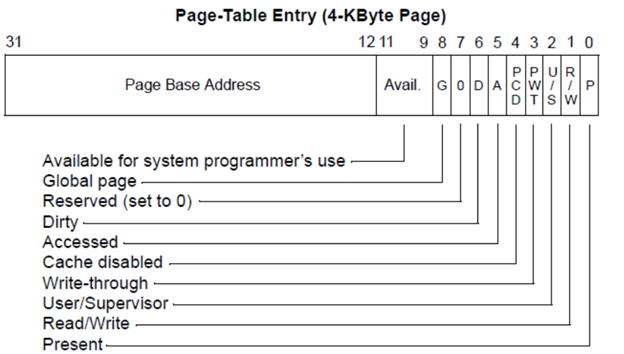
Одна страница в которой лежат эти структуры ($2^{10}$ штук) называется Page Table.
Одна такая Page Table описывается структурой в 4 байта PDE(page directory entry)
И эти структуры лежат в Page directory, адрес на которую лежит в CR3. (Control register)
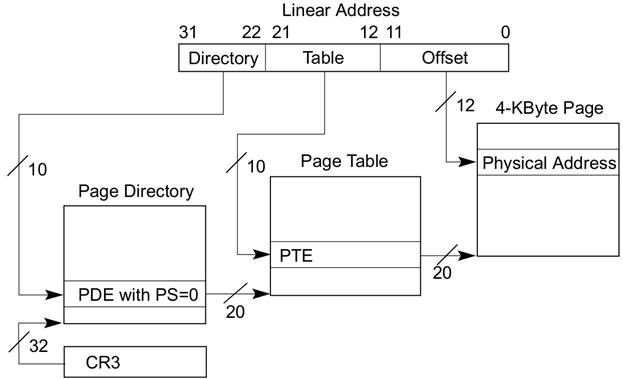
[10, 10, 12]У каждого процесса своя иерархия, у каждого есть своя ссылка на свою page directory.
Feature:
· Каждая программа имеет в распоряжении 4Gb. Но физическое пространство такое же.
· Есть куча флагов на разных уровнях иерархии, поэтому мы можем управлять памятью.
· Ленивое выделение - страница реальная отобразиться в память когда она нужна.
· Почти отсутсвие дефрагментации.
· Разделяемые библиотеки. Разные процессы мапят одну и ту же память, которая содержит библиотеку. Каждый процесс мапит в свой виртуальные адрес. Эта память находиться в read-only. Если вдруг кто-то захочет поменять код библиотеки, то случается page-fault. Потом процессор копирует нужные страницы и ставит write permission. То есть в режиме copy-on-write.
· swap(paging): swap - выгрузка всего дампа (сейчас редкость), paging - выгрузка части. Сброс страниц оперативки в память. Если страница долго не используется, то ОС выгружает ее, если мы хотим обратиться к ней, то она вгружается.
TLB: Мы получили очень гибкий механизм,
но долгий. Поэтому сущетсвует TLB(translation lookaside buffer)-кеш.
Но не все так просто: при
переключени ядра на другой процесс нужно его сбрасывать. При этом остальный
кешы процессора (L1, L2, L3) сбрасывать не надо, так как они хранят только
физические адреса.
Так же TLB можно использовать в уязвимости Meltdown.
Замечание: Традиционно первые сколько-то адресов не замапленые в никуда, это сделано, чтобы null-pointer падал гарантированно. Он просто идет в page directory и там написано, что не замапалено.
Замечание: Бывает спекулятивное подгрузка страниц. Можно посмотреть на Аиде, которая может вырубать это на работающем процессе, что посмотреть что поменяется.
Что делать если у нас оперативки больше, чем 4GB? Расширения:
[31..30, 29..21, 20..12, 11..0] = [2, 9, 9, 12]Адресное
пространство делиться на системное и не системное. Это определяет по первому
старшему биту. Для 32 битных адресов: младшие 2ГБ - user space, старшие 2ГБ -
kernel space.
Так сделано для удобства работы ОСи. Например, чтобы понимать у каких данных
нужно проверять права доступа.
Замечание: Поэтому для 32битных приложений все равно полезно 64битная операционка, так тогда оно получит не 2ГБ, а 4ГБ.
Зачем нужен 64bit?
От сегментной адресации не осталось почти ничего еще в 32bit режиме. Кроме:
cs осталось
кольцо правcs указывается
битность сегмента, которая определяет битность режима.Остальные сегменты получили базу 0, и лимит
максимальный - 4Gb. Тем самым смещение виртуального адреса совпадает с
линейным, который потом транслируется в физический через страницы.
Что с fs, gs? От них осталось поле базы.
fs --
обычно используется для thread local storagelast_error(),
но это работает и при нескольких тредов. Потому, что они хранятся
локально для каждого треда.fs указывает
к каждом треде на разное смещение в TEB(thread enviroment block), из
который уже узнается настоящий адрес переменной.gcgc(64), и fs(32).Страничная адресация: Идейно ничего нового, просто больше страниц, больше уровней, возможность делать еще большие страницы в PSE.
16/32 битный код не переключается обратно из long mode, для этого у него есть свои подрежимы(compatibility mode).
Переход в другую битность - это просто far jump. При этом прогружается другой сегмент, с другой битностью. Но чтобы все реально работало есть много тонкостей, поэтому часто просто стараются избежать разнородной битности в коде.
Есть системные библиотеки под каждую битность. Когда 32-битный код делает системный вызов, то вызывается NTDLL32.dll, которая делает far_call к NTDLL64.dll. Тем самым 32-битный код вызвает 64-битные системные вызовы.
Во всех текущих процессорах x64 не
используются все 64 бита виртуального адреса. Так как
пока 264 слишком много для текущих требований, то из соображений
оптимизации не все биты адреса транслируются. Только младшие 48 бит учавствуют
в трансляции, что позволяет адресовать 256 TB. Учитывая деление виртуального
пространства на user space и kernel space получаем доступный диапазон: 00000000'00000000..00007FFF'FFFFFFFF
+ FFFF8000'00000000..FFFFFFFF'FFFFFFFF
Это подсистема(ABI) linux, которая позволяет работать в 64битном мире, но указатели размером 32бита. Иногда это полезно. Так тогда мы получаем полезности 64битного режима, но не платим за это размером указателей.
![]()
EFER.LME - long
mode enableCR4.PAE -
включить pae-расширение страничной адресацииCP0.PG -
включить paging (возможности сбрасывать страницы в память)CP0.PE -
protected mode enableEFLAGS.VM -
virtual-8086 modeCS.L - флаг
дескриптора сегмента CS, который отвечает за 64-битность сегмента, при
этом флаг D должен
быть равен 0.Замечание: Необходимо помнить, что переключени режимов - это привелегированная операция, а подрежимов - нет.
AMD выпустили новую ISA, которая полностью поддерживала x86 и назвали ее AMD64. Потом Intel ее поддержал. Другие названия: x86-64, x64
rax, rbx ...)
32битные названия - это их младшие части.esi, edi, ebp, esp появилась
возможность обращаться к их младшей части. (rsi -> esi -> sih:sil)r8..15 (r9 -> r9d -> r9w -> r9b) Замечание: TODO:
более четко сформулироватьmov al, bh % ok
mov r9b, bh % нельзя, так как коды таких команды отданы под sil, dil
[base_register +
index_register * scale_factor + off32]base_register - rax, rcx, ... r15index_register - rax, ..., rspr15scale_factor - 1,
2, 4, 8off32 - это
знаковая константа. И ее битность являет проблемой. Метки перестают
работать, так как их адрес стал 64битным, а в схеме мы не может это
указать.rip для
указания смещения по коду.mov reg,
[rip + const32] TODOmov reg [rel
label],
компилятор приводит это к тому, что выше.default rel,
чтобы дать указание компилятору все обращения к меткам приводить код
строчке выше.Так
mov acc,
[offset64] -
только для al, ax, eax, rax.mov r*,
const64mov
eax, ecx -
обнуляет старшие 32 бита.
Это позволяет избежать больших констант, то есть больших кодов команд.
Замечание: У команды nop такой же
код, как у команды xchg
eax, eax. Поэтому в этом случае старшая часть не зануляется.
xchg eax, eax % нет зануления
xchg ebx, ebx % есть зануление
Замечание: Вместо xor rax, rax лучше
писать xor eax,
eax, так как занимает меньше места.
Добавили xmm8..15. А про mmx стараются
забыть.
aaa, aad, aam, aas, daa, das -
10ичная арифметика.bound, into -
что-то с проверкой границ.pushad/popad -
выгрузить все.los/les -
что-то с сегментами.push/pop {cs,
ds ...}jmp/call для
абсолютного адреса.inc/dec -
теперь кодируется только в полную форму, старая занимала 1 байт.sysenter/sysexit - intel
команды для системного вызова.rcx, rdx, r8, r9xmm0, xmm1, xmm2, xmm3f(int a, float b, int *c);
// a -> rcx// b -> xmm1// c -> r8
rax или
в rdx:rax для
128 бит.xmm0this передается также(в нулевой
аргумент)
rbx, rbp, rsi, rdi, r12..15, xmm6..15
Замечание: сохранение xmm большая
проблема.
Она заключается в том на стеке всегда выделяется 32 байта вне зависимости от количества аргументов. Оно нужно для того, чтобы скинуть все аргументы на стек.
stack -> [ret][shadow space][other args]...
Это может быть полезно для variadic-функции, чтобы единообразно их обрабатывать.
rdi, rsi, rdx, rcx, r8, r9xmm0..7 в rax записанно
сколько загруженных xmmf(int a, float b, int *c);
// a -> edi// b -> xmm0// c -> rsi// rax = 1
rax или
в rdx:rax для
128 бит.xmm0:xmm1this передается также(в нулевой
аргумент)
rbx, rbp, r12..15
Она заключается в том, что мы можем
писать на 128 байт ниже rsp.
Это может быть полезно для последний функции.
NB) Есть две таблицы: - таблица, для
всего, ее используется система. - урезанная таблица, для процесса. При syscall,
мы переходим в код ядра, с полными таблицами.
СТРУКТУРНОЕ ПРОЕКТИРОВАНИЕ И ПРОГРАММИРОВАНИЕНисходящее проектированиеМетод нисходящего проектирования предполагает последовательное разложение общей функции обработки данных на простые функциональные элементы ("сверху-вниз"). В результате строится иерархическая схема, отражающая состав и взаимоподчиненность отдельных функций, которая носит название функциональная структура алгоритма (ФСА) приложения. Последовательность действий по разработке функциональной структуры алгоритма приложения:
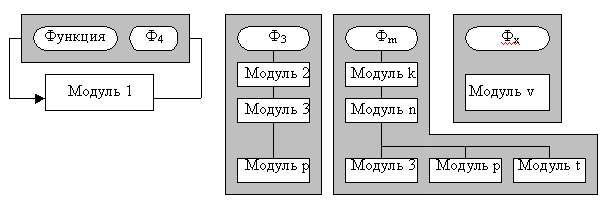
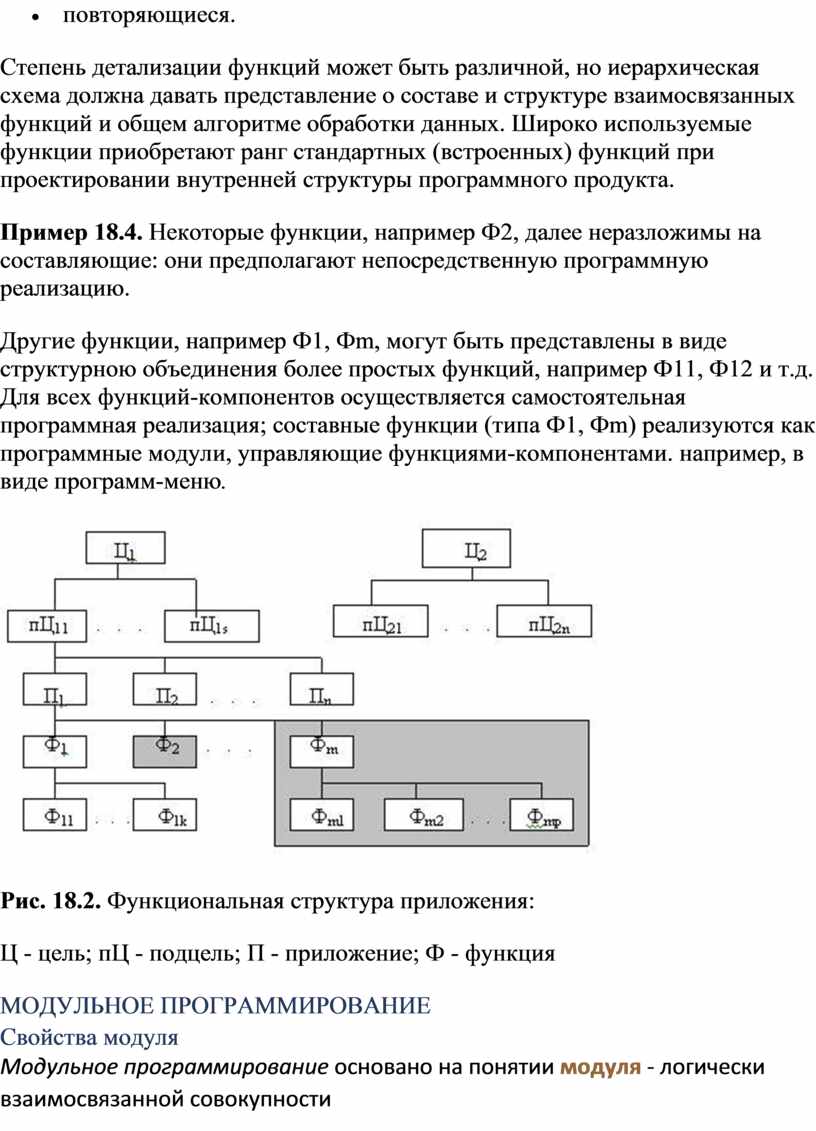
Подобная структура приложения (рис. 18.2) отражает наиболее важное - состав и взаимосвязь функций обработки информации для реализации приложений, хотя и не раскрывает логику выполнения каждой отдельной функции, условия или периодичность их вызовов. Разложение должно носить строго функциональный характер, т.е. отдельный элемент ФСА описывает законченную содержательную функцию обработки информации, которая предполагает определенный способ реализации на программном уровне. Функции ввода-вывода информации рекомендуется отделять от функций вычислительной или логической обработки данных. По частоте использования функции делятся на:
Степень детализации функций может быть различной, но иерархическая схема должна давать представление о составе и структуре взаимосвязанных функций и общем алгоритме обработки данных. Широко используемые функции приобретают ранг стандартных (встроенных) функций при проектировании внутренней структуры программного продукта. Пример 18.4. Некоторые функции, например Ф2, далее неразложимы на составляющие: они предполагают непосредственную программную реализацию. Другие функции, например Ф1, Фm, могут быть представлены в виде структурною объединения более простых функций, например Ф11, Ф12 и т.д. Для всех функций-компонентов осуществляется самостоятельная программная реализация; составные функции (типа Ф1, Фm) реализуются как программные модули, управляющие функциями-компонентами. например, в виде программ-меню.
Рис. 18.2. Функциональная структура приложения: Ц - цель; пЦ - подцель; П - приложение; Ф - функция МОДУЛЬНОЕ ПРОГРАММИРОВАНИЕСвойства модуляМодульное программирование основано на понятии модуля - логически взаимосвязанной совокупности функциональных элементов, оформленных в виде отдельных программных модулей. Модуль характеризуют:
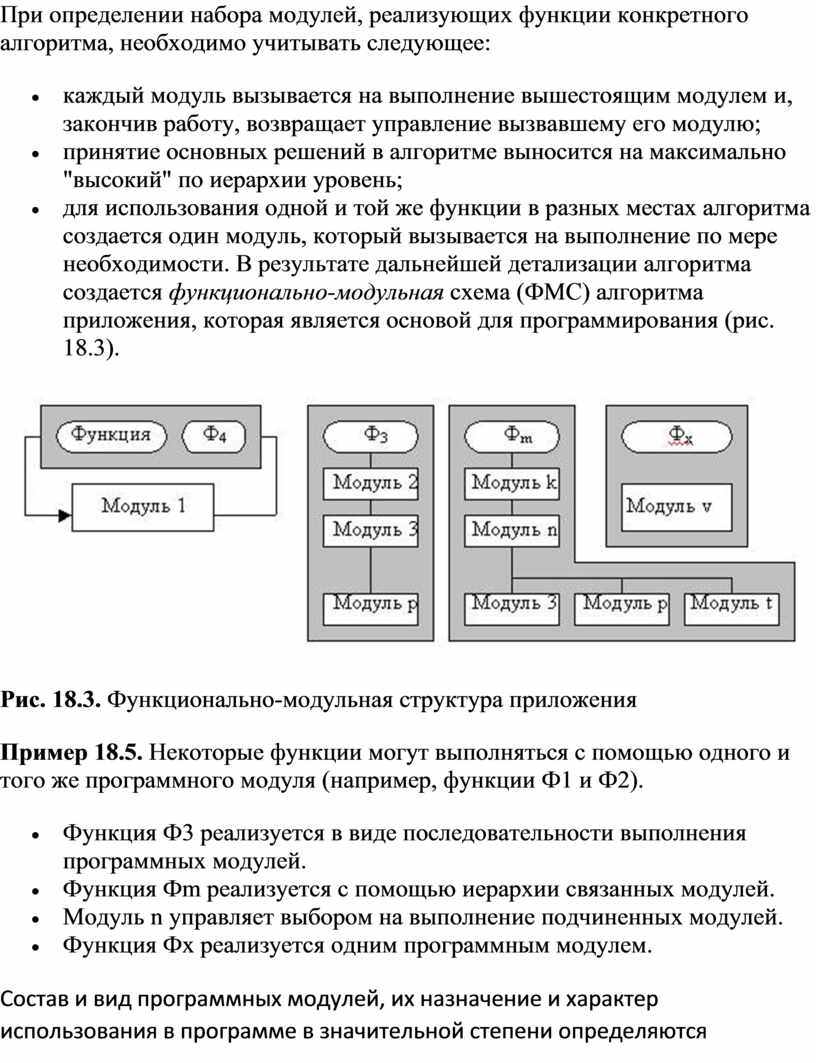
Таким образом, модули содержат определение доступных для обработки данных, операции обработки данных, схемы взаимосвязи с другими модулями. Каждый модуль состоит из спецификации и тела.Спецификации определяют правила использования модуля, а тело - способ реализации процесса обработки. Модульная структура программных продуктовПринципы модульного программирования программных продуктов во многом сходны с принципами нисходящего проектирования. Сначала определяются состав и подчиненность функций, а затем - набор программных модулей, реализующих эти функции. Однотипные функции реализуются одними и теми же модулями. Функция верхнего уровня обеспечивается главным модулем; он управляет выполнением нижестоящих функций, которым соответствуют подчиненные модули. При определении набора модулей, реализующих функции конкретного алгоритма, необходимо учитывать следующее:
Рис. 18.3. Функционально-модульная структура приложения Пример 18.5. Некоторые функции могут выполняться с помощью одного и того же программного модуля (например, функции Ф1 и Ф2).
Состав и вид программных модулей, их назначение и характер использования в программе в значительной степени определяются инструментальными средствами. Например, применительно к средствам СУБД отдельными модулями могут быть:
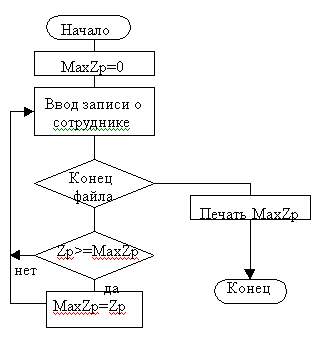
Алгоритмы большой сложности обычно представляются с помощью схем двух видов:
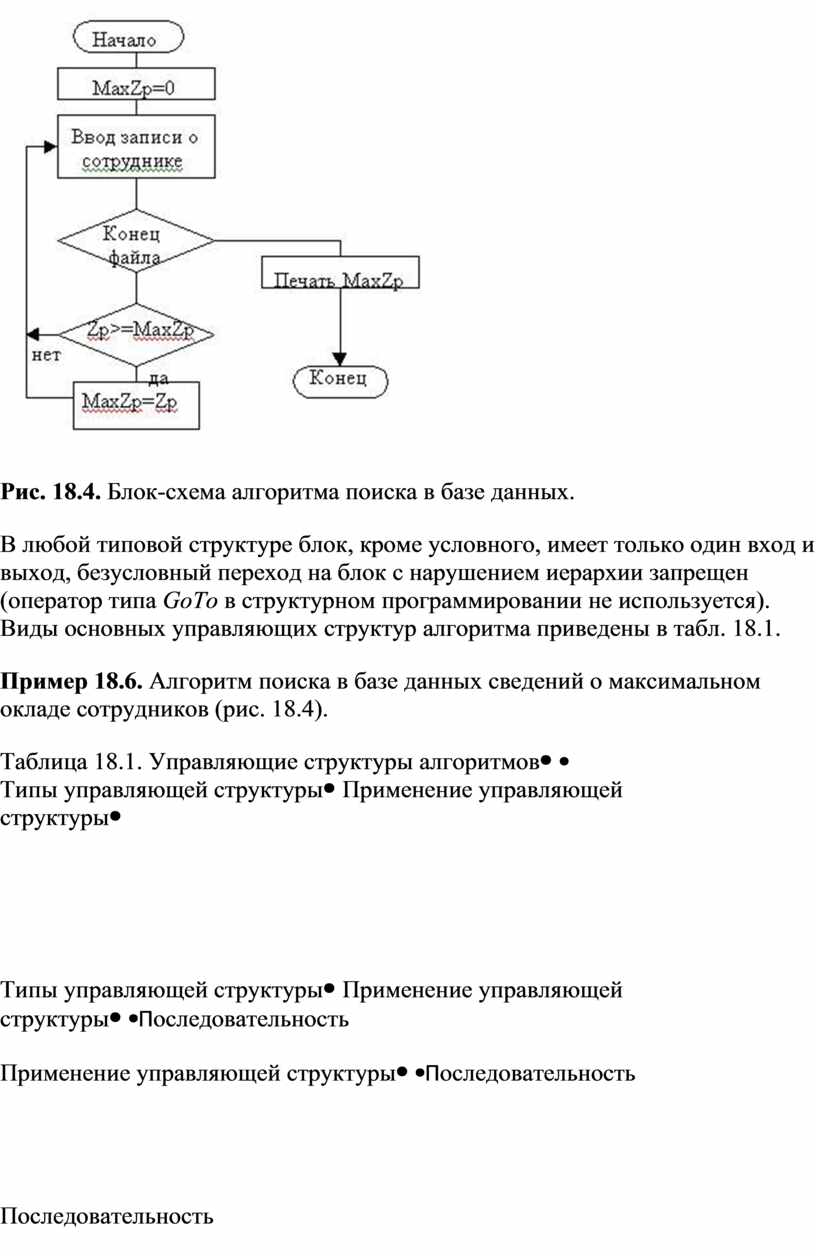
Наиболее часто детально проработанные алгоритмы изображаются в виде блок-схем согласно требованиям структурного программирования; при их разработке используются условные обозначения согласно ГОСТ 19.003-80 ЕСПД (Единая система программной документации). Обозначения условные графические, ГОСТ 19.002-80 ЕСПД. Схемы алгоритмов и программ. Правила обозначения. СТРУКТУРНОЕ ПРОГРАММИРОВАНИЕСтруктурное программирование основано на модульной структуре программного продукта и типовых управляющих структурах алгоритмов обработки данных различных программных модулей (рис. 18.4). Рис. 18.4. Блок-схема алгоритма поиска в базе данных. В любой типовой структуре блок, кроме условного, имеет только один вход и выход, безусловный переход на блок с нарушением иерархии запрещен (оператор типа GoTo в структурном программировании не используется). Виды основных управляющих структур алгоритма приведены в табл. 18.1. Пример 18.6. Алгоритм поиска в базе данных сведений о максимальном окладе сотрудников (рис. 18.4). Таблица 18.1. Управляющие структуры алгоритмов |
|
Типы управляющей структуры |
Применение управляющей структуры |
|
Последовательность Блок 1 Блок 2 Конец |
Последовательность включает фиксированный перечень блоков (операторов). Каждый очередной блок обрабатывается после завершения предыдущего без дополнительных условий. Для изменения порядка обработки блоков редактируется последовательность выполняемых |
|
Альтернатива (условие выбора) Начало Да Условие Нет Альтернатива1 Альтернатива2 Конец |
В блоке Условие содержится условие выбора альтернативы обработки. Каждая альтернатива выполняется 1 раз; выполнение одной из двух альтернатив - обязательно. Развитие данного типа структуры является множественная альтернатива, когда последовательно проверяются условия выполнения определенных альтернатив. Если очередное условие истинно, обрабатывается соответствующая ему альтернатива, после чего происходит выход. В противном случае - переход к проверке условия следующей альтернативы. Если ни одно из условий не выполнилось, происходит выход. |
|
Цикл ("пока") Начало Условие Нет Да Тело цикла Конец |
В блоке Условие задается условие тела цикла - определенной обработки. Если условие не выполняется, цикл прерывается и осуществляется выход. Условие может содержать счетчик повторений тела цикла либо логическое условие. Тело цикла - произвольная последовательность блоков (операторов) обработки ВВЕРХ |
Скачано с www.znanio.ru




































Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.