Поделиться

Первые вопросы билетов
Операционные системы
1. Виды операционных систем и их классификация. Однозадачные и многозадачные операционные системы.
Операцио́нная систе́ма, сокр. ОС (англ. operating system, OS) — комплекс управляющих и обрабатывающих программ, которые, с одной стороны, выступают как интерфейс между устройствами вычислительной системы и прикладными программами, а с другой стороны — предназначены для управления устройствами, управления вычислительными процессами, эффективного распределения вычислительных ресурсов между вычислительными процессами и организации надёжных вычислений. Это определение применимо к большинству современных операционных систем общего назначения.
Виды ОС:
Классификация ОС:
1)по назначению (общего назначения, специального назначения (мини ЭВМ,
микро ЭВМ, ЭВМ реального времени));
2)по режиму обработки задач (однопрограммные, многопрограммные); 3)по
архитектурным особенностям (микроядерные, монолитные);
4)по организации работы (однотерминальные, многотерминальные).
Процесс - минимальный программный объект, обладающий собственными системными ресурсами.
Процесс (задача) – это программа в стадии выполнения.
Интерфе́йс (англ. interface — сопряжение, поверхность раздела, перегородка) — граница раздела двух систем, устройств или программ, определённая их характеристиками, характеристиками соединения, сигналов обмена
Интерфейс прикладного
программирования
Прикладные программисты используют в своих приложениях обращения к ОС, когда
для выполнения тех или иных действий им требуется особый статус, которым
обладает только операционная система. Например, в большинстве современных ОС
все действия, связанные с управлением аппаратными средствами компьютера, может
выполнять только ОС. Помимо этих функций прикладной программист может
воспользоваться набором сервисных функций ОС, которые упрощают написание
приложений. Функции такого типа реализуют универсальные действия, часто
требующиеся в различных приложениях, такие, например, как обработка текстовых
строк. Эти функции могли бы быть выполнены и самим приложением, однако гораздо
проще использовать уже готовые, отлаженные процедуры, включенные в состав
операционной системы. В то же время даже при наличии в ОС соответствующей
функции программист может реализовать ее самостоятельно в рамках приложения,
если предложенный операционной системой вариант его не вполне устраивает.
Многозадачность — свойство операционной системы или среды программирования обеспечивать возможность параллельной обработки нескольких процессов. Истинная многозадачность операционной системы возможна только в распределённых вычислительных системах.
Существует 2 типа многозадачности:
- Процессная многозадачность (основанная на процессах — одновременно выполняющихся программах). Здесь программа — наименьший элемент кода, которым может управлять планировщик операционной системы. Более известна большинству пользователей (работа в текстовом редакторе и прослушивание музыки).
- Поточная многозадачность (основанная на потоках). Наименьший элемент управляемого кода — поток (одна программа может выполнять 2 и более задачи одновременно).
Примером многозадачных ОС являются Windows 95, Windows 2000, Windows 7/XP…
Однозадачные К ним относятся MS-DOS, PC-DOS
2. Назначение и функции операционной среды. Визуализация операционных сред, сред и приложений.
Операционная среда - это совокупность инструментов, методов их интеграции и приемов работы с ними, позволяющая решать любые задачи в инструментальной области и большинство задач в прикладных областях. Операционная среда — совокупность компьютерных программ, обеспечивающая оператору возможность управлять вычислительными процессами и файлами.
Основные функции ОС:
- прием от пользователя заданий или команд, сформулированных на соответствующем языке и их обработка;
- прием и исполнение программных запросов на запуск, приостановку, остановку других программ;
- загрузка в оперативную память подлежащих исполнению программ;
- инициация программы — передача ей управления, в результате чего процессор исполняет программу;
- идентификация всех программ и данных;
- обеспечение работы систем управлений файлами (СУФ) и/или систем управления БД (СУБД), что позволяет резко увеличить эффективность всего ПО;
- обеспечение режима мультипрограммирования, то есть выполнение двух или более программ на одном процессоре, создающее видимость их одновременного исполнения;
- обеспечение функций по организации и управлению всеми операциями ввода/вывода;
- удовлетворение жестким ограничениям на время ответа в режиме реального времени;
- распределение памяти, а в большинстве современных систем и организация виртуальной памяти;
- планирование и диспетчеризация задач в соответствии с заданной стратегией и дисциплинами обслуживания; организация механизмов обмена сообщениями и данными между выполняющимися программами;
- защита одной программы от влияния другой;
- обеспечение сохранности данных;
- предоставление услуг на случай частичного сбоя системы;
- обеспечение работы систем программирования, с помощью которых пользователи готовят свои программы.
функции операционной среды - унификация, разделение и учет системных ресурсов, а также планирование и сопровождение задач. Под словом "сопровождение" мы подразумеваем всевозможные средства разработки и организации взаимодействия задач, которые пользователи системы применяют для построения приложений.
Операционная система (ОС) играет роль связующего звена между аппаратурой компьютера и выполняемыми программами, а также пользователем.
Виртуализа́ция в вычислениях — процесс представления набора вычислительных ресурсов, или их логического объединения, который даёт какие-либо преимущества перед оригинальной конфигурацией. Это новый виртуальный взгляд на ресурсы составных частей, не ограниченных реализацией, физической конфигурацией или географическим положением. Обычно виртуализированные ресурсы включают в себя вычислительные мощности и хранилище данных. По-научному, виртуализация — это изоляция вычислительных процессов и ресурсов друг от друга.
Примером виртуализации являются симметричные мультипроцессорные компьютерные архитектуры, которые используют более одного процессора. Операционные системы обычно конфигурируются таким образом, чтобы несколько процессоров представлялись как единый процессорный модуль. Вот почему программные приложения могут быть написаны для одного логического (виртуального) вычислительного модуля, что значительно проще, чем работать с большим количеством различных процессорных конфигураций.
Виртуализация приложений
Достоинства:
Виртуализация на уровне ОС
3. Операционные системы семейства unix. Структура unix и unix подобных операционных систем. Файловая система unix.
Начиная с ЭВМ второго поколения, встала задача полной и эффективной загрузки
Операционная система - набор программ, обеспечивающих функ‑
ционирование центрального процессора и периферийных устройств ЭВМ как единого
комплекса, служащего для разработки и выполнения про‑
грамм.
Можно выделить следующие функции или подсистемы ОС:
Процесс - некоторая логически связанная последовательность дейст‑
вий, не обязательно линейная.
Ресурс - средство вычислительной техники, которое может быть вы‑
делено процессу на некоторое время.
Виды ОС: DOS, Windows (версии), UNIX, MAC OS, Novel NetWare и т.п.
Общие черты ОС:
- принцип независимости программ от внешних устройств.
‑
1.Классификация ОС.
Компьютер обменивается информацией с человеком посредством набора определенных
правил, которые в компьютерной литературе называются интерфейсом. Интерфейс, по
определению - это правила взаимодействия операционной системы с пользователями,
а также соседних уровней в сети ЭВМ.
Типы интерфейсов.
1) Командный интерфейс. Командный интерфейс называется так потому, что в этом
виде интерфейса человек подает "команды" компьютеру, а компьютер их
выполняет и выдает результат человеку. Командный интерфейс реализован в виде пакетной
технологии и технологии командной строки.
2) WIMP - интерфейс (Window - окно, Image - образ, Menu - меню, Pointer -
указатель). Характерной особенностью этого вида интерфейса является то, что
диалог с пользователем ведется не с помощью команд, а с помощью графических
образов - меню, окон, других элементов. Хотя и в этом интерфейсе подаются
команды машине, но это делается "опосредованно", через графические
образы. Этот вид интерфейса реализован на двух уровнях технологий: простой
графический интерфейс и "чистый" WIMP - интерфейс.
3) SILK - интерфейс (Speech - речь, Image - образ, Language - язык, Knowlege -
знание). Этот вид интерфейса наиболее приближен к обычной, человеческой форме
общения. В рамках этого интерфейса идет обычный "разговор" человека и
‑
компьютера. При этом компьютер находит для себя команды, анализируя
человеческую речь и находя в ней ключевые фразы. Результат выполнения команд он
также преобразует в понятную человеку форму.
Операционные системы могут различаться особенностями реализации внутренних
алгоритмов управления основными ресурсами компьютера (процессорами, памятью,
устройствами), особенностями использованных методов проектирования, типами
аппаратных платформ, областями использования и многими другими свойствами.
‑
В зависимости от особенностей использованного алгоритма управления процессором
операционные системы делят на:
• многозадачные и однозадачные,
• многопользовательские и однопользовательские,
• на системы, поддерживающие многонитевую обработку и не поддерживающие ее,
• на многопроцессорные (асимметричные ОС и симметричные ОС) и однопроцессорные
системы.
^ Поддержка
многозадачности
По числу одновременно выполняемых задач операционные системы могут быть
разделены на два класса: однозадачные (например, MS DOS, MSX) и многозадачные
(ОС ЕС, OS/2, UNIX, Windows 95-98).
Под задачей можно понимать некоторую прикладную программу, приложение
(например, MS Word, Excel и т.п.).
Однозадачные ОС в основном выполняют функцию предоставления пользователю
виртуальной машины, делая более простым и удобным про‑
цесс взаимодействия пользователя с компьютером. Однозадачные ОС включают
средства управления периферийными устройствами, управления файлами, общения с
пользователем.
Виртуальной машиной можно назвать машину с условно неограни‑
ченными локальными ресурсами (не связанными с аппаратурой), отдан‑
ными задаче в безраздельное пользование.
Многозадачные ОС, кроме вышеперечисленных функций, управляют разделением
совместно используемых ресурсов, таких как процессор, опе‑
ративная память, файлы и внешние устройства (т.е. решают вопрос о пре‑
доставлении ресурса той или иной задаче во временное пользование).
Поддержка многопользовательского режима
По числу одновременно работающих пользователей ОС делятся:
Главным отличием многопользовательских систем от однопользова‑
тельских является наличие средств защиты информации каждого пользова‑
теля от несанкционированного доступа других пользователей. Следует за‑
метить, что не всякая многозадачная система является многопользователь‑
ской и не всякая однопользовательская ОС является однозадачной. Напри‑
мер, Windows98 является многозадачной, но однопользовательской ОС. ^ Вытесняющая и
невытесняющая ‑
многозадачность Важнейшим разделяемым ресурсом является процессорное
время. Способ распределения процессорного времени между несколькими одно‑
временно существующими в системе процессами (или нитями) во многом определяет
специфику ОС. Среди множества существующих вариантов реализации многозадачности
можно выделить две группы алгоритмов:
- невытесняющая многозадачность (NetWare, Windows 3.x);
- вытесняющая многозадачность (Windows NT, OS/2, UNIX).
Основным различием между вытесняющим и невытесняющим вари‑
антами многозадачности является степень централизации механизма пла‑
нирования процессов. В первом случае механизм планирования процессов целиком
сосредоточен в операционной системе, а во втором распределен между системой и
прикладными программами. При невытесняющей мно‑
гозадачности активный процесс выполняется до тех пор, пока он не закон‑
чится, ему потребуется занятый в настоящее время ресурс или он сам, по
собственной инициативе, не отдаст управление операционной системе для того,
чтобы та выбрала из очереди другой готовый к выполнению процесс. При
вытесняющей многозадачности решение о переключении процессора с одного процесса
на другой принимается операционной системой, а не самим активным процессом.
^ Поддержка
многонитевости
Важным свойством операционных систем является возможность распараллеливания
вычислений в рамках одной задачи. Многонитевая ОС разделяет процессорное время
не между задачами, а между их отдельными ветвями (нитями).
^ Многопроцессорная
обработка
Другим важным свойством ОС является отсутствие или наличие в ней средств
поддержки многопроцессорной обработки - мультипроцессирование, которое приводит
к усложнению всех алгоритмов управления ре‑
сурсами
В наши дни становится общепринятым введение в ОС функций под‑
держки многопроцессорной обработки данных. Такие функции имеются в операционных
системах Solaris с версии 2.x фирмы Sun, Open Server с вер‑
сии 3.x компании Santa Crus Operations, OS/2 фирмы IBM, Windows NT фирмы
Microsoft и NetWare 4.1 фирмы Novell.
Многопроцессорные ОС могут классифицироваться по способу ор‑
ганизации вычислительного процесса в системе с многопроцессорной ар‑
хитектурой: асимметричные ОС и симметричные ОС. Асимметричная ОС целиком
выполняется только на одном из процессоров системы, распреде‑
ляя прикладные задачи по остальным процессорам. Симметричная ОС полностью
децентрализована и использует все множество процессоров, разделяя их между
системными и прикладными задачами.
Выше были рассмотрены характеристики ОС, связанные с управле‑
нием только одним типом ресурсов, - процессором. Важное влияние на облик
операционной ‑
системы в целом, на возможности ее использования в той или иной области
оказывают особенности и других подсистем управ‑
ления локальными ресурсами - подсистем управления памятью, файлами,
устройствами ввода/вывода.
Специфика ОС проявляется и в том, каким образом она реализует се‑
тевые функции: распознавание и перенаправление в сеть запросов к уда‑
ленным ресурсам, передача сообщений по сети, выполнение удаленных запросов. При
реализации сетевых функций возникает комплекс задач, связанных с распределенным
характером хранения и обработки данных в сети: ведение справочной информации
обо всех доступных в сети ресурсах и серверах, адресация взаимодействующих
процессов, обеспечение про‑
зрачности доступа, тиражирование данных, согласование копий, поддерж‑
ка безопасности данных.
^ Особенности
аппаратных платформ
На свойства операционной системы непосредственное влияние ока‑
зывают аппаратные средства, на которые она ориентирована. По типу ап‑
паратуры различают операционные системы персональных компьютеров,
мини-компьютеров, мейнфреймов, кластеров и сетей ЭВМ. Среди пере‑
численных типов компьютеров могут встречаться как однопроцессорные варианты,
так и многопроцессорные. В любом случае специфика аппарат‑
ных средств, как правило, отражается на специфике операционных систем.
Очевидно, что ОС большой машины является более сложной и мно‑
гофункциональной, по сравнению с ОС персонального компьютера. Так, в ОС больших
машин функции по планированию потока выполняемых задач, очевидно, реализуются
путем использования сложных приоритет‑
ных дисциплин и требуют большей вычислительной мощности, чем в ОС персональных
компьютеров. Аналогично обстоит дело и с другими функ‑
циями.
Сетевая ОС имеет в своем составе средства передачи сообщении ме‑
жду компьютерами по линиям связи, которые совершенно не нужны в ав‑
тономной ОС. На основе этих сообщений сетевая ОС поддерживает разде‑
ление ресурсов компьютера между удаленными пользователями, подклю‑
ченными к сети. Для поддержания функций передачи сообщений сетевые ОС содержат
специальные программные компоненты, реализующие попу‑
лярные коммуникационные протоколы, такие как IP, IPX, Ethernet и др.
Многопроцессорные системы требуют от операционной системы осо‑
бой организации, с помощью которой сама операционная система, а также
поддерживаемые ею приложения могли бы выполняться параллельно от‑
дельными процессорами системы. Параллельная работа отдельных частей ОС создает
дополнительные проблемы для разработчиков ОС, так как в этом случае гораздо
сложнее обеспечить согласованный доступ отдельных процессов к общим системным
таблицам, исключить эффект гонок и прочие нежелательные последствия
асинхронного выполнения работ.
Другие требования предъявляются к операционным системам кла‑
стеров. Кластер - слабо связанная совокупность нескольких вычислитель‑
ных систем, работающих ‑
совместно для выполнения общих приложений и представляющихся пользователю
единой системой. Наряду со специаль‑
ной аппаратурой для функционирования кластерных систем необходима и программная
поддержка со стороны операционной системы, которая сво‑
дится в основном к синхронизации доступа к разделяемым ресурсам, обна‑
ружению отказов и динамической реконфигурации системы. Одной из первых
разработок в области кластерных технологий были решения ком‑
пании Digital Equipment на базе компьютеров VAX. Этой компанией за‑
ключено соглашение с корпорацией Microsoft о разработке кластерной технологии,
использующей Windows NT. Несколько компаний предлагают кластеры на основе
UNIX-машин.
Наряду с ОС, ориентированными на совершенно определенный тип аппаратной
платформы, существуют операционные системы, специально разработанные таким
образом, чтобы они могли быть легко перенесены с компьютера одного типа на
компьютер другого типа, так называемые мо‑
бильные ОС. Наиболее ярким примером такой ОС является популярная система UNIX.
В этих системах аппаратно-зависимые места тщательно ло‑
кализованы, так что при переносе системы на новую платформу переписы‑
ваются только они. Средством, облегчающим перенос остальной части ОС, является
написание ее на машинно-независимом языке, например на С, ко‑
торый и был разработан для программирования операционных систем.
^ Особенности
областей использования
Многозадачные ОС подразделяются на три типа в соответствии с ис‑
пользованными при их разработке критериями эффективности:
реального времени (QNX, RT/11).
Системы пакетной обработки предназначались для решения задач в основном
вычислительного характера, не требующих быстрого получения результатов. Главной
целью и критерием эффективности систем пакетной обработки является максимальная
пропускная способность, т.е. решение максимального числа задач в единицу
времени. Для достижения этой цели в системах пакетной обработки используется
следующая схема функцио‑
нирования: в начале работы формируется пакет заданий, каждое задание содержит
требование к системным ресурсам; из этого пакета заданий формируется
мультипрограммная смесь, т.е. множество одновременно выполняемых задач. Для
одновременного выполнения выбираются задачи, предъявляющие отличающиеся
требования к ресурсам, так, чтобы обеспе‑
чивалась сбалансированная загрузка всех устройств вычислительной ма‑
шины: например, в мультипрограммной смеси желательно одновременное присутствие
вычислительных задач и задач с интенсивным вводом/выво‑
дом. Таким образом, выбор нового задания из пакета заданий зависит от
внутренней ситуации, складывающейся в системе, т.е. выбирается «выгод‑
ное» задание. Следовательно, в таких ОС невозможно гарантировать вы‑
полнение того или иного задания в течение определенного периода време‑
ни. В системах пакетной обработки переключение процессора с выполнения одной
задачи на другую происходит только в случае, если активная задача сама
отказывается от процессора, например, из-за необходимости ‑
выпол‑
нить операцию ввода/вывода. Поэтому одна задача может надолго занять процессор,
что делает невозможным выполнение интерактивных задач. Таким образом,
взаимодействие пользователя с вычислительной машиной, на которой установлена
система пакетной обработки, сводится к тому, что он приносит задание, отдает
его диспетчеру-оператору, а в конце дня после выполнения всего пакета заданий
получает результат. Очевидно, что такой порядок снижает эффективность работы
пользователя.
Системы разделения времени призваны исправить основной недос‑
таток систем пакетной обработки - изоляцию пользователя-программиста от
процесса выполнения его задач. Каждому пользователю системы разде‑
ления времени предоставляется терминал, с которого он может вести диа‑
лог со своей программой. Так как в системах разделения времени каждой задаче
выделяется только квант процессорного времени, ни одна задача не занимает
процессор надолго, и время ответа оказывается приемлемым. Ес‑
ли квант выбран достаточно небольшим, то у всех пользователей, одно‑
временно работающих на одной и той же машине, складывается впечатле‑
ние, что каждый из них единолично использует машину. Ясно, что систе‑
мы разделения времени обладают меньшей пропускной способностью, чем системы
пакетной обработки, так как на выполнение принимается каждая запущенная
пользователем задача, а не та, которая «выгодна» системе, и, кроме того,
имеются накладные расходы вычислительной мощности на более частое переключение
процессора с задачи на задачу. Критерием эф‑
фективности систем разделения времени является не максимальная пропу‑
скная способность, а удобство и эффективность работы пользователя.
Системы реального времени применяются для управления различ‑
ными техническими объектами, такими как станок, спутник, научная экс‑
периментальная установка, или технологическими процессами, такими как
гальваническая линия, доменный процесс и т.п. Во всех этих случаях су‑
ществует предельно допустимое время, в течение которого должна быть выполнена
та или иная программа, управляющая объектом, в противном случае может произойти
авария: спутник выйдет из зоны видимости, экс‑
периментальные данные, поступающие с датчиков, будут потеряны, тол‑
щина гальванического покрытия не будет соответствовать норме. Таким образом,
критерием эффективности для систем реального времени являет‑
ся их способность выдерживать заранее заданные интервалы времени ме‑
жду запуском программы и получением результата (управляющего воздей‑
ствия). Это время называется временем реакции системы, а соответствую‑
щее свойство системы - реактивностью. Для этих систем мультипро‑
граммная смесь представляет собой фиксированный набор заранее разра‑
ботанных программ, а выбор программы на выполнение осуществляется исходя из
текущего состояния объекта или в соответствии с расписанием плановых работ.
Некоторые операционные системы могут совмещать в себе свойства систем разных
типов, например, часть задач может выполняться в режиме пакетной обработки, а
часть - в режиме реального времени или в режиме разделения времени. В таких
случаях режим пакетной обработки часто на‑
зывают фоновым режимом.
‑
Особенности методов построения
При описании операционной системы часто указываются особенно‑
сти ее структурной организации и основные концепции, положенные в ее основу.
К таким базовым концепциям относятся:
Способы построения ядра системы - монолитное ядро или микро‑
ядерный подход. Большинство ОС использует монолитное ядро, которое компонуется
как одна программа, работающая в привилегированном ре‑
жиме и использующая быстрые переходы с одной процедуры на другую, не требующие
переключения из привилегированного режима в пользова‑
тельский, и наоборот. Альтернативой является построение ОС на базе микроядра,
работающего также в привилегированном режиме и выпол‑
няющего только минимум функций по управлению аппаратурой, в то вре‑
мя как функции ОС более высокого уровня выполняют специализирован‑
ные компоненты ОС - серверы, работающие в пользовательском режиме. При таком
построении ОС работает более медленно, так как часто выпол‑
няются переходы между привилегированным режимом и пользовательским, зато
система получается более гибкой - ее функции можно наращи‑
вать, модифицировать или сужать, добавляя, модифицируя или исключая серверы
пользовательского режима. Кроме того, серверы хорошо защище‑
ны друг от друга, как и любые пользовательские процессы.
Построение ОС на базе объектно-ориентированного подхода дает возможность
использовать все его достоинства, хорошо зарекомендовав‑
шие себя на уровне приложений, внутри операционной системы, а именно:
аккумуляцию удачных решений в форме стандартных объектов, возмож‑
ность создания новых объектов на базе имеющихся с помощью механизма
наследования, хорошую защиту данных за счет их инкапсуляции во внут‑
ренние структуры объекта, что делает данные недоступными для несанк‑
ционированного использования извне, структурированность системы, со‑
стоящей из набора хорошо определенных объектов.
Наличие нескольких прикладных сред дает возможность в рамках одной ОС
одновременно выполнять приложения, разработанные для не‑
скольких ОС. Многие современные операционные системы поддерживают одновременно
прикладные среды MS DOS, Windows, UNIX (POSIX), OS/2 или хотя бы некоторого
подмножества из этого популярного набора. Кон‑
цепция множественных прикладных сред наиболее просто реализуется в ОС на базе
микроядра, над которым работают различные серверы, часть ко‑
торых реализуют прикладную среду той или иной операционной системы.
Распределенная организация операционной системы позволяет упро‑
стить работу пользователей и программистов в сетевых средах. В распре‑
деленной ОС реализованы механизмы, которые дают возможность пользо‑
вателю представлять и воспринимать сеть в виде традиционного однопро‑
цессорного компьютера. Характерными признаками распределенной орга‑
низации ОС являются: наличие единой справочной службы разделяемых ресурсов,
единой службы времени, использование механизма вызова уда‑
ленных процедур (RPC) для прозрачного распределения программных ‑
процедур по машинам, многонитевой обработки, позволяющей распарал‑
леливать вычисления в рамках одной задачи и выполнять эту задачу сразу на
нескольких компьютерах сети, а также наличие других распределенных служб.
‑
^ 2.Особенности
ОС Unix.
UNIX появилась в 1969 году. За 30 с лишним лет система стала довольно
популярной и получила распространение на машинах с различной мощностью
обработки, от микропроцессоров до больших ЭВМ, обеспечивая на них общие условия
выполнения программ. Система делится на две части. Одну часть составляют
программы и сервисные функции – это делает операционную среду UNIX такой
популярной; данная часть ОС легко доступна пользователям, она включает такие
программы, как командный процессор, обмен сообщениями, пакеты обработки текстов
и системы обработки исходных текстов программ. Другая часть включает в себя
собственно операционную систему, поддерживающую эти программы и функции.
UNIX – традиционно сетевая операционная система.
1. Функциональные характеристики
К основным функциям ядра ОС UNIX принято относить следующие:
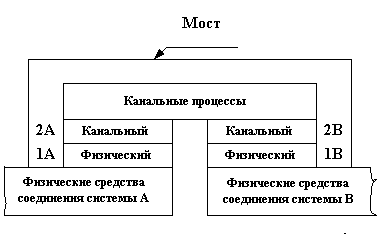
2. Особенности архитектуры ОС UNIX
Архитектура ОС UNIX – многоуровневая (рис.1). На нижнем уровне, непосредственно
над оборудованием, работает ядро операционной системы. Функции ядра доступны
через интерфейс системных вызовов, образующих второй уровень. На следующем
уровне работают командные интерпретаторы, команды и утилиты системного администрирования,
коммуникационные драйверы и протоколы, - все то, что обычно относят к
системному программному обеспечению. Наконец, внешний уровень образуют
прикладные программы пользователя, сетевые и другие коммуникационные службы,
СУБД и утилиты.
3. Способы управления процессами и ресурсами
Файлы и процессы, являются центральными понятиями модели операционной системы
UNIX. Рисунок 1. представляет блок-схему ядра системы, отражающую состав
модулей, из которых состоит ядро, и их взаимосвязи друг с другом. Слева
изображена файловая подсистема, а справа подсистема управления процессами – две
главные компоненты ядра.
‑
Рисунок.1. Блок-схема ядра операционной системы
Обращения к операционной системе выглядят так же, как обычные вызовы функций в
программах на языке Си, и библиотеки устанавливают соответствие между этими
вызовами функций и элементарными системными операциями. При этом программы на
ассемблере могут обращаться к операционной системе непосредственно, без
использования библиотеки системных вызовов. Программы часто обращаются к другим
библиотекам, таким как библиотека стандартных подпрограмм ввода-вывода,
достигая тем самым более полного использования системных услуг. Для этого во
время компиляции библиотеки связываются с программами и частично включаются в
программу пользователя. Совокупность обращений к операционной системе разделена
на те обращения, которые взаимодействуют с подсистемой управления файлами, и
те, которые взаимодействуют с подсистемой управления процессами. Файловая
подсистема управляет файлами, размещает записи файлов, управляет свободным
пространством, доступом к файлам и поиском данных для пользователей. Процессы
взаимодействуют с подсистемой управления файлами, используя при этом
совокупность специальных обращений к операционной системе, таких как open (для
того, чтобы открыть файл на чтение или запись),close, read, write, stat
(запросить атрибуты файла), chown (изменить запись с информацией о владельце
файла) и chmod (изменить права доступа к файлу).
‑
Подсистема управления файлами обращается к данным, которые хранятся в файле,
используя буферный механизм, управляющий потоком данных между ядром и
устройствами внешней памяти. Буферный механизм, взаимодействуя с драйверами
устройств ввода-вывода блоками, инициирует передачу данных к ядру и обратно.
Драйверы устройств являются такими модулями в составе ядра, которые управляют
работой периферийных устройств. Устройства ввода-вывода блоками относятся
программы пользователя к типу запоминающих устройств с произвольной выборкой;
их драйверы построены таким образом, что все остальные компоненты системы
воспринимают эти устройства как запоминающие устройства с произвольной
выборкой. Например, драйвер запоминающего устройства на магнитной ленте
позволяет ядру системы воспринимать это устройство как запоминающее устройство
с произвольной выборкой. Подсистема управления файлами также непосредственно
взаимодействует с драйверами устройств "неструктурированного"
ввода-вывода, без вмешательства буферного механизма. К устройствам неструктурированного
ввода-вывода, иногда именуемым устройствами посимвольного ввода-вывода
(текстовыми), относятся устройства, отличные от устройств ввода-вывода блоками.
Подсистема управления процессами отвечает за синхронизацию процессов,
взаимодействие процессов, распределение памяти и планирование выполнения
процессов. Подсистема управления файлами и подсистема управления процессами
взаимодействуют между собой, когда файл загружается в память на выполнение:
подсистема управления процессами читает в память исполняемые файлы перед тем,
как их выполнить.
Примерами обращений к операционной системе, используемых при управлении
процессами, могут служить fork (создание нового процесса), exec (наложение
образа программы на выполняемый процесс), exit (завершение выполнения процесса),
wait (синхронизация продолжения выполнения основного процесса с моментом выхода
из порожденного процесса), brk (управление размером памяти, выделенной
процессу) и signal (управление реакцией процесса на возникновение
экстраординарных событий.
Модуль распределения памяти контролирует выделение памяти процессам. Если в
какой-то момент система испытывает недостаток в физической памяти для запуска
всех процессов, ядро пересылает процессы между основной и внешней памятью с
тем, чтобы все процессы имели возможность выполняться. Существует два способа
управления распределением памяти: выгрузка (подкачка) и замещение страниц.
Программу подкачки иногда называют планировщиком, т.к. она
"планирует" выделение памяти процессам и оказывает влияние на работу
планировщика центрального процессора. «Планировщик» планирует очередность
выполнения процессов до тех пор, пока они добровольно не освободят центральный
процессор, дождавшись выделения какого-либо ресурса, или пока ядро системы не
выгрузит их после того, как их время выполнения превысит заранее определенный
квант времени. Планировщик выбирает на выполнение готовый к запуску процесс с
наивысшим приоритетом; выполнение предыдущего процесса (приостановленного)
будет продолжено тогда, когда его приоритет будет наивысшим среди приоритетов
всех готовых к запуску процессов. Существует несколько форм взаимодействия
процессов ‑
между собой, от асинхронного обмена сигналами о событиях до синхронного обмена
сообщениями.
Наконец, аппаратный контроль отвечает за обработку прерываний и за связь с
машиной. Такие устройства, как диски и терминалы, могут прерывать работу
центрального процессора во время выполнения процесса. При этом ядро системы
после обработки прерывания может возобновить выполнение прерванного процесса.
Прерывания обрабатываются не самими процессами, а специальными функциями ядра
системы, перечисленными в контексте выполняемого процесса.
4. Условия эксплуатации
UNIX - многопользовательская операционная система. Пользователи, занимающиеся
общими задачами, могут объединяться в группы. Каждый пользователь обязательно
принадлежит к одной или нескольким группам. Все команды выполняются от имени
определенного пользователя, принадлежащего в момент выполнения к определенной
группе.
В многопользовательских системах необходимо обеспечивать защиту объектов
(файлов, процессов), принадлежащих одному пользователю, от всех остальных. ОС
UNIX предлагает базовые средства защиты и совместного использования файлов на
основе отслеживания пользователя и группы, владеющих файлом, трех уровней
доступа (для пользователя-владельца, для пользователей группы-владельца, и для
всех остальных пользователей) и трех базовых прав доступа к файлам (на чтение,
на запись и на выполнение). Базовые средства защиты процессов основаны на
отслеживании принадлежности процессов пользователям.
Для отслеживания владельцев процессов и файлов используются числовые
идентификаторы. Идентификатор пользователя и группы - целое число (обычно) в
диапазоне от 0 до 65535. Присвоение уникального идентификатора пользователя
выполняется при заведении системным администратором нового регистрационного
имени. Значения идентификатора пользователя и группы - не просто числа, которые
идентифицируют пользователя, - они определяют владельцев файлов и процессов.
Среди пользователей системы выделяется один пользователь - системный
администратор или суперпользователь, обладающий всей полнотой прав на
использование и конфигурирование системы. Это пользователь с идентификатором 0
и регистрационным именем root.
При представлении информации человеку удобнее использовать вместо
соответствующих идентификаторов символьные имена - регистрационное имя
пользователя и имя группы. Соответствие идентификаторов и символьных имен, а
также другая информация о пользователях и группах в системе (учетные записи),
как и большинство другой информации о конфигурации системы UNIX, по традиции,
представлена в виде текстовых файлов. Эти файлы - /etc/passwd, /etc/group и
/etc/shadow.
‑
5. Достоинства и недостатки
Широкое распространение UNIX породило проблему несовместимости его
многочисленных версий. Для пользователя весьма неприятен тот факт, что пакет,
купленный для одной версии UNIX, отказывается работать на другой версии UNIX.
Периодически делались и делаются попытки стандартизации UNIX, но они пока имеют
ограниченный успех. Процесс сближения различных версий UNIX и их расхождения
носит циклический характер. Перед лицом новой угрозы со стороны какой-либо
другой операционной системы различные производители UNIX-версий сближают свои
продукты, но затем конкурентная борьба вынуждает их делать оригинальные
улучшения и версии снова расходятся. В этом процессе есть и положительная
сторона - появление новых идей и средств, улучшающих как UNIX, так и многие
другие операционные системы, перенявшие у него за долгие годы его существования
много полезного. Наибольшее распространение получили две несовместимые линии
версий UNIX: линия AT&T - UNIX System V, и линия университета Berkeley-BSD.
Многие фирмы на основе этих версий разработали и поддерживают свои версии UNIX:
SunOS и Solaris фирмы Sun Microsystems, UX фирмы Hewlett-Packard, XENIX фирмы
Microsoft, AIX фирмы IBM, UnixWare фирмы Novell (проданный теперь компании
SCO), и список этот можно еще долго продолжать.
Наибольшее влияние на унификацию версий UNIX оказали такие стандарты как SVID
фирмы AT&T, POSIX, созданный под эгидой IEEE, и XPG4 консорциума X/Open. В
этих стандартах сформулированы требования к интерфейсу между приложениями и ОС,
что дает возможность приложениям успешно работать под управлением различных версий
UNIX.
Одним из основных преимуществ семейства операционных систем типа UNIX и
возникшего на их основе подхода к стандартизации интерфейсов операционных
систем (важная часть общего подхода открытых систем) является то, что они
обеспечивают единую операционную среду на компьютерах с разной архитектурой.
‑
Заключение
Операционная система UNIX, являющаяся первой в истории мобильной ОС,
обеспечивающей надежную среду разработки и использования мобильных прикладных
систем, одновременно представляет собой практическую основу для построения
открытых программно-аппаратных систем и комплексов. Именно широкое внедрение в
практику ОС UNIX позволило перейти от лозунга Открытых Систем к практической
разработке этой концепции. Большой вклад в развитие направления Открытых Систем
внесла деятельность по стандартизации интерфейсов ОС UNIX.
Можно выделить несколько ветвей ОС UNIX, различающихся не только реализацией,
но временами интерфейсами и семантикой (хотя, по мере развития процесса
стандартизации, эти различия становятся все менее значительными). Сегодня
популярен новый свободно распространяемый вариант ОС UNIX, называемый FreeBSD.
Ведутся работы над более развитыми версиями BSDNet.
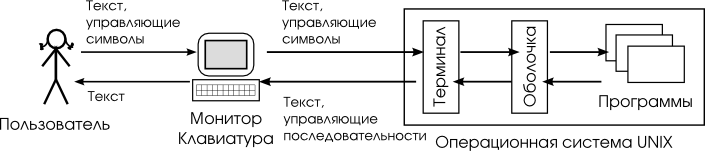
Основная среда взаимодействия с UNIX – командная строка. Суть её в том, что каждая строка, передаваемая пользователем системе, – это команда, которую та должна выполнить. Пока не нажата клавиша Enter, строку можно редактировать, затем она отсылается системе.
Команды интерпретируются и выполняются специальной программой – командной оболочкой (или «shell», по-английски). Через командную оболочку производится управление пользовательскими процессами – для этого используются средства межпроцессного обмена, описанные ранее (см. «Межпроцессное взаимодействие»).
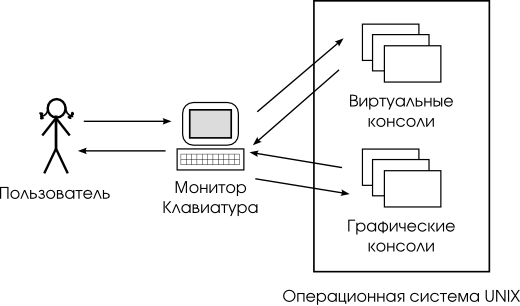
Командная оболочка непосредственно связана с терминалом, через который осуществляется передача управляющих последовательностей и текста. На рисунке Рисунок 2.1, «Интерфейс командной строки» представлена общая схема взаимодействия пользователя с системой при использовании командной строки.
Рисунок 2.1. Интерфейс командной строки
Презентация 3-02: одновременный доступ к системе
То, что UNIX – многопользовательская и многозадачная система, проявляется не только в разграничении прав доступа (см. раздел Глава 3, Безопасность операционной системы UNIX), но и в организации рабочего места. Каждый компьютер, на котором работает UNIX, предоставляет возможность зарегистрироваться и получить доступ к системе нескольким пользователям одновременно. Даже если в распоряжении всех пользователей есть только один монитор и одна системная клавиатура, эта возможность небесполезна: одновременная регистрация в системе нескольких пользователей позволяет работать по очереди без необходимости каждый раз завершать все начатые задачи (закрывать все окна, прерывать исполнение всех программ) и затем возобновлять их. Более того, ничто не препятствует зарегистрироваться в системе несколько раз под одним и тем же входным именем. Таким образом, можно получить доступ к одним и тем же ресурсам (своим файлам) и организовать параллельную работу над несколькими задачами.
Характерный для современных версий UNIX способ организации параллельной работы пользователей – виртуальные консоли. Виртуальные консоли (virtual console) – это несколько параллельно выполняемых операционной системой программ, предоставляющих пользователю возможность зарегистрироваться в системе в текстовом режиме и получить доступ к командной строке (см. Рисунок 2.2, «Виртуальные и графические консоли»).
В операционной системе Linux переключение между виртуальными консолями в
текстовом режиме производится с помощью комбинации клавиш Alt+F1,
Alt+F2 и т.п.. При этом каждая виртуальная
консоль обозначается специальным именем: «tty1», «tty2» и т.д.. По умолчанию в Linux доступно не менее шести
виртуальных консолей, переключаться между которыми можно при помощи сочетания
клавиши Alt с одной из функциональных клавиш (F1-F6).
С каждым сочетанием связана соответствующая по номеру виртуальная консоль.
Виртуальные консоли обозначаются «ttyN», где «N» – номер виртуальной консоли. На самом деле, каждая
из таких конолей связано с собственным терминалом, который
характеризуется файлом устройства с соответствующим именем (например, /dev/tty1).
Современные версии UNIX предоставляют пользователям графические пользовательские интерфейсы (подробнее графическая подсистема UNIX рассматривается в разделе Глава 7, Графическая подсистема UNIX), которые также дают возможность работы в командной строке. Эта возможность достигается с помощью графических терминалов – специальных программ, которые эмулируют текстовый терминал в графическом окне.
Также существует возможность запуска нескольких графических подсистем, тогда переключение между ними будет осуществляться аналогично переключению между виртуальными консолями – комбинацией клавиш Ctrl+Alt+F1.
Рисунок 2.2. Виртуальные и графические консоли
Каждое устройство терминала имеет свои возможности по вводу и
выводу информации. Примерати таких возможностей являются: число цветов
отображения, способность перемещать курсор и изменять размер экрана, набор
управляющих символов и т.п.. Терминалы разделяют по типам:
набору возможностей, регламентированных в специальном конфигурационном файле.
Примерами типов являются: tty (телетайп) или xterm (графический терминал). Тип
терминала явно указан в имени устройства терминала (например, /dev/tty1). Все настройки типов
терминалов находятся в директории /etc/termcap.
Презентация 3-03: формат командной строки
Командная строка состоит из приглашения и вводимой команды. Приглашение – это специальная последовательность символов, которая располагается в начале строки и задает начало области ввода команды. Рассмотрим пример выполнения команды:
Пример 2.1. Пример выполнения команды
user@desktop ~ $ date
Втр Окт 4 23:15:37 MSD 2005
user@desktop ~ $
Здесь приглашением является строка user@desktop
~ $, которая помимо символа начала ввода ($) содержит информацию
об имени пользователя, имени компьютера и текущей директории.
Каждая команда UNIX состоит из следующих частей:
Имя команды
Идентификатор команды, совпадающий с именем программы, которая запускается для исполнения команды. Некоторые команды (такие как echo) являются встроенными для данной командной оболочки и для их выполнения вызывается не программа, а внутренняя функция оболочки.
Параметры или ключи или флаги или опции
Команда может иметь один или несколько
параметров, разделённых пробелом. Параметры могут быть однобуквенными (как -l) или полнословными (например, --help). Однобуквенные параметры
могут группироваться, например запуск команды ls -al
эквивалентен запуску ls -a -l. Некоторые параметры состоят из
имени и аргумента, например в коменде grep -f access.log -n test
имя файла access.log –
часть параметра -f.
Аргументы
Некоторые команды могут иметь аргументы. Аргументом может являться текстовая строка, соответвтующая имени файла или другого объекта. Аргументы также разделяются символом пробела, чтобы передать в качестве аргумента строку символов с пробелами, можно воспользоваться символами кавычек:
user@desktop ~ $ echo "Hello, world."Hello, world.
Перенаправления
Стандартный ввод и вывод каждой команды (см. «Межпроцессное взаимодействие») может быть перенаправлен в файл. По умолчанию ввод и вывод команды связываются с пользовательским терминалом. Для указания источника ввода или назначения вывода (для обычной информации и для ошибок отдельно) используются специальные символы (<, > и >>).
Как правило, порядок данных частей команды должен быть именно таким, однако некоторые из них (кроме имени команды) могут отсутствовать.
Презентация 3-04: исполнение команды
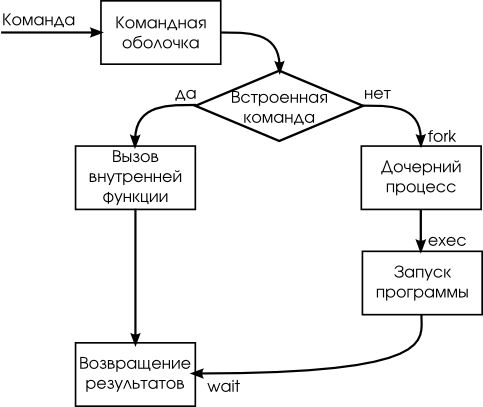
Командная оболочка – это обычный процесс в операционной системе UNIX. Когда пользователь вводит команду (например, по нажатию Enter), командная оболочка выполняет следующие действия:
Рисунок 2.3. Запуск команды оболочкой
Презентация 3-05: возвращаемое значение
Каждый процесс при завершении возвращает своему родительскому процессу специальный код завершения программы. Этот код может использоваться для получения результата выполнения программы и для проверки корректности её выполнения (возврата кода ошибки).
Традиционно для UNIX, в случае успешного выполнения программа (а также
большинство системных функций) возвращает значение 0. Другие значения (все, отличные от 0) означают тот или иной вид ошибки. Так
как программы часто выводят инфоромацию об ошибках через специальный поток
вывода ошибок (stderr), возвращаемые значения чаще всего могут принимать
только два значения: «ноль» и «не
ноль».
Если рассмотреть простейший пример программы на языке C:
видно, что программы передают код завершения через
возвращаемое значение главной функции (main)
или как параметр функции exit.
В командной строке результат выполнения программы можно проанализировать с
помощью специальной переменной ($?):
user@desktop ~ $ test -f /tmp/file.txtuser@desktop ~ $ echo $?
Организация файловой системы UNIX имеет древовидную структуру, вершина которой называется корнем, а сама структура называется файловым деревом. Каждая вершина в файловом дереве, за исключением листьев, является каталогом, листья же в свою очередь являются либо обычными файлами, либо файлами устройств (Рис. 1).
|
Рисунок 1: Структура файловой системы UNIX с точки зрения пользователя |
|
[IMAGE ] |
Для того, чтобы добраться до файла необходимо указать его имя, которому предшествует указание пути поиска, который описывает местоположение файла в файловом дереве. Путь поиска состоит из компонент, разделенных между собой наклонной чертой (``/''), которые представляют из себя последовательность вершин в файловом дереве, которые необходимо посетить, чтобы достигнуть требуемый файл. Путь поиска может начинаться в корне, в этом случае первая компонента пути записывается как ``/'' (например ``/usr/src/cmd/date.c''). Такой путь называется полным. Также путь может отсчитываться относительно текущей директории (например если текущей директорией является ``cmd'', то путь ``date.c'' соответствует пути ``/usr/src/cmd/date.c'').
В файловой системе UNIX также существует понятие прав доступа к файлу. Права доступа к файлу регулируются установкой специальных битов разрешения доступа, связанных с файлом. Устанавливая биты разрешения доступа, можно независимо управлять выдачей разрешений на чтение, запись и выполнение для трех категорий пользователей: владельца файла, группового пользователя и прочих. Пользователи также могут создавать файлы, если разрешен доступ к каталогу. Вновь созданные файлы становятся листьями в древовидной структуре файловой системы.
Устройства в системе UNIX трактуются так, как если бы они были файлами. Обращение программ к устройствам имеет тот же самый синтаксис, что и обращение к обычным файлам; семантика операций чтения и записи по отношению к устройствам в большой степени совпадает с семантикой операций чтения и записи обычных файлов. Способ защиты устройств совпадает со способом защиты обычных файлов: путем соответствующей установки битов разрешения доступа к ним. Поскольку имена устройств выглядят так же, как и имена обычных файлов, и поскольку над уст- ройствами и над обычными файлами выполняются одни и те же операции, большинству программ нет необходимости различать внутри себя типы обрабатываемых файлов.
Итак, файловая система UNIX характеризуется:
Операционная система выполняет две основные задачи: манипулирование данными и их хранение. Большинство программ в основном манипулирует данными, но, в конечном счете, они где-нибудь хранятся. В системе UNIX таким местом хранения является файловая система. Более того, в UNIX все устройства, с которыми работает операционная система, также представлены в виде специальных файлов в файловой системе.
Логическая файловая система в ОС UNIX (или просто файловая система) - это иерархически организованная структура всех каталогов и файлов в системе, начинающаяся с корневого каталога. Файловая система UNIX обеспечивает унифицированный интерфейс доступа к данным, расположенным на различных носителях, и к периферийным устройствам. Логическая файловая система может состоять из одной или нескольких физических файловых (под)систем, являющихся разделами физических носителей (дисков, CD-ROM или дискет).
Файловая система контролирует права доступа к файлам, выполняет операции создания и удаления файлов, а также выполняет запись/чтение данных файла. Поскольку большинство прикладных функций выполняется через интерфейс файловой системы, следовательно, права доступа к файлам определяют привилегии пользователя в системе.
Файловая система обеспечивает перенаправление запросов, адресованных периферийным устройствам, соответствующим модулям подсистемы ввода-вывода.
Иерархическая структура файловой системы UNIX упрощает ориентацию в ней. Каждый каталог, начиная с корневого (/), в свою очередь, содержит файлы и другие каталоги (подкаталоги). Каждый каталог содержит также ссылку на родительский каталог (для корневого каталога родительским является он сам), представленную каталогом с именем две точки (..) и ссылку на самого себя, представленную каталогом с именем точка (.).
Каждый процесс имеет текущий каталог. Сразу после регистрации текущим каталогом пользователя (на самом деле, процесса - начальной программы, обычно, командного интерпретатора) становится начальный каталог, указанный в файле /etc/passwd.
Каждый процесс может сослаться (назвать) на любой файл или каталог в файловой системе по имени. Способам задания имен файлов посвящен следующий подраздел.
В ОС UNIX поддерживается три способа указания имен файлов:
Другие символы, кроме косой черты, не имеют в именах файлов UNIX особого значения (это не метасимволы). В частности, нет системного понятия расширения файла.
В ОС UNIX нет теоретических ограничений на количество вложенных каталогов. Тем не менее, в каждой реализации имеются практические ограничения на максимальную длину имени файла, которое указывается в командах (как и на длину командной строки в целом). Оно задается константой PATH_MAX в заголовочном файле /usr/include/limits.h. Так, в ОС Solaris 8 имя файла не может быть длиннее 1024 символов.
Команда pwd выдает полное имя текущего (рабочего) каталога. Команда pwd не имеет параметров. Вот пример ее использования:
$ pwd
/home/user01
$
Для изменения текущего каталога используется команда cd:
cd [каталог]
Если каталог не указан, используется значение переменной среды $HOME (обычно это начальный каталог пользователя). Чтобы сделать новый каталог текущим (войти в каталог), нужно иметь для него право на выполнение. Команда cd является встроенной командой интерпретатора и использует для изменения текущего каталога соответствующий системный вызов.
Рассмотрим пример совместного использования команд cd и pwd для переходов по каталогам файловой системы:
$ pwd/home/user01$ cd ..$ pwd/home$ cd user01/tmp$ pwd/home/user/tmp$ cd
$ pwd
/home/user01
Для просмотра информации о типах (и других атрибутах) файлов в ОС UNIX используется команда ls со следующим синтаксисом:
ls [-abCcdeFfgiLlmnopqRrstux1] [файл ...]
Команда ls выдает информацию об указанных файлах или о файлах и каталогах в текущем каталоге (если файл не задан). Формат и подробность выдаваемой информации зависит от опций. Основные опции команды ls представлены в табл. 10:
Таблица 10. Основные опции команды ls
|
Опция |
Назначение |
|
-a |
Выдает все файлы и подкаталоги, включая те, имена которых начинаются с точки (.). По умолчанию такие файлы не выдаются (они считаются скрытыми). |
|
-F |
Добавляет к имени файла суффикс, показывающий его тип (см. следующий раздел). Помечает каталоги косой чертой (/), выполняемые файлы - звездочкой (*), именованные каналы (FIFO) - вертикальной чертой (|), символические связи - "собакой" (@), а сокеты - знаком равенства (=). |
|
-i |
Для каждого файла выдает в первом столбце листинга номер индексного дескриптора (i-node). Об индексных дескрипторах см. в разделе, посвященном физическим файловым системам UNIX. |
|
-l |
Выдает длинный листинг, включающий права доступа, количество связей, владельца, группу, размер в байтах, время последнего изменения каждого файла и, естественно, имя файла. Если файл является специальным файлом устройства, вместо размера выдаются главный и второстепенный номера устройства. Если с момента последнего изменения прошло более 6 месяцев, оно обычно выдается в формате 'месяц день год'. Для файлов, измененных позднее, чем 6 месяцев назад, время выдается в формате 'месяц день время'. Если файл является символической связью, в длинном листинге после имени файла указывается стрелочка (->) и имя файла, на который связь ссылается. |
|
-r |
Изменяет порядок сортировки на обратный стандартному (обратный лексикографический или сначала самые старые файлы, в зависимости от других опций). |
|
-R |
Рекурсивно выдает содержимое подкаталогов. |
|
-t |
Сортирует листинг по временной отметке (сначала - самые новые), а не по имени файла. По умолчанию используется время последнего изменения. (Опции -u и -c позволяют сортировать по времени последнего обращения и времени создания, соответственно.) |
Как видно из синтаксиса, можно задавать одновременно несколько опций. Вот как можно посмотреть подробную информацию о файлах в каталоге /tmp, начиная с самых давно изменявшихся:
С помощью каталогов формируется логическое дерево файловой системы. Каталог - это файл, содержащий имена находящихся в нем файлов, а также указатели на дополнительную информацию - метаданные, позволяющие операционной системе производить действия с этими файлами. Каталоги определяют положение файла в дереве файловой системы. Любой процесс, имеющий право на чтение каталога, может прочесть его содержимое, но только ядро имеет право на запись данных каталога.
Типы файлов
Категория: Файловая
система | Автор: admin |
30-09-2009, 04:40 | Просмотров: 1898 ![]()
В большинстве файловых систем поддерживается семь типов файлов:
· обычные файлы;
· каталоги;
· файлы байт-ориентированных (символьных) устройств;
· файлы блок-ориентированных (блочных) устройств;
· сокеты;
· именованные каналы (FIFO);
· символические ссылки.
В некоторых системах не реализована поддержка таких типов файлов, как сокеты или именованные каналы.
Обычные файлы
Обычный файл — это просто последовательность байтов. В UNIX не накладывается ограничений на его структуру. Текстовые документы, исполняемые программы, библиотеки функций и многое другое — все это хранится в обычных файлах. К ним возможен как последовательный, так и прямой доступ.
Каталоги
Каталог содержит именованные ссылки на другие файлы. Он создается командой mkdir и удаляется (если пустой) командой rmdir. Каталоги, в которых есть файлы, можно удалить командой rm -r.
Специальные ссылки ‘.’ и ‘..’ обозначают соответственно сам каталог и его родительский каталог. Их нельзя удалить. Поскольку у корневого каталога нет родителя, ссылка ‘..’ в нем эквивалентна ссылке ‘.’.
Имя файла хранится в родительском каталоге, а не в самом файле. На файл можно ссылаться из нескольких каталогов одновременно и даже из нескольких элементов одного и того же каталога, причем у всех ссылок могут быть разные имена. Это создает иллюзию того, что файл в одно и то же время находится в разных каталогах.
Ссылку невозможно отличить от имени файла, на который она указывает: в UNIX они идентичны. UNIX подсчитывает количество ссылок, указывающих на каждый файл, и при удалении файла не освобождает блоки данных до тех пор, пока не будет удалена его последняя ссылка. Ссылки можно задавать только в пределах одной файловой системы.
Ссылки такого рода обычно называют "жесткими", чтобы отличить их от символических ("мягких") ссылок, которые описаны ниже. Жесткие ссылки создаются командой ln, а удаляются командой rm.
Синтаксис команды ln легко запомнить, так как она повторяет работу команды ср. Команда
ср oldfile newfile
создает копию файла oldfile под именем newfile. Точно так же, команда
ln oldfile newfile
создает новую ссылку newfile на файл oldfile.
Важно понимать, что жесткие ссылки не являются отдельным типом файлов. Просто файловая система позволяет создавать ссылки на один и тот же файл в разных каталогах. Атрибуты файла, в частности права доступа и идентификатор владельца, являются общими для всех ссылок.
Файлы байт-ориентированных и блок-ориентированных устройств
Файлы устройств позволяют UNIX-программам взаимодействовать с аппаратными средствами и периферийными устройствами системы. При конфигурировании ядра к нему подключаются те модули, которые знают, как взаимодействовать с каждым из имеющихся устройств*. За всю работу по управлению конкретным устройством отвечает специальная программа, называемая драйвером устройства.
Драйверы устройств образуют стандартный коммуникационный интерфейс, который выглядит для пользователя как обычный файл. Когда ядро получает запрос к файлу байт-ориентированного или блок-ориентированного устройства, оно просто передает этот запрос соответствующему драйверу. Важно отличать файлы устройств от драйверов устройств. Файлы сами по себе не являются драйверами. Их можно представить как шлюзы, через которые драйверу передаются запросы.
Файлы байт-ориентированных устройств позволяют связанным с ними драйверам выполнять свою собственную буферизацию ввода-вывода. Файлы блок-ориентированных устройств обрабатываются драйверами, которые осуществляют ввод-вывод большими порциями (блоками) и возлагают обязанности по выполнению задач буферизации на ядро. Аппаратные средства некоторых типов, такие как накопители на жестких дисках и магнитных лентах, могут быть представлены файлами любого типа.
В системе может присутствовать несколько однотипных устройств. Поэтому файлы устройств характеризуются двумя номерами: старшим и младшим. Старший номер устройства говорит ядру о том, к какому драйверу относится данный файл, а младший номер сообщает драйверу, к какому физическому устройству следует обращаться. Например, старший номер устройства 6 в Linux обозначает драйвер параллельного порта. Первый параллельный порт (/dev/lp0) будет иметь старший номер 6 и младший номер 0.
Некоторые драйверы используют младший номер устройства нестандартным способом. Например, драйверы накопителей на магнитных лентах часто руководствуются им при выборе плотности записи и для определения того, необходимо ли перемотать ленту после закрытия файла устройства. В некоторых системах "драйвер терминала" (который на самом деле управляет всеми последовательными устройствами) применяет младшие номера устройств для того, чтобы отличать модемы, используемые для вызова удаленных систем, от модемов, работающих на прием сообщений.
Файлы устройств можно создавать командой mknod. а удалять — командой rm. В большинстве систем имеется командный сценарий MAKEDEV (обычно находится в каталоге /dev), который создает стандартные наборы управляющих файлов для основных устройств. Прежде чем бездумно вызывать этот сценарий, просмотрите его текст, чтобы понять, что конкретно он делает в вашей системе.
Сокеты
Сокеты инкапсулируют соединения между процессами, позволяя им взаимодействовать, не подвергаясь влиянию других процессов. В UNIX поддерживается несколько видов сокетов, использование которых в большинстве своем предполагает наличие сети. Сокеты UNIX локальны для конкретного компьютера. Обращение к ним осуществляется через объект файловой системы, а не через сетевой порт.
Несмотря на то что другие процессы распознают файлы сокетов как элементы каталога, процессы, не участвующие в соединении, не могут осуществлять над этими файлами операции чтения и записи. С сокетами работают система печати, система X Window и система Syslog.
Сокеты создаются с помощью системного вызова socket. Когда с обеих сторон соединение закрыто, сокет можно удалить посредством команды rm либо системного вызова unlink.
Именованные каналы
Подобно сокетам, именованные каналы обеспечивают взаимодействие двух процессов, выполняемых на одной машине. Именованные каналы создаются командой mknod, а удаляются командой rm.
Символические ссылки
Символическая, или "мягкая", ссылка обеспечивает возможность вместо путевого имени файла указывать псевдоним. Когда ядро сталкивается с символической ссылкой при поиске файла, оно извлекает из нее хранящееся в ней путевое имя. Различие между жесткими и символическими ссылками состоит в том, что жесткая ссылка — прямая, т.е. указывает непосредственно на индексный дескриптор файла, тогда как символическая ссылка указывает на файл по имени. Файл, адресуемый символической ссылкой, и сама ссылка физически являются разными объектами файловой системы.
Символические ссылки создаются командой ln -s, а удаляются командой rm. Поскольку они содержат произвольное путевое имя, то могут указывать на файлы, хранящиеся в других файловых системах, и даже на несуществующие файлы. Иногда несколько символических ссылок образуют цикл.
Символическая ссылка может содержать либо абсолютное, либо относительное путевое имя. Например, команда
In -s ../../ufs /usr/include/bsd/sys/ufs
связывает имя /usr/include/bsd/sys/ufs с каталогом /usr/include/ufs с помощью относительного пути. Каталог /usr/include можно переместить куда угодно, но символическая ссылка, тем не менее, останется корректной.
Остерегайтесь использовать обозначение ".." в путевых именах, включающих символические ссылки, поскольку по символическим ссылкам нельзя проследовать в обратном направлении. Ссылка всегда обозначает истинный родительский каталог данного файла или каталога. Например, в приведенной выше ссылке путь
/usr/include/bsd/sys/ufз/../param.h
раскрывается как
/usг/include/param.h
а не
/usr/include/bsd/sys/param.h
Распространенная ошибка — думать, будто первый аргумент команды ln -s как-то связан с текущим каталогом. На самом деле он не раскрывается командой ln, а записывается в символическую ссылку буквально.
Архитектура вычислительных систем
1. Элементы последовательной логики. Основные операционные элементы цифровой техники
Триггер (триггерная система) — класс электронных устройств, обладающих способностью длительно находиться в одном из двух устойчивых состояний и чередовать их под воздействием внешних сигналов. Каждое состояние триггера легко распознаётся по значению выходного напряжения. По характеру действия триггеры относятся к импульсным устройствам — их активные элементы (транзисторы, лампы) работают в ключевом режиме, а смена состояний длится очень короткое время.
Отличительной особенностью триггера как функционального устройства является свойство запоминания двоичной информации. Под памятью триггера подразумевают способность оставаться в одном из двух состояний и после прекращения действия переключающего сигнала. Приняв одно из состояний за «1», а другое за «0», можно считать, что триггер хранит (помнит) один разряд числа, записанного в двоичном коде.
При изготовлении триггеров применяются преимущественно полупроводниковые приборы (обычно биполярные и полевые транзисторы), в прошлом — электромагнитные реле, электронные лампы. В настоящее время логические схемы, в том числе с использованием триггеров, создают в интегрированных средах разработки под различные программируемые логические интегральные схемы (ПЛИС). Используются, в основном, в вычислительной технике для организации компонентов вычислительных систем: регистров, счётчиков, процессоров, ОЗУ.
![]()
Рис. 3. Временная диаграмма работы динамического триггера
![]()
Рис. 4. Симметричные триггеры: а — с непосредственной связью между каскадами; б — с резистивной связью
![]()
Рис. 5. Функциональная классификация триггеров
![]()
Рис. 6. Классификация триггеров по способу ввода информации
Триггеры подразделяются на две большие группы — динамические и статические. Названы они так по способу представления выходной информации.
Динамический триггер представляет собой управляемый генератор, одно из состояний которого (единичное) характеризуется наличием на выходе непрерывной последовательности импульсов определённой частоты, а другое (нулевое) — отсутствием выходных импульсов. Смена состояний производится внешними импульсами (рис. 3). Динамические триггеры в настоящее время используются редко.
К статическим триггерам относят устройства, каждое состояние которых характеризуется неизменными уровнями выходного напряжения (выходными потенциалами): высоким — близким к напряжению питания и низким — около нуля. Статические триггеры по способу представления выходной информации часто называют потенциальными.
Статические (потенциальные) триггеры, в свою очередь, подразделяются на две неравные по практическому значению группы — симметричные и несимметричные триггеры. Оба класса реализуются на двухкаскадном двухинверторном усилителе с положительной обратной связью, а названием своим они обязаны способам организации внутренних электрических связей между элементами схемы.
Симметричные триггеры отличает симметрия схемы и по структуре, и по параметрам элементов обоих плеч. Для несимметричных триггеров характерна неидентичность параметров элементов отдельных каскадов, а также и связей между ними.
Симметричные статические триггеры составляют основную массу триггеров, используемых в современной радиоэлектронной аппаратуре. Схемы симметричных триггеров в простейшей реализации (2х2ИЛИНЕ) показаны на рис. 4.
Основной и наиболее общий классификационный признак — функциональный — позволяет систематизировать статические симметричные триггеры по способу организации логических связей между входами и выходами триггера в определённые дискретные моменты времени до и после появления входных сигналов. По этой классификации триггеры характеризуются числом логических входов и их функциональным назначением (рис. 5).
Вторая классификационная схема, независимая от функциональной, характеризует триггеры по способу ввода информации и оценивает их по времени обновления выходной информации относительно момента смены информации на входах (рис. 6).
Каждая из систем классификации характеризует триггеры по разным показателям и поэтому дополняет одна другую. К примеру, триггеры RS-типа могут быть в синхронном и асинхронном исполнении.
Асинхронный триггер изменяет своё состояние непосредственно в момент появления соответствующего информационного сигнала(ов), с некоторой задержкой равной сумме задержек на элементах, составляющих данный триггер.
Синхронные триггеры реагируют на информационные сигналы только при наличии соответствующего сигнала на так называемом входе синхронизации С (от англ. clock). Этот вход также обозначают термином «такт». Такие информационные сигналы называют синхронными. Синхронные триггеры в свою очередь подразделяют на триггеры со статическим и с динамическим управлением по входу синхронизации С.
Триггеры со статическим управлением воспринимают информационные сигналы при подаче на вход С логической единицы (прямой вход) или логического нуля (инверсный вход).
Триггеры с динамическим управлением воспринимают информационные сигналы при изменении (перепаде) сигнала на входе С от 0 к 1 (прямой динамический С-вход) или от 1 к 0 (инверсный динамический С-вход). Также встречается название «триггер управляемый фронтом».
Одноступенчатые триггеры (latch, защёлки) состоят из одной ступени представляющей собой элемент памяти и схему управления, бывают, как правило, со статическим управлением. Одноступенчатые триггеры с динамическим управлением применяются в первой ступени двухступенчатых триггеров с динамическим управлением. Одноступенчатый триггер на УГО обозначают одной буквой - Т.
Двухступенчатые триггеры (flip-flop, шлёпающие) делятся на триггеры со статическим управлением и триггеры с динамическим управлением. При одном уровне сигнала на входе С информация, в соответствии с логикой работы триггера, записывается в первую ступень (вторая ступень заблокирована для записи). При другом уровне этого сигнала происходит копирование состояния первой ступени во вторую (первая ступень заблокирована для записи), выходной сигнал появляется в этот момент времени с задержкой равной задержке срабатывания ступени. Обычно двухступенчатые триггеры применяются в схемах, где логические функции входов триггера зависят от его выходов, во избежание временны́х гонок. Двухступенчатый триггер на УГО обозначают двумя буквами - ТТ.
Триггеры со сложной логикой бывают также одно- и двухступенчатые. В этих триггерах наряду с синхронными сигналами присутствуют и асинхронные. Такой триггер изображён на рис. 1, верхний (S) и нижний (R) входные сигналы являются асинхронными.
Триггерные схемы классифицируют также по следующим признакам:
Триггер — это запоминающий элемент с двумя (или более) устойчивыми состояниями, изменение которых происходит под действием входных сигналов и предназначен для хранения одного бита информации, то есть лог. 0 или лог. 1.
Все разновидности триггеров представляют собой элементарный автомат, включающий собственно элемент памяти (ЭП) и комбинационную схему (КС), которая может называться схемой управления или входной логикой (рис. 7).
![]()
Рис. 7 структура триггеров в виде КС и ЭП
В графе триггера каждая вершина графа соединена со всеми другими вершинами, при этом переходы от вершины к вершине возможны в обе стороны (двухсторонние). Граф двоичного триггера — две точки соединённые отрезком прямой линии, троичного триггера — треугольник, четверичного триггера — квадрат с диагоналями, пятеричного триггера — пятиугольник с пентаграммой и т. д. При N=1 граф триггера вырождается в одну точку, в математике ему соответствует унарная единица или унарный ноль, а в электронике — монтажная «1» или монтажный «0», то есть простейшее ПЗУ. Устойчивые состояния имеют на графе триггера дополнительную петлю, которая обозначает, что при снятии управляющих сигналов триггер остаётся в установленном состоянии.
Состояние триггера определяется сигналами на прямом и инверсном выходах. При положительном кодировании (позитивная логика) высокий уровень напряжения на прямом выходе отображает значение лог. 1 (состояние = 1), а низкий уровень — значение лог. 0 (состояние = 0). При отрицательном кодировании (негативная логика) высокому уровню (напряжению) соответствует логическое значение «0», а низкому уровню (напряжению) соответствует логическое значение «1».
Изменение состояния триггера (его переключение или запись) обеспечивается внешними сигналами и сигналами обратной связи, поступающими с выходов триггера на входы схемы управления (комбинационной схемы или входной логики). Обычно внешние сигналы, как и входы триггера, обозначают латинскими буквами R, S, T, C, D, V и др. В простейших схемах триггеров отдельная схема управления (КС) может отсутствовать. Поскольку функциональные свойства триггеров определяются их входной логикой, то названия основных входов переносятся на всю схему триггера.
Входы триггеров разделяются на информационные (R, S, T и др.) и управляющие (С, V). Информационные входы предназначены для приема сигналов запоминаемой информации. Названия входных сигналов отождествляют с названиями входов триггера. Управляющие входы служат для управления записью информации. В триггерах может быть два вида управляющих сигналов:
На V-входы триггера поступают сигналы, которые разрешают (V=1) или запрещают (V=0) запись информации. В синхронных триггерах с V-входом запись информации возможна при совпадении сигналов на информационном С и V-входах.
Работа триггеров описывается с помощью таблицы переключений, являющейся аналогом таблицы истинности для комбинационной логики. Выходное состояние триггера обычно обозначают буквой Q. Индекс возле буквы означает состояние до подачи сигнала (t) либо (t-1) или после подачи сигнала (t+1) или (t). В триггерах с парафазным (двухфазным) выходом имеется второй (инверсный) выход, который обозначают как Q, /Q или Q'.
Кроме табличного определения работы триггера существует формульное задание
функции триггера в секвенциальной логике. Например, функцию
RS-триггера в секвенциальной логике представляет формула ![]() . Аналитическая запись
SR-триггера выглядит так:
. Аналитическая запись
SR-триггера выглядит так: ![]() .
.
|
S |
R |
Q(t) |
Q(t) |
Q(t+1) |
Q(t+1) |
|
0 |
0 |
0 |
1 |
0 |
1 |
|
0 |
0 |
1 |
0 |
1 |
0 |
|
0 |
1 |
0 |
1 |
0 |
1 |
|
0 |
1 |
1 |
0 |
0 |
1 |
|
1 |
0 |
0 |
1 |
1 |
0 |
|
1 |
0 |
1 |
0 |
1 |
0 |
|
1 |
1 |
0 |
1 |
не определено |
не определено |
|
1 |
1 |
1 |
0 |
не определено |
не определено |
![]()
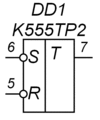
Асинхронный RS-триггер с инверсными входами
RS-триггер[10][11], или SR-триггер — триггер, который сохраняет своё предыдущее состояние при нулевых входах и меняет своё выходное состояние при подаче на один из его входов единицы.
При подаче единицы на вход S (от англ. Set — установить) выходное состояние становится равным логической единице. А при подаче единицы на вход R (от англ. Reset — сбросить) выходное состояние становится равным логическому нулю. Состояние, при котором на оба входа R и S одновременно поданы логические единицы, в простейших реализациях является запрещённым (так как вводит схему в режим генерации), в более сложных реализациях RS-триггер переходит в третье состояние QQ=00. Одновременное снятие двух «1» практически невозможно. При снятии одной из «1» RS-триггер переходит в состояние, определяемое оставшейся «1». Таким образом RS-триггер имеет три состояния, из которых два устойчивых (при снятии сигналов управления RS-триггер остаётся в установленном состоянии) и одно неустойчивое (при снятии сигналов управления RS-триггер не остаётся в установленном состоянии, а переходит в одно из двух устойчивых состояний).
RS-триггер используется для создания сигнала с положительным и отрицательным фронтами, отдельно управляемыми посредством стробов, разнесённых во времени. Также RS-триггеры часто используются для исключения так называемого явления дребезга контактов.
RS-триггеры иногда называют RS-фиксаторами[12].
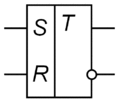
Условное графическое обозначение асинхронного RS-триггера
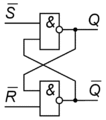
Логическая схема асинхронного RS-триггера на элементах 2И–НЕ
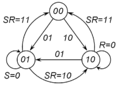
Граф переходов асинхронного RS-триггера
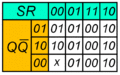
Карта Карно асинхронного RS-триггера
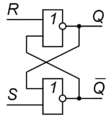
Асинхронный RS-триггер на логических элементах 2ИЛИ-НЕ
Схема устранения дребезга контактов
|
C |
S |
R |
Q(t) |
Q(t+1) |
|
0 |
x |
x |
0 |
0 |
|
1 |
1 |
|||
|
1 |
0 |
0 |
0 |
0 |
|
1 |
0 |
0 |
1 |
1 |
|
1 |
0 |
1 |
0 |
0 |
|
1 |
0 |
1 |
1 |
0 |
|
1 |
1 |
0 |
0 |
1 |
|
1 |
1 |
0 |
1 |
1 |
|
1 |
1 |
1 |
0 |
не определено |
|
1 |
1 |
1 |
1 |
не определено |
Схема синхронного RS-триггера совпадает со схемой одноступенчатого парафазного (двухфазного) D-триггера, но не наоборот, так как в парафазном (двухфазном) D-триггере не используются комбинации S=0, R=0 и S=1, R=1.
Алгоритм функционирования синхронного RS-триггера можно представить формулой
![]()
где x — неопределённое состояние.

Условное графическое обозначение синхронного RS-триггера
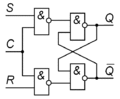
Схема синхронного RS-триггера на элементах 2И-НЕ
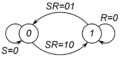
Граф переходов синхронного RS-триггера
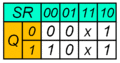
Карта Карно синхронного RS-триггера
![]()
Рис. 1 Схема RS-триггера двухступенчатого со сложной логикой на элементах 2И-НЕ и 3И-НЕ
УГО этого триггера смотри на рис.1. На данном рисунке неправильно подается
тактовый сигнал!
D-триггеры также называют триггерами задержки(от англ. Delay).
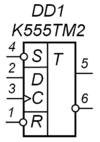
![]()
Пример условного графического обозначения (УГО) D-триггера с динамическим синхронным входом С и с дополнительными асинхронными инверсными входами S и R
|
D |
Q(t) |
Q(t+1) |
|
0 |
0 |
0 |
|
0 |
1 |
0 |
|
1 |
0 |
1 |
|
1 |
1 |
1 |
D-триггер (D от англ. delay — задержка[13][14][15] либо от data[16] - данные) — запоминает состояние входа и выдаёт его на выход. D-триггеры имеют, как минимум, два входа: информационный D и синхронизации С. После прихода активного фронта импульса синхронизации на вход С D-триггер открывается. Сохранение информации в D-триггерах происходит после спада импульса синхронизации С. Так как информация на выходе остаётся неизменной до прихода очередного импульса синхронизации, D-триггер называют также триггером с запоминанием информации или триггером-защёлкой. Рассуждая чисто теоретически, парафазный (двухфазный) D-триггер можно образовать из любых RS- или JK-триггеров, если на их входы одновременно подавать взаимно инверсные сигналы.
D-триггер в основном используется для реализации защёлки. Так, например, для снятия 32 бит информации с параллельной шины, берут 32 D-триггера и объединяют их входы синхронизации для управления записью информации в защёлку, а 32 D входа подсоединяют к шине.
В одноступенчатых D-триггерах во время прозрачности все изменения информации на входе D передаются на выход Q. Там, где это нежелательно, нужно применять двухступенчатые (двухтактные, Master-Slave, MS) D-триггеры.
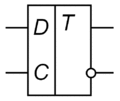
Условное графическое обозначение D-триггера со статическим входом синхронизации С
В одноступенчатом триггере имеется одна ступень запоминания информации, а в двухступенчатом — две такие ступени. Вначале информация записывается в первую ступень, а затем переписывается во вторую и появляется на выходе. Двухступенчатый триггер обозначают ТТ. Двухступенчатый D – триггер называют триггером с динамическим управлением. Общая схема двухступенчатого триггера
Т-триггер (от англ. Toggle - переключатель) часто называют счётным триггером, так как он является простейшим счётчиком до 2.
Асинхронный Т-триггер не имеет входа разрешения счёта - Т и переключается по каждому тактовому импульсу на входе С.
![]()
Работа схемы асинхронного двухступенчатого T-триггера с парафазным входом на двух парафазных D-триггерах на восьми логических вентилях 2И-НЕ. Слева — входы, справа — выходы. Синий цвет соответствует 0, красный — 1
|
T |
Q(t) |
Q(t+1) |
|
0 |
0 |
0 |
|
0 |
1 |
1 |
|
1 |
0 |
1 |
|
1 |
1 |
0 |

![]()
Условное графическое обозначение (УГО) синхронного T-триггера с динамическим входом синхронизации С на схемах.
Синхронный Т-триггер[17], при единице на входе Т, по каждому такту на входе С изменяет своё логическое состояние на противоположное, и не изменяет выходное состояние при нуле на входе T. Т-триггер можно построить на JK-триггере, на двухступенчатом (Master-Slave, MS) D-триггере и на двух одноступенчатых D-триггерах и инверторе.
Как можно видеть в таблице истинности JK-триггера, он переходит в инверсное состояние каждый раз при одновременной подаче на входы J и K логической 1. Это свойство позволяет создать на базе JK-триггера Т-триггер, объединяя входы J и К.
В двухступенчатом (Master-Slave, MS) D-триггере инверсный выход Q соединяется со входом D, а на вход С подаются счётные импульсы. В результате триггер при каждом счётном импульсе запоминает значение Q, то есть будет переключаться в противоположное состояние.
Т-триггер часто применяют для понижения частоты в 2 раза, при этом на Т
вход подают единицу, а на С — сигнал с частотой, которая будет
поделена на 2.
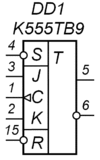
![]()
JK-триггер с дополнительными асинхронными инверсными входами S и R
|
J |
K |
Q(t) |
Q(t+1) |
|
0 |
0 |
0 |
0 |
|
0 |
0 |
1 |
1 |
|
0 |
1 |
0 |
0 |
|
0 |
1 |
1 |
0 |
|
1 |
0 |
0 |
1 |
|
1 |
0 |
1 |
1 |
|
1 |
1 |
0 |
1 |
|
1 |
1 |
1 |
0 |
JK-триггер[18][19] работает так же как RS-триггер, с одним лишь исключением: при подаче логической единицы на оба входа J и K состояние выхода триггера изменяется на противоположное. Вход J (от англ. Jump — прыжок) аналогичен входу S у RS-триггера. Вход K (от англ. Kill — убить) аналогичен входу R у RS-триггера. При подаче единицы на вход J и нуля на вход K выходное состояние триггера становится равным логической единице. А при подаче единицы на вход K и нуля на вход J выходное состояние триггера становится равным логическому нулю. JK-триггер в отличие от RS-триггера не имеет запрещённых состояний на основных входах, однако это никак не помогает при нарушении правил разработки логических схем. На практике применяются только синхронные JK-триггеры, то есть состояния основных входов J и K учитываются только в момент тактирования, например по положительному фронту импульса на входе синхронизации.
На базе JK-триггера возможно построить D-триггер или Т-триггер. Как можно видеть в таблице истинности JK-триггера, он переходит в инверсное состояние каждый раз при одновременной подаче на входы J и K логической 1. Это свойство позволяет создать на базе JK-триггера Т-триггер, объединив входы J и К[20].
Алгоритм функционирования JK-триггера можно представить формулой
![]()
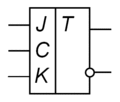
Условное графическое обозначение JK-триггера со статическим входом С
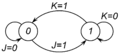
Граф переходов JK-триггера
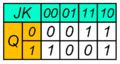
Карта Карно JK-триггера
![]()
Модель пятеричного RS1S2S3S4-триггера в логическом симуляторе Atanua[21]
Триггер с любым числом устойчивых состояний N строится из N логических элементов (N-1)ИЛИ-НЕ или (N-1)И-НЕ путём соединения выхода каждого элемента (Q0, Q1, …, Q(N-1)) с соответствующими входами всех других элементов[22][неавторитетный источник?]. То есть наименьшее число логических элементов для построения N-ичного триггера равно N.
Триггеры на элементах (N-1)ИЛИ-НЕ работают в прямом одноединичном коде (на выходе Q одного из элементов — «1», на выходах Q других элементов — «0»).
Триггеры на элементах (N-1)И-НЕ работают в инверсном однонулевом коде (на выходе Q одного из элементов — «0», на выходах Q других элементов — «1»).
При добавлении N транзисторов доступа эти триггеры могут работать как ячейки статической сверхоперативной памяти (SRAM).
При добавлении схем управления переключением эти триггеры могут работать как N-ичные аналоги двоичного RS-триггера.
В непозиционных системах счисления:
удельные затраты инверторов от числа состояний триггера не зависят: ![]() , где
, где ![]() — число инверторов,
— число инверторов, ![]() —
число состояний триггера.
—
число состояний триггера.
Удельные затраты диодов в логических частях логических элементов от числа
состояний триггера имеют линейную зависимость: ![]() , где x1 — число инверторов,
x2 — число состояний триггера, (x2-1) — число диодов в логической
части одного логического элемента. По этому параметру выгоднее двоичные
триггеры.
, где x1 — число инверторов,
x2 — число состояний триггера, (x2-1) — число диодов в логической
части одного логического элемента. По этому параметру выгоднее двоичные
триггеры.
![]()
Снимок модели пятеричного RS1S2S3S4-триггера Larry K. Baxter’а в логическом симуляторе Atanua
В приведённом выше подходе построения триггеров с любым числом устойчивых состояний при увеличении числа устойчивых состояний — n, увеличивается число входов в логических элементах в каждой элементарной ячейке триггера. Larry K. Baxter, Lexington, Mass. Assignee: Shintron Company, Inc., Cambridge, Mass. US Patent 3,764,919 Oct. 9, 1973 Filed: Dec. 22, 1972 Fig.3 предлагает другой подход к построению триггеров с любым числом устойчивых состояний, при котором число логических элементов и число входов в логических элементах в каждой элементарной ячейке триггера остаётся постоянным, но при этом увеличивается время переключения триггера пропорционально числу разрядов триггера.
Тиристор подходит для замены элемента памяти в триггерах.
Описание схемы на примере RS триггера: К катоду тиристора подключается выход триггера Q, к управляющему электроду подключается вход S, к аноду подключается постоянное напряжение через полевой транзистор с изолированным затвором, к затвору полевого транзистора подключается вход R.
Описание работы: Начальное состояние на выходе Q ноль: тиристор находится в замкнутом состоянии, ток на выходе соответствует нулю. Переход в состояние единица: на вход S подается напряжение равно логической единице тиристор разблокируется и напряжение на выходе Q повышается соответственно логической единице, при последующем понижении напряжения на входе S тиристор сохраняет низкое сопротивление и напряжение на выходе Q остается равным логической единице. Переход от логической единицы к нулю: на вход R подается напряжение равное логической единице полевой транзистор переходит в замкнутое состояние, напряжение на аноде тиристора падает, вследствие чего сопротивление тиристора возрастает и он переходит в состояние низкого выходного напряжения соответствующего логическому нулю, это состояние сохраняется при повышении входного напряжения на аноде тиристора.
Тиристор можно заменить на два биполярных транзистора (смотря какая реализация будет удобнее).
Как итог мы получаем RS триггер на трех транзисторах.
– 1 –
Факультет нелинейных процессов
Кафедра электроники, колебаний и волн
А.А. Бахчевников, А.С. Вакуленко, Е.Н. Егоров, А.А. Овчинников,
И.С. Ремпен
ОСНОВЫ ЦИФРОВОЙ ЛОГИКИ
Учебно-методическое пособие
Саратов – 2008
– 2 –
Содержание
Введение. 3
1. Основы алгебры логики 4
2. Базовые элементы логических систем 16
2.1. Резистивно-транзисторная логика 16
2.2. Комплементарная МОП-логика 16
3. Комбинационные цифровые устройства 18
3.1. Преобразователи кодов 18
3.2. Шифратор 18
3.3. Дешифратор 20
3.4. Мультиплексор 21
3.5. Демультиплексор 22
3.6. Компаратор кодов 23
4. Некоторые замечания о проектировании цифровых
узлов 24
5. Практические задания 26
5.1. Порядок выполнения лабораторной работы 26
5.2. Контрольные вопросы 27
5.3. Расчётное задание 28
5.4. Задание для численного и натурного эксперимента 30
Литература 31
– 3 –
Введение
Появившись около тридцати лет назад, цифровые и комбинированные
цифроаналоговые устройства к настоящему моменту получили чрезвычайно широкое
распространение. Если на заре своего существования цифровые устройства рассматривались
исключительно как узлы вычислительных машин, то к настоящему моменту спектр их
применения крайне широк и в ряде случаев цифровые системы теснят аналоговые с
традиционно занимаемых ими позиций. Хорошим примером последнему могут служить так
называемые цифровые потенциометры, микросхемы, одно из наиболее частых использований
которых – замена аналоговых переменных резисторов в цепях обратной связи усилителей в
бытовой и в контрольно-измерительной аппаратуре. В подавляющем большинстве случаев
цифровые устройства оказываются дешевле в производстве, меньше страдают от разброса
параметров, неизбежно возникающего при их изготовлении, менее подвержены влиянию
окружающей среды, а значит, работают стабильнее и надёжнее своих аналоговых
предшественников. При этом зачастую они занимают меньше места и потребляют
значительно меньше энергии.
Современные цифровые устройства крайне сложны, однако в основе их
функционирования лежат те же принципы, что и несколько десятилетий назад. Понимание
этих принципов является ключом к пониманию работы любых цифровых устройств. Целью
данного пособия является ознакомление студентов с основами цифровой схемотехники и
основными математическими принципами, лежащими в её основе. Методическое пособие
имеет следующую структуру. В первом и втором разделах описаны основные математические
и физические принципы функционирования цифровых устройств. Раздел 3 знакомит читателя
с функционированием некоторых базовых логических устройств. В разделе 4 содержатся
краткие рекомендации по проектированию цифровых устройств, которые могут оказаться
полезными при выполнении контрольных заданий раздела 5.
– 4 –
1. Основы алгебры логики.
Специфическим свойством любого цифрового устройства является представление
сигналов в виде последовательности чисел с ограниченной разрядностью. Сигналы, которыми
оперируют цифровые устройства, являются квантованными по уровню, что означает, что
уровни этих сигналов могут принимать лишь счётное множество значений
U
a) t
U
b) t
U
c) t
U
d) t
U
U
h
l
Наибольшее распространение получили системы, в которых число элементов
множества уровней равно двум. Следует отметить, что в принципе, число уровней может
быть произвольным, однако наиболее удобной оказалась именно двухуровневая система –
достаточно просто представить себе и реализовать электрическую цепь, имеющую только два
устойчивых состояния (Рис. 2).
Vcc
Рис. 1. а) аналоговый сигнал
b) дискретный сигнал
с) цифровой сигнал с
произвольными уровнями
d) двоичный сигнал.
Рис. 2. Нетрудно видеть, что приведённая
электрическая цепь может работать в двух
режимах: в случае, когда ключ разомкнут ток
течёт через лампочку, когда ключ замкнут, ток
через лампочку не течёт.
– 5 –
Достаточно часто для обозначения цифровых устройств используют термин
«логические устройства». Второе название указывает на тесную связь процессов обработки
цифрового сигнала с процессом вычисления значений логических функций в алгебре логики.
Данный раздел математической логики оперирует высказываниями и рассматривает вопросы
построения сложных высказываний из некоторого набора простых высказываний. Следует
особо отметить, что высказывания алгебры логики характеризуются только двумя признаками
– истинностью или ложностью. Любое высказывание может быть истинным либо ложным и
может быть представлено как совокупность конечного числа элементарных высказываний.
Поэтому кажется очень заманчивой возможность использовать алгебру логики
применительно к цифровым устройствам, которые обрабатывают двухуровневые сигналы.
Как указывалось выше, логические выражения могут быть сложными, то есть, по-
прежнему принимая всего два состояния, представлять собой комбинацию более простых
логических выражений. Высказывания (или логические выражения) в алгебре логики обычно
обозначаются заглавными латинскими буквами A, B и т.д. Сложные логические выражения
формируются из более простых посредством логических связок, называемых также
логическими операциями. Рассмотрим примеры наиболее распространённых логических
операций:
1. Логическое «И», называемое также конъюнкцией и логическим умножением.
Обычно обозначается следующими символами: &, *, или же отсутствием символа между
двумя логическими высказываниями. Высказывание A&B (AB, A*B) истинно тогда и только
тогда, когда истины оба высказывания A и B. Это обстоятельство удобно выразить в виде
таблицы истинности для конъюнкции:
A B AB
истинно истинно истинно
истинно ложно ложно
ложно истинно ложно
ложно ложно ложно
С точки зрения алгебры высказываний, операция конъюнкции полностью определяется
приведённой выше таблицей истинности. Отметим, что любая комбинация логических
– 6 –
выражений и логических связок будет полностью определятся соответствующей таблицей
истинности. В дальнейшем мы будем неоднократно использовать таблицу истинности для
определения значения логических функций.
2. Логическое «ИЛИ____QPMPOВ», называемое также дизъюнкцией и логическим сложением.
Обычно данная операция обозначается символом ∨. Сложное высказывание A∨B истинно в
том случае, если истинно хотя бы одно из входящих в его состав простых высказываний.
Операция дизъюнкции может быть представлена следующей таблицей истинности:
A B AB
истинно истинно истинно
истинно ложно истинно
ложно истинно истинно
ложно ложно ложно
3. Логическое «НЕ» A , называемое отрицанием A. Данная операция задаётся
следующей таблицей истинности:
A A
истинно ложно
ложно истинно
Операция отрицания является унарной операцией, то есть в ней участвует одно
логическое выражение. Рассмотренные же ранее операции конъюнкции и дизъюнкции
представляют собой бинарные операции, поскольку в них участвуют два логических
высказывания.
Используя описанные выше операции можно строить сколь угодно сложные
логические выражения. В принципе, можно ограничится использованием только операции
отрицания и любой бинарной в качестве базовых – все остальные операции возможно
переопределить через имеющиеся две, однако для упрощения структуры конечных функций и
вычислений обычно всё же в качестве базовых операций выбирают все три из описанных
выше. Более того, зачастую оказывается удобным вводить дополнительные логические
операции, определяя их через базовые. В качестве примера можно привести операцию
«исключающего ИЛИ», обозначаемую как ⊕ или XOR:
A⊕ B = AB ∨ AB
для которой справедлива следующая таблица истинности:
– 7 –
A B AB
Истинно истинно ложно
Истинно ложно истинно
Ложно истинно истинно
Ложно ложно ложно
Существует достаточно большое количество собственных обозначений для различного
рода сложных комбинаций базовых операторов и высказываний. Более подробно этот
вопрос освещён, например, в [1,5]
При построении сложных логических выражений, следует помнить, что первой
выполняется операция отрицания (применительно к самым простым выражениям), затем
операция логического умножения и лишь затем логическое сложение.
Поскольку логические операции полностью характеризуются таблицами истинности,
можно уйти от понятия высказывания и оперировать только таблицами. Более того, для
обозначения истинности высказывания мы будем использовать символ 1, для обозначения
ложности – 0. Это позволит нам ввести понятие логической функции:
О.1. Функцией алгебры логики или логической функцией f(x1,…,xn)от логических
переменных x1,…,xn называется функция, принимающая значения 0,1 и аргументы
которой также принимают значения 0,1.
Логическая функция однозначно задаётся своей таблицей истинности:
x1 x2 … xn-1 xn f(x1,x2,…,xn-1,xn)
0 0 … 0 0 f(0,0,…,0,0)
1 0 … 0 0 f(1,0,…,0,0)
… … … … … …
1 1 … 1 0 f(1,1,…,1,0)
1 1 … 1 1 f(1,1,…,1,1)
Приведём основные равносильности (*), справедливые для алгебры логики,
определённой выше:
– 8 –
Ко мму та ти вн ый закон:
1 2 2 1 x x = x x 1 2 2 1 x + x = x + x
Ассоциативный закон:
1 2 3 1 2 3 x (x x ) = (x x )x 1 2 3 1 2 3 x + (x + x ) = (x + x ) + x
Дистрибутивный за кон:
1 2 3 1 2 1 3 x (x + x ) = x x + x x ( )( ) 1 2 3 1 2 1 3 x + x x = x + x x + x
Правило с к ле и ва ни я :
1 1 2 1 x (x + x ) = x 1 1 2 1 x + x x = x
Правило повторения :
xx = x x + x = x
Правило о т р и ца н ия :
xx = 0 x + x = 1
Правило д в о й но г о о т р иц а ни я :
(x)= x
Теорема д е М ор га н а:
1 2 1 2 x x = x + x 1 2 1 2 x + x = x x
О п е ра ц ии с 0 и 1:
0 1
0 0
1
=
⋅ =
⋅ =
x
x x
1 0
1 1
0
=
+ =
+ =
x
x x
Для дальнейшего изложения материала требуется ввести формальное определение
алгебры логики. Алгебру логики, называемую также иногда булевой алгеброй по имени её
основоположника Дж. Буля, можно формально определить следующим образом:
О.2. Множество M , на котором определены две бинарные операции x, y ⇒ xy и
x, y ⇒ x ∨ y и одна унарная x⇒ x и выделены два элемента 0,1∈M , причём для этих
операций и элементов выполняются соотношения (*), называется булевой алгеброй.
Обозначим множество натуральных чисел как N. Обозначим совокупность его
подмножеств как NM. Через xy (x,y∈N) обозначим пересечение множеств x и y, через
x∨y – их объединение, через x - дополнение к подмножеству x до всего множества N,
через 0 – пустое множество. Нетрудно видеть, что приведённый способ позволяет
определить булеву алгебру практически на любом множестве.
– 9 –
Приведя основные положения алгебры логики вернёмся к цифровым устройствам и
обсудим вопрос о применении к ним алгебры логики.
Как известно, при выполнении различных операций в современных цифровых
системах числа обычно представляются в двоичной системе счисления, т.е. системы
счисления, основанием которой является число 2. При этом целое k-разрядное десятичное
число A10 записывается в виде n-разрядного двоичного числа A2:
Σ Σ−
=
−
=
= = =
1
0
2
1
0
10 (10 ) (2 )
n
j
j
j
k
i
i
i A a A a
Нетрудно показать, что на множестве {0,1} также можно определить булеву алгебру.
Тогда арифметические действия над числами, записанными в данной системе счисления
легко представить в виде логических операций. Так умножение в двоичной системе
счисления аналогично конъюнкции, дизъюнкция же аналогична сложению по модулю два
(поскольку сложения по иному модулю в данной системе счисления выполнить
затруднительно, в дальнейшем мы будем подразумевать, что сложение происходит именно по
модулю два). Отрицание соответствует вычитанию из единицы. Также вполне очевидным
является тот факт, что все соотношения (*) будут также справедливы в двоичной системе
счисления (с учётом приведённой арифметической операции это нетрудно показать). Поэтому
можно говорить о том, то любые цифровые устройства фактически реализуют те или иные
логические функции.
Сложно спорить с тем, что таблицы истинности (называемые в литературе по
схемотехнике также таблицами переключения) являются гораздо более наглядным способом
представления логической функции, чем запись в виде некоторой комбинациилогических
переменных и операций. Частой бывает ситуация, когда необходимо синтезировать
устройство, реализующую ту или иную таблицу переключений. Вместе с тем далеко не всегда
очевидно, каким образом можно осуществить переход от таблицы истинности к логической
функции. Для осуществления такого перехода разработано несколько методик, одна из
которых изложена ниже.
Для осуществления перехода от табличного представления к алгебраическому,
каждому набору переменных ставится в соответствие минтерм – конъюнкция всех
переменных, которые входят в неё в прямом виде, если их значение равно 1, в инверсном
виде , если значение переменной равно 0. Для k переменных возможно составить q=2k
минтермов, номер которых соответствует десятичному представлению k-й комбинации
– 10 –
переменных: m0, m1,…,mq-1. Значение искомой функции F для i-го набора переменных будем
обозначать fi. Тогда искомую функцию можно представить в следующем виде:
Σ−
=
=
1
0
q
i
i i F f m
Такое представление функции называется её совершенной дизъюнктивной нормальной
формой.
В качестве примера рассмотрим построение логической функции по следующей
таблице истинности:
A B минтермы Значения
функции
0 0 m = AB 0 1
0 1 m = AB 1 0
1 0 m = AB 2 0
1 1 m = AB 3 1
Как видно из изложенного выше, любую сложную логическую функцию можно
представить множеством эквивалентных способов. С другой стороны, чем проще логическое
выражение функции, тем меньше элементов требуется для её реализации. Уменьшение числа
элементов схемы, в свою очередь, снижает энергопотребление схемы (что в некоторых
случаях является важным условием пригодности схемы к использованию), габариты
устройства, увеличивает быстродействие. Уменьшение числа элементов схемы также
упрощает отладку и устранение неисправностей в конечном устройстве.
Сложность логической функции определяется количеством переменных, входящих в
её алгебраическое выражение в прямом или инверсном виде. Минимальным называется такое
эквивалентное представление функции, которое имеет минимальную сложность.
Соответственно процесс сведения функции к минимальному представлению называется
минимизацией. Минимизация может осуществляться применением соотношений (*) к
логической функции. Помимо прямого применения аксиом булевой алгебры существуют
также другие способы минимизации логических функций, однако их рассмотрение выходит
далеко за рамки настоящего пособия. Дополнительную информацию о них можно получить в
[1,5] .
– 11 –
Иногда описывать логику работы бывает более удобно с помощью арифметических
операций, совершаемых над двоичными числами. Арифметические операции с двоичными
числами полностью аналогичны операциям с десятичными числами, однако зачастую их
выполнение вызывает серьёзные трудности. Мы не будем подробно останавливаться на
данном вопросе, обозначим лишь основные вопросы, на которые необходимо обращать
внимание.
При сложении двух цифр 1 получается 0 и возникает так называемый перенос 1, что
означает передач цифры 1 в ближайший старший разряд, где она складывается с имеющимися
– 12 –
там цифрами. При сложении других комбинаций цифр результат аналогичен результату
десятичной системы счисления.
При вычитании существует только одна особенность: 0-1. В этом случае из
ближайшего старшего разряда берется цифра 1, что означает так называемый заем. Операцию
вычитания, представленную в табл.2, можно упростить, используя дополнения
отрицательных двоичных чисел.
Рассмотрим следующий пример: произвести сложение двух чисел: А=111111111 и
В=000000001
Если не принимать во внимание последний перенос влево, то сумма этих чисел равна
0, т.к. (000000001)2=(1)10, то должно быть (111111111)2=(-1)10.
Двоичное дополнение каждого числа можно определить следующим образом: в
данном числе 0 заменяется 1, а 1 заменяется 0 и к самому младшем разряду прибавляется
цифра 1.
Умножение двоичных чисел производится довольно просто, также как и в
десятичной системе. Если цифра множителя 1, то произведение равно множимому, если
множитель 0, то произведение равно 0. При умножении положительного и отрицательного
чисел действуют те же правила, что и в десятичной системе счисления, знак произведения
определяется отдельно.
Существует несколько способов деления. Один из способов деления основан на
принципе восстановления первоначального делимого. Делитель вычитается из делимого, и
если результат положителен, то в частное записывается цифра 1. К результату вычитания
приписывается след цифра делимого, вычитающий делитель сдвигается на одну позицию
вправо. Если результат вычитания отрицательный, то в частное пишется цифра 0, к
– 13 –
отрицательному числу прибавляется делитель для восстановления первоначального делимого
и т.д.
Как уже было отмечено выше, цифровая схемотехника работает с сигналами,
квантованными по уровню, причём количество уровней квантования равно двум. Обычно эти
уровни называют высоким, которому соответствует некоторое значение напряжения
(типичными значениями являются напряжения в диапазоне +3..+15В,) и низким, которому
соответствует ноль потенциала. Высокому уровню ставится в соответствие логическая 1,
низкому – логический 0. Следует отметить, что в некоторых системах принято обратное
представление логических нулей и единиц. Такие системы называются системами с
инверсной или негативной логикой. В качестве логических переменных выступают значения
потенциала в точках, интерпретируемых как вход схемы, выход схемы представляет собой
результат выполнения некоторой логической функции. Как и в алгебре логики, функция
строится с помощью конечного набора логических операций, которые выполняются
– 14 –
базовыми элементами цифровых схем. Основываясь на подобном наборе элементов возможно
построить цифровое устройство любой сложности, позволяющее решать практически любую
вычислительную задачу.
Справедливости ради следует сказать, что сложные системы управления и обработки
сигналов имеет смысл разрабатывать, основываясь на более совершенных и
универсальных цифровых устройствах, таких, как программируемые логические
интегральные схемы и микроконтроллеры. Достойные восхищения примеры
построения крайне сложных цифровых систем на основе простых цифровых устройств
приведены в книге [7]. Авторы не могли удержаться и не привести её в качестве
образца широты возможностей цифровой схемотехники даже при ограниченной
элементной базе, однако ни в коем случае не стоит забывать, что описанные задачи
могут и в настоящее время должны решаться более простыми методами.
В качестве базовых элементов цифровой схемотехники традиционно рассматривают
следующие устройства:
Логическая
функция
Обозначение, принятое в отечественной
литературе
Международное
обозначение
Инверсия (НЕ)
И
ИЛИ
– 15 –
Логическая
функция
Обозначение, принятое в отечественной
литературе
Международное
обозначение
ИЛИ-НЕ
И-НЕ
Искл. ИЛИ-НЕ
Искл. ИЛИ
Для реализации основных логических функций имеется ряд различных схем,
которые отличаются по потребляемой мощности, напряжению питания, значениям высокого
и низкого уровней выходного напряжения, времени задержки распространения сигнала и
нагрузочной способности. Чтобы правильно выбрать тип схемы, необходимо, по крайней
мере, в общих чертах знать их внутреннюю структуру. С этой целью в далее приведено
описание некоторых типов логических элементов. Следует помнить, что данное описание не
претендует на полноту и носит исключительно иллюстративный характер. Более подробную
информацию о конструктивных особенностях различных типов цифровых устройств можно
почерпнуть в [1].
При соединении интегральных схем иногда к одному выходу подключается большое
число входов логических элементов. Максимальное количество входов схем данного типа,
подключаемых к выходу без уменьшения гарантируемого запаса помехоустойчивости,
характеризуется нагрузочной способностью элемента (коэффициентом разветвления по
выходу). Коэффициент разветвления по выходу, равный 10, означает, что можно подключить
– 16 –
10 входов логических элементов. Если нагрузочная способность стандартного элемента
оказывается недостаточной, вместо него применяют элемент с повышенной мощностью
(буфер).
2. Базовые элементы цифровых систем.
2.1 Резистивно-транзисторная логика (РТЛ)
Простейшим элементом РТЛ является схема ИЛИ-НЕ, представленная на рис. 1.
Если входное напряжение имеет высокий уровень, то соответствующий транзистор
открывается и на выходе формируется низкий уровень. Следовательно, в позитивной логике
реализуется функция ИЛИ-НЕ.
Относительно низкоомное базовое сопротивление обеспечивает полное открывание
транзисторов при малом потреблении тока. Однако это приводит к весьма малой
нагрузочной способности элемента. В этом отношении рассматриваемые далее схемы
существенно лучше.
2.2.Комплементарная МОП-логика (КМОП)
Рассмотрим принцип действия схем КМОП на примере инвертора, изображенного на
рис. 2.
Пороговое напряжение обоих транзисторов составляет, как правило, 1,5 В. Если Ue =
0, то открыт р-канальный МОП-транзистор Т2, а n-канальный МОП-транзистор T1 заперт. При
этом выходное напряжение равно VDD. Если Ue = VDD, то транзистор Т2 заперт, a T1 открыт и
выходное напряжение равно нулю. Напряжение питания можно произвольно выбирать в
диапазоне от 3 до 15 В.
Рис.3. Элемент ИЛИ-НЕ типа РТЛ
– 17 –
Очевидно, что в статическом режиме потребление тока данной схемой будет равно
нулю. Лишь в момент переключения, пока входное напряжение находится в пределах |Up| < <
Ue < UDD - |Up|, существует небольшой ток утечки.
На рис. 3 изображен логический элемент КМОП ИЛИ-НЕ, работающий на том же
принципе, что и описанный выше инвертор. Чтобы всегда можно было обеспечить большое
управляемое сопротивление нагрузки, когда любое из входных напряжений будет иметь
высокий уровень, соответствующее число р-канальных транзисторов включается
последовательно. Несмотря на то, что при этом выходное сопротивление схемы в состоянии
логической единицы возрастает, выходное напряжение логической единицы остается на
уровне VDD, так как в стационарном режиме ток не течет. Путем изменения параллельного
включения транзисторов на последовательное (и наоборот) из схемы ИЛИ-НЕ можно
получить логический элемент И-НЕ, представленный на рис. 4.
Рис. 4. КМОП-инвертор.
Рис.5. Элемент ИЛИ-НЕ типа
КМОП
– 18 –
3. Комбинационные устройства
Комбинационными называются устройства, характеризующиеся отсутствием памяти.
К комбинационным устройствам относятся электронные ключи, элементы НЕ, ИЛИ-НЕ, И-
НЕ, шифраторы, дешифраторы и мультиплексоры, демультиплексоры и компараторы.
3.1 Преобразователи кодов.
Для представления информации используются разнообразные двоичные и двоично-
десятичные коды: прямой, обратный, дополнительный, «с избытком 3» и многие другие.
Часто возникает задача преобразования данных из одного кода в другой. Так, например, для
отображения некоторого двоичного числа на стандартном семисегментном индикаторе
необходимо преобразовать это число в код, используемый индикатором. Эту задачу решают
с использованием преобразователей кода: шифраторов, дешифраторов, мультиплексоров и
демультиплексоров.
3.2 Шифраторы.
Шифрацией называется процесс преобразование m-разрядного двоичного кода,
имеющего km безразличных наборов входных переменных, в однозначно соответствующий
ему n-разрядный код, имеющий меньшее число разрядов n<m и безразличных наборов kn<km.
Рис.6. Элемент И-НЕ типа КМОП
– 19 –
В результате шифрации происходит сжатие информации для передачи по меньшему числу
линий связи. Функциональный узел, выполняющий операцию шифрации, называется
шифратором. Обычно говорят о шифраторах из m в n.
Наиболее часто в цифровых системах шифраторы используются для передачи
информации между различными устройствами при ограниченном числе линий связи, а также
для преобразования вводимых чисел в двоичную форму. Так, ввод десятичных чисел часто
производится нажатием соответствующей клавиши на управляющем пульте. При этом
преобразование числа в двоично-десятичную форму выполняется с помощью шифратора «из
10 в 4». При нажатии произвольной i клавиши замыкается ключ на одном из входов
шифратора, подавая таким, образом, на этот вход логический 0. Благодаря исключению
безразличных комбинаций, число выходных переменных возможно уменьшить до четырёх.
Таблица истинности для шифратора «из 10 в 4» приведена ниже.
I X0 X1 X2 X3 X4 X5 X6 X7 X8 X9 A3 A2 A1 A0
0 0 1 1 1 1 1 1 1 1 1 0 0 0 0
1 1 0 1 1 1 1 1 1 1 1 0 0 0 1
2 1 1 0 1 1 1 1 1 1 1 0 0 1 0
3 1 1 1 0 1 1 1 1 1 1 0 0 1 1
4 1 1 1 1 0 1 1 1 1 1 0 1 0 0
5 1 1 1 1 1 0 1 1 1 1 0 1 0 1
6 1 1 1 1 1 1 0 1 1 1 0 1 1 0
7 1 1 1 1 1 1 1 0 1 1 0 1 1 1
8 1 1 1 1 1 1 1 1 0 1 1 0 0 0
9 1 1 1 1 1 1 1 1 1 0 1 0 0 1
– 20 –
3.3 Дешифратор.
Дешифратор выполняет функцию, обратную функции шифратора.
A B C F0 F1 F2 F3 F4 F5 F6 F7
0 0 0 0 1 1 1 1 1 1 1
0 0 1 1 0 1 1 1 1 1 1
0 1 0 1 1 0 1 1 1 1 1
0 1 1 1 1 1 0 1 1 1 1
1 0 0 1 1 1 1 0 1 1 1
1 0 1 1 1 1 1 1 0 1 1
1 1 0 1 1 1 1 1 1 0 1
1 1 1 1 1 1 1 1 1 1 0
Рис. 14 Схема шифратора, переводящего
десятичные числа в двоичные
Рис. 13. Схематическое
обозначение дешифратора,
выполненного в виде МОП
микросхемы
– 21 –
Часть принципиальной схемы дешифратора приведена на рис. 13.
Максимальное число выходов, а соответственно количество дешифрированных чисел,
необходимое для дешифрации n-разрядного двоичного числа, равно N = 2n . Согласно этому
выражению, схема на рис. 13 может иметь максимально N = 24 = 16 выходов.
Для этого дешифратора активные уровни логические 0. Он принимает входной
четырехразрядный код и выдает 0 на один из десяти выходов. Номер выбранного выхода
соответствует десятичному эквиваленту входного двоичного кода.
3.4 Мультиплексор.
Мультиплексором (селектором) называется функциональный узел, обеспечивающий
передачу информации, поступающей по нескольким входным линиям связи, на одну
выходную линию. Выбор то или иной выходной линии A осуществляется в соответствии с
поступающим адресным кодом S0,S1,… . При наличие n адресных входов можно
реализовать M=2^n комбинаций адресных сигналов Si, каждый из которых обеспечивает
выбор одной из M входных точек.
Принципиальная схема с четырьмя информационными входами показана на рис. 15.
Рис. 13 Схема дешифратора на десять
выходов
Рис. 12 Схематическое
обозначение дешифратора.
– 22 –
В зависимости от состояния входов адреса а0 и а1 выход мультиплексора Y
соединяется с одним из его информационных входов х0-х3. Непосредственно из условия
следует: Y = а1а0 х0 + а1а0 х1 + а1а0 х2 + а1а0 х3 .
Логическое произведение адресных сигналов равно единице только для той входной
переменной, индекс которой совпадает с требуемым адресом. Например, если а1=1 и а0=0, то
0 1 2 3 2 Y = 0 ⋅1⋅ х + 0 ⋅ 0 ⋅ х +1⋅1х +1⋅ 0 ⋅ х = х .
По казанному принципу эта схема может быть распространена на любое число
входных переменных. При помощи n адресных входов можно выбрать один из 2n
информационных сигналов.
3.5 Демультиплексор.
Для восстановления мультиплексированной информации используются
демультиплексоры, которые в соответствии с принятым адресом направляют информацию в
одну из M выходных линий. При этом на остальных выходах поддерживается логический
ноль.
Сигнал Х подается на информационный вход. Схема подключает его именно к тому
выходу, номер которого задан адресными сигналами а0, а1.
Рис. 15 Схема мультиплексора с
четырьмя информационными входами
Рис. 16 Схематическое изображение
мультиплексора
– 23 –
В наиболее распространённых на настоящий момент сериях логических МОП
микросхем специфических устройств, выполняющих функции демульпилексора нет. Это
связано с тем, что интегральные мультиплексоры могу пропускать сигнал в двух
направлениях – из информационной линии в линию с указанным адресом обратно из линии с
указанным адресом в некоторую общую линию. Соответственно в данном случае различие
между мультиплексором и мультиплексором – сугубо формальное. Однако о данном свойстве
микросхем-мультиплексоров следует помнить, чтобы избежать неприятностей при
моделировании и отладке цифровых устройств.
3.6 Компараторы кодов.
Для сравнения операндов в цифровых системах часто используют специальные
схемы – двоичные компараторы. Простейшим вариантом компараторов являются схемы для
определения равенства двух операндов A и B. Результатом сравнения является обнаружения
одного из трех возможных состояний А=В, А>В и А<В. Примеры схемной реализации и
таблица состояний компаратора приведены ниже. Сравнение чисел с разрядностью больше 1
осуществляется аналогичным образом поразрядно.
Рис. 16 Схема
демультиплексора с четырьмя
выходами
– 24 –
Таблица состояний компаратора
одноразрядных чисел
А В Ya>b Ya=b Ya<b
0
0
1
1
0
1
0
1
0
0
1
0
1
0
0
1
0
1
0
0
Для сравнения многоразрядных чисел, сперва сравниваются старшие разряды. Если
они различны, то они определяют результат сравнения. Если они равны, то необходимо
сравнить следующие за ним младшие разряды и т.д. [2].
Рис. НН. Схема компаратора,
осуществляющего сравнение
одноразрядных чисел
Рис. НН-1. Схематическое
обозначение четырёхразрядного
компаратора.
4. Несколько слов о методике проектирования цифровых узлов.
Исходными данными для проектирования цифрового устройства является его
функциональное описание и требование к основным электрическим параметрам.
Функциональное описание обычно задаётся в виде таблицы истинности или алгебраического
выражения. Процесс проектирования разбивается на несколько последовательно
выполняемых этапов:
• Выбор элементной базы и способа реализации;
- Определяется требованиями, предъявляемыми к электрическим параметрам устройства:
быстродействию, потребляемой мощности, помехоустойчивости и т.д.
• Упрощение заданной логической функции;
- Осуществляется с использованием законов алгебры логики, приведённых выше.
• Преобразование упрощённой логической функции и синтез логической схемы;
- Преобразование производится так, чтобы представить полученную на предыдущем этапе
логическую функцию в виде комбинации операций, выполняемых базовыми элементами,
на которых будет реализовано проектируемое устройство.
• Синтез электрической схемы;
- Осуществляется заменой элементов логической схемы их схемотехническими
эквивалентами.
• Анализ и оптимизация электрической схемы.
- На данном этапе производится проверка соответствия параметров схемы предъявленным
требованиям. Также на данном этапе осуществляется определение основных
электрических характеристик полученных схем.
2. Арифметические и арифметико-логические схемы и узлы.
Арифметико-логическое устройство (АЛУ) - центральная часть процессора, выполняющая арифметические и логические операции.
АЛУ реализует важную часть процесса обработки данных. Она заключается в выполнении набора простых операций. Операции АЛУ подразделяются на три основные категории: арифметические, логические и операции над битами. Арифметической операцией называют процедуру обработки данных, аргументы и результат которой являются числами (сложение, вычитание, умножение, деление,...). Логической операцией именуют процедуру, осуществляющую построение сложного высказывания (операции И, ИЛИ, НЕ,...). Операции над битами обычно подразумевают сдвиги.
Содержание[убрать]
|
Разработчик компьютера ENIAC, Джон фон Нейман, был первым создателем АЛУ. В 1945 году он опубликовал первые научные работы по новому компьютеру, названному EDVAC (Electronic Discrete Variable Computer). Годом позже он работал со своими коллегами над разработкой компьютера для Принстонского института новейших исследований (IAS). Архитектура этого компьютера позже стала прототипом архитектур большинства последующих компьютеров. В своих работах фон Нейман указывал устройства, которые, как он считал, должны присутствовать в компьютерах. Среди этих устройств присутствовало и АЛУ. Фон Нейман отмечал, что АЛУ необходимо для компьютера, поскольку оно гарантирует, что компьютер будет способен выполнять базовые математические операции включая сложение, вычитание, умножение и деление
АЛУ состоит из регистров, сумматора с соответствующими логическими схемами и элемента управления выполняемым процессом. Устройство работает в соответствии с сообщаемыми ему именами (кодами) операций, которые при пересылке данных нужно выполнить над переменными, помещаемыми в регистры.
Арифметико-логическое устройство функционально можно разделить на две части :
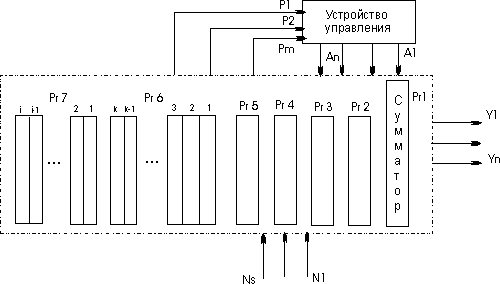
![]()
Структурная схема арифметико-логического устройства
Рисунок 1 - Структурная схема арифметико-логического устройства
Структурная схема АЛУ и его связь с другими блоками машины показаны на рисунке 1. В состав АЛУ входят регистры Рг1 - Рг7, в которых обрабатывается информация , поступающая из оперативной или пассивной памяти N1, N2, ...NS; логические схемы, реализующие обработку слов по микрокомандам, поступающим из устройства управления.
Закон переработки информации задает микропрограмма , которая записывается в виде последовательности микрокоманд A1,A2, ..., Аn-1,An. При этом различают два вида микрокоманд: внешние, то есть такие микрокоманды, которые поступают в АЛУ от внешних источников и вызывают в нем те или иные преобразования информации (на рис. 1 микрокоманды A1,A2,..., Аn), и внутренние, которые генерируются в АЛУ и воздействуют на микропрограммное устройство, изменяя естественный порядок следования микрокоманд. Например, АЛУ может генерировать признаки в зависимости от результата вычислений: признак переполнения, признак отрицательного числа, признак равенства 0 всех разрядов числа др. На рис. 1 эти микрокоманды обозначены р1, p2,..., рm.
Результаты вычислений из АЛУ передаются по кодовым шинам записи у1, у2, ...,уs, в ОЗУ. Функции регистров, входящих в АЛУ:
Часть операционных регистров является программно-доступной, то есть они могут быть адресованы в команде для выполнения операций с их содержимым. К ним относятся : сумматор, индексные регистры, некоторые вспомогательные регистры.
Остальные регистры программно-недоступные, так как они не могут быть адресованы в программе. Операционные устройства можно классифицировать по виду обрабатываемой информации, по способу обработки информации и логической структуре.
АЛУ может оперировать четырьмя типами информационных объектов: булевскими (1 бит), цифровыми (4 бита), байтными (8 бит) и адресными (16 бит). В АЛУ выполняется 51 различная операция пересылки или преобразования этих данных. Так как используется 11 режимов адресации (7 для данных и 4 для адресов), то путем комбинирования "операция/ режим адресации" базовое число команд 111 расширяется до 255 из 256 возможных при однобайтном коде операции.
Выполняемые в АЛУ операции можно разделить на следующие группы:
Современные ЭВМ общего назначения обычно реализуют операции всех приведённых выше групп, а малые и микроЭВМ, микропроцессоры и специализированные ЭВМ часто не имеют аппаратуры арифметики чисел с плавающей точкой, десятичной арифметики и операций над алфавитно-цифровыми полями. В этом случае эти операции выполняются специальными подпрограммами. К арифметическим операциям относятся сложение, вычитание, вычитание модулей («короткие операции») и умножение и деление («длинные операции»). Группу логических операций составляют операции дизъюнкция (логическое ИЛИ) и конъюнкция (логическое И) над многоразрядными двоичными словами, сравнение кодов на равенство. Специальные арифметические операции включают в себя нормализацию, арифметический сдвиг (сдвигаются только цифровые разряды, знаковый разряд остаётся на месте), логический сдвиг (знаковый разряд сдвигается вместе с цифровыми разрядами). Обширна группа операций редактирования алфавитно-цифровой информации
Арифметическо-логическое устройство
![]()
Схема 4-битного АЛУ 74181
![]()
Схема одноразрядного бинарного (двухоперандного) троичного полуАЛУ в трёхбитной одноединичной системе троичных логических элементов

![]()
Схема одноразрядного трёхбитного бинарного (двухоперандного) АЛУ в трёхбитной одноединичной системе троичных логических элементов
3. Запоминающие устройства ЭВМ, классификация. Обощенная структурная схема запоминающего устройства.
1.2. Классификация запоминающих устройств
1.2.1.
Классификация ЗУ по функциональному назначению
1.2.2.
Классификация ЗУ по принципу организации
В настоящее время существует большое количество различных типов ЗУ, используемых в ЭВМ и системах. Эти устройства различаются рядом признаков: принципом действия, логической организацией, конструктивной и технологической реализацией, функциональным назначением и т.д. Большое количество существующих типов ЗУ обусловливает различия в структурной и логической организации (систем) памяти ЭВМ. Требуемые характеристики памяти достигаются не только за счет применения ЗУ с соответствующими характеристиками, но в значительной степени за счет особенностей ее структуры и алгоритмов функционирования.
Память ЭВМ почти всегда является "узким местом", ограничивающим производительность компьютера. Поэтому в ее организации используется ряд приемов, улучшающих временные характеристики памяти и, следовательно, повышающих производительность ЭВМ в целом.
Классификация запоминающих устройств и систем памяти позволяет выделить общие и характерные особенности их организации, систематизировать базовые принципы и методы, положенные в основу их реализации и использования.
Один из возможных вариантов классификации ЗУ представлен на рис.3. В нем устройства памяти подразделяются по двум основным критериям: по функциональному назначению (роли или месту в иерархии памяти) и принципу организации.
1.2.1. Классификация ЗУ по
функциональному назначению
При разделении ЗУ по функциональному назначению иногда рассматривают два класса: внутренние и внешние ЗУ ЭВМ. Такое деление первоначально основывалось на различном конструктивном расположении их в ЭВМ. В настоящее время, например, накопители на жестких магнитных дисках, традиционно относимые к внешним ЗУ, конструктивно располагаются непосредственно в основном блоке компьютера. Поэтому разделение на внешние и внутренние ЗУ имеет в ряде случаев относительный, условный характер. Обычно к внутренним ЗУ относят устройства, непосредственно доступные процессору, а к внешним – такие, обмен информацией которых с процессором происходит через внутренние ЗУ.
Общий вид иерархии памяти ЭВМ представлен на рис.4. На нем показаны различные типы ЗУ, причем поскольку рисунок обобщенный, то не все из представленных на нем ЗУ обязательно входят в состав ЭВМ, а характер связей между устройствами может отличаться от показанного на рисунке.
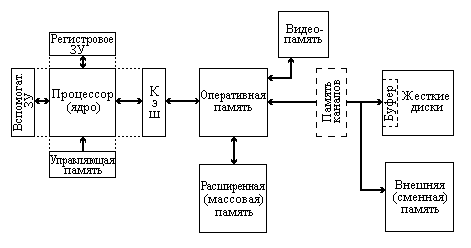
Рис. 4. Возможный состав системы памяти ЭВМ
1. Верхнее место в иерархии памяти занимают регистровые ЗУ, которые входят в состав процессора и часто рассматриваются не как самостоятельный блок ЗУ, а просто как набор регистров процессора. Такие ЗУ в большинстве случаев реализованы на том же кристалле, что и процессор, и предназначены для хранения небольшого количества информации (до нескольких десятков слов, а в RISC-архитектурах – до сотни), которая обрабатывается в текущий момент времени или часто используется процессором. Это позволяет сократить время выполнения программы за счет использования команд типа регистр-регистр и уменьшить частоту обменов информацией с более медленными ЗУ ЭВМ. Обращение к этим ЗУ производится непосредственно по командам процессора.
2. Следующую позицию в иерархии занимают буферные ЗУ. Их назначение состоит в сокращении времени передачи информации между процессором и более медленными уровнями памяти компьютера. Буферная память может устанавливаться на различных уровнях, но здесь речь идет именно об указанном ее местоположении. Ранее такие буферные ЗУ в отечественной литературе называли сверхоперативными, сейчас это название практически полностью вытеснил термин "кэш-память" или просто кэш.
Принцип использования буферной памяти во всех случаях сводится к одному и тому же. Буфер представляет собой более быстрое (а значит, и более дорогое), но менее емкое ЗУ, чем то, для ускорения работы которого он предназначен. При этом в буфере размещается только та часть информации из более медленного ЗУ, которая используется в настоящий момент. Если доля h обращений к памяти со стороны процессора, удовлетворяемых непосредственно буфером (кэшем) высока (0,9 и более), то среднее время для всех обращений оказывается близким ко времени обращения к кэшу, а не к более медленному ЗУ.
Пусть двухуровневая память состоит из кэш и оперативной памяти,
как показано на рис.5. И пусть, например, время обращения к кэшу tc
= 1 нс (10-9 с), время tm обращения к более медленной памяти в десять раз
больше – tm = 10 нс, а доля обращений, удовлетворяемых
кэшем, h = 0,95.
Тогда
среднее время обращения к такой двухуровневой памяти Tср
составит Tср = 1 * 0.95 + 10 * (1 – 0.95 ) = 1.45 нс, т.е.
всего на 45% больше времени обращения к кэшу. Значение h зависит от
размера кэша и характера выполняемых программ и иногда называется отношением
успехов или попаданий (hit ratio).
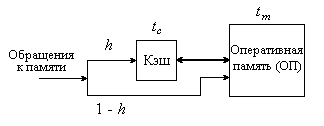
Рис.5. К расчету среднего времени обращения
(tc – время обращения к кэш-памяти,
tm – время обращения к ОП,
h – доля обращения, обслуживаемых кэш-памятью,
1 – h – доля обращений, обслуживаемых ОП)
Размеры кэш-памяти существенно изменяются с развитием технологий. Так, если в первых ЭВМ, где была установлена кэш-память, во второй половине 1960-х годов (большие ЭВМ семейства IBM-360) ее емкость составляла всего от 8 до 16 КБайт, то уже во второй половине 1990-х годов емкость кэша рядовых персональных ЭВМ составляла 512 КБайт. Причем сама кэш-память может состоять из двух (а в серверных системах – даже трех) уровней: первого (L1) и второго (L2), также отличающихся своей емкостью и временем обращения.
Конструктивно кэш уровня L1 входит в состав процессора (поэтому его иногда называют внутренним). Кэш уровня L2 либо также входит в микросхему процессора, либо может быть реализован в виде отдельной памяти. Как правило, на параметры быстродействия процессора большее влияние оказывают характеристики кэш-памяти первого уровня.
Время обращения к кэш-памяти, которая обычно работает на частоте процессора, составляет от десятых долей до единиц наносекунд, т.е. не превышает длительности одного цикла процессора.
Обмен информацией между кэш-памятью и более медленными ЗУ для улучшения временных характеристик выполняется блоками, а не байтами или словами. Управляют этим обменом аппаратные средства процессора и операционная система, и вмешательство прикладной программы не требуется. Причем непосредственно командам процессора кэш-память недоступна, т.е. программа не может явно указать чтение или запись в кэш-памяти, которая является для нее, как иногда говорят, “прозрачной” (прямой перевод используемого в англоязычной литературе слова transparent).
Некоторые особенности организации кэш-памяти рассмотрены в главе 4.
3. Еще одним (внутренним) уровнем памяти являются служебные ЗУ. Они могут иметь различное назначение.
Одним из примеров таких устройств являются ЗУ микропрограмм, которые иногда называют управляющей памятью. Другим – вспомогательные ЗУ, используемые для управления многоуровневой памятью.
В управляющей памяти, использующейся в ЭВМ с микропрограммным управлением, хранятся микропрограммы выполнения команд процессора, а также различных служебных операций.
Вспомогательные ЗУ для управления памятью (например, теговая память, используемая для управления кэш-памятью, буфер переадресации TLB – translation location buffer) представляют собой различные таблицы, используемые для быстрого поиска информации в разных ступенях памяти, отображения ее свойств, очередности перемещения между ступенями и пр.
Емкости и времена обращения к таким ЗУ зависят от их назначения. Обычно – это небольшие (до нескольких Кбайт), но быстродействующие ЗУ. Специфика назначения предполагает недоступность их командам процессора.
4. Следующим уровнем иерархии памяти является оперативная память. Оперативное ЗУ (ОЗУ) является основным запоминающим устройством ЭВМ, в котором хранятся выполняемые в настоящий момент процессором программы и обрабатываемые данные, резидентные программы, модули операционной системы и т.п. Название оперативной памяти также несколько изменялось во времени. В некоторых семействах ЭВМ ее называли основной памятью, основной оперативной памятью и пр. В англоязычной литературе также используется термин RAM (random access memory), означающий память с произвольным доступом.
Эта память используется в качестве основного запоминающего устройства ЭВМ для хранения программ, выполняемых или готовых к выполнению в текущий момент времени, и относящихся к ним данных. В оперативной памяти располагаются и компоненты операционной системы, необходимые для ее нормальной работы. Информация, находящаяся в ОЗУ, непосредственно доступна командам процессора, при условии соблюдения требований защиты.
Оперативная память реализуется на полупроводниках (интегральных схемах), стандартные объемы ее составляют (в начале 2000-х годов) сотни мегабайт – единицы гигабайт, а времена обращения – единицы÷десятки наносекунд.
5. Еще одним уровнем иерархии ЗУ может являться дополнительная память, которую иногда называли расширенной или массовой. Первоначально (1970-е годы) эта ступень использовалась для наращивания емкости оперативной памяти до величины, соответствующей адресному пространству (например, 24-битного адреса) команд, с помощью подключения более дешевого и емкого, чем ОЗУ, запоминающего устройства.
Это могла быть ферритовая память или даже память на магнитных дисках. Конечно, она была более медленной, а хранимая в ней информация сперва передавалась в оперативную память и только оттуда попадала в процессор. При записи путь был обратный.
Затем, в ранних моделях ПЭВМ, дополнительная память также использовалась для наращивания емкости ОЗУ и представляла собой отдельную плату с микросхемами памяти. А еще позже термин дополнительная память (extended или expanded memory) стал обозначать область оперативного ЗУ с адресами выше одного мегабайта. Конечно, этот термин применим только к IBM PC совместимым ПЭВМ.
6. В состав памяти ЭВМ входят также ЗУ, принадлежащие отдельным функциональным блокам компьютера. Формально эти устройства непосредственно не обслуживают основные потоки данных и команд, проходящие через процессор. Их назначение обычно сводится к буферизации данных, извлекаемых из каких-либо устройств и поступающих в них.
Типичным примером такой памяти является видеопамять графического адаптера, которая используется в качестве буферной памяти для снижения нагрузки на основную память и системную шину процессора.
Другими примерами таких устройств могут служить буферная память контроллеров жестких дисков, а также память, использовавшаяся в каналах (процессорах) ввода-вывода для организации одновременной работы нескольких внешних устройств.
Емкости и быстродействие этих видов памяти зависят от конкретного функционального назначения обслуживаемых ими устройств. Для видеопамяти, например, объем может достигать величин, сравнимых с оперативными ЗУ, а быстродействие – даже превосходить быстродействие последних.
7. Следующей ступенью памяти, ставшей фактически стандартом для любых ЭВМ, являются жесткие диски. В этих ЗУ хранится практически вся информация, которая используется более или менее активно, начиная от операционной системы и основных прикладных программ и кончая редко используемыми пакетами и справочными данными.
Емкость этой ступени памяти, которая может включать в свой состав до десятков дисков, обеспечивая хранение очень большого количества данных, зависит от области применения ЭВМ. Типовая емкость жесткого диска, составляющая на начало 2000-х годов десятки гигабайт, удваивается примерно каждые полтора года.
Со временами обращения дело обстоит несколько иначе: компоненты этого времени, обусловленные перемещением блока головок чтения-записи уменьшаются сравнительно медленно (примерно вдвое за 10 лет). Компонента, обусловленная временем подвода сектора и зависящая от скорости вращения шпинделя диска, также уменьшается с ростом этой скорости примерно такими же темпами. А скорость передачи данных растет значительно быстрее, что связано с увеличением плотности записи информации на диски.
8. Все остальные запоминающие устройства можно объединить с точки зрения функционального назначения в одну общую группу, охарактеризовав ее как группу внешних ЗУ. Под словом “внешние” следует подразумевать то, что информация, хранимая в этих ЗУ, в общем случае расположена на носителях не являющихся частью собственно ЭВМ. Под это определение подпадают гибкие диски, компакт диски, накопители на сменных магнитных дисках и магнитооптические диски, твердотельные (флэш) диски и флэш-карты, стримеры, внешние винчестеры и др. Естественно, что параметры этих устройств достаточно различны. Функциональное назначение их обычно сводится либо к архивному хранению информации, либо к переносу ее од одного компьютера к другому.
Некоторые сомнения в принадлежности к данной категории могут вызвать сменные диски, устанавливаемые в салазки (rack). Такие диски, действительно, лучше отнести к предыдущей (седьмой) группе.
1.2.2. Классификация ЗУ по
принципу организации
Особенности организации ЗУ определяются, в первую очередь, используемыми технологиями, логикой их функционирования, а также некоторыми другими факторами. Эти особенности и соответствующие разновидности ЗУ перечисляются ниже.
1. По функциональным возможностям ЗУ можно
разделять:
- на простые, допускающие только хранение информации;
- многофункциональные, которые позволяют не только хранить, но и перерабатывать
хранимую информацию без участия процессора непосредственно в самих ЗУ [2].
Подход, используемый во второй группе ЗУ, в принципе, позволяет создать производительные системы с параллельной обработкой данных. В частности, похожие подходы используются в различных частях видеотракта компьютера.
2. По возможности изменения
информации различают ЗУ:
- постоянные (или с однократной записью);
- односторонние (с перезаписью или перепрограммируемые);
- двусторонние.
В постоянных ЗУ (ПЗУ) информация заносится либо при изготовлении, либо посредством записи (или, как иначе называют эту процедуру, программирования или прожига), которая может быть выполнена только однократно. В ходе такой записи изменяется сам носитель информации, например, пережигаются проводники в микросхемах ПЗУ или формируются лунки в отражающем слое CD-ROM.
Односторонними называют ЗУ, которые имеют существенно различные времена записи и считывания информации. Наиболее распространенными типами таких ЗУ являются перепрограммируемые постоянные ЗУ или компакт-диски с перезаписью – CD-RW. Время записи в устройствах этих типов значительно превышает время считывания информации.
К односторонним ЗУ можно отнести и ЗУ на приборах с зарядовой связью (ПЗС), в которых время записи (формирования изображения), вообще говоря, заметно меньше времени считывания (передачи изображения).
Двусторонние ЗУ имеют близкие значения времен чтения и записи. Типичными представителями таких ЗУ являются оперативные ЗУ и ЗУ на жестких дисках.
3. По способу доступа различают
ЗУ:
- с адресным доступом;
- с ассоциативным доступом.
При адресном доступе для записи или чтения место расположения информации в ЗУ определяется ее адресом. Логически адрес может иметь различную структуру. Например, в оперативных ЗУ адрес представляет собой двоичный код, одна часть разрядов которого указывают строку матрицы элементов памяти, а другая – столбец этой матрицы. На пересечении заданных строки и столбца находится искомая информация (см. рис.1). В ЗУ на магнитных дисках адрес может представлять собой либо комбинацию номеров цилиндра, головки и сектора (так называемая CHS-геометрия), либо логический номер сектора (LBA-адресация). Возможны и иные варианты.
В любом случае, заданный адрес отрабатывается схемами доступа ЗУ (дешифратором, блоком позиционирования головок и т.п.) таким образом, что в операции участвует соответствующая адресу область матрицы элементов памяти, запоминающей среды или носителя информации.
При этом, в зависимости от того, как именно срабатывает механизм
доступа, различают следующие виды адресного доступа:
- произвольный;
- прямой (циклический);
- последовательный.
Термин “память с произвольным доступом” (random access memory – RAM) применяют к ЗУ, в которых выбор места хранения информации производится непосредственным подключением входов и выходов элементов памяти (через буферы, усилители и логические элементы) к входным и выходным шинам ЗУ. Это наиболее быстрый вид адресного доступа, применяемый в оперативных ЗУ и кэш-памяти.
При прямом (циклическом) доступе непосредственной коммутации связей оказывается недостаточно. В таких ЗУ обычно происходит еще и перемещение данных относительно механизма чтения/записи, механизма чтения/записи относительно данных или и то и другое. Физически это может быть как механическое перемещение, например, в жестких дисках, перемещение областей намагниченности, как в ЗУ на магнитных доменах, перенос зарядов и др.
С логической точки зрения такие ЗУ можно сопоставить набору сдвигающих регистров, информация в которых сдвигается циклически и может вводиться в регистр или выводиться из него только в одном из разрядов. Термины “циклический” и “прямой” доступ близки по содержанию, хотя “прямой доступ” – имеет более широкий смысл.
Последовательный доступ характерен для ЗУ, использующих в качестве носителя информации (запоминающей среды) магнитную ленту, например, для стримеров. В таких ЗУ для доступа к блоку данных необходимо переместить носитель так, чтобы участок, на котором располагается требуемый блок данных, оказался под блоком головок чтения/записи.
Кроме того, при всех формах адресного доступа адресуемым элементом может быть не только байт или слово (как в оперативной памяти и кэш-памяти), но целый блок данных. Это обычно связано либо с конструктивными особенностями ЗУ, либо с большим временем доступа.
При ассоциативном доступе место хранения информации при чтении и записи определяется не адресом, а значением некоторого ключа поиска. Каждое записанное и хранимое в ассоциативной памяти слово имеет поле ключа. Значение этого ключа сравнивается со значением ключа поиска при чтении данных из памяти. В случае совпадения сравниваемых значений информация считывается из памяти.
Ассоциативная память эффективна для решения задач, связанных с поиском данных. Однако ее использование ограничено в силу сравнительно высокой ее сложности.
Действительно, с аппаратной точки зрения сам поиск может быть организован по-разному: последовательно по разрядам ключевых полей или параллельно по всем ключам во всем массиве памяти. Второй способ, конечно, более быстрый, но требует соответствующей организации (ключевой части) памяти, которая должна иметь для этого в ключевой части каждого хранимого слова схемы сравнения. Именно поэтому такая память существенно более дорогая, чем оперативная, и используется в основном для решения задач, требующих быстрого поиска в небольших объемах информации.
Одним из частых применений ассоциативной памяти является быстрое преобразование логических (линейных) адресов данных в физические (т.е. адреса ячеек памяти), выполняемое, например, так называемым буфером трансляции адресов. Другой близкой задачей является определение того, имеется ли требуемая информация в верхних уровнях ЗУ или необходима ее подкачка из более медленных ЗУ.
4. По организации носителя различают
ЗУ:
- с неподвижным носителем;
- с подвижным носителем.
В первых из них носитель механически неподвижен в процессе чтения и записи информации, что имеет место, например, в оперативных и кэш ЗУ, твердотельных дисках, ЗУ с переносом зарядов и др.
Для ЗУ второй группы чтение и запись информации сопровождаются механическим перемещением носителя, что обычно имеет место в различных ЗУ с магнитной записью, например в жестких и гибких дисках.
Однако, возможны и иные варианты. Например, фирмой IBM разрабатывается ЗУ с механическим перемещением записывающих и считывающих элементов (микроигл) и неподвижным носителем информации (пластиковой пленкой).
5. По возможности смены носителя
ЗУ могут быть:
- с постоянным носителем;
- со сменным носителем.
В ЗУ первого вида носитель является частью самого устройства и не может быть извлечен из него в процессе нормального функционирования (оперативные ЗУ, жесткие диски).
В ЗУ второй группы носитель не является собственной частью устройства и может устанавливаться в ЗУ и извлекаться из него в процессе работы (гибкие диски, CD-ROM-дисководы, карты памяти, магнито-оптические диски).
6. По способу подключения к
системе ЗУ делятся:
- на внутренние (стационарные);
- внешние (съемные).
В первом случае ЗУ, как правило, является обязательным компонентом вычислительной системы, устанавливается в корпусе системы (например, оперативная память) или интегрируется с другими ее компонентами (например, кэш-память).
Во втором случае устройство подключается к системе дополнительно и представляет собой отдельный блок. Подключение (и отключение) таких ЗУ, в зависимости от особенности их реализации, может производиться как при выключенной системе – так называемое “холодное подключение”, так и в работающей системе – “горячее подключение”.
Последний вариант в серверных системах предусматривают и для стационарных ЗУ (жестких дисков).
7. По количеству блоков,
образующих модуль или ступень памяти, можно различать:
- одноблочные ЗУ;
- многоблочные ЗУ.
Такое разделение может представлять интерес в том случае, когда в многоблочное ЗУ входят блоки (или банки памяти), допускающие возможность параллельной работы. В этом случае за счет одновременной работы блоков можно повысить общую производительность модуля (ступени) ЗУ, иначе называемую его пропускной способностью и измеряемую количеством информации, которое модуль может записать или считать в единицу времени.
Но возможность одновременной работы блоков еще не означает, что они именно так и будут работать. Чтобы это произошло, необходимо обращения системы к памяти более или менее равномерно распределять по различным блокам. Достичь этого можно различными способами, например запустить параллельные задачи или процессы (threads), работающие с разными блоками, либо разместить информацию, относящуюся к одному процессу, в разных блоках.
Однако, поскольку параллельные процессы в действительности выполняются параллельно только в многопроцессорных системах (в крайнем случае, в гиперпоточных архитектурах), то часто используют второй путь, прибегая к так называемому чередованию (interleave) адресов между блоками. Т.е. последовательные адреса или группы адресов адресного пространства назначают в различные блоки памяти так, как это показано на рис. 6,б. На этом рисунке показана память, состоящая из двух блоков, но на практике известны системы, допускающие расслоение по шестнадцати блокам.
Ясно, что в случае такого назначения адресов при выполнении какой-либо программы обращения к памяти будут распределяться по блокам достаточно равномерно. А при обмене блоком данных с другой ступенью памяти обращения по последовательным адресам тем более будут попадать в различные блоки памяти.
Рассматривая расслоение адресов, можно отметить его аналогию с некоторыми режимами работы RAID-контроллеров.
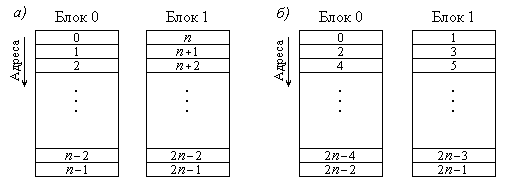
Рис. 6. Распределение адресов адресного пространства памяти по
блокам
(а – последовательное, б – с расслоением по блокам)
Конечно, за пределами приведенной классификации остались такие довольно представительные признаки, как физические принципы реализации, уровень потребляемой мощности, радиационная устойчивость и некоторые другие, которые в определенных случаях могут иметь немаловажное значение.
1.8. Запоминающие устройства
Мы уже знаем, что для хранения 1 бита информации может быть использован триггер. Набор триггеров образует регистровое запоминающее устройство. Выпускаемые промышленностью микросхемы памяти можно классифицировать по различным признакам. По функциональному назначению микросхемы памяти подразделяют на микросхемы постоянных запоминающих устройств (ПЗУ) и микросхемы оперативных запоминающих устройств (ОЗУ). Постоянные запоминающие устройства работают в режимах хранения и считывания информации. ОЗУ работают в режимах записи, хранения и считывания информации. ОЗУ применяются для хранения кодов выполняемых программ и промежуточных результатов обработки информации.
Существует четыре типа микросхем ПЗУ: ROM (Read Only Memory) – постоянные запоминающие устройства; PROM (Programmable ROM) – программируемые постоянные запоминающие устройства; EPROM (Erasable PROM) - перепрограммируемые постоянные запоминающие устройства с ультрафиолетовым стиранием информации; EEPROM (Electrically Erasable PROM) - перепрограммируемые постоянные запоминающие устройства с электронным стиранием информации, также называемые flash ROM.
В зависимости от элемента памяти (ЭП) микросхемы ОЗУ подразделяют на статические и динамические. В статических ОЗУ элементом памяти является триггер на биполярных или полевых транзисторах. В динамических ОЗУ элементом памяти является конденсатор, в качестве которого обычно используется затвор полевого транзистора.
На принципиальных схемах обычно используют обозначения выводов микросхемы в соответствии с сигналами, присутствующими на этих выводах: А – адрес, С – тактовый, ST – строб, CAS – выбор адреса столбца, RAS – выбор адреса строки, CS – выбор кристалла, E – разрешение, WR – запись, RD – считывание, WR/RD – запись-считывание, OE – разрешение выхода, D – данные (информация), DI – входные данные, DO – выходные данные, REF – регенерация, PR – программирование, ER – стирание, UPR – напряжение программирования, UCC – напряжение питания,0V – общий.
Рассмотрим обобщенную структурную схему запоминающего устройства, приведенную на рисунке 1.62. Матрица накопителя имеет m строк и n столбцов. На пересечении строки и столбца располагается элемент памяти. Матрица накопителя, имеющая m строк и n столбцов, имеет m·n ячеек памяти. Для выборки строк и столбцов используют дешифраторы или демультиплексоры.
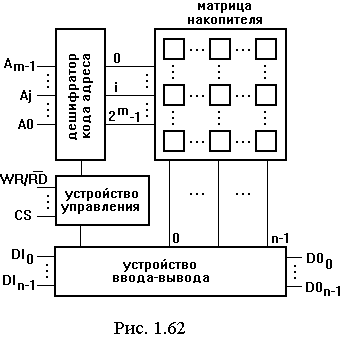
В запоминающих устройствах статического типа в качестве элементов памяти используют триггеры на биполярных или полевых транзисторах. Большее быстродействие имеют устройства на биполярных транзисторах. В качестве запоминающего элемента микросхем памяти статического типа может быть использован, например, D-триггер, снабженный специальным входом разрешения.
Для устойчивой работы микросхемы памяти при записи и чтении информации необходимо сигналы подавать в определенной последовательности и с допустимыми временными задержками. Микросхемы памяти характеризуются различными динамическими (временными) параметрами. Длительность сигнала обозначают tw(B), а интервал между сигналами tREC(B), где B – обозначение сигнала. Для сигнала CS эти записи имеют вид: tw(CS), tREC(CS). Время установления одного сигнала относительно другого tSU(B-C) определяется как интервал времени между началами двух сигналов на разных входах микросхемы, где В – обозначение сигнала, состояние которого изменяется первым, а С – обозначение сигнала, состояние которого изменяется в конце временного интервала. Время установления сигнала выборки микросхемы относительно сигналов адреса запишется в виде tSU(A-CS). Время сохранения одного сигнала после другого tV(B-C) определяется как интервал времени между окончаниями двух сигналов на разных входах микросхемы, например tV(CS-A) – время сохранения сигналов адреса после снятия сигнала выборки микросхемы. Важными динамическими параметрами микросхем памяти являются время выборки адреса tA(A) и время выборки tA(CS) (часто обозначается tCS) сигнала CS.
По режиму доступа микросхемы статических ОЗУ подразделяются на тактируемые и нетактируемые (асинхронные). Тактируемые микросхемы ОЗУ при каждом обращении к любой ячейке памяти требуют подачи импульса на вход CS. Сигналы разрешения выхода, записи-считывания могут быть поданы импульсом или уровнем.
Широкое распространение получили КМДП-микросхемы статических ОЗУ следующих серий К537, КМ1603, К581, К188, К176, К561. Большинство микросхем имеют питающее напряжение 5 В. Микросхемы памяти К561 допускают напряжение питания от 6 до 12 вольт. Микросхемы серии К176 имеют питающее напряжение 9В. В серии К537 имеется более 20 микросхем, отличающихся информационной емкостью, быстродействием и потребляемой мощностью. Среди микросхем этой серии имеются тактируемые и асинхронные.
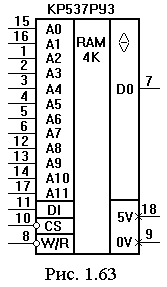
На рисунке 1.63 приведено условное обозначение микросхемы КР537РУ3. При CS=1 (микросхема не выбрана) выход D0 находится в высоимпедансном состоянии, а сигналы на адресных входах, входе DI и входе WR/RD могут быть любыми. Такой режим работы микросхемы называют режимом хранения. В режиме чтения на входе CS должен быть сигнал логического нуля, на входе WR/RD сигнал логической единицы, на адресных входах установлен адрес необходимой ячейки памяти, а на выходе D0 в этом случае будет содержимое ячейки памяти. Сигнал на входе DI в режиме чтения может быть любым. В режиме записи на входе CS должен быть сигнал логического нуля, на входе WR/RD сигнал логического нуля, на адресных входах установлен адрес необходимой ячейки памяти, а на входе DI данные, которые необходимо записать. Выход D0 находится в высокоимпедансном состоянии.
Запоминающий элемент памяти динамического типа имеет существенно меньше радиотехнических элементов (транзисторы, конденсаторы, резисторы) и следовательно можно на одном кристалле разместить значительно больше запоминающих элементов по сравнению с их числом для памяти статического типа. Микросхемы памяти динамического типа имеют существенно меньшее быстродействие. Время доступа к ячейке памяти динамического типа 60-70 нс, а время доступа к ячейке памяти микросхем статического типа около 2 нс. Микросхемы памяти статического типа в компьютерах используют для так называемой кэш-памяти.
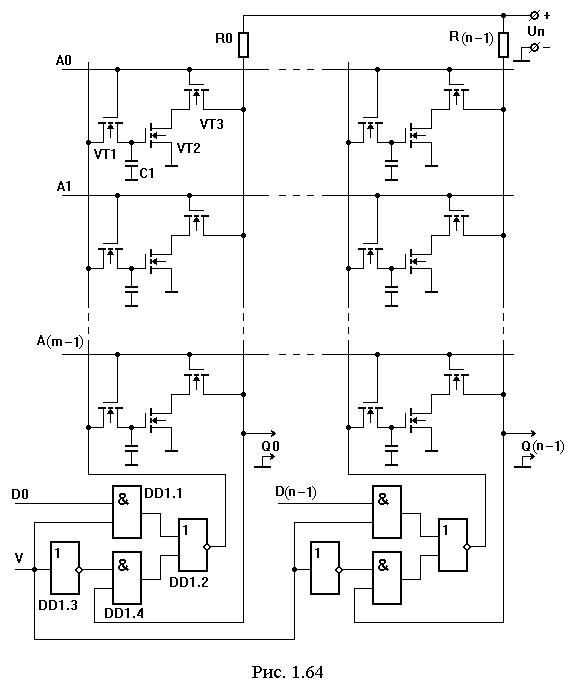
Рассмотрим принцип хранения и регенерации информации в ОЗУ динамического типа. На рисунке 1.64 приведена схема, позволяющая понять принцип записи и регенерации информации в ОЗУ динамического типа. Данное запоминающее устройство содержит m строк по n разрядов каждая. Запоминающим элементом памяти динамического типа является конденсатор. В реальных устройствах конденсатор образован емкостью затвор-исток транзистора VТ2. Если конденсатор заряжен, то транзистор VТ2 будет открыт, и такое состояние ассоциируется с логическим нулем. Если конденсатор разряжен, то транзистор VТ2 будет закрыт, и это соответствует логической единице. Конденсатор с течением времени разряжается, так как электронные ключи VТ1, VТ3 не являются идеальными. В природе нет также идеального конденсатора. По этой причине необходимо конденсатор периодически подзаряжать, если он был заряжен.
Пусть на входе запись «V» уровень логического нуля, а конденсатор С1 был заряжен. Для восстановления заряда конденсатора необходимо периодически читать информацию. Рассмотрим разряд D0. Подадим напряжение логической единицы на линию выборки очередной строки, например, строки А0. В этом случае транзисторы VТ1, VТ3 открываются, транзистор VТ2 также
открыт, так как мы рассматриваем случай, когда конденсатор С1 заряжен. Резистор R0, канал транзистора VТ3 и канал транзистора VТ2 образуют делитель напряжения, подаваемого от источника питания. На линии чтения Q0 будет в этом случае напряжение логического нуля (выходное напряжение мало). Напряжение логического нуля подается на нижний вход элемента DD1.4, следовательно, на выходе элемента DD1.4 будет напряжение логического нуля. На выходе элемента DD1.2 будет напряжение логической единицы, так как на верхнем входе этого элемента в рассматриваемый момент времени напряжение логического нуля (на входе V логический нуль). Конденсатор С1 заряжается по цепи: выход элемента DD1.2 (логическая единица), через канал открытого транзистора VТ1, конденсатор С1, общий провод, минус источника питания.
Пусть конденсатор С1 разряжен. В этом случае на линии чтения будет напряжение, почти равное напряжению источника питания, то есть напряжение логической единицы. Это напряжение подается на нижний по схеме вход элемента DD1.4. На верхнем входе этого элемента в рассматриваемый момент времени напряжение логической единицы, так как на вход запись V подано напряжение логического нуля. На выходе элемента DD1.4 будет логическая единица, а на выходе логического элемента DD1.2 будет напряжение логического нуля и конденсатор С1 будет оставаться разряженным (конденсатор может заряжаться только по следующей цепи: выход элемента DD1.2, канал открытого транзистора VТ1, конденсатор С1, общий провод, минус источника). Таким образом, периодически читая информацию, мы обеспечиваем ее сохранность. Для записи информации на входе D0 устанавливают логический нуль, или логическую единицу, на вход «V» подают напряжение логической единицы и выбирают строку, в которой находится необходимая ячейка памяти.
Занесение информации в микросхемы ПЗУ осуществляется либо при их изготовлении, либо потребителем. Микросхемы, информацию в которые заносит потребитель, называют программируемыми (ППЗУ). Программирование микросхем ПЗУ осуществляется с помощью специального устройства, называемого программатором микросхем. Микросхемы ПЗУ, допускающие неоднократное программирование, называются репрограммируемыми ПЗУ (РПЗУ). По способу стирания информации в РПЗУ микросхемы подразделяют на микросхемы с ультрафиолетовым стиранием информации (СППЗУ) и со стиранием электрическим сигналом (ЭСПЗУ).
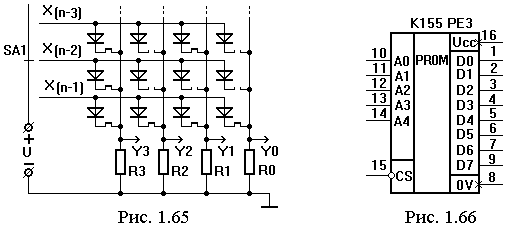
Рассмотрим однократно программируемые пользователем микросхемы ПЗУ с пережигаемыми перемычками. На рисунке 1.65 показан фрагмент запоминающего устройства, имеющего n слов по 4 двоичных разряда каждое. Слово выбирается переключателем SA1. В ПЗУ записаны следующие четырехразрядные слова: в строке X(n-3) – 1010, в строке X(n-2) –1000, и в строке X(n-1) –1111. Для записи слова 1000 в строке X(n-2) необходимо поочередно на короткое время (десятые доли секунды) закоротить резисторы R2, R1, R0.
В качестве примера ПЗУ с пережигаемыми перемычками рассмотрим микросхему К155РЕ3, условное обозначение которой приведено на рисунке 1.66.
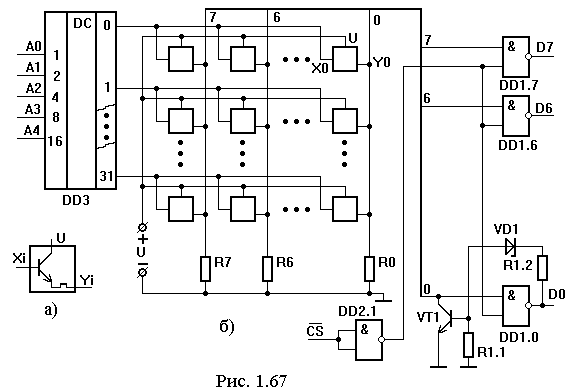
Упрощенная функциональная схема микросхемы К155РЕ3 приведена на рисунке 1.67. Логические элементы DD1.0-DD1.7 имеют выход с открытым коллектором. С выхода элемента DD1.0 на его вход подключается цепочка резистор R1.2, стабилитрон VD1, резистор R1.1, транзистор VT1, необходимая при программировании микросхемы. Для остальных логических элементов DD1.1-DD1.7 эти цепочки на функциональной схеме не показаны. При программировании на выход микросхемы через ограничительный резистор сопротивлением
390 Ом подается напряжение 10-15 В, в результате чего пробивается стабилитрон VD1 и открывается транзистор VT1. Открывшийся транзистор закорачивает резистор R0 и перемычка в эмиттерной цепи транзистора необходимой ячейки памяти перегорает (для пережигания перемычки на время программирования увеличивают питающее напряжение).
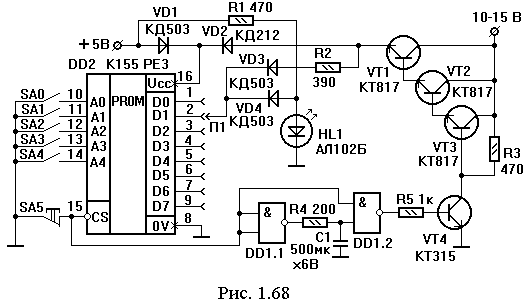
На рисунке 1.68 приведена схема простого программатора для микросхем К155РЕ3. Переключателями SA0-SA4 задается адрес требуемой ячейки памяти размером 8 бит. Логические элементы DD1.1, DD1.2, резистор R4, конденсатор C1 образуют одновибратор, формирующий импульс записи. Длительность импульса определяется сопротивлением резистора R4 и емкостью конденсатора C1. Кнопка SA5 находится в положении, соответствующем выбранной микросхеме. В этом случае светодиод HL1 отображает записанную в разряде D1 информацию. При нажатии на кнопку SA5 выходы программируемой микросхемы оказываются закрытыми, транзистор VT4 на короткое время закрывается, а транзисторы VT1-VT3 – открываются. На вывод 16 программируемой микросхемы подается повышенное напряжение. Кроме этого повышенное напряжение подается на один из выходов микросхемы, который подключается с помощью перемычки П1.
В репрограммируемых ПЗУ элементом памяти является специальный полевой транзистор с плавающим затвором. В зависимости от того имеет, или не имеет затвор заряд, ячейке памяти могут быть поставлены в соответствие либо логическая единица, либо логический нуль, причем любое из этих состояний может сохраняться в отсутствии питающего напряжения десятки тысяч часов.
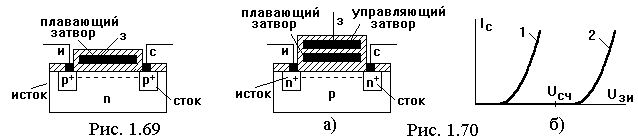
На рисунке 1.69 схематически изображен полевой транзистор с плавающим затвором с индуцированным каналом p-типа. Если плавающий затвор не имеет заряда, сопротивление между выводами стока и истока транзистора большое. При программировании между истоком и подложкой прикладывается большое импульсное напряжение, в результате чего электроны проходят через тонкий слой диэлектрика и накапливаются в затворе. Между стоком и истоком транзистора образуется канал p-типа.
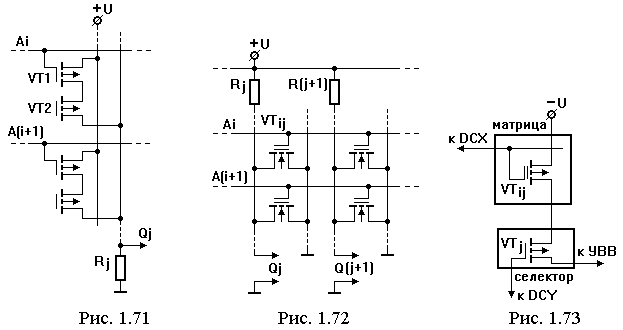
На рисунке 1.70,а показано схематически устройство полевого транзистора с плавающим и управляющим затворами с каналом n-типа, а на рисунке 1.70,б – стокозатворные характеристики этого транзистора для двух случаев (кривая 1 для случая отсутствия заряда на плавающем затворе, для кривой 2 плавающий затвор имеет отрицательный заряд). Выбрав напряжение считывания так, как показано на рисунке 1.70,б, получаем ячейку памяти для хранения 1 бита информации.
На рисунке 1.71 приведена схема, поясняющая принцип хранения информации в ПЗУ с ультрафиолетовым стиранием информации. Выборка необходимой строки в данном ПЗУ осуществляется подачей сигнала логического нуля на соответствующую строку. Пусть сигнал логического нуля подан на строку Ai и плавающий затвор транзистора VT2 имеет отрицательный заряд. В этом случае открывается транзистор VT1, а так как транзистор VT2 открыт, то на резисторе Rj будет напряжение логической единицы.
На рисунке 1.72 показан фрагмент запоминающего устройства с полевыми транзисторами с плавающим и управляющим затворами. Выборка строки осуществляется сигналом логической единицы. При такой организации запоминающего устройства отрицательный заряд на плавающем затворе соответствет хранению логической единицы.
На рисунке 1.73 приведен фрагмент запоминающего устройства, в котором адресация необходимой ячейки памяти производится с помощью дешифратора строк DCX и дешифратора столбцов DCY. В селекторе происходит выделение необходимого числа разрядов на одну ячейку памяти, и сигналы с селектора поступают на устройство ввода-вывода УВВ.

Микросхема К573РФ2 с ультрафиолетовым стиранием информации, условное обозначение которой приведено на рисунке 1.74, имеет емкость 2 килобайта и допускает 100 циклов программирования. Имеются 4 модификации этой микросхемы: РФ21, РФ22, РФ23, РФ24. Микросхемы РФ21, РФ22 имеют емкость 1К х 8 бит. На адресную линию А10 для микросхемы РФ21 подают логический нуль, а для микросхемы РФ22 – логическую единицу. Микросхемы РФ23, РФ24 имеют емкость 2К х 4 бит. В этих микросхемах используются все адресные линии. В микросхеме РФ23 для ввода-вывода данных используют линии 11, 13, 14, 16, а в микросхеме РФ24 – линии 10, 11, 13, 16.
Напряжение программирования 25 В на микросхему К573РФ2 и ее модификации подают постоянным уровнем. Считывание информации из микросхемы производится в асинхронном режиме доступа к накопителю, при котором сигналы на входы CS и OE подаются уровнями. Указанные сигналы можно подавать и в форме импульсов [29].
ЗАПОМИНАЮЩИЕ УСТРОЙСТВА ПК
РЕГИСТРОВАЯ КЭШ-ПАМЯТЬ
Регистровая КЭШ-память - высокоскоростная память сравнительно большой емкости, являющаяся буфером между ОП и МП и позволяющая увеличить скорость выполнения операций. Создавать ее целесообразно в ПК с тактовой частотой задающего генератора 40 МГц и более. Регистры КЭШ-памяти недоступны для пользователя, отсюда и название КЭШ (Cache), в переводе с английского означает "тайник".
В КЭШ-памяти хранятся данные, которые МП получил и будет использовать в ближайшие такты своей работы. Быстрый доступ к этим данным и позволяет сократить время выполнения очередных команд программы. При выполнении программы данные, считанные из ОП с небольшим опережением, записываются в КЭШ-память.
По принципу записи результатов различают два типа КЭШ-памяти:
КЭШ-память "с обратной записью" - результаты операций прежде, чем их записать в ОП, фиксируются в КЭШ-памяти, а затем контроллер КЭШ-памяти самостоятельно перезаписывает эти данные в ОП;
КЭШ-память "со сквозной записью" - результаты операций одновременно, параллельно записываются и в КЭШ-память, и в ОП.
Микропроцессоры начиная от МП 80486 имеют свою встроенную КЭШ-память (или КЭШ-память 1-го уровня), чем, в частности, и обусловливается их высокая производительность. Микропроцессоры Pentium и Pentium Pro имеют КЭШ-память отдельно для данных и отдельно для команд, причем если у Pentium емкость этой памяти небольшая - по 8 Кбайт, то у Pentium Pro она достигает 256 - 512 Кбайт.
Следует иметь в виду, что для всех МП может использоваться дополнительная КЭШ-память (КЭШ-память 2-го уровня), размещаемая на материнской плате вне МП, емкость которой может достигать нескольких мегабайтов.
Примечание. Оперативная память может строиться на микросхемах динамического (Dinamic Random Access Memory - DRAM) или статического (Static Random Access Memory - SRAM) типа. Статический тип памяти обладает существенно более высоким быстродействием, но значительно дороже динамического, Для регистровой памяти(МПП и КЭШ-память) используются SRAM, а ОЗУ основной памяти строится на базе DRAM-микросхем.
ОСНОВНАЯ ПАМЯТЬ
Физическая структура
Основная память содержит оперативное (RAM - Random Access Memory - память с произвольным доступом) и постоянное (ROM - Read-Only Memory) запоминающие устройства.
Оперативное запоминающее устройство предназначено для хранения информации (программ и данных), непосредственно участвующей в вычислительном процессе на текущем этапе функционирования ПК.
ОЗУ - энергозависимая память: при отключении напряжения питания информация, хранящаяся в ней, теряется. Основу ОЗУ составляют большие интегральные схемы, содержащие матрицы полупроводниковых запоминающих элементов (триггеров). Запоминающие элементы расположены на пересечении вертикальных и горизонтальных шин матрицы; запись и считывание информации осуществляются подачей электрических импульсов по тем шинам матрицы, которые соединены с элементами, принадлежащими выбранной ячейке памяти.
Конструктивно элементы оперативной памяти выполняются в виде отдельных микросхем типа DIP (Dual In-line Package - двухрядное расположение выводов) или в виде модулей памяти типа SIP (Single In-line Package - однорядное расположение выводов), или, что чаще, SIMM (Single In line Memory Module - модуль памяти с одноразрядным расположением выводов). Модули SIMM имеют емкость 256Кбайт, 1, 4, 8, 16 или 32 Мбайта, с контролем и без контроля четности хранимых битов; могут иметь 30- ("короткие") и 72-("длинные") контактные разъемы, соответствующие разъемам на материнской плате компьютера. На материнскую плату можно установить несколько (четыре и более) модулей SIMM.
Постоянное запоминающее устройство также строится на основе установленных на материнской плате модулей (кассет) и используется для хранения неизменяемой информации: загрузочных программ операционной системы, программ тестирования устройств компьютера и некоторых драйверов базовой системы ввода-вывода (BIOS - Base Input-Output System) и др. Из ПЗУ можно только считывать информацию, запись информации в ПЗУ выполняется вне ЭВМ в лабораторных условиях. Модули и кассеты ПЗУ имеют емкость, как правило, не превышающую нескольких сот килобайт. ПЗУ - энергонезависимое запоминающее устройство.
В последние годы в некоторых ПК стали использоваться полупостоянные. перепрограммируемые запоминающие устройства - FLASH-память. Модули или карты FLASH-памяти могут устанавливаться прямо в разъемы материнской платы и имеют следующие параметры: емкость от 32 Кбайт до 4 Мбайт, время доступа по считыванию 0.06 мкс, время записи одного байта примерно 10 мкс: FLASH-память - энергонезависимое запоминающее устройство.
Для перезаписи информации необходимо подать на специальный вход FLASH-памяти напряжение программирования (12В), что исключает возможность случайного стирания информации. Перепрограммирование FLASH- памяти может выполняться непосредственно с дискетыили с клавиатуры ПК при наличии; специального контроллера либо с внешнего программатора, подключаемого к ПК.
FLASH-память может быть полезной как для создания весьма быстродействующих компактных, альтернативных НЖМД запоминающих устройств - "твердотельных дисков", так и для замены ПЗУ, хранящего программы BIOS, позволяя "прямо с дискеты" обновлять и заменять эти программы на более новыеверсии при модернизации ПК.
Структурно основная память состоит из миллионов отдельных ячеек памяти емкостью 1 байт каждая. Общая емкость основной памяти современных ПК обычно лежит в пределах от 1 до 32 Мбайт. Емкость ОЗУ на один-два порядка превышает емкость ПЗУ: ПЗУ занимает 128 (реже 256) Кбайт, остальной объем - это ОЗУ.
Логическая структура основной памяти
Каждая ячейка памяти имеет свой уникальный (отличный от всех других) адрес. Основная память имеет для ОЗУ и ПЗУ единое адресное пространство.
Адресное пространство определяет максимально возможное количество непосредственно адресуемых ячеек основной памяти.
Адресное пространство зависит от разрядности адресных шин, ибо максимальное количество разных адресов определяется разнообразием двоичных чисел, которые можно отобразить в n разрядах, т.е. адресное пространство равно 2n, где n - разрядность адреса.
Для ПК характерно стандартное распределение непосредственно адресуемой памяти между ОЗУ, ПЗУ и функционально ориентированной информацией рис
Основная память в соответствии с методами доступа и адресации делится на отдельные, иногда частично или полностью перекрывающие друг друга области, имеющие общепринятые названия. В частности, укрупненно логическая структура основной памяти ПК обшей емкостью, например, 16 Мбайт представлена на рисунок

Рисунок Распределение 1-Мбайтной области ОП

Рисунок Логическая структура основной памяти
Прежде всего основная память компьютера делится на две логические области: непосредственно адресуемую память, занимающую первые 1024 Кбайта ячеек с адресами от 0 до 1024 Кбайт-1, расширенную память, доступ к ячейкам которой возможен при использовании специальных программ-драйверов.
Драйвер - специальная программа, управляющая работой памяти или внешними устройствами ЭВМ и организующая обмен информацией между МП, ОП и внешними устройствами ЭВМ.
Драйвер, управляющий работой памяти, называется диспетчером памяти.
Стандартной памятью (СМА - Conventional Memory Area) называется непосредственно адресуемая память в диапазоне от 0 до 640 Кбайт.
Непосредственно адресуемая память в диапазоне адресов от 640 до 1024 Кбайт называется верхней памятью (UMA - Upper Memory Area). Верхняя память зарезервирована для памяти дисплея (видеопамяти) и постоянного запоминающего устройства. Однако обычно в ней остаются свободные участки - "окна", которые могут быть использованы при помощи диспетчера памяти в качестве оперативной памяти общего назначения.
Расширенная память - это память с адресами 1024 Кбайта и выше.
Непосредственный доступ к этой памяти возможен только в защищенном режиме работы микропроцессора.
В реальном режиме имеются два способа доступа к этой памяти, но только при использовании драйверов:
по спецификации XMS (эту память называют тогда ХМА - eXtended Memory Area);
по спецификации EMS (память называют ЕМ -Expanded Memory).
Доступ к расширенной памяти согласно спецификации XMS (eXtended Memory Specification) организуется при использовании драйверов ХММ (extended Memory Manager). Часто эту память называют дополнительной, учитывая, что в первых моделях персональных компьютеров эта память размещалась на отдельных дополнительных платах, хотя термин Extended почти идентичен, термину Expanded и более точно переводится как расширенный, увеличенный.
Спецификация EMS (Expanded Memory Specification) является более ранней. Coгласно этой спецификации доступ реализуется путем отображения по мере необходимости отдельных полей Expanded Memory в определенную область верхней памяти. При этом хранится не обрабатываемая информация, а лишь адреса, обеспечивающие доступ к этой информации. Память, организуемая по спецификации EMS, носит название отображаемой, поэтому и сочетание слов Expanded Memory (EM) часто переводят как отображаемая память. Для организации отображаемой памяти необходимо воспользоваться драйвером EMM386.EXE (Expanded Memory Manager) или пакетом управления памятью QEMM.
Расширенная память может быть использована главным образом для хранения дат и некоторых программ ОС. Часто расширенную память используют для организации виртуальных (электронных) дисков.
Исключение составляет небольшая 64-Кбайтная область памяти с адресами от 1024 до 1088 Кбайт (так называемая высокая память, иногда ее называют старшая: НМА - High Memory Area), которая может адресоваться и непосредственно при использовании драйвера HIMEM.SYS (High Memory Manager) в соответствии со спецификацией XMS. НМА обычно используется для хранения программ и данных операционной системы.
В современных ПК существует режим виртуальной адресации (virtual - кажущийся, воображаемый). Виртуальная адресация используется для увеличения предоставляемой программам оперативной памяти за счет отображения в части адресного пространства фрагмента внешней памяти.
ВНЕШНЯЯ ПАМЯТЬ
Устройства внешней памяти или, иначе, внешние запоминающие устройства весьма разнообразны. Их можно классифицировать по целому ряду признаков: по виду носителя, типу конструкции, по принципу записи и считывания информации, методу доступа и т.д.
Носитель - материальный объект, способный хранить информацию.
Один из возможных вариантов классификации ВЗУ приведен на рисунке
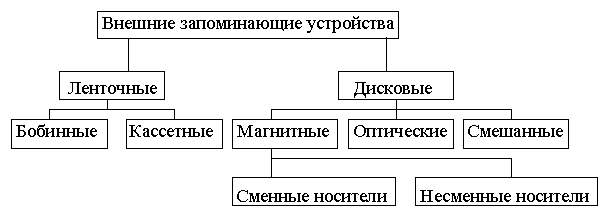
Рисунок Классификация ВЗУ
В зависимости от типа носителя все ВЗУ можно подразделить на накопители на магнитной ленте и дисковые накопители.
Накопители на магнитной ленте, в свою очередь, бывают двух видов: накопители на бобинной магнитной ленте (НБМЛ) и накопители на кассетной магнитной ленте (НКМ- стриммеры). В ПК используются только стриммеры.
Диски относятся к машинным носителям информации с прямым доступом. Понятие прямой доступ означает, что ПК может "обратиться" к дорожке, на которой начинается участок с искомой информацией или куда нужно записать новую информацию, непосредственно, где бы ни находилась головка записи/чтения накопителя.
Накопители на дисках более разнообразны :
- накопители на гибких магнитных дисках (НГМД), иначе, на флоппи-дисках или на дискетах;
- накопители на жестких магнитных дисках (НЖМД) типа "винчестер";
- накопители на сменных жестких магнитных дисках, использующие эффект Бернулли;
- накопители на флоптических дисках, иначе, floptical-накопители;
- накопители сверхвысокой плотности записи, иначе, VHD-накопители;
- накопители на оптических компакт-дисках CD-ROM (Compact Disk ROM);
- накопители на оптических дисках типа СС WORM (Continuous Composite Write Once Read Many - однократная запись - многократное чтение);
- накопители на магнитооптических дисках (НМОД) и др.
Таблица 1. Сравнительные характеристики дисковых накопителей
|
Тип накопления |
Емкость, Мбайт |
Время доступа, мс |
Трансфер, Кбайт/с |
Вид доступа |
|
НГМД |
1,2; 1,44 |
65-100 |
150 |
Чтение/запись |
|
Винчестер |
250-4000 |
8-20 |
500-3000 |
Чтение/запись |
|
Бернулли |
20-230 |
20 |
500-2000 |
Чтение/запись |
|
Floptical |
20,8 |
65 |
100-300 |
Чтение/запись |
|
VHD |
120-240 |
65 |
200-600 |
Чтение/запись |
|
CD-ROM |
250-1500 |
15-300 |
150-1500 |
Только чтение |
|
CC WORM |
120-1000 |
15-150 |
150-1500 |
Чтение/ однократная запись |
|
НМОД |
128-1300 |
15-150 |
300-1000 |
Чтение/запись |
Логическая структура диска
Магнитные диски (МД) относятся к магнитным машинным носителям информации. В качестве запоминающей среды у них используются магнитные материалы со специальными свойствами (с прямоугольной петлей гистерезиса), позволяющими фиксировать два магнитных состояния - два направления намагниченности. Каждому из этих состояний ставятся в соответствие двоичные цифры: 0 и 1. Накопители на МД (НМД) являются наиболее распространенными внешними запоминающими устройствами в ПК. Диски бывают жесткими и гибкими, сменными и встроенными в ПК. Устройство для чтения и записи информации на магнитном диске называется дисководом.
Все диски: и магнитные, и оптические характеризуются своим диаметром или, иначе, форм-фактором. Наибольшее распространение получили диски с форм-факторами 3,5" (89 мм) и 5,25" (133 мм). Диски с форм-фактором 3,5" при меньших габаритах имеют большую емкость, меньшее время доступа и более высокую скорость чтения данных подряд (трансфер), более высокие надежность и долговечность.
Информация на МД записывается и считывается магнитными головками вдоль концентрических окружностей - дорожек (треков). Количество дорожек на МД и их информационная емкость зависят от типа МД, конструкции накопителя на МД, качества магнитных головок и магнитного покрытия (см. рисунок ).
Каждая дорожка МД разбита на сектора. В одном секторе дорожки может быть помещено 128, 256, 512 или 1024 байт, но обычно 512 байт данных. Обмен данными между НМД и ОП осуществляется последовательно целым числом секторов. Кластер - это минимальная единица размещения информации на диске, состоящая из одного или нескольких смежных секторов дорожки.
При записи и чтении информации МД вращается вокруг своей оси, а механизм управления магнитной головкой подводит ее к дорожке, выбранной для записи или чтения информации.
Данные на дисках хранятся в файлах, которые обычно отождествляют с участком (областью, полем) памяти на этих носителях информации.
Файл - это именованная область внешней памяти, выделенная для хранения массива данный.
Поле памяти создаваемому файлу выделяется кратным определенному количеству кластеров. Кластеры, выделяемые одному файлу, могут находиться в любом свободном месте дисковой памяти и необязательно являются смежными. Файлы, хранящиеся в разбросанных по диску кластерах, называются фрагментированными.
Для пакетов магнитных дисков (диски установлены на одной оси) и для двухсторонних дисков вводится понятие "цилиндр". Цилиндром называется совокупность дорожек МД, находящихся на одинаковом расстоянии от его центра.
Накопители на гибких магнитных дисках
На гибком магнитном диске (дискете) магнитный слой наносится на гибкую основу. Используемые в ПК ГМД имеют форм-фактор 5,25" и 3,5". Емкость ГМД колеблется в пределах от 180 Кбайт до 2,88 Мбайта. ГМД диаметром 5,25 дюйма помещается в плотный гибкий конверт, а диаметром 3.5 дюйма - в пластмассовую кассету для защиты от пыли и механических повреждений.
Основные характеристики некоторых типов НГМД приведены в табл.2.
Таблица 2. Основные характеристики НГМД
Конструктивно дискета диаметром 133 мм изготовляется из гибкого пластика (лавсана), покрытого износоустойчивым ферролаком, и помещается в футляр-конверт. Дискета имеет две прорези: центральное отверстие для соединения с дисководом и смещенное от центра небольшое отверстие (обычно скрытое футляром), определяющее радиус-вектор начала всех дорожек на ГМД. Футляр также имеет несколько прорезей: центральное отверстие чуть большее, чем отверстие на дискете; широкое окно для считывающих и записывающих магнитных головок и боковую прорезь в виде прямоугольника, закрытие которой липкой лентой, например, защищает дискету от записи и стирания информации.
Дискета диаметром 89 мм имеет более жесткую конструкцию, более тщательно защищена от внешних воздействий, но в принципе имеет примерно те же конструктивные элементы. Режим запрета записи на этих дискетах устанавливается специальным переключателем, расположенным в одном из углов дискеты.
В последние годы появились дискеты с тефлоновым покрытием (например. Verbutim Data Life Plus), которое предохраняет магнитное покрытие и записанную на нем информацию от грязи, пыли, воды, жира, отпечатков пальцев и даже от растворителей типа ацетона. Возможная емкость 3,5-дюймовой дискеты Data Life Plus - 2,88 Мбайта. Следует упомянуть и дискеты "Go anywhere", распространяемые у нас в стране под названием "Вездеход". Они также обладают стойкостью к различным внешним воздействиям: температуре, влажности, запыленности.
Каждую новую дискету в начале работы с ней следует отформатировать.
Форматирование дискеты - это создание структуры записи информации на ее поверхности: разметка дорожек, секторов, записи маркеров и другой служебной информации.
Возможный вариант форматирования зависит от типа дискеты (маркируемого на ее конверте):
- SS/SD - односторонняя (Single Sides), одинарной плотности (Single Density);
- SS/DD - односторонняя, двойной плотности (Double Density);
- DS/SD - двухсторонняя (Double Sides), одинарной плотности;
- DS/DD - двухсторонняя, двойной плотности;
- DS/HD - двухсторонняя, высокой плотности (Hign Density), обеспечивающая максимальные емкости.
Правила обращения с дискетой:
- не сгибать дискету;
- не прикасаться руками к магнитному покрытию диска;
- не подвергать дискету воздействию магнитных полей;
- нужно хранить дискету в бумажном конверте при положительной температуре;
- надписи на приклеенной к дискете этикетке следует делать без нажима карандашом;
- брать дискету только за один угол защитного конверта;
- нельзя мыть дискету;
- нужно извлекать дискету перед выключением ПК;
- вставлять дискету в дисковод и вынимать ее из него только тогда, когда не горит сигнальная лампочка включения дисковода.
Накопители на жестких магнитных дисках
В качестве накопителей на жестких магнитных дисках (НЖМД) широкое распространение в ПК получили накопители типа "винчестер".
Термин винчестер возник из жаргонного названия первой модели жесткого диска емкостью 16 Кбайт (IBM, 1973 г.), имевшего 30 дорожек по 30 секторов, что случайно совпало с калибром "30/30" известного охотничьего ружья "Винчестер".
В этих накопителях один или несколько жестких дисков, изготовленных из сплавов алюминия или из керамики и покрытых ферролаком, вместе с блоком магнитных головок считывания/записи помещены в герметически закрытый корпус. Емкость этих накопителей благодаря чрезвычайно плотной записи, получаемой в таких несъемных конструкциях, достигает нескольких тысяч мегабайт; быстродействие их также значительно более высокое, нежели у НГМД.
Максимальные значения на 1995 г.:
- емкость 5000 Мбайт (стандарт емкости на 1995 г.-850 Мбайт);
- скорость вращения 7200 об./мин;
- время доступа - 6 мс;
- трансфер - 11 Мбайт/с.
НЖМД весьма разнообразны. Диаметр дисков чаще всего 3,5" (89 мм), но есть и другие, в частности 5,25" (133 мм) и 1,8" (45 мм). Наиболее распространенная высота корпуса дисковода 25 мм у настольных ПК, 41 мм - у машин-серверов, 12 мм - у портативных ПК и др.
В современных винчестерах стал использоваться метод зонной записи. В этом случае все пространство диска делится на несколько зон, причем во внешних зонах секторов размещается больше данных, чем во внутренних. Это, в частности, позволило увеличить емкость жестких дисков примерно на 30%.
Для того чтобы получить на магнитном носителе структуру диска, включающую в себя дорожки и сектора, над ним должна быть выполнена процедура, называемая физическим, или низкоуровневым, форматированием (physical, или low-level formatting). В ходе выполнения этой процедуры контроллер записывает на носитель служебную информацию, которая определяет разметку цилиндров диска на сектора и нумерует их. Форматирование низкого уровня предусматривает и маркировку дефектных секторов для исключения обращения к ним в процессе эксплуатации диска.
Максимальная емкость и скорость передачи данных существенно зависят от интерфейса, используемого накопителем.
Распространенный сейчас интерфейс AT Attachment (ATA), широкоизвестный и под именем Integrated Device Electronics (IDE), предложенный в 1988 г. пользователям ПК IBM PC/AT, ограничивает емкость одного накопителя 504 Мбайтами (эта емкость ограничена адресным пространством традиционной адресации "головка - цилиндр - сектор": 16 головок * 1024 цилиндра * 63 сектора * 512 байт в секторе = 504 Кбайта = 528 482 304 байта) и обеспечивает скорость передачи данных 5-10 Мбайт/с.
Интерфейс Fast ATA-2 или Enhanced IDE (EIDE), использующий как традиционную (но расширенную) адресацию по номерам головки, цилиндра и сектора, так и адресацию логических блоков (Logic Block Address LBA), поддерживает емкость диска до 2500 Мбайт и скорость обмена до 16 Мбайт/с. С помощью EIDE к материнской плате может подключаться до четырех накопителей, в том числе и CD-ROM, и НКМЛ. Для старых версий BIOS для поддержки EIDE нужен специальный драйвер.
Наряду с ATA и ATA-2 широко используются и две версии более сложных дисковых интерфейсов Small Computer System Interface (интерфейс малых компьютерных систем): SCSI и SCSI-2. Их достоинства: высокая скорость передачи данных (интерфейс Fast Wide SCSI-2 и ожидаемый в ближайшее время интерфейс SCSI-3 поддерживают скорость до 40 Мбайт/с), большое количество (до 7 шт.) и максимальная емкость подключаемых накопителей. Их недостатки: высокая стоимость (примерно в 5 -10 раз дороже ATA), сложность установки и настройки. Интерфейсы SCSI-2 и SCSI-3 рассчитаны на использование в мощных машинах-серверах и рабочих станциях.
Для повышения скорости обмена данными процессора с дисками НЖМД следует кэшировать. КЭШ-память для дисков имеет то же функциональное назначение, что и КЭШ для основной памяти, т.е. служит быстродействующим буфером памяти для кратковременного хранения информации, считываемой или записываемой на диск. КЭШ-память может быть встроенной в дисковод, а может создаваться программным путем (например, драйвером Microsoft Smartdrive) в оперативной памяти. Скорость обмена данными процессора с КЭШ-памятью диска может достигать 100 Мбайт/с.
В ПК имеется обычно один, реже несколько накопителей на жестких магнитных дисках. Однако в MS DOS (MicroSoft Disk Operation System - дисковая операционная система фирмы Microsoft) программными средствами один физический диск может быть разделен на несколько "логических" дисков; тем самым имитируется несколько НМД на одном накопителе.
Дисковые массивы RAID
В машинах-серверах баз данных и в суперЭВМ часто применяются дисковые массивы RAID (Redundant Array of Independent Disks - матрица с резервируемыми независимыми дисками), в которых несколько накопителей на жестких дисках объединены в один большой логический диск, при этом используются основанные на введении информационной избыточности методы обеспечения достоверности информации, существенно повышающие надежность работы системы (при обнаружении искаженной информации она автоматически корректируется, а неисправный накопитель в режиме Plug and Play (вставляй и работай) замещается исправным).
Существует несколько уровней базовой компоновки массивов RAID:
1-й уровень включает два диска, второй из которых является точной копией первого;
2-й уровень использует несколько дисков специально для хранения контрольных сумм и обеспечивает самый сложный функционально и самый эффективный метод исправления ошибок;
3-й уровень включает четыре диска: три информационных, а четвертый хранит контрольные суммы, обеспечивающие исправление ошибок в первых трех;
4-й и 5-й уровни используют диски, на каждом из которых хранятся свои собственные контрольные суммы.
Дисковые массивы второго поколения - RAID6 и RAID7. Последние могут объединять до 48 физических дисков любой емкости, формирующих до 120 логических дисков; имеют внутреннюю КЭШ-память до 256 Мбайт и разъемы для подключения внешних интерфейсов типа SCSI. Внутренняя шина X-bus имеет пропускную способность 80 Мбайт/с (для сравнения: трансфер SCSI-3 до 40 Мбайт/с, а скорость считывания с физического диска до 5 Мбайт/с).
Среднее время наработки на отказ в дисковых массивах RAID - сотни тысяч часов, а при 2-м уровне компоновки - до миллиона часов. В обычных НМД эта величина не превышает тысячи часов. Информационная емкость дисковых массивов RAID - от 3 до 700 Гбайт (максимальная достигнутая в 1995 г. емкость дисковых накопителей 5,5 Тбайта=5500 Гбайт).
Применяются и НЖМД со сменными пакетам и дисков (накопители Бернулли), использующие пакеты из дисков диаметром 133 мм, они имеют емкость от 20 до 230 Мбайт и меньшее быстродействие, но более дорогие, чем винчестеры. Основное их достоинство: возможность накопления и хранения пакетов вне ПК.
Основные направления улучшения характеристик НМД:
- использование высокоэффективных дисковых интерфейсов (E1DE, SCSI);
- использование более совершенных магнитных головок, позволяющих увеличить плотность записи и, следовательно, емкость диска и трансфер (без увеличения скорости вращения диска);
- применение зонной записи, при которой на внешних дорожках диска размещается больше данных, нежели на внутренних;
- эффективное кэширование диска.
Накопители на оптических дисках
В последние годы все большее распространение получают накопители на оптических дисках (НОД). Благодаря маленьким размерам (используются компакт-диски диаметром 3,5" и 5,25"), большой емкости и надежности эти накопители становятся все более популярными.
Неперезаписываемые лазерно-оптические диски обычно называют компакт-дисками ПЗУ - Compact Disk CD-ROM. Эти диски поставляются фирмой-изготовителем с уже записанной на них информацией (в частности, с программным обеспечением). Запись информации на них возможна только вне ПК, в лабораторных условиях, лазерным лучом большой мощности, который оставляет на активном слое CD след - дорожку с микроскопическими впадинами. Таким образом создается первичный "мастер-диск". Процесс массового тиражирования CD-ROM по "мастер-диску" выполняется путем литья под давлением. В оптическом дисководе ПК эта дорожка читается лазерным лучом существенно меньшей мощности.
CD-ROM ввиду чрезвычайно плотной записи информации имеют емкость от 250 Мбайт до 1,5 Гбайта, время доступа в разных оптических дисках также колеблется от 30 до 300 мс, скорость считывания информации от 150 до 1500 Кбайт/с.
Перезаписываемые лазерно-оптические диски с однократной (CD-R - CD Recordable) и многократной (CD-E - CD Erasable) записью должны появиться, по сообщениям зарубежной прессы, в 1996 г. На этих CD лазерный луч непосредственно в дисководе компьютера при записи прожигает микроскопические углубления на поверхности диска под защитным слоем; чтение записи выполняется лазерным лучом так же, как и у CD-ROM. Дисководы CD-E будут способны читать и обычные CD-ROM.
Перезаписываемые магнитооптические диски (СС-Е - Continuous Composite Erasable) используют лазерный луч для местного разогрева поверхности диска при записи информации магнитной головкой. Считывание информации выполняется лазерным лучом меньшей мощности.
Сущность процессов записи/считывания обусловлена следующим. Активный слой на поверхности магнитооптического диска может быть перемагничен магнитной головкой только при высокой температуре. Такая температура (сотни градусов) создается лазерным импульсом длительностью порядка 0,1 мкс. При считывании информации вектор поляризации отраженного от поверхности диска лазерного луча на несколько градусов изменяет свое направление в зависимости от направления намагниченного участка активного слоя. Изменение направления поляризации и воспринимается соответствующим датчиком,
Магнитооптические диски с однократной записью (СС WORM - Continuous Composite Write Once Read Many) аналогичны обычным магнитооптическим накопителям с той разницей, что в них на контрольные дорожки дисков наносятся специальные метки, предотвращающие стирание и повторную запись на диск.
В магнитооптических накопителях запись информации обычно осуществляется за два прохода, поэтому скорость записи значительно меньше скорости считывания.
Емкость современных магнитооптических дисков доходит до 2,6 Гбайта (ожидаются в ближайшее время СС-Е емкостью 5,2 Гбайта), время доступа от 15 до 150 мс, скорость считывания до 2000 Кбайт/с. Но перезаписывающие дисководы очень дороги (около тысячи долларов).
Основными достоинствами НОД являются:
- сменяемость и компактность носителей;
- большая информационная емкость;
- высокая надежность и долговечность CD и головок считывания/записи (до 50 лет);
- меньшая (по сравнению с НМД) чувствительность к загрязнениям и вибрациям;
- нечувствительность к электромагнитным полям.
Основными локальными интерфейсами для НОД являются интерфейсы EIDE и SCSI. В ПК используются также диски с высокой плотностью записи, на поверхности которых для более точного позиционирования магнитной головки используется лазерный луч. По внешнему виду эти диски напоминают 3,5-дюймовые (реже 5,25") дискеты, но имеют более жесткую конструкцию.
Среди накопителей, использующих такие диски, следует назвать:
- накопители на флоптических дисках - выполняют обычную магнитную запись информации, но со значительно большей плотностью размещения дорожек на поверхности диска. Такая плотность достигается ввиду наличия на дисках специальных нанесенных лазерным лучом серводорожек, служащих при считывании/записи базой для позиционирования лазерного луча, и соответственно магнитной головки, жестко связанной с лазером. Стандартная емкость флоптического диска 20,8 Мбайта;
- накопители сверхвысокой плотности записи (VHD - Very High Density) - используют кроме лазерного позиционирования еще и специальные дисководы, обеспечивающие иную технологию записи/считывания: "перпендикулярного" способа записи вместо обычного "продольного". Сейчас выпускаются VHD-диски емкостью 120-240 Мбайт; фирма Hewlett Packard объявила о создании диска емкостью 1000 Мбайт, а фирма IBM - дисков емкостью 8700 и 10800 Мбайт.
Накопители на магнитной ленте
Накопители на магнитной ленте были первыми ВЗУ вычислительных машин- В универсальных ЭВМ широко использовались и используются накопители на бобинной магнитной ленте, а в персональных ЭВМ - накопители на кассетной магнитной ленте.
Кассеты с магнитной лентой (картриджи) весьма разнообразны: они отличаются как шириной применяемой магнитной ленты, так и конструкцией. Объемы хранимой на одной кассете информации постоянно растут. Так, емкость картриджей первого поколения, содержащих магнитную ленту длиной 120 м, шириной 3,81 мм с 2 - 4 дорожками, не превышала 25 Мбайт; в конце 80-х гг. появились картриджи с большей плотностью записи на ленте шириной четверть дюйма (Quarter Inch Cartridge) (стандарты QIC - 40/80); первые такие картриджи были выпущены фирмой ЗМ - кассеты DC300 емкостью 60 - 250 Мбайт (поэтому этот стандарт часто называют стандарт ЗМ); последние модели картриджей (стандарт QIC 3010-3020) имеют емкость 340, 680 и даже 840-1700 Мбайт и более (стандарт QIC ЗОЮ - 3020 Wide, увеличивший ширину магнитной ленты до 0,315 дюйма). При сжатии данных может быть достигнута еще большая емкость, например, НКМЛ Conner CTD 8000 имеет емкость 8 Гбайт, Sony DDS-2 -16 Гбайт при трансфере 250 Кбайт/с.
Лентопротяжные механизмы для картриджей носят название стриммеров - это инерционные механизмы, требующие после каждой остановки ленты ее небольшой перемотки назад (перепозиционирования). Это перепозиционирование увеличивает и без того большое время доступа к информации на ленте (десятки секунд), поэтому стриммеры нашли применение в персональных компьютерах лишь для резервного копирования и архивирования информации с жестких дисков и в бытовых компьютерах для хранения пакетов игровых программ.
Скорость считывания информации с магнитной ленты в стриммерах также невысока и обычно составляет около 100 Кбайт/с. НКМЛ могут использовать локальные интерфейсы SCSI.
СРАВНИТЕЛЬНЫЕ ХАРАКТЕРИСТИКИ ЗАПОМИНАЮЩИХ УСТРОЙСТВ
Итак, персональные ЭВМ имеют четыре иерархических уровня памяти: микропроцессорную память, регистровую КЭШ-память, основную память, внешнюю память. Две важнейшие характеристики (емкость памяти и ее быстродействие) указанных типов памяти приведены в табл. 3.
Таблица 3. Сравнительные характеристики запоминающих устройств.
|
Тип памяти |
Емкость |
Быстродействие |
|
МПП |
Десятки байт |
tобр=0,001 - 0,004 мкс |
|
КЭШ-память |
Сотни килобайт |
tобр=0,002 - 0,005 мкс |
|
ОП ОЗУ ПЗУ |
Единицы- десятки мегабайт Сотни килобайт |
tобр=0,07 - 0,1 мкс tобр=0,07 - 0,2 мкс |
|
ВЗУ НЖМД НГМД CD-ROM |
Сотни мегабайт - единицы гигабайт Единицы мегабайт Сотни мегабайт - единицы гигабайт |
tд=7-30 мс Vсч=500-3000 Кбайт/с tд=50-100 мс Vсч=40-100 Кбайт/с tд=15-300 мс Vсч=150-1500 Кбайт/с |
Примечание. Общепринятые сокращения: с - секунда, мс - миллисекунда, мкс - микросекунда, нс - наносекунда;
1с = 103 =106 мкс=109-нс.
4. Аналого-цифровые и цифро-аналоговые преобразователи.
Отличительные особенности:
ATmega128 содержит 10-разр. АЦП последовательного приближения. АЦП связан с 8-канальным аналоговым мультиплексором, 8 однополярных входов которого связаны с линиями порта F. Общий входных сигналов должен иметь потенциал 0В (т.е. связан с GND). АЦП также поддерживает ввод 16 дифференциальных напряжений. Два дифференциальных входа (ADC1, ADC0 и ADC3, ADC2) содержат каскад со ступенчатым программируемым усилением: 0 дБ (1x), 20 дБ (10x), или 46 дБ (200x). Семь дифференциальных аналоговых каналов используют общий инвертирующий вход (ADC1), а все остальные входы АЦП выполняют функцию неинвертирующих входов. Если выбрано усиление 1x или 10x, то можно ожидать 8-разр. разрешение, а если 200x, то 7-разрядное.
АЦП содержит УВХ (устройство выборки-хранения), которое поддерживает на постоянном уровне напряжение на входе АЦП во время преобразования. Функциональная схема АЦП показана на рисунке 108.
АЦП имеет отдельный вывод питания AVCC (аналоговое питание). AVCC не должен отличаться более чем на ± 0.3В от VCC. См. параграф “Подавитель шумов АЦП”, где приведены рекомендации по подключению этого вывода.
В качестве внутреннего опорного напряжения может выступать напряжение от внутреннего ИОНа на 2.56В или напряжение AVCC. Если требуется использование внешнего ИОН, то он должен быть подключен к выводу AREF с подключением к этому выводу блокировочного конденсатора для улучшения шумовых характеристик.
Электроника для начинающих*
В этой статье рассмотрены
основные вопросы, касающиеся принципа действия АЦП различных типов. При этом
некоторые важные теоретические выкладки, касающиеся математического описания
аналого-цифрового преобразования остались за рамками статьи, но приведены
ссылки, по которым заинтересованный читатель сможет найти более глубокое
рассмотрение теоретических аспектов работы АЦП. Таким образом, статья касается
в большей степени понимания общих принципов функционирования АЦП, чем
теоретического анализа их работы.
 "
"
Введение
В качестве отправной точки дадим определение аналого-цифровому преобразованию.
Аналого-цифровое преобразование – это процесс преобразования входной физической
величины в ее числовое представление. Аналого-цифровой преобразователь –
устройство, выполняющее такое преобразование. Формально, входной величиной АЦП
может быть любая физическая величина – напряжение, ток, сопротивление, емкость,
частота следования импульсов, угол поворота вала и т.п. Однако, для определенности,
в дальнейшем под АЦП мы будем понимать исключительно преобразователи
напряжение-код.
Понятие аналого-цифрового преобразования тесно связано с понятием измерения.
Под измерением понимается процесс сравнения измеряемой величины с некоторым
эталоном, при аналого-цифровом преобразовании происходит сравнение входной
величины с некоторой опорной величиной (как правило, с опорным напряжением).
Таким образом, аналого-цифровое преобразование может рассматриваться как
измерение значения входного сигнала, и к нему применимы все понятия метрологии,
такие, как погрешности измерения.
Основные характеристики АЦП
АЦП имеет множество характеристик, из которых основными можно назвать частоту
преобразования и разрядность. Частота преобразования обычно выражается в отсчетах
в секунду (samples per second, SPS), разрядность – в битах. Современные АЦП
могут иметь разрядность до 24 бит и скорость преобразования до единиц GSPS
(конечно, не одновременно). Чем выше скорость и разрядность, тем труднее
получить требуемые характеристики, тем дороже и сложнее преобразователь.
Скорость преобразования и разрядность связаны друг с другом определенным
образом, и мы можем повысить эффективную разрядность преобразования,
пожертвовав скоростью.
Типы АЦП
Существует множество типов АЦП, однако в рамках данной статьи мы ограничимся
рассмотрением только следующих типов:
Существуют также и другие типы АЦП, в том числе конвейерные и комбинированные
типы, состоящие из нескольких АЦП с (в общем случае) различной архитектурой.
Однако приведенные выше архитектуры АЦП являются наиболее показательными в силу
того, что каждая архитектура занимает определенную нишу в общем диапазоне
скорость-разрядность.
Наибольшим быстродействием и самой низкой разрядностью обладают АЦП прямого
(параллельного) преобразования. Например, АЦП параллельного преобразования
TLC5540 фирмы Texas Instruments обладает быстродействием 40MSPS при разрядности
всего 8 бит. АЦП данного типа могут иметь скорость преобразования до 1 GSPS.
Здесь можно отметить, что еще большим быстродействием обладают конвейерные АЦП
(pipelined ADC), однако они являются комбинацией нескольких АЦП с меньшим
быстродействием и их рассмотрение выходит за рамки данной статьи.
Среднюю нишу в ряду разрядность-скорость занимают АЦП последовательного
приближения. Типичными значениями является разрядность 12-18 бит при частоте
преобразования 100KSPS-1MSPS.
Наибольшей точности достигают сигма-дельта АЦП, имеющие разрядность до 24 бит
включительно и скорость от единиц SPS до единиц KSPS.
Еще одним типом АЦП, который находил применение в недавнем прошлом, является
интегрирующий АЦП. Интегрирующие АЦП в настоящее время практически полностью
вытеснены другими типами АЦП, но могут встретиться в старых измерительных
приборах.
АЦП прямого преобразования
АЦП прямого преобразования получили широкое распространение в 1960-1970 годах,
и стали производиться в виде интегральных схем в 1980-х. Они часто используются
в составе «конвейерных» АЦП (в данной статье не рассматриваются), и имеют
разрядность 6-8 бит при скорости до 1 GSPS.
Архитектура АЦП прямого преобразования изображена на рис. 1
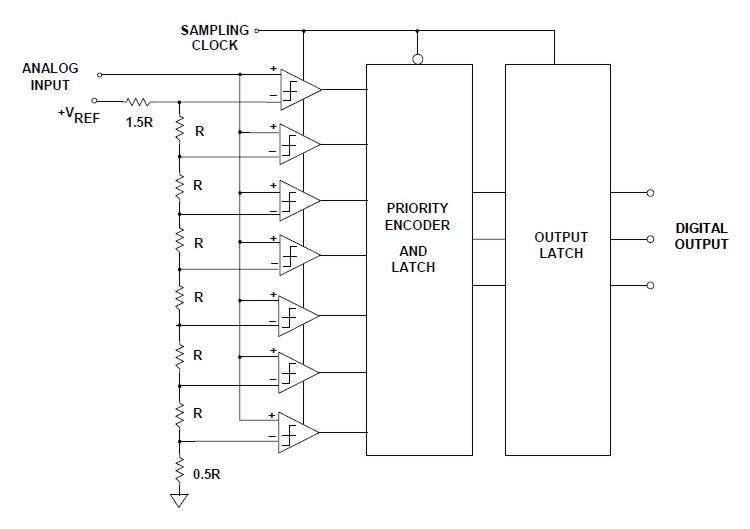
Рис. 1. Структурная схема АЦП прямого преобразования
Принцип действия АЦП предельно прост: входной сигнал поступает одновременно на
все «плюсовые» входы компараторов, а на «минусовые» подается ряд напряжений,
получаемых из опорного путем деления резисторами R. Для схемы на рис. 1 этот
ряд будет таким: (1/16, 3/16, 5/16, 7/16, 9/16, 11/16, 13/16) Uref, где Uref –
опорное напряжение АЦП.
Пусть на вход АЦП подается напряжение, равное 1/2 Uref. Тогда сработают первые
4 компаратора (если считать снизу), и на их выходах появятся логические
единицы. Приоритетный шифратор (priority encoder) сформирует из «столбца»
единиц двоичный код, который фиксируется выходным регистром.
Теперь становятся понятны достоинства и недостатки такого преобразователя. Все
компараторы работают параллельно, время задержки схемы равно времени задержки в
одном компараторе плюс время задержки в шифраторе. Компаратор и шифратор можно
сделать очень быстрыми, в итоге вся схема имеет очень высокое быстродействие.
Но для получения N разрядов нужно 2^N компараторов (и сложность шифратора тоже
растет как 2^N). Схема на рис. 1. содержит 8 компараторов и имеет 3 разряда,
для получения 8 разрядов нужно уже 256 компараторов, для 10 разрядов – 1024
компаратора, для 24-битного АЦП их понадобилось бы свыше 16 млн. Однако таких
высот техника еще не достигла.
АЦП последовательного приближения
АЦП последовательного приближения реализует алгоритм «взвешивания», восходящий
еще к Фибоначчи. В своей книге «Liber Abaci» (1202
г.) Фибоначчи рассмотрел «задачу о выборе наилучшей системы гирь», то есть о
нахождении такого ряда весов гирь, который бы требовал для нахождения веса
предмета минимального количества взвешиваний на рычажных весах. Решением этой
задачи является «двоичный» набор гирь. Подробнее о задаче Фибоначчи можно
прочитать, например, здесь: http://www.goldenmuseum.com/2015AMT_rus.html.
Аналого-цифровой преобразователь последовательного приближения (SAR, Successive
Approximation Register) измеряет величину входного сигнала, осуществляя ряд
последовательных «взвешиваний», то есть сравнений величины входного напряжения
с рядом величин, генерируемых следующим образом:
1. на первом шаге на выходе встроенного цифро-аналогового преобразователя
устанавливается величина, равная 1/2Uref (здесь и далее мы предполагаем, что
сигнал находится в интервале (0 – Uref).
2. если сигнал больше этой величины, то он сравнивается с напряжением, лежащим
посередине оставшегося интервала, т.е., в данном случае, 3/4Uref. Если сигнал
меньше установленного уровня, то следующее сравнение будет производиться с
меньшей половиной оставшегося интервала (т.е. с уровнем 1/4Uref).
3. Шаг 2 повторяется N раз. Таким образом, N сравнений («взвешиваний»)
порождает N бит результата.
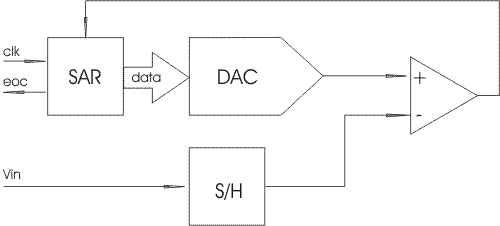
Рис. 2. Структурная схема АЦП последовательного приближения.
Таким образом, АЦП последовательного приближения состоит из следующих узлов:
1. Компаратор. Он сравнивает входную величину и текущее значение «весового»
напряжения (на рис. 2. обозначен треугольником).
2. Цифро-аналоговый преобразователь (Digital to Analog Converter, DAC). Он
генерирует «весовое» значение напряжения на основе поступающего на вход
цифрового кода.
3. Регистр последовательного приближения (Successive Approximation Register,
SAR). Он осуществляет алгоритм последовательного приближения, генерируя текущее
значение кода, подающегося на вход ЦАП. По его названию названа вся данная
архитектура АЦП.
4. Схема выборки-хранения (Sample/Hold, S/H). Для работы данного АЦП
принципиально важно, чтобы входное напряжение сохраняло неизменную величину в
течение всего цикла преобразования. Однако «реальные» сигналы имеют свойство
изменяться во времени. Схема выборки-хранения «запоминает» текущее значение
аналогового сигнала, и сохраняет его неизменным на протяжении всего цикла
работы устройства.
Достоинством устройства является относительно высокая скорость преобразования:
время преобразования N-битного АЦП составляет N тактов. Точность преобразования
ограничена точностью внутреннего ЦАП и может составлять 16-18 бит (сейчас стали
появляться и 24-битные SAR ADC, например, AD7766 и AD7767).
Дельта-сигма АЦП
И, наконец, самый интересный тип АЦП – сигма-дельта АЦП, иногда называемый в
литературе АЦП с балансировкой заряда. Структурная схема сигма-дельта АЦП
приведена на рис. 3.
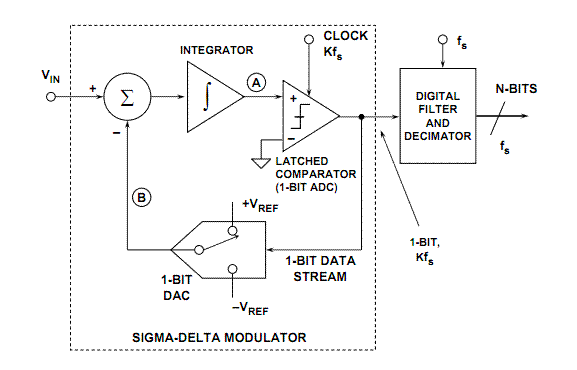
Рис.3. Структурная схема сигма-дельта АЦП.
Принцип действия данного АЦП несколько более сложен, чем у других типов АЦП.
Его суть в том, что входное напряжение сравнивается со значением напряжения,
накопленным интегратором. На вход интегратора подаются импульсы положительной
или отрицательной полярности, в зависимости от результата сравнения. Таким
образом, данный АЦП представляет собой простую следящую систему: напряжение на
выходе интегратора «отслеживает» входное напряжение (рис. 4). Результатом
работы данной схемы является поток нулей и единиц на выходе компаратора,
который затем пропускается через цифровой ФНЧ, в результате получается N-битный
результат. ФНЧ на рис. 3. Объединен с «дециматором», устройством, снижающим
частоту следования отсчетов путем их «прореживания».
Рис. 4. Сигма-дельта АЦП как следящая система
Ради строгости изложения, нужно сказать, что на рис. 3 изображена структурная
схема сигма-дельта АЦП первого порядка. Сигма-дельта АЦП второго порядка имеет
два интегратора и две петли обратной связи, но здесь рассматриваться не будет.
Интересующиеся данной темой могут обратиться к [3].
На рис. 5 показаны сигналы в АЦП при нулевом уровне на входе (сверху) и при
уровне Vref/2 (снизу).
Рис. 5. Сигналы в АЦП при разных уровнях сигнала на входе.
Более наглядно работу сигма-дельта АЦП демонстрирует небольшая программа,
находящаяся тут: http://designtools.analog.com/dt/sdtutorial/sdtutorial.html.
Теперь, не углубляясь в сложный математический анализ, попробуем понять, почему
сигма-дельта АЦП обладают очень низким уровнем собственных шумов.
Рассмотрим структурную схему сигма-дельта модулятора, изображенную на рис. 3, и
представим ее в таком виде (рис. 6):
Рис. 6. Структурная схема сигма-дельта модулятора
Здесь компаратор представлен как сумматор, который суммирует непрерывный
полезный сигнал и шум квантования.
Пусть интегратор имеет передаточную функцию 1/s. Тогда, представив полезный
сигнал как X(s), выход сигма-дельта модулятора как Y(s), а шум квантования как
E(s), получаем передаточную функцию АЦП:
Y(s) = X(s)/(s+1) + E(s)s/(s+1)
То есть, фактически сигма-дельта модулятор является фильтром низких частот
(1/(s+1)) для полезного сигнала, и фильтром высоких частот (s/(s+1)) для шума,
причем оба фильтра имеют одинаковую частоту среза. Шум, сосредоточенный в
высокочастотной области спектра, легко удаляется цифровым ФНЧ, который стоит
после модулятора.
Рис. 7. Явление «вытеснения» шума в высокочастотную часть спектра
Однако следует понимать, что это чрезвычайно упрощенное объяснение явления
вытеснения шума (noise shaping) в сигма-дельта АЦП.
Итак, основным достоинством сигма-дельта АЦП является высокая точность, обусловленная
крайне низким уровнем собственного шума. Однако для достижения высокой точности
нужно, чтобы частота среза цифрового фильтра была как можно ниже, во много раз
меньше частоты работы сигма-дельта модулятора. Поэтому сигма-дельта АЦП имеют
низкую скорость преобразования.
Они могут использоваться в аудиотехнике, однако основное применение находят в
промышленной автоматике для преобразования сигналов датчиков, в измерительных
приборах, и в других приложениях, где требуется высокая точность. но не требуется
высокой скорости.
Немного истории
Самым старым упоминанием АЦП в истории является, вероятно, патент Paul M.
Rainey, «Facsimile Telegraph System,» U.S. Patent 1,608,527, Filed July 20,
1921, Issued November 30, 1926. Изображенное в патенте устройство фактически
является 5-битным АЦП прямого преобразования.
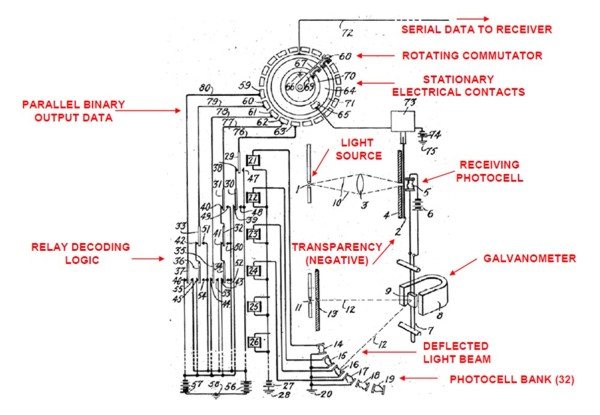
Рис. 8. Первый патент на АЦП

Рис. 9. АЦП прямого преобразования (1975
г.)
Устройство, изображенное на рисунке, представляет собой АЦП прямого
преобразования MOD-4100 производства Computer Labs, 1975 года выпуска, собранный
на основе дискретных компараторов. Компараторов 16 штук (они расположены
полукругом, для того, чтобы уравнять задержку распространения сигнала до
каждого компаратора), следовательно, АЦП имеет разрядность всего 4 бита.
Скорость преобразования 100 MSPS, потребляемая мощность 14 ватт.
На следующем рисунке изображена продвинутая версия АЦП прямого преобразования.

Рис. 10. АЦП прямого преобразования (1970
г.)
Устройство VHS-630 1970 года выпуска, произведенное фирмой Computer Labs,
содержало 64 компаратора, имело разрядность 6 бит, скорость 30MSPS и потребляло
100 ватт (версия 1975 года VHS-675 имела скорость 75 MSPS и потребление 130
ватт).
Цифро-аналоговый преобразователь (ЦАП) — устройство для преобразования цифрового (обычно двоичного) кода в аналоговый сигнал (ток, напряжение или заряд). Цифро-аналоговые преобразователи являются интерфейсом между дискретным цифровым миром и аналоговыми сигналами.
Аналого-цифровой преобразователь (АЦП) производит обратную операцию.
Звуковой ЦАП обычно получает на вход цифровой сигнал в импульсно-кодовой модуляции (англ. PCM, pulse-code modulation). Задача преобразования различных сжатых форматов в PCM выполняется соответствующими кодеками.
Наиболее общие типы электронных ЦАП:
Большинство ЦАП большой разрядности (более 16 бит) построены на этом принципе вследствие его высокой линейности и низкой стоимости. Быстродействие дельта-сигма ЦАП достигает сотни тысяч отсчетов в секунду, разрядность — до 24 бит. Для генерации сигнала с модулированной плотностью импульсов может быть использован простой дельта-сигма модулятор первого порядка или более высокого порядка как MASH (англ. Multi stage noise SHaping). С увеличением частоты передискретизации смягчаются требования, предъявляемые к выходному фильтру низких частот и улучшается подавление шума квантования;
ЦАП находятся в начале аналогового тракта любой системы, поэтому параметры ЦАП во многом определяют параметры всей системы в целом. Далее перечислены наиболее важные характеристики ЦАП.
Цифро-аналоговый преобразователь (ЦАП) - это устройство для преобразования цифрового кода в аналоговый сигнал по величине, пропорциональной значению кода.
ЦАП применяются для связи цифровых управляющих систем с устройствами, которые управляются уровнем аналогового сигнала. Также, ЦАП является составной частью во многих структурах аналого-цифровых устройств и преобразователей.
ЦАП характеризуется функцией преобразования. Она связывает изменение цифрового кода с изменением напряжения или тока. Функция преобразования ЦАП выражается следующим образом
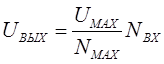 , где
, где
Uвых - значение выходного напряжения, соответствующее цифровому коду Nвх, подаваемому на входы ЦАП.
Uмах - максимальное выходное напряжение, соответствующее подаче на входы максимального кода Nмах
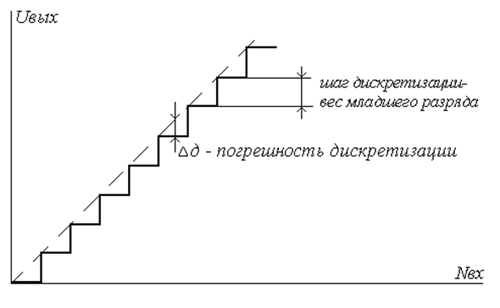
Величину Кцап, определяемую отношением ![]() ,
называют коэффициентом цифроаналогового преобразования. Несмотря на ступенчатый
вид характеристики, связанный с дискретным изменением входной величины
(цифрового кода), считается, что ЦАП являются линейными преобразователями.
,
называют коэффициентом цифроаналогового преобразования. Несмотря на ступенчатый
вид характеристики, связанный с дискретным изменением входной величины
(цифрового кода), считается, что ЦАП являются линейными преобразователями.
Если величину Nвх представить через значения весов его разрядов, функцию преобразования можно выразить следующим образом
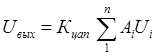 , где
, где
i - номер разряда входного кода Nвх; Ai - значение i-го разряда (ноль или единица); Ui – вес i-го разряда; n – количество разрядов входного кода (число разрядов ЦАП).
Вес разряда определяется для конкретной разрядности, и вычисляется по следующей формуле
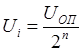 , где
, где
UОП - опорное напряжение ЦАП
Принцип работы большинства ЦАП - это суммирование долей аналоговых сигналов (веса разряда), в зависимости от входного кода.
ЦАП можно реализовать с помощью суммированием токов, суммированием напряжений и делением напряжения. В первом и втором случае в соответствии со значениями разрядов входного кода, суммируются сигналы генераторов токов и источников Э.Д.С. Последний способ представляет собой управляемый кодом делитель напряжения. Два последних способа не нашли широкого распространения в связи с практическими трудностями их реализации.

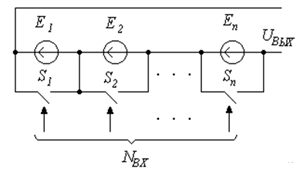
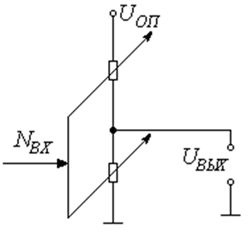
Рассмотрим построение простейшего ЦАП с взвешенным суммированием токов.

Этот ЦАП состоит из набора резисторов и набора ключей. Число ключей и число резисторов равно количеству разрядов n входного кода. Номиналы резисторов выбираются в соответствии с двоичным законом. Если R=3 Ом, то 2R= 6 Ом , 4R=12 Ом, и так и далее, т.е. каждый последующий резистор больше предыдущего в 2 раза. При присоединении источника напряжения и замыкании ключей, через каждый резистор потечет ток. Значения токов по резисторам, благодаря соответствующему выбору их номиналов, тоже будут распределены по двоичному закону. При подаче входного кода Nвх включение ключей производится в соответствии со значением соответствующих им разрядов входного кода. Ключ замыкается, если соответствующий ему разряд равен единице. При этом в узле суммируются токи, пропорциональные весам этих разрядов и величина вытекающего из узла тока в целом будет пропорциональна значению входного кода Nвх.
Сопротивление резисторов матрицы выбирают достаточно большое (десятки кОм). Поэтому для большинства практических случаев для нагрузки ЦАП играет роль источника тока. Если на выходе преобразователя необходимо получить напряжение, то на выходе такого ЦАП устанавливается преобразователь "ток-напряжение", например, на операционном усилителе
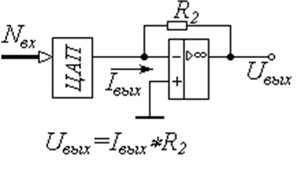
Однако при смене кода на входах ЦАП меняется величина тока, отбираемая от источника опорного напряжения. Это является главным недостатком такого способа построения ЦАП. Такой метод построения можно использовать только в том случае, если источник опорного напряжения будет с низким внутренним сопротивлением. В другом случае в момент смены входного кода изменяется ток, отбираемый у источника, что приводит к изменению падения напряжения на его внутреннем сопротивлении и, в свою очередь, к дополнительному напрямую не связанному со сменой кода изменению выходного тока. Исключить этот недостаток позволяет структура ЦАП с переключающимися ключами
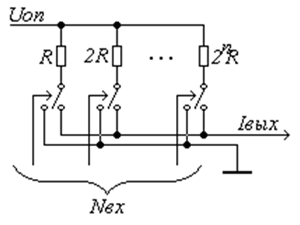
В такой структуре имеется два выходных узла. В зависимости от значения разрядов входного кода соответствующие им ключи подключаются к узлу, связанному с выходом устройства, или к другому узлу, который чаще всего заземляется. При этом через каждый резистор матрицы ток течет постоянно, независимо от положения ключа, а величина тока, потребляемого от источника опорного напряжения, постоянна.
Общим недостатком обоих рассмотренных структур является большое соотношение между наименьшим и наибольшим номиналом резисторов матрицы. Вместе с тем, не смотря на большую разницу номиналов резисторов необходимо обеспечивать одинаковую абсолютную точность подгонки как самого большого, так и самого маленького по номиналу резистора. В интегральном исполнении ЦАП при числе разрядов более 10 это обеспечить достаточно трудно.
От всех указанных выше недостатков свободны структуры на основе резистивных R-2R матриц
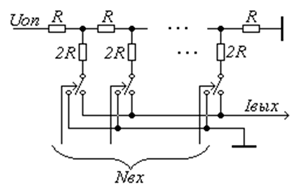
При таком построении резистивной матрицы ток в каждой последующей параллельной ветви меньше чем в предыдущей в два раза. Наличие только двух номиналов резисторов в матрице позволяет достаточно просто осуществлять подгонку их значений.
Выходной ток для каждой из представленных структур пропорционален одновременно не только величине входного кода, но и величине опорного напряжения. Часто говорят, что он пропорционален произведению этих двух величин. Поэтому такие ЦАП называют умножающими. Такими свойствами будут обладать все ЦАП, в которых формирование взвешенных значений токов, соответствующих весам разрядов, производится с помощью резистивных матриц.
Интегральные технологии позволяет достаточно просто формировать на кристалле резисторы, например, КМОП - технология. Как и все прочие ИС, созданные на ее основе, такие ЦАП, характеризуются низкой стоимостью и низким потреблением. Недостатком данной технологии- это паразитные емкости, и вытекающей из него низкое быстродействие. Большего быстродействия поможет достичь биполярная технология. НО она не рассчитана для создания точных резисторов, Поэтому при использовании таких технологий ЦАП делается на основе транзисторных источников тока. Зависимость выходного тока транзисторных источников тока от величины питающего напряжения не линейна, поэтому такие ЦАП умножающими не являются.
Кроме использования по прямому назначению умножающие ЦАП используются как аналого-цифровые перемножители, в качестве кодоуправляемых сопротивлений и проводимостей. Они широко применяются как составные элементы при построении кодоуправляемых (перестраиваемых) усилителей, фильтров, источников опорных напряжений, формирователей сигналов и т.д.
Основные параметры и погрешности ЦАП
Основные параметры, которые можно увидеть в справочнике:
1. Число разрядов – количество разрядов входного кода.
2. Коэффициент преобразования – отношение приращения выходного сигнала к приращению входного сигнала для линейной функции преобразования.
3. Время установления выходного напряжения или тока – интервал времени от момента заданного изменения кода на входе ЦАП до момента, при котором выходное напряжение или ток окончательно войдут в зону шириной младшего значащего разряда (МЗР).
4. Максимальная частота преобразования – наибольшая частота смены кода, при которой заданные параметры соответствуют установленным нормам.
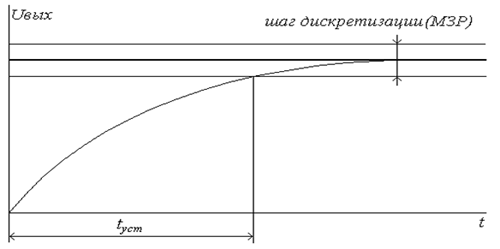
Существуют и другие параметры, характеризующие исполнение ЦАП и особенности его функционирования. В их числе: входное напряжение низкого и высокого уровня, ток потребления, диапазон выходного напряжения или тока.
Важнейшими параметрами для ЦАП являются те, которые определяют его точностные характеристики.
Точностные характеристики каждого ЦАП, прежде всего, определяются нормированными по величине погрешностями.
Погрешности делятся на динамические и статические. Статическими погрешностями называются погрешности, остающиеся после завершения всех переходных процессов, связанных со сменой входного кода. Динамические погрешности определяются переходными процессами на выходе ЦАП, возникшими вследствие смены входного кода.
Основные типы статических погрешностей ЦАП:
Абсолютная погрешность преобразования в конечной точке шкалы – отклонение значения выходного напряжения (тока) от номинального значения, соответствующего конечной точке шкалы функции преобразования. Измеряется в единицах младшего разряда преобразования.
Напряжение смещения нуля на выходе – напряжение постоянного тока на выходе ЦАП при входном коде, соответствующем нулевому значению выходного напряжения. Измеряется в единицах младшего разряда. Погрешность коэффициента преобразования (масштабная) –связанная с отклонением наклона функции преобразования от требуемого.
Нелинейность ЦАП – отклонение действительной функции преобразования от оговоренной прямой линии. Является самой плохой погрешностью с которой трудно бороться.
Погрешности нелинейности в общем случае разделяют на два типа – интегральные и дифференциальные.
Погрешность интегральной нелинейности – максимальное отклонение реальной характеристики от идеальной. Фактически при этом рассматривается усредненная функция преобразования. Определяют эту погрешность в процентах от конечного диапазона выходной величины.
Дифференциальная нелинейность связана с неточностью задания весов разрядов, т.е. с погрешностями элементов делителя, разбросом остаточных параметров ключевых элементов, генераторов токов и т.д.
Желательно, чтобы коррекция погрешностей производилось при изготовлении преобразователей (технологическая подгонка). Однако, часто она желательна и при использовании конкретного образца БИС в том или ином устройстве. В этом случае коррекция проводится введением в структуру устройства кроме БИС ЦАП дополнительных элементов. Такие методы получили название структурных.
Самым сложным процессом является обеспечение линейности, так как они определяются связанными параметрами многих элементов и узлов. Чаще всего осуществляют подгонку только смещения нуля, коэффициента
Точностные параметры, обеспечиваемые технологическими приемами, ухудшаются при воздействии на преобразователь различных дестабилизирующих факторов, в первую очередь – температуры. Необходимо помнить и о факторе старения элементов.
Погрешность смещения нуля и масштабная погрешность легко корректируются на выходе ЦАП. Для этого в выходной сигнал вводят постоянное смещение, компенсирующее смещение характеристики преобразователя. Необходимый масштаб преобразования устанавливают, либо корректируя коэффициент усиления, устанавливаемого на выходе преобразователя усилителя, либо подстраивая величину опорного напряжения, если ЦАП является умножающим.
Компенсационные методы заключаются во введении в структуру преобразователя вспомогательных резистивных матриц, управляемых кодом, обратным коду, подаваемому на основную матрицу. Это позволяет уменьшить паразитное влияние кодозависимых токов, протекающих по общим шинам земли и питания, стабилизирует рассеиваемую мощность и тепловой режим схемы.
Методы коррекции с тестовым контролем заключаются в идентификации погрешностей ЦАП на всем множестве допустимых входных воздействий и добавлением, рассчитанных на основе этого поправок, к входной или выходной величине для компенсации этих погрешностей.
При любом методе коррекции с контролем по тестовому сигналу предусматриваются следующие действия:
1. Измерение характеристики ЦАП на достаточном для идентификации погрешностей множестве тестовых воздействий.
2. Идентификация погрешностей вычислением их отклонений по результатам измерений.
3. Вычисление корректирующих поправок для преобразуемых величин или требуемых корректирующих воздействий на корректируемые блоки.
4. Проведение коррекции.
Контроль может проводиться один раз перед установкой преобразователя в устройство с помощью специального лабораторного измерительного оборудования. Может проводиться и с помощью специализированного оборудования встроенного в устройство. При этом контроль, как правило, проводится периодически, все то время пока преобразователь не участвует непосредственно в работе устройства. Такая организация контроля и коррекции преобразователей может осуществляться при его работе в составе микропроцессорной измерительной системы.
Основной недостаток любого метода сквозного контроля – большое время контроля наряду с разнородностью и большим объемом используемой аппаратуры.
Определенные тем или иным способом величины поправок хранятся, как правило, в цифровой форме. Коррекция же погрешностей с учетом этих поправок может проводиться как в аналоговой, так и цифровой форме.
При цифровой коррекции поправки добавляются с учетом их знака к входному коду ЦАП. В результате на вход ЦАП поступает код, при котором на его выходе формируется требуемое значение напряжения или тока. Наиболее простая реализация такого способа коррекции состоит из корректируемого ЦАП, на входе которого установлено цифровое запоминающее устройство (ЗУ). Входной код играет роль адресного. В ЗУ по соответствующим адресам занесены, заранее рассчитанные с учетом поправок, значения кодов, подаваемые на корректируемый ЦАП.
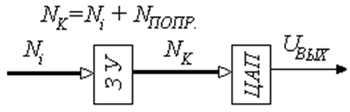
При аналоговой коррекции кроме основного ЦАП используется еще один дополнительный ЦАП. Диапазон его выходного сигнала соответствует максимальной величине погрешности корректируемого ЦАП. Входной код одновременно поступает на входы корректируемого ЦАП и на адресные входы ЗУ поправок. Из ЗУ поправок выбирается соответствующая данному значению входного кода поправка. Код поправки преобразуется в пропорциональный ему сигнал, который суммируется с выходным сигналом корректируемого ЦАП. Ввиду малости требуемого диапазона выходного сигнала дополнительного ЦАП по сравнению с диапазоном выходного сигнала корректируемого ЦАП собственными погрешностями первого пренебрегают.
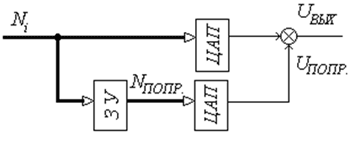
В ряде случаев возникает необходимость проведения коррекции динамики работы ЦАП.
Переходная характеристика ЦАП при смене различных кодовых комбинаций будет различной, иными словами – различным будет время установления выходного сигнала. Поэтому при использовании ЦАП необходимо учитывать максимальное время установления. Однако в ряде случаев удается корректировать поведение передаточной характеристики.
Для успешного применения современных БИС ЦАП недостаточно знать перечень их основных характеристик и основные схемы их включения.
Существенное влияние на результаты применения БИС ЦАП оказывает выполнение эксплуатационных требований, обусловленных особенностями конкретной микросхемы. К таким требованиям относятся не только использование допустимых входных сигналов, напряжения источников питания, емкости и сопротивления нагрузки, но и выполнение очередности включения разных источников питания, разделение цепей подключения разных источников питания и общей шины, применение фильтров и т.д.
Для прецизионных ЦАП особое значение приобретает выходное напряжение шума. Особенность проблемы шума в ЦАП заключается в наличии на его выходе всплесков напряжения, вызванных переключением ключей внутри преобразователя. По амплитуде эти всплески могут достигать нескольких десятков значений весов МЗР и создавать трудности в работе следующих за ЦАП устройств обработки аналоговых сигналов. Решением проблемы подавления таких всплесков является использование на выходе ЦАП устройств выборки-хранения (УВХ). УВХ управляется от цифровой части системы, формирующей новые кодовые комбинации на входе ЦАП. Перед подачей новой кодовой комбинации УВХ переводится в режим хранения, размыкая цепь передачи аналогового сигнала на выход. Благодаря этому всплеск выходного напряжения ЦАП не попадает на вывод УВХ, которое затем переводится в режим слежения, повторяя выходной сигнал ЦАП.
Специальное внимание при построении ЦАП на базе БИС необходимо уделять выбору операционного усилителя, служащего для преобразования выходного тока ЦАП в напряжение. При подаче входного кода ЦАП на выходе ОУ будет действовать ошибка DU, обусловленная его напряжением смещения и равная
![]() ,
,
где Uсм – напряжение смещения ОУ; Rос – величина сопротивления в цепи обратной связи ОУ; Rм – сопротивление резистивной матрицы ЦАП (выходное сопротивление ЦАП), зависящее от величины поданного на его вход кода.
Поскольку отношение ![]() изменяется от 1 до 0, ошибка,
обусловленная Uсм, изменяется в приделах (1...2)Uсм.
Влиянием Uсм пренебрегают при использовании ОУ, у
которого
изменяется от 1 до 0, ошибка,
обусловленная Uсм, изменяется в приделах (1...2)Uсм.
Влиянием Uсм пренебрегают при использовании ОУ, у
которого ![]() .
.
Вследствие большой площади транзисторных ключей в КМОП БИС существенная выходная емкость БИС ЦАП (40...120 пФ в зависимости от величины входного кода). Эта емкость оказывает существенное влияние на время установления выходного напряжения ОУ до требуемой точности. Для уменьшения этого влияния Rос шунтируют конденсатором Сос.
В ряде случаев на выходе ЦАП необходимо получать двуполярное выходное напряжение. Этого можно добиться введением на выходе смещения диапазона выходного напряжения, а для умножающих ЦАП переключением полярности источника опорного напряжения.
Следует обратить внимание, что если вы используете интегральный ЦАП, имеющий число разрядов большее чем вам нужно, то входы неиспользуемых разрядов подключают к земляной шине, однозначно определяя на них уровень логического нуля. Причем для того, чтобы работать по возможности с большим диапазоном выходного сигнала БИС ЦАП за таковые разряды принимают разряды, начиная с самого младшего.
Один из практических примеров применения ЦАП- это формирователи сигналов разной формы. Сделал небольшую модель в протеусе. С помощью ЦАП управляемого МК (Atmega8, хотя можно сделать и на Tiny), формируются сигналы различной формы. Программа написана на Си в CVAVR. По нажатию кнопки формируемый сигнал меняется .
БИС ЦАП DAC0808 National Semiconductor,8 –разрядный, высокоскоростной, включена согласно типовой схеме. Так как выход у него токовый, с помощью инвертирующего усилителя на ОУ преобразуется в напряжение.
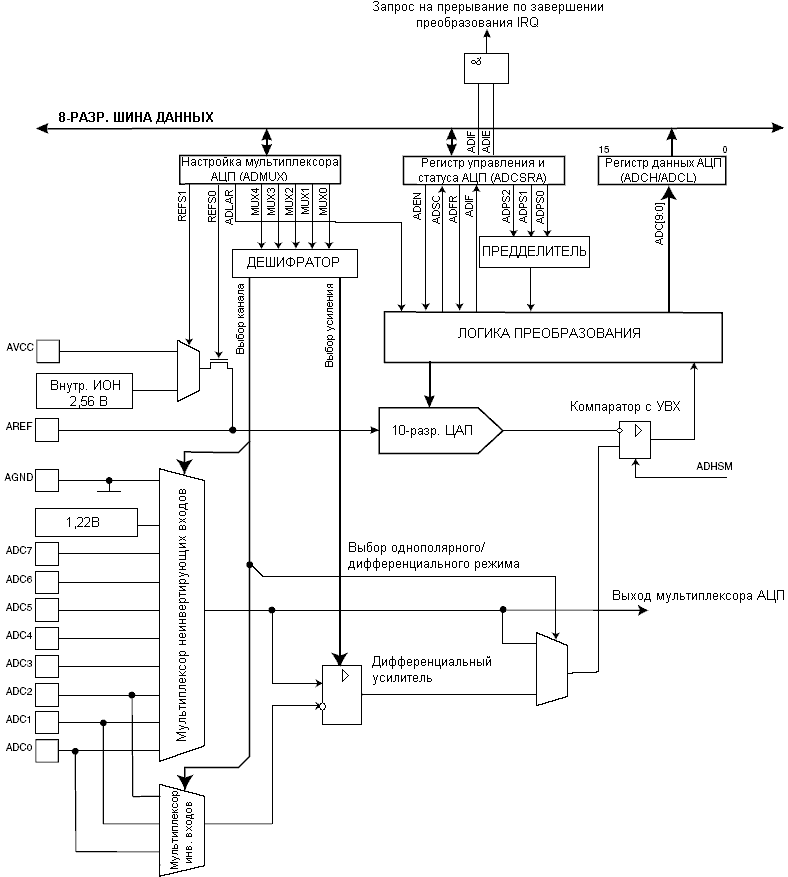
Рисунок 108 - Функциональная схема аналогово-цифрового преобразователя
Принцип действия
АЦП преобразовывает входное аналоговое напряжение в 10-разр. код методом последовательных приближений. Минимальное значение соответствует уровню GND, а максимальное уровню AREF минус 1 мл. разр. К выводу AREF опционально может быть подключено напряжение AVCC или внутренний ИОН на 1.22В путем записи соответствующих значений в биты REFSn в регистр ADMUX. Несмотря на то, что ИОН на 2.56В находится внутри микроконтроллера, к его выходу может быть подключен блокировочный конденсатор для снижения чувствительности к шумам, т.к. он связан с выводом AREF.
Канал аналогового ввода и каскад дифференциального усиления выбираются путем записи бит MUX в регистр ADMUX. В качестве однополярного аналогового входа АЦП может быть выбран один из входов ADC0…ADC7, а также GND и выход фиксированного источника опорного напряжения 1,22 В. В режиме дифференциального ввода предусмотрена возможность выбора инвертирующих и неинвертирующих входов к дифференциальному усилителю.
Если выбран дифференциальный режим аналогового ввода, то дифференциальный усилитель будет усиливать разность напряжений между выбранной парой входов на заданный коэффициент усиления. Усиленное таким образом значение поступает на аналоговый вход АЦП. Если выбирается однополярный режим аналогового ввода, то каскад усиления пропускается
Работа АЦП разрешается путем установки бита ADEN в ADCSRA. Выбор опорного источника и канала преобразования не возможно выполнить до установки ADEN. Если ADEN = 0, то АЦП не потребляет ток, поэтому, при переводе в экономичные режимы сна рекомендуется предварительно отключить АЦП.
АЦП генерирует 10-разрядный результат, который помещается в пару регистров данных АЦП ADCH и ADCL. По умолчанию результат преобразования размещается в младших 10-ти разрядах 16-разр. слова (выравнивание справа), но может быть опционально размещен в старших 10-ти разрядах (выравнивание слева) путем установки бита ADLAR в регистре ADMUX.
Практическая полезность представления результата с выравниванием слева существует, когда достаточно 8-разрядное разрешение, т.к. в этом случае необходимо считать только регистр ADCH. В другом же случае необходимо первым считать содержимое регистра ADCL, а затем ADCH, чем гарантируется, что оба байта являются результатом одного и того же преобразования. Как только выполнено чтение ADCL блокируется доступ к регистрам данных со стороны АЦП. Это означает, что если считан ADCL и преобразование завершается перед чтением регистра ADCH, то ни один из регистров не может модифицироваться и результат преобразования теряется. После чтения ADCH доступ к регистрам ADCH и ADCL со стороны АЦП снова разрешается.
АЦП генерирует собственный запрос на прерывание по завершении преобразования. Если между чтением регистров ADCH и ADCL запрещен доступ к данным для АЦП, то прерывание возникнет, даже если результат преобразования будет потерян.
Запуск преобразования
Одиночное преобразование запускается путем записи лог. 1 в бит запуска преобразования АЦП ADSC. Данный бит остается в высоком состоянии в процессе преобразования и сбрасывается по завершении преобразования. Если в процессе преобразования переключается канал аналогового ввода, то АЦП автоматически завершит текущее преобразование прежде, чем переключит канал.
В режиме автоматического перезапуска АЦП непрерывно оцифровывает аналоговый сигнал и обновляет регистр данных АЦП. Данный режим задается путем записи лог. 1 в бит ADFR регистра ADCSRA. Первое преобразование инициируется путем записи лог. 1 в бит ADSC регистра ADCSRA. В данном режиме АЦП выполняет последовательные преобразования, независимо от того сбрасывается флаг прерывания АЦП ADIF или нет.
Предделитель и временная диаграмма преобразования
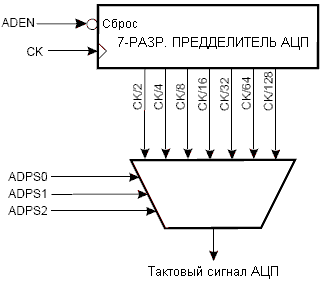
Рисунок 109 – Предделитель АЦП
Если требуется максимальная разрешающая способность (10 разрядов), то частота на входе схемы последовательного приближения должна быть в диапазоне 50…200 кГц. Если достаточно разрешение менее 10 разрядов, но требуется более высокая частота преобразования, то частота на входе АЦП может быть установлена свыше 200 кГц.
Модуль АЦП содержит предделитель, который формирует производные частоты свыше 100 кГц по отношению к частоте синхронизации ЦПУ. Коэффициент деления устанавливается с помощью бит ADPS в регистре ADCSRA. Предделитель начинает счет с момента включения АЦП установкой бита ADEN в регистре ADCSRA. Предделитель работает пока бит ADEN = 1 и сброшен, когда ADEN=0.
Если инициируется однополярное преобразование установкой бита ADSC в регистре ADCSRA, то преобразование начинается со следующего нарастающего фронта тактового сигнала АЦП. Особенности временной диаграммы дифференциального преобразования представлены в “Каналы дифференциального усиления”.
Нормальное преобразование требует 13 тактов синхронизации АЦП. Первое преобразование после включения АЦП (установка ADEN в ADCSRA) требует 25 тактов синхронизации АЦП за счет необходимости инициализации аналоговой схемы.
После начала нормального преобразования на выборку-хранение затрачивается 1.5 такта синхронизации АЦП, а после начала первого преобразования – 13,5 тактов. По завершении преобразования результат помещается в регистры данных АЦП и устанавливается флаг ADIF. В режиме одиночного преобразования одновременно сбрасывается бит ADSC. Программно бит ADSC может быть снова установлен и новое преобразование будет инициировано первым нарастающим фронтом тактового сигнала АЦП.
В режиме автоматического перезапуска новое преобразование начинается сразу по завершении предыдущего, при этом ADSC остается в высоком состоянии. Времена преобразования для различных режимов преобразования представлены в таблице 95.
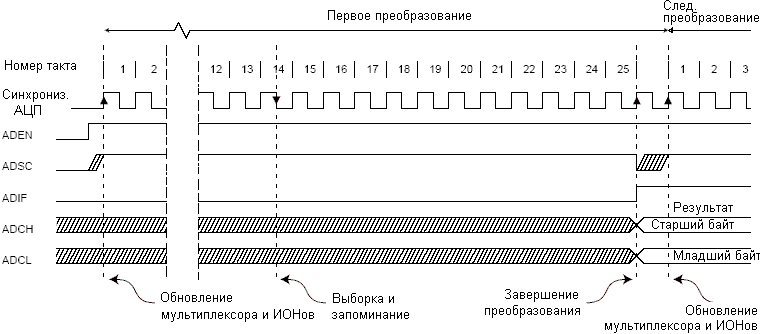
Рисунок 110 – Временная диаграмма работы АЦП при первом преобразовании в режиме
одиночного преобразования
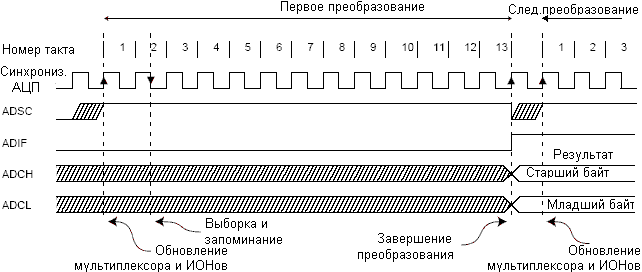
Рисунок 111 – Временная диаграмма работы АЦП в режиме одиночного преобразования
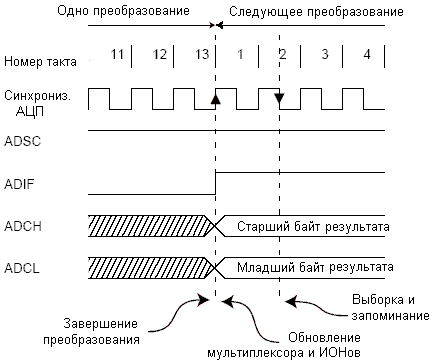
Рисунок 112 – Временная диаграмма работы АЦП в режиме автоматического
перезапуска
Таблица 95 – Время преобразования АЦП
|
Тип преобразования |
Длительность выборки-хранения (в тактах с момента начала преобразования) |
Время преобразования (в тактах) |
|
Первое преобразование |
14.5 |
25 |
|
Нормальное однополярное преобразование |
1.5 |
13 |
|
Нормальное дифференциальное преобразование |
1.5/2.5 |
13/14 |
Каналы дифференциального усиления
Если используются каналы дифференциального усиления, то необходимо принять во внимание некоторые особенности.
Дифференциальные преобразования синхронизированы по отношению к внутренней синхронизации CKАЦП2, частого которого равна половине частоты синхронизации АЦП. Данная синхронизация выполняется автоматически интерфейсом АЦП таким образом, чтобы выборка-хранение инициировалась определенным фронтом CKАЦП2. Если преобразование (все одиночные преобразования и первое преобразование в режиме автоматического перезапуска) инициировалось пользователем, когда CKАЦП2 находился в низком лог. состоянии, то его длительность будет эквивалента однополярному преобразованию (13 тактов синхронизации АЦП). Если преобразование инициируется пользователем, когда CKАЦП2 равен лог. 1 , оно будет длиться 14 тактов синхронизации АЦП вследствие работы механизма синхронизации. В режиме автоматического перезапуска новое преобразование инициируется сразу по завершении предыдущего, а т.к. в этот момент CKАЦП2 равен лог. 1, то все преобразования, которые были автоматически перезапущены (т.е. все, кроме первого), будут длиться 14 тактов синхронизации АЦП. Усилительный каскад оптимизирован под частотный диапазон до 4 кГц для любых коэффициентов усиления. Усиление сигналов более высоких частот будет нелинейным. Поэтому, если входной сигнал содержит частотные составляющие выше частотного диапазона усилительного каскада, то необходимо установить внешний фильтр низких частот. Обратите внимание, что частота синхронизации АЦП не связана с ограничением по частотному диапазону усилительного каскада. Например, период синхронизации АЦП может быть 6 мкс, при котором частота преобразования канала равна 12 тыс. преобр. в секунду, независимо от частотного диапазона этого канала.
Изменение канала или выбор опорного источника
Биты MUXn и REFS1:0 в регистре ADMUX поддерживают одноступенчатую буферизацию через временный регистр. Этим гарантируется, что новые настройки канала преобразования и опорного источника вступят в силу в безопасный момент для преобразования. До начала преобразования любые изменения канала и опорного источника вступаю в силу сразу после их модификации. Как только начинается процесс преобразования доступ к изменению канала и опорного источника блокируется, чем гарантируется достаточность времени на преобразование для АЦП. Непрерывность модификации возвращается на последнем такте АЦП перед завершением преобразования (перед установкой флага ADIF в регистре ADCSRA). Обратите внимание, что преобразование начинается следующим нарастающим фронтом тактового сигнала АЦП после записи ADSC. Таким образом, пользователю не рекомендуется записывать новое значение канала или опорного источника в ADMUX до 1-го такта синхронизации АЦП после записи ADSC.
Особые меры необходимо предпринять при изменении дифференциального канала. Как только осуществлен выбор дифференциального канала усилительному каскаду требуется 125 мкс для стабилизации нового значения. Следовательно, в течение первых после переключения дифференциального канала 125 мкс не должно стартовать преобразование. Если же в этот период преобразования все-таки выполнялись, то их результат необходимо игнорировать.
Такую же задержку на установление необходимо ввести при первом дифференциальном преобразовании после изменения опорного источника АЦП (за счет изменения бит REFS1:0 в ADMUX).
Если разрешена работа интерфейса JTAG, то функции каналов АЦП на выводах порта F 7…4 отменяется. См. табл. 42 и “Альтернативные функции порта F”.
Входные каналы АЦП
При переключении входного канала необходимо учесть некоторые рекомендации, которые исключат некорректность переключения.
В режиме одиночного преобразования переключение канала необходимо выполнять перед началом преобразования. Переключение канала может произойти только в течение одного такта синхронизации АЦП после записи лог. 1 в ADSC. Однако самым простым методом является ожидание завершения преобразования перед выбором нового канала.
В режиме автоматического перезапуска канал необходимо выбирать перед началом первого преобразования. Переключение канала происходит аналогично - в течение одного такта синхронизации АЦП после записи лог. 1 в ADSC. Но самым простым методом является ожидание завершения перового преобразования, а затем переключение канала. Поскольку следующее преобразование уже запущено автоматически, то следующий результат будет соответствовать предыдущему каналу. Последующие преобразования отражают результат для нового канала.
При переключении на дифференциальный канал первое преобразование будет характеризоваться плохой точностью из-за переходного процесса в схеме автоматической регулировки смещения. Следовательно, первый результат такого преобразования рекомендуется игнорировать.
Источник опорного напряжения АЦП
Источник опорного напряжения (ИОН) для АЦП (VИОН) определяет диапазон преобразования АЦП. Если уровень однополярного сигнала свыше VИОН, то результатом преобразования будет 0x3FF. В качестве VИОН могут выступать AVCC, внутренний ИОН 2,56В или внешний ИОН, подключенный к выв. AREF. AVCC подключается к АЦП через пассивный ключ. Внутреннее опорное напряжение 2,56В генерируется внутренним эталонным источником VBG, буферизованного внутренним усилителем. В любом случае внешний вывод AREF связан непосредственно с АЦП и, поэтому, можно снизить влияние шумов на опорный источник за счет подключения конденсатора между выводом AREF и общим. Напряжение VИОН также может быть измерено на выводе AREF высокоомным вольтметром. Обратите внимание, что VИОН является высокоомным источником и, поэтому, внешне к нему может быть подключена только емкостная нагрузка.
Если пользователь использует внешний опорный источник, подключенный к выв. AREF, то не допускается использование другой опции опорного источника, т.к. это приведет к шунтированию внешнего опорного напряжения. Если к выв. AREF не приложено напряжение, то пользователь может выбрать AVCC и 2.56В качестве опорного источника. Результат первого преобразования после переключения опорного источника может характеризоваться плохой точностью и пользователю рекомендуется его игнорировать.
Если используются дифференциальные каналы, то выбранный опорный источник должен быть меньше уровня AVCC, что показано в табл. 136.
Подавитель шумов АЦП
АЦП характеризуется возможностью подавления шумов, которые вызваны работой ядра ЦПУ и периферийных устройств ввода-вывода. Подавитель шумов может быть использован в режиме снижения шумов АЦП и в режиме холостого хода. При использовании данной функции необходимо придерживаться следующей процедуры:
Обратите внимание, что АЦП не отключается автоматически при переводе во все режимы сна, кроме режима холостого хода и снижения шумов АЦП. Поэтому, пользователь должен предусмотреть запись лог. 0 в бит ADEN перед переводом в такие режимы сна во избежание чрезмерного энергопотребления. Если работа АЦП была разрешена в таких режимах сна и пользователь желает выполнить дифференциальное преобразование, то после пробуждения необходимо включить, а затем выключить АЦП для инициации расширенного преобразования, чем будет гарантировано получение действительного результата.
Схема аналогового входа
Схема аналогового входа для однополярных каналов представлена на рисунке 113. Независимо от того, какой канал подключен к АЦП, аналоговый сигнал, подключенный к выв. ADCn, нагружается емкостью вывода и входным сопротивлением утечки. После подключения канала к АЦП аналоговый сигнал будет связан с конденсатором выборки-хранения через последовательный резистор, сопротивление которого эквивалентно всей входной цепи.
АЦП оптимизирован под аналоговые сигналы с выходным сопротивлением не более 10 кОм. Если используется такой источник сигнала, то время выборки незначительно. Если же используется источник с более высоким входным сопротивлением, то время выборки будет определяться временем, которое требуется для зарядки конденсатора выборки-хранения источником аналогового сигнала. Рекомендуется использовать источники только с малым выходным сопротивлением и медленно изменяющимися сигналами, т.к. в этом случае будет достаточно быстрым заряд конденсатора выборки-хранения.
По отношению к каналам с дифференциальным усилением рекомендуется использовать сигналы с внутренним сопротивлением до нескольких сотен кОм. Следует предусмотреть, чтобы в предварительных каскадах формирования аналогового сигнала ко входу АЦП не вносились частоты выше fАЦП/2, в противном случае результат преобразования может быть некорректным. Если вероятность проникновения высоких частот существует, то рекомендуется перед АЦП установить фильтр низких частот.
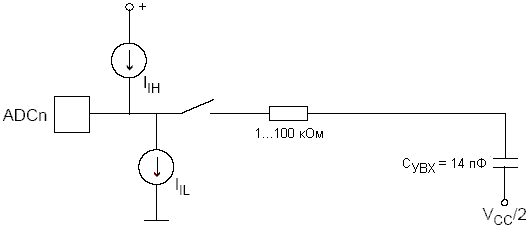
Рисунок 113 – Схема аналогового входа
Рекомендации по снижению влияния шумов на результат преобразования
Работа цифровых узлов внутри и снаружи микроконтроллера связана с генерацией электромагнитных излучений, которые могут негативно сказаться на точность измерения аналогового сигнала. Если точность преобразования является критическим параметром, то уровень шумов можно снизить, придерживаясь следующих рекомендаций:
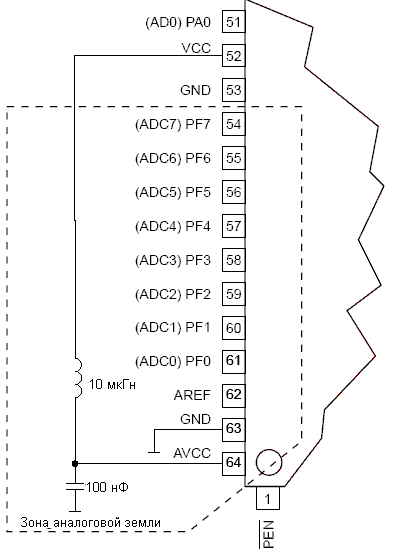
Рисунок 114 – Подключение питания АЦП
Методы компенсации смещения
Усилительный каскад имеет встроенную схему компенсации смещения, которая стремится максимально приблизить к нулю смещение дифференциального измерения. Оставшееся смещение можно измерить, если в качестве дифференциальных входов АЦП выбрать один и тот же вывод микроконтроллера. Измеренное таким образом остаточное смещение можно программно вычесть из результата преобразования. Использование программного алгоритма коррекции смещения позволяет уменьшить смещение ниже одного мл. разр.
Определения погрешностей аналогово-цифрового преобразования
n-разрядный однополярный АЦП преобразовывает напряжение линейно между GND и VИОН с количеством шагами 2n (мл. разрядов). Минимальный код = 0, максимальный = 2n-1. Основные погрешности преобразования являются отклонением реальной функции преобразования от идеальной. К ним относятся:
Смещение – отклонение первого перехода (с 0x000 на 0x001) по сравнению с идеальным переходом (т.е. при 0.5 мл. разр.). Идеальное значение : 0 мл. разр.
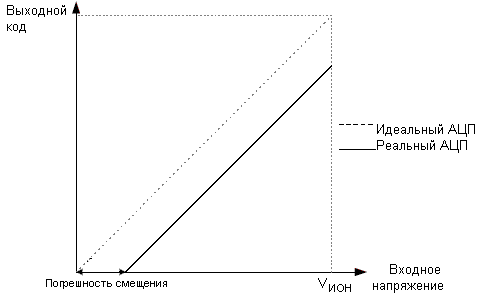
Рисунок 115 – Погрешность смещения
Погрешность усиления. После корректировки смещения погрешность усиления представляет собой отклонение последнего перехода (с 0x3FE на 0x3FF) от идеального перехода (т.е. отклонение при максимальном значении минус 1,5 мл. разр.). Идеальное значение: 0 мл. разр.
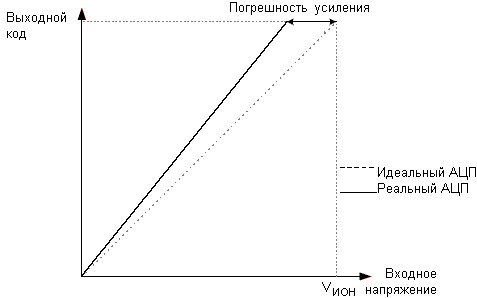
Рисунок 116 – Погрешность усиления
Интегральная нелинейность (ИНЛ). После корректировки смещения и погрешности усиления ИНЛ представляет собой максимальное отклонение реальной функции преобразования от идеальной для любого кода. Идеальное значение ИНЛ = 0 мл. разр.
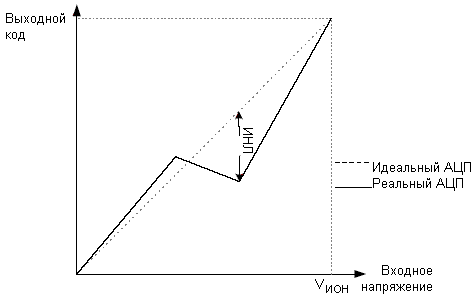
Рисунок 117 - Интегральная нелинейность (ИНЛ)
Дифференциальная нелинейность (ДНЛ). Максимальное отклонение между шириной фактического кода (интервал между двумя смежными переходами) от ширины идеального кода (1 мл. разр.). Идеальное значение: 0 мл. разр.
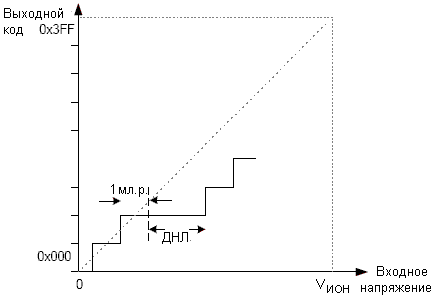
Рисунок 118 - Дифференциальная нелинейность (ДНЛ)
Погрешность квантования. Возникает из-за преобразования входного напряжения в конечное число кодов. Погрешность квантования- интервал входного напряжения протяженностью 1 мл. разр. (шаг квантования по напряжению), который характеризуется одним и тем же кодом. Всегда равен ±0.5 мл. разр.
Абсолютная погрешность. Максимальное отклонение реальной (без подстройки) функции преобразования от реальной при любом коде. Является результатом действия нескольких эффектов: смещение, погрешность усиления, дифференциальная погрешность, нелинейность и погрешность квантования. Идеальное значение: ±0.5 мл. разр.
Результат преобразования АЦП
По завершении преобразования (ADIF = 1) результат может быть считан из пары регистров результата преобразования АЦП (ADCL, ADCH).
Для однополярного преобразования:
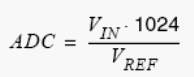
где Vвх – уровень напряжения на подключенном к АЦП входу;
Vион –напряжение выбранного источника опорного напряжения (см. табл. 97 и табл. 98). Код 0x000 соответствует уровню аналоговой земли, а 0x3FF - уровню напряжения ИОН минус 1 шаг квантования по напряжению. При использовании дифференциального канала
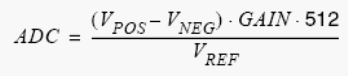
где
Vpos - напряжение на неинвертирующем (инвертирующем) входе;
Vneg - коэффициент усиления;
Vref - напряжение выбранного ИОН.
Результат представляется в коде двоичного дополнения, начиная с 0x200 (-512d) до 0x1FF (+511d). Обратите внимание, что при необходимости быстро определить полярность результата достаточно опросить старший бит результата преобразования (ADC9 в ADCH). Если данный бит равен лог. 1, то результат отрицательный, если же лог. 0, то положительный. На рисунке 119 представлена функция преобразования АЦП в дифференциальном режиме.
В таблице 96 представлены результирующие выходные коды для дифференциальной пары каналов (ADCn - ADCm) с коэффициентом усиления Ку и опорным напряжением VИОН.
Рисунок 119 – Функция преобразования АЦП при измерении дифференциального
сигнала
Таблица 96 – Связь между входным напряжением и выходными кодами
|
VАЦПn |
Считываемый код |
Соответствующее десятичное значение |
|
VАЦПm + VИОН /Ky |
0x1FF |
511 |
|
VАЦПm + 0.999 VИОН / Ky |
0x1FF |
511 |
|
VАЦПn + 0.998 VИОН / Ky |
0x1FE |
510 |
|
… |
... |
... |
|
VАЦПm + 0.001 VИОН / Ky |
0x001 |
1 |
|
VАЦПm |
0x000 |
0 |
|
VАЦПm - 0.001 VИОН / Ky |
0x3FF |
-1 |
|
… |
... |
... |
|
VАЦПm - 0.999 VИОН / Ky |
0x201 |
-511 |
|
VАЦПm – VИОН / Ky |
0x200 |
-512 |
Пример: Пусть ADMUX = 0xED (пара входов ADC3 - ADC2, Ку=1, Vион=2.56В, результат с левосторонним выравниванием), напряжение на входе ADC3 = 300 мВ, а на входе ADC2 = 500 мВ, тогда:
КодАЦП = 512 * 10 * (300 - 500) / 2560 = -400 = 0x270
С учетом выбранного формата размещения результата (левосторонний) ADCL = 0x00, а ADCH = 0x9C. Если же выбран правосторонний формат (ADLAR=0), то ADCL = 0x70, ADCH = 0x02.
Регистр управления мультиплексором АЦП– ADMUX
|
Разряд |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
|
|
REFS1 |
REFS0 |
ADLAR |
MUX4 |
MUX3 |
MUX2 |
MUX1 |
MUX0 |
ADMUX |
|
Чтение/запись |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
|
|
Исх. значение |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
Разряд 7:6 – REFS1:0: Биты выбора источника опорного напряжения
Данные биты определяют какое напряжение будет использоваться в качестве опорного для АЦП (см. табл. 97). Если изменить значения данных бит в процессе преобразования, то новые установки вступят в силу только по завершении текущего преобразования (т.е. когда установится бит ADIF в регистре ADCSRA). Внутренний ИОН можно не использовать, если к выводу AREF подключен внешний опорный источник.
Таблица 97 – Выбор опорного источника АЦП
|
REFS1 |
REFS0 |
Опорный источник |
|
0 |
0 |
AREF, внутренний VИОН отключен |
|
0 |
1 |
AVCC с внешним конденсатором на выводе AREF |
|
1 |
0 |
Зарезервировано |
|
1 |
1 |
Внутренний источник опорного напряжения 2.56В с внешним конденсатором на выводе AREF |
Разряд 5 – ADLAR: Бит управления представлением результата преобразования
Бит ADLAR влияет на представление результата преобразования в паре регистров результата преобразования АЦП. Если ADLAR = 1, то результат преобразования будет иметь левосторонний формат, в противном случае - правосторонний. Действие бита ADLAR вступает в силу сразу после изменения, независимо от выполняющегося параллельно преобразования. Полное описание действия данного бита представлено в “Регистры данных АЦП – ADCL и ADCH”.
Разряд 4:0 – MUX4:0: Биты выбора аналогового канала и коэффициента усиления
Данные биты определяют какие из имеющихся аналоговых входов подключаются к АЦП. Кроме того, с их помощью можно выбрать коэффициент усиления для дифференциальных каналов (см. табл. 98). Если значения бит изменить в процессе преобразования, то механизм их действия вступит в силу только после завершения текущего преобразования (после установки бита ADIF в регистре ADCSRA).
Таблица 98 – Выбор входного канала и коэффициента усиления
|
MUX4..0 |
Однополярный вход |
Неинвертирующий дифференциальный вход |
Инвертирующий дифференциальный вход |
Коэффициент усиления, Ку |
|
00000 |
ADC0 |
Нет |
||
|
00001 |
ADC1 |
|||
|
00010 |
ADC2 |
|||
|
00011 |
ADC3 |
|||
|
00100 |
ADC4 |
|||
|
00101 |
ADC5 |
|||
|
00110 |
ADC6 |
|||
|
00111 |
ADC7 |
|||
|
01000 |
Нет |
ADC0 |
ADC0 |
10 |
|
01001 |
ADC1 |
ADC0 |
10 |
|
|
01010 |
ADC0 |
ADC0 |
200 |
|
|
01011 |
ADC1 |
ADC0 |
200 |
|
|
01100 |
ADC2 |
ADC2 |
10 |
|
|
01101 |
ADC3 |
ADC2 |
10 |
|
|
01110 |
ADC2 |
ADC2 |
200 |
|
|
01111 |
ADC3 |
ADC2 |
200 |
|
|
10000 |
ADC0 |
ADC1 |
1 |
|
|
10001 |
ADC1 |
ADC1 |
1 |
|
|
10010 |
ADC2 |
ADC1 |
1 |
|
|
10011 |
ADC3 |
ADC1 |
1 |
|
|
10100 |
ADC4 |
ADC1 |
1 |
|
|
10101 |
ADC5 |
ADC1 |
1 |
|
|
10110 |
ADC6 |
ADC1 |
1 |
|
|
10111 |
ADC7 |
ADC1 |
1 |
|
|
11000 |
ADC0 |
ADC2 |
1 |
|
|
11001 |
ADC1 |
ADC2 |
1 |
|
|
11010 |
ADC2 |
ADC2 |
1 |
|
|
11011 |
ADC3 |
ADC2 |
1 |
|
|
11100 |
ADC4 |
ADC2 |
1 |
|
|
11101 |
|
ADC5ADC21 |
||
|
11110 |
1.23В (VBG) |
|||
Регистр А управления и статуса АЦП – ADCSRA
|
Разряд |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
|
|
ADEN |
ADSC |
ADFR |
ADIF |
ADIE |
ADPS2 |
ADPS1 |
ADPS0 |
ADCSRA |
|
Чтение/запись |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
Чт./Зп. |
|
|
Исх. значение |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
Разряд 7 – ADEN: Разрешение работы АЦП
Запись в данный бит лог. 1 разрешает работу АЦП. Если в данный бит записать лог. 0, то АЦП отключается, даже если он находился в процессе преобразования.
Разряд 6 – ADSC: Запуск преобразования АЦП
В режиме одиночного преобразования установка данного бита инициирует старт каждого преобразования. В режиме автоматического перезапуска установкой этого бита инициируется только первое преобразование, а все остальные выполняются автоматически. Первое преобразование после разрешения работы АЦП, инициированное битом ADSC, выполняется по расширенному алгоритму и длится 25 тактов синхронизации АЦП, вместо обычных 13 тактов. Это связано с необходимостью инициализации АЦП.
В процессе преобразования при опросе бита ADSC возвращается лог. 1, а по завершении преобразования – лог. 0. Запись лог. 0 в данный бит не предусмотрено и не оказывает никакого действия.
Разряд 5 – ADFR: Выбор режима автоматического перезапуска АЦП
Если в данный бит записать лог. 1, то АЦП перейдет в режим автоматического перезапуска. В этом режиме АЦП автоматически выполняет преобразования и модифицирует регистры результата преобразования через фиксированные промежутки времени. Запись лог. 0 в этот бит прекращает работу в данном режиме.
Разряд 4 – ADIF: Флаг прерывания АЦП
Данный флаг устанавливается после завершения преобразования АЦП и обновления регистров данных. Если установлены биты ADIE и I (регистр SREG), то происходит прерывание по завершении преобразования. Флаг ADIF сбрасывается аппаратно при переходе на соответствующий вектор прерывания. Альтернативно флаг ADIF сбрасывается путем записи лог. 1 в него. Обратите внимание, что при выполнении команды "чтение-модификация-запись" с регистром ADCSRA ожидаемое прерывание может быть отключено. Данное также распространяется на использование инструкций SBI и CBI.
Разряд 3 – ADIE: Разрешение прерывания АЦП
После записи лог. 1 в этот бит, при условии, что установлен бит I в регистре SREG, разрешается прерывание по завершении преобразования АЦП.
Разряды 2:0 – ADPS2:0: Биты управления предделителем АЦП
Данные биты определяют на какое значение тактовая частота ЦПУ будет отличаться от частоты входной синхронизации АЦП.
Таблица 99 – Управление предделителем АЦП
|
ADPS2 |
ADPS1 |
ADPS0 |
Коэффициент деления |
|
0 |
0 |
0 |
2 |
|
0 |
0 |
1 |
2 |
|
0 |
1 |
0 |
4 |
|
0 |
1 |
1 |
8 |
|
1 |
0 |
0 |
16 |
|
1 |
0 |
1 |
32 |
|
1 |
1 |
0 |
64 |
|
1 |
1 |
1 |
128 |
Регистры данных АЦП – ADCL и ADCH
ADLAR = 0:
|
Разряд |
15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
|
|
|
- |
- |
- |
- |
- |
- |
ADC9 |
ADC8 |
ADCH |
|
|
ADC7 |
ADC6 |
ADC5 |
ADC4 |
ADC3 |
ADC2 |
ADC1 |
ADC0 |
ADCL |
|
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
|
Чтение/запись |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
|
|
|
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
|
|
Исх. значение |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
|
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
ADLAR = 1:
|
Разряд |
15 |
14 |
13 |
12 |
11 |
10 |
9 |
8 |
|
|
|
ADC9 |
ADC8 |
ADC7 |
ADC6 |
ADC5 |
ADC4 |
ADC3 |
ADC2 |
ADCH |
|
|
ADC1 |
ADC0 |
- |
- |
- |
- |
- |
- |
ADCL |
|
|
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
|
|
Чтение/запись |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
|
|
|
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
Чт. |
|
|
Исх. значение |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
|
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
По завершении преобразования результат помещается в этих двух регистрах. При использовании дифференциального режима преобразования результат представляется в коде двоичного дополнения.
Если выполнено чтение ADCL, то доступ к этим регистрам для АЦП будет заблокирован (т.е. АЦП не сможет в дальнейшем модифицировать результат преобразования), пока не будет считан регистр ADCH.
Левосторонний формат представления результата удобно использовать, если достаточно 8 разрядов. В этом случае 8-разрядный результат хранится в регистре ADCH и, следовательно, чтение регистра ADCL можно не выполнять. При правостороннем формате необходимо сначала считать ADCL, а затем ADCH.
ADC9:0: Результат преобразования АЦП
5. Базовая модель последовательного микропроцессора. Адресация памяти. Взаимодействие микропроцессоров с микросхемами памяти.
(МП) - программно-управляемое универсальное устройство для цифровой обработки дискретной и (или) аналоговой информации и управления процессом этой обработки, построенное на одной или неск. больших интегральных схемах (БИС). По существу, МП может выполнять те же функции, что и процессор ЭВМ (или его составная часть),- отсюда с учётом изготовления его по технологии микроэлектроники произошло назв. "МП".
Области применения МП определяются, с одной стороны, возможностями МП как БИС - компонента электронных схем, а с другой - возможностями МП по обработке информации и управлению этим процессом, присущими ЭВМ. В совокупности с БИС постоянного запоминающего устройства (ПЗУ), оперативного запоминающего устройства (ОЗУ) (см. Памяти устройства )и БИС управления вводом-выводом информации МП позволяет создавать универсальные ЭВМ, причём он выполняет функции процессора (организацию работы ЭВМ, логич. и арифметич. обработку информации). Др. область применения МП - специа-лизиров. системы для сбора информации с объекта, её обработки и оптим. управления объектом. Примерами из этой области являются специализиров. управляющие МП (микроконтроллеры) и приборы со встроенной микропроцессорной системой ввода-вывода информации и её обработки (т. н. интеллектуальные приборы).
Спектр применений МП в физике определяется наряду с этим ещё двумя обстоятельствами. Во-первых, МП, работающий от внеш. источника энергии и управляющий состоянием замкнутой системы, способен управлять изменением её энтропии заданным образом [1]. Эта способность широко используется в автомати-зиров. устройствах управления системами для оптимизации либо повышения эффективности происходящих в них процессов (напр., удержание на заданном уровне темп-ры печи, в контур управления нагревателем к-рой включён МП). Во-вторых, любой алгоритм обработки информации можно реализовать программно (с помощью выполнения соответствующей программы универсальным МП) либо аппаратурно (с помощью епециализиров. МП, при разработке к-рого искомый алгоритм был реализован непосредственно в его электронной схеме). Последний способ обеспечивает макс, быстродействие алгоритма и представляет интерес в том случае, когда требуется обрабатывать информацию с частотой, превышающей частоту её обработки программным путём. Напр., для обработки изображений, следующих с частотой телевизионной развёртки, широко используется фурье-МП, аппаратурно реализующий алгоритмы быстрого преобразования Фурье.
МП характеризуются: полупроводниковой технологией изготовления интегральных схем, составляющих МП, их кол-вом; архитектурой (логич. организацией МП, определяющей процесс обработки информации в конкретном МП и включающей методы кодирования информации, состав, назначение и принципы взаимодействия аппаратурных средств МП); набором инструкций; ёмкостью адресуемой памяти; производительностью; стоимостью и др. [1, 2, 4, 5].
Первый МП - 4-разрядный Intel-4004 (фирма Intel, США) - появился в 1971 в ходе разработки программируемого калькулятора. Он состоял из 4 БИС, мог адресовать 4,5 кбайт памяти и имел 45 инструкций со временем выполнения 10-20 мкс. За ним в 1974 последовал 8-разрядный МП, а в 1976 насчитывалось уже св. 50 разд. типов МП. К 1989 разрядность МП увеличилась до 16-32 бит, время выполнения инструкций снизилось до 0,1-2 мкс, объём адресуемой памяти увеличился до десятков Мбайт.
По числу БИС, составляющих МП, их можно условно разделить на два существенно различных класса: однокристальные и многокристальные.
Однокристальные МП (ОМП) - функционально законченные процессоры с фиксируемыми разрядностью и набором инструкций. При этом инструкциями процессора являются инструкции ОМП. Обычно архитектура систем, построенных непосредственно на основе таких МП, повторяет архитектуру МП. Для построения системы достаточно подключить к ОМП блоки ОЗУ, ПЗУ, управления вводом-выводом информации и тактового генератора. ОМП различаются типом шин [типом набора проводников, функционально предназначенных для передачи информац. и (или) управляющих сигналов] адреса и данных: раздельные шины адреса и данных позволяют одновременно передавать по ним коды адреса и данных; совмещённые шины адреса и данных позволяют передавать адрес и данные в разные моменты времени, причём сначала производится адресация, т. е. выбор источника или получателя информации, а затем обмен данными. Такой способ, несмотря на большую сложность, позволяет сократить кол-во проводников шины и уменьшить кол-во выводов ОМП, что весьма существенно при увеличении его разрядности.
ОМП различаются также по способу синхронизации при выдаче адреса и обмена данными. В синхронных системах все сигналы строго определены во времени и обмен ведётся без подтверждения факта получения или выдачи информации абонентом.
В синхронно-асинхронных системах передача адреса осуществляется синхронно, а обмен происходит при взаимном обмене источника информации и её получателя сигналами подтверждения приёма (передачи) информации по след, схеме:
- источник начинает цикл обмена, выставляя данные на шины, и с временной задержкой, необходимой для надёжной установки данных на линиях связи, выставляет сигнал данные на шине;
- получатель по сигналу данные на шине производит их запись и только после этого выставляет сигнал данные получены на соответствующую линию связи;
- источник, получив сигнал данные получены, снимает сигнал данные на шине и сами данные;
- получатель после снятия сигнала данные на шине снимает сигнал данные получены;
- источник после снятия сигнала данные получены завершает текущий цикл обмена.
Этот способ обеспечивает высокую надёжность обмена, т. к. менее чувствителен к помехам, сбоям и временным характеристикам как узлов, участвующих в обмене, так и линий связи.
Многокристальные (секционные) МП (CMП) - секции разрядности 2, 4, 8 или 16 бит о фиксиров. набором инструкций для построения процессора с изменяемой разрядностью слова и разл. архитектурой. CMII позволяют создавать специализиров. процессоры с наборами инструкций, ориентированными на определ. применение (напр., фурье-анализ, процедуры обработки данных). При этом каждая инструкция такого специали-зиров. процессора состоит из последовательности инструкций (программы) СМП. В этом случае принято называть инструкции СМП микроинструкциями, а процесс разработки инструкций процессора - микропрограммированием.
Наряду с удобствами применение СМП связано с определ. трудностями: требуется микропрограммирование инструкций процессора. Поэтому наиб, распространёнными являются ОМП. В то же время, благодаря микропрограммированию инструкций процессора, состоящего из СМП, можно достичь его макс, производительности. В этом направлении наиб, перспективна разработка процессоров с сокращённым набором инструкций RISC (от англ. Reduce Instruction Set).
Архитектура МП. Для программиста понятие архитектуры МП включает в себя совокупность аппаратурных, программных и микропрограммных возможностей МП, важных при его программировании (внеш. архитектура). Для разработчика микропроцессорной аппаратуры важными особенностями, с точки зрения архитектуры МП, являются его аппаратурная организация и логич. структура электронных схем, отд. блоков и связывающих их информац. шин (внутр. архитектура). Эти особенности могут быть отличными от внеш. архитектуры МП.
Существует два типа внутр. архитектуры процессора, построенного из СМП: вертикальная и горизонтальная. В случае вертикальной архитектуры секция является функционально законченным и-разрядным процессором (2, 4, 8 или 16 бит), допускающим наращивание разрядности слова объединением секций. При горизонтальной архитектуре построения процессора секция является одним из его узлов, объединяемых для получения re-разрядного процессора.
Внеш. архитектура МП, как правило, традиционна: один набор команд обрабатывает один набор данных - SlSD (от англ. Single Instruction Single Data stream). Совр. МП в этом отношении предоставляют проектировщикам микропроцессорных систем новые возможности, т. к. большинство их имеет аппаратурные и программные средства для построения многопроцессорных систем. Так, становятся возможными архитектуры типов SIMD (от англ. Single Instruction Multiple Data stream), MISD (от англ. Multiple Instruction Single Data stream) и MIMD (от англ. Multiple Instruction Multiple Data stream).
Принцип функционирования МП. МП работает, выполняя т. н. циклы инструкций - последоват. извлечения из памяти (ОЗУ, ПЗУ) инструкций, управляющих работой МП, их анализ и исполнение. При этом в начале цикла МП обращается к памяти один раз для чтения инструкции, а затем при необходимости ещё неск. раз для чтения (записи) данных из памяти или ввода-вывода данных через устройства ввода-вывода информации (УВВ).
В ОМП обычно используется одна и та же шина для обращения к памяти и УВВ (рис. 1, а), причём в один и тот же момент времени может читаться или записываться только одна инструкция или слово данных, т. е. инструкции и данные обрабатываются последовательно (рис. 1, б).
Рис. 1. Архитектура (а) и временная диаграмма цикла инструкции (б) однокристального микропроцессора.
В СМП шины данных (адреса) памяти, в к-рых хранятся микроинструкции, как правило, разделены (рис. 2, а) и процесс выборки след, инструкции может быть совмещён во времени с исполнением текущей инструкции (рис. 2, б).
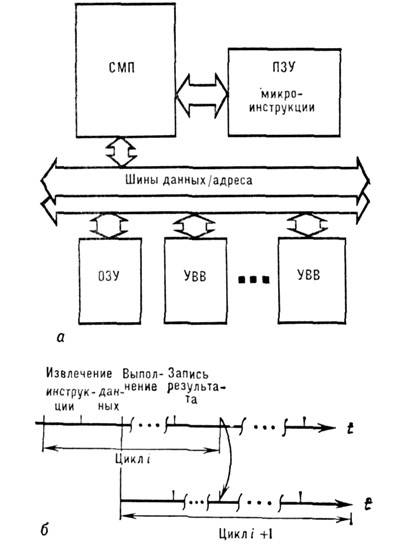
Рис. 2. Архитектура (а) и временная диаграмма цикла инструкции (б) секционного микропроцессора.
Технология изготовления МП. При произ-ве МП используются все известные виды технологий (ТТЛ, ТТЛШ, И 2 Л, И 3JI, ЭСЛ, n -МОП, к-МОП и р -МОП [3-4]), дающие разл. выходные характеристики МП. Так, технология ТТЛШ позволяет получить быстродействующие МП с высокой радиац. стойкостью, но имеющие большую потребляемую мощность и невысокую степень интеграции, технология n -МОП обеспечивает высокую степень интеграции при умеренной мощности потребления, но низкую радиац. стойкость. Высокими потребительскими свойствами обладают МП, изготовленные по технологии к -МОП на подложке из сапфира, а изготовленные по технологии р -МОП имеют низкую себестоимость, но обладают небольшим быстродействием.
Универсальные и специализированные МП. Универсальный МП представляет собой многофункциональную БИС или их набор с программируемой логикой работы. Из-за своей универсальности он зачастую имеет низкую эффективность использования в разл. областях применений из-за несоответствия архитектуры МП характеру задач.
Альтернативой ему в этом отношении является специализиров. МП, архитектура к-рого полностью ориентирована на решение конкретной задачи. Появление таких МП стало возможным благодаря технологии произ-ва БИС на базе вентильных матриц или базовых матричных кристаллов, когда один или неск. нижних слоев БИС являются неизменными, а меняется лишь верх, слой (слои) [5].
Специализиров. МП развиваются по пути создания МП, реализующих спец. алгоритмы обработки данных (алгоритмич. МП). Для традиц. архитектуры первыми шагами в этом направлении стала разработка МП с сокращённым набором инструкций (RISC) и МП с набором инструкций языков программирования высокого уровня.
Алгоритмич. МП - по сути развитие указанных направлений. Напр., применительно к задачам физики создаются алгоритмич. МП, служащие для обработки изображений и речи, цифровой фильтрации сигналов (систолич. ЭВМ) [5], а также МП для аналитич. вычислений, реализации метода наим. квадратов, линейного программирования, работы с фактографич. базами данных и др.
Среди специализиров. МП можно выделить МП для обработки сигналов (сигнальные МП), к-рьте по сути дела являются алгоритмич. МП, обрабатывающими информацию, заданную не в цифровом виде. При этом перед началом её цифровой обработки МП преобразует эту информацию в цифровой вид (напр., аналоговый сигнал - с помощью встроенного аналого-цифрового преобразователя). В случае аналоговых входных сигналов обрабатывающий их специализиров. МП наз. аналоговым MП [4]. Они могут выполнять функции любой аналоговой схемы (усиление сигнала, модуляцию, смещение, фильтрацию и др.) в реальном масштабе времени. При этом применение аналогового МП значительно повышает точность обработки сигналов, их воспроизводимость, расширяет функциональные возможности обработки сигналов за счёт цифровых методов.
Прогресс в развитии МП будет определяться как новыми микроэлектронными технологиями их изготовления, так и новой архитектурой МП, реализующей разл. способы обработки информации: параллельную, ассоциативную и др. Причём поскольку технология в ближайшие годы позволит достигнуть предела по параметру плотности логич. вентилей на кристалл (определяется межатомными размерами кристалла), на первое место выйдет разработка новых принципов обработки информации и архитектур МП.
Микропроцессор характеризуется:
1) тактовой частотой, определяющей максимальное время выполнения переключения
элементов в ЭВМ;
2) разрядностью, т.е. максимальным числом одновременно обрабатываемых двоичных разрядов.
Разрядностть МП обозначается m/n/k/ и включает:
m - разрядность внутренних регистров, определяет принадлежность к тому или
иному классу процессоров;
n - разрядность шины данных, определяет скорость передачи информации;
k - разрядность шины адреса, определяет размер адресного пространства.
Например, МП i8088 характеризуется значениями m/n/k=16/8/20;
3) архитектурой. Понятие архитектуры микропроцессора включает в себя систему
команд и способы адресации, возможность совмещения выполнения команд во
времени, наличие дополнительных устройств в составе микропроцессора, принципы и
режимы его работы. Выделяют понятия микроархитектуры и макроархитектуры.
Микроархитектура микропроцессора - это аппаратная организация и логическая структура микропроцессора, регистры, управляющие схемы, арифметико-логические устройства, запоминающие устройства и связывающие их информационные магистрали.
Макроархитектура - это система команд, типы обрабатываемых данных, режимы адресации и принципы работы микропроцессора.
В общем случае под архитектурой ЭВМ понимается абстрактное представление машины в терминах основных функциональных модулей, языка ЭВМ, структуры данных.
Архитектура типичной небольшой вычислительной системы на основе микроЭВМ показана на рис. 2.1 Такая микроЭВМ содержит все 5 основных блоков цифровой машины: устройство ввода информации, управляющее устройство (УУ), арифметико-логическое устройство (АЛУ) (входящие в состав микропроцессора), запоминающие устройства (ЗУ) и устройство вывода информации.
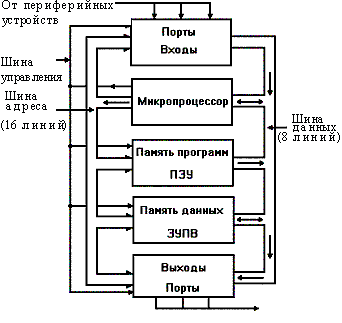
Рис. 2.1. Архитектура типового микропроцессора.
Микропроцессор координирует работу всех устройств цифровой системы с помощью шины управления (ШУ). Помимо ШУ имеется 16-разрядная адресная шина (ША), которая служит для выбора определенной ячейки памяти, порта ввода или порта вывода. По 8-разрядной информационной шине или шине данных (ШД) осуществляется двунаправленная пересылка данных к микропроцессору и от микропроцессора. Важно отметить, что МП может посылать информацию в память микроЭВМ или к одному из портов вывода, а также получать информацию из памяти или от одного из портов ввода.
Постоянное запоминающее устройство (ПЗУ) в микроЭВМ содержит некоторую программу (на практике программу инициализации ЭВМ). Программы могут быть загружены в запоминающее устройство с произвольной выборкой (ЗУПВ) и из внешнего запоминающего устройства (ВЗУ). Это программы пользователя.
В качестве примера, иллюстрирующего работу микроЭВМ, рассмотрим процедуру,
для реализации которой нужно выполнить следующую последовательность
элементарных операций:
1. Нажать клавишу с буквой "А" на клавиатуре.
2. Поместить букву "А" в память микроЭВМ.
3. Вывести букву "А" на экран дисплея.
Это типичная процедура ввода-запоминания-вывода, рассмотрение которой дает возможность пояснить принципы использования некоторых устройств, входящих в микроЭВМ.
На рис. 2.2 приведена подробная диаграмма
выполнения процедуры ввода-запоминания-вывода. Обратите внимание, что команды
уже загружены в первые шесть ячеек памяти. Хранимая программа содержит
следующую цепочку команд:
1. Ввести данные из порта ввода 1.
2. Запомнить данные в ячейке памяти 200.
3. Переслать данные в порт вывода 10.
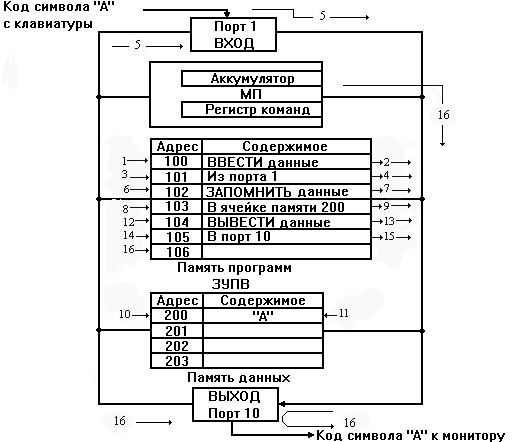
Рис. 2.2. Диаграмма выполнения процедуры ввода-запоминания-вывода.
В данной программе всего три команды, хотя на рис. 2.2 может показаться, что в памяти программ записано шесть команд. Это связано с тем, что команда обычно разбивается на части. Первая часть команды 1 в приведенной выше программе - команда ввода данных. Во второй части команды 1 указывается, откуда нужно ввести данные (из порта 1). Первая часть команды, предписывающая конкретное действие, называется кодом операции (КОП), а вторая часть - операндом. Код операции и операнд размещаются в отдельных ячейках памяти программ. На рис. 2.2 КОП хранится в ячейке 100, а код операнда - в ячейке 101 (порт 1); последний указывает откуда нужно взять информацию.
В МП на рис. 2.2 выделены еще два новых блока - регистры: аккумулятор и регистр команд.
Рассмотрим прохождение команд и данных внутри микроЭВМ с помощью занумерованных кружков на диаграмме. Напомним, что микропроцессор - это центральный узел, управляющий перемещением всех данных и выполнением операций.
Итак, при выполнении типичной
процедуры ввода-запоминания-вывода в микроЭВМ происходит следующая
последовательность действий:
1. МП выдает адрес 100 на шину адреса. По шине управления поступает сигнал,
устанавливающий память программ (конкретную микросхему) в режим считывания.
2. ЗУ программ пересылает первую команду ("Ввести данные") по шине
данных, и МП получает это закодированное сообщение. Команда помещается в
регистр команд. МП декодирует (интерпретирует) полученную команду и определяет,
что для команды нужен операнд.
3. МП выдает адрес 101 на ША; ШУ используется для перевода памяти программ в
режим считывания.
4. Из памяти программ на ШД пересылается операнд "Из порта 1". Этот
операнд находится в программной памяти в ячейке 101. Код операнда (содержащий
адрес порта 1) передается по ШД к МП и направляется в регистр команд. МП теперь
декодирует полную команду ("Ввести данные из порта 1").
5. МП, используя ША и ШУ, связывающие его с устройством ввода, открывает порт
1. Цифровой код буквы "А" передается в аккумулятор внутри МП и
запоминается.Важно отметить, что при обработке каждой программной команды МП
действует согласно микропроцедуре выборки-декодирования-исполнения.
6. МП обращается к ячейке 102 по ША. ШУ используется для перевода памяти
программ в режим считывания.
7. Код команды "Запомнить данные" подается на ШД и пересылается в МП,
где помещается в регистр команд.
8. МП дешифрирует эту команду и определяет, что для нее нужен операнд. МП
обращается к ячейке памяти 103 и приводит в активное состояние вход считывания
микросхем памяти программ.
9. Из памяти программ на ШД пересылается код сообщения "В ячейке памяти
200". МП воспринимает этот операнд и помещает его в регистр команд. Полная
команда "Запомнить данные в ячейке памяти 200" выбрана из памяти
программ и декодирована.
10. Теперь начинается процесс выполнения команды. МП пересылает адрес 200 на ША
и активизирует вход записи, относящийся к памяти данных.
11. МП направляет хранящуюся в аккумуляторе информацию в память данных. Код
буквы "А" передается по ШД и записывается в ячейку 200 этой памяти.
Выполнена вторая команда. Процесс запоминания не разрушает содержимого
аккумулятора. В нем по-прежнему находится код буквы "А".
12. МП обращается к ячейке памяти 104 для выбора очередной команды и переводит
память программ в режим считывания.
13. Код команды вывода данных пересылается по ШД к МП, который помещает ее в
регистр команд, дешифрирует и определяет, что нужен операнд.
14. МП выдает адрес 105 на ША и устанавливает память программ в режим
считывания.
15. Из памяти программ по ШД к МП поступает код операнда "В порт 10",
который далее помещается в регистр команд.
16. МП дешифрирует полную команду "Вывести данные в порт 10". С
помощью ША и ШУ, связывающих его с устройством вывода, МП открывает порт 10,
пересылает код буквы "А" (все еще находящийся в аккумуляторе) по ШД.
Буква "А" выводится через порт 10 на экран дисплея.
В большинстве микропроцессорных систем (МПС) передача информации осуществляется способом, аналогичным рассмотренному выше. Наиболее существенные различия возможны в блоках ввода и вывода информации.
Подчеркнем еще раз, что именно микропроцессор является ядром системы и осуществляет управление всеми операциями. Его работа представляет последовательную реализацию микропроцедур выборки-дешифрации-исполнения. Однако фактическая последовательность операций в МПС определяется командами, записанными в памяти программ.
Таким образом, в МПС микропроцессор
выполняет следующие функции:
- выборку команд программы из основной памяти;
- дешифрацию команд;
- выполнение арифметических, логических и других операций, закодированных в
командах;
- управление пересылкой информации между регистрами и основной памятью, между
устройствами ввода/вывода;
- отработку сигналов от устройств ввода/вывода, в том числе реализацию
прерываний с этих устройств;
- управление и координацию работы основных узлов МП.
http://dfe.petrsu.ru/koi/posob/microcpu/index.html
![]() Внешняя память компьютера или ВЗУ -
важная составная часть электронно вычислительной машины, обеспечивающая
долговременное хранение программ и данных на различных носителях информации. Внешние
запоминающие устройства (ВЗУ) - можно классифицировать по целому ряду
признаков : по виду носителя, по типу конструкции, по принципу записи и
считывания информации, по методу доступа и т.д. При этом под носителем
понимается материальный объект, способный хранить информацию.
Внешняя память компьютера или ВЗУ -
важная составная часть электронно вычислительной машины, обеспечивающая
долговременное хранение программ и данных на различных носителях информации. Внешние
запоминающие устройства (ВЗУ) - можно классифицировать по целому ряду
признаков : по виду носителя, по типу конструкции, по принципу записи и
считывания информации, по методу доступа и т.д. При этом под носителем
понимается материальный объект, способный хранить информацию.
Свойства внешней памяти :
В состав внешней памяти включаются :
Накопители – это запоминающие устройства, предназначенные для длительного (то есть не зависящего от электропитания) хранения больших объемов информации.
Кроме основной своей характеристики – информационной емкости – дисковые накопители характеризуются и двумя другими показателями : временем доступа и скоростью считывания последовательно расположенных байтов.
![]() Flash-память (англ. Flash-Memory) –
разновидность твердотельной полупроводниковой энергонезависимой
перезаписываемой памяти. Flash-память может быть прочитана сколько
угодно раз, но писать в такую память можно лишь ограниченное число раз (обычно
около 10 тысяч раз). Несмотря на то, что такое ограничение есть, 10 тысяч
циклов перезаписи это намного больше, чем способна выдержать дискета или CD-RW.
Flash-память (англ. Flash-Memory) –
разновидность твердотельной полупроводниковой энергонезависимой
перезаписываемой памяти. Flash-память может быть прочитана сколько
угодно раз, но писать в такую память можно лишь ограниченное число раз (обычно
около 10 тысяч раз). Несмотря на то, что такое ограничение есть, 10 тысяч
циклов перезаписи это намного больше, чем способна выдержать дискета или CD-RW.
Flash память наиболее известна применением в USB Flash Drive. USB Flash Drive (на компьютерном сленге флэшка или карандаш) - носитель информации, использующий Flash - память для хранения данных и подключаемый к компьютеру или иному считывающему устройству через стандартный разъём USB. USB Flash Drive называют также USB Flash-картой.
Flash-карты получили большую популярность в 2000-е годы из-за компактности, лёгкости перезаписывания файлов и большого объёма памяти (от 32 Мб до 64 Гб). Основное назначение : хранение, перенос и обмен данными, резервное копирование, загрузка операционных систем (LiveUSB) и др.
![]() Флэш-память широко используется в портативных
устройствах, работающих на батарейках и аккумуляторах – цифровых фотокамерах и
видеокамерах, цифровых диктофонах, MP3-плеерах, КПК, мобильных телефонах, а
также смартфонах и коммуникаторах. Кроме того, она используется для хранения
встроенного программного обеспечения в различных устройствах - контроллерах.
Флэш-память широко используется в портативных
устройствах, работающих на батарейках и аккумуляторах – цифровых фотокамерах и
видеокамерах, цифровых диктофонах, MP3-плеерах, КПК, мобильных телефонах, а
также смартфонах и коммуникаторах. Кроме того, она используется для хранения
встроенного программного обеспечения в различных устройствах - контроллерах.
Одним из первых, флэшки JetFlash в 2002 году начал выпускать тайваньский концерн Transcend...
У флэш-дисков отсутствуют какие-либо подвижные части, по форме чаще всего они представляют собой прямоугольные картриджи. Для хранения информации в них используются специализированные микросхемы памяти с металлизацией (металл-нитридные), выполненные по технологии Flash. Дисками их называют условно, поскольку флэш-диски полностью эмулируют функциональные возможности HDD.
По существу, флэш-диски - это «полупостоянные» запоминающие устройства, стирание, считывание и запись информации в которых выполняется электрическими сигналами (в отличие от прочих ПЗУ, в которых эти действия производятся лучом лазера или чисто механически – «перепрошивкой»). Количество циклов перезаписи информации в одну и ту же ячейку у флэш-памяти ограничено, но оно обычно превышает 1 миллион – эта величина иногда указывается в паспорте микросхемы.
Накопители на оптических дисках разделяют на :
Цифровые видеодиски впервые появились в 1996 году. DVD имеют габариты обычных CD-ROM, но значительно большей емкости, которая у них достигает десятков Гбайт...
![]() DVD – Digital Versatile Disk, цифровой
универсальный диск (иногда его называют Digital Video Disk, цифровой
видеодиск). Физически DVD-диск – это тот же привычный диск диаметром 4,72
дюйма (существует стандарт также на 3,5
дюйма) и толщиной 0,05 дюйма. Так же как и компакт-диск, он почти не
изнашивается со временем, не чувствителен к магнитному и инфракрасному
излучениям.
DVD – Digital Versatile Disk, цифровой
универсальный диск (иногда его называют Digital Video Disk, цифровой
видеодиск). Физически DVD-диск – это тот же привычный диск диаметром 4,72
дюйма (существует стандарт также на 3,5
дюйма) и толщиной 0,05 дюйма. Так же как и компакт-диск, он почти не
изнашивается со временем, не чувствителен к магнитному и инфракрасному
излучениям.
Но в DVD используются однослойная и двухслойная, односторонняя и двухсторонняя уплотненная запись. Уплотнение записи данных на DVD было достигнуто путем уменьшения диаметра пишущего-читающего луча (зелено-голубой лазер) в два раза, при этом уменьшаются сами точки (питы), сокращается расстояние между соседними точками на дорожке и увеличивается количество дорожек. Только за счет повышения плотности записи удалось достичь более чем четырехкратного роста емкости.
Самый простой тип записываемого DVD – это DVD-R, который предусматривает однократную запись информации на носитель с последующим многократным чтением. Перезаписываемыми форматами DVD являются DVD-RAM и DVD-RW. Существуют и другие форматы перезаписываемых DVD-дисков: ASMO, MMVF и др.
6.1. Система ввод/вывода.
Назначением системы ввода-вывода является обеспечение обмена информацией между внешними (периферийными) устройствами и оперативной памятью. К внешним устройствам относятся:
Устройства внешней памяти
Информация, хранимая в устройствах внешней памяти, организована в файловые структуры. Файл – это единица информации в виде массива байт произвольной длины, которому присвоен уникальный идентификатор (имя).
Каждый идентификатор может содержать трехсимвольное расширение, отделенное от имени точкой. Расширение может быть использовано для задания группового признака (типа файла), характеризующего хранимую информацию: текстовую, графическую и т.д. Например, запись vc.exe означает идентификатор vc с расширением exe (исполняемый файл).
Отдельные файлы объединяются в каталоги (для некоторых ОС - в папки). Каждый каталог имеет свое имя и может быть зарегистрирован в другом каталоге. Тогда он называется подкаталогом. Так образуется древовидная файловая структура для каждого логического устройства. Корневой каталог является каталогом высшего уровня. Логическое внешнее устройство – это устройство, различимое программой. Физическое внешнее устройство может отображаться на одно логическое устройство или быть разделено на несколько логических устройств с непересекаемыми областями носителя информации.
Поиск информации во внешней памяти на логическом уровне производится по идентификатору файла. Перед идентификатором файла указывается путь в виде имени логического устройства и перечня имен всех каталогов (путь к файлу) ветви файловой структуры до искомого файла. Например, адрес с:\vc\nc.exe означает файл nc.exe, который находится в каталоге vc на логическом устройстве внешней памяти "с".
Преобразование логического адреса файла в физический и поиск информации на физическом уровне зависят от типа устройства внешней памяти. Наиболее распространенными устройствами внешней памяти до настоящего времени являлись накопители на основе записи на магнитную поверхность. Это магнитные ленты, а также магнитные, оптические и магнитооптические диски. В настоящее время они вытесняются новыми формами записи.
Запись и чтение информации в накопителях на магнитной поверхности производится при помощи магнитных головок. Простейшая магнитная головка (рис. 10) состоит из катушки с магнитопроводом. Магнитопровод имеет воздушный зазор. При протекании тока через катушку в магнитопроводе возникает магнитный поток, который в области воздушного зазора выходит за пределы головки и может замыкаться через магнитоактивный слой носителя информации.
Запись информации на магнитную поверхность основана на явлении остаточной намагниченности.
Если к локальному участку поверхности с магнитоактивным слоем подвести магнитное поле определенной интенсивности, то после снятия магнитного поля на участке поверхности остается остаточная намагниченность магнитоактивного слоя (магнитный отпечаток). Направление остаточной намагниченности определяется ориентацией подводимого магнитного поля. Создание магнитного поля производится при помощи подачи тока определенной силы и направления на катушку магнитной головки.
Локализация магнитного поля на участке поверхности производится при помощи воздушного зазора кольцевого магнитопровода магнитной головки. Так производится запись одного бита информации. При движении магнитной головки относительно поверхности носителя информации производится запись многобитовой информации.
Чтение записанной информации чаще всего производится за счет магнитоиндукционных явлений. При движении магнитной головки над поверхностью носителя остаточное поле магнитных отпечатков замыкается через магнитопровод головки. При этом на обмотках катушки наводится напряжение, пропорциональное произведению скорости изменения магнитного потока через катушку на число витков катушки. То есть напряжение на обмотках катушки будет зависеть от чередования записанных магнитных отпечатков.
Запись информации на магнитооптических дисках также основана на явлении остаточной намагниченности, но физические методы записи и чтения здесь свои.
Наиболее простые магнитооптические диски используют запись на предварительно намагниченную поверхность. Запись магнитного отпечатка производится при помощи кратковременного нагрева локального участка магнитоактивного слоя лазерным лучом и подачи внешнего перемагничивающего поля. Напряженность поля выбирается меньше порога перемагничивания материала магнитоактивного слоя. Но порог перемагничивания падает с ростом температуры. Поэтому перемагничивание магнитоактивного слоя происходит только в локальной области нагрева поверхности лазерным лучом. Плотность записи при этом значительно возрастает.
Возросшая плотность записи исключает использование при чтении обычных магнитоиндукционных головок. Чтение информации производится лазерным лучом. Намагниченность участка магнитоактивного слоя меняет плоскость поляризации отраженного лазерного луча. Это явление используется при чтении информации.
В оптических дисках запись информации основана на изменении рельефа отражающей поверхности диска. Чтение информации производится за счет различного рассеивания лазерного луча, отраженного от поверхности диска. По функциональным возможностям магнитные диски могут быть:
Кроме этого файловую структуру используют относительно новые виды внешней памяти на основе МДП-транзисторов с плавающим затвором. Это различные варианты флэш-памяти. Запись информации производится за счет туннелирования электронов на изолированный затвор, чтение – аналогично чтению в однотранзисторных ячейках динамической памяти (раздел 9.1, рис. 9.1). Один из вариантов групповой записи информации в ячейки флэш-памяти с дублирующей динамической памятью реализуется подачей магнитного поля, уменьшающего порог туннелирования электронов в область затвора.
Устройства ввода. Это устройства ввода данных в систему оперативной памяти из системы устройств внешней памяти или устройств связи с внешними объектами.
К устройствам ввода относятся:
Устройства вывода. Это устройства вывода данных из системы оперативной памяти в систему внешней памяти или устройств связи с внешними объектами.
Процессор может осуществлять программное управление операциями ввода/вывода, но не являться объектом ввода или вывода.
Устройства коммуникации. Это устройства, обеспечивающие связь с другими ЭВМ или управляемыми объектами, включая удаленные объекты.
USB-флеш-накопитель (сленг. флешка, флэшка, флеш-драйв) — запоминающее устройство, использующее в качестве носителя флеш-память и подключаемое к компьютеру или иному считывающему устройству по интерфейсу USB.
USB-флешки обычно съёмные и перезаписываемые. Размер — 3—5 см, вес — меньше 60 г. Получили большую популярность в 2000-е годы из-за компактности, лёгкости перезаписывания файлов и большого объёма памяти (от 32 МБ до 1 ТБ[1]). Основное назначение USB-накопителей — хранение, перенос и обмен данными, резервное копирование, загрузка операционных систем (LiveUSB) и др. Разработан умещающийся на флешку пакет программ для автоматического снятия улик с компьютера неквалифицированным полицейским (COFEE).
Обычно устройство имеет вытянутую форму и съёмный колпачок, прикрывающий разъём; иногда прилагается шнур для ношения на шее. Современные флешки могут иметь самые разные размеры и способы защиты разъёма, а также «нестандартный» внешний вид (армейский нож, часы и т. п.) и различные дополнительные возможности (например, проверку отпечатка пальца и т. п.).
Кластер (англ. cluster) — в некоторых типах файловых систем логическая единица хранения данных в таблице размещения файлов, объединяющая группу секторов. Например, на дисках с размером секторов в 512 байт, 512-байтный кластер содержит один сектор, тогда как 4-килобайтный кластер содержит восемь секторов.
Как правило, это наименьшее место на диске, которое может быть выделено для хранения файла.
Понятие кластер используется в файловых системах FAT, NTFS, a так же HFS Plus. Другие файловые системы оперируют схожими понятиями (зоны в Minix, блоки в Unix).
В некоторых файловых системах Linux (ReiserFS, Reiser4, Btrfs), BSD (FreeBSD UFS2) последний блок файла может быть поделен на подфрагменты, в которые могут быть помещены «хвосты» других файлов. В NTFS маленькие файлы могут быть записаны в Master File Table (MFT). В файловой же системе FAT из-за примитивного алгоритма степень фрагментации постоянно растёт и требуется периодическая дефрагментация. Маленький кластер лучше подходит для маленьких файлов. Так экономнее расходуется место. Большой кластер позволяет достичь более высоких скоростей, но на мелких файлах место будет использоваться нерационально (многие сектора будут не полностью заполненными, но будут считаться занятыми).
Се́ктор диска — минимальная адресуемая единица хранения информации на дисковых запоминающих устройствах (НЖМД, дискета, CD). Является частью дорожки диска. У большинства устройств размер сектора составляет 512 байт (например, у жестких и гибких дисков), либо 2048 байт (например, у оптических дисков).
Для более эффективного использования места на диске файловая система может объединять секторы в кластеры, размером от 512 байт (один сектор) до 64 кбайт (128 секторов). Переход к кластерам произошел потому, что размер таблицы FAT был ограничен, а размер диска увеличивался. В случае FAT16 для диска объемом 512 Мб кластер будет составлять 8 Кб, до 1 Гб — 16 Кб, до 2 Гб — 32 Кб и так далее.
Количество секторов на цилиндрах ранее было одинаковым, на современных дисках количество секторов на цилиндрах разное, но контроллер жёсткого диска сообщает о некоем условном количестве дорожек, секторов и сторон, хотя позднее была создана система (LBA) обращения к дискам, в которой все секторы пронумерованы. Первый сектор диска обычно является загрузочным.
Первый сектор НЖМД содержит главную загрузочную запись, содержащую короткую программу передачи управления в загрузочный сектор, находящийся на разделе, и таблицу разделов (слайсов).
Каждая дорожка разбивается на фрагменты, называемые секторами (sectors), причем
все дорожки на диске имеют одинаковое количество секторов. Сектор представляет
собой минимальную физическую единицу хранения информации на диске. Размер
сектора всегда представляет собой одну из степеней числа 2, и почти всегда
равен 512 байт.
Каждая дорожка имеет одно и то же количество секторов. Это говорит о том, что
на дорожках, расположенных ближе к центру диска, секторы упакованы гораздо
плотнее. На рисунке показана дорожка с секторами. На этой иллюстрации можно
видеть, что секторы, расположенные ближе к шпинделю, упакованы теснее и находятся
ближе друг к другу, чем секторы, находящиеся на внешних дорожках. Чтобы
определить, где начинается сам сектор, контроллер диска использует
идентификационную информацию сектора, которая хранится в области,
непосредственно предшествующей данным сектора.
Рис. Секторы и кластеры
Файловые системы Windows 95 выделяют пространство кластерами, где кластер
состоит из одного или нескольких смежных секторов. Размер кластера в Windows 95
базируется на размере тома.
Когда файл записывается на диск, файловая система выделяет соответствующее
количество кластеров для хранения данных файла. Например, если каждый кластер
равен 512 байт, а размер сохраняемого файла составляет 800 байт, то для его
хранения будут выделены два кластера. Впоследствии, если вы модифицируете файл
таким образом, что он увеличится в размерах, скажем, до 1600 байт, для его
сохранения будут дополнительно выделены еще два кластера.
Если смежных кластеров на диске нет (под смежными понимаются кластеры,
расположенные вплотную друг к другу, один за другим), для сохранения файла
будут выделены те кластеры, какие есть, и тогда файл будет фрагментированным.
Фрагментация представляет собой такую проблему файловой системы, когда для
считывания нужного файла необходимо выполнить поиск по нескольким
местоположением (т.е. выполнить несколько перемещений головок). За счет того,
что на это требуется время, фрагментированные файлы считываются с задержкой.
Если размер кластера увеличить, это снижает потенциальную возможность
фрагментации, однако повышает вероятность неэкономного расходования дискового
пространства, при котором кластеры будут содержать неиспользованное дисковое
пространство.
Использование кластеров, размер которых больше одного сектора, снижает
фрагментацию и уменьшает объем дискового пространства, необходимый для хранения
информации об использованных и неиспользованных областях на диске. Поскольку
файловая система FAT может использовать только 16 бит для нумерации кластеров,
тома, использующие FAT, могут иметь размер не более 65535 секторов.
Таблица разделов — часть главной загрузочной записи (MBR), состоящая из четырёх записей по 16 байт. Каждая запись описывает один из разделов жёсткого диска. Первая запись находится по смещению 1BEh от начала сектора, содержащего MBR, каждая последующая запись вплотную примыкает к предыдущей.
Для созания на диске более 4 разделов используются расширеные разделы, позволяющие создать неограниченое количество логических дисков внутри себя.
|
Смещение |
Размер |
Описание |
|
0h |
1 |
Признак активного раздела (0 — неактивный, 80h — активный) |
|
1h |
1 |
Номер поверхности (головки) диска, с которой начинается раздел |
|
2h |
2 |
Номера цилиндра и сектора, с которых начинается раздел |
|
4h |
1 |
Код типа раздела |
|
5h |
1 |
Номер поверхности (головки) диска, на которой заканчивается раздел |
|
6h |
2 |
Номера цилиндра и сектора, которыми заканчивается раздел |
|
8h |
4 |
Абсолютный номер начального сектора раздела |
|
Ch |
4 |
Число секторов в разделе |
Адреса начала и конца раздела задаются в формате CHS, используемом традиционными функциями дискового сервиса BIOS, из-за чего номер цилиндра разорван на две части: старшие два бита хранятся в двух старших битах слова, отведённого под номера цилиндра и сектора; за ними следуют шесть бит номера сектора, а младшие восемь бит номера цилиндра занимают весь младший байт слова. Если задать корректный адрес с помощью формата CHS невозможно, все три байта полей начала и конца раздела должны содержать FFh.
32-разрядные номер первого сектора раздела и количество секторов в разделе, указанные в таблице разделов, позволяют использовать функции расширенного дискового сервиса, поддерживающие адресацию LBA; в этом случае 32-разрядный номер сектора является младшим двойным словом адреса в формате LBA, а старшее двойное слово будет равно нулю. Если число секторов в разделе превосходит FFFFFFFFh, то в поле длины указывается это значение. 32-разрядные номер и количество секторов позволяют работать с разделами ёмкостью до 2 Тбайт; для выхода за пределы этого ограничения применяется иная схема деления диска на разделы, основанная на GUID-таблице разделов (GPT).
|
Код |
Вид раздела |
Размер раздела |
Файловая система |
|
00h |
нет раздела |
|
|
|
01h |
основной |
< 16 Мбайт |
FAT12 |
|
04h |
основной |
16–32 Мбайт |
FAT16 |
|
05h |
расширенный |
до 2 Тбайт |
|
|
06h |
основной |
32 Мбайт – 2 Гбайт |
FAT16 |
|
07h |
основной |
512 Мбайт – 2 Тбайт |
NTFS |
|
0Bh |
основной |
512 Мбайт – 2 Тбайт |
FAT32 |
|
0Ch |
основной |
512 Мбайт – 2 Тбайт |
FAT32 |
|
0Eh |
основной |
32 Мбайт – 2 Гбайт |
FAT16 |
|
0Fh |
расширенный |
512 Мбайт – 2 Тбайт |
|
|
EEh |
основной |
весь диск |
защитная запись UEFI |
|
EFh |
основной |
? |
файловая система UEFI |
Для начала давайте определимся с терминологией. Под
словами, вынесенными в заголовок статьи, зачастую понимают две разные вещи,
которые в некоторых случаях могут быть эквивалентны, а в некоторых - нет.
Первое понятие - собственно Master Boot Record. Это запись (программный код и
данные), которая загружается в память с винчестера и обеспечивает опознание
логических разделов на нем, определяет активный раздел и загружает из него
загрузочную запись (Boot Record - BR), которая продолжит запуск операционной
системы (ОС). И второе понятие - Загрузочный Сектор, Master Boot Sector (MBS) -
это сектор, располагающийся на цилиндре 0, плоскости (головка) 0 и имеющий
номер 1. В большинстве случаев MBS содержит весь необходимый код и все данные,
поэтому его содержимое и есть MBR, однако бывают случаи (которые мы рассмотрим
в конце статьи), когда код и данные не помещаются в одном секторе (просто не
хватает места или по соображениям безопасности), и тогда код этого сектора
обеспечивает загрузку в память остальных секторов. В этом случае MBR - это
совокупность всех секторов, которые должны быть загружены, а MBS - всего лишь
первый сектор.
Однако начнем мы со случая, когда MBR и MBS - одно и то же, и
будем называть их более привычным и широко распространённым термином MBR.
Слегка отступая от темы, замечу, что такой MBR (обеспечивающий загрузку любой
ОС и занимающий только MBS) обычно называют термином Generic MBR.
Вообще MBR появился на жестких дисках начиная с MS DOS версии
3.0, в более ранних версиях жёсткий диск форматировался как дискета, и в первом
секторе располагался BR. Соответственно диск представлял из себя один раздел и
не мог быть разбит на логические части - правда, при тех размерах дисков,
которые тогда выпускались, это было неактуально.
Размер сектора на жестком диске - 512 байт. Этого
пространства вполне хватает для размещения там всего необходимого - и кода, и
данных. Однако только одна структура должна там присутствовать обязательно -
это сигнатура. Этим словом называется специальная, строго установленная,
последовательность из 2 байт с шестнадцатеричными значениями 55h AAh, которая
записывается в последние 2 байта сектора и соответственно имеет смещение от
начала сектора 1FEh. Если хотя бы один из двух последних байтов отличается по
значению, считается, что первый сектор не является MBR и не содержит
осмысленной информации. Если компьютер при старте, прочитав первый сектор, не
обнаружит правильной сигнатуры, он не будет передавать управление
располагающемуся там коду, даже если он правильный, а выдаст сообщение о том,
что главная загрузочная запись не найдена. Или будет пробовать найти её на
других устройствах - например, на дискете. Слегка отклоняясь от темы, замечу,
что BR также содержит сигнатуру 55h AAh в последних двух байтах.
Ну уж коли начали с хвоста, то пойдём от него к началу
сектора. Перед сигнатурой, вплотную к ней, расположены 4 блока данных по 16 байтов
каждый (соответственно со смещением от начала сектора 1BEh, 1CEh, 1DEh, 1EEh).
Совокупность этих блоков называется Таблица Разделов, Partition Table (PT), а
каждая отдельная запись - элементом таблицы разделов (Partition Table Entry)
или просто разделом (Partition). Этих 16 байтов вполне достаточно, чтобы
указать все необходимые характеристики раздела, а именно: тип раздела, признак
активности раздела, начальный и конечный сектора раздела в формате Цилиндр
(дорожка) - Головка (сторона) - Сектор (Cylinder - Head - Sector, CHS),
относительный номер первого сектора (относительно MBR) и количество секторов в
разделе.
Всё остальное пространство сектора занято программным кодом,
который обеспечивает разбор PT, поиск активного раздела, загрузку в память BR этого
раздела и передачу ему управления. Как легко подсчитать, на код остаётся 512 -
4 * 16 - 2 = 446 байт. Этого пространства с избытком хватает для выполнения
указанных действий.
Главная загрузочная запись (англ. master boot record, MBR) — код и
данные, необходимые для последующей загрузки операционной системы и
расположенные в первых физических секторах (чаще всего в самом первом) на жёстком диске или другом устройстве хранения
информации.
MBR содержит небольшой фрагмент исполняемого кода, таблицу разделов (partition table) и специальную сигнатуру.
Функция MBR — «переход» в тот раздел жёсткого диска, с которого следует исполнять «дальнейший код» (обычно — загружать ОС). На «стадии MBR» происходит выбор раздела диска, загрузка кода ОС происходит на более поздних этапах алгоритма.
В процессе запуска компьютера, после окончания начального теста (Power-on self-test — POST), Базовая система ввода-вывода (BIOS) загружает «код MBR» в оперативную память (в IBM PC обычно с адреса 0000:7c00) и передаёт управление находящемуся в MBR загрузочному коду.
Файловая система - это структура каталогов, используемая для организации файлов и их хранения на диске. Файловая система представляет собой набор файлов и каталогов, которые хранятся на диске в стандартном формате файловой системы UNIX. Все дисковые системы имеют какую-либо файловую систему. В операционной системе UNIX файловые системы имеют два основных компонента: файлы и каталоги. Файл представляет собой реальную информацию в том виде, как она хранится на диске, а каталог - это список имен файлов. В дополнение к отслеживанию имен файлов файловая система должна также отслеживать даты доступа к файлам и права собственности на файлы. Управление файловыми системами UNIX является одной из наиболее важных задач системного администратора. Под управлением конкретной файловой системой подразумевается решение следующих задач:
Обеспечение пользователям возможности доступа к данным. Это означает, что файловые системы запущены и работоспособны, полномочия доступа к файлам установлены надлежащим образом и данные доступны.
Защита файловых систем от разрушения файлов и отказов аппаратных средств вычислительной системы. Эта задача решается посредством регулярного контроля файловой системы и правильной организации резервного копирования.
Защита файловых систем от несанкционированного доступа. Только авторизованные пользователи должны иметь доступ к файлам. Данные должны быть защищены от злоумышленников, заинтересованных в получении несанкционированного доступа к ним.
Предоставление пользователям требуемого дискового пространства для хранения их файлов.
Поддержание чистоты файловой системы. Другими словами, в файловой системе должно храниться лишь то, что необходимо, не следует засорять дисковое пространство. Необходимо выполнение определенных процедур, чтобы быть уверенным, что пользователи придерживаются надлежащих соглашений по наименованиям и что данные хранятся организованным образом.
Вам придется столкнуться с использованием термина "файловая система" в нескольких аспектах. Обычно термин "файловая система" описывает некоторый конкретный тип файловой системы (дисковая, сетевая или виртуальная файловая система). Это понятие может также описывать полное дерево файлов, начинающееся с корневого каталога и далее вниз. В другом контексте термин "файловая система" может быть использован для описания структуры дискового пространства, как будет показано далее в настоящей главе.
Программное обеспечение операционной системы Solaris использует архитектуру VFS (Virtual File System - виртуальной файловой системы), которая предоставляет стандартный интерфейс для различных типов файловых систем. Архитектура VFS позволяет ядру операционной системы поддерживать основные операции, такие как чтение, запись и просмотр списка файлов, и при этом от пользователя или программы не требуется знаний о типе файловой системы, лежащей в основе этих операций. Более того, операционная система Solaris предоставляет команды управления файловыми системами, которые позволяют вам проводить обслуживание этих систем.
Существует довольно много разных файловых систем, которые отличаются друг от друга внутренним устройством, однако пользователь везде найдёт привычную структуру из вложенных каталогов и файлов. Файловые системы различаются скоростью доступа, надёжностью хранения данных, степенью устойчивости при сбоях, некоторыми дополнительными возможностями. Современные операционные системы поддерживают по несколько типов файловых систем (помимо файловых систем, используемых для хранения данных на жёстком диске, также файловые системы CD и DVD и пр.). Хотя для каждой операционной системы обычно есть одна «традиционная» файловая система, которая предлагается по умолчанию, является универсальной и подходит абсолютному большинству пользователей.
Важное свойство файловых систем — поддержка журналирования. Журналируемая файловая система ведёт постоянный учёт всех операций записи на диск. Благодаря этому после сбоя электропитания файловая система всегда автоматически возвращается в рабочее состояние.
Существует несколько типов файловых систем, которые в полной мере поддерживают все возможности, необходимые для полноценной работы Linux (все необходимые типы и атрибуты файлов, в том числе права доступа).
Ext2/3
Этот тип файловой системы разработан специально для Linux и традиционно используется на большинстве Linux-систем. Фактически в названии «Ext2/3» объединены названия двух вариантов этой файловой системы. Ext3 отличается от Ext2 только поддержкой журналирования, в остальном они одинаковы и легко могут быть преобразованы одна в другую в любой момент без потери данных. Обычно предпочтителен вариант с журналированием (Ext3) в силу его большей надёжности. При высокой параллельной дисковой загрузке производительность Ext3 снижается, что выражается в снижении скорости операций с диском и повышении значения нагрузки на систему (Load Average).
ReiserFS
Файловая система этого типа похожа скорее на базу данных: внутри неё используется своя собственная система индексации и быстрого поиска данных, а представление в виде файлов и каталогов — только одна из возможностей использования такой файловой системы. Традиционно считается, что ReiserFS отлично подходит для хранения огромного числа маленьких файлов. Поддерживает журналирование.
XFS
Файловая система, наиболее подходящая для хранения очень больших файлов, в которых постоянно что-нибудь дописывается или изменяется. Поддерживает журналирование. Лишена недостатков Ext3 по производительности, но при её использовании выше риск потерять данные при сбоях питания (в том числе и по причине принудительного обнуления повреждённых блоков в целях безопасности; при этом метаданные файла обычно сохраняются и он выглядит как корректный). Рекомендуется использовать эту файловую систему с проверенным аппаратным обеспечением, подключенным к управляемому источнику бесперебойного питания (UPS).
SWAPFS
Этот тип файловой системы находится на особом положении — он используется для организации на диске области подкачки (swap). Область подкачки используется в Linux для организации виртуальной памяти: когда программам недостаточно имеющейся в наличии оперативной памяти, часть рабочей информации временно размещается на жёстком диске.
JFS
Разработана IBM для файловых серверов с высокой нагрузкой: при разработке особый упор делался на производительность и надёжность, что и было достигнуто. Поддерживает журналирование.
В Linux поддерживается, кроме собственных, немало форматов файловых систем, используемых другими ОС. Если способ записи на эти файловые системы известен и не слишком замысловат, то работает и запись, и чтение, в противном случае — только чтение (чего нередко бывает достаточно). Файловые системы перечисленных ниже типов обычно присутствуют на разделах диска, принадлежащих другим операционным системам.
FAT12/FAT16/FAT32
Эти файловые системы используются в MS-DOS и разных версиях Windows, а также на многих съёмных носителях (в частности, на дискетах и USB-flash). Linux поддерживает чтение и запись на эти файловые системы.
NTFS
Файловая система NTFS изначально появилась в системах Windows NT, но может использоваться и другими версиями Windows (например, Windows 2000). В Linux NTFS поддерживается на чтение и на запись.
В общем случае, данные, содержащиеся в файле, имеют некоторую логическую структуру. Эта структура является базой при разработке программы, предназначенной для обработки этих данных.
Например, чтобы текст мог быть правильно выведен на экран, программа должна иметь возможность выделить отдельные слова, строки, абзацы и т.д. Признаками, отделяющими один структурный элемент от другого, могут служить определенные кодовые последовательности или просто известные программе значения смещений этих структурных элементов, относительно начала файла. Поддержание структуры данных может быть либо целиком возложено на приложения либо в той или иной степени может взять на себя ФС (файловую систему).
В первом случае, когда все действия, связанные со структуризацией и интерпретацией содержимого файла целиком относятся к ведению приложения. Файл представляется ФС неструктурированной последовательностью данных. Приложение формулирует запросы к ФС на ввод/вывод, используя общие для всех приложений системные средства. Например, указывая смещение от начала файла и количество байт, которые необходимо считать или записать.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью (потоком) байт, стала популярной вместе с ОС UNIX, а теперь она широко используется в большинстве современных ОС (MS-DOS, Windows2000/NT, NetWare).
Неструктурированная модель файла позволяет легко организовать разделение файла между несколькими приложениями: разные приложения могут по-своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файлов, которая применялась в ОС OS/360, DEC RSX, VMS, а в настоящее время используется достаточно редко – это структурированный файл. В этом случае поддержание структуры файла поручается ОС. ФС видит файл как упорядоченную последовательность логических записей. Приложение может обращаться к ФС с запросами на ввод-вывод на уровне записей, например, «считать запись 25 из файла FILE.DOC». ФС должна обладать информацией о структуре файла, достаточной для того, чтобы выделить любую запись. ФС предоставляет приложению доступ к записи, а вся дальнейшая обработка данных, содержащаяся в этой записи, выполняется приложением. Замечание. Развитием этого подхода стали СУБД.
Физическая организация файла (ФОФ) – это способ размещения файла на диске. Основные критерии эффективности физической организации файлов:
Фрагментация – это наличие большого числа несмежных участков свободной памяти очень маленького размера (фрагментов). Настолько маленького, что ни одна из вновь поступающих программ не может поместиться ни в одном из участков, хотя суммарный объем фрагментов может составить значительную величину, намного превышающую требуемый объем памяти.
Существует несколько способов физической организации файла. Непрерывное размещение – это простейший вариант ФОФ, при котором файлу предоставляется последовательность кластеров диска, образующих непрерывный участок дисковой памяти:
![]() Достоинства способа: высокая скорость доступа, так как
затраты на поиск и считывание кластеров файла минимальны, отсутствие
фрагментации на уровне файла, минимален объем адресной информации – достаточно
хранить только номер первого кластера и объем файла. Недостатки невозможно
сказать, какого размера должна быть непрерывная область, выделяемая файлу, так как
файл при каждой модификации может увеличить свой размер, фрагментация на уровне
кластеров, из-за которой нельзя выбрать место для размещения файла целиком.
Из-за этих недостатков на практике используются другие методы, при которых файл
размещается в нескольких, в общем случае несмежных областях диска.
Достоинства способа: высокая скорость доступа, так как
затраты на поиск и считывание кластеров файла минимальны, отсутствие
фрагментации на уровне файла, минимален объем адресной информации – достаточно
хранить только номер первого кластера и объем файла. Недостатки невозможно
сказать, какого размера должна быть непрерывная область, выделяемая файлу, так как
файл при каждой модификации может увеличить свой размер, фрагментация на уровне
кластеров, из-за которой нельзя выбрать место для размещения файла целиком.
Из-за этих недостатков на практике используются другие методы, при которых файл
размещается в нескольких, в общем случае несмежных областях диска.
Размещение файла в виде связанного списка кластеров дисковой памяти.
При таком способе в начале каждого кластера содержится указатель на следующий кластер:
![]() Достоинства: Адресная
информация минимальна расположение файла может быть задано одним числом –
номером первого кластера, фрагментация на уровне кластеров отсутствует, так как
каждый кластер может быть присоединен к цепочке кластеров какого-либо файла,
файл может изменять свой размер, наращивая число кластеров.
Достоинства: Адресная
информация минимальна расположение файла может быть задано одним числом –
номером первого кластера, фрагментация на уровне кластеров отсутствует, так как
каждый кластер может быть присоединен к цепочке кластеров какого-либо файла,
файл может изменять свой размер, наращивая число кластеров.
Недостатки: Сложность организации доступа к произвольно заданному месту файла – чтобы прочитать пятый по порядку кластер файла, необходимо последовательно прочитать четыре первых кластера, прослеживая цепочку номеров кластеров, количество данных файла в одном кластере не равно степени двойки (одно слово израсходовано на номер следующего кластера), а многие программы читают данные кластерами, размер которых равен степени двойки, Фрагментация на уровне файлов (файл может разбиваться на несмежные фрагменты).
При отсутствии фрагментации на уровне кластеров на диске все равно имеется определенное количество областей памяти небольшого размера, которые невозможно использовать, то есть фрагментация все же существует. Эти фрагменты представляют собой неиспользуемые части последних кластеров, назначенных файлам, так как объем файла в общем случае не кратен размеру кластера. На каждом файле в среднем теряется половина кластера. Эти потери особенно велики, когда на диске имеется большое количество маленьких файлов, а кластер имеет большой размер.
Использование связанного списка индексов (например, в FAT)
Данный способ является модификацией предыдущего метода. Файлу также выделяется память в виде связанного списка кластеров. Номер первого кластера запоминается в записи каталога, где хранятся характеристики этого файла. Остальная адресная информация отделена от кластеров файла. С каждым кластером диска связан индекс. Индексы располагаются в отдельной области диска – в файловых системах FAT это таблица (File Allocation Table):
![]() Когда память свободна, все индексы имеют нулевое
значение. Если некоторый кластер N назначен некоторому файлу, то индекс этого
кластера становится равным либо номеру M следующего кластера данного файла,
либо принимает специальное значение – признак того, что этот кластер является
для файла последним. Индекс же предыдущего кластера файла принимает значение N,
указывая на вновь назначенный кластер.
Когда память свободна, все индексы имеют нулевое
значение. Если некоторый кластер N назначен некоторому файлу, то индекс этого
кластера становится равным либо номеру M следующего кластера данного файла,
либо принимает специальное значение – признак того, что этот кластер является
для файла последним. Индекс же предыдущего кластера файла принимает значение N,
указывая на вновь назначенный кластер.
Достоинства: минимальность адресной информации, отсутствие фрагментации на уровне кластеров, отсутствие проблем при изменении размера файла, для доступа к произвольному кластеру файла не требуется последовательно считывать его кластеры, достаточно прочитать только секторы диска, содержащие таблицу индексов, отсчитать нужное количество кластеров файла по цепочке и определить номер нужного кластера, данные файла заполняют кластер целиком, следовательно имеют объем, равный степени двойки. Недостатки: Фрагментация на уровне файлов (файл может разбиваться на несмежные фрагменты).
Перечисление номеров кластеров, занимаемых этим файлом.
Достоинства: высокая скорость доступа к произвольному кластеру файла, так как здесь применяется прямая адресация, которая исключает просмотр цепочки указателей при поиске адреса произвольного кластера файла, отсутствие фрагментации на уровне кластеров. Недостатки: длина адреса зависит от размера файла и для большого файла может составить значительную величину. Данный подход с некоторыми модификациями используется в ОС UNIX.
Файл, имеющий образ цельного, непрерывающегося набора байт, на самом деле разбросан «кусочками» по всему диску, причем это разбиение никак не связано с логической структурой файла: логически объединенные файлы из одного каталога совсем не обязательно должны соседствовать на диске.
Принципы размещения файлов, каталогов и системной информации на реальном устройстве (диске) называются физической организацией файловой системы.
Замечание. Различные файловые системы имеют разную физическую организацию (например, размер кластера). Основным типом устройства, которое используется для хранения файлов, являются дисковые накопители. Эти устройства предназначены для считывания и записи данных на жесткие и гибкие магнитные диски, оптические диски, flash-носители и др.
Жесткий диск состоит из одной или нескольких стеклянных или металлических пластин, каждая из которых покрыта с одной или двух сторон магнитным материалом. Для записи информации на магнитную поверхность дисков применяется следующий способ: поверхность рассматривается как последовательность точечных позиций, каждая из которых считается битом и может быть установлена в 0 или 1. Так как расположения точечных позиций определяется неточно, то для записи требуются заранее нанесенные метки, которые помогают записывающему устройству находить позиции записи. Процесс нанесения таких меток называется физическим форматированием и является обязательным перед первым использованием накопителя.
Физическое форматирование – это процесс записи на поверхность диска служебной информации, обозначающей сектора на диске (пометка начала и конца дорожки и сектора).
На каждой стороне каждой пластины размечены тонкие концентрические окружности (по ним располагаются синхронизирующиеся метки). Каждая концентрическая окружность называется дорожкой.
Количество дорожек зависит от типа диска. Нумерация дорожек начинается с 0 от внешнего края к центру диска. Когда диск вращается, головка чтения/записи считывает двоичные данные с магнитной дорожки или записывает их на нее. Нумерация сторон начинается с 0.
Группы дорожек (треков) одного радиуса, расположенных на поверхностях магнитных дисков, называются цилиндрами. Номер цилиндра совпадает с номером образующей дорожки. Жесткие диски могут иметь по несколько десятков тысяч цилиндров, на поверхности дискеты, как правило, их восемьдесят. Зная количество рабочих поверхностей, дорожек на одной стороне, размер сектора, можно определить емкость диска.
Для дискет 3.5”: 2 рабочие поверхности, 80 дорожек на каждой стороне, 18 секторов на каждой дорожке, 512 байт – каждый сектор. Тогда, емкость дискеты=21801181512=1 474 560 байтов = 1.44 Мбайт.
Каждая дорожка разбивается на секторы. Сектор – наименьшая адресуемая единица обмена данными дискового устройства с оперативной памятью. Нумерация секторов начинается с 1. Каждый сектор состоит из поля данных и поля служебной информации, ограничивающей и идентифицирующей его.
Для того чтобы контроллер диска мог найти на диске нужный сектор, необходимо задать ему все составляющие адреса сектора: номер цилиндра, номер поверхности, номер сектора ([c-h-s]).
ОС при работе с диском использует, как правило, собственную единицу дискового пространства, называемую кластером.
Кластер (ячейка размещения данных) – объем дискового пространства, участвующий в единичной операции чтения/записи, осуществляемой ОС.
Кластер – это минимальный размер места на диске, которое может быть выделено файловой системой для хранения одного файла.
Пример. Если файл имеет размер 2560 байт, а размер кластера в файловой системе определен в 1024 байта, то файлу будет выделено на диске 3 кластера.
Размер кластера зависит от формата диска и может соответствовать одному сектору или нескольким смежным секторам дорожки.
Размер кластера определяется, как правило, автоматически при логическом форматировании.
Узнать размер кластера можно следующими способами:
Процесс подготовки диска к записи данных разбивается на следующие этапы:
В результате выполнения процедуры физического форматирования в секторах
создаются адресные метки, использующиеся для их идентификации в процессе
использования диска (создаются дорожки и секторы).
Низкоуровневый формат диска не зависит от типа ОС, которая этот диск будет
использовать.
В результате выполнения процедуры логического разбиения HDD делится на
логические разделы (тома) перед форматированием диска под определенную файловую
систему.
Раздел – это непрерывная часть физического диска, которую ОС представляет пользователю как логическое устройство (логический диск). Необходимость в разбиении на разделы возникает в следующих случаях:

ОС может поддерживать разные статусы разделов, особым образом отмечая разделы, которые могут быть использованы для загрузки модулей ОС, и разделы, в которых можно устанавливать только приложения и хранить файлы данных. Один из разделов диска помечается как загружаемый (основной, первичный, Primary). Именно из этого раздела считывается загрузчик ОС. А другой – как дополнительный (расширенный, Extenshion).
Разметку диска под конкретный тип файловой системы выполняют процедуры высокоуровневого, или логического, форматирования. При высокоуровневом форматировании определяется размер кластера и на диск записывается информация, необходимая для работы файловой системы, в том числе информация о доступном и неиспользуемом пространстве, о границах областей, отведенных под файлы и каталоги, информация о поврежденных областях. Кроме того, на диск записывается загрузчик ОС.
Логическое форматирование – процесс преобразования уже размеченного дискового пространства в соответствии со стандартами конкретной ОС. Единый стандарт разметки границ дискового раздела и разграничения разделов содержится в таблице разделов диска, которая находится в 1-ом секторе диска (цилиндр 0, дорожка 0, сектор 1). Таблица разделов содержит параметры диска, число разделов, размер и расположение каждого раздела и др.
Для организации логического диска каждая ОС разделяет его на две части:

Системная область предназначена для хранения служебной информации и управляет использованием области данных: применяется для регистрации состояния каждого участка диска. Эта область создается при форматировании и обновляется при операциях с файлами.
В системной области находятся:
Область данных предназначена для регистрации данных, хранящейся на диске. Содержит файлы и каталоги, подчиненные корневому каталогу. С учетом общей структуры логического диска структуру всего дискового пространства, разбитого на несколько разделов, можно представить следующим образом:
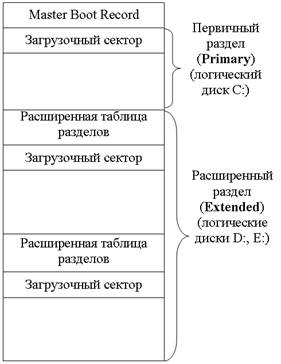
Вся информация, необходимая для начальной загрузки компьютера, находится в самом первом секторе жёсткого диска. Эта информация называется главной записью загрузки — MBR (Master Boot Record).
Расширенная таблица разделов состоит из двух элементов: первый элемент расширенной таблицы разделов для первого логического устройства указывает на его загрузочный сектор, второй элемент — на EBR следующего логического устройства (Extended Boot Record, EBR - Расширенная загрузочная запись).
http://sdo.uspi.ru/mathem&inform/lek12/lek_12.htm
7. Ассемблер для микропроцессоров с системой команд I-8086. Трансляция, компоновка и отладка программ
|
|
||||||||||||||||
|
Базы данных • Интернет • Компьютеры • Операционные системы • Программирование • Сети • |
||||||||||||||||
|
|
|
||||||||||||||
|
Emanual.ru – это сайт, посвящённый всем значимым событиям в IT-индустрии: новейшие разработки, уникальные методы и горячие новости! Тонны информации, полезной как для обычных пользователей, так и для самых продвинутых программистов! Интересные обсуждения на актуальные темы и огромная аудитория, которая может быть интересна широкому кругу рекламодателей. У нас вы узнаете всё о компьютерах, базах данных, операционных системах, сетях, инфраструктурах, связях и программированию на популярных языках! |
||||||||||
|
||||||||||
Компьютерные сети
1. Протокол передачи данных. Назначение и характеристики основных протоколов стека TCP\IP
Сеть Internet - это сеть сетей, объединяющая как локальные сети, так и глобальные сети типа NSFNET. Поэтому центральным местом при обсуждении принципов построения сети является семейство протоколов межсетевого обмена TCP/IP.
Под термином "TCP/IP" обычно понимают все, что связано с протоколами TCP и IP. Это не только собственно сами проколы с указанными именами, но и протоколы построенные на использовании TCP и IP, и прикладные программы.
Главной задачей стека TCP/IP является объединение в сеть пакетных подсетей через шлюзы. Каждая сеть работает по своим собственным законам, однако предполагается, что шлюз может принять пакет из другой сети и доставить его по указанному адресу. Реально, пакет из одной сети передается в другую подсеть через последовательность шлюзов, которые обеспечивают сквозную маршрутизацию пакетов по всей сети. В данном случае, под шлюзом понимается точка соединения сетей. При этом соединяться могут как локальные сети, так и глобальные сети. В качестве шлюза могут выступать как специальные устройства, маршрутизаторы, например, так и компьютеры, которые имеют программное обеспечение, выполняющее функции маршрутизации пакетов. Маршрутизация - это процедура определения пути следования пакета из одной сети в другую.
Такой механизм доставки становится возможным благодаря реализации во всех узлах сети протокола межсетевого обмена IP. Если обратиться к истории создания сети Internet, то с самого начала предполагалось разработать спецификации сети коммутации пакетов. Это значит, что любое сообщение, которое отправляется по сети, должно быть при отправке "нашинковано" на фрагменты. Каждый из фрагментов должен быть снабжен адресами отправителя и получателя, а также номером этого пакета в последовательности пакетов, составляющих все сообщение в целом. Такая система позволяет на каждом шлюзе выбирать маршрут, основываясь на текущей информации о состоянии сети, что повышает надежность системы в целом. При этом каждый пакет может пройти от отправителя к получателю по своему собственному маршруту. Порядок получения пакетов получателем не имеет большого значения, т.к. каждый пакет несет в себе информацию о своем месте в сообщении. При создании этой системы принципиальным было обеспечение ее живучести и надежной доставки сообщений, т.к. предполагалось, что система должна была обеспечивать управление Вооруженными Силами США в случае нанесения ядерного удара по территории страны.
При рассмотрении процедур межсетевого взаимодействия всегда опираются на стандарты, разработанные International Standard Organization (ISO). Эти стандарты получили название "Семиуровневой модели сетевого обмена" или в английском варианте "Open System Interconnection Reference Model" (OSI Ref.Model). В данной модели обмен информацией может быть представлен в виде стека, представленного на рисунке 2.1. Как видно из рисунка, в этой модели определяется все - от стандарта физического соединения сетей до протоколов обмена прикладного программного обеспечения. Дадим некоторые комментарии к этой модели.
Физический уровень данной модели определяет характеристики физической сети передачи данных, которая используется для межсетевого обмена. Это такие параметры, как: напряжение в сети, сила тока, число контактов на разъемах и т.п. Типичными стандартами этого уровня являются, например RS232C, V35, IEEE 802.3 и т.п.
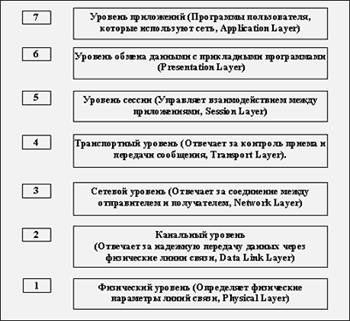
Рис. 2.1. Семиуровневая модель протоколов межсетевого обмена OSI
К канальному уровню отнесены протоколы, определяющие соединение, например, SLIP (Strial Line Internet Protocol), PPP (Point to Point Protocol), NDIS, пакетный протокол, ODI и т.п. В данном случае речь идет о протоколе взаимодействия между драйверами устройств и устройствами, с одной стороны, а с другой стороны, между операционной системой и драйверами устройства. Такое определение основывается на том, что драйвер - это, фактически, конвертор данных из оного формата в другой, но при этом он может иметь и свой внутренний формат данных.
К сетевому (межсетевому) уровню относятся протоколы, которые отвечают за отправку и получение данных, или, другими словами, за соединение отправителя и получателя. Вообще говоря, эта терминология пошла от сетей коммутации каналов, когда отправитель и получатель действительно соединяются на время работы каналом связи. Применительно к сетям TCP/IP, такая терминология не очень приемлема. К этому уровню в TCP/IP относят протокол IP (Internet Protocol). Именно здесь определяется отправитель и получатель, именно здесь находится необходимая информация для доставки пакета по сети.
Транспортный уровень отвечает за надежность доставки данных, и здесь, проверяя контрольные суммы, принимается решение о сборке сообщения в одно целое. В Internet транспортный уровень представлен двумя протоколами TCP (Transport Control Protocol) и UDP (User Datagramm Protocol). Если предыдущий уровень (сетевой) определяет только правила доставки информации, то транспортный уровень отвечает за целостность доставляемых данных.
Уровень сессии определяет стандарты взаимодействия между собой прикладного программного обеспечения. Это может быть некоторый промежуточный стандарт данных или правила обработки информации. Условно к этому уровню можно отнеси механизм портов протоколов TCP и UDP и Berkeley Sockets. Однако обычно, рамках архитектуры TCP/IP такого подразделения не делают.
Уровень обмена данными с прикладными программами (Presentation Layer) необходим для преобразования данных из промежуточного формата сессии в формат данных приложения. В Internet это преобразование возложено на прикладные программы.
Уровень прикладных программ или приложений определяет протоколы обмена данными этих прикладных программ. В Internet к этому уровню могут быть отнесены такие протоколы, как: FTP, TELNET, HTTP, GOPHER и т.п.
Вообще говоря, стек протоколов TCP отличается от только что рассмотренного стека модели OSI. Обычно его можно представить в виде схемы, представленной на рисунке 2.2.

Рис. 2.2. Структура стека протоколов TCP/IP
В этой схеме на уровне доступа к сети располагаются все протоколы доступа к физическим устройствам. Выше располагаются протоколы межсетевого обмена IP, ARP, ICMP. Еще выше основные транспортные протоколы TCP и UDP, которые кроме сбора пакетов в сообщения еще и определяют какому приложению необходимо данные отправить или от какого приложения необходимо данные принять. Над транспортным уровнем располагаются протоколы прикладного уровня, которые используются приложениями для обмена данными.
Базируясь на классификации OSI (Open System Integration) всю архитектуру протоколов семейства TCP/IP попробуем сопоставить с эталонной моделью (рисунок 2.3).

Рис. 2.3. Схема модулей, реализующих протоколы семейства TCP/IP в узле сети
Прямоугольниками на схеме обозначены модули, обрабатывающие пакеты, линиями - пути передачи данных. Прежде чем обсуждать эту схему, введем необходимую для этого терминологию.
Драйвер - программа, непосредственно взаимодействующая с сетевым адаптером.
Модуль - это программа, взаимодействующая с драйвером, с сетевыми прикладными программами или с другими модулями.
Схема приведена для случая подключения узла сети через локальную сеть Ethernet, поэтому названия блоков данных будут отражать эту специфику.
Сетевой интерфейс - физическое устройство, подключающее компьютер к сети. В нашем случае - карта Ethernet.
Кадр - это блок данных, который принимает/отправляет сетевой интерфейс.
IP-пакет - это блок данных, которым обменивается модуль IP с сетевым интерфейсом.
UDP-датаграмма - блок данных, которым обменивается модуль IP с модулем UDP.
TCP-сегмент - блок данных, которым обменивается модуль IP с модулем TCP.
Прикладное сообщение - блок данных, которым обмениваются программы сетевых приложений с протоколами транспортного уровня.
Инкапсуляция - способ упаковки данных в формате одного протокола в формат другого протокола. Например, упаковка IP-пакета в кадр Ethernet или TCP-сегмента в IP-пакет. Согласно словарю иностранных слов термин "инкапсуляция" означает "образование капсулы вокруг чужих для организма веществ (инородных тел, паразитов и т.д.)". В рамках межсетевого обмена понятие инкапсуляции имеет несколько более расширенный смысл. Если в случае инкапсуляции IP в Ethernet речь идет действительно о помещении пакета IP в качестве данных Ethernet-фрейма, или, в случае инкапсуляции TCP в IP, помещение TCP-сегмента в качестве данных в IP-пакет, то при передаче данных по коммутируемым каналам происходит дальнейшая "нарезка" пакетов теперь уже на пакеты SLIP или фреймы PPP.
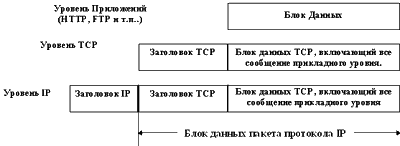
Рис. 2.4. Инкапсуляция протоколов верхнего уровня в протоколы TCP/IP
Вся схема (рисунок 2.4) называется стеком протоколов TCP/IP или просто стеком TCP/IP. Чтобы не возвращаться к названиям протоколов расшифруем аббревиатуры TCP, UDP, ARP, SLIP, PPP, FTP, TELNET, RPC, TFTP, DNS, RIP, NFS:
TCP - Transmission Control Protocol - базовый транспортный протокол, давший название всему семейству протоколов TCP/IP.
UDP - User Datagram Protocol - второй транспортный протокол семейства TCP/IP. Различия между TCP и UDP будут обсуждены позже.
ARP - Address Resolution Protocol - протокол используется для определения соответствия IP-адресов и Ethernet-адресов.
SLIP - Serial Line Internet Protocol (Протокол передачи данных по телефонным линиям).
PPP - Point to Point Protocol (Протокол обмена данными "точка-точка").
FTP - File Transfer Protocol (Протокол обмена файлами).
TELNET - протокол эмуляции виртуального терминала.
RPC - Remote Process Control (Протокол управления удаленными процессами).
TFTP - Trivial File Transfer Protocol (Тривиальный протокол передачи файлов).
DNS - Domain Name System (Система доменных имен).
RIP - Routing Information Protocol (Протокол маршрутизации).
NFS - Network File System (Распределенная файловая система и система сетевой печати).
При работе с такими программами прикладного уровня, как FTP или telnet, образуется стек протоколов с использованием модуля TCP, представленный на рисунке 2.5.
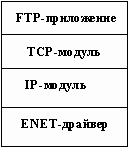
Рис. 2.5. Стек протоколов при использовании модуля TCP
При работе с прикладными программами, использующими транспортный протокол UDP, например, программные средства Network File System (NFS), используется другой стек, где вместо модуля TCP будет использоваться модуль UDP (рисунок 2.6).

Рис. 2.6. Стек протоколов при работе через транспортный протокол UDP
При обслуживании блочных потоков данных модули TCP, UDP и драйвер ENET работают как мультиплексоры, т.е. перенаправляют данные с одного входа на несколько выходов и наоборот, с многих входов на один выход. Так, драйвер ENET может направить кадр либо модулю IP, либо модулю ARP, в зависимости от значения поля "тип" в заголовке кадра. Модуль IP может направить IP-пакет либо модулю TCP, либо модулю UDP, что определяется полем "протокол" в заголовке пакета.
Получатель UDP-датаграммы или TCP-сообщения определяется на основании значения поля "порт" в заголовке датаграммы или сообщения.
Все указанные выше значения прописываются в заголовке сообщения модулями на отправляющем компьютере. Так как схема протоколов - это дерево, то к его корню ведет только один путь, при прохождении которого каждый модуль добавляет свои данные в заголовок блока. Машина, принявшая пакет, осуществляет демультиплексирование в соответствии с этими отметками.
Технология Internet поддерживает разные физические среды, из которых самой распространенной является Ethernet. В последнее время большой интерес вызывает подключение отдельных машин к сети через TCP-стек по коммутируемым (телефонным) каналам. С появлением новых магистральных технологий типа ATM или FrameRelay активно ведутся исследования по инкапсуляции TCP/IP в эти протоколы. На сегодняшний день многие проблемы решены и существует оборудование для организации TCP/IP сетей через эти системы.
При описании основных протоколов стека TCP/IP будем следовать модели стека описанной в предыдущем разделе. Первыми будут рассмотрены протоколы канального ровня SLIP и PPP. Это единственные протоколы этого уровня которые будут нами рассмотрены, так как были разработаны в рамках Internet и для Internet. Другие протоколы, например, NDIS или ODI, мы рассматривать не будем, т.к. они создавались под другие сети, хотя и могут использоваться в сетях TCP/IP также, как например, и пакетный протокол.
2.2.1. Протоколы SLIP и PPP
Интерес к этим двум протоколам вызван тем, что они применяются как на коммутируемых, так и на выделенных телефонных каналах. При помощи этих каналов к сети подключается большинство индивидуальных пользователей, а также небольшие локальные сети. Такие линии связи могут обеспечивать скорость передачи данных до 115200 битов за секунду.
Протокол SLIP (Serial Line Internet Protocol). Технология TCP/IP позволяет организовать межсетевое взаимодействие, используя различные физические и канальные протоколы обмена данными (IEEE 802.3 - ethernet, IEEE 802.5 - token ring, X.25 и т.п.). Однако, без обмена данными по телефонным линиям связи с использованием обычных модемов популярность Internet была бы значительно ниже. Большинство пользователей Сети используют свой домашний телефон в качестве окна в мир компьютерных сетей, подключая компьютер через модем к модемному пулу компании, предоставляющей IP-услуги или к своему рабочему компьютеру. Наиболее простым способом, обеспечивающим полный IP-сервис, является подключение через последовательный порт персонального компьютера по протоколу SLIP.
Согласно RFC-1055, впервые SLIP был включен в качестве средства доступа к IP-сети в пакет фирмы 3COM - UNET. В 1984 году Рик Адамс(Rick Adams) реализовал SLIP для BSD 4.2, и таким образом SLIP стал достоянием всего IP-сообщества.
Обычно, этот протокол применяют как на выделенных, так и на коммутируемых линиях связи со скоростями от 1200 до 19200 бит в секунду. Если модемы позволяют больше, то скорость можно "поднять", т.к. современные персональные компьютеры позволяют передавать данные в порт со скоростью 115200 битов за секунду. Однако, при определении скорости обмена данными следует принимать во внимание, что при передаче данных по физической линии данные подвергаются преобразованиям: компрессия и защита от ошибок на линии. Такое преобразование заставляет определять меньшую скорость на линии, чем скорость порта.
Следует отметить, что среди условно-свободно распространяемых программных IP-стеков (FreeWare), Trumpet Winsock, например, обязательно включена поддержка SLIP-коммуникаций. Такие операционные системы, как FreeBSD, Linux, NetBSD, которые можно свободно скопировать и установить на своем персональном компьютере, или HP-UX, которая поставляется вместе с рабочими станциями Hewlett Packard, имеют в своем арсенале программные средства типа sliplogin (FreeBSD) или slp (HP-UX), обеспечивающими работу компьютера в качестве SLIP-сервера для удаленных пользователей, подключающихся к IP-сети по телефону. В протоколе SLIP нет определения понятия "SLIP-сервер", но реальная жизнь вносит коррективы в стандарты. В контексте нашего изложения "SLIP-клиент" - это компьютер инициирующий физическое соединение, а "SLIP-сервер" - это машина, постоянно включенная в IP-сеть. В главе, посвященной организации IP-сетей и подключению удаленных компьютеров, будет подробно рассказано о различных способах подключения по SLIP-протоколу, поэтому не останавливаясь на деталях такого подключения перейдем к обсуждению самого протокола SLIP.
В отличии от Ethernet, SLIP не "заворачивает" IP-пакет в свою обертку, а "нарезает" его на "кусочки". При этом делает это довольно примитивно. SLIP-пакет начинается символом ESC (восьмеричное 333 или десятичное 219) и кончается символом END (восьмеричное 300 или десятичное 192). Если внутри пакета встречаются эти символы, то они заменяются двухбайтовыми последовательностями ESC-END (333 334) и ESC-ESC (333 335). Стандарт не определяет размер SLIP-пакета, поэтому любой SLIP-интерфейс имеет специальное поле, в котором пользователь должен указать эту длину. Однако, в стандарте есть указание на то, что BSD SLIP драйвер поддерживает пакеты длиной 1006 байт, поэтому "современные" реализации SLIP-программ должны поддерживать эту длину пакетов. SLIP-модуль не анализирует поток данных и не выделяет какую-либо информацию в этом потоке. Он просто "нарезает" ее на "кусочки", каждый из которых начинается символом ESC, а кончается символом END. Из приведенного выше описания понятно, что SLIP не позволяет выполнять какие-либо действия, связанные с адресами, т.к. в структуре пакета не предусмотрено поле адреса и его специальная обработка. Компьютеры, взаимодействующие по SLIP, обязаны знать свои IP-адреса заранее. SLIP не позволяет различать пакеты по типу протокола, например, IP или DECnet. Вообще-то, при работе по SLIP предполагается использование только IP (Serial Line IP все-таки), но простота пакета может быть соблазнительной и для других протоколов. В SLIP нет информации, позволяющей корректировать ошибки линии связи. Коррекция ошибок возлагается на протоколы транспортного уровня - TCP, UDP. В стандартном SLIP не предусмотрена компрессия данных, но существуют варианты протокола с такой компрессией. По поводу компрессии следует заметить следующее: большинство современных модемов, поддерживающих стандарты V.42bis и MNP5, осуществляют аппаратную компрессию. При этом практика работы по нашим обычным телефонным каналам показывает, что лучше отказаться от этой компрессии и работать только с автоматической коррекцией ошибок, например MNP4 или V.42. Вообще говоря, каждый должен подобрать тот режим, который наиболее устойчив в конкретных условиях работы телефонной сети (вплоть до времени года, и частоты аварий на теплотрассах).
Соединения типа "точка-точка" - протокол PPP (Point to Point Protocol). PPP - это более молодой протокол, нежели SLIP. Однако, назначение у него то же самое - управление передачей данных по выделенным или коммутируемым линиям связи. Согласно RFC-1661, PPP обеспечивает стандартный метод взаимодействия двух узлов сети. Предполагается, что обеспечивается двунаправленная одновременная передача данных. Как и в SLIP, данные "нарезаются" на фрагменты, которые называются пакетами. Пакеты передаются от узла к узлу упорядоченно. В отличии от SLIP, PPP позволяет одновременно передавать по линии связи пакеты различных протоколов. Кроме того, PPP предполагает процесс автоконфигурации обоих взаимодействующих сторон. Собственно говоря, PPP состоит из трех частей: механизма инкапсуляции (encapsulation), протокола управления соединением (link control protocol) и семейства протоколов управления сетью (network control protocols).
При обсуждении способов транспортировки данных при межсетевом обмене часто применяется инкапсуляция, например, инкапсуляция IP в X.25. С инкапсуляцией TCP в IP мы уже встречались. Инкапсуляция обеспечивает мультиплексирование различных сетевых протоколов (протоколов межсетевого обмена, например IP) через один канал передачи данных. Инкапсуляция PPP устроенна достаточно эффективно, например для передачи HDLC фрейма требуется всего 8 дополнительных байтов (8 октетов, согласно терминологии PPP). При других способах разбиения информации на фреймы число дополнительных байтов может быть сведено до 4 или даже 2. Для обеспечения быстрой обработки информации граница PPP пакета должна быть кратна 32 битам. При необходимости в конец пакета для выравнивания на 32-битовую границу добавляется "балласт". Вообще говоря, понятие инкапсуляции в терминах PPP - это не только добавление служебной информации к транспортируемой информации, но, если это необходимо, и разбиение этой информации на более мелкие фрагменты.
Под датаграммой в PPP понимают информационную единицу сетевого уровня, применительно к IP - IP-пакет. Под фреймом понимают информационную единицу канального уровня (согласно модели OSI). Фрейм состоит из заголовка и хвоста, между которыми содержатся данные. Датаграмма может быть инкапсулирована в один или несколько фреймов. Пакетом называют информационную единицу обмена между модулями сетевого и канального уровня. Обычно, каждому пакету ставится в соответствие один фрейм, за исключением тех случаев, когда канальный уровень требует еще большей фрагментации данных или, наоборот, объединяет пакеты для более эффективной передачи. Типичным случаем фрагментации являются сети ATM. В упрощенном виде PPP-фрейм показан на рисунке 2.7.

Рис. 2.7. PPP-фрейм
В поле "протокол" указывается тип инкапсулированной датаграммы. Существуют специальные правила кодирования протоколов в этом поле (см.ISO 3309 и RFC-1661). В поле "информация" записывается собственно пакет данных, а в поле "хвост" добавляется "пустышка" для выравнивания на 32-битувую границу. По умолчанию для фрейма PPP используется 1500 байтов. В это число не входит поле "протокол".
Протокол управления соединением предназначен для установки соглашения между узлами сети о параметрах инкапсуляции (размер фрейма, например). Кроме этого, протокол позволяет проводить идентификацию узлов. Первой фазой установки соединения является проверка готовности физического уровня передачи данных. При этом, такая проверка может осуществляться периодически, позволяя реализовать механизм автоматического восстановления физического соединения как это бывает при работе через модем по коммутируемой линии. Если физическое соединение установлено, то узлы начинают обмен пакетами протокола управления соединением, настраивая параметры сессии. Любой пакет, отличный от пакета протокола управления соединением, не обрабатывается во время этого обмена. После установки параметров соединения возможен переход к идентификации. Идентификация не является обязательной. После всех этих действий происходит настройка параметров работы с протоколами межсетевого обмена (IP, IPX и т.п.). Для каждого из них используется свой протокол управления. Для завершения работы по протоколу PPP по сети передается пакет завершения работы протокола управления соединением.
Процедура конфигурации сетевых модулей операционной системы для работы по протоколу PPP более сложное занятие, чем аналогичная процедура для протокола SLIP. Однако, возможности PPP соединения гораздо более широкие. Так например, при работе через модем модуль PPP, обычно, сам восстанавливает соединение при потере несущей частоты. Кроме того, модуль PPP сам определяет параметры своих фреймов, в то время как при SLIP их надо подбирать вручную. Правда, если настраивать оба конца, то многие проблемы не возникают из-за того, что параметры соединения известны заранее. Более подробно с протоколом PPP можно познакомиться в RFC-1661 и RFC-1548.
2.2.2. Протокол ARP. Отображение канального уровня на уровень межсетевого обмена
Прежде чем начать описание протокола ARP необходимо сказать несколько слов о протоколе Ethernet.
Технология Ethernet. Кадр Ethernet содержит адрес назначения, адрес источника, поле типа и данные. Размер адреса Ethernet - 6 байтов. Каждый сетевой адаптер имеет свой сетевой адрес. Адаптер "слушает" сеть, принимает адресованные ему кадры и широковещательные кадры с адресом FF:FF:FF:FF:FF:FF, отправляет кадры в сеть.
Технология Ethernet реализует метод множественного доступа с контролем несущей и обнаружением столкновений. Этот метод предполагает, что все устройства взаимодействуют в одной среде. В каждый момент времени передавать может только одно устройство, а все остальные только слушать. Если два или более устройств пытаются передать кадр одновременно, то фиксируется столкновение и каждое устройство возобновляет попытку передачи кадра через случайный промежуток времени. Одним словом, в каждый момент времени в сегменте узла сети находится только один кадр.
Понятно, что чем больше компьютеров подключено в сегменте Ethernet, тем больше столкновений будет зафиксировано и тем медленнее будет работать сеть. Кроме того, если в сети стоит сервер, к которому часто обращаются, то это также снизит общую производительность сети.
Важной особенностью интерфейса Ethernet является то, что каждая интерфейсная карта имеет свой уникальный адрес. Каждому производителю карт выделен свой пул адресов в рамках которого он может выпускать карты (таблица 2.1). Согласно протоколу Ethernet, каждый интерфейс имеет 6-ти байтовый адрес. Адрес записывается в виде шести групп шестнадцатиричных цифр по две в каждой (шестнадцатеричная записи байта). Первые три байта называются префиксом, и именно они закреплены за производителем. Каждый префикс определяет 224 различных комбинаций, что равно почти 17-ти млн. адресам.
Таблица 2.1 <pПрефиксы адресов Ethernet интерфейсов(карт) и Производители, за которыми эти префиксы закреплены
|
Префикс |
Производитель |
Префикс |
Производитель |
|
00:00:0C |
Cisco |
08:00:0B |
Unisys |
|
00:00:0F |
NeXT |
08:00:10 |
T&T |
|
00:00:10 |
Sytek8:00:11 |
Tektronix |
|
|
00:00:1D |
Cabletron |
08:00:14 |
Exelan |
|
00:00:65 |
Network General |
08:00:1A |
Data General |
|
00:00:6B |
MIPS |
08:00:1B |
Data General |
|
00:00:77 |
Cayman System |
08:00:1E |
Sun |
|
00:00:93 |
Proteon |
08:00:20 |
CDC |
|
00:00:A2 |
Wellfleet |
08:00:2% |
DEC |
|
00:00:A7 |
NCD |
08:00:2B |
Bull |
|
00:00:A9 |
Network Systems |
08:00:38 |
Spider Systems |
|
00:00:C0 |
Western Digital |
08:00:46 |
Sony |
|
00:00:C9 |
Emulex |
08:00:47 |
Sequent |
|
00:80:2D |
Xylogics Annex |
08:00:5A |
IBM |
|
00:AA:00 |
Intel |
08:00:69 |
Silicon Graphics |
|
00:DD:00 |
Ungermann-Bass |
08:00:6E |
Exelan |
|
00:DD:01 |
Ungermann-Bass |
08:00:86 |
Imageon/QMS |
|
02:07:01 |
MICOM/Interlan |
08:00:87 |
Xyplex terminal servers |
|
02:60:8C |
3Com |
08:00:89 |
Kinetics |
|
08:00:02 |
3Com(Bridge) |
08:00:8B |
Pyromid |
|
08:00:03 |
ACC |
08:00:90 |
Retix |
|
08:00:05 |
Symbolics |
AA:00:03 |
DEC |
|
08:00:08 |
BBN |
AA:00:04 |
DEC |
|
08:00:09 |
Hewlett-Packard |
</p
Протокол ARP (RFC 826). Address Resolution Protocol используется для определения соответствия IP-адреса адресу Ethernet. Протокол используется в локальных сетях. Отображение осуществляется только в момент отправления IP-пакетов, так как только в этот момент создаются заголовки IP и Ethernet. Отображение адресов осуществляется путем поиска в ARP-таблице. Упрощенно, ARP-таблица состоит из двух столбцов:
|
IP-адрес |
Ethernet-адрес |
|
223.1.2.1 |
08:00:39:00:2F:C3 |
|
223.1.2.3 |
08:00:5A:21:A7:22 |
|
223.1.2.4 |
08:00:10:99:AC:54 |
В первом столбце содержится IP-адрес, а во втором Ethernet-адрес. Таблица соответствия необходима, так как адреса выбираются произвольно и нет какого-либо алгоритма для их вычисления. Если машина перемещается в другой сегмент сети, то ее ARP-таблица должна быть изменена.
Таблицу ARP можно посмотреть, используя команду arp:
quest:/usr/paul:\[8\]%arp -a paul.polyn.kiae.su (144.206.192.34) at 0:0:1:16:2:45 polyn.net.kiae.su (144.206.130.137) at 0:1:1b:9:d0:90 arch.kiae.su (144.206.136.10) at 0:0:c:1b:ae:7b demin.polyn.kiae.su (144.206.192.4) at 0:0:1:16:29:80 quest:/usr/paul:\[9\]%
Правда здесь существуют нюансы. В каждый момент времени таблица ARP разная. Это хорошо видно на следующем примере:
Ix: {8} arp -apolyn.net.kiae.su (144.206.130.137) at 0:1:1b:9:d0:90 permanent
quest.net.kiae.su (144.206.130.138) at 0:0:1b:12:32:32 ? (144.206.140.201) at 0:0:c0:89:c4:a4
polyn.net.kiae.su (144.206.160.32) at 0:80:29:b1:9f:e3 permanent Ix.polyn.kiae.su (144.206.160.33) at (incomplete) Ix: {9} ping apollo.polyn.kiae.su PING apollo.polyn.kiae.su (144.206.160.40): 56 data bytes 64 bytes from 144.206.160.40: icmp_seq=0 ttl=255 time=1.409 ms 64 bytes from 144.206.160.40: icmp_seq=1 ttl=255 time=0.799 ms 64 bytes from 144.206.160.40: icmp_seq=2 ttl=255 time=0.797 ms 64 bytes from 144.206.160.40: icmp_seq=3 ttl=255 time=0.857 ms ^c --- apollo.polyn.kiae.su ping statistics --- 4 packets transmitted, 4 packets received, 0% packet loss round-trip min/avg/max = 0.797/0.965/1.409 ms ix: {10} arp -a polyn.net.kiae.su (144.206.130.137) at 0:1:1b:9:d0:90 permanent quest.net.kiae.su (144.206.130.138) at 0:0:1b:12:32:32 ? (144.206.140.201) at 0:0:c0:89:c4:a4
polyn.net.kiae.su (144.206.160.32) at 0:80:29:b1:9f:e3 permanent ix.polyn.kiae.su (144.206.160.33) at (incomplete) apollo.polyn.kiae.su (144.206.160.40) at 8:0:9:b:3d:b8 ix: {11}В приведенном примере подчеркиванием выделены команды, которые пользователь вводил из командной строки. При первом использовании команды ARP в таблице ARP нет машины apollo.polyn.kiae.su, хотя она находится в том же сегменте Ethernet, что и машина polyn.net.kiae.su, на которой выполняются команды. После выполнения команды ping в таблицу добавляется новая строка, которая задает соответствие Ethernet-адреса машины apollo и ее IP-адреса.
Кроме этого, в обоих отчетах arp есть строка с пустым именем машины, а точнее символом "?" в имени машины. В разделе 3.1 будут подробно рассмотрены вопросы определения имени машины по IP-адресу и IP-адреса по имени машины. В данном случае для машины с адресом 144.206.140.201 просто не определено соответствие между IP-адресом и именем машины.
При работе в локальной IP-сети при обращении к какому-либо ресурсу, например архиву FTP, его Ethernet-адрес ищется по IP-адресу в ARP-таблице и после этого запрос отправляется на сервер.
ARP-таблица заполняется автоматически, что хорошо видно из приведенного ранее примера. Если нужного адреса в таблице нет, то в сеть посылается широковещательный запрос типа "чей это IP-адрес?". Все сетевые интерфейсы получают этот запрос, но отвечает только владелец адреса. При этом существует два способа отправки IP-пакета, для которого ищется адрес: пакет ставится в очередь на отправку или уничтожается. В первом случае за отправку отвечает модуль ARP, а во втором случае модуль IP, который повторяет посылку через некоторое время. Широковещательный запрос выглядит так:
|
IP-адрес отправителя |
223.1.2.1 |
|
Ethernet-адрес отправителя |
08:00:39:00:2F:C3 |
|
Искомый IP-адрес |
222.1.2.2 |
|
Искомый Ethernet-адрес |
<пусто> |
Ответ машины, чей адрес ищется, будет выглядеть следующим образом:
|
IP-адрес отправителя |
222.1.2.2 |
|
Ethernet-адрес отправителя |
08:00:28:00:38:А9 |
|
IP-адрес получателя |
223.1.2.1 |
|
Ethernet-адрес получателя |
08:00:39:00:2F:C3 |
Полученный таким образом адрес будет добавлен в ARP-таблицу.
Следует отметить, что если искомого IP-адреса нет в локальной сети и сеть не соединена с другой сетью шлюзом, то разрешить запрос не удается. IP-модуль будет уничтожать такие пакеты, обычно по time-out (превышен лимит времени на разрешение запроса). Модули прикладного уровня, при этом, не могут отличить физического повреждения сети от ошибки адресации.
Однако в современной сети Internet, как правило, запрашивается информация с узлов, которые реально в локальную сеть не входят. В этом случае для разрешения адресных коллизий и отправки пакетов используется модуль IP.
Если машина соединена с несколькими сетями, т.е. она является шлюзом, то в таблицу ARP вносятся строки, которые описывают как одну, так и другую IP-сети. При использовании Ethernet и IP каждая машина имеет как минимум один адрес Ethernet и один IP-адрес. Собственно Ethernet-адрес имеет не компьютер, а его сетевой интерфейс. Таким образом, если компьютер имеет несколько интерфейсов, то это автоматически означает, что каждому интерфейсу будет назначен свой Ethernet-адрес. IP-адрес назначается для каждого драйвера сетевого интерфейса. Грубо говоря, каждой сетевой карте Ethernet соответствуют один Ethernet-адрес и один IP-адрес. IP-адрес уникален в рамках всего Internet.
2. Эталонная модель OSI|ISO: назначение и основные функции уровней. Роль модели OSI в стандартизации и унификации систем коммуникаций.
|
|
![]()
![]()
![]()
![]()
Next: Уровни
работы сети Internet Up: Работа
Internet: организацияструктура, Previous: Введение
Международная Организация по Стандартизации (ISO) приняла стандарт ISO 7498, описывающий взаимодействие открытых систем (OSI), каковыми среди прочего являются и сетевые компьютеры. Расскажем о нём.
Современные сети построены по многоуровневому принципу. Чтобы организовать связь двух компьютеров, требуется сначала создать свод правил их взаимодействия, определить язык их общения, т.е. определить, что означают посылаемые ими сигналы и т.д. Эти правила и определения называются протоколами. Для работы сетей необходимо запастись множеством различных протоколов: например, управляющих физической связью, установлением связи по сети, доступом к различным ресурсам и т.д. Многоуровневая структура используется с целью упростить и упорядочить это великое множество протоколов и отношений. Она также позволяет составлять сетевые системы из продуктов -- модулей программного обеспечения, -- выпущенных разными производителями.
Стандарт, выработанный ISO, называется Взаимодействие Открытых Систем -- Open System Interconnection -- OSI. Он описывает структуру самих открытых систем, требования к ним, их взаимодействие. Модель взаимодействия сетевых систем, представленная в этом стандарте, известна под названием ``эталонная модель ISO/OSI''. Она вертикально структурирована и имеет семь уровней.
Продемонстрируем основные принципы многоуровневого взаимодействия на диаграмме. Структура эталонной модели согласно ISO показана на рисунке 3.1.
![]()
Figure: Эталонная модель ISO/OSI
Взаимодействие уровней в этой модели -- субординарное. Каждый уровень может реально взаимодействовать только с соседними уровнями (верхним и нижним), виртуально -- только с аналогичным уровнем на другом конце линии.
Под реальным взаимодействием мы подразумеваем непосредственное взаимодействие, непосредственную передачу информации, например, пересылку данных в оперативной памяти из области, отведённой одной программе, в область другой программы. При непосредственной передаче данные остаются неизменными всё время.
Под виртуальным взаимодействием мы понимаем опосредованное взаимодействие и передачу данных; здесь данные в процессе передачи могут уже определённым, заранее оговоренным образом видоизменяться.
Такое взаимодействие аналогично переписке двух больших начальников. Рассмотрим схему цепи посылки письма в такой переписке. Например, директор Systy Artems пишет письмо редактору газеты ``Гудок''. Г-н Рухмеров* пишет письмо на своём фирменном бланке (на листе шикарной мелованной бумаги) и отдаёт этот листок секретарю. Секретарь запечатывает листок в конверт, надписывает конверт, наклеивает марку и передаёт почте. Почта доставляет письмо в соответствующее почтовое отделение. Это почтовое отделение связи непосредственно доставляет письмо получателю -- секретарю редактора газеты ``Гудок''. Секретарь распечатывает конверт и по мере надобности подаёт письмо редактору. Ни одно из звеньев цепи не может быть пропущено, иначе цепь разорвётся: если отсутствует, например, секретарь, то листок с письменами г-на Рухмерова так и будет пылиться на столе.
Здесь мы видим, как информация (лист бумаги с текстом) передаётся с верхнего уровня вниз, проходя множество необходимых ступеней -- стадий обработки. Обрастает служебной информацией (пакет, адрес на конверте, почтовый индекс; контейнер с корреспонденцией; почтовый вагон и т.д.), изменяется на каждой стадии обработки и постепенно доходит до самого нижнего уровня -- уровня почтового транспорта (гужевого, железнодорожного, воздушного, ...), которым реально перевозится в пункт назначения. В пункте назначения происходит обратный процесс: вскрывается контейнер и извлекается корреспонденция, считывается адрес на конверте и почтальон несёт его адресату (секретарю), который восстанавливает информацию в первоначальном виде, -- достаёт письмо из конверта, определяет его срочность, важность, и в зависимости от этого передаёт информацию выше -- директору.
Два директора (директор и редактор), таким образом, виртуально имеют прямую связь. Ведь второй директор (редактор газеты ``Гудок'') получает в точности ту же информацию, которую отправил первый (г-н Рухмеров), а именно -- лист бумаги с текстом письма. Начальствующие персоны совершенно не заботятся проблемами пересылки этой информации.
Секретари также виртуально имеют прямую связь: секретарь редактора получит в точности то же, что отправила секретарь г-на Рухмерова, а именно -- конверт с письмом. Секретарей совершенно не волнуют проблемы почты, пересылающей письма. И так далее.
Аналогичные связи и процессы имеют место и в эталонной модели ISO/OSI. Физическая связь реально существует только на самом нижнем уровне (аналог почтовых поездов, самолётов, автомобилей). Горизонтальные связи между всеми остальными уровнями являются виртуальными, реально они осуществляются передачей информации сначала вниз, последовательно до самого нижнего уровня, где происходит реальная передача, а потом, на другом конце, обратная передача вверх последовательно до соответствующего уровня. На рисунке 3.1 показан путь информации на уровне 6.
Модель ISO/OSI предписывает очень сильную стандартизацию вертикальных межуровневых взаимодействий. Такая стандартизация гарантирует совместимость продуктов, работающих по стандарту какого-либо уровня, с продуктами, работающими по стандартам соседних уровней, даже в том случае, если они выпущены разными производителями. Количество уровней может показаться избыточным, однако же, такое разбиение необходимо для достаточно чёткого разделения требуемых функций во избежание излишней сложности и создания структуры, которая может подстраиваться под нужды конкретного пользователя, оставаясь в рамках стандарта.
Вообще-то нам кажется, что выбор числа 7 определился особенностями человеческой психики и сознания. Известно, что средний человек может одновременно оперировать (удерживая их в поле своего внимания) максимум 7 объектами (физическими, логическими, лингвистическими и т.п.). Вы никогда не задумывались, почему в радуге 7 цветов?
Дадим краткий обзор уровней.
Уровень 0
связан с физической средой -- передатчиком сигнала и на самом деле не включается в эту схему, но весьма полезен для понимания. Этот почётный уровень представляет посредников, соединяющих конечные устройства: кабели, радиолинии и т.д. Кабелей существует великое множество различных видов и типов: экранированные и неэкранированные витые пары, коаксиальные, опто-волоконные и т.д. Т.к. этот уровень не включён в схему, он ничего и не описывает, только указывает на среду.
Уровень 1
-- физический. Включает физические аспекты передачи двоичной информации по линии связи. Детально описывает, например, напряжения, частоты, природу передающей среды. Этому уровню вменяется в обязанность поддержание связи и приём-передача битового потока. Безошибочность желательна, но не требуется.
Уровень 2
-- канальный. Связь данных. Обеспечивает безошибочную передачу блоков данных (называемых на этом уровне кадрами (frame)) через уровень 1, который при передаче может искажать данные. Этот уровень должен определять начало и конец кадра в битовом потоке, формировать из данных, передаваемых физическим уровнем, кадры или последовательности кадров, включать процедуру проверки наличия ошибок и их исправления. Этот уровень (и только он) оперирует такими элементами, как битовые последовательности, методы кодирования, маркеры. Он несёт ответственность за правильную передачу данных (пакетов) на участках между непосредственно связанными элементами сети. Обеспечивает управление доступом к среде передачи.
Этот уровень довольно сложен, поэтому часто он делится на подуровни, например, в стандартах IEEE канальный уровень подразделяется на два подуровня: MAC (Medium Access Control) -- управление доступом к среде и LLC (Logical Link Control) -- управление логической связью (каналом). Уровень MAC управляет доступом к сети (с передачей маркера в сетях Token Ring или распознаванием конфликтов (столкновений передач) в сетях типа Ethernet) и управлением сетью. Уровень LLC, действующий над уровнем MAC, и есть собственно тот уровень, который посылает и получает сообщения с данными.
Уровень 3
-- сетевой. Этот уровень пользуется возможностями, предоставляемыми ему уровнем 2, для обеспечения связи любых двух точек в сети. Любых, необязательно смежных. Этот уровень осуществляет проводку сообщений по сети, которая может иметь много линий связи, или по множеству совместно работающих сетей, что требует маршрутизации, т.е. определения пути, по которому следует пересылать данные. Маршрутизация производится на этом же уровне. Выполняет обработку адресов, а также мультиплексирование и демультиплексирование.
Основной функцией программного обеспечения на этом уровне является выборка информации из источника, преобразование её в пакеты и правильная передача в точку назначения. Есть два принципиально различных способа работы сетевого уровня.
Первый -- это метод виртуальных каналов. Он состоит в том, что канал связи устанавливается при вызове (в начале сеанса (session) связи), по нему передаётся информация, и по окончании передачи канал закрывается (уничтожается). Передача пакетов происходит с сохранением исходной последовательности, даже если пакеты пересылаются по различным физическим маршрутам, т.е. виртуальный канал динамически перенаправляется. При помещении данных в этот канал не требуется указания адреса пункта назначения, т.к. он определяется во время установления связи.
Второй -- метод дейтаграмм. Дейтаграммы -- независимые пакеты, они включают всю необходимую для их пересылки информацию.
В то время, как первый метод предоставляет следующему уровню (уровню 4) надёжный канал передачи данных, свободный от искажений (ошибок) и правильно доставляющий пакеты в пункт назначения, второй метод требует от следующего уровня работы над ошибками и проверки доставки нужному адресату.
Уровень 4
-- транспортный. Регламентирует пересылку данных между процессами, выполняемыми на компьютерах сети. Завершает организацию передачи данных: контролирует на сквозной основе поток данных, проходящий по маршруту, определённому третьим уровнем: правильность передачи блоков данных, правильность доставки в нужный пункт назначения, их комплектность, сохранность, порядок следования. Собирает информацию из блоков в её прежний вид. Или же оперирует с дейтаграммами, т.е. ожидает отклика-подтверждения приёма из пункта назначения, проверяет правильность доставки и адресации, повторяет посылку дейтаграммы, если не пришёл отклик. В рамках транспортного протокола предусмотрено пять классов качества транспортировки и соответствующие процедуры управления. Этот же уровень должен включать развитую и надёжную схему адресации для обеспечения связи через множество сетей и шлюзов. Другими словами, задачей данного уровня является довести до ума передачу информации из любой точки в любую другую во всей сети.
Транспортный уровень скрывает от всех высших уровней все детали и проблемы передачи данных, характерные для используемого типа передающей сети. Таким образом, он обеспечивает стандартное взаимодействие лежащего над ним уровня с приёмом-передачей информации независимо от конкретной технической реализации этой передачи, от используемых сетей и т.д.
Уровень 5
-- сеансовый. Координирует взаимодействие связывающихся процессов (работающих программ): устанавливает их связь, оперирует с ней, восстанавливает аварийно оконченные сеансы. Он координирует не компьютеры и устройства, а процессы в сети, поддерживает их взаимодействие -- управляет сеансами связи между процессами прикладного уровня. Этот же уровень ответственен за картографию сети -- он преобразовывает адреса, удобные для людей, в реальные сетевые адреса, например, в Internet это соответствует преобразованию региональных (доменных) компьютерных имён в числовые адреса Internet, и наоборот.
Уровень 6
-- уровень представления данных. Этот уровень имеет дело с синтаксисом и семантикой передаваемой информации, т.е. здесь устанавливается взаимопонимание двух сообщающихся компьютеров относительно того, как они представляют и понимают по получении передаваемую информацию. Здесь решаются такие задачи, как перекодировка текстовой информации и изображений, сжатие и распаковка, поддержка сетевых файловых систем (NFS), абстрактных структур данных и т.д.
Уровень 7
-- прикладной. Обеспечивает интерфейс между пользователем и сетью, делает доступными для человека всевозможные услуги. На этом уровне реализуется, по крайней мере, пять прикладных служб: передача файлов, удалённый терминальный доступ, электронная передача сообщений, справочная служба и управление сетью. В конкретной реализации определяется пользователем (программистом) согласно его насущным нуждам и возможностям его кошелька, интеллекта и фантазии.
Следует понимать, что подавляющее большинство современных сетей в силу исторических причин лишь в общих чертах, приближённо, соответствуют эталонной модели ISO/OSI.
Рассмотрим некоторые из указанных уровней в их проекции на Internet подробнее. Не забывайте, что проекция искажена в силу несоответствия технологии internet стандарту эталонной модели -- перемешаны некоторые уровни и функции уровней .
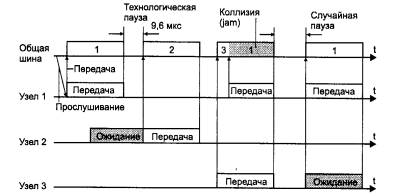
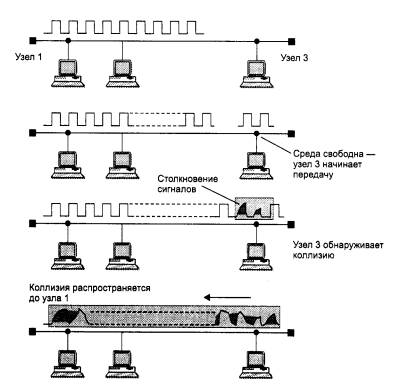



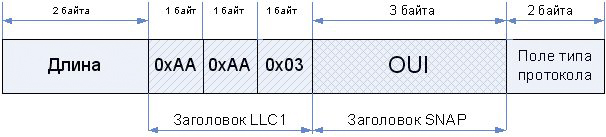
|
Характеристики |
Ethernet |
IEEE 802.3 |
|||||
|
10Base5 |
10Base2 |
1Base5 |
10BaseT |
10Broad36 |
10BaseF |
||
|
Скорость, Mbps |
10 |
1 |
10 |
10 |
10 |
10 |
10 |
|
Метод передачи |
Baseband |
Baseband |
Baseband |
Baseband |
Baseband |
Broadband |
Baseband |
|
Макс. длина сегмента, м |
500 |
500 |
185 |
250 |
100 |
1800 |
1800 |
|
Среда передачи |
50-Ом коаксиал (толстый) |
50-Ом коаксиал (толстый) |
50-Ом коаксиал (тонкий) |
неэкр. витая пара |
неэкр. витая пара |
75-Om коаксиал |
Многомодовая оптика 62.5мкм диам. |
|
Топология |
Шина |
Шина |
Шина |
Звезда |
Звезда |
Шина |
Звезда |
О компании
Контакты
Схема проезда

Торговый дом
+7 (495) 931
99 19
Интернет-магазин
+7 (495) 502
95 81
Товаров - 0
на сумму 0 Р
Корзина пуста
Прайс-лист
Ключевые слова: GSM;
сигнализация;
Сегодня
GSM-сети характеризуются достаточно высокой скоростью передачи данных,
повышением эффективности использования сетевых ресурсов и переходом на более
выгодную тарификацию. Как же развивался GSM-стандарт?
При разработке стандарта GSM (начало 90-х) в первую очередь учитывались
следующие аспекты: качество связи и передачи сообщений, проектирование
интерфейсов для взаимодействия с различными видами внешних сетей, реализация
межсетевого и международного роуминга, а также обеспечение конфиденциальности.
Высокая скорость передачи данных в то время не было принципиальным фактором:
для приложений казалось вполне достаточно 9,6 кбит/с. После доработки базового
стандарта GSM скорость передачи данных была увеличена до 14,4 кбит/с. Сейчас
для мобильного доступа к интернету и даже для передачи
мультимедийных сообщений таких скоростей явно не хватает.
К концу 90-х годов были найдены возможности совершенствования систем GSM
благодаря внедрению новых, более скоростных технологий передачи данных.
К ним относятся высокоскоростная передача данных с коммутацией каналов (High
Speed Circuit Switched Date - HSCSD) и пакетные сервисы передачи данных, такие
как обобщенная служба пакетной радиопередачи (General Packet Radio Service -
GPRS), а также усовершенствованная технология передачи данных для развития GSM
(Enhanced Data Rates for GSM Evolution - EDGE).
Для увеличения пропускной способности
использовался метод объединения нескольких GSM-каналов передачи данных в одном
с более высокой скоростью (HSCSD, GPRS, EDGE).
Внедрение пакетных методов информационного обмена (технологии GPRS, EDGE) стало
новым этапом в эволюции систем GSM. Кроме того, в технологии EDGE используется
особый метод модуляции с более высокой частотной эффективностью, благодаря чему
достигается существенное повышение скорости передачи данных.
Какой же метод передачи данных изначально закладывался в базовый стандарт GSM?
Основные принципы
передачи данных
Для доставки данных базовый стандарт GSM предусматривает использование каналов
передачи трафика (Traffic Channel - ТСН). Реализуются каналы TCH/F 2,4 TCH/F
4,8 и TCH/F 9,6 на 2,4, 4,8 и 9,6 кбит/с соответственно. При этом применяются
различные схемы помехоустойчивого избыточного кодирования.
В стандарте GSM используется комбинированный множественный доступ с частотным
(FDMA) и временным (TDMA) разделением каналов. Таким образом, все каналы
трафика формируются на основе физического канала со скоростью передачи 22,8
кбит/с, который использует один из восьми канальных интервалов (слотов) в кадре TDM. Стандарт GSM предусматривает
манипуляцию с минимальным частотным сдвигом (GMSK-модуляции) и метод доступа
FDMA. Формируются радиоканалы с полосой пропускания 200 кГц.
Все режимы, которые поддерживаются в базовом стандарте GSM, используют
технологию передачи данных в сети с коммутацией каналов (Circuit Switched Data
- CSD). Выделенный канал закрепляется за абонентом на все время сеанса связи, и
обмен данными осуществляется в реальном времени.
Процесс CSD-соединения и осуществление телефонного вызова идентичны, поэтому
технология CSD позволяет обеспечить зону покрытия, которая полностью совпадает
с зоной покрытия всей сети GSM.
Тарификация услуг передачи данных CSD не зависит от объема переданных и
полученных данных и определяется продолжительностью сеанса связи.
Скорости 9,6 кбит/с достаточно только для организации факсимильной связи с
использованием аппаратов третьей группы, передачи SMS-coобщений длиной до 160
символов и работы электронной почты (правда, с определенными ограничениями).
Кроме того, базовый стандарт GSM, а, значит, и технология CSD, основанная на
коммутации каналов, характеризуется достаточно длительным временем установления
соединения - около 20 с. Таким образом, учитывая современные требования,
базовый стандарт GSM имеет весьма скромные возможности передачи данных.
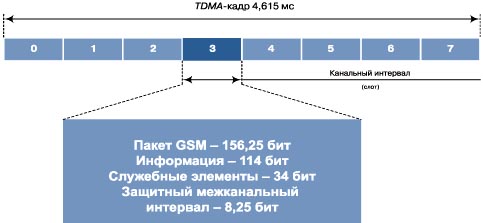
В
радиоканале с использованием TDMA может быть образовано восемь физических
каналов, по одному на каждый слот
Скоростная передача
данных с коммутацией каналов
Технология высокоскоростной передачи данных с коммутацией каналов HSCD
реализуется на базе уже действующих сетей GSM. Увеличение скорости передачи
данных достигается за счет того, что в кадре TDM одному пользователю выделяется
несколько временных канальных интервалов. При этом в технологии HSCSD в
качестве основы используются три схемы кодирования (CS1, CS2 и CS3) для каналов
трафика базового стандарта TCH/F 4,8, TCH/F 9,6/ и TCH/F 14,4. Схема
кодирования CS1 обеспечивает более высокую степень помехозащиты. Использование
двух канальных интервалов и схемы кодирования CS2 гарантирует скорость передачи
19,2 кбит/с (9,6X2), а при использовании CS3 достигается скорость 28,8 кбит/с
(14,4Х2).
Для внедрения HSCSD со скоростями до 28,8 кбит/с необходима модификация программных
средств мобильных станций MS и центра коммутации MSC, а также протоколов
обмена данными. Усовершенствованное программное обеспечение должно
гарантировать разделение (объединение) информационного потока на несколько
субпотоков, которые затем будут переданы (приняты) по нескольким каналам TCH.
В базовом стандарте GSM сдвиг между приемом сигналов базовой станции и
последующей их передачей мобильной станцией в одном кадре составляет 2 слота.
При режиме работы с двумя занятыми слотами этот сдвиг будет равен 4 интервалам.
Следует отметить, что технология HSCSD со скоростью передачи до 28,8 кбит/с уже
расширяет возможности пользователей сетей GSM.
Для обеспечения более скоростных режимов работы возможно объединение четырех
канальных интервалов. При этом достигаются скорости передачи 38,4 кбит/с
(9,6Х4), схема кодирования CS2, и 57,6 кбит/с (14,4X4), схема CS3. Вместе с тем
скоростные режимы работы требуют наличия соответствующих абонентских терминалов
GSM.
Теоретически технология HSCSD позволяет использовать все восемь слотов. В этом
случае пользовательская скорость передачи равна 76,8 (CS2) или 115,2 (CS3)
кбит/с. Однако для реализации этих возможностей необходима доработка некоторых элементов
инфраструктуры, так как скорость обмена данными между базовыми станциями и
центром коммутации MSC в большинстве случаев ограничивается 64 кбит/с
(интерфейс А).
Технология HSCSD допускает асимметричный режим работы, когда для линии связи "вниз" (от
базовой станции к абоненту) выделяется большее количество интервалов, чем для
линии "вверх" (от абонента к базовой станции).Такой механизм отражает
типичный режим роботы мобильных пользователей, которые в основном принимают
данные, а отправляют короткие сообщения в виде запроса.
Внедрение технологий HSCSD в сетях GSM (начиная с 2000 года) обеспечило реализацию
таких услуг, как мобильный доступ к интернету, электронная почта, передача
факсимильных сообщений. Однако использование технологии HSCSD не очень выгодно,
поскольку она основана на концепции коммутации каналов. Это означает, что
тарифицируется не переданное количество информации, а длительность соединения,
включая время установления канала HSCSD и время его использования. Для
организации высокоскоростного канала сеть GSM выделяет определенное число TCH.
Следовательно, для переключения, установки соединения и освобождения каналов
требуется большее количество времени, чем при использовании только одного TCH.
Особенно экономически неоправданна технология HSCSD при осуществлении передачи
небольших по объему потоков данных. В этом случае для выполнения процедур
установления канала требуется достаточно много времени.
Передача данных с
коммутацией пакетов
Технология GPRS
Технология GPRS обеспечивает сквозную (от абонента к абоненту) пакетную
передачу данных на основе IP-протокола. Наличие такой службы особенно
необходимо для интернет-приложений, работа которых основана именно на пакетном
обмене информацией.
Технология GPRS реализует гибкий и эффективный механизм использования сетевых
ресурсов GSM, когда возникает необходимость в частой передаче небольших объемов
информации (запросы пользователей) и в менее частой передаче больших объемов
информации (ответы вэб-сервера) при наличии продолжительных пауз.
Внедрение GPRS не требует кардинальной модернизации инфраструктуры GSM,
поскольку служба передачи GPRS надстраивается над существующей сетью. Передача
пакетов системы GPRS происходит по уже функционирующим каналам базовой сети
GSM, в которой развертывается соответствующее оборудование.
В сети GSM-GPRS изменяется статус мобильного абонента, который теперь может
работать одновременно в двух режимах - телефонного разговора и пакетной
передачи (приема) данных, то есть все службы GPRS используются параллельно с
традиционными службами GSM. Так что развертывание GPRS не влияет на
обслуживание абонентов, которые пользуются только телефонными услугами обычной
сети, работающей на основе базового стандарта GSM.
Технология GPRS позволяет предлагать дополнительные услуги - подключение к
интернету и радиодоступ к локальным
вычислительным сетям по протоколам X.25 и IP.
Системы GPRS первого поколения обеспечивали предоставление пакетных услуг в
соединении "точка-точка" (Point-to-Point - РТР). Есть две версии РТР:
PTP-CONS (CONS - Connection Oriented Network Service) - сетевая служба РТР,
ориентированная на установление логического соединения, и сетевая служба
РТР-CLNS без установления логического соединения (CLNS - Connection Less Network
Service).
Служба РТР-CONS поддерживает приложения, основанные на протоколе Х.25 и TCP/IP. Служба PTP-CLNS ориентирована на
протокол UDP.
В системах GPRS второго поколения реализована многоадресная или многоточечная
пакетная передача PTM (Point-to-Multipoint).
В технологии GPRS, как и в HSCSD, повышение скорости передачи данных
достигается за счет использования многослотового режима. Для образования канала
передачи данных может выделяться от 1 до 8 канальных интервалов в кадре TDM.
Таким образом, скорость передачи данных увеличивается пропорционально
количеству задействованных слотов.
Канальные интервалы распределяются не фиксировано, а управляются запросами
пользователей системы GPRS, то есть распределение канальных интервалов зависит
от текущей загрузки. Оно производится отдельно для исходящих и нисходящих
радиолиний. При этом до 32 абонентов могут по очереди использовать один и тот
же высокоскоростной канал в режиме передачи (приема) с соответствующей
задержкой ожидания.
Профиль качества обслуживания
Стандарт GPRS предусматривает профиль качества обслуживания пользователей,
который определяет следующие четыре показателя качества: уровень приоритетного
обслуживания, класс надежности, класс задержки передачи и пропускную
способность пользовательских каналов.
В системах GPRS используется три уровня приоритетного обслуживания: высокий,
средний и низкий.
В процессе передачи модули данных GPRS (Service Data Unit - SDU) могут
дублироваться или следовать в неправильном порядке. Также может произойти
потеря модулей SDU или передача их в искаженном виде. В стандарте GPRS задаются
значения вероятности возникновения подобных сбоев, в соответствии с которыми
различаются классы надежности. Первый класс надежности целесообразно
использовать в том случае, когда информационная система является весьма
чувствительной к ошибкам и неспособна их исправить собственными силами. Второй
класс подходит системам, более устойчивым к ошибкам. Третий класс можно
использовать, когда в системе задействованы протоколы, нечувствительные к
ошибкам или обеспечивающие их коррекцию.
Процесс пакетного обмена данными характеризуется задержкой передачи. Нормы
значений задержек передачи для разных классов качества обслуживания в стандарте
GPRS предусмотрены для пакетов длиной 128 и 1024 байт. При этом оговаривается
среднее и 95-процентное значения задержек.
Эти значения определяются задержками доступа к каналу в стационарной сети
GSM-GPRS, задержками в радиоканале и задержками, связанными с механизмом
пакетной передачи. Задержки во внешних сетях не учитываются.
Надо отметить, что буферизация пакетов в системе GPRS, в отличие от систем с
промежуточным хранением, практически не приводит к дополнительным задержкам,
так как технология GPRS обеспечивает переадресацию пакетов чрезвычайно быстро.
Все задержки, вне зависимости от класса, в несколько раз превышают
соответствующие значения для стационарных сетей. Этот факт необходимо учитывать
при реализации в сетях GSM-GPRS протоколов высшего уровня, например, протокола
TCP/IP.
Инфраструктура сети
GSM-GPRS
Как уже упоминалось, система GPRS надстраивается над существующей сетью GSM, в
которую необходимо добавить два базовых узла: сервисный узел пакетной передачи
GPRS (Serving GPRS Support Node - SGSN) и шлюзовой узел услуг GPRS (Gateway
GPRS Support Node - GGSN).
Сервисный узел, подключаемый ко всем основным элементам базовой сети GSM (BSS,
MSC, VLR, HLR, EIR), является важнейшим компонентом системы GPRS. Он
обеспечивает обмен IP-трафиком между абонентами GPRS и выполняет все основные
процедуры обслуживания мобильных абонентов.
Любые данные, подлежащие передаче через сеть GPRS, должны закрепляться за
конкретной мобильной станцией (MS). Эта процедура реализуется с помощью
механизмов управления мобильностью. Она (процедура) включает в себя присвоение
временной идентификации логического канала
(Temporary Logical Link Identity - TLLI) и порядкового номера ключа шифрования
(Ciphering Key Sequence Number - CKSN), используемого для кодирования данных. В
каждой MS в сети GPRS устанавливается окружение GPRS, которое сохраняется для
MS и соответствующего узла SGSN. Это окружение содержит информацию о состоянии
мобильной станции. Такая информация необходима для регистрации абонентов при их
переходе в режим GPRS и выходе из него, для включения (активизации) режима
передачи (приема) и выключения этого режима.
Окружение GPRS также содержит данные маршрутизации, необходимые для регистрации
и учета местоположения MS, которая находится в зоне обслуживания конкретного
узла SGSN. К этим данным относятся идентификация TLLI, область маршрутизации
(Rou-ting Area - RA), идентификаторы ячейки и канал
пакетных данных (PDCH).
Процедуры управления мобильностью включают в себя аутентификацию мобильных
абонентов, идентификацию мобильных терминалов и шифрование данных. Стоит
отметить, что в системах GPRS шифрование производится между мобильной станцией и
узлом SGSN, то есть границы шифрования в сетях GSM-GPRS расширены по сравнению
с обычной системой GSM, где шифрование производится только в пределах
радиоинтерфейса.
Обслуживаемая территория сети GPRS разделяется на зоны RA, которые отличаются
от определяемых в базовом GSM-стандарте зон местонахождения (Location Area -
LA). Обычно выбирается меньший размер зоны RA по сравнению с зоной LA.
Зона RA необходима для поиска абонента в сети системы GPRS, причем этот поиск
осуществляет узел SGSN.
Система GPRS надстраивается
над существующей сетью GSM путем установки сервисного узла SGSN и шлюзового
узла GGSN > >
Функционирование
элементов сети
В осуществлении процедур обслуживания, связанных с регистрацией и учетом
расположения всех абонентов, участвуют регистры расположения собственных
абонентов (Home Location Register - HLR) и гостей (Visitor Location Register -
VLR). Каждый абонент в совмещенной сети GSM-GPRS "закрепляется" за
одним или несколькими узлами SGSN с помощью HLR. Узел SGSN взаимодействует с
регистром HLR через интерфейс Gr и может запрашивать сведения об абонентах. Для
управления сигнализацией тех
абонентов, которые могут одновременно работать в двух режимах передачи, то есть
с коммутацией пакетов и каналов, используется специальный интерфейс Gs между
VLR и сервисным узлом SGSN. Сведения об абонентах может также запрашивать узел
GGSN, взаимодействуя с основным регистром положения HLR по интерфейсу Gc.
Если абонент пересекает границы зоны RA, то обновляются данные о его
расположении в регистре VLR и дополнительном регистре GR узла SGSN. Таким
образом, на сетевом уровне узел SGSN выполняет функции, аналогичные тем,
которые обеспечивает центр коммутации и управления MSC совместно с регистром
перемещения (гостевым) VLR в базовой сети с коммутацией каналов.
Исходящий IP-трафик из узла SGSN направляется в подсистему базовой станции
(Base Station System -BSS) через контроллер пакетов PCU (интерфейс GB). Внутри
этой подсистемы трафик перенаправляется на контроллеры базовых станций BSC
(интерфейс A-bis), а дальше - по радиоинтерфейсу Um на мобильные терминалы
абонентов МТ.
В контроллерах BSC базовой сети GSM происходит соединение трафика от центра
коммутации MSC с трафиком от узла SGSN.
Шлюзовой узел GGSN обеспечивает связь сети GSM-GPRS с внешними сетями передачи
данных по протоколам Х.25 и IP, в том числе и подключение к интернет-провайдеру
(ISP). Пакеты данных, поступающие из внешней сети PDN, через узел GGSN
(интерфейс взаимодействия Gi) переправляются в узлы SGSN. Узел GGSN с точки зрения
внешней пакетной сети (Packet Data Network - PDN) воспринимается как некая
" диспетчерская" станция,
владеющая всеми IP-адресами абонентов, которые обслуживаются системой GPRS.
Оборудование узла GGSN обеспечивает динамическое выделение IP-адресов, а также
реализацию функций безопасности и обработки счетов
абонентов. На основе IP-адресации осуществляется взаимодействие узлов SGSN и
GGSN. При этом обмен данными между этими узлами может происходить как по
локальной IP-сети оператора (интерфейс Gn), так и по сетям TCP/IP общего
пользователя (интерфейс Gp).
Первоначальное развертывание системы GSM-GPRS оператор обычно начинает с
реализации небольших сегментов сети. При этом узлы SGSN и GGSN располагаются
рядом и объединяются в один узел поддержки услуг GPRS (GPRS Support Node -
GSN). Здесь взаимодействие элементов осуществляется с использованием интерфейса
Gn.
В случае же разнесенной установки SGSN и GGSN (как правило, при наращивании
системы) связь осуществляется через интерфейс Gp. Интерфейс Gp выполняет все
функции интерфейса Gn и обеспечивает повышенные меры безопасности, которые
необходимы при установлении межсетевых соединений между разными мобильными
сетями (Public Land Mobile Network - PLMN).
Кроме двух базовых узлов (SGSN и GGSN), сеть GPRS включает в себя также центр
услуг широковещательной передачи (Point-to-Multipoint Service Centre - PTM-SC).
Он осуществляет обработку широковещательного трафика между магистральным
каналом сети и регистром положения HLR.
Основным элементом, обеспечивающим предварительную обработку тарификационной
информации для услуг GPRS, является биллинговый шлюз (Billing Gateway - BG).
Механизм тарификации, используемый в GPRS, существенно отличается от того,
который применяется для базовых сетей GSM и технологии высокоскоростной
передачи HSCSD.
В GPRS допускается возможность совместного использования несколькими абонентами
одного канала и предоставления нескольких видов услуг одному абоненту. В любом
случае в GPRS абонент платит не за время занятости канала, а только за объем
переданной (принятой) информации, качество обслуживания и срочность доставки.
При этом GPRS-тарифы гибко дифференцированы в зависимости от потоков переданной
информации и снижаются по мере увеличения суммарного объема используемого
трафика.
Терминалы GPRS
Для работы в сетях GSM-GPRS стандартом определены три класса мобильных
радиотерминалов.
Терминалы класса А представляют полный спектр услуг, поскольку они могут
одновременно работать в базовой сети с коммутацией каналов GSM и в пакетной
сети GPRS. Таким образом, эти терминалы обеспечивают возможность принимать и
посылать вызовы и сообщения через MSC (голос и данные) и в то же время
параллельно обмениваться данными через SGSN.
Терминалы класса В также могут работать в двух режимах, однако параллельная
работа невозможна. В определенный момент времени обеспечивается передача или
прием только одного вида трафика. Например, чтобы принять вызов, поступающий в
ходе активной сессии в интернете, абонент вынужден прервать работу с данными.
Терминалы класса С обеспечивают возможность работы либо в сети GSM, либо в сети
GPRS. При этом, если абонент находится в каком-то одном режиме, он не сможет
принять входящие вызовы или сигналы из другой сети, то есть такие терминалы
обеспечивают только возможность выбора режима работы. К классу С также часто
относят радиотерминалы, которые могут функционировать только в режиме пакетной
передачи.
Мобильная станция в зависимости от конкретных потребностей абонента может
представлять собой различные варианты реализации терминальных решений.
В частности, комбинированные терминалы объединяют в одно законченное
функциональное устройство мобильный терминал (МТ) и терминальное оборудование
(ТЕ). Такие малогабаритные мобильные станции (попросту телефоны) имеют, как
правило, ограниченные возможности передачи и приема данных. Чтобы расширить эти
возможности, нужно подключить ряд дополнительных оконечных устройств.
Реализация варианта использования мобильного телефона с компьютером требует
оснащения компьютера специализированным программным обеспечением, а телефон
должен поддерживать коммуникационный протокол. Соединение компьютера с
мобильным телефоном также возможно с помощью инфракрасного порта.
Вместо мобильного телефона к компьютеру можно подключить специальную
радиокарту, выполняющую функции МТ.
Есть также специальные терминалы, предназначенные только для передачи данных от
различных источников информации (видеокамеры, микрофоны, всевозможные датчики и др.). Такие мобильные станции
могут использоваться только для контроля и мониторинга.
Переход на пакетные
решения стал важнейшим этапом эволюции технологий передачи данных в GSM >
>
Усовершенствованная
передача данных
Технология высокоскоростного радиодоступа EDGE была предложена еще в начале
1997 года и послужила основой развития стандарта GSM.
На первом этапе (так называемая "фаза 1") технология позволила
увеличить скорость передачи до 384 кбит/с на одну несущую сети GSM. Для новых
поколений пико- и микросотовых систем на втором этапе ("фаза 2")
предполагается обеспечить скорость передачи до 2048 кбит/с. В дальнейшем на
основе этой технологии планируют осуществить плавный переход от доминирующих в
настоящее время мобильных сетей с коммутацией каналов к сетям, которые обладают
преимуществами сетей с коммутацией пакетов, причем это касается как трафика
передачи данных, так и речевого трафика. Таким образом, появится возможность
продлить использование уже установленного оборудования GSM вплоть до внедрения
мобильных систем третьего поколения.
Радиоинтерфейс технологии EDGE надстраивается над существующей системой GSM и
совместим со всеми службами GSM, в том числе с технологиями HSCSD и GPRS.
Внедрение EDGE не требует создания новых сетевых (структурных) элементов.
Технология EDGE пригодна для использования в сетях GSM, работающих в диапазонах
400, 900 и 1800 МГц.
Радиоинтерфейс EDGE основан на использовании спектрально эффективной модуляции
и адаптивной настройки канала в зависимости от требований абонента и реальных
условий связи в точке нахождения абонента. При этом производится автоматическое
распознавание типа модуляции, используемого в радиолинии, с последующим
переходом к наиболее приемлемой схеме помехоустойчивого кодирования.
На основе технологии EDGE могут быть организованы две усовершенствованные
службы передачи данных: служба пакетной передачи EGPRS (Enhanced GPRS) и служба
передачи с коммутацией каналов ECSD(Enhanced CSD). По сравнению с базовым GSM
максимальная скорость передачи на один физический канал увеличивается до 38,4
кбит/с для ECSD и до 69,2 кбит/с для EGPRS.
В технологии EDGE, в свою очередь, применяется два метода модуляции:
GMSK-модуляция, используемая в базовом стандарте GSM, и 8-позиционная фазовая
модуляция (8 PSK). При этом скорость передачи символов в радиоканале одинакова
и соответствует полосе пропускания одного частотного канала - 200 кГц.
В технологии EDGE применено шесть уровней помехоустойчивого кодирования - от
PS1 до PS6, обеспечивающих различную степень помехозащиты. Увеличение скорости
передачи данных (как и в технологиях HSCSD и GPRS) достигается за счет
использования нескольких слотов для передачи и приема. При объединении всех
восьми слотов скорость передачи на одну несущую теоретически может быть
увеличена до 553,6 кбит/с (69,2Х8).
Предполагается автоматическое распознавание типа модуляции и адаптивная смена
режима кодирования. Смена схемы кодирования производится каждый раз, когда
предыдущий декодируемый блок принимается с достоверностью ниже установленного
порога. В результате следующий блок данных уже передается с использованием
схемы кодирования, обладающей более высокой помехозащищенностью.
Абонентские терминалы, предоставляющие услуги EDGE, можно разделить на два
типа. В первом, более простом и дешевом терминале, обеспечивается режим
модуляции 8 PSK в линии "вниз" и GMSK в линии "вверх".
Использование высокоскоростной передачи в прямом канале и низкоскоростного
режима в обратном канале соответствует типичной ситуации обмена данными в сетях
пакетной передачи. Радиотерминалы второго типа способны обеспечить в двух
направлениях любой из двух режимов модуляции (8 PSK и GMSK).
Особенности применения
технологий
Одним из основных преимуществ передачи данных в сетях GSM является то, что
каждая технология может найти свое применение, ведь все они уже доступны на
Украине.
Так, технология CSD может оказаться вполне подходящим вариантом при
необходимости непрерывной передачи данных в реальном времени на скорости не
больше 9,6 кбит/с. Кроме того, эта технология совместима со всеми аналоговыми и
цифровыми протоколами передачи данных и ее поддерживает абсолютное большинство
современных мобильных терминалов GSM.
Применение технологии HSCSD оправдано в том случае, когда необходимо непрерывно
передавать массивы данных большого объема в реальном времени.
Пакетные технологии передачи данных в GSM позволяют обеспечить полноценную
интеграцию интернета и мобильных сетей. В дополнение к традиционным
интернет-приложениям эти технологии позволяют разворачивать полнофункциональные
специализированные решения, требующие удаленного доступа. При этом подобные
решения сочетаются с преимуществами радиоинтерфейса.
Мост (bridge) – ретрансляционная система, соединяющая каналы передачи данных.
Рис. 9.1 Структура моста
В соответствии с базовой эталонной моделью взаимодействия открытых систем
мост описывается протоколами физического и канального уровней, над которыми
располагаются канальные процессы. Мост опирается на пару связываемых им
физических средств соединения, которые в этой модели представляют физические
каналы. Мост преобразует физический (1A, 1B) и канальный (2A, 2B) уровни
различных типов (рис. 9.4). Что касается канального процесса, то он
объединяет разнотипные каналы передачи данных в один общий.
Мост (bridge), а также его быстродействующий аналог – коммутатор
(switching hub), делят общую среду передачи данных на логические сегменты.
Логический сегмент образуется путем объединения нескольких физических сегментов
(отрезков кабеля) с помощью одного или нескольких концентраторов. Каждый
логический сегмент подключается к отдельному порту моста/коммутатора. При
поступлении кадра на какой-либо из портов мост/коммутатор повторяет этот кадр,
но не на всех портах, как это делает концентратор, а только на том порту, к
которому подключен сегмент, содержащий компьютер-адресат.
Мосты могут соединять сегменты, использующие разные типы носителей, например
10BaseT (витая пара) и 10Base2 (тонкий коаксиальный кабель). Они могут
соединять сети с разными методами доступа к каналу, например сети Ethernet
(метод доступа CSMA/CD) и Token Ring (метод доступа TPMA).
Разница между мостом и коммутатором состоит в том, что мост в каждый момент
времени может осуществлять передачу кадров только между одной парой портов, а
коммутатор одновременно поддерживает потоки данных между всеми своими
портами. Другими словами, мост передает кадры последовательно, а коммутатор
параллельно.
Мосты используются только для связи локальных сетей с глобальными, то есть
как средства удаленного доступа, поскольку в этом случае необходимость в
параллельной передаче между несколькими парами портов просто не возникает.
Рис. 9.1 Соединение двух сетей при помощи двух каналов
Когда появились первые устройства, позволяющие разъединять сеть на несколько
доменов коллизий (по сути фрагменты ЛВС, построенные на hub-ах), они были
двух портовыми и получили название мостов (bridge-ей). По мере развития
данного типа оборудования, они стали многопортовыми и получили название
коммутаторов (switch-ей). Некоторое время оба понятия существовали
одновременно, а позднее вместо термина «мост» стали применять «коммутатор».
Далее в этой теме будет использоваться термин «коммутатор» для обозначения
этих обеих разновидностей устройств, поскольку все сказанное ниже в равной
степени относится и к мостам, и к коммутаторам. Следует отметить, что в
последнее время локальные мосты полностью вытеснены коммутаторами.
Нередки случаи, когда необходимо соединить локальные сети, в которых различаются
лишь протоколы физического и канального уровней. Протоколы остальных уровней в
этих сетях приняты одинаковыми. Такие сети могут быть соединены мостом. Часто
мосты наделяются дополнительными функциями. Такие мосты обладают определенным
интеллектом (интеллектом в сетях называют действия, выполняемые
устройствами) и фильтруют сквозь себя блоки данных, адресованные абонентским
системам, расположенным в той же сети. Для этого в памяти каждого моста имеются
адреса систем, включенных в каждую из сетей. Блоки, проходящие через
интеллектуальный мост, дважды проверяются, на входе и выходе. Это позволяет
предотвращать появление ошибок внутри моста.
Мосты не имеют механизмов управления потоками блоков данных. Поэтому может
оказаться, что входной поток блоков окажется большим, чем выходной. В этом
случае мост не справится с обработкой входного потока, и его буферы могут
переполняться. Чтобы этого не произошло, избыточные блоки выбрасываются.
Специфические функции выполняет мост в радиосети. Здесь он обеспечивает
взаимодействие двух радиоканалов, работающих на разных частотах. Его именуют
ретранслятором.
Мосты (bridges) оперируют данными на высоком уровне и имеют совершенно
определенное назначение. Во-первых, они предназначены для соединения сетевых
сегментов, имеющих различные физические среды, например для соединения
сегмента с оптоволоконным кабелем и сегмента с коаксиальным кабелем. Мосты
также могут быть использованы для связи сегментов, имеющих различные
протоколы низкого уровня (физического и канального).
Коммутатор (switch) – устройство, осуществляющее выбор одного из
возможных вариантов направления передачи данных.
Рис. 9.1 Внешний вид коммутатора Switch 2000
В коммуникационной сети коммутатор является ретрансляционной системой
(система, предназначенная для передачи данных или преобразования протоколов),
обладающей свойством прозрачности (т.е. коммутация осуществляется здесь без
какой-либо обработки данных). Коммутатор не имеет буферов и не может
накапливать данные. Поэтому при использовании коммутатора скорости передачи
сигналов в соединяемых каналах передачи данных должны быть одинаковыми.
Канальные процессы, реализуемые коммутатором, выполняются специальными
интегральными схемами. В отличие от других видов ретрансляционных систем,
здесь, как правило, не используется программное обеспечение.
Рис. 9.2 Структура коммутатора
Вначале коммутаторы использовались лишь в территориальных сетях. Затем они
появились и в локальных сетях, например, частные учрежденческие коммутаторы.
Позже появились коммутируемые локальные сети. Их ядром стали коммутаторы
локальных сетей.
Коммутатор (Switch) может соединять серверы в кластер и служить основой для
объединения нескольких рабочих групп. Он направляет пакеты данных между
узлами ЛВС. Каждый коммутируемый сегмент получает доступ к каналу передачи
данных без конкуренции и видит только тот трафик, который направляется в его
сегмент. Коммутатор должен предоставлять каждому порту возможность соединения
с максимальной скоростью без конкуренции со стороны других портов (в отличие
от совместно используемого концентратора). Обычно в коммутаторах имеются один
или два высокоскоростных порта, а также хорошие инструментальные средства
управления. Коммутатором можно заменить маршрутизатор, дополнить им
наращиваемый маршрутизатор или использовать коммутатор в качестве основы для
соединения нескольких концентраторов. Коммутатор может служить отличным
устройством для направления трафика между концентраторами ЛВС рабочей группы
и загруженными файл-серверами.
Коммутатор локальной сети (local-area network switch) – устройство,
обеспечивающее взаимодействие сегментов одной либо группы локальных сетей.
Коммутатор локальной сети, как и обычный коммутатор, обеспечивает
взаимодействие подключенных к нему локальных сетей (рис.9.8). Но в дополнение
к этому он осуществляет преобразование интерфейсов, если соединяются
различные типы сегментов локальной сети. Чаще всего это сети Ethernet,
кольцевые сети IBM, сети с оптоволоконным распределенным интерфейсом данных.
Рис. 9.1 Схема подключения локальных сетей к коммутаторам
В перечень функций, выполняемых коммутатором локальной сети, входят:
- обеспечение сквозной коммутации;
- наличие средств маршрутизации;
- поддержка простого протокола управления сетью;
- имитация моста либо маршрутизатора;
- организация виртуальных сетей;
- скоростная ретрансляция блоков данных.
Маршрутизатор (router) – ретрансляционная система, соединяющая две
коммуникационные сети либо их части.
Каждый маршрутизатор реализует протоколы физического (1А, 1B),
канального (2А, 2B) и сетевого (3A, 3B) уровней, как показано на
рис.9.9. Специальные сетевые процессы соединяют части коммутатора в единое
целое. Физический, канальный и сетевой протоколы в разных сетях различны.
Поэтому соединение пар коммуникационных сетей осуществляется через
маршрутизаторы, которые осуществляют необходимое преобразование указанных
протоколов. Сетевые процессы выполняют взаимодействие соединяемых сетей.
Маршрутизатор работает с несколькими каналами, направляя в какой-нибудь из
них очередной блок данных.
Маршрутизаторы обмениваются информацией об изменениях структуры сетей,
трафике и их состоянии. Благодаря этому, выбирается оптимальный маршрут
следования блока данных в разных сетях от абонентской системы-отправителя к
системе-получателю. Маршрутизаторы обеспечивают также соединение
административно независимых коммуникационных сетей.
Рис. 9.1 Структура маршрутизатора
Архитектура маршрутизатора также используется при создании узла коммутации
пакетов.
Маршрутизаторы превосходят мосты своей способностью фильтровать и направлять
пакеты данных на сети. Так как маршрутизаторы работают на сетевом уровне, они
могут соединять сети, использующие разную сетевую архитектуру, методы доступа
к каналам связи и протоколы.
Маршрутизаторы не обладают такой способностью к анализу сообщений как мосты,
но зато могут принимать решение о выборе оптимального пути для данных между
двумя сетевыми сегментами.
Мосты принимают решение по поводу адресации каждого из поступивших пакетов
данных, переправлять его через мост или нет в зависимости от адреса
назначения. Маршрутизаторы же выбирают из таблицы маршрутов наилучший для
данного пакета.
В поле зрения маршрутизаторов находятся только пакеты, адресованные к ним
предыдущими маршрутизаторами, в то время как мосты должны обрабатывать все
пакеты сообщений в сегменте сети, к которому они подключены.
Тип топологии или протокола уровня доступа к сети не имеет значения для
маршрутизаторов, так как они работают на уровень выше, чем мосты (сетевой
уровень модели OSI). Маршрутизаторы часто используются для связи между
сегментами с одинаковыми протоколами высокого уровня. Наиболее
распространенным транспортным протоколом, который используют маршрутизаторы,
является IPX фирмы Novell или TCP фирмы Microsoft.
Необходимо запомнить, что для работы маршрутизаторов требуется один и тот же
протокол во всех сегментах, с которыми он связан. При связывании сетей с
различными протоколами лучше использовать мосты. Для управления
загруженностью трафика сегмента сети также можно использовать мосты.
Шлюз (gateway) – ретрансляционная система, обеспечивающая взаимодействие
информационных сетей.
Рис. 9.1 Структура шлюза
Шлюз является наиболее сложной ретрансляционной системой, обеспечивающей
взаимодействие сетей с различными наборами протоколов всех семи уровней. В
свою очередь, наборы протоколов могут опираться на различные типы физических
средств соединения.
В тех случаях, когда соединяются информационные сети, то в них часть уровней
может иметь одни и те же протоколы. Тогда сети соединяются не при помощи
шлюза, а на основе более простых ретрансляционных систем, именуемых
маршрутизаторами и мостами.
Шлюзы оперируют на верхних уровнях модели OSI (сеансовом, представительском и
прикладном) и представляют наиболее развитый метод подсоединения сетевых
сегментов и компьютерных сетей. Необходимость в сетевых шлюзах возникает при
объединении двух систем, имеющих различную архитектуру. Например, шлюз
приходится использовать для соединения сети с протоколом TCP/IP и большой ЭВМ
со стандартом SNA. Эти две архитектуры не имеют ничего общего, и потому
требуется полностью переводить весь поток данных, проходящих между двумя
системами.
В качестве шлюза обычно используется выделенный компьютер, на котором
запущено программное обеспечение шлюза и производятся преобразования,
позволяющие взаимодействовать нескольким системам в сети. Другой функцией
шлюзов является преобразование протоколов. При получении сообщения IPX/SPX
для клиента TCP/IP шлюз преобразует сообщения в протокол TCP/IP.
Шлюзы сложны в установке и настройке. Шлюзы работают медленнее, чем
маршрутизаторы.
Во всех предыдущих разделах сам механизм управления маршрутами, порождения пакетов посети старательно обходился стороной, т.к. это предмет особого разговора. Программы управления маршрутами довольно сложны, а функции, которые они выполняют, являются критичными для всей системы в целом.
Основывается система маршрутизации на таблице маршрутов, которая определяет куда пакет с данным IP-адресом следует направлять. Ниже приведен пример такой таблицы, полученный при помощи команды netstat.
Пример 2.1. Таблица маршрутов
quest:/usr/src/sys/i386/conf:\[16\]>netstat -rnRouting tablesDestination Gateway Flags Refs Use IfaceMTU RttNetmasks:(root node)(0) 0000 ff00(0) 0000 ffff e000(root node)Route Tree for Protocol Family inet:(root node) =>default 144.206.136.12 UG 1 1081 ed1 - -127 127.0.0.1 UR 0 0 lo0 - -127.0.0.1 127.0.0.1 UH 0 51 lo0 - -144.206 144.206.131.5 UG 0 0 ed1 - -144.206.64 144.206.136.230 UG 0 0 ed1 - -144.206.96 144.206.130.135 UG 0 0 ed1 - -144.206.128 144.206.130.138 U 2 9900 ed1 - -144.206.192 144.206.192.1 U 2 26203 ed0 - -194.226.56 144.206.130.207 UGD 0 0 ed1 - -(root node)quest:/usr/src/sys/i386/conf:\[17\]>
В данном примере в левой колонке указаны адреса возможных IP-адресов, которые система принимает из сети, далее идет адрес шлюза для данных адресов, затем флаги маршрутизации, степень использования данного маршрута и интерфейс, на котором данный маршрут обслуживается.
Однако, наша таблица не дает ответа на степень изменчивости данной таблицы. Для этого нам придется снова вернуться к изучению протоколов, но только теперь уже протоколов маршрутизации.
2.9.1. Статическая маршрутизация
В принципе, возможна работа без применения вообще каких-либо протоколов маршрутизации. В этом случае маршрутизацию называют статической. Таблица маршрутов в этом случае строится при помощи команд ifconfig, которые вписывают строки, отвечающие за рассылку сообщений в локальной сети, и команды route, которая используется для внесения изменений вручную.
Вообще говоря, из всей статической маршрутизации выделяют, так называемую, минимальную маршрутизацию. Такая маршрутизация возникает тогда, когда локальная сеть не имеет выхода в Internet и не состоит из подсетей. В этом случае достаточно выполнить команды ifconfig для интерфейса lo и интерфейса Ethernet и все будет работать:
/usr/paul>ifconfig lo inet 127.0.0.1/usr/paul>ifconfig ed1 inet 144.226.43.1 netmask 255.255.255.0
В таблице маршрутов появятся только эти две строки, но так как сеть ограничена, и пакеты не надо отправлять в другие сети, то модуль ARP будет прекрасно справляться с доставкой пакетов по сети.
Если же сеть подключена к Internet, то в таблицу маршрутов надо ввести, по крайней мере, еще одну строку - адрес шлюза. Делается это при помощи команды route.
Команда route имеет следующий вид:
route <команда> <сеть или хост> <шлюз> <метрика>
В поле "команда" указывается команда работы с таблицей маршрутов:
В поле "сеть или хост" указывается адрес отправки пакета.
В поле "шлюз" указывается IP-адрес, через который следует отправлять пакеты, предназначенные хосту или сети из предыдущего поля.
Поле "метрика" определяет расстояние в числе шлюзов, которые данный пакет пройдет, если его направить по данному маршруту.
Типичным примером применения команды route является назначение шлюза по умолчанию:
/usr/paul>route add default 144.206.160.32
В данном примере все пакеты, адресаты которых не были найдены в локальной сети, отправляются на сетевой интерфейс с адресом 144.206.160.32. Метрика при этом принимается по умолчанию равная 1. Таким образом указывается, что это адрес шлюза.
Для того, чтобы получить таблицу маршрутов, приведенную в примере 2.1, нужно выполнить следующие команды:
/usr/paul>route add 144.206.0.0 144.206.136.5 netmask 255.255.224.0/usr/paul>route add 144.206.96.0 144.206.130.135 netmask 255.255.224.0/usr/paul>route add 144.206.128 144.206.130.138 netmask 255.255.224.0/usr/paul>route add 144.206.192.0 144.206.192.1 netmask 255.255.224.0
Если сравнить эти записи с примером 2.1, то можно заметить, что одной строчки в списке команд не хватает. Это строка, которая описывает маршрут к сети 194.226.56 через шлюз 144.206.130.207. Дело в том, что поле флагов отчета netstat говорит нам, что такого маршрута в первоначальной таблице не было.
В поле флагов отчета netstat мы можем встретить следующие флаги:
U - говорит о том, что маршрут активен и может использоваться для маршрутизации пакетов;
H - говорит о том, что этот маршрут используется для посылки пакетов определенному в маршруте хосту;
G - говорит о том, что пакеты направляются на шлюз, который ведет к адресату;
D - этот флаг определяет тот факт, что данный маршрут был добавлен в таблицу по той причине, что с одного из шлюзов пришел ICMP-пакет, указывающий адрес правильного шлюза, который в нашей таблице отсутствовал.
Строчка, которая описывает не указанный в командах маршрут в таблице маршрутов выглядит следующим образом:
Destination Gateway Flags Refs Use IfaceMTU Rtt194.226.56 144.206.130.207 UGD 0 0 ed1 - -
Поле флагов содержит флаги: U-маршрут активен, G-пакеты направляются на шлюз и D-маршрут получен по сообщению ICMP о перенаправлении пакетов. Следовательно, первоначально такого маршрута в таблице маршрутов не было.
Если пользователи системы часто ходят в сеть 194.226.56.0, то в таблицу такой маршрут следует добавить:
/usr/paul>route add 194.226.56.0 144.206.130.207 netmask 255.255.224.0
При помощи команды route можно не только добавлять маршруты в таблицу маршрутов, но и удалять их от туда. Делается это по команде delete. Например, если нам надо изменить значение шлюза по умолчанию, то мы можем выполнить следующую последовательность команд:
/usr/paul>route delete default/usr/paul/route add default 144.206.136.10 netmask 255.255.224.0
В данном случае сначала мы удалим из таблицы (пример 2.1) маршрут умолчания, а затем добавим туда новый. При удалении маршрута достаточно назвать только адрес назначения, чтобы route идентифицировала маршрут, который следует удалить.
Можно по команде route получить информацию и о конкретном маршруте, но удобнее все-таки пользоваться командой netstat. В последней и информации указывается больше, и можно получить такую информацию, о которой вы просто можете даже не подозревать, если приходят ICMP-сообщения или используется динамическая маршрутизация.
В заключении обсуждения вопросов статической маршрутизации хотелось бы сделать небольшое замечание по поводу Windows NT. До версии 4.0 в Windows NT штатно существовала только статическая маршрутизация. Для сетей локальных с надежными линиями связи этого вполне достаточно. Фактически, администратору нужно только указать IP-адреса на каждом из сетевых интерфесов, указать адрес шлюза по умолчанию и поднять флажок пересылки пакетов с одного интерфейса на другой. После этого все должно работать. Если локальная сеть подключается к провайдеру, то, как правило, все сводится к получению адреса из сети провайдера для внешнего интерфейса, т.е. интерфейса, который будет связывать вас с адресом шлюза провайдера и адресом своей сети или подсети. Если только провайдер не затеет изменения структуры своей сети, вес будет работать годами без каких-либо изменений. Для таких сетей шлюз на основе Windows NT можно организовать. Однако, не все так просто, когда речь идет о сети или подсети, которые подключаются в качестве части сети, которая не организована по иерархическому принципу. В этом случае возможно изменение наилучших маршрутов гораздо чаще, чем один раз в десятилетие и в этом случае статическая маршрутизация может оказаться недостаточной. Кроме того, важным фактором повышения надежности сетевого взаимодействия является наличие нескольких маршрутов к одним и тем же информационным ресурсам. В случае отказа одного из них можно использовать другие. Но проблема заключается в том, что система всегда использует тот маршрут, который первым встретился в таблице маршрутов, хотя и существуют мультимаршрутные системы, но они распространены, мягко говоря не очень широко. Следовательно, маршруты из таблицы надо удалять и вносить. Если сеть работает не устойчиво, то это превращается в головную боль администратора. Вот почему до версии Windows NT 4.0 рассматривать эту систему в качестве реального претендента на маршрутизатор не представляется возможным. В Windows NT 4.0 появилась поддержка динамической маршрутизации в лице протокола RIP, но поддержки других протоколов маршрутизации пока еще нет.
Таким образом, мы подошли к проблеме автоматического управления таблицей маршрутов на основе информации, получаемой из сети. Такая процедура называется динамической маршрутизацией.
2.9.2. Динамическая маршрутизация
Прежде чем вникать в подробности и особенности динамической маршрутизации обратим внимание на двухуровневую модель, в рамках которой рассматривается все множество машин Internet. В рамках этой модели весь Internet рассматривают как множество автономных систем (autonomous system - AS). Автономная система - это множество компьютеров, которые образуют довольно плотное сообщество, где существует множество маршрутов между двумя компьютерами, принадлежащими этому сообществу. В рамках этого сообщества можно говорить об оптимизации маршрутов с целью достижения максимальной скорости передачи информации. В противоположность этому плотному конгломерату, автономные системы связаны между собой не так тесно как компьютеры внутри автономной системы. При этом и выбор маршрута из одной автономной системы может основываться не на скорости обмена информацией, а надежности, безотказности и т.п.
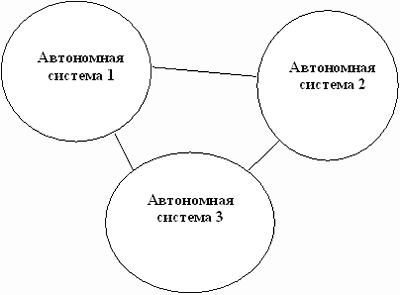
Рис. 2.24. Схема взаимодействия автономных систем
Сама идеология автономных систем возникла в тот период, когда ARPANET представляла иерархическую систему. В то время было ядро системы, к которому подключались внешние автономные системы. Информация из одной автономной системы в другую могла попасть только через маршрутизаторы ядра. Такая структура до сих пор сохраняется в MILNET.
На рисунке 2.24 автономные системы связаны только одной линией связи, что больше соответствует тому, как российский сектор подключен к Internet. В классических публикациях по Internet взаимодействие автономных частей чаще обозначают пересекающимися кругами, подчеркивая тот факт, что маршрутов из одной автономной системы в другую может быть несколько.
Обсуждение этой модели Internet необходимо только для того, чтобы объяснить наличие двух типов протоколов динамической маршрутизации: внешних и внутренних.
Внешние протоколы служат для обмена информацией о маршрутах между автономными системами.
Внутренние протоколы служат для обмена информацией о маршрутах внутри автономной системы.
В реальной практике построения локальных сетей, корпоративных сетей и их подключения к провайдерам нужно знать, главным образом, только внутренние протоколы динамической маршрутизации. Внешние протоколы динамической маршрутизации необходимы только тогда, когда следует построить закрытую большую систему, которая с внешним миром будет соединена только небольшим числом защищенных каналов данных.
К внешним протоколам относятся Exterior Gateway Protocol (EGP) и <="" i="">.
EGP предназначен для анонсирования сетей, которые доступны для автономных систем за пределами данной автономной системы. По данному протоколу шлюз одной AS передает шлюзу другой AS информацию о сетях из которых состоит его AS. EGP не используется для оптимизации маршрутов. Считается, что этим должны заниматься протоколы внутренней маршрутизации.
BGP - это другой протокол внешней маршрутизации, который появился позже EGP. В своих сообщениях он уже позволяет указать различные веса для маршрутов, и, таким образом, способствовать выбору наилучшего маршрута. Однако, назначение этих весов не определяется какими-то независимыми факторами типа времени доступа к ресурсу или числом шлюзов на пути к ресурсу. Предпочтения устанавливаются администратором и потому иногда такую маршрутизацию называют политической маршрутизацией, подразумевая, что она отражает техническую политику администрации данной автономной системы при доступе из других автономных систем к ее информационным ресурсам. Протокол BGP используют практически все российские крупные IP-провайдеры, например крупные узлы сети Relcom.
К внутренним протоколам относятся протоколы Routing Information Protocol (RIP), HELLO, Intermediate System to Intermediate System (ISIS), Shortest Path First (SPF) и Open Shortest Path First (OSPF).
Протокол RIP (Routing Information Protocol) предназначен для автоматического обновления таблицы маршрутов. При этом используется информация о состоянии сети, которая рассылается маршрутизаторами (routers). В соответствии с протоколом RIP любая машина может быть маршрутизатором. При этом, все маршрутизаторы делятся на активные и пассивные. Активные маршрутизаторы сообщают о маршрутах, которые они поддерживают в сети. Пассивные маршрутизаторы читают эти широковещательные сообщения и исправляют свои таблицы маршрутов, но сами при этом информации в сеть не предоставляют. Обычно в качестве активных маршрутизаторов выступают шлюзы, а в качестве пассивных - обычные машины (hosts).
В основу алгоритма маршрутизации по протоколу RIP положена простая идея: чем больше шлюзов надо пройти пакету, тем больше времени требуется для прохождения маршрута. При обмене сообщениями маршрутизаторы сообщают в сеть IP-номер сети и число "прыжков" (hops), которое надо совершить, пользуясь данным маршрутом. Надо сразу заметить, что такой алгоритм справедлив только для сетей, которые имеют одинаковую скорость передачи по любому сегменту сети. Часто в реальной жизни оказывается, что гораздо выгоднее воспользоваться оптоволокном с 3-мя шлюзами, чем одним медленным коммутируемым телефонным каналом.
Другая идея, которая призвана решить проблемы RIP, - это учет не числа hop'ов, а учет времени отклика. На этом принципе построен, например, протокол OSPF. Кроме этого OSPF реализует еще и идею лавинной маршрутизации. В RIP каждый маршрутизатор обменивается информацией только с соседями. В результате, информации о потере маршрута в сети, отстоящей на несколько hop'ов от локальной сети, будет получена с опозданием. Лавинная маршрутизация позволяет решить эту проблему за счет оповещения всех известных шлюзов об изменениях локального участка сети.
К сожалению, многовариантную маршрутизацию поддерживает не очень много систем. Различные клоны Unix и NT, главным образом ориентированы на протокол RIP. Достаточно посмотреть на программное обеспечение динамической маршрутизации, чтобы убедится в этом. Программа routed поддерживает только RIP, программа gated поддерживает RIP, HELLO, OSPF, EGP и BGP, в Windows NT поддерживается только RIP.
Поэтому мы рассмотрим возможность динамического управления таблицей маршрутов только по протоколу RIP.
2.9.3. Программа routed
Программа routed поставляется с любым клоном Unix и используется в качестве демона протокола RIP по умолчанию. Как правило, она используется без аргументов и запускается в момент загрузки операционной системы. Однако, если машина не является шлюзом, то имеет смысл указать флаг "-q". Этот флаг означает, что routed не будет посылать информации в сеть, а только будет слушать информацию от других машин. Обычно, активными являются шлюзы, а все остальные системы являются пассивными.
Однако, часто бывает полезно при начальной загрузке инициализировать таблицу маршрутов и определить строки, которые из нее не следует удалять ни при каких условиях. Самый типичный случай - назначение шлюза по умолчанию. Для этой цели можно использовать файл /etc/gateways, который программа routed просматривает при запуске и использует для первоначальной настройки таблицы маршрутов. Содержание этого файла может выглядеть следующим образом:
net 0.0.0.0 gateway 144.206.136.10 netric 1 passive
В данном примере адрес 0.0.0.0 используется для определения адреса умолчания, машина 144.206.136.10 - это шлюз по умолчанию, метрика определяет число hop'ов до этого шлюза, а параметр "passive" - говорит о том, что даже если с этого шлюза никакой информации о маршрутах не приходит, то его все равно не надо удалять из таблицы маршрутов. Последний параметр указывается в том случае, если шлюз только один, если же возможно использование другого шлюза и эти шлюзы активно извещают машины сети о своих таблицах маршрутов, то следует вместо passive использовать active:
net 0.0.0.0 gateway 144.206.136.10 netric 1 active
В этом случае пассивный шлюз из таблицы маршрутов будет удален, а тот, который может исполнять функции реального шлюза будет в таблицу включен. В сети kiae изменение шлюза по умолчанию можно наблюдать по несколько раз в день.
Когда используется только Ethernet, то программа routed может использоваться и на машинах шлюзах, но если система связана с внешним миром через SLIP или PPP, то использование routed может привести к потере самого главного маршрута. Он будет удален из таблицы из соображений неактивности. В этом случае лучше всего использовать программу gated.
2.9.4. Программа gated
Gated - это коллективный продукт американских университетов, который был разработан для работы сети NFSNET. Права copyright закреплены за Корнельским университетом, хотя части кода являются собственностью других университетов и ассоциаций.
Gated - это модульная программа предназначенная организации много функционального шлюза, который мог бы обслуживать как внутреннюю маршрутизацию, так и внешнюю. Gated поддерживает протоколы RIP (версии 1 и 2), HELLO, OSPF версии 2, EGP версии 2 и BGP версий от 2 до 4. Все перечисленные возможности относятся к версии 3.5. На системах типа HPUX 9.x или IRIX 6.x могут стоять и более ранние версии, которые всего этого набора протоколов могут и не поддерживать.
Рассмотрим два основных примера использования gated в локальной сети: вместо routed на обычной машине и на машине-шлюзе в другую сеть. При этом будем опираться на следующую схему, изображенную на рисунке 2.25.
Рис. 2.25. Подключение локальной сети к Internet и настройки gated
Gated настраивается при помощи своего файла конфигурации /etc/gated.conf. Именно в нем пишутся все команды настройки, которые gated проверяет при запуске.
При работе на обычной машине, системе надо только указать интерфейс и протокол динамической маршрутизации, который gated должна использовать:
## Interface shouldn`t be removed from routing table#interface 144.206.160.40 passive ;## routing protocol is rip.#
rip yes;
В большинстве случаев достаточно просто указать протокол, т.к. интерфейс попадет в таблицу маршрутизации после выполнения команды ifconfig.
Теперь обратимся к настройкам gated на машине-шлюзе. В принципе, можно также обойтись одним указанием на протокол RIP и все будет работать. Если же надо сохранять маршруты через интерфейсы в таблице маршрутов, то следует указать в файле конфигурации оба интерфеса:
# Interfaces shouldn`t be removed from routing tableinterface 144.206.160.32 passive ;interface 144.206.130.137 passive ;# routing protocol is rip.rip yes;
Однако можно использовать и более сложное описание, основанное на логике работы gated. А логика эта состоит в том , что gated объявляет соседним шлюзам по RIP, что подсеть 144.206.160.0 доступна через интерфейс 144.206.130.137, в свою очередь для подсети gated объявляет, что весь мир доступен через интерфейс 144.206.160.32. Очевидно, что это логика заимствована из архитектуры внешних протоколов маршрутизации и распространена на протоколы внутренние. Это позволяет вести описание маршрутов в едином ключе.
rip yes;
export proto rip interface 144.206.130.137{ proto direct { announce 144.206.160.0 metric 0 ; } ;} ;export proto rip interface 144.206.160.32{ proto rip interface 144.206.130.137 { announce all ; } ;} ;
Первая команда export анонсирует подсеть 144.206.160.0 через интерфейс 144.206.130.137. При этом сообщается, что это шлюз в данную подсеть, т.е. интерфейс 144.206.130.137 расположен на машине, которая включена в эту подсеть. О том, что пакеты для подсети надо посылать непосредственно на этот интерфейс говорит предложение proto direct, а то, что интерфейс стоит на шлюзе в подсеть говорит метрика, равная 0.
Второе предложение сообщает всем машинам подсети через интерфейс 144.206.160.32 все маршруты, которые данный шлюз получает из подсети 144.206.128.0 через интерфейс 144.206.130.137. Фактически осуществляется сквозная пересылка всей информации во внутрь системы.
При написании управляющих предложений export следует всегда помнить, что внешнее предложение определяет всегда интерфейс, через который сообщается информация, а внутреннее предложение определяет источник, через который эту информацию получает gated.
Важным является и синтаксис предложений, который сильно смахивает на синтаксис языка программирования С.
Во всех руководствах по gated приводится еще один пример, когда сеть, через подсеть подключают к Internet. Здесь приведем пример из руководства к gated 3.5.
rip yes;export proto rip interface 136.66.12.3 metric 3{ proto rip interface 136.66.1.5 { announce all ; } ;} ;export proto ripinterface 136.66.1.5{proto rip interface 136.66.12.3
{announce 0.0.0.0 ;
} ;
{ ;
В данном случае все, что gated получает из локальной сети через интерфейс 136.66.1.5 транслируется в подсеть, которая связывает данную сеть с Internet, через интерфейс 136.66.12.3 (речь идет только о маршрутах, так как gated работает только с таблицей маршрутов).
Второе предложение export определяет куда следует отправлять информацию по умолчание из сети, чтобы она достигла адресата, расположенного за пределами данной локальной сети. Адрес 0.0.0.0, который соответствует любой машине за интерфейсом 136.66.12.3 анонсируется через интерфейс 136.66.1.5. для всей локальной сети.
И последние замечания о gated. Они касаются возможности управлять доступом к машинам локальной сети. Если маршрут доступа к машине или локальной подсети не экспортировать во внешний мир, то о машине или подсети никто и не узнает. Правда в этом случае нельзя использовать эти машины для доступа к внешним ресурсам также.
В одном из докладов Министерства Обороны США, выполненном по запросу Конгресса, отмечалось, что в последнее время число атак на компьютеры вооруженных сил увеличилось. При этом атакующие, главным образом, используют программы захвата и анализа трафика TCP/IP, который передается по сети Internet. Надо сказать, что проблема эта не новая. Еще во время начала проекта Athena в Масачусетском Технологическом Институте, в результате которой появилась система Керберос, одной из основных целей проекта называлась защита от захвата и анализа пакетов.
До последнего времени, в российском секторе Internet хотя и знали, что такая проблема существует, хотя провайдеры и пользовались сами сканированием, серьезных шагов по защите от этого сканирования не предпринимали. В данном случае речь идет о том, что требование тотальной защиты, как это имеет место во всех зарубежных коммерческих и правительственных сетях, не выдвигалось. Не смотря на то, что Relcom первым продемонстрировал в 1991 году возможности бесконтрольного, со стороны государства, распространения информации через Internet, ни Demos, ни AO Relcom не ставили перед собой задачи сплошной защиты своих внутренних сетей от атаки из вне при помощи просмотра содержания IP-пакетов.
Надо сказать, что довольно долгое время такая практика себя оправдывала. Серьезных нарушений в работе сети не происходило, а атаки на шлюзы и локальные подсети успешно отбивались системами фильтрации трафика. Но к осени 1996 года ситуация изменилась. И главной причиной изменения стало внедрение системы доступа к сети по dial-ip. Теперь в сети появилось большое количество случайных людей со стороны. Кроме того, внедрение Internet во многих московских вузах привело к увеличению среди пользователей сети доли студентов. При этом следует отметить, что доступ из академических и учебных заведений в Internet по большей части остается бесплатным для пользователей, а это значит, что ресурсами сети можно пользоваться круглосуточно, не заботясь о том, сколько у тебя в кармане денег.
Склонность человеческой натуры к подсматриванию и подглядыванию хорошо известна. А если за это еще и не накажут, и заниматься этим можно сколько душе угодно, то вероятность появления любопытных резко возрастает.
К осени 1996 года число зарегистрированных пользователей Dial-IP составило несколько тысяч человек только в AO Relcom. SovamTeleport начал заниматься предоставлением такого доступа на полгода раньше (с осени 1995), следовательно там число пользователей должно быть еще больше. Кроме того, многие университеты, учебные заведения и научно-исследовательские организации для своих сотрудников создали модемные пулы. Естественно, что администраторы подсетей или их близкие друзья также не могли пройти мимо возможности работать на дому. Исходя из этого, можно предположить, что только в Москве число пользователей Dial-IP составляет несколько десятков тысяч человек.
Совершенно очевидно, что среди такого количества людей обязательно найдется некто, кто посвятит все свое свободное время исследованию сети, тем более что слава всемогущих хакеров, взламывающих компьютеры Пентагона, не дает спать спокойно многим.
И вот в середине сентября 1996 года прозвенел первый звоночек. Точнее, на эту проблему обратил внимание наших провайдеров CERT (Computer Emagency Response Team). В Канаде были зарегистрированы попытки входа в систему по различным портам TCP с указанием действительно существовавших идентификаторов и паролей пользователей. Попытку зарегистрировала программа межсетевого фильтра (FilreWall), о чем и сообщила администратору. Администратор оказался человеком дотошным и стал выяснять кто и откуда пытался проникнуть в систему.
Двухнедельные занятия по изучению файлов отчетов о доступе к основным компьютерам центров управления российскими сетями показали удручающую картину. Действительно, на многих машинах наблюдались посещения в режиме привилегированных пользователей с адресов, которые не ассоциировались ни с одним из тех лиц, кому такой доступ был разрешен. Были найдены и списки идентификаторов и паролей, и инструмент, которым пользовались взломщики, и отчеты этой программы, которые хранились злоумышленниками на компьютерах за пределами российской части Internet.
Собственно определить кто и откуда коллекционировал информацию не представляло большого труда, но главным был вопрос о том, что в этом случае следует предпринимать. Ведь подобного прециндента в практике российского Internet-сообщества еще не было.
Во-первых, конечно надо было защищаться. Средства защиты хорошо известны - это фильтрация трафика и шифрация обменов. Благо на настоящий момент Гос.тех комиссией выдано более сотни лицензий на возможность проведения такого сорта мероприятий и сертифицировано как аппаратное, так и программное обеспечение. Но пассивная оборона - это только половина дела, хотелось еще и наказать наглецов. А вот с последним и возникли проблемы. В принципе, по новому российскому законодательству предусмотрены наказания вплоть до лишения свободы на строк до семи лет за компьютерные преступления, но для этого надо вести следственные мероприятия, передавать дело в суд и т.п. Все это не входит в компетенцию провайдеров, потому что может занять много времени, а кроме того о таких прецидентах, что-то пока ничего слышно не было.
Общение с организацией, предоставившей Dial-IP вход, также не дало гарантий от повторения подобных инцидентов. Поэтому было принято решение зафильтровать сетки, с которых осуществлялся первоначальный вход в сеть при взломе.
К чему привела эта практика, на своей шкуре почувствовали многие пользователи сети. На первый взгляд, вроде ничего страшного, ну не пускают тебя к отечественным информационным ресурсам, а мы, что называется, и не хотели. Будем ходить на Запад. Но не тут-то было.
Дело в том, что к отечественным информационным сервисам относится и служба DNS. DNS обслуживает запросы на получение по доменному имени машины ее IP-адреса. Каждый домен имеет несколько серверов, которые могут удовлетворить запрос пользователя, но только один из них является главным. Все остальные время от времени сверяют информацию в своей базе данных с информацией в базе данных главного сервера. При фильтрации обычно закрывают порты TCP. Это значит, что отвечать на запросы, которые используют 53 порт UDP, сервер будет, а вот осуществить копирование описания зоны на дублирующий сервер, которое производится по 53 порту TCP, межсетевой фильтр не даст. Как результат, дублирующие сервера будут отказывать в обслуживании, и доступ к ресурсам, из-за невозможности получить за приемлемое время IP-адрес, будет затруднен.
В результате доступ к такому информационному ресурсу, как World Wide Web, происходит через "пень-колоду". Что говорить о доступе к отечественным ресурсам. Ведь не "видно" не только тех, кто спрятался за "стенами", но и тех, кто разместил там серверы DNS. Особенно пикантной становится ситуация, если в защищенную зону попадет root-сервер DNS для доменов SU и RU.
Сколько теперь будет успокаиваться поднятая этими действиями волна - не известно, но то, что провайдеры, к которым в данном случае относятся и некоммерческие сети, должны вместе договориться об общих принципах политики безопасности - это очевидно, в противном случае ситуация будет повторяться постоянно, но уже гораздо с большими последствиями для всех заинтересованных сторон.
И попутно, хотелось бы заметить, что всякие разговоры о проблемах с сервером InfoArt, когда, как утверждалось, было подменено содержание базы данных службы доменных имен, могут являться следствием указанных выше причин. Хотя то, что события совпали по времени может быть простой случайностью.
После столь долгого вступления хотелось все же обратиться к тому средству, которым воспользовались злоумышленники. Программы, позволяющие захватывать пакеты из сети называются sniffers (буквально - "нюхачи", но мне кажется лучше назвать их "пылесосами", т.к. сосут они все подряд, хотя есть и интеллектуальные, которые из всех пакетов выбирают только то, что нужно).
Первые такие программы использовали то, что в сетях Ethernet все компьютеры подсоединяются на один кабель. В обычном режиме карта Ethernet принимает только те фреймы, которые ей предназначены, т.е. указаны в заголовке фрейма. Однако в целях отладки многие карты можно заставить работать в режиме "пылесоса", тогда они будут принимать все фреймы, которые передаются по кабелю. Такой режим работы карты называется promiscuous mode. Если можно получить пакет в машину, то, следовательно, его можно проанализировать.
Главная проблема, связанная с "нюхачами" заключается в том, чтобы они успевали перерабатывать весь трафик, который проходит через интерфейс. Код одной из достаточно эффективных программ этого типа (Esniff) был опубликован в журнале Phrack. Esniff предназначена для работы в Sunos. Программа очень компактная и захватывает только первые 300 байтов заголовка, что вполне достаточно для получения идентификатора и пароля telnet-сессии. Программа свободно распространяется по сети и каждый желающий может ее "срисовать" по адресу ftp://coombs.anu.edu.au/pub/net/log. Существуют и другие программы этого типа и не только для платформ Sun. Это Gobler, athdump, ethload для MS-DOS или Paketman, Interman, Etherman, Loadman - для целого ряда платформ, которые включают в себя Alpha, Dec-Mips, SGI и др. "Нюхачи" существуют не только для Ethernet. Многие компании выпускают системы анализа трафика и для высокоскоростных линий передачи данных. Достаточно зайти на домашнюю страницу AltaVista и запустить запрос, состоящий из одного слова "sniffer" как вы сразу получите целый список страниц на данную тему. Лучше правда "sniffer AND security", т.к. система может понять вас буквально и выложить информацию и об органах дыхания.
Когда программы анализа трафика писались, то предполагалось, что пользоваться ими будут профессионалы, отвечающие за надежность работы сети. Однако, как это часто бывает, система оказалась обоюдоострой. Как же бороться с непрошенными гостями?
Во-первых, если система многопользовательская, то при помощи команды ifconfig можно увидеть интерфейс, который работает в режиме "пылесоса". Среди флагов появляется значение PROMISC. Однако, злоумышленник может подменить команду ifconfig, чтобы она не показывала этот режим работы. Поэтому следует убедиться в том, что программа та, которая была первоначально, а во-вторых, ее протестировать.
Обнаружить "пылесос" на других машинах сети нельзя, особенно это касается машин с MS-DOS. Поэтому от сканирования защищаются путем установки межсетевых фильтров и введения механизмов шифрации либо всего трафика, либо только идентификаторов и паролей.
Существуют и аппаратные способы защиты. Ряд сетевых адаптеров не поддерживает режим promiscuous mode. Если эти карты использовать для организации локальной сети, то можно обезопасить себя от "подглядывания".
Для того, чтобы "подглядывать" вовсе не обязательно включать режим принятия всех пакетов. Если запустить программу анализа пакетов на шлюзе, то вся информация также будет доступна, т.к. шлюз пропускает через себя все пакеты в/из локальной сети, для которой он является шлюзом.
В заключении хотелось бы сказать, вслед за Jeff Schiller и Joanne Costell из Масачусетского Технологического Института, что, для использования sniffer не надо иметь семи пядей во лбу, не надо иметь диплом о высшем образовании и вообще запустить программу и воспользоваться результатами может и младенец. То, что кто-то смог наколлекционировать чужие пароли и идентификаторы не говорит о его уме или профессиональной пригодности. Единственным последствием таких действий станет неминуемое ужесточение правил использования сети, от которого плохо станет всем.
Взаимодействие компьютеров в сети Интернет происходит при помощи
сетевого протокола IP (Internet Protocol). Каждому из компьютеров
присваивается специальный IP-адрес – 32-битное число,
записываемое обычно как четыре числа (октета) от 0 до 255, разделённые
точками – например, 213.128.193.154. Протокол IP и IP-адресация подробнее описаны в разделе "Основы
компьютерных сетей".
Иногда при подключении компьютерной сети к Интернету выделяется достаточное количество IP-адресов, чтобы присвоить каждому из компьютеров сети. В этом случае компьютеры получают реальные IP-адреса, т.е. адреса, непосредственно используемые для обмена данными с Интернетом. Однако, поскольку реальный IP-адрес должен быть уникален в масштабе всего Интернета, количество таких адресов ограничено, и, следовательно, получение реальных IP-адресов на всю сеть является достаточно дорогостоящим.
Чаще всего реальный IP-адрес имеется только у маршрутизатора. Компьютерам сети присваиваются внутренние IP-адреса, используемые только в пределах сети. При связи с Интернетом все компьютеры представлены IP-адресом маршрутизатора. Такое решение называется трансляция адресов (Network Address Translation, NAT).
При использовании NAT у маршрутизатора имеются как внутренний, так и реальный IP-адреса. Пакеты данных, предназначенные для передачи в Интернет, поступают от компьютеров сети к маршрутизатору. Он пересылает их далее, но в качестве адреса отправителя указывает свой реальный IP-адрес. Когда приходят ответные пакеты, маршрутизатор определяет, какой пакет предназначен для какой станции, указывает нужный адрес как адрес назначения пакета и пересылает его в локальную сеть.
(Существуют и более сложные схемы применения технологии NAT, но они используются достаточно редко, в основном – в больших сетях).
При работе с сетью Интернет через сеть с использованием технологии NAT имеется ряд ограничений, связанных с тем, что компьютер в сети не доступен напрямую из Интернета. Пакет данных из Интернета может достичь этого компьютера, только если он отправлен в ответ на исходящий от него пакет (и этот факт определён маршрутизатором). Из-за этого, если попытаться использовать компьютер с внутренним IP-адресом в качестве сервера, доступ к нему смогут получить только другие компьютеры внутри сети. Некоторые Интернет-сервисы, например, системы для голосовых переговоров, не работают при подключении через NAT (хотя это иногда возможно исправить при помощи настройки маршрутизатора для конкретного сервиса).
Эти ограничения имеют и положительную сторону – компьютеры с внутренними IP-адресами оказываются неуязвимы для многих видов информационных атак из Интернета.
В сети, подключённой к Интернету, может также функционировать proxy-сервер; нередко эта функция также исполняется маршрутизатором. Proxy-сервер для протоколов HTTP и FTP сохраняет на диске копии загружаемой информации (WWW-страниц и файлов) из Интернета. Если та же информация запрашивается снова (возможно, другим компьютером сети), proxy-сервер отправляет в ответ её локальную копию, а не производит новую загрузку из Интернета. (Правильно настроенный proxy-сервер всегда проверяет, не изменилась ли запрашиваемая информация в Интернете с момента сохранения копии, и использует копию, если изменений не было).
Использование Proxy-сервера позволяет ускорить работу и сэкономить оплачиваемый трафик.
В этой главе объясняется, как настраивать параметры трансляции сетевых адресов (NAT); использование NAT позволяет использовать во внутренней сети резервные адреса и тем самым расширить ее адресное пространство, обеспечить сокрытие структуры внутренней сети с прозрачным доступом к Интернет.
Любой сети, желающей подключиться к Интернет, необходим набор IP адресов, которые может выделить любая имеющая на это право организация. Существуют три класса IP адресов: класс А, внутри которого можно описать до 16777214 хостов, класс В, позволяющий описать до 65533 хостов и класс С с 254 хостами.
Бум, который переживает Интернет в последние годы, привел к тому, что сети класса А и В в настоящее время стали недоступны для организаций и отдельных пользователей. Поэтому Вам может быть выделена только сеть класса С, с 254 адресами. При большем числе хостов вам потребуются другие сети класса С, что усложняет работу администратора. Другой способ решения проблемы состоит в использовании трансляции сетевых адресов (NAT).
Трансляция сетевых адресов - это технология, которая позволяет использовать
для внутренней сети любые адреса, возможно даже из класса А; при этом
сохраняется одновременный и прозрачный доступ в Интернет для всех хостов.
Механизм функционирования такого процесса достаточно прост: каждый раз, когда
хост с зарезервированным адресом пытается получить доступ в Интернет,
межсетевой экран контролирует эту попытку и автоматически преобразует его адрес
в разрешенный. Когда хост назначения отвечает и посылает данные на разрешенный
адрес, межсетевой экран преобразует его обратно в зарезервированный адрес и
передает данные внутреннему хосту. При этом ни клиент, ни сервер не знают о
существовании этого преобразования.
Кроме уже упомянутых преимуществ, трансляция сетевых адресов позволяет все хосты внутренней сети сделать невидимыми для внешней сети, что увеличивает уровень безопасности.
Трансляция сетевых адресов не может быть использована для сервисов, которые передают информацию об IP-адресах или портах внутри протокола. Межсетевой экран Aker из сервисов такого вида поддерживает только сервисы FTP и Real Audio/Real Video.
Внутренняя сеть состоит из хостов, входящих в состав одной или более подсетей, защищенных межсетевым экраном Aker. Сюда включаются также внутренние сетевые устройства, такие как маршрутизаторы, коммутаторы, серверы, клиенты и т.д. В межсетевом экране Aker внутренняя сеть называется частной сетью (Private Network).
Внешние сети состоят из тех хостов, которые не являются частью внутренней сети. Они могут находиться или не находиться под административной ответственностью вашей организиции.
Если организация подключена к Интернет, внешней сетью будет весь Интернет.
Независимо от технических возможностей, адреса внутренней сети не следует выбирать случайным образом. Специально для этих целей существуют зарезерезерированные адреса. Эти адреса не присвоены и никогда не будут присвоены какому-либо хосту, непосредственно соединенному с Интернет.
Зарезервированными являются следующие адреса:
От 10.0.0.0 до 10.255.255.255, маска 255.0.0.0
(класс A)
От 172.16.0.0 до 172.31.0.0, маска 255.255.0.0 (класс B)
От 192.168.0.0 до 192.168.255.255, маска 255.255.255.0 (класс C)
Существуют два различных типа преобразования сетевых адресов: 1-1 и много - 1. Каждый из них обладает своими характерными особенностями. Для улучшения результатов обычно применяют их комбинацию.
Тип 1-1 - наиболее понятный, но обычно наименее полезный. Он заключается в создании пары адресов с отображением одного зарезервированного адреса в один реальный адрес. В результате различные хосты будут иметь различные адреса трансляции.
Очень существенное ограничение этого типа состоит в невозможности отображения большего количества хостов, чем количество реальных адресов, поскольку они всегда преобразуются по схеме один-в-один. С другой стороны, эта процедура позволяет иметь доступ извне к хостам с зарезервированными адресами.
Преобразование много-в-один, как свидетельствует его название, делает возможным нескольким хостам с зарезервированными адресами использовать один и тот же реальный адрес. Чтобы достичь этой цели, преобразование использует IP-адреса в комбинации с портами (в случае TCP и UDP протоколов) и в комбинации с порядковыми номерами (в случае ICMP). Это отображение производится динамически межсетевым экраном каждый раз, когда устанавливается соединение. Поскольку существует 65535 портов или различных порядковых номеров, то можно осуществить до 65535 одновременных активных соединений, использующих один и тот же адрес.
Единственным ограничением этой технологии является то, что она не позволяет иметь доступ к внутренним хостам снаружи. Все соединения должны инициироваться изнутри.
Предположим, что некоторая организация получает сеть класса С (обозначим ее А.В.С.0). Эта сеть позволяет описать 254 реальных хоста (адреса А.В.С.0 и А.В.С.255 резервируются для специальных целей и не быть использованы, остаются значения между А.В.С.1 и А.В.С.254). Предположим еще, что локальная сеть состоит из 1000 хостов, которые необходимо подключить к Интернет. Так как реальных адресов недостаточно, необходимо воспользоваться трансляцией сетевых адресов. Поэтому для использования во внутренней сети была выбрана зарезервированная сеть класса А 10.x.x.x c cетевой маской 255.0.0.0.
Межсетевой экран Aker устанавливается на границе между Интернет и внутренней сетью, имеющей адреса из зарезервированной сети. Aker будет выполнять преобразование зарезервированных адресов 10.x.x.x в реальные адреса А.В.С.x. В результате межсетевой экран должен иметь по крайней мере два адреса: реальный адрес, до которого можно добраться через Интернет, и зарезервированный, к которому возможен доступ только из внутренней сети. (Как правило на межсетевом экране устанавливают два или более адаптера, один для внешней сети, а один или более - для внутренней. Возможно, хотя крайне нежелательно установить на межсетевой экран всего один сетевой адаптером, с присвоением реального и зарезервированного адреса одному и тому же адаптеру.)
Предположим, что адрес А.В.С.2 выбран для реального (внешнего) сегмента, а адрес 10.0.0.2 для внутреннего сегмента. Реальный адрес будет использоваться межсетевым экраном для преобразования всех соединений из внутренней сети в Интернет. С внешней стороны все соединения будут выглядеть так, как будто они начинаются на межсетевом экране.
В межсетевом экране Aker такой адрес называется виртуальным адресом (он виртуальный, поскольку на самом деле соединения не инициируются межсетевым экраном). Этот адрес должен быть настроен на одном из сетевых интерфейсов межсетевого экрана. Если на сетевом интерфейсе описано более одного реального адреса, виртуальным адресом может быть любой из них.
При такой схеме все внутренние хосты могут получить доступ к ресурсам Интернет прозрачно, как если бы они имели действительные адреса. Однако при этом внешние хосты не могут образовывать соединения с внутренними (так как внутренние хосты не имеют реальных адресов). Для решения этой проблемы у межсетевого экрана Aker есть таблица статического преобразования, которая выполняет преобразования 1-1 и позволяет имитировать реальный адрес для любого из зарезервированных. Эта таблица называется таблицей серверной трансляции.
Вернемся опять к нашей гипотетической организации. Предположим, что в вашей сети существует WWW сервер с адресом 10.1.1.5. Предположим еще. что вам хотелось бы, чтобы этот сервер предоставлял информацию как для внутренней сети, так и для Интернет. В этом случае нужно так выбрать реальный адрес, чтобы он мог использоваться внешними клиентами для соединения с этим сервером. Положим, что выбранный адрес есть А.В.С.10. Тогда в таблицу статического преобразования должен прибавиться элемент для отображения адреса А.В.С.10 во внутренний адрес 10.1.1.5. С этого момента все обращения к адресу А.В.С.10 будут автоматически направляться по адресу 10.1.1.5
Реальный адрес, выбранный для выполнения преобразования 1-1, нельзя присвоить какому-нибудь хосту. В нашем примере возможны конфигурации, содержащие до 253 серверов во внутренней сети, к которым можно иметь доступ извне (один из 254 допустимых действующих адресов уже использован для преобразования трафика всех клиентов).
Межсетевой экран Aker использует технологию proxy-arp для взаимодействия внешних сетевых устройств (например, внешний маршрутизатор) с виртуальными серверами.
С Интернет существует выделенный канал
Оборудование: 1 роутер, 1 Aker Firewall, n клиентов,
2 сервера во внутренней сети
Реальный адрес: А.В.С.x ; сетевая маска 255.255.255.0
Зарезервированный адрес: 10.x.x.x ; сетевая маска 255.0.0.0
Адреса серверов: 10.1.1.1, 10.2.1.1
Адреса клиентов: 10.x.x.x
Адрес маршрутизатора: реальная сеть: А.В.С.1 , Интернет: x.x.x.x
Конфигурация межсетевого экрана Aker:
Адреса адаптера: внутренняя сеть: 10.0.0.2 ,
Виртуальный IP адрес A.B.C.2
Внутренняя сеть: 10.0.0.0
Маска внутренней сети: 255.0.0.0
Таблица серверной трансляции:
A.B.C.10 - 10.1.1.1
A.B.C.30 - 10.2.1.1
Взаимодействие отделов
В этом примере мы покажем, как обеспечить взаимодействие между собой отделов одной компании с использованиемтрансляции адресов между ними.
Оборудование: 1 роутер, 3 Aker Firewalls, n клиентов, 4 внутренних
сетевых клиента
Реальные адреса: A.B.C.x, маска 255.255.255.0
Зарезервированные адреса: 10.x.x.x маска 255.255.0.0
Зарезервированные адреса:172.16.x.x, маска 255.240.0.0
Адреса подсети 1:
10.1.x.x
Адрес сервера: 10.1.1.1
Адрес клиента: 10.1.x.x
Адрес роутера: внутренняя сеть: A.B.C.1 , Интернет:x.x.x.x
Конфигурация межсетевого экрана Aker:
Внутренняя сеть: 10.1.0.1, Реальная сеть A.B.C.2
Виртуальный IP адрес: A.B.C.2
Внутренняя сеть: 10.0.0.0
Маска внутренней сети: 255.0.0.0
Адреса подсети 3:
Внешние: 10.2.x.x
Внутренние: 172.16.x.x
Адрес сервера: 172.16.1.1
Адреса клиента: 172.x.x.x
Конфигурация межсетевого экрана Aker:
Подсеть 2: 172.16.0.1, Подсеть 1:10.1.0.2
Виртуальный IP адрес: 10.1.0.2
Внутренняя сеть (2): 172.16.0.0
Маска внутренней сети: 255.240.0.0
Таблица трансляции серверов:
10.2.1.1 - 172.16.1.1
Адреса подсети 3:
Внешний: 10.3.x.x
Внутренний: 172.16.x.x
Адрес сервера: 172.16.1.1
Адреса клиента: 172.x.x.x
Конфигурация межсетевого экрана Aker:
Подсеть3: 172.16.0.1, Подсеть 1:10.1.0.3
Виртуальный IP адрес: 10.1.0.3
Внутренняя сеть (3): 172.16.0.0
Маска внутренней сети: 255.240.0.0
Таблица трансляции серверов:
10.3.1.1 - 172.16.1.1
При такой конфигурации необходимо описать в таблице маршрутизации маршруты к подсетям 10.1.х.х , 10.2.х.х и 10.3.х.х .
Для получения доступа к меню описания трансляции сетевых адресов необходимо выполнить следующие шаги:
Окно трансляции сетевых адресов
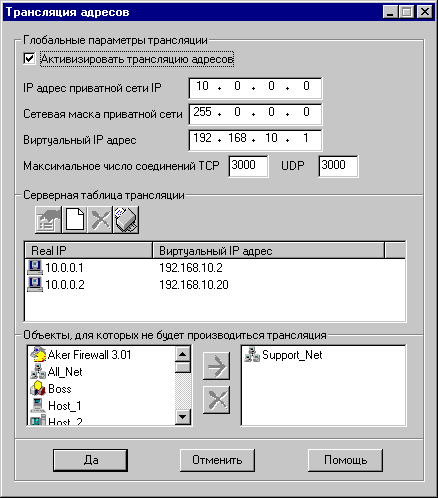
Окно трансляции сетевых адресов состоит из нескольких полей, которые необходимо заполнить для правильной работы NAT в межсетевом экране Aker. Эти поля имеют вид:
Общие параметры трансляции:
Активизировать трансляцию адресов: Эта опция должна быть включена для активизации механизма трансляции адресов. Когда механизм трансляции не активен, конфигурация будет сохраняться, но ее нельзя будет изменить.
IP адрес приватной сети: IP адрес внутренней сети.
Сетевая маска приватной сети: Сетевая маска внутренней сети.
Виртуальный IP адрес: Это реальный IP адрес, в который будут транслироваться адреса источника всех пакеты от хостов внутренней сети при их соединении в внешними серверами. Этот адрес должен быть одним из адресов сетевого интерфейса межсетевого экрана.
Максимальное число TCP и UDP соединений: Это максимальное число одновременных соединений между внутренней и внешней сетями для UDP и TCP протоколов. Параметр может принимать значениеот 0 до 55000 (значение 0 не следует использовать, так как оно деактивирует трансляцию для выделенного протокола; при этом генерируется сообщение об ошибке при каждом обращении клиента к сервису, основанному на этом протоколе).
Максимальный периоде времени, в течение которого соединение считается активным, даже при отсутствии трафика, можно настраивать с помощью системных параметров. Настройка этого параметра описана в главе 4 Настройка системных параметров.
Трансляция адресов много-в-один работает только для протоколов TCP, UDP и ICMP. Для сервисов, основанных на других протоколах, трансляция производиться не будет, если только хост источника не помещен в таблицу серверной трансляции.
Таблица серверной трансляции:
Таблица серверноой трансляции используется для определения отображения один-в-один;серверам присваиваются реальные адреса и внешние хосты получают к ним доступ.
Чтобы добавить новое отображение в список, нужно выполнить следующие действия:
или:
Для редактирования элемента списка надо сделать следующее:
или
Для удаления отображения из списка необходимо выполнить следующее:
или
Для опций Добавить или Редактировать появится следующее окно:
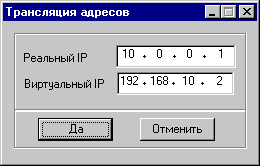
Реальный IP: Это IP адрес сетевого интерфейса внутреннего хоста
Виртуальный IP: Это реальный IP адрес, в который будут транслироваться адреса из внутренней сети. Этот адрес нельзя присваивать какому-либо внешнему хосту и он не может являться адресом сетевого интерфейса межсетевого экрана Aker.
Важные замечания:
Таблица объектов, для которых трансляция не будет производиться используется для задания хостов, сетей и наборов, приватные адреса которых не будут транслироваться. В этом случае, даже если хост описан в серверной таблице, его адрес источника не будет транслироваться при обращении к объектам, описанным в этой таблице
В этой таблице два списка: в левом представлены все описанные в системе объекты типа хост, сеть, набор. Справа представлены те обьекты, для которых трансляция производиться не будет.
Для добавления объекта к таблице исключений необходимо
Для удаления объекта из таблицы исключений необходимо:
Интерфейс командной строки для трансляции сетевых адресов прост в использовании и обладает теми же возможностями, что и графический интерфейс. Путь к программе: /etc/firewall/fwconver
Синтаксис:
fwconver [activate | deactivate | show | help]
fwconver add server <Real IP> <Virtual IP> fwconver add entity <name> fwconver remove server <position> fwconver remove entity <name> fwconver <max_con_tcp | max_con_udp> <number fwconver <private_net | netmask | virtual_ip> <address>
Program help:
Aker Firewall - Version 3.01 fwconver - настройка параметров трансляции сетевых адресов
Использование: fwconver [activate | deactivate | show | help] fwconver [activate | deactivate | show | help] fwconver add server <Real IP> <Virtual IP> fwconver add entity <name> fwconver remove server <position> fwconver remove entity <name> fwconver <max_con_tcp | max_con_udp> <number fwconver <private_net | netmask | virtual_ip> <address> activate = активизирует трансляцию сетевых адресов deactivate = деактивизирует трансляцию сетевых адресов
show = показывает активную конфигурацию
add = добавляет новый элемент в таблицу серверной трансляции или в таблицу
объектов, для которых трансляция производиться не будет
remove = удаляет элемент из таблицы серверной трансляции или из таблицы объектов,
для которых трансляция производиться не будет
max_con_tcp = устанавливает максимальное число одновременных TCP соединений
max_con_udp = устанавливает максимальное число одновременных UDP соединений
private_net = устанавливает IP адрес частной сети
netmask = устанавливает сетевую маску частной сети
virtual_ip = устанавливает виртуальные адреса для трансляции
help = показывает данное сообщение
Для команды добавления:
server = добавление записи в таблицу серверной трансляции
entity = добавление записи в таблицу объектов, для которых
трансляция производиться не будет
Real IP = преобразуемый реальный адрес
Virtual IP = IP адрес, в который будет преобразован реальный адрес
name = имя объекта, добавляемого в таблицу объектов, для которых
трансляция производиться не будет
Для команды удаления:
server = удаление записи из таблицы серверной трансляции
entity = удаление записи из таблицы объектов, для которых
трансляция производиться не будет
position = позиция элемента, удаляемого из таблицы
(Слово ALL можно использовать для удаления всех элементов таблицы)
name = имя объекта, удаляемого из таблицы объектов, для которых
трансляция производиться не будет
Для полей max_con_tcp и max_con_udp :
number = максимальное число одновременных соединений (от 0 до 55000)
Для полей private_net, netmask и virtual_ip:
address = адрес
Пример 1: (Просмотр конфигурации)
#fwconver showGlobal Translation parameters:------------------------------Network address translation : activatedMaximum number of TCP connections: 300Maximum number of UDP connections: 300Private network address : 10.0.0.0Private network mask : 255.0.0.0Virtual IP address : 200.239.39.11 Servers translation table:--------------------------01 - 10.4.1.3 200.239.39.302 - 10.4.1.7 200.239.39.7Entities to which the translation will not be performed:--------------------------------------------------------
Internal_network_1 (Network)
Пример 2: (деактивизация трансляции адресов и просмотр конфигурации)
#fwconver deactivate#fwconver showGlobal Translation parameters:------------------------------Network address translation : deactivatedMaximum number of TCP connections: 300Maximum number of UDP connections: 300Private network address : 10.0.0.0Private network mask : 255.0.0.0Virtual IP address : 200.239.39.11 Servers translation table:--------------------------01 - 10.4.1.3 200.239.39.302 - 10.4.1.7 200.239.39.7Entities to which the translation will not be performed:--------------------------------------------------------
Internal_network_1 (Network)
Пример 3: (Удаление первого элемента таблицы серверной трансляции и просмотр конфигурации)
#fwconver remove 1#fwconver showGlobal Translation parameters:------------------------------Network address translation : deactivatedMaximum number of TCP connections: 300Maximum number of UDP connections: 300Private network address : 10.0.0.0Private network mask : 255.0.0.0Virtual IP address : 200.239.39.11 Servers translation table:--------------------------
01 - 10.4.1.7 200.239.39.7
Entities to which the translation will not be performed:--------------------------------------------------------
Internal_network_1 (Network)
Прнимер 4: (Добавление элемента в таблицу серверной трансляции и просмотр конфигурации)
#fwconver add 10.4.1.9 200.239.39.39#fwconver showGlobal Translation parameters:------------------------------Network address translation : deactivatedMaximum number of TCP connections: 300Maximum number of UDP connections: 300Private network address : 10.0.0.0Private network mask : 255.0.0.0Virtual IP address : 200.239.39.11 Servers translation table:--------------------------01 - 10.4.1.7 200.239.39.702 - 10.4.1.9 200.239.39.39Entities to which the translation will not be performed:--------------------------------------------------------
Internal_network_1 (Network)
Пример 5: (добавление объекта в таблицу исключений и просмотр конфигурации)
#fwconver add entity Server_01Entity added to the table of entities to which the network address translationwill not be performed #fwconver showGlobal Translation parameters:------------------------------Network address translation : deactivatedMaximum number of TCP connections: 300Maximum number of UDP connections: 300Private network address : 10.0.0.0Private network mask : 255.0.0.0Virtual IP address : 200.239.39.11 Servers translation table:--------------------------01 - 10.4.1.7 200.239.39.702 - 10.4.1.9 200.239.39.39 Entities to which the translation will not be performed:--------------------------------------------------------Internal_network_1 (Network)Server_01 (Host)
Системное и прикладное программное обеспечение
1.Теоретические основы растровой графики. Программные средства обработки растровой графики.
Компьютерная
графика - раздел информатики, который изучает средства и способы создания и
обработки графических изображений при помощт компьютерной техники. Несмотря на
то, что для работы с компьютерной графикой существует множество классов
программного обеспечения, различают четыре вида компьютерной графики. Это растровая
графика, векторная графика, трёхмерная и фрактальная графика. Они
отличаются принципами формирования изображения при отображении на экране монитора
или при печати на бумаге.
Растровую графику применяют при разработке электронных
(мультимедийных) и полиграфических изданий. Иллюстрации, выполненные средствами
растровой графики, редко создают вручную с помощью компьютерных программ. Чаще
для этой цели используют отсканированные иллюстрации, подготовленные художником
на бумаге, или фотографии. В последнее время для ввода растровых изображений в
компьютер нашли широкое применение цифровые фото- и видеокамеры.
Соответственно, большинство графических редакторов, предназначенных для работы
с растровыми иллюстрациями, ориентированы не столько на создание изображений,
сколько на их обработку. В Интернете применяют растровые иллюстрации в тех
случаях, когда надо передать полную гамму оттенков цветного изображения.
Растровая графика
Основным (наименьшим) элементом растрового изображения является точка. Если изображение экранное, то эта точка называется пикселом. Каждый пиксел растрового изображения имеет свойства: размещение и цвет. Чем больше количество пикселей и чем меньше их размеры, тем лучше выглядит изображение. Большие объемы данных - это основная проблема при использовании растровых изображений. Для активных работ с большеразмерными иллюстрациями типа журнальной полосы требуются компьютеры с исключительно большими размерами оперативной памяти (128 Мбайт и более). Разумеется, такие компьютеры должны иметь и высокопроизводительные процессоры. Второй недостаток растровых изображений связан с невозможностью их увеличения для рассмотрения деталей. Поскольку изображение состоит из точек, то увеличение изображения приводит только к тому, что эти точки становятся крупнее и напоминают мозаику. Никаких дополнительных деталей при увеличении растрового изображения рассмотреть не удается. Более того, увеличение точек растра визуально искажает иллюстрацию и делает её грубой. Этот эффект называется пикселизацией.
Разрешение изображения - это свойство самого изображения. Оно тоже измеряется в точках на дюйм - dpi и задается при создании изображения в графическом редакторе или с помощью сканера. Так, для просмотра изображения на экране достаточно, чтобы оно имело разрешение 72 dpi, а для печати на принтере - не меньше как 300 dpi. Значение разрешения изображения хранится в файле изображения.
Каковы
параметры растровых изображений?
Размер - произведение ширины на высоту в пикселях.
Разрешение - количество информации на единицу длины. Измеряется в ppi (pixels
per inch ≈ пиксели на дюйм) и dpi (dots per inch - точки на дюйм). Имеет
смысл только, если известны реальные размеры изображения или отпечатка.
Модель - способ описания элементов изображения в цифровом виде. Например,
Bitmap, Grayscale, Indexed, RGB, HLS, Lab, CMYK. В WWW используются модели
Grayscale, Indexed, RGB.
Цветовая модель RGB - естественный язык цвета сканнеров, мониторов и других
электронных устройств.
Глубина цвета - количество бит памяти, выделяемых для описания тоновых или
цветовых характеристик каждого пикселя в соответствие с моделью. Например,
1бит/пикс. (Bitmap, Halftone), 8 бит/пикс. (Grayscale, Indexed), 24 бит/пикс.
(RGB).
Разреше́ние — величина, определяющая количество точек (элементов растрового изображения) на единицу площади (или единицу длины). Термин обычно применяется к изображениям в цифровой форме, хотя его можно применить, например, для описания уровня грануляции фотопленки, фотобумаги или иного физического носителя. Более высокое разрешение (больше элементов) типично обеспечивает более точные представления оригинала. Другой важной характеристикой изображения является разрядность цветовой палитры.
Разреше́ние — величина, определяющая количество точек (элементов растрового изображения) на единицу площади (или единицу длины). Термин обычно применяется к изображениям в цифровой форме, хотя его можно применить, например, для описания уровня грануляции фотопленки, фотобумаги или иного физического носителя. Более высокое разрешение (больше элементов) типично обеспечивает более точные представления оригинала. Другой важной характеристикой изображения является разрядность цветовой палитры.
Как правило, разрешение в разных направлениях одинаково, что даёт пиксель квадратной формы. Но это не обязательно — например, горизонтальное разрешение может отличаться от вертикального, при этом элемент изображения (пиксель) будет не квадратным, а прямоугольным.
Ошибочно под разрешением понимают размеры фотографии, экрана монитора или изображения в пикселях[источник не указан 238 дней]. Размеры растровых изображений выражают в виде количества пикселов по горизонтали и вертикали, например: 1600×1200. В данном случае это означает, что ширина изображения составляет 1600, а высота — 1200 точек (такое изображение состоит из 1 920 000 точек, то есть примерно 2 мегапикселя). Количество точек по горизонтали и вертикали может быть разным для разных изображений. Изображения, как правило, хранятся в виде, максимально пригодном для отображения экранами мониторов — они хранят цвет пикселов в виде требуемой яркости свечения излучающих элементов экрана (RGB), и рассчитаны на то, что пикселы изображения будут отображаться пикселами экрана один к одному. Это обеспечивает простоту вывода изображения на экран.
При выводе изображения на поверхность экрана или бумаги, оно занимает прямоугольник определённого размера. Для оптимального размещения изображения на экране необходимо согласовывать количество точек в изображении, пропорции сторон изображения с соответствующими параметрами устройства отображения. Если пикселы изображения выводятся пикселами устройства вывода один к одному, размер будет определяться только разрешением устройства вывода. Соответственно, чем выше разрешение экрана, тем больше точек отображается на той же площади и тем менее зернистой и более качественной будет ваша картинка. При большом количестве точек, размещённом на маленькой площади, глаз не замечает мозаичности рисунка. Справедливо и обратное: малое разрешение позволит глазу заметить растр изображения («ступеньки»). Высокое разрешение изображения при малом размере плоскости отображающего устройства не позволит вывести на него всё изображение, либо при выводе изображение будет «подгоняться», например для каждого отображаемого пиксела будут усредняться цвета попадающей в него части исходного изображения. При необходимости крупно отобразить изображение небольшого размера на устройстве с высоким разрешением приходится вычислять цвета промежуточных пикселей. Изменение фактического количества пикселей изображения называется передискретизация, и для неё существуют целый ряд алгоритмов разной сложности.
При выводе на бумагу такие изображения преобразуются под физические возможности принтера: проводится цветоделение, масштабирование и растеризация для вывода изображения красками фиксированного цвета и яркости, доступными принтеру. Принтеру для отображения цвета разной яркости и оттенка приходится группировать несколько меньшего размера точек доступного ему цвета, например один серый пиксел такого исходного изображения, как правило, на печати представляется несколькими маленькими чёрными точками на белом фоне бумаги. В случаях, не касающихся профессиональной допечатной подготовки, этот процесс производится с минимальным вмешательством пользователя, в соответствии с настройками принтера и желаемым размером отпечатка. Изображения в форматах, получаемых при допечатной подготовке и рассчитанные на непосредственный вывод печатающим устройством, для полноценного отображения на экране нуждаются в обратном преобразовании.
Большинство форматов графических файлов позволяют хранить данные о желаемом масштабе при выводе на печать, то есть о желаемом разрешении в dpi (англ. dots per inch — эта величина говорит о каком-то количестве точек на единицу длины, например 300 dpi означает 300 точек на один дюйм). Это исключительно справочная величина. Как правило, для получения распечатка фотографии, который предназначен для рассматривания с растояния порядка 20-30 сантиметров, достаточно разрешения 300 dpi. Исходя из этого можно прикинуть, какого размера отпечаток можно получить из имеющегося изображения или какого размера изображение надо получить, чтоб затем сделать отпечаток нужного размера.
Например, надо напечатать с разрешением в 300 dpi изображение на бумаге размером 10×10 см. Переведя размер в дюймы получим 3,9×3,9 дюймов. Теперь, умножив 3,9 на 300 и получаем размер фотографии в пикселях: 1170×1170. Таким образом, для печати изображения приемлемого качества размером 10×10 см, размер исходного изображения должен быть не менее 1170×1170 пикселей.
Для обозначения разрешающей способности различных процессов преобразования изображений (сканирование, печать, растеризация и т. п.) используют следующие термины:
По историческим причинам величины стараются приводить к dpi, хотя с практической точки зрения ppi более однозначно характеризует для потребителя процессы печати или сканирования. Измерение в lpi широко используется в полиграфии. Измерение в spi используется для описания внутренних процессов устройств или алгоритмов.
Для создания реалистичного изображения средствами компьютерной графики цвет иногда оказывается важнее (высокого) разрешения, поскольку человеческий глаз воспринимает картинку с большим количеством цветовых оттенков как более правдоподобную. Вид изображения на экране напрямую зависит от выбранного видеорежима, основу которого составляют три характеристики: кроме собственно разрешения (кол-ва точек по горизонтали и вертикали), отличаются частота обновления изображения (Гц) и количество отображаемых цветов (цветорежим или разрядность цвета)). Последний параметр (характеристику) часто также называют разрешение цвета, или частота разрешения (частотность или разрядность гаммы) цвета.
Разница между 24- и 32-разрядным цветом на глаз отсутствует, потому как в 32-разрядном представлении 8 разрядов просто не используются, облегчая адресацию пикселов, но увеличивая занимаемую изображением память, а 16-разрядный цвет заметно «грубее». У профессиональных цифровых фотокамер у сканеров (например, 48 или 51 бит на пиксел) более высокая разрядность оказывается полезна при последующей обработке фотографий: цветокоррекции, ретушировании и т. п.
Для векторных изображений, в силу принципа построения изображения, понятие разрешения неприменимо.
Разрешение устройства (inherent resolution) описывает максимальное разрешение изображения, получаемого с помощью устройства ввода или вывода.
Для изображений применяемых на сайте, большое значение имеет понятие разрешение, которое выражается количеством точек на единицу длины. Различают разные типы:
Разрешение монитора указывается двумя значениями и определяет количество точек по горизонтали и вертикали. Элементарную точку на экране принято называть пикселом. Таким образом, значение 800х600 означает, что видимая область монитора имеет 800 пикселов по горизонтали и 600 — по вертикали. Пиксел — это относительная единица измерения, ее величина зависит от установленного экранного разрешения и размера монитора. Например, для 19-дюймового монитора популярным разрешением является 1280 на 1024 пикселов. Картинка с такими же размерами (1280x1024) будет занимать всю область экрана. Уменьшив разрешение до 1024 на 768, мы, тем самым, увеличим размеры изображения на экране.
Разрешение монитора имеет важное значения для веб-дизайнеров, ведь от этого параметра зависит и размер помещаемых на веб-страницу изображений. При неудачном учете этого значения рисунок может не поместиться целиком на веб-страницу и тогда появится горизонтальная полоса прокрутки, которая создает неудобства посетителям сайта и может испортить дизайн. Таким образом, для сайта, который ориентирован на разрешение монитора пользователей 800 на 600, ширину изображений следует ограничить размером 700–770 пикселов. Данная величина получается с учетом ширины полосы прокрутки браузера и толщины вертикальных рамок окна.
Количество пикселов, показываемых на единицу длины изображения, характеризует величину разрешения экранного изображения и называется пиксел на дюйм (pixel per inch — ppi). Если изображение предназначено только для вывода на экран монитора, а не для печати, то графические программы, как правило, устанавливают разрешение 72 ppi.
Для любого печатающего устройства характерна величина, выражающая, сколько точек на дюйм он может воспроизвести, которая называется dpi (dot per inch — количество точек на дюйм). Для примера, большинство лазерных принтеров поддерживает разрешение 600 dpi и выше. Размер точки определяется характеристиками принтера и свойствами изображения.
Поскольку графические редакторы не в состоянии передать величину точки в силу физических различий между пикселом экрана и печатной точкой, то плотность точек заменяется количеством пикселов на экране. Так, для изображения, которое на печати будет иметь размер один на один дюйм, при разрешении 72 dpi количество пикселов будет равно 5184 (72x72). Увеличение разрешения до 300 dpi увеличит и количество пикселов до 90 тысяч (300x300). Более высокое разрешение, как правило, передает и большее количество деталей в изображении.
Иногда между собой путают разрешение изображения и разрешение печати в связи с тем, что в некоторых графических программах используется только один термин — dpi. Поэтому следует учитывать, что если изображение предназначено для вывода на экран монитора, на веб-страницу, например, то разрешение в данном случае должно пониматься как ppi (пиксел на дюйм).
Любое графическое изображение может быть показано как на экране, так и распечатано на принтере. По этой причине графические редакторы поддерживают два взаимосвязанных размера изображения — один измеряется в пикселах и предназначен для вывода на экран, а другой — измеряется в сантиметрах, миллиметрах, дюймах и других типографских единицах и показывает, какой ширины и высоты будет напечатано изображение.
Изменение разрешение изображения никак не сказывается на ширине и высоте напечатанного изображения (Document Size на рис. 1), но существенно влияет на качество печати, хотя увидеть конечный результат на экране мы не в состоянии. Вместо этого будет изменяться количество пикселов по горизонтали и вертикали, чтобы сохранить плотность точек на прежнем уровне. Увеличивая разрешение в два раза, мы, тем самым, увеличиваем количество пикселов в 4 раза, что немудрено, ведь линейные размеры изображения удваиваются по ширине и высоте.
Форматы графических файлов определяют способ хранения информации в файле
(растровый, векторный), а также форму хранения информации (используемый
алгоритм сжатия).
Сжатие применяется для растровых графических файлов, т.к. они имеют достаточно
большой объем. Существуют различные алгоритмы сжатия, причем для различных типов
изображения целесообразно применять подходящие типы алгоритмов сжатия.
В таблице приведена краткая характеристика часто используемых графических
форматов.
|
Тип графической информации |
Алгоритм сжатия |
Графические форматы |
|
Рисунки типа аппликации, содержащие большие области однотонной закраски. |
Заменяет последовательность повторяющихся величин (пикселей одинакового цвета) на две величины (пиксель и количество его повторений). |
BMP, PCX |
|
Рисунки типа диаграмм |
Осуществляет поиск повторяющихся в рисунке "узоров". |
TIFF, GIF |
|
Отсканированные фотографии, иллюстрации |
Основан на том, что человеческий глаз очень чувствителен к изменению яркости отдельных точек изображения, но гораздо хуже замечает изменение цвета. При глубине цвета 24 бита, компьютер обеспечивает воспроизведение более 16 млн. различных цветов, тогда как человек вряд ли способен различить. |
JPEG |
В компьютерной графике применяют, по меньшей мере, три десятка форматов файлов для хранения изображений. Но в данной статье мы рассмотрим только два основных формата, которые распознаются достаточно большим числом Web-броузеров: GIF и JPEG.
Формат GIF (Graphics Interchange Format) был введен компанией CompuServe в качестве первого формата для передачи и демонстрации графики через модем.
Цвет каждого пикселя кодируется восьмью битами, поэтому GIF-файл может
содержать до 256 цветов. Цвета, которые используются в GIF-изображении,
хранятся внутри самого файла в специальной таблице цветов, называемой
индексированной палитрой.
Файлы GIF могут также содержать различные оттенки серого цвета. Существуют две
основные версии формата GIF: GIF87 и GIF89a - они названы так по
году стандартизации. Обе версии поддерживают способ представления графического
файла с чередованием строк. Более поздний вариант GIF89a допускает задание
одного цвета в качестве прозрачного.
Прозрачность подразумевает, что один цвет изображения (обычно это цвет фона)
может быть объявлен прозрачным. Это ведет к тому, что вместо фона изображения
виден просвечивающий сквозь него фон самой Web-страницы. Благодаря этому
изображение на странице выглядит более естественным.
Чередование строк означает, что во время приема изображения из Интернета его
детали прорисовываются постепенно. Эффект похож на то, что происходит, когда на
нерезкую картинку постепенно наводят фокус. Благодаря чередованию строк
пользователи с медленными модемами могут обычно еще в самом начале приема
картинки оценить ее содержание и время, необходимое на полную передачу, и тем
самым принять решение, стоит ли продолжать прием или можно от него
отказаться.
GIF-файлы можно также использовать для создания на экране несложной анимации.
Основным ограничением GIF-файлов является их неспособность хранить и
демонстрировать неиндексированные изображения, подготовленные в режиме True
Color (16,8 миллиона оттенков) или High Color (32-64 тысячи оттенков). Иными
словами, GIF-изображения должны состоять из 256 или меньшего числа
цветов.
Сжатие файлов в формате GIF является сжатием без потерь. Это означает, что
упаковка изображения никоим образом не сказывается на его качестве. При этом
сжатие оказывается наиболее эффективным в тех случаях, когда в составе
изображения имеются большие области однородной окраски с четко очерченными
границами. И наоборот, сжатие по алгоритму GIF крайне неэффективно при наличии
областей с градиентной окраской или случайным распределением цветовых оттенков,
что имеет место при использовании различных методов настройки растра или
сглаживания краев области изображения.
Формат JPEG (Joint Photographic Experts Group) был разработан для того, чтобы эффективно хранить и передавать цветные фотографии с полным набором цветовых оттенков. Изначально формат JPEG применялся для того, чтобы фотожурналисты, специализирующиеся на опубликовании новостей, имели возможность сжать файлы своих цифровых фотоснимков до размера, пригодного для передачи с места событий в издательство через модем.
Формат JPEG приспособлен для хранения неиндексированных по цвету
изображений, сформированных в режиме RGB с глубиной цвета True Color.
Цвет кодируется 24-мя битами на пиксель, и тем самым одновременно может
воспринимать более 16 миллионов цветов. Степень сжатия файлов может меняться по
решению пользователя. С учетом практического предела использования Web-графики
в 72 dpi обычно можно выбирать очень высокую степень сжатия (до 100:1) без
сколько-нибудь заметного ухудшения качества изображения.
Формат JPEG имеет возможность представления графического файла аналогично
"чересстрочной развертке" формата GIF. Это называется в терминах
формата JPEG - "прогрессивной разверткой". Оба метода позволяют
броузеру вначале прорисовывать изображение с низким разрешением, а затем
повышать его качество по мере подкачки файла, тем самым существенно сокращая
кажущееся время загрузки графики.
Формат JPEG имеет два существенных недостатка:
Многократное сохранение файла в этом формате ведет к ухудшению качества
изображения. Поэтому не стоит архивировать изображение в формате JPEG, если
только речь не идет о носителях информации, доступной только для чтения. Кроме
того, искажения будут проявляться и в случае, если фото формата JPEG будет
скомбинировано с изображением другого формата, а затем записано со сжатием.
Изображения, сохраненные в формате JPEG, не могут иметь прозрачных областей.
Используйте GIF-формат для хранения всех малоразмерных графических
элементов: значков-ссылок, надписей и миниатюр. Применяйте формат GIF для
хранения изображений любого размера, изначально состоящих из больших областей
однородной окраски.
Исключение из данного перечня могут составлять файлы, содержащие необычно много
цветов и тонких цветовых переходов. Лучшим советчиком в этом случае может
служить эксперимент.
Применяйте данный формат во всех случаях, когда размер изображения по каждой из координат превышает 200 пикселей, а само изображение представляет собой полноценную фотографию или образец художественной графики, включающий тонкие переливы цветов.
|
|
|
|
|
|
При подготовке файлов для размещения в сети Интернет приходиться
сталкиваться с проблемой преобразования графических файлов из одного формата в
другой.
Например, у вас есть очень интересный файл в формате TIFF, который вы
хотите разместить на своих Web-страницах. Поэтому вам необходимо преобразовать
этот файл в один из форматов GIF или JPEG.
Преобразование форматов графических файлов можно выполнить с помощью графических
редакторов, воспринимающих файлы разных форматов. Для этих целей можно
воспользоваться графическим редактором Photo Editor, входящим в Microsoft
Office. Этот редактор умеет работать практически со всеми распространенными
форматами графических файлов: TIFF, PCX, GIF, JPEG и др. При этом он дает
возможность конвертировать файлы из одного формата в другой с помощью обычной
операции Сохранить как… (Save as…).
При преобразовании файлов можно уточнить желаемые параметры.
Например, выполнить преобразование из цветного в черно-белый формат,
выбрать количество цветов, степень сжатия файла, либо фактор качества - большой
файл и лучшее качество изображения, или же маленький файл с более низким
качеством изображения.
Форматы графических данных
В компьютерной графике применяют по меньшей мере три десятка форматов файлов
для хранения изображений. Но лишь часть из них стала стандартом «де-факто» и
применяется в подавляющем большинстве программ. Как правило, несовместимые
форматы имеют файлы растровых, векторных, трехмерных изображений, хотя
существуют форматы, позволяющие хранить данные разных классов. Многие
приложения ориентированы на собственные «специфические» форматы, перенос их
файлов в другие программы вынуждает использовать специальные фильтры или
экспортировать изображения в «стандартный» формат.
TIFF (Tagged Image File Format). Формат предназначен для хранения растровых
изображений высокого качества (расширение имени файла .TIF). Относится к числу
широко распространенных, отличается переносимостью между платформами (IBM PC и
Apple Macintosh), обеспечен поддержкой со стороны большинства графических,
верстальных и дизайнерских программ. Предусматривает широкий диапазон цветового
охвата — от монохромного черно-белого до 32-разрядной модели цветоделения CMYK.
Начиная с версии 6.0 в формате TIFF можно хранить сведения о масках (контурах
обтравки) изображений. Для уменьшения размера файла применяется встроенный
алгоритм сжатия LZW.
PSD (PhotoShop Document). Собственный формат программы Adobe Photoshop
(расширение имени файла .PSD), один из наиболее мощных по возможностям хранения
растровой графической информации. Позволяет запоминать параметры слоев,
каналов, степени прозрачности, множества масок. Поддерживаются 48-разрядное
кодирование цвета, цветоделение и различные цветовые модели. Основной
недостаток выражен в том, что отсутствие эффективного алгоритма сжатия
информации приводит к большому объему файлов.
PCX, Формат появился как формат хранения растровых данных программы PC
PaintBrush фирмы Z-Soft и является одним из наиболее распространенных
(расширение имени файла .PCX). Отсутствие возможности хранить цветоделенные
изображения, недостаточность цветовых моделей и другие ограничения привели к
утрате популярности формата. В настоящее время считается устаревшим.
PhotoCD. Формат разработан фирмой Kodak для хранения цифровых растровых
изображений высокого качества (расширение имени файла .PCD). Сам формат
хранения данных в файле называется Image Рас. Файл имеет внутреннюю структуру,
обеспечивающую хранение изображения с фиксированными величинами разрешений, и
потому размеры любых файлов лишь незначительно отличаются друг от друга и
находятся в диапазоне 4-5 Мбайт. Каждому разрешению присвоен собственный
уровень, отсчитываемый от так называемого базового (Base), составляющего
512x768 точек, Всего в файле пять уровней — от Base/16 (128x192 точек) до
BasexlG (2048x3072 точек). При первичном сжатии исходного изображения
применяется метод субдискретизации, практически без потери качества. Затем
вычисляются разности Base — Basex4 и Basex4 — Basexl6. Итоговый результат
записывается в файл. Чтобы воспроизвести информацию с высоким разрешением,
производится обратное преобразование. Для хранения информации о цвете
использована цветовая модель YCC,
Windows Bitmap. Формат хранения растровых изображений в операционной системе
Windows (расширение имени файла .BMP). Соответственно, поддерживается всеми
приложениями, работающими в этой среде.
JPEG (Joint Photographic Experts Group). Формат предназначен для хранения
растровых изображений (расширение имени файла. JPG). Позволяет регулировать
соотношение между степенью сжатия файла и качеством изображения. Применяемые
методы сжатия основаны на удалении «избыточной» информации, поэтому формат
рекомендуют использовать только для электронных публикаций.
GIF (Graphics Interchange Format). Стандартизирован в 1987 году как средство
хранения сжатых изображений с фиксированным (256) количеством цветов
(расширение имени файла .GiF). Получил популярность в Интернете благодаря
высокой степени сжатия. Последняя версия формата GIF89a позволяет выполнять
чересстрочную загрузку изображений и создавать рисунки с прозрачным фоном.
Ограниченные возможности по количеству цветов обусловливают его применение
исключительно в электронных публикациях.
PNG (Portable Network Graphics). Сравнительно новый (1995 год) формат хранения
изображений для их публикации в Интернете (расширение имени файла .PNG).
Поддерживаются три типа изображений — цветные с глубиной 8 или 24 бита и
черно-белое с традицией 256 оттенков серого. Сжатие информации происходит
практически без потерь, предусмотрены 254 уровня альфа-канала, чересстрочная
развертка.
WMF (Windows MetaFile). Формат хранения векторных изображений операционной
системы Windows (расширение имени файла .WMF). По определению поддерживается
всеми приложениями этой системы. Однако отсутствие средств для работы со
стандартизированными цветовыми палитрами, принятыми в полиграфии, и другие
недостатки ограничивают его применение.
EPS (Encapsulated PostScript). Формат описания как векторных, так и растровых
изображений на языке PostScript фирмы Adobe, фактическом стандарте в области
допечатных процессов и полиграфии (расширение имени файла. EPS), Так как язык
PostScript является универсальным, в файле могут одновременно храниться
векторная и растровая графика, шрифты, контуры обтравки (маски), параметры
калибровки оборудования, цветовые профили. Для отображения на экране векторного
содержимого используется формат WMF, а растрового — TIFF. Но экранная копия
лишь в общих чертах отображает реальное изображение, что является существенным
недостатком EPS. Действительное изображение можно увидеть лишь на выходе
выводного устройства, с помощью специальных программ просмотра или после
преобразования файла в формат PDF'B приложениях Acrobat Reader, Acrobat
Exchange.
PDF (Portable Document Format). Формат описания документов, разработанный
фирмой Adobe (расширение имени файла .PDF). Хотя этот формат в основном
предназначен для хранения документа целиком, его впечатляющие возможности
позволяют обеспечить эффективное представление изображений. Формат является
аппа-ратно-независимым, поэтому вывод изображений допустим на любых устройствах
— от экрана монитора до фотоэкспонирующего устройства. Мощный алгоритм сжатия
со средствами управления итоговым разрешением изображения обеспечивает
компактность файлов при высоком качестве иллюстраций.
Понятие цвета
Цвет чрезвычайно важен в компьютерной графике как средство усиления зрительного
впечатления и повышения информационной насыщенности изображения. Ощущение цвета
формируется человеческим мозгом в результате анализа светового потока,
попадающего на сетчатку глаза от излучающих или отражающих объектов. Считается,
что цветовые рецепторы (колбочки) подразделяются на три группы, каждая из
которых воспринимает только единственный цвет — красный, зеленый или синий.
Нарушения в работе любой из групп приводит к явлению дальтонизма — искаженного
восприятия цвета.
Световой поток формируется излучениями, представляющими собой комбинацию трех
«чистых» спектральных цветов (красный, зеленый, синий — КЗС) и их производных
(в англоязычной литературе используют аббревиатуру RGB — Red, Green, Blue). Для
излучающих объектов характерно аддитивное цветовоспроизведение (световые
излучения суммируются), для отражающих объектов — субтрактивное
цветовоспроизведение (световые излучения вычитаются). Примером объекта первого
типа является электронно-лучевая трубка монитора, второго типа —
полиграфический отпечаток.
Физические характеристики светового потока определяются параметрами мощности, яркости
и освещенности. Визуальные параметры ощущения цвета характеризуются светлотой,
то есть различимостью участков, сильнее или слабее отражающих свет. Минимальную
разницу между яркостью различимых по светлоте объектов называют порогом.
Величина порога пропорциональна логарифму отношения яркостей.
Последовательность оптических характеристик объекта (расположенная по
возрастанию или убыванию), выраженная в оптических плотностях или логарифмах
яркостей, составляет градацию и является важнейшим инструментом для анализа и
обработки изображения.
Для точного цветовоспроизведения изображения на экране монитора важным является
понятие цветовой температуры, В классической физике считается, что любое тело с
температурой, отличной от 0 градусов по шкале Кельвина, испускает излучение. С
повышением температуры спектр излучения смещается от инфракрасного до
ультрафиолетового диапазона, проходя через оптический.
Для идеального черного тела легко находится зависимость между длиной волны
излучения и температурой тела. На основе этого закона, например, была
дистанционно вычислена температура Солнца — около 6500 К. Для целей правильного
цветовоспроизведения характерна обратная задача. То есть, монитор с
выставленной цветовой температурой 6500 К должен максимально точно воспроизвести
спектр излучения идеального черного тела, нагретого до такой же степени. Таким
образом, стандартные значения цветовых температур используют в качестве
всеобщего эталона, обеспечивающего одинаковое цветовоспроизведение на разных
излучающих устройствах.
На практике зрение человека непрерывно подстраивается под спектр, характерный
для цветовой температуры источника излучения. Например, на улице в яркий
солнечный день цветовая температура составляет около 7000 К. Если с улицы зайти
в помещение, освещенное только лампами накаливания (цветовая температура около
2800 К), то в первый момент свет ламп покажется желтым, белый лист бумаги тоже
приобретет желтый оттенок. Затем происходит адаптация зрения к новому
соотношению КЗС, характерному для цветовой температуры 2800 К, свет лампы и
лист бумаги будут восприниматься как белые.
Насыщенность цвета показывает, насколько данный цвет отличается от
монохроматического («чистого») излучения того же цветового тона. В компьютерной
графике за единицу принимается насыщенность цветов спектральных излучений.
Ахроматические цвета (белый, серый, черный) характеризуется только светлотой.
Хроматические цвета имеют параметры насыщенности, светлоты и цветового тона.
Способы описания цвета
В компьютерной графике применяют понятие цветового разрешения (другое название
— глубина цвета). Оно определяет метод кодирования цветовой информации для ее
воспроизведения на экране монитора. Для отображения черно-белого изображения
достаточно двух бит (белый и черный цвета). Восьмиразрядное кодирование
позволяет отобразить 256 градаций цветового тона. Два байта (16 бит) определяют
65 536 оттенков (такой режим называют High Color). При 24-разрядном способе
кодирования возможно определить более 16,5 миллионов цветов (режим называют
True Color).
С практической точки зрения цветовому разрешению монитора близко понятие
цветового охвата. Под ним подразумевается диапазон цветов, который можно
воспроизвести с помощью того или иного устройства вывода (монитор, принтер,
печатная машина и прочие).
В соответствии с принципами формирования изображения аддитивным или
суб-трактивным методами разработаны способы разделения цветового оттенка на
составляющие компоненты, называемые цветовыми моделями. В компьютерной графике
в основном применяют модели RGB и HSB (для создания и обработки аддитивных
изображений) и CMYK (для печати копии изображения на полиграфическом
оборудовании).
Цветовые модели расположены в трехмерной системе координат, образующей цветовое
пространство, так как из законов Гроссмана следует, что цвет можно выразить
точкой в трехмерном пространстве.
Первый закон Грассмана (закон трехмерности). Любой цвет однозначно выражается
тремя составляющими, если они линейно независимы. Линейная независимость
заключается в невозможности получить любой из этих трех цветов сложением двух
остальных.
Второй закон Грассмана (закон непрерывности). При непрерывном изменении
излучения цвет смеси также меняется непрерывно. Не существует такого цвета, к
которому нельзя было бы подобрать бесконечно близкий.
Третий закон Грассмана (закон аддитивности). Цвет смеси излучений зависит
только от их цвета, но не спектрального состава. То есть цвет (С) смеси
выражается суммой цветовых уравнений излучений:
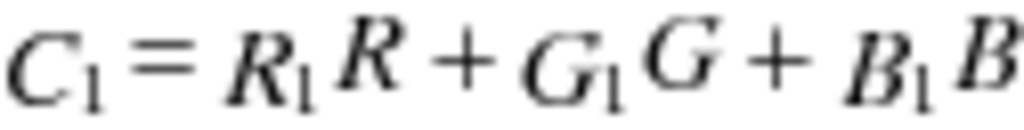
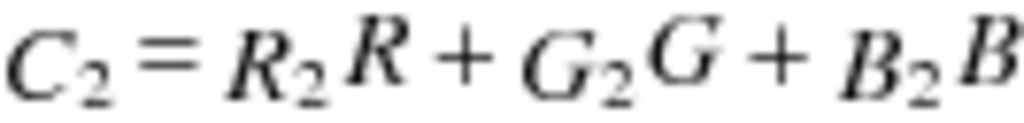
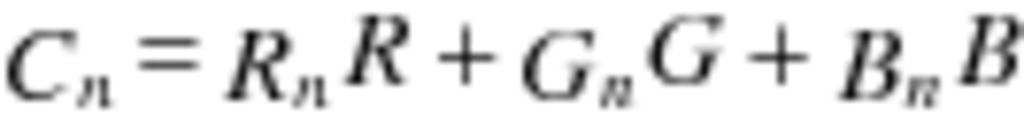
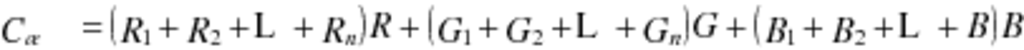
Таким образом, прямоугольная трехмерная координатная система цветового
пространства для аддитивного способа формирования изображения имеет точку
начала координат, соответствующую абсолютно черному цвету (цветовое излучение
отсутствует), и три оси координат, соответствующих основным цветам. Любой цвет
(С) может быть выражен в цветовом пространстве вектором, который описывается
уравнением:
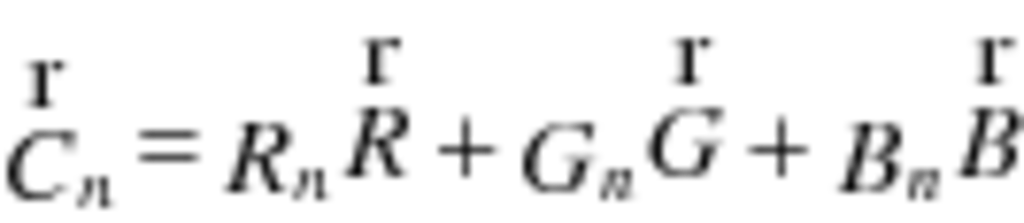 ,
,
которое практически идентично уравнению свободного вектора в пространстве,
рассматриваемому в векторной алгебре. Направление вектора характеризует
цветность, а его модуль выражает яркость.
Так как величина излучения основных цветов является основой цветовой модели, ее
максимальное значение принято считать за единицу. Тогда в трехмерном цветовом
пространстве можно построить плоскость единичных цветов, образованную
треугольником цветности. Каждой точке плоскости единичных цветов соответствует
след цветового вектора, пронизывающего ее в этой точке. Следовательно,
цветность любого излучения может быть представлена единственной точкой внутри
треугольника цветности, в вершинах которого находятся точки основных цветов. То
есть положение точки любого цвета можно задать двумя координатами, а третья
легко находится по двум другим.
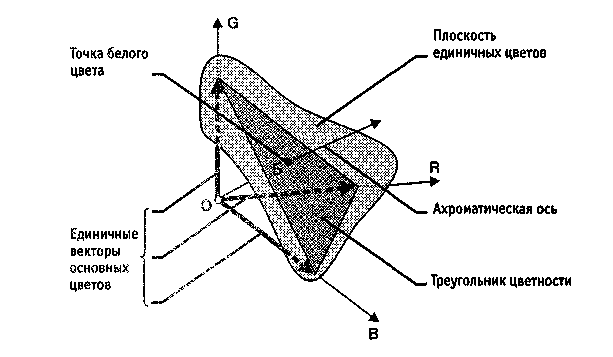
Рис. 15,11. Плоскость единичных цветов
Если на плоскости единичных цветов указать значения координат, соответствующих
реальным спектральным излучениям оптического диапазона (от 380 до 700 нм), и
соединить их кривой, то мы получим линию, являющуюся геометрическим местом
точек цветности монохроматических излучений, называемую локусом. Внутри локуса
находятся все реальные цвета.
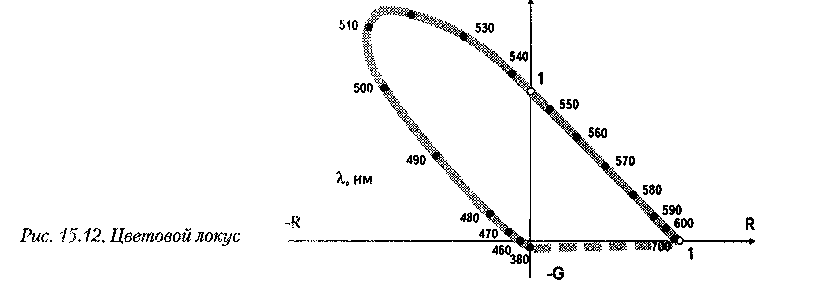
Чтобы избежать отрицательных значений координат, была выбрана колориметрическая
система XYZ, полученная путем пересчета из RGB. В этой системе точке белого
соответствуют координаты (0,33; 0,33). Колориметрическая система XYZ является
универсальной, в ней можно выразить цветовой охват как аддитивных, так и
субтрактивных источников цвета. Для аддитивных источников цветовой охват
выражается треугольником с координатами вершин, соответствующими излучению
основных цветов R, G, В,
Для субтрактивных источников (полученных в процессе печати красками, чернилами,
красителями) используется модель CMYK, поэтому цветовой охват описывается
шестиугольником, когда помимо точек синтеза основной триады (желтая, пурпурная,
голубая) добавляются точки попарных наложений, соответствующие основным цветам:
желтая + голубая = зеленая, желтая + пурпурная = красная, голубая + пурпурная =
синяя.

Цветовая модель СIЕ Lab
В 1920 году была разработана цветовая пространственная модель CIELab
(Communication Internationale de I'Edairage — международная комиссия по
освещению. L,a,b — обозначения осей координат в этой системе). Система является
аппаратно независимой и потому часто применяется для переноса данных между устройствами,
В модели CIELab любой цвет определяется светлотой (Z,) и хроматическими
компонентами: параметром а, изменяющимся в диапазоне от зеленого до красного, и
параметром Ь, изменяющимся в диапазоне от синего до желтого. Цветовой охват
модели CIELab значительно превосходит возможности мониторов и печатных
устройств, поэтому перед выводом изображения, представленного в этой модели,
его приходится преобразовывать. Данная модель была разработана для согласования
цветных фотохимических процессов с полиграфическими. Сегодня она является
принятым по умолчанию стандартом для программы Adobe Photoshop.
Цветовая модель RGB
Цветовая модель RGB является аддитивной, то есть любой цвет представляет собой
сочетание в различной пропорции трех основных цветов — красного (Red), зеленого
(Green), синего (Blue). Она служит основой при создании и обработке
компьютерной графики, предназначенной для электронного воспроизведения (на
мониторе, телевизоре). При наложении одного компонента основного цвета на
другой яркость суммарного излучения увеличивается. Совмещение трех компонентов
дает ахроматический серый цвет, который при увеличении яркости приближается к
белому цвету. При 256 градационных уровнях тона черному цвету соответствуют
нулевые значения RGB, а белому — максимальные, с координатами (255,255,255).

желтый
пурпурный
голубой
Рис. 15.14. Аддитивная цветовая модель RGB
Цветовая модель HSB
Цветовая модель HSB разработана с максимальным учетом особенностей восприятия
цвета человеком. Она построена на основе цветового круга Манселла. Цвет
описывается тремя компонентами: оттенком (Hue), насыщенностью {Saturation) и
яркостью {Brightness). Значение цвета выбирается как вектор, исходящий из
центра окружности. Точка в центре соответствует белому цвету, а точки по
периметру окружности — чистым спектральным цветам. Направление вектора задается
в градусах и определяет цветовой оттенок. Длина вектора определяет насыщенность
цвета. На отдельной оси, называемой ахроматической, задается яркость, при этом
нулевая точка соответствует черному цвету. Цветовой охват модели HSB перекрывает
все известные значения реальных цветов.

Рис. 15.15. Цветовая модель HSB
Модель HSB принято использовать при создании изображений на компьютере с
имитацией приемов работы и инструментария художников. Существуют специальные
программы, имитирующие кисти, перья, карандаши. Обеспечивается имитация работы
с красками и различными полотнами. После создания изображения его рекомендуется
преобразовать в другую цветовую модель, в зависимости от предполагаемого
способа публикации.
Цветовая модель CMYK, цветоделение
Цветовая модель CMYK относится к субтрактивным, и ее используют при подготовке
публикаций к печати. Цветовыми компонентами CMY служат цвета, полученные
вычитанием основных из белого:
голубой (cyan) = белый - красный = зеленый + синий;
пурпурный (magenta) = белый - зеленый = красный + синий;
желтый (yellow) = белый - синий = красный + зеленый.
Такой метод соответствует физической сущности восприятия отраженных от печатных
оригиналов лучей. Голубой, пурпурный и желтый цвета называются дополнительными,
потому что они дополняют основные цвета до белого. Отсюда вытекает и главная
проблема цветовой модели CMY — наложение друг на друга дополнительных цветов на
практике не дает чистого черного цвета. Поэтому в цветовую модель был включен
компонент чистого черного цвета. Так появилась четвертая буква в аббревиатуре
цветовой модели CMYK (Cyan, Magenta, Yellow, blaсК).
белый
Рис. 15.16. Цветовая модель CMYK
Для печати на полиграфическом оборудовании цветное компьютерное изображение
необходимо разделить на составляющие, соответствующие компонентам цветовой
модели CMYK. Этот процесс называют цветоделением. В итоге получают четыре
отдельных изображения, содержащих одноцветное содержимое каждого компонента в
оригинале. Затем в типографии с форм, созданных на основе цветоделенных пленок,
печатают многоцветное изображение, получаемое наложением цветов CMYK.
Цветовая палитра
Электронная и/зетовая палитра в компьютерной графике по предназначению подобна
палитре художника, но включает гораздо большее число цветов. Электронная
палитра состоит из определенного числа ячеек, каждая из которых содержит
отдельный цветовой тон. Конкретная цветовая палитра соотносится с определенной
цветовой моделью, так как ее цвета созданы на основе цветового пространства
этой модели. Но если в цветовой модели возможно воспроизвести любой из
описываемых ею цветов, цветовая палитра содержит ограниченный набор цветов,
называемых стандартными.
Примером стандартных цветовых палитр являются наборы фирмы Pantone,
ориентированные на полиграфическую публикацию изображений. Программы создания и
обработки компьютерной графики, как правило, предоставляют на выбор несколько
цветовых палитр в цветовых моделях RGB, HSB, CIELab, CMYK.
Состав цветовых палитр RGB зависит от выбранного цветового разрешения — 24, 16
или 8 бит. В последнем случае цветовая палитра называется индексной, потому что
каждый цветовой оттенок кодируется одним числом, которое выражает не цвет
пиксела, а индекс (номер) цвета. Таким образом, к файлу цветного изображения,
созданного в индексной палитре, должна быть приложена сама палитра, так как
программе обработки компьютерной графики неизвестно, какая именно палитра была
использована.
Изображения, подготавливаемые для публикации в Интернете, принято создавать в
так называемой безопасной палитре цветов. Она является вариантом рассмотренной
выше индексной палитры. Но так как файлы изображений в Web-графике должны иметь
минимальный размер, необходимо было отказаться от включения в их состав
индексной палитры. Для этого была принята единая фиксированная палитра цветов;
названная «безопасной*, то есть обеспечивающей правильное отображение цветов на
любых устройствах (в программах), поддерживающих единую палитру. Безопасная
палитра содержит всего 216 цветов, что связано с ограничениями, накладываемыми
требованиями совместимости с компьютерами, не относящимися к классу IBM PC.
Системы управления цветом
При создании и обработке элементов компьютерной графики необходимо добиться,
чтобы изображение выглядело практически одинаково на всех стадиях процесса, на
любом устройстве отображения, при любом методе визуализации (аддитивном или
субтрактивном). Иначе, чем больше переходных этапов будет содержать процесс
обработки, тем большие искажения будут вноситься в оригинал, и конечный
результат может совершенно не удовлетворять даже минимальным требованиям к
качеству. Для согласования цветов на всех стадиях обработки компьютерной
графики применяют системы управления цветом (Color Management System — CMS).
Такие системы содержат набор объективных параметров, обязательных для всех
устройств при обмене цветовыми данными. Универсальность CMS достигается
введением трех типов переменных, каждая из которых управляет представлением
цвета на своем уровне:
Цветовая гамма. Каждый тип устройства имеет свою цветовую гамму, область
которой всегда меньше, чем цветовой охват практически любой цветовой модели.
CMS управляет преобразованием цвета между различными цветовыми моделями с
учетом цветовой гаммы конкретных устройств;
Профиль. Каждое устройство воспроизводит цвета особенным образом, что зависит
от технических и программных решений, принятых изготовителем. Для согласования
отображения цветов на различных устройствах они должны иметь собственный
профиль, описывающий различия в представлении цвета между устройством и
определенной цветовой моделью. Международным консорциумом по цвету
(International Color Consortium — ICC) установлен промышленный стандарт на
параметры описания характеристик воспроизведения цвета. Устройства, имеющие
профиль ICC, напрямую управляются СМ5. В противном случае возможна генерация
профиля в некоторых системах CMS.
Калибровка. Даже устройства одной модели от одного производителя имеют отличия
в реализации профиля ICC, обусловленные допусками при изготовлении компонентов,
условиями эксплуатации, внешними помехами. Поэтому CMS как правило включает
средства калибровки, то есть настройки конкретного экземпляра в соответствии с
требованиями профиля ICC и фиксации неустранимых отклонений (с целью их
программной компенсации). Средства калибровки могут быть аппаратно-программными
и чисто программными. Сам процесс калибровки выполняется с периодичностью,
установленной изготовителем, или автоматически, при выходе параметров ICC за
границы допусков.
Не существует идеальной системы управления цветом, одинаково пригодной для всех
устройств, одинаково работающей на всех платформах и во всех программных
средах. Наиболее близко к идеалу подходят CMS, реализованные на уровне
операционной системы. Впервые CMS под названием ColorSync в операционную
систему встроила фирма Apple, что предопределило успех компьютеров Macintosh в
сфере издательской деятельности, допечатной подготовки и полиграфии. В
операционной системе Windows 95/98 используется модуль CMS фирмы Kodak,
названный Color Matching Module. Однако его поддержка со стороны производителей
пока явно недостаточна — набор профилей ICC ограничен.
Из CMS, являющихся внешними по отношению к операционной системе, наибольшее
распространение получили программы фирм, давно работающих в области цветной
фотографии, печати, цифровых графических технологий.
Agfa Foto Tune. Эта система управления цветом работает на платформах Windows и
Apple. Включает множество профилей ICC для мониторов, цветных принтеров,
сканеров, цифровых фотокамер, полиграфического оборудования. Имеются средства
создания заказных профилей для устройств, не попавших в список. Преобразования
между цветовыми профилями устройств (например сканер — монитор) могут
производиться напрямую, без промежуточной конвертации в цветовую модель CIELab
и обратно.
Kodak DayStar ColorMatch. Система предназначена для пользователей пакетов Adobe
Photoshop и QuarkXPress. Отличается модульным построением, поэтому базовая
поставка содержит ограниченное число профилей, а остальные необходимо
приобретать дополнительно. Система имеет средства поддержки формата Kodak
PhotoCD с учетом вывода изображений на фотопринтеры. Средства калибровки
включают стандартный шаблон IT8 для сканеров и устройство Digital Colorimeter
для мониторов.
§ Теоретические основы сжатия данных. Диспетчеры архивов
Избыточность — термин из теории информации, означающий превышение количества информации, используемой для передачи или хранения сообщения, над его информационной энтропией. Для уменьшения избыточности применяется сжатие данных без потерь, в то же время контрольная сумма применяется для внесения дополнительной избыточности в поток, что позволяет производить исправление ошибок при передаче информации по каналам, вносящим искажения (спутниковая трансляция, беспроводная передача и т. д.).
Основные характеристики сжатия
Основными техническими характеристиками процессов сжатия и результатов их работы являются:
Обратимое и необратимое сжатие
Существует несколько различных подходов к проблеме сжатия информации. Одни имеют весьма сложную теоретическую математическую базу, другие основаны на свойствах информационного потока и алгоритмически достаточно просты. Любой способ подход и алгоритм, реализующий сжатие или компрессию данных, предназначен для снижения объема выходного потока информации в битах при помощи ее обратимого или необратимого преобразования. Поэтому, прежде всего, по критерию, связанному с характером или форматом данных, все способы сжатия можно разделить на две категории: обратимое и необратимое сжатие.
Под необратимым сжатием подразумевают такое преобразование входного потока данных, при котором выходной поток, основанный на определенном формате информации, представляет, с некоторой точки зрения, достаточно похожий по внешним характеристикам на входной поток объект, однако отличается от него объемом. Степень сходства входного и выходного потоков определяется степенью соответствия некоторых свойств объекта (т.е. сжатой и несжатой информации, в соответствии с некоторым определенным форматом данных), представляемого данным потоком информации. Такие подходы и алгоритмы используются для сжатия, например, данных растровых графических файлов с низкой степенью повторяемости байтов в потоке. При таком подходе используется свойство структуры формата графического файла и возможность представить графическую картинку приблизительно схожую по качеству отображения (для восприятия человеческим глазом) несколькими (а точнее n) способами. Поэтому, кроме степени или величины сжатия, в таких алгоритмах возникает понятие качества, т.к. исходное изображение в процессе сжатия изменяется, то под качеством можно понимать степень соответствия исходного и результирующего изображения, оцениваемая субъективно, исходя из формата информации. Для графических файлов такое соответствие определяется визуально, хотя имеются и соответствующие интеллектуальные алгоритмы и программы. Необратимое сжатие невозможно применять в областях, в которых необходимо иметь точное соответствие информационной структуры входного и выходного потоков. Данный подход реализован в популярных форматах представления видео и фото информации, известных как JPEG и JFIF алгоритмы и JPG и JIF форматы файлов.
Обратимое сжатие всегда приводит к снижению объема выходного потока информации без изменения его информативности, т.е. - без потери информационной структуры. Более того, из выходного потока, при помощи восстанавливающего или декомпрессирующего алгоритма, можно получить входной, а процесс восстановления называется декомпрессией или распаковкой, и только после процесса распаковки данные пригодны для обработки в соответствии с их внутренним форматом.
В обратимых алгоритмах кодирование как процесс можно рассматривать со статистической точки зрения, что еще более полезно, не только для построения алгоритмов сжатия, но и для оценки их эффективности. Для всех обратимых алгоритмов существует понятие стоимости кодирования. Под стоимостью кодирования понимается средняя длина кодового слова в битах. Избыточность кодирования равна разности между стоимостью и энтропией кодирования, а хороший алгоритм сжатия всегда должен минимизировать избыточность (напомним, что под энтропией информации понимают меру ее неупорядоченности.). Фундаментальная теорема Шеннона о кодировании информации говорит о том, что "стоимость кодирования всегда не меньше энтропии источника, хотя может быть сколь угодно близка к ней". Поэтому, для любого алгоритма, всегда имеется некоторый предел степени сжатия, определяемый энтропией входного потока.
Перейдем теперь непосредственно к алгоритмическим особеннотям обратимых алгоритмов и рассмотрим важнейшие теоретические подходы к сжатию данных, связанные с реализацией кодирующих систем и способы сжатия информации.
Сжатие способом кодирования серий
Наиболее известный простой подход и алгоритм сжатия информации обратимым путем - это кодирование серий последовательностей (Run Length Encoding - RLE). Суть методов данного подхода состоит в замене цепочек или серий повторяющихся байтов или их последовательностей на один кодирующий байт и счетчик числа их повторений. Проблема всех аналогичных методов заключается лишь в определении способа, при помощи которого распаковывающий алгоритм мог бы отличить в результирующем потоке байтов кодированную серию от других - некодированных последовательностей байтов. Решение проблемы достигается обычно простановкой меток вначале кодированных цепочек. Такими метками могут быть, например, характерные значения битов в первом байте кодированной серии, значения первого байта кодированной серии и т.п.. Данные методы, как правило, достаточно эффективны для сжатия растровых графических изображений (BMP, PCX, TIF, GIF:), т.к. последние содержат достаточно много длинных серий повторяющихся последовательностей байтов. Недостатком метода RLE является достаточно низкая степень сжатия или стоимость кодирования файлов с малым числом серий и, что еще хуже - с малым числом повторяющихся байтов в сериях.
Сжатие без применения метода RLE
Процесс сжатия данных без применения метода RLE можно разбить на два этапа - моделирование (modelling) и собственно кодирование (encoding). Эти процессы и их реализующие алгоритмы достаточно независимы и разноплановы.
Как известно, применение сжатия данных позволяет более эффективно использовать емкость дисковой памяти. Не менее полезно применение сжатия при передачи информации в любых системах связи. В последнем случае появляется возможность передавать значительно меньшие (как правило, в несколько раз) объемы данных и, следовательно, требуются значительно меньшие ресурсы пропускной способности каналов для передачи той же самой информации. Выигрыш может выражаться в сокращении времени занятия канала и, соответственно, в значительной экономии арендной платы.
Научной предпосылкой возможности сжатия данных выступает известная из теории информации теорема кодирования для канала без помех, опубликованная в конце 40-х годов в статье Клода Шеннона "Математическая теория связи". Теорема утверждает, что в канале связи без помех можно так преобразовать последовательность символов источника (в нашем случае DTE) в последовательность символов кода, что средняя длина символов кода может быть сколь угодно близка к энтропии источника сообщений Н(Х), определяемой как:
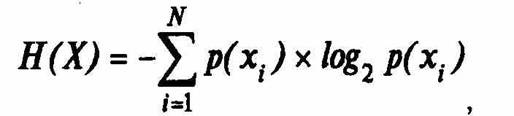
где p(xf) — вероятность появления конкретного сообщения .с, из N возможных символов алфавита источника. Число N называют объемом алфавита источника.
Энтропия источника Н(Х) выступает количественной мерой разнообразия выдаваемых источником сообщений и является его основной характеристикой. Чем выше разнообразие алфавита Х сообщений и порядка их появления, тем больше энтропия Н(Х) и тем сложнее эту последовательность сообщений сжать. Энтропия источника максимальна, если априорные вероятности сообщений и вероятности их выдачи являются равными между собой. С другой стороны, Н(Х)=0, если одно из сообщений выдается постоянно, а появление других сообщений невозможно.
Единицей измерения энтропии является бит. 1 бит — это та неопределенность,
которую имеет источник с равновероятной выдачей двух возможных сообщений,' обычно
символов "О" и "1".
Энтропия Н(Х) определяет среднее число двоичных знаков, необходимых
для кодирования исходных символов (сообщений) источника. Так, если исходными
символами являются русские буквы (N=32=2 ) и они передаются
равновероятно и независимо, то Н(Х)=5 бит. Каждую буквы можно
закодировать последовательностью из пяти двоичных символов, поскольку
существуют 32 такие последовательности. Однако можно обойтись и меньшим числом
символов на букву. Известно, что для русского литературного текста Я(Х)=1,5
бит, для стихов Н(Х)=\ ,0 бит, а для текстов телеграмм Н(.Х)=0,8
бит. Следовательно, возможен способ кодирования в котором в среднем на букву
русского текста будет затрачено немногим более 1,5, 1,0 или даже 0,8 двоичных
символов.
Если исходные символы передаются не равновероятно и не независимо, то
энтропия источника будет ниже своей максимальной величины Я^^(Х)=/о<7^У. В
этом случае возможно более экономное кодирование. При этом на каждый исходный
символ в среднем будет затрачено и*= Н(Х) символов кода. Для
характеристики достижимой степени сжатия используется коэффициент избыточности КИЗБ^^
—Н(Х)/Нмд^(Х). Для характеристики же достигнутой степени сжатия на
практике применяют так называемый коэффициент сжатия Кеж- Коэффициент
сжатия — это отношение первоначального размера данных к их размеру в сжатом
виде, — обычно дается в формате К.сж'-^- Путем несложных рассуждений
можно получить соотношение РИЗБ ^1—1 /^еж-Известные методы сжатия
направлены на снижение избыточности, вызванной как неравной априорной вероятностью
символов, так и зависимостью между порядком поступления символов. В первом
случае для кодирования исходных символов используется неравномерный код. Часто
появляющиеся символы кодируются более коротким кодом, а менее вероятные (редко
встречающиеся) — более длинным кодом.
Устранение избыточности, обусловленной корреляцией между символами, основано на
переходе от кодирования отдельных символов к кодированию групп этих символов.
За счет этого происходит укрупнение алфавита источника, так как число N тоже
растет. Общая избыточность при укрупнении алфавита не изменяется. Однако
уменьшение избыточности, обусловленной взаимными связями символов,
сопровождается соответствующим возрастанием избыточности, обусловленной
неравномерностью появления различных групп символов, то есть символов нового
укрупненного алфавита. Происходит как бы конвертация одного вида избыточности в
другой.
Таким образом, процесс устранения избыточности источника сообщений сводится к двум операциям — декорреляции (укрупнению алфавита) и кодированию оптимальным неравномерным кодом.
Сжатие бывает с потерями и без потерь. Потери допустимы при сжатии (и восстановлении) некоторых специфических видов данных, таких как видео и аудиоинформация. По мере развития рынка видеопродукции и систем мультимедиа все большую популярность приобретает метод сжатия с потерями MPEG 2 (Motion Pictures Expert Group), обеспечивающий коэффициент сжатия до 20:1. Если восстановленные данные совпадают с данными, которые были до сжатия, то имеем дело со сжатием без потерь. Именно такого рода методы сжатия применяются при передаче информации в СПД.
На сегодняшний день существует множество различных алгоритмов сжатия данных без потерь, подразделяющихся на несколько основных групп.
Этот метод является одним из старейших и наиболее простым. Он применяется в основном для сжатия графических файлов. Самым распространенным графическим форматом, использующим этот тип сжатия, является формат PCX. Один из вариантов метода RLE предусматривает замену последовательности повторяющихся символов на строку, содержащую этот символ, и число, соответствующее количеству его повторений. Применение метода кодирования повторов для сжатия текстовых или исполняемых (*.ехе, *.сот) файлов оказывается неэффективным. Поэтому в современных системах связи алгоритм RLE практически не используется.
В основе вероятностных методов сжатия (алгоритмов Шеннона-Фано (Shannon
Fano) и Хаффмена (Huffman)) лежит идея построения "дерева",
положение символа на "ветвях" которого определяется частотой его
появления. Каждому символу присваивается код, длина которого обратно
пропорциональна частоте появления этого символа. Существуют две разновидности
вероятностных методов, различающих способом определения вероятности появления
каждого символа:
> статические (static) методы, использующие фиксированную таблицу
частоты появления символов, рассчитываемую перед началом процесса сжатия;
> динамические (dinamic) или адаптивные (adaptive) методы,
в которых частота появления символов все время меняется и по мере считывания
нового блока данных происходит перерасчет начальных значений частот.
Статические методы характеризуются хорошим быстродействием и не требуют
значительных ресурсов оперативной памяти. Они нашли широкое применение в
многочисленных программах-архиваторах, например ARC, PKZIP и др., но для сжатия
передаваемых модемами данных используются редко — предпочтение отдается
арифметическому кодированию и методу словарей, обеспечивающим большую степень
сжатия.
Принципы арифметического кодирования были разработаны в конце 70-х годов В результате арифметического кодирования строка символов заменяется .[ействительным числом больше нуля и меньше единицы. Арифметическое кодирование позволяет обеспечить высокую степень сжатия, особенно в случаях, когда сжимаются данные, где частота появления различных символов сильно варьируется. Однако сама процедура арифметического кодирования требует мощных вычислительных ресурсов, и до недавнего времени этот метод мало применялся при сжатии передаваемых данных из-за медленной работы алгоритма. Лишь появление мощных процессоров, особенно с RISC-архитектурой, позволило создать эффективные устройства арифметического сжатия данных.
Алгоритм, положенный в основу метода словарей, был впервые описан в работах
израильских исследователей Якйба Зива и Абрахама Лемпеля, которые впервые
опубликовали его в 1977 г. В последующем алгоритм был назван Lempel-Ziv,
или сокращенно LZ. На сегодняшний день LZ-алгоритм и его модификации получили
наиболее широкое распространение, по сравнению с другими методами сжатия. В его
основе лежит идея замены наиболее часто встречающихся последовательностей
символов (строк) в передаваемом потоке ссылками на "образцы",
хранящиеся в специально создаваемой таблице (словаре). Алгоритм основывается на
том, что по потоку данных движется скользящее "окно", состоящее из
двух частей. В большей по объему части содержатся уже обработанные данные, а в
меньшей помещается информация, прочитанная по мере ее просмотра. Во время
считывания каждой новой порции информации происходит проверка, и если
оказывается, что такая строка уже помещена в словарь ранее, то она заменяется
ссылкой на нее.
Большое число модификаций метода LZ — LZW, LZ77, LZSS и др. — применяются для
различных целей, Так, методы LZW и BTLZ (British Telecom Lempel-Ziv)
применяются для сжатия данных по протоколу V.42bis, LZ77 — в утилитах Stasker и
DoudleSpase, а также во многих других системах программного и аппаратного
сжатия.
Методы сжатия данных имеют достаточно длинную историю развития, которая началась задолго до появления первого компьютера. В этой статье будет произведена попытка дать краткий обзор основных теорий, концепций идей и их реализаций, не претендующий, однако, на абсолютную полноту. Более подробные сведения можно найти, например, в Кричевский Р.Е. [1989], Рябко Б.Я. [1980], Witten I.H. [1987], Rissanen J. [1981], Huffman D.A.[1952], Gallager R.G. [1978], Knuth D.E. [1985], Vitter J.S. [1986] и др.
Сжатие информации - проблема, имеющая достаточно давнюю историю, гораздо более давнюю, нежели история развития вычислительной техники, которая (история) обычно шла параллельно с историей развития проблемы кодирования и шифровки информации. Все алгоритмы сжатия оперируют входным потоком информации, минимальной единицей которой является бит, а максимальной - несколько бит, байт или несколько байт. Целью процесса сжатия, как правило, есть получение более компактного выходного потока информационных единиц из некоторого изначально некомпактного входного потока при помощи некоторого их преобразования. Основными техническими характеристиками процессов сжатия и результатов их работы являются:
- степень сжатия (compress rating) или отношение (ratio) объемов исходного и результирующего потоков;
- скорость сжатия - время, затрачиваемое на сжатие некоторого объема информации входного потока, до получения из него эквивалентного выходного потока;
- качество сжатия - величина, показывающая на сколько сильно упакован выходной поток, при помощи применения к нему повторного сжатия по этому же или иному алгоритму.
Существует несколько различных подходов к проблеме сжатия информации. Одни имеют весьма сложную теоретическую математическую базу, другие основаны на свойствах информационного потока и алгоритмически достаточно просты. Любой способ подход и алгоритм, реализующий сжатие или компрессию данных, предназначен для снижения объема выходного потока информации в битах при помощи ее обратимого или необратимого преобразования. Поэтому, прежде всего, по критерию, связанному с характером или форматом данных, все способы сжатия можно разделить на две категории: обратимое и необратимое сжатие.
Под необратимым сжатием подразумевают такое преобразование входного потока данных, при котором выходной поток, основанный на определенном формате информации, представляет, с некоторой точки зрения, достаточно похожий по внешним характеристикам на входной поток объект, однако отличается от него объемом. Степень сходства входного и выходного потоков определяется степенью соответствия некоторых свойств объекта (т.е. сжатой и несжатой информации, в соответствии с некоторым определенным форматом данных), представляемого данным потоком информации. Такие подходы и алгоритмы используются для сжатия, например, данных растровых графических файлов с низкой степенью повторяемости байтов в потоке. При таком подходе используется свойство структуры формата графического файла и возможность представить графическую картинку приблизительно схожую по качеству отображения (для восприятия человеческим глазом) несколькими (а точнее n) способами. Поэтому, кроме степени или величины сжатия, в таких алгоритмах возникает понятие качества, т.к. исходное изображение в процессе сжатия изменяется, то под качеством можно понимать степень соответствия исходного и результирующего изображения, оцениваемая субъективно, исходя из формата информации. Для графических файлов такое соответствие определяется визуально, хотя имеются и соответствующие интеллектуальные алгоритмы и программы. Необратимое сжатие невозможно применять в областях, в которых необходимо иметь точное соответствие информационной структуры входного и выходного потоков. Данный подход реализован в популярных форматах представления видео и фото информации, известных как JPEG и JFIF алгоритмы и JPG и JIF форматы файлов.
Обратимое сжатие всегда приводит к снижению объема выходного потока информации без изменения его информативности, т.е. - без потери информационной структуры. Более того, из выходного потока, при помощи восстанавливающего или декомпрессирующего алгоритма, можно получить входной, а процесс восстановления называется декомпрессией или распаковкой, и только после процесса распаковки данные пригодны для обработки в соответствии с их внутренним форматом.
В обратимых алгоритмах кодирование как процесс можно рассматривать со статистической точки зрения, что еще более полезно, не только для построения алгоритмов сжатия, но и для оценки их эффективности. Для всех обратимых алгоритмов существует понятие стоимости кодирования. Под стоимостью кодирования понимается средняя длина кодового слова в битах. Избыточность кодирования равна разности между стоимостью и энтропией кодирования, а хороший алгоритм сжатия всегда должен минимизировать избыточность (напомним, что под энтропией информации понимают меру ее неупорядоченности.). Фундаментальная теорема Шеннона о кодировании информации говорит о том, что "стоимость кодирования всегда не меньше энтропии источника, хотя может быть сколь угодно близка к ней". Поэтому, для любого алгоритма, всегда имеется некоторый предел степени сжатия, определяемый энтропией входного потока.
Перейдем теперь непосредственно к алгоритмическим особенностям обратимых алгоритмов и рассмотрим важнейшие теоретические подходы к сжатию данных, связанные с реализацией кодирующих систем и способы сжатия информации.
Наиболее известный простой подход и алгоритм сжатия информации обратимым путем - это кодирование серий последовательностей (Run Length Encoding - RLE). Суть методов данного подхода состоит в замене цепочек или серий повторяющихся байтов или их последовательностей на один кодирующий байт и счетчик числа их повторений. Проблема всех аналогичных методов заключается лишь в определении способа, при помощи которого распаковывающий алгоритм мог бы отличить в результирующем потоке байтов кодированную серию от других - некодированных последовательностей байтов. Решение проблемы достигается обычно простановкой меток в начале кодированных цепочек. Такими метками могут быть, например, характерные значения битов в первом байте кодированной серии, значения первого байта кодированной серии и т.п. Данные методы, как правило, достаточно эффективны для сжатия растровых графических изображений (BMP, PCX, TIF, GIF), т.к. последние содержат достаточно много длинных серий повторяющихся последовательностей байтов. Недостатком метода RLE является достаточно низкая степень сжатия или стоимость кодирования файлов с малым числом серий и, что еще хуже - с малым числом повторяющихся байтов в сериях.
Процесс сжатия данных без применения метода RLE можно разбить на два этапа: моделирование (modelling) и, собственно, кодирование (encoding). Эти процессы и их реализующие алгоритмы достаточно независимы и разноплановы.
Под кодированием обычно понимают обработку потока символов (в нашем случае байтов или полубайтов) в некотором алфавите, причем частоты появления символов в потоке различны. Целью кодирования является преобразование этого потока в поток бит минимальной длины, что достигается уменьшением энтропии входного потока путем учета частот символов. Длина кода, представляющего символы из алфавита потока должна быть пропорциональна объему информации входного потока, а длина символов потока в битах может быть не кратна 8 и даже переменной. Если распределение вероятностей частот появления символов из алфавита входного потока известно, то можно построить модель оптимального кодирования. Однако, ввиду существования огромного числа различных форматов файлов задача значительно усложняется т.к. распределение частот символов данных заранее неизвестно. В таком случае, в общем виде, используются два подхода.
Первый заключается в просмотре входного потока и построении кодирования на основании собранной статистики (при этом требуется два прохода по файлу - один для просмотра и сбора статистической информации, второй - для кодирования, что несколько ограничивает сферу применения таких алгоритмов, т.к., таким образом, исключается возможность однопроходного кодирования "на лету", применяемого в телекоммуникационных системах, где и объем данных, подчас, не известен, а их повторная передача или разбор может занять неоправданно много времени). В таком случае, в выходной поток записывается статистическая схема использованного кодирования. Данный метод известен как статическое кодирование Хаффмена [Huffman].
Второй метод - метод адаптивного кодирования (adaptive coder method). Его общий принцип состоит в том, чтобы менять схему кодирования в зависимости от характера изменений входного потока. Такой подход имеет однопроходный алгоритм и не требует сохранения информации об использованном кодировании в явном виде. Адаптивное кодирование может дать большую степень сжатия, по сравнению со статическим, поскольку более полно учитываются изменения частот входного потока. Данный метод известен как динамическое кодирование Хаффмена [Huffman], [Gallager], [Knuth], [Vitter].
В статическом кодировании Хаффмена входным символам (цепочкам битов различной длины) ставятся в соответствие цепочки битов, также, переменной длины - их коды. Длина кода каждого символа берется пропорциональной двоичному логарифму его частоты, взятому с обратным знаком. А общий набор всех встретившихся различных символов составляет алфавит потока. Это кодирование является префиксным, что позволяет легко его декодировать результативный поток, т.к., при префиксном кодировании, код любого символа не является префиксом кода никакого другого символа - алфавит уникален.
Пример:
Пусть входной алфавит состоит из четырех символов: a, b, c, d, частоты которых в входном потоке равны, соответственно, 1/2, 1/4, 1/8, 1/8. Кодирование Хаффмена для этого алфавита задается следующей таблицей:
Например, кодом цепочки abaaacb, представленной на входе как 00 01 00 00 00 10 01, будет 0 10 0 0 0 110 10, соответственно - 14 бит на входе дали 11 бит на выходе. Кодирование по Хаффмену обычно строится и хранится в виде двоичного дерева, в "листьях" которого находятся символы, а на "ветвях" - цифры 0 или 1. Тогда уникальным кодом символа является путь от корня дерева к этому символу, по которому все 0 и 1 "собираются" в одну уникальную последовательность.
При использовании адаптивного кодирования Хаффмена усложнение алгоритма состоит в необходимости постоянной корректировки дерева и кодов символов основного алфавита в соответствии с изменяющейся статистикой входного потока.
Методы Хаффмена дают достаточно высокую скорость и умеренно хорошее качество сжатия. Эти алгоритмы давно известны и широко применяется как в программных (всевозможные компрессоры, архиваторы и программы резервного копирования файлов и дисков), так и в аппаратных (системы сжатия "прошитые" в модемы и факсы, сканеры) реализациях.
Однако, кодирование Хаффмена имеет минимальную избыточность при условии, что каждый символ кодируется в алфавите кода символа отдельной цепочкой из двух бит - {0, 1}. Основным же недостатком данного метода является зависимость степени сжатия от близости вероятностей символов к 2 в некоторой отрицательной степени, что связано с тем, что каждый символ кодируется целым числом бит. Так при кодировании потока с двухсимвольным алфавитом сжатие всегда отсутствует, т.к. несмотря на различные вероятности появления символов во входном потоке алгоритм фактически сводит их до 1/2.
Данная проблема, как правило, решается путем введения в алфавит входного потока новых символов вида "ab", "abc",. . . и т.п., где a, b, c - символы первичного исходного алфавита. Такой процесс называется сегментацией или блокировкой входного потока. Однако, сегментация не позволяет полностью избавиться от потерь в сжатии (они лишь уменьшаются пропорционально размеру блока), но приводит к резкому росту размеров дерева кодирования, и, соответственно, длине кода символов вторичных алфавитов. Так, если, например, символами входного алфавита являются байты со значениями от 0 до 255, то при блокировании по два символа мы получаем 65536 символов (различных комбинаций) и столько же листьев дерева кодирования, а при блокировании по три - 16777216! Конечно, при таком усложнении, соответственно возрастут требования и к памяти и ко времени построения дерева, а при адаптивном кодировании - и ко времени обновления дерева, что приведет к резкому увеличению времени сжатия. Напротив, в среднем, потери составят 1/2 бита на символ при отсутствии сегментации, и 1/4 или 1/6 бита соответственно при ее наличии, для блоков длиной 2 и 3 бита.
Совершенно иное решение предлагает т.н. арифметическое кодирование [Witten]. Арифметическое кодирование является методом, позволяющим упаковывать символы входного алфавита без потерь при условии, что известно распределение частот этих символов и является наиболее оптимальным, т.к. достигается теоретическая граница степени сжатия.
Предполагаемая требуемая последовательность символов, при сжатии методом арифметического кодирования, рассматривается как некоторая двоичная дробь из интервала [0, 1). Результат сжатия представляется, как последовательность двоичных цифр из записи этой дроби. Идея метода состоит в следующем: исходный текст рассматривается как запись этой дроби, где каждый входной символ является "цифрой" с весом, пропорциональным вероятности его появления. Этим объясняется интервал, соответствующий минимальной и максимальной вероятностям появления символа в потоке. Поясним работу метода на примере:
Пусть алфавит состоит из двух символов: a и b с вероятностями соответственно 3/4 и 1/4. К ак уже говорилось выше, кодирование Хаффмена не может упаковывать слова в данном алфавите, т.к. не справляется без сегментации с двухсимвольным алфавитом.
Рассмотрим наш интервал вероятностей [0, 1). Разобьем его на части, длина которых пропорциональна вероятностям символов. В нашем случае это [0, 3/4) и [3/4,1). Суть алгоритма в следующем: каждому слову во входном алфавите соответствует некоторый подинтервал из интервала [0, 1) а пустому слову соответствует весь интервал [0, 1). После получения каждого следующего символа интервал уменьшается с выбором той его части, которая соответствует новому символу. Кодом цепочки является интервал, выделенный после обработки всех ее символов, точнее, двоичная запись любой точки из этого интервала, а длина полученного интервала пропорциональна вероятности появления кодируемой цепочки.
Применим данный алгоритм для цепочки "aaba":
В качестве кода можно взять любое число из интервала, полученного на шаге 4, например, 0.1.
Алгоритм декодирования работает синхронно с кодирующим: начав с интервала [0, 1), он последовательно определяет символы входной цепочки. В частности, в нашем случае он вначале разделит (пропорционально частотам символов) интервал [0, 1) на [0, 0.11) и [0.11, 1). Поскольку число 0.0111 (код цепочки "aaba") находится в первом из них, можно получить первый символ: "a". Затем делим первый подинтервал [0, 0.11) на [0, 0.1001) и [0.1001, 0.1100) (пропорционально частотам символов). Опять выбираем первый, так как 0 " 0.0111 " 0.1001. Продолжая этот процесс, мы однозначно декодируем все четыре символа. Для того, чтобы декодирующий алгоритм мог определить конец цепочки, мы можем либо передавать ее длину отдельно, либо добавить к алфавиту дополнительный уникальный символ - "конец цепочки".
При разработке этого метода возникают две проблемы: во-первых, необходима арифметика с плавающей точкой, теоретически, неограниченной точности, и, во-вторых, - результат кодирования становится известен лишь при окончании входного потока. Однако, дальнейшие исследования показывают [Rubin], что можно практически без потерь обойтись целочисленной арифметикой небольшой точности (16-32 разряда), а также добиться инкрементальной работы алгоритма: цифры кода могут выдаваться последовательно по мере чтения входного потока при ограничении числа символов входной цепочки каким либо разумным числом.
Кодирование представляет собой лишь часть процесса упаковки. Как было показано, арифметическое кодирование имеет минимальную избыточность при заданном распределении символов входного потока. Но какой алфавит выбрать и каким соответствующим распределением воспользоваться? Ответы на эти вопросы дает построение модели входного потока, представляющей собой некоторый способ определения возможного распределения вероятностей появления каждого очередного символа в потоке. Каждого, поскольку статические модели (в которых распределение принимается неизменным), в большинстве случаев, не дают максимального качества сжатия. Гораздо больший интерес представляют так называемые адаптивные модели, учитывающие текущий контекст потока. Такие модели позволяют строить быстрые однопроходные алгоритмы сжатия, не требующие априорных знаний о входном потоке данных и строящие распределение "на лету". В отдельную группу выделяют также класс "локально адаптивных" алгоритмов, отдающих при построении распределения предпочтение некоторым особенным, например, последним поступившим символам.
Возможны различные подходы к этой проблеме: простейший из них - сбор статистики появления каждого символа независимо от других (моделирование источником Бернулли, при котором вероятность появления последующего символа не зависит от того, какие символы встретились перед ним). Возможно, также и использование марковских моделей: сбор статистики появления каждого символа в которых производится с учетом некоторого количества предыдущих появлявшихся символов (в марковском источнике первого порядка вероятность появления символа зависит только от одного последнего символа, второго - от двух и т. д.). Марковские модели могут давать более точную картину источника, однако число состояний в них больше, соответственно большим будет объем хранимых таблиц частот. Кроме того, при использовании кодирования Хаффмена они могут даже ухудшить качество сжатия, поскольку порождаемые ими вероятности обычно хуже приближаются степенями 1/2.
Здесь нельзя не упомянуть простой и достаточно эффективный метод кодирования источника с неизвестным распределением частот, известный как сжатие при помощи "стопки книг" или как сжатие сортировкой или хешированием. Метод был впервые открыт и исследован Рябко в 1980г., а затем переоткрыт Бентли, Слейтером, Тарьяном и Веи в 1986г. Идея метода состоит в следующем: пусть алфавит источника состоит из N символов с номерами 1, 2,..., N. Кодирующий алгоритм сохраняет последовательность символов, представляющую собой некоторую перестановку символов в последовательности первичного входного алфавита. При поступлении на вход некоторого символа c, имеющего в этой переставленной последовательности номер i, кодирующий алгоритм записывает код этого символа (например, монотонный код). Затем поступивший символ переставляется в начало последовательности и номера всех символов, стоящих перед c, увеличиваются на 1. Таким образом, наиболее часто встречающиеся символы будут переходить в начало списка и иметь более короткие коды, что в свою очередь снизит объем выходного потока при их записи в качестве символов выходного потока.
Все рассмотренные выше методы и модели кодирования предполагали в качестве входных данных цепочки символов (тексты) в некотором конечном алфавите. При этом оставался открытым вопрос о связи этого входного алфавита кодирующего алгоритма с данными, подлежащими упаковке (обычно также представленными в виде цепочек в алфавите (при байтовой организации обычно состоящем из 256 различных символов - значений байт).
В простейшем случае для кодирования в качестве входного алфавита можно использовать именно эти символы (байты) входного потока. Именно так работает метод squashing программы PKPAK (использовано статическое кодирование Хаффмена и двухпроходный алгоритм). Степень сжатия при этом относительно невелика - для текстовых файлов порядка 50%. Гораздо большей степени сжатия можно добиться при выделении из входного потока повторяющихся цепочек - блоков и кодирования ссылок на эти цепочки с построением хеш таблиц от первого до n-го уровня.
Метод, о котором и пойдет речь, принадлежит Лемпелю и Зиву, и обычно называется LZ-compression. Суть его состоит в следующем: упаковщик постоянно хранит некоторое количество последних обработанных символов в буфере. По мере обработки входного потока вновь поступившие символы попадают в конец буфера, сдвигая предшествующие символы и вытесняя самые старые. Размеры этого буфера, называемого также скользящим словарем (sliding dictionary), варьируются в разных реализациях кодирующих систем. Экспериментальным путем установлено, что программа LHArc использует 4-килобайтный буфер, LHA и PkZip - 8-ми, а ARJ - 16-килобайтный.
Затем, после построения хеш таблиц алгоритм выделяет (путем поиска в словаре) самую длинную начальную подстроку входного потока, совпадающую с одной из подстрок в словаре, и выдает на выход пару (length, distance), где length - длина найденной в словаре подстроки, а distance - расстояние от нее до входной подстроки (то есть фактически индекс подстроки в буфере, вычтенный из его размера). В случае, если такая подстрока не найдена, в выходной поток просто копируется очередной символ входного потока.
В первоначальной версии алгоритма предлагалось использовать простейший поиск по всему словарю. Время сжатия при такой реализации было пропорционально произведению длины входного потока на размер буфера, что совсем непригодно для практического использования. Однако, в дальнейшем, было предложено использовать двоичное дерево и хеширование для быстрого поиска в словаре, что позволило на порядок поднять скорость работы алгоритма.
Таким образом, алгоритм Лемпеля-Зива преобразует один поток исходных символов в два параллельных потока длин и индексов в таблице (length + distance). Очевидно, что эти потоки являются потоками символов с двумя новыми алфавитами, и к ним можно применить один из упоминавшихся выше методов (RLE, кодирование Хаффмена или арифметическое кодирование).
Так мы приходим к схеме двухступенчатого кодирования - наиболее эффективной из практически используемых в настоящее время. При реализации этого метода необходимо добиться согласованного вывода обоих потоков в один файл. Эта проблема обычно решается путем поочередной записи кодов символов из обоих потоков.
Данный алгоритм отличают высокая скорость работы как при упаковке, так и при распаковке, достаточно скромные требования к памяти и простая аппаратная реализация. Недостаток - низкая степень сжатия по сравнению со схемой двухступенчатого кодирования. Предположим, что у нас имеется словарь, хранящий строки текста и содержащий порядка от 2-х до 8-ми тысяч пронумерованных гнезд. Запишем в первые 256 гнезд строки, состоящие из одного символа, номер которого равен номеру гнезда. Алгоритм просматривает входной поток, разбивая его на подстроки и добавляя новые гнезда в конец словаря. Прочитаем несколько символов в строку s и найдем в словаре строку t - самый длинный префикс s. Пусть он найден в гнезде с номером n. Выведем число n в выходной поток, переместим указатель входного потока на length(t) символов вперед и добавим в словарь новое гнездо, содержащее строку t+c, где с - очередной символ на входе (сразу после t). Алгоритм преобразует поток символов на входе в поток индексов ячеек словаря на выходе. При размере словаря в 4096 гнезд можно передавать 12 бит на каждый индекс. Каждая распознанная цепочка добавляет в словарь одно гнездо. При переполнении словаря упаковщик может либо прекратить его заполнение, либо очистить (полностью или частично).
При практической реализации этого алгоритма следует учесть, что любое гнездо словаря, кроме самых первых, содержащих односимвольные цепочки, хранит копию некоторого другого гнезда, к которой в конец приписан один символ. Вследствие этого можно обойтись простой списочной структурой с одной связью.
От алгоритмов сжатия к форматам файлов, программам паковщикам и архиваторам.
Конечно, для системы сжатия информации хороший алгоритм - первоочередной, но не единственный больной вопрос. Конечному пользователю, как правило, нет дела до принципов организации функционирования и внутренней структуры используемых им программ, лишь бы работали качественно. Под качеством систем сжатия принято понимать несколько критериев, которые определяются применением при ее реализации и конкретном использовании. Так большинство применений необратимого сжатия лежит в области технологии хранения графической информации - картинки и видео, что, в свою очередь локализует алгоритм в рамках одного файла для одного стандарта и характера входного потока. Однако, на практике, из-за экономии места на накопителях, возникает необходимость сжатия любого файла (в том числе и выполнимого модуля). Эту проблему решают паковщики. И, наконец, проблему сжатия нескольких файлов и даже всех файлов каталогов и дисков решают программы - архиваторы. Заметим, что в список возможных задач архиваторов входит не только сжатие/извлечение информации файлов различных форматов, но и сохранение дерева файловой системы, атрибутов файлов, их имен, некоторой комментирующей информации, создание самораспаковывающихся архивов, архивация с сохранением кодов циклического контроля ошибок, для гарантии абсолютного соответствия извлеченных файлов исходным файлам, шифровку данных архива и архивация с паролем, обеспечение пользователя удобным интерфейсом и др. Поэтому, архиваторы являются одной из самых сложных систем программ. В настоящее время, к вышеперечисленным задачам можно пожелать наличия некоторых необязательных, но удобных свойств и возможностей. Это конфигурируемость пакета, наличие развитого оконного интерфейса, а не интерфейса командной строки, настраиваемость на определенный тип информации, сохранение параметров в файле архива, создание многотомных и/или самоизвлекающихся архивов и др. Все это желательно иметь при малой длине файла архиватора. Между программами паковщиками и архиваторами обычно не имеется принципиальных различий, однако, паковщики упаковывают информацию одного файла в один файл, а архиваторы образуют один файл выходного потока, который, впрочем, может быть автоматически нарезан на файлы равной длины для записи на гибкие диски. Отдельную группу составляют программы паковщики, занимающиеся сжатием выполнимых модулей и дисков. Также упаковку данных при помощи алгоритмов сжатия используют системы резервного копирования, сжатия устройств (логических дисков MS-DOS), факс-модемные драйверы и утилиты и др.
В настоящий момент на рынке программных продуктов и серверах программного обеспечения можно встретить достаточно большое число архивирующих и сжимающих утилит, большинство из которых доступны для некоммерческого использования. Такая доступность, прежде всего, связана с тем, что каждая, даже коммерческая, программа нуждается в обширном рынке пользователей. А поскольку форматы файлов архиваторов и паковщиков, даже использующих один и тот же алгоритм, не одинаковы, то такие программы невольно конкурируют за рынок пользователей. С этим также связано и то, что поддержка более популярных форматов файловых архивов начинает включаться в другие утилиты и программы и используемые форматы становятся стандартными форматами архивов (zip, arj, rar, ha, pak, cab и др.). Стандартный формат подразумевает исключительную легкость при поиске программы, необходимой для извлечения файлов из сжатого состояния и поддержку их другими программами.
Нами были проанализированы более 300 архиваторов и паковщиков и отобраны наиболее интересные. Тесты сжатия производились на ПК Intel Pentium 233MHz с RAM 64Mb под управлением ОС MS-Windows 95 (4.0.1111). Для тестирования использовались 7 файлов с совокупным размером 8646421 байт. В архиве содержались как текстовые (txt 643830), графические (bmp 2233560, psd 959170), двоичные (exe 4014592, dll 352256) и мультимедийные (avi 342420, mid 100593) файлы. Архивация производилась при работе в фоновом режиме из под оболочки FAR 1.52. Для измерения времени использовалась команда time. Файлы сжимались с жесткого диска на жесткий диск. Необходимо отметить, что в качестве опций для сжатия использовались параметры для наилучшего сжатия каждого файла, а в случае наличия у программы специальных параметров, определяющих сжатие файлов строго определенного формата, при его тестировании они также использовались. Результаты лучших экземпляров сведены нами в таблицу. Данные в таблице отсортированы в порядке ухудшения коэффициента сжатия, а ratio показывает, сколько процентов объема осталось после сжатия.
Как видно из приведенных результатов, в общем зачете -
быстродействие/коэффициент сжатия победителями вышли IMP и UHARC. Абсолютными
чемпионами по сжатию стали ACB и UHARC, а по
скорости - AIN,
однако, медленнее всех оказался ACB, затем идет BOA и
UHARC. Наш
привычный RAR
занимает достаточно высокое место по скорости и относительно скромную позицию
по сжатию, однако, это единственная из включенных нами в таблицу программ,
имеющая оконно-ориентированный пользовательский интерфейс. Работа с остальными
программами осуществляется посредством задания параметров в командной строке
или файле.
................
Несмотря на то, что в наше время цена мегабайта дискового пространства уменьшается с каждым годом, а качество носителей информации растет, потребность в архивации и резервном копировании остается, а проблема все также актуальна, как и десять лет назад. Это определяется тем, что архивация и сжатие данных необходимы не только для экономии места на локальном дисковом носителе, но и для переноса информации, резервирования, резервного копирования и т.п. Поэтому, выбирая архиватор, необходимо руководствоваться его универсальностью и надежностью, но не забывать конечно и о главных параметрах - качество и скорость сжатия. Среди имеющихся в настоящий момент архиваторов многие являются специфичными к определенным форматам файлов, что несомненно следует использовать, но по назначению. Общий оценочный анализ показывает, что среди архиваторов с ratio <40% большинство имеет значительно более длительное время паковки, которое может быть настолько велико (отличаться в сотни раз) по сравнению с выигрышем в сжатии (на 7-10%), что целесообразность использования данных программ сомнительна даже на очень мощных персональных компьютерах, таких как Pentium II 330MHz. Угнетает и тот факт, что большинство систем сжатия по прежнему компонуются как выполнимые модули реального режима для ОС MS-DOS и все возможности защищенного режима не используются. Этот же относится и к интерфейсу программ, который в общем оставляет желать лучшего, т.к. командная строка, хоть и является достаточно универсальным средством взаимодействия пользователя с программами, однако, весьма плохо приспособлена для быстрого просмотра списков имен, множественного выбора из списков (например файлов в архиве), множественного помещения в список и т.п., т.е. для операций, наиболее часто встречающихся в процессе работы с архивами. Возражающим посоветую произвести такую операцию, замерив затраченное на нее время. Возьмите архив из ~500 файлов с различными расширениями и извлеките из него 20-30 файлов, причем имена которых определите во время просмотра содержимого архива. Выполните эту задачу при помощи командной строки и при помощи какого-нибудь оконного интерфейса. Такие и подобные операции пользователями интерфейсов командной строки обычно выполняются путем извлечения всех файлов из архива и удаления ненужных или переписывания необходимых в отдельный каталог, их архивация и удаление. Нет нужды говорить, что такая операция с применением оконного интерфейса и списков с возможностью множественного выбора элементов по маске производится гораздо быстрее и без затрат дополнительных дисковых ресурсов.
Из стандартных и наиболее полезных на текущий момент свойств программ архиваторов следует также отметить следующие:
Автор рекомендует использовать архиватор, если он отвечает большинству, если не всем, приведенным выше пожеланиям, а также имеет оконный интерфейс и разработан для различных сред и платформ. Немаловажно при выборе архиватора учитывать совместимость распространенность и возможную дальнейшую поддержку авторами новых версий, т.к. оказавшись "один на один" со старой версией и множеством архивов, рано или поздно придет время, когда потребуется переархивировать все архивы.
Из попавших в рамки наших тестов, таким рекомендациям соответствует лишь RAR и WinRAR, а среди остальных - PkZip, WinZIP, ARJ, LHA и GZIP. Эти программы и стандарты поддерживаются большинством файловых менеджеров, для них написано множество оболочек и управляющих командных файлов.
Не забывайте, индустрия и теория сжатия информации постоянно развиваются. Поэтому не за горами появление еще более мощных и удобных в использовании программ и алгоритмов.
1. ОБЩИЕ ПОНЯТИЯ ОБ АРХИВАЦИИ ДАННЫХ
С развитием информационных технологий остро встал вопрос относительно способов хранения данных. Начиная с сороковых годов 20 ст., ученые разрабатывают методы представления данных, использование которых бы пространство на носителях информации использовалось экономнее. Результатом этих исследований стала технология сжатия и архивации данных (backup).
Архивация данных – это объединение нескольких файлов или каталогов в один файл – архив. Сжатие данных – это уменьшение объема выходных файлов путем удаления избыточной информации.
Для выполнения этих заданий используются так называемые программы-архиваторы, которые обеспечивают как архивацию, так и сжатие данных. С помощью специальных алгоритмов архиваторы удаляют из файлов всю избыточную информацию, а при обратных операциях распаковки они обновляют информацию, представляя ее в первичном виде. При этом сжатие и обновление информации производится без потерь. Сжатие без потерь является актуальным при работе с текстовыми и программными файлами, в задачах криптографии.
Существуют также методы сжатия с потерями. Они удаляют из потока информацию, которая незначительно влияет на данные или вообще не воспринимается человеком. Эти методы сжатия используются для аудио- и видеофайлов, некоторых форматов графических файлов.
Методы сжатия без потерь
На сегодняшний день разработано множество способов сжатия без потерь, в основе их лежат такие методы кодирования:
Ø Групповое кодирование RLE (Run Lengs Encoding) – один из самых старых методов сжатия, который используют в основном для архивации графики.
Ø Кодирование Хаффмана (Huffman) – в основе лежит тот факт, что некоторые символы в тексте могут попадаться чаще средней частоты повторений, а другие - реже.
Ø Кодирование Лемпеля – Зива (Lempel, Ziv) – использует факт неоднократного повторения фрагментов текста, т. е. последовательностей байтов.
Ø Уменьшение объема файлов. Эта функция выполняется с помощью методов сжатия, которые были рассмотрены выше. Уменьшение файлов актуально не только для экономии свободного места на дисках, но и для быстрой передачи файлов по сети.
Ø Резервное копирование. В процессе эксплуатации компьютера не исключены ситуации, которые угрожают невозвратимой потерей информации (неисправность устройства накопления или дефекты на поверхности жесткого диска, неправильные операции с файлами или случайное удаление файлов, или уничтожение информации компьютерным вирусом). Для сохранения важной информации используется резервное копирование на внешние носители (магнитооптические диски, диски CD – R и CD – RW, винчестеры). Резервное копирование выполняется с помощью специальных утилит, которые обеспечивают создание компактных архивов. Одна из таких утилит входит в комплект Windows.
Ø Архивация при шифровании данных. Эта операция выполняется с целью уменьшения вероятности взлома криптосистемы. Доказано, что чем меньше корреляция (связь) между блоками выходной информации, тем ниже вероятность взлома. Процедура архивации, уменьшая избыточную информацию, ликвидирует корреляции в выходном пакете.
В программах архиваторах используются специальные термины и высказывания:
Ø Add file – добавление файла в архив. Если архив не существует, то он создается.
Ø Extract files – извлечение файла из архива.
Ø Fresh files – добавление в архив новых версий файлов, которые там уже есть.
Ø Move files – перемещение файла в архив.
Ø Multiple volumes - многотомные архивы, которые состоят из нескольких файлов (томов). Они обычно создаются для записи архивных файлов на отдельные дискеты.
Ø Ratio – степень сжатия файла, которая может определяться как отношение исходного объема файла к сжатому или наоборот (в зависимости от программы-архиватора).
Ø Self-extract (SFX) archive – самораспаковывающийся архив, который является архивным файлом с расширением exe или com. После запуска данного файла происходит автоматическое извлечение содержимого архива. Термин SFX обозначает буквально «самоизвлечение».
Ø Solid archive – непрерывный архив, который обычно создается из нескольких похожих файлов. Содержимое данных файлов рассматривается как один непрерывный поток данных. Благодаря возможным повторениям достигается большее сжатие, чем при раздельной упаковке файлов. Непрерывные архивы могут и занимать на треть меньше места, чем обычные архивы. Недостатком непрерывных архивов является их большая уязвимость (при повреждении архива не открывается ни один файл). Кроме того, такие архивы распаковываются очень медленно.
Ø Update files – добавление в архив новых файлов.
24.05.2010
Среди всех функций архива выделяют пять самых основных функций – это управление документами, учет, обеспечение полной сохранности, создание научно-справочного аппарата, управление документами, которые находятся в архивах.
Обеспечение полной безопасности над созданием и оформлением дел в процессе работы учреждения.
Аналогично с задачами, которые возлагаются на архив, могут выполняться следующие функции:
К дополнительным функциям диспетчеров архивов относятся сервисные функции, делающие работу более удобной. Они часто реализуются внешним подключением дополнительных служебных программ и обеспечивают:
Информационная безопасность
1.Понятие угрозы информационной безопасности. Виды угроз и противодействий. Вредоносное ПО.
Информационная безопасность (в узком смысле) – защита собственных
информационных ресурсов.
Информационная безопасность (в широком смысле) – защита отдельных людей,
сотрудников, общества от воздействия вредоносной информации.
Любое технологическое, в том числе и информационное, новшество, предоставляющее
возможность решения определенных социальных проблем, порождает новые проблемы и
становится источником потенциальной опасности. Если своевременно не
позаботиться о нейтрализации негативных факторов, то эффект от внедрения новых
технологий может оказаться отрицательным – неправомерное разглашение
конфиденциальной информации, уничтожение, искажение, фальсификация информации
так же как и дезорганизация процессов обработки могут нанести ущерб многим.
Жизненно важно, чтобы информационные отношения были легко доступны по мере
востребованности и надёжно защищены от несанкционированного доступа. Острота
проблемы информационной безопасности возрастает в силу ряда объективных причин:
• В связи с расширением сферы применения растёт уровень доверия к
автоматизированным информационным системам (АИС);
• Изменяется подход к сущности информации (под ней теперь понимается товар,
стоимость которого существенно превосходит стоимость участвующих в его создании
технических средств). По этой причине на область создания информационных
объектов и предоставления информационных услуг влияют характерные для рынка
явления (например, конкуренция);
• Распространение вычислительных сетей, позволяющих осуществлять удалённый доступ
к совместно используемым информационным ресурсам > Участились вмешательства
в работу этих сетей;
• Несовершенны законодательные акты и правовые нормы, защищающие субъекты
информационной деятельности, в сфере компьютерных преступлений нет достаточного
количества специалистов.
Физические и юридические лица (субъекты) могут находиться в различных
отношениях с информацией (информационных отношениях), подразумевающих действия
(обработку, хранение, ...) над информационными объектами (сообщениями, базами
данных, файлами, ...). По отношению к последним субъекты могут разделяться на
источники информации, пользователей, собственников: владельцев и
распорядителей, различающихся в правах и доступе – лица, о которых собирается
информация (образуют особый вид данных: личные/конфиденциальные, которые нельзя
тиражировать и использовать без согласия объектов), владельцев систем сбора,
обработки, передачи данных. Для успешного осуществления своих намерений
субъекты добиваются своевременного доступа либо сохранения в тайне части
информации, либо подтверждения достоверности, либо защиты от ложной информации,
либо контроля за процессами получения, обработки, тиражирования информации. При
этом субъект является потенциально уязвимым с точки зрения нанесения им
определенного ущерба, поэтому рассмотрение вопросов информационной безопасности
подразумевает учёт ущерба, который может быть нанесён этому субъекту.
Основными свойствами информации, на которые направлены информационные угрозы,
являются:
? Доступность, Д. Свойство системы, в которой циркулируют данные,
характеризующее способность своевременного обеспечения доступа субъектов к
интересующей их информации, а также готовность АИС к обслуживанию запросов
объектов, когда есть необходимость получения информации.
? Целостность, Ц. Неизменность при транзакции данных. Это свойство
информационных объектов, заключающееся в их существовании в неизменном виде по
отношению к определённому периоду времени, поддержании адекватного состояния
относительно установленного регламента, сохранении полноты и точности данных.
? Конфиденциальность, К. Субъективно определяемая характеристика информационных
объектов, указывающая на необходимость ограничения круга субъектов, имеющих
доступ к информационным объектам. Нарушение свойства может произойти через
разглашение или утечку (лишение статуса закрытости против воли хозяина данных).
Виды угроз: естественные (связанные со стихийными бедствиями), техногенные
(сбои), человеческие случайные, человеческие преднамеренные. Цель любой угрозы:
получение информации, уничтожение её, модификация, создание препятствий в
доступе к ней. Направления связаны с нарушением одного из трёх свойств.
Объектами могут быть отдельные файлы и документы, базы данных, носители,
средства обработки, персонал.
Система защиты состоит из нескольких эшелонов (рис 1): Правовой защиты (законы,
акты, правила), Организационной защиты (регламентирование работы),
Инженерно-технической защиты (программы, шифрование, фильтры). Цели системы
защиты: уменьшение ущерба для объектов, ликвидация последствий и восстановление
работоспособности способами мониторинга, пресечения и противодействия.
Ущерб – негативный эффект от реализации информационной угрозы. Оценка ущерба
осуществляется при помощи расчёта рисков , где Ру – вероятность осуществления
угрозы, Ря – уязвимость объекта, Sо – величина ущерба (предполагается
категоризация объектов, для чего используются номинальные оценки свойств
объектов (Д, Ц, К) . Альтернативой изучению рисков являются типовые решения
построения систем защиты.
Объекты подразделяются на критически важные и объекты общего назначения
(различаются по значимости и конфиденциальности). Модель важности является
нелинейной, аддитивной. Уязвимость объектов зависит от надёжности системы
защиты, если мер не предусмотрено, то Ря=1, иначе оценка производится при
помощи специальных таблиц.
Словосочетание "информационная безопасность" в разных контекстах может иметь различный смысл. В Доктрине информационной безопасности Российской Федерации термин "информационная безопасность" используется в широком смысле. Имеется в виду состояние защищенности национальных интересов в информационной сфере, определяемых совокупностью сбалансированных интересов личности, общества и государства.
В Законе РФ "Об участии в международном информационном обмене" (закон утратил силу, в настоящее время действует "Об информации, информационных технологиях и о защите информации") информационная безопасность определяется аналогичным образом – как состояние защищенности информационной среды общества, обеспечивающее ее формирование, использование и развитие в интересах граждан, организаций, государства.
В данном курсе наше внимание будет сосредоточено на хранении, обработке и передаче информации вне зависимости от того, на каком языке (русском или каком-либо ином) она закодирована, кто или что является ее источником и какое психологическое воздействие она оказывает на людей. Поэтому термин "информационная безопасность" будет использоваться в узком смысле, так, как это принято, например, в англоязычной литературе.
Под информационной безопасностью мы будем понимать защищенность информации и поддерживающей инфраструктуры от случайных или преднамеренных воздействий естественного или искусственного характера, которые могут нанести неприемлемый ущерб субъектам информационных отношений, в том числе владельцам и пользователям информации и поддерживающей инфраструктуры. (Чуть дальше мы поясним, что следует понимать под поддерживающей инфраструктурой.)
Защита информации – это комплекс мероприятий, направленных на обеспечение информационной безопасности.
Таким образом, правильный с методологической точки зрения подход к проблемам информационной безопасности начинается с выявления субъектов информационных отношений и интересов этих субъектов, связанных с использованием информационных систем (ИС). Угрозы информационной безопасности – это оборотная сторона использования информационных технологий.
Из этого положения можно вывести два важных следствия:
Возвращаясь к вопросам терминологии, отметим, что термин "компьютерная безопасность" (как эквивалент или заменитель ИБ ) представляется нам слишком узким. Компьютеры – только одна из составляющих информационных систем, и хотя наше внимание будет сосредоточено в первую очередь на информации, которая хранится, обрабатывается и передается с помощью компьютеров, ее безопасность определяется всей совокупностью составляющих и, в первую очередь, самым слабым звеном, которым в подавляющем большинстве случаев оказывается человек (записавший, например, свой пароль на "горчичнике", прилепленном к монитору).
Согласно определению информационной безопасности, она зависит не только от компьютеров, но и от поддерживающей инфраструктуры, к которой можно отнести системы электро-, водо- и теплоснабжения, кондиционеры, средства коммуникаций и, конечно, обслуживающий персонал. Эта инфраструктура имеет самостоятельную ценность, но нас будет интересовать лишь то, как она влияет на выполнение информационной системой предписанных ей функций.
Обратим внимание, что в определении ИБ перед существительным "ущерб" стоит прилагательное "неприемлемый". Очевидно, застраховаться от всех видов ущерба невозможно, тем более невозможно сделать это экономически целесообразным способом, когда стоимость защитных средств и мероприятий не превышает размер ожидаемого ущерба. Значит, с чем-то приходится мириться и защищаться следует только от того, с чем смириться никак нельзя. Иногда таким недопустимым ущербом является нанесение вреда здоровью людей или состоянию окружающей среды, но чаще порог неприемлемости имеет материальное (денежное) выражение, а целью защиты информации становится уменьшение размеров ущерба до допустимых значений.
Cистемы хранения данных
|
|
|
Для того чтобы повысить эффективность управления и свести к минимуму расходы, предприятия и организации стремятся оптимизировать существующие бизнес-процессы. Наиболее важным активом при этом становится информация, доступность и актуальность которой является ключевым фактором успеха в конкурентной среде. Такая ситуация стимулирует широкомасштабное развитие технологий хранения данных.
Современная система хранения данных обеспечивает надежное хранение информационных ресурсов и обеспечивает доступ к ним. В состав системы входят дисковые массивы, инфраструктура доступа к ним и программные комплексы управления хранением данных.
Сетевое хранение данных
На инфраструктуру доступа к устройствам хранения данных возлагается ответственность за доступность информации для приложений и конечных пользователей, поэтому эта составляющая систем хранения данных развивается наиболее динамично. Вместо традиционного прямого подключения дисковых массивов к серверам (DAS – Direct Attached Storage) появились и нашли широкое применение технологии, основанные на использовании сети в качестве инфраструктуры доступа к данным. Технология SAN (Storage Area Network) использует выделенную сеть на основе протокола Fibre Channel и производит обмен данными на уровне блоков. Устройства NAS (Network Attached Storage), являющиеся, по существу, специализированными файл-серверами, в качестве транспорта задействует существующие IP-сети и оперирует на уровне файлов. Наилучшим вариантом представляется одновременное использование SAN и NAS, при котором способ доступа к данным определяется исходя из конкретных требований.
Основными преимуществами сетевого хранения данных являются:
В настоящее время основной топологией, применяемой при построении SAN, является коммутируемая архитектура (FC_SF – switch fabric), использование которой позволяет увеличить адресуемость до 16 млн. устройств, размеры области досягаемости данных и готовность всей сети хранения в целом.
По мере роста объема данных применение SAN становится наиболее оправданным решением с экономической точки зрения. Сегодня стоимость внедрения сетей хранения данных ненамного отличается от стоимости систем хранения с прямым подключением. В дальнейшем высокая масштабируемость SAN позволит снизить стоимость хранения информации.
Компания Открытые Технологии рассматривает внедрение сетей хранения данных как одно из наиболее перспективных направлений развития корпоративных информационных систем. Нашими партнерами являются лидеры в области построения SAN – компании Brocade Communication Systems, EMC2, Sun Microsystems, Hitachi Data Systems, VERITAS и BMC Software.
Репликация данных
Репликация данных обеспечивает выполнение большого числа задач, наиболее актуальными из которых являются:
Репликация данных может быть осуществлена встроенными средствами программных комплексов, однако в этом случае организация централизованного процесса репликации невозможна. Кроме этого, репликация данных на уровне приложений порождает дополнительные нагрузки на вычислительные мощности серверов. Для устранения этих недостатков применяются специализированные программные репликаторы или используются аппаратные средства репликации данных.
Вне зависимости от способа репликации может быть применен один из двух режимов – синхронный либо асинхронный. Синхронный режим репликации обеспечивает абсолютную актуальность данных, но требует применения высокопроизводительной коммуникационной инфраструктуры, например, внедрения SAN.
Резервирование данных
Эффективным способом избежать потерь информации, возникающих вследствие сбоев, служит зеркалирование. Однако при помощи зеркалирования данных невозможно устранить первопричину потерь – ошибочные действия пользователей. Резервное копирование данных позволяет избежать потерь как в случае программных или аппаратных сбоев, так и возникающих вследствие ошибок операторов.
При построении систем резервного копирования и восстановления данных требуют решения две важнейшие задачи:
Время останова приложений возможно свести к минимуму, применяя специальные методы, такие как создание моментальных копий (snapshots). Моментальная копия – это «снимок» состояния и запись местонахождения данных. С помощью этой информации данные могут быть восстановлены в случае потери или повреждения. Создание моментальной копии требует останова приложения, однако время простоя исчисляется секундами.
С применением коммутируемой архитектуры SAN процессы резервного копирования и восстановления данных могут быть организованы без использования ресурсов локальной сети (внесетевое резервное копирование – LAN-free backup), а также серверов (внесерверное копирование – server-free backup). Кроме этого, благодаря централизованной схеме резервирования данных сокращается число устройств (ленточных накопителей, и т.п.), участвующих в процессе.
При внесетевом резервном копировании данные с дисковых массивов транспортируются внутри SAN, на ленточные накопители, подключенные непосредственно к сети хранения.
При внесерверном копировании данные перемещаются с устройств хранения на ленточные накопители без прямого участия серверов – обмен данными происходит непосредственно между устройствами хранения внутри SAN на уровне блоков данных, однако при необходимости возможно пофайловое восстановление информации. Главное преимущество внесерверного копирования заключается в высвобождении вычислительных серверных ресурсов.
Большинство веб-приложений ASP.NET тем или иным образом используют доступ к данным. Многие приложения аккумулируют данные в базе данных или файле, а хранимые данные часто основаны на сведениях, предоставленных пользователями. Поскольку исходные данные могут поступать из ненадежных источников, а информация хранится длительное время и необходимо быть уверенным в том, что неавторизованные пользователи не смогут получить непосредственный доступ к данным, требуется уделить особое внимание проблеме безопасности доступа к данным. В этом разделе приводятся рекомендации, которые помогут повысить безопасность доступа к данным в веб-приложении ASP.NET.
Предлагаемые рекомендации в отношении конфигурации и кодирования помогут повысить безопасность приложений. Но не менее важно на постоянной основе следить за тем, чтобы на веб-сервере были установлены последние обновления для системы безопасности Microsoft Windows и служб IIS, а также обновления для системы безопасности Microsoft SQL Server или другого программного обеспечения, обеспечивающего доступ к источникам данных.
Более подробные советы и рекомендации по написанию безопасного кода и защите приложений приведены в книге «Защищенный код» Майкла Ховарда и Дэвида Леблана, а также на веб-узле Шаблоны и методики Майкрософт (на английском языке).
Обеспечение безопасного доступа к источнику данных
В следующих подразделах содержатся сведения, которые поясняют различные аспекты безопасности доступа к данным.
Для соединения с базой данных требуется строка подключения. Поскольку строки подключения могут содержать конфиденциальные данные, необходимо придерживаться следующих правил:
· Не храните строки подключения на странице. Например, избегайте установки строк подключения в декларативных свойствах элемента управления SqlDataSource или других элементов управления источниками данных. Вместо этого храните строки подключения в файле Web.config веб-узла. Пример см. в разделе Практическое руководство. Безопасность строк подключения при использовании элементов управления источником данных.
· Не храните строки подключения в виде обычного текста. Чтобы обеспечить безопасность подключения к серверу базы данных, рекомендуется зашифровать строку подключения в файле конфигурации, воспользовавшись защищенной конфигурацией. Дополнительные сведения см. в разделе Шифрование сведений о конфигурации с помощью функции защищенной конфигурации.
По возможности следует подключаться к экземпляру SQL Server с помощью встроенных средств безопасности вместо явного задания имени пользователя и пароля. Это позволит избежать риска раскрытия строки соединения, идентификатора пользователя и пароля.
Рекомендуется, чтобы удостоверением процесса (например, пула приложений), который выполняет приложения ASP.NET, являлась учетная запись для процессов по умолчанию или учетная запись пользователя с ограниченными правами. Дополнительные сведения см. в разделе Олицетворение ASP.NET.
В сценариях, где различные веб-узлы подключаются к разным базам данных SQL Server, может оказаться нецелесообразным использовать встроенные средства безопасности. Например, при предоставлении услуги размещения веб-узлов каждому клиенту обычно назначается отдельная база данных SQL Server, но все пользователи работают с веб-сервером как анонимные пользователи. В таких случаях требуется явное указание учетных данных для подключения к экземпляру SQL Server. Убедитесь, что учетные данные хранятся безопасным образом, как описано в подразделе Строки подключения.
Рекомендуется назначать минимальные разрешения идентификатору пользователя, с помощью которого выполняется подключение к базе данных SQL Server приложения.
Элементы управления с привязкой к данным могут поддерживать разнообразные операции с данными, включая выбор, вставку, удаление и обновление записей в таблицах данных. Рекомендуется настраивать элементы управления данными на выполнение минимальных функций, требующихся странице или приложению. Например, если элемент управления не должен позволять пользователям удалять данные, не включайте с элементом управления источником данных запрос на удаление и не разрешайте удаление в этом элементе управления.
Когда процесс подключается к базе данных SQL Server, экспресс-выпуск (к MDF-файлу), он должен иметь права администратора. В общем, это делает базы данных SQL Server, экспресс-выпуск непрактичными для разработки веб-узлов, так как процесс ASP.NET не выполняется (и не должен) с правами администратора. Поэтому используйте базы данных SQL Server, экспресс-выпуск только при соблюдении следующих условий:
· База данных используется в качестве тестовой при разработке веб-приложения. Когда приложение будет готово для развертывания, следует перенести базу данных с SQL Server, экспресс-выпуск в рабочий экземпляр SQL Server.
· База данных используется в составе веб-узла, поддерживающего олицетворение и позволяющего управлять правами олицетворяемого пользователя. Эта стратегия действенна, только если приложение работает в локальной сети (не на общедоступном веб-узле).
· Храните файл MDF в папке App_Data веб-узла, поскольку содержимое этой папки не будет возвращено в ответ на прямой HTTP-запрос. Следует также сопоставить расширение MDF с ASP.NET в службах IIS и в обработчике ASP.NET HttpForbiddenHandler с помощью следующего элемента в файле Web.config веб-узла:
· <httpHandlers>
· <add verb="*" path="*.mdf" type="System.Web.HttpForbiddenHandler" />
· </httpHandlers>
Сведения о том, как сопоставить в службах IIS расширение имени файла с ASP.NET см. в разделе Практическое руководство. Регистрация обработчиков HTTP-данных.
Базы данных Microsoft Access (файлы MDB) имеют меньше возможностей по обеспечению безопасности, чем базы данных SQL Server. Базы данных Microsoft Access не рекомендуются для создания веб-узлов. Однако, если есть причины использовать MDB-файл как часть веб-приложения, придерживайтесь следующих правил:
· Храните MDB-файл в папке App_Data веб-узла, поскольку содержимое этой папки не будет возвращено в ответ на прямой HTTP-запрос. Следует также сопоставить расширение MDB с ASP.NET в службах IIS и в обработчике ASP.NET HttpForbiddenHandler с помощью следующего элемента в файле Web.config веб-узла:
· <httpHandlers>
· <add verb="*" path="*.mdb" type="System.Web.HttpForbiddenHandler" />
· </httpHandlers>
Сведения о том, как сопоставить в службах IIS расширение имени файла с ASP.NET см. в разделе Практическое руководство. Регистрация обработчиков HTTP-данных.
· Добавьте соответствующие права для учетной записи пользователя или тех учетных записей, которые будут выполнять операции чтения и записи файла MDB. Если веб-узел поддерживает анонимный доступ, то, как правило, это будет локальная учетная запись ASPNET или учетная запись NETWORK SERVICE. Поскольку Microsoft Access создает LDB-файл сведений о блокировке, учетная запись пользователя должна иметь право на запись в папку, содержащую MDB-файл.
· Если база данных защищена паролем, не следует использовать для подключения к ней элемент управления AccessDataSource, так как элемент управления AccessDataSource не поддерживает передачу учетных данных. Вместо этого используйте элемент управления SqlDataSource с поставщиком ODBC и передавайте учетные данные в строке подключения. Проверьте, что строки подключения защищены согласно рекомендациям подраздела Строки подключения.
Если данные сохраняются в XML-файл, поместите его в папку App_Data веб-узла, так как содержимое этой папки не будет возвращено в ответ на прямой HTTP-запрос.
Защита от злоумышленного пользовательского ввода
Если приложение принимает от пользователей вводимые данные, необходимо убедиться, что эти данные не содержат вредоносного содержимого, способного нарушить работу приложения. Ввод злоумышленных данных может использоваться для инициирования следующих видов атак:
· Внедрение сценария. Атака методом внедрения сценария пытается отправить в приложение исполняемый сценарий с таким расчетом, чтобы его запустили другие пользователи. Обычно такая атака отправляет сценарий странице, которая сохраняет его в базе данных, так что другой пользователь, просматривающий данные, непреднамеренно инициирует выполнение этого кода.
· Внедрение кода SQL. Атака путем внедрения кода SQL предпринимает попытку поставить под угрозу базу данных (и, потенциально, компьютер, на котором работает база данных) с помощью создания команд SQL, которые выполняются вместо или дополнительно к командам приложения.
Во всех случаях пользовательского ввода соблюдайте следующие правила:
· Везде, где только возможно, используйте проверочные элементы управления, чтобы ограничить пользовательский ввод допустимыми значениями.
· Перед запуском серверного кода всегда проверяйте, что значение свойства IsValid равно true. Значение false означает, что один или несколько проверочных элементов управления сообщают об ошибке при проверке данных.
· Всегда выполняйте проверку на стороне сервера, даже если обозреватель также выполняет проверку, чтобы защититься от пользователей, обходящих проверку на стороне клиента. Особенно это относится к элементу управления CustomValidator. Не следует использовать только логику проверки на стороне клиента.
· Всегда перепроверяйте пользовательский ввод на уровне бизнес-логики приложения. Не полагайтесь на то, что вызывающий процесс предоставляет безопасные данные. Например, при использовании элемента управления ObjectDataSource добавьте в объект, выполняющий обновление данных, кодирование и дополнительную проверку.
Для защиты от атак внедрения сценария соблюдайте следующие правила:
· Кодируйте пользовательский ввод с помощью метода HtmlEncode, который преобразует символы HTML в их текстовое представление (например, <b> становится <b>), что позволяет не допустить выполнение обозревателем разметки.
· Если используются объекты параметров для передачи пользовательского ввода в SQL-запрос, добавьте в элемент управления источника данных обработчики событий, вызывающиеся до выполнения запроса, и включите в эти обработчики кодирование. Например, в обработчике события Inserting элемента управления SqlDataSource кодируйте значение параметра перед выполнением запроса.
· При использовании элемента управления GridView с присоединенными полями установите для объекта BoundField свойство HtmlEncode в true. Элемент управления GridView будет кодировать пользовательский ввод, когда строка находится в режиме редактирования.
· Для элементов управления, которые могут быть переведены в режим редактирования, рекомендуется использовать шаблоны. Например, элементы управления GridView, DetailsView, FormView, DataList и Login могут отображать текстовые поля. Тем не менее, за исключением элемента управления GridView (см. выше) элементы управления автоматически не выполняют проверку данных или HTML-кодирование пользовательского ввода. Поэтому рекомендуется создавать шаблоны для таких элементов управления и включать в шаблон элемент управления вводом, например TextBox, и проверочный элемент управления. Кроме того, следует кодировать значение, извлекаемое из элемента управления.
Для защиты от атак внедрения кода SQL соблюдайте следующие правила:
· Не создавайте команды SQL путем соединения строк, особенно содержащих данные пользовательского ввода. Вместо этого используйте параметризованные запросы или хранимые процедуры.
· При создании параметризованного запроса используйте объекты параметров для установки значений параметров. Дополнительные сведения см. в разделах Использование параметров с элементом управления SqlDataSource и Использование параметров с элементами управления источников данных.
В элементах управления с привязкой к данным, таких как GridView, иногда необходимо сохранять конфиденциальные сведения. Например, элемент управления GridView может содержать список ключей в свойстве DataKeys, даже если эта информация не отображается. Между циклами обмена данными элемент управления хранит эти сведения в режиме просмотра.
Данные режима просмотра кодируются и хранятся вместе с содержимым страницы и могут быть декодированы и предоставлены нежелательному источнику. Если необходимо хранить конфиденциальные сведения в режиме просмотра, можно потребовать, чтобы страница шифровала эти данные. Для шифрования данных присвойте свойству страницы ViewStateEncryptionMode значение true.
Рекомендуется избегать хранения конфиденциальных сведений в объекте Cache, если разрешено олицетворение клиента и результаты из источника данных извлекаются на основе удостоверения клиента. Если кэширование включено, кэшированные данные одного пользователя могут быть доступны для просмотра всем пользователям и возможно предоставление конфиденциальных сведений нежелательному источнику. Олицетворение клиента разрешается, когда атрибуту impersonate элемента конфигурации identity присваивается значение true и на веб-сервере для данного приложения отключена анонимная идентификация.
Компью́терный ви́рус — разновидность компьютерных программ или вредоносный код, отличительной особенностью которых является способность к размножению (саморепликация). В дополнение к этому вирусы могут без ведома пользователя выполнять прочие произвольные действия, в том числе наносящие вред пользователю и/или компьютеру.
Даже если автор вируса не программировал вредоносных эффектов, вирус может приводить к сбоям компьютера из-за ошибок, неучтённых тонкостей взаимодействия с операционной системой и другими программами. Кроме того, вирусы обычно занимают некоторое место на накопителях информации и отбирают некоторые другие ресурсы системы. Поэтому вирусы относят к вредоносным программам.
Некомпетентные пользователи ошибочно относят к компьютерным вирусам и другие виды вредоносных программ — программы-шпионы и прочее.[1] Известны десятки тысяч компьютерных вирусов, которые распространяются через Интернет по всему миру.
Создание и распространение вредоносных программ (в том числе вирусов) преследуется в России согласно Уголовному кодексу РФ (глава 28, статья 273). Согласно доктрине информационной безопасности РФ[2], в России должен проводиться правовой ликбез в школах и вузах при обучении информатике и компьютерной грамотности по вопросам защиты информации в ЭВМ, борьбы с компьютерными вирусами, детскими порносайтами и обеспечению информационной безопасности в сетях ЭВМ.
Компьютерный вирус - это небольшая программа, написанная программистом высокой квалификации, способная к саморазмножению и выполнению разных деструктивных действий. На сегодняшний день известно свыше 50 тыс. компьютерных вирусов.
Существует много разных версий относительно даты рождения первого компьютерного вируса. Однако большинство специалистов сходятся на мысли, что компьютерные вирусы, как таковые, впервые появились в 1986 году, хотя исторически возникновение вирусов тесно связано с идеей создания самовоспроизводящихся программ. Одним из "пионеров" среди компьютерных вирусов считается вирус "Brain", созданный пакистанским программистом по фамилии Алви. Только в США этот вирус поразил свыше 18 тыс. компьютеров. В начале эпохи компьютерных вирусов разработка вирусоподобных программ носила чисто исследовательский характер, постепенно превращаясь на откровенно вражеское отношение к пользователям безответственных, и даже криминальных "элементов". В ряде стран уголовное законодательство предусматривает ответственность за компьютерные преступления, в том числе за создание и распространение вирусов.
Вирусы действуют только программным путем. Они, как правило, присоединяются к файлу или проникают в тело файла. В этом случае говорят, что файл заражен вирусом. Вирус попадает в компьютер только вместе с зараженным файлом. Для активизации вируса нужно загрузить зараженный файл, и только после этого, вирус начинает действовать самостоятельно.
Некоторые вирусы во время запуска зараженного файла становятся резидентными (постоянно находятся в оперативной памяти компьютера) и могут заражать другие загружаемые файлы и программы. Другая разновидность вирусов сразу после активизации может быть причиной серьезных повреждений, например, форматировать жесткий диск. Действие вирусов может проявляться по разному: от разных визуальных эффектов, мешающих работать, до полной потери информации. Большинство вирусов заражают исполнительные программы, то есть файлы с расширением .EXE и .COM, хотя в последнее время большую популярность приобретают вирусы, распространяемые через систему электронной почты.
Следует заметить, что компьютерные вирусы способны заражать лишь компьютеры. Поэтому абсолютно абсурдными являются разные утверждения о влиянии компьютерных вирусов на пользователей компьютеров.
Существует очень много разных вирусов. Условно их можно классифицировать следующим образом:
1) загрузочные вирусы или BOOT-вирусы заражают boot-секторы дисков. Очень опасные, могут привести к полной потере всей информации, хранящейся на диске;
2) файловые вирусы заражают файлы. Делятся на:
3) загрузочно-файловые вирусы способные поражать как код boot-секторов, так и код файлов;
4) вирусы-невидимки или STEALTH-вирусы фальсифицируют информацию прочитанную из диска так, что программа, какой предназначена эта информация получает неверные данные. Эта технология, которую, иногда, так и называют Stealth-технологией, может использоваться как в BOOT-вирусах, так и в файловых вирусах;
5) ретровирусы заражают антивирусные программы, стараясь уничтожить их или сделать нетрудоспособными;
6) вирусы-черви снабжают небольшие сообщения электронной почты, так называемым заголовком, который по своей сути есть Web-адресом местонахождения самого вируса. При попытке прочитать такое сообщение вирус начинает считывать через глобальную сеть Internet свое 'тело' и после загрузки начинает деструктивное действие. Очень опасные, так как обнаружить их очень тяжело, в связи с тем, что зараженный файл фактически не содержит кода вируса.
Если не принимать меры для защиты от компьютерных вирусов, то следствия заражения могут быть очень серьезными. В ряде стран уголовное законодательство предусматривает ответственность за компьютерные преступления, в том числе за внедрение вирусов. Для защиты информации от вирусов используются общие и программные средства.
К программным средствам защиты относят разные антивирусные программы (антивирусы). Антивирус - это программа, выявляющая и обезвреживающая компьютерные вирусы. Следует заметить, что вирусы в своем развитии опережают антивирусные программы, поэтому даже в случае регулярного пользования антивирусов, нет 100% гарантии безопасности. Антивирусные программы могут выявлять и уничтожать лишь известные вирусы, при появлении нового компьютерного вируса защиты от него не существует до тех пор, пока для него не будет разработан свой антивирус. Однако, много современных антивирусных пакетов имеют в своем составе специальный программный модуль, называемый эвристическим анализатором, который способен исследовать содержимое файлов на наличие кода, характерного для компьютерных вирусов. Это дает возможность своевременно выявлять и предупреждать об опасности заражения новым вирусом.
1) программы-детекторы: предназначены для нахождения зараженных файлов одним из известных вирусов. Некоторые программы-детекторы могут также лечить файлы от вирусов или уничтожать зараженные файлы. Существуют специализированные, то есть предназначенные для борьбы с одним вирусом детекторы и полифаги, которые могут бороться с многими вирусами;
2) программы-лекари: предназначены для лечения зараженных дисков и программ. Лечение программы состоит в изъятии из зараженной программы тела вируса. Также могут быть как полифагами, так и специализированными;
3) программы-ревизоры: предназначены для выявления заражения вирусом файлов, а также нахождение поврежденных файлов. Эти программы запоминают данные о состоянии программы и системных областей дисков в нормальном состоянии (до заражения) и сравнивают эти данные в процессе работы компьютера. В случае несоответствия данных выводится сообщение о возможности заражения;
4) лекари-ревизоры: предназначены для выявления изменений в файлах и системных областях дисков и, в случае изменений, возвращают их в начальное состояние.
5) программы-фильтры: предназначены для перехвата обращений к операционной системе, которые используются вирусами для размножения и сообщают об этом пользователя. Пользователь может разрешить или запретить выполнение соответствующей операции. Такие программы являются резидентными, то есть они находятся в оперативной памяти компьютера.
6) программы-вакцины: используются для обработки файлов и boot-секторов с целью предупреждения заражения известными вирусами (в последнее время этот метод используется все чаще).
Следует заметить, что выбор одного "наилучшего" антивируса крайне ошибочное решение. Рекомендуется использовать несколько разных антивирусных пакетов одновременно. Выбирая антивирусную программу следует обратить внимание на такой параметр, как количество распознающих сигнатур (последовательность символов, которые гарантированно распознают вирус). Второй параметр - наличие эвристического анализатора неизвестных вирусов, его присутствие очень полезно, но существенно замедляет время работы программы. На сегодняшний день существует большое количество разнообразных антивирусных программ. Рассмотрим коротко, распространенные в странах СНГ.
Один из лучших антивирусов с мощным алгоритмом нахождения вирусов. Полифаг, способный проверять файлы в архивах, документы Word и рабочие книги Excel, выявляет полиморфные вирусы, которые в последнее время, получают все большее распространение. Достаточно сказать, что эпидемию очень опасного вируса OneHalf остановил именно DrWeb. Эвристический анализатор DrWeb, исследуя программы на наличие фрагментов кода, характерных для вирусов, разрешает найти почти 90% неизвестных вирусов. При загрузке программы, в первую очередь DrWeb проверяет самого себя на целостность, после чего тестирует оперативную память. Программа может работать в диалоговом режиме, имеет удобный настраиваемый интерфейс пользователя.
Антивирус-ревизор диска ADINF (Avanced DiskINFoscope) разрешает находить и уничтожать, как существующие обычные, stealth- и полиморфные вирусы, так и совсем новые. Антивирус имеет в своем распоряжении лечащий блок ревизора ADINF - Adinf Cure Module - что может обезвредить до 97% всех вирусов. Эту цифру приводит "Диалогнаука", исходя из результатов тестирования, которое происходило на коллекциях вирусов двух признанных авторитетов в этой области - Д.Н.Лозинского и фирмы Dr.Sоlомоn's (Великобритания).
ADINF загружается автоматически в случае включения компьютера и контролирует boot-сектор и файлы на диске (дата и время создания, длина, контрольная сумма), выводя сообщения про их изменения. Благодаря тому, что ADINF осуществляет дисковые операции в обход операционной системы, обращаясь к функциям BIOS, достигаются не только возможность выявления активных stеаlth-вірусів, но и высокая скорость проверки диска. Если найден boot-вирус, то ADINF просто восстановит предшествующий загрузочный сектор, который хранится в его таблице. Если вирус файловый, то здесь на помощь приходит лечащий блок Adinf Cure Module, который на основе отчета основного модуля о зараженных файлах сравнивает новые параметры файлов с предыдущими, хранящиеся в специальных таблицах. При выявлении расхождений ADINF восстанавливает предыдущее состояние файла, а не уничтожает тело вируса, как это делают полифаги.
Антивирус AVP (AntiVirus Program) относится к полифагам, в процессе работы проверяет оперативную память, файлы, в том числе архивные, на гибких, локальных, сетевых и CD-ROM дисках, а также системные структуры данных, такие как загрузочный сектор, таблицу разделов и т.д. Программа имеет эвристический анализатор, который, по утверждениям разработчиков антивируса способен находить почти 80% всех вирусов. Программа AVP является 32-разрядным приложением для работы в среде операционных систем Windows 98, NT и 2000, имеет удобный интерфейс, а также одну из самых больших в мире антивирусную базу. Базы антивирусов к AVP обновляются приблизительно один раз в неделю и их можно получить с Internеt. Эта программа осуществляет поиск и изъятие разнообразнейших вирусов, в том числе:
Кроме того, программа AVP осуществляет контроль файловых операций в системе в фоновом режиме, выявляет вирус до момента реального заражения системы, а также определяет неизвестные вирусы с помощью эвристического модуля.
Ныне существует немало разновидностей вирусов, различающихся по основному способу распространения и функциональности. Если изначально вирусы распространялись на дискетах и других носителях, то сейчас доминируют вирусы, распространяющиеся через Интернет. Растёт и функциональность вирусов, которую они перенимают от других видов программ.
В настоящее время не существует единой системы классификации и именования вирусов (хотя попытка создать стандарт была предпринята на встрече CARO в 1991 году). Принято разделять вирусы:
Антивирусная программа (антивирус) — любая программа для обнаружения компьютерных вирусов, а также нежелательных (считающихся вредоносными) программ вообще и восстановления зараженных (модифицированных) такими программами файлов, а также для профилактики — предотвращения заражения (модификации) файлов или операционной системы вредоносным кодом.
На данный момент антивирусное программное обеспечение разрабатывается в
основном для ОС семейства Windows от компании Microsoft, что вызвано большим
количеством вредоносных программ именно под эту платформу (а это, в свою
очередь, вызвано большой популярностью этой ОС, также как и большим количеством
средств разработки, в том числе бесплатных и даже «инструкций по написанию
вирусов»). В настоящий момент на рынок выходят продукты и под другие платформы
настольных компьютеров, такие как Linux и Mac OS X. Это вызвано началом
распространения вредоносных программ и под эти платформы, хотя UNIX-подобные
системы всегда славились своей надежностью. Например, известное видео «Mac or
PC» шуточно показывает преимущество Mac OS над Windows и большим антивирусным
иммунитетом Mac OS по сравнению с Windows[1].
Помимо ОС для настольных компьютеров и ноутбуков, также существуют платформы и
для мобильных устройств, такие как Windows Mobile, Symbian, iOS, BlackBerry,
Android, Windows Phone 7 и др. Пользователи устройств на данных ОС также
подвержены риску заражения вредоносным программным обеспечением, поэтому
некоторые разработчики антивирусных программ выпускают продукты и для таких
устройств.
Классифицировать антивирусные продукты можно сразу по нескольким признакам, таким как: используемые технологии антивирусной защиты, функционал продуктов, целевые платформы.
По используемым технологиям антивирусной защиты:
По функционалу продуктов:
По целевым платформам:
Антивирусные продукты для корпоративных пользователей можно также классифицировать по объектам защиты:
В 2009 началось активное распространение т. н. лжеантивирусов — программного обеспечения, не являющегося антивирусным (то есть не имеющего реального функционала для противодействия вредоносным программам), но выдающим себя за таковое. По сути, лжеантивирусы могут являться как программами для обмана пользователей и получения прибыли в виде платежей за «лечение системы от вирусов», так и обычным вредоносным программным обеспечением. В настоящий момент это распространение приостановлено.
Говоря о системах Майкрософт, обычно антивирус действует по схеме:
Для использования антивирусов необходимы постоянные обновления так называемых баз антивирусов. Они представляют собой информацию о вирусах — как их найти и обезвредить. Поскольку вирусы пишут часто, то необходим постоянный мониторинг активности вирусов в сети. Для этого существуют специальные сети, которые собирают соответствующую информацию. После сбора этой информации производится анализ вредоносности вируса, анализируется его код, поведение, и после этого устанавливаются способы борьбы с ним. Чаще всего вирусы запускаются вместе с операционной системой. В таком случае можно просто удалить строки запуска вируса из реестра, и на этом в простом случае процесс может закончиться. Более сложные вирусы используют возможность заражения файлов. Например, известны случаи, как некие даже антивирусные программы, будучи зараженными, сами становились причиной заражения других чистых программ и файлов. Поэтому более современные антивирусы имеют возможность защиты своих файлов от изменения и проверяют их на целостность по специальному алгоритму. Таким образом, вирусы усложнились, как и усложнились способы борьбы с ними. Сейчас можно увидеть вирусы, которые занимают уже не десятки килобайт, а сотни, а порой могут быть и размером в пару мегабайт. Обычно такие вирусы пишут в языках программирования более высокого уровня, поэтому их легче остановить. Но по-прежнему существует угроза от вирусов, написанных на низкоуровневых машинных кодах наподобие ассемблера. Сложные вирусы заражают операционную систему, после чего она становится уязвимой и нерабочей. К сожалению, по прогнозам, в ближайшем будущем работа антивирусных компаний сильно осложнится в связи с тем, что будут сильнее распространяться вирусы с защитой от копирования.
Самыми популярными и эффективными антивирусными программами являются антивирусные сканеры (другие названия: доктора, фаги, полифаги). Следом за ними по эффективности и популярности следуют CRC-сканеры (так-же: ревизор, checksumer, integrity checker). Часто оба приведенных метода объединяются в одну универсальную антивирусную программу, что значительно повышает ее мощность. Применяются также различного типа мониторы (фильтры, блокировщики) и иммунизаторы (детекторы).
Сканеры
Принцип работы антивирусных сканеров основан на проверке файлов, секторов и системной памяти и поиске в них известных и новых (неизвестных сканеру) вирусов. Сканеры также можно разделить на две категории — «универсальные» и «специализированные». Универсальные сканеры рассчитаны на поиск и обезвреживание всех типов вирусов вне зависимости от операционной системы, на работу в которой рассчитан сканер. Специализированные сканеры предназначены для обезвреживания ограниченного числа вирусов или только одного их класса, например макро-вирусов. Специализированные сканеры, рассчитанные только на макро-вирусы, часто оказываются наиболее удобным и надежным решением для защиты систем документооборота в средах MS Word и MS Excel. Сканеры также делятся на «резидентные», производящие сканирование «на лету», и «нерезидентные», обеспечивающие проверку системы только по запросу.
CRC-сканеры
Принцип работы CRC-сканеров основан на подсчете CRC-сумм (контрольных сумм) для присутствующих на диске файлов/системных секторов. Эти CRC-суммы затем сохраняются в базе данных антивируса, как, впрочем, и некоторая другая информация: длины файлов, даты их последней модификации и т.д. При последующем запуске CRC-сканеры сверяют данные, содержащиеся в базе данных, с реально подсчитанными значениями. Если информация о файле, записанная в базе данных, не совпадает с реальными значениями, то CRC-сканеры сигнализируют о том, что файл был изменен или заражен вирусом.
Мониторы
Антивирусные мониторы — это резидентные программы, перехватывающие «вирусо-опасные» ситуации и сообщающие об этом пользователю. К «вирусо-опасным» относятся вызовы на открытие для записи в выполняемые файлы, запись в загрузочные сектора дисков, попытки программ остаться резидентно и т.д., то есть вызовы, которые характерны для вирусов в моменты из размножения.
Иммунизаторы
Иммунизаторы делятся на два типа: иммунизаторы, сообщающие о заражении, и иммунизаторы, блокирующие заражение каким-либо типом вируса. Первые обычно записываются в конец файлов (по принципу файлового вируса) и при запуске файла каждый раз проверяют его на изменение. Недостаток у таких иммунизаторов всего один, что он летален: абсолютная неспособность сообщить о заражении стелс-вирусом. Поэтому такие иммунизаторы, как и мониторы, практически не используются в настоящее время.
Алгоритмы поиска компьютерных вирусов
Сигнатурный метод поиска вирусов
Сигнатура – это программный код вируса. Когда антивирусная компания находит тело вируса, она добавляет в свою базу его сигнатуру. Скачивая обновленные базы, Вы, таким образом, уменьшаете вероятность проникновения вируса на Ваш компьютер. Антивирусная программа, сканирует каждый файл на компьютере на предмет известных сигнатур.
В этой связи есть один интересный момент. Некоторые базы имеют в своем арсенале 70 тысяч сигнатур, а в других – скажем сто. Вторые в глазах пользователя выглядят привлекательнее. Но, самом деле, это ничего не означает. Алгоритмы создания сигнатуры одних производителей отличаются от алгоритмов других. Поэтому у одной компании одна сигнатура может обозначать целую группу вирусов, в то время как у другой эту же группу будет описывать несколько сигнатур.
Существенный недостаток в таком методе – его нединамичность. Компании требуется несколько дней для поиска и создания новых сигнатур. А программисту нужно всего несколько минут для написания нового вируса и несколько секунд для заражения его на тысячи и сотни тысяч компьютеров.
Эвристический метод поиска
Именно медлительность в обновлении баз и все более сложные алгоритмы вирусов породили антивирусные компании этот метод. Собственно с помощью него антивирусные компании сканируют сеть на предмет поиска новых вирусов.
Что же он собой представляет? Это нечто типа «сигнатурный метод для сигнатур». Здесь анализируются не файлы, а прошлые методы поиска, их ошибки и достижения, устанавливаются определенные закономерности в поведении вирусов. Только этот метод сможет уберечь Вас от свежего вируса. Недостаток его заключается в том, что есть возможность отправить в вирусное хранилище ни в чем не повинный файл, если он по своему поведению или содержанию напомнит вирус. Зараженные файлы, отправленные в хранилище, не контактируют с другими файлами и с системой, поэтому безопасны. Антивирусная система может отсылать эти файлы на сайты антивирусных лабораторий, где они будут подвергаться дальнейшему анализу.
Скачано с www.znanio.ru

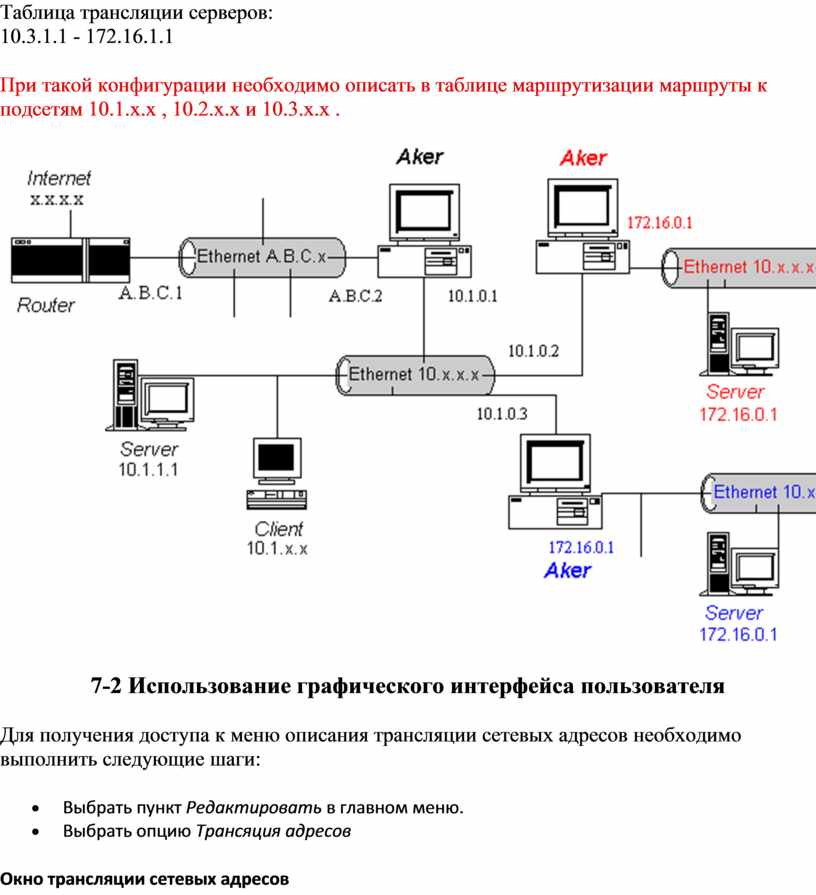


































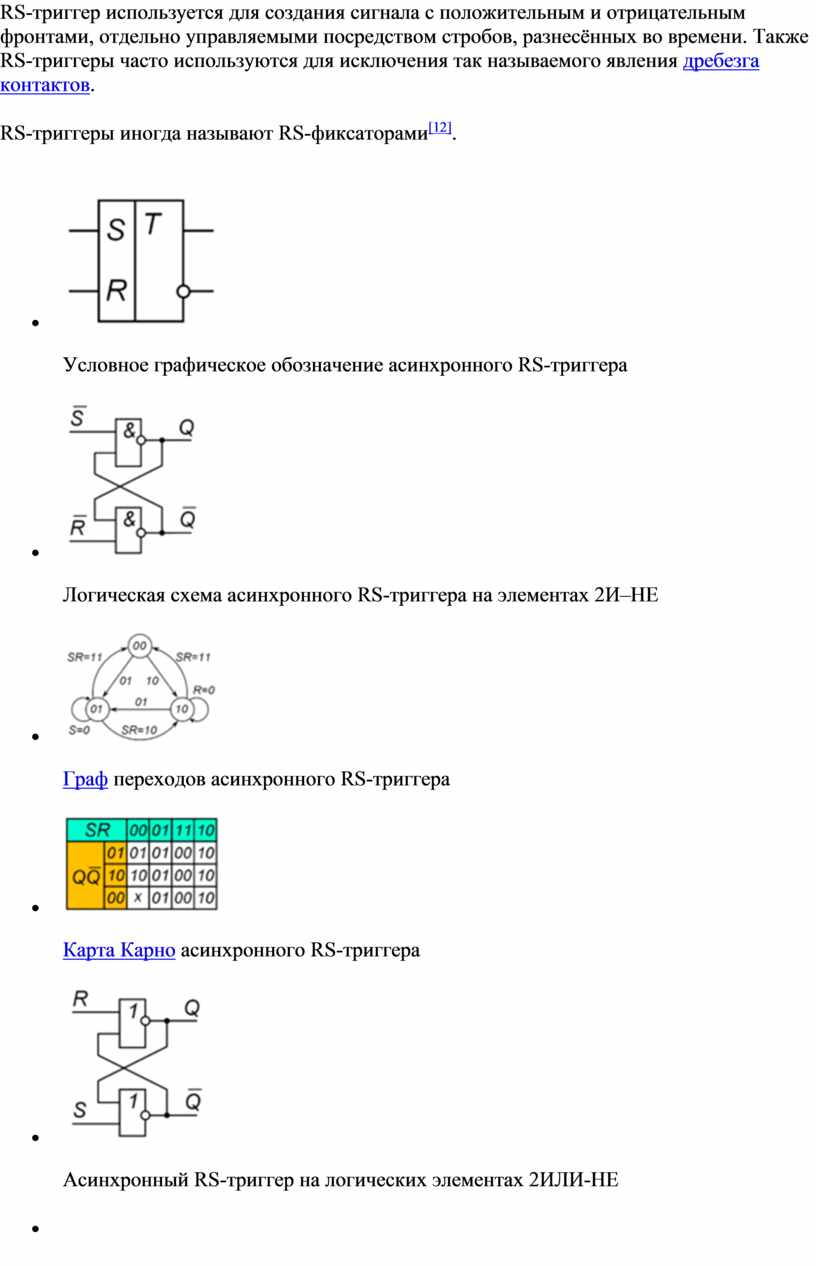





![JK-триггер [18][19] работает так же как](https://fs.znanio.ru/d5af0e/ad/59/3c4905a724a5309a42568f854bc9cd8ca1.jpg)






Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.