Поделиться

РЕАЛИЗАЦИЯ ЯЗЫКА
В этом разделе мы познакомимся с процессом перевода программы с языка высокого уровня в такую форму, которая может быть выполнена машиной.
Процесс перевода. Процесс перевода программы с одного языка на другой называется трансляцией (translation). Про- грамма в своем оригинальном виде называется исходной программой (sourse program), а оттранслированная ее версия назы- вается объектным кодом программы (object program). Процесс трансляции состоит из трех этапов – лексического анализа, синтаксического разбора и генерации кода, которые выполняются элементами транслятора, называемыми лексическим ана- лизатором (lexical analyzer), синтаксическим анализатором (parser) и генератором кода (code generator) (рис. 5.12).
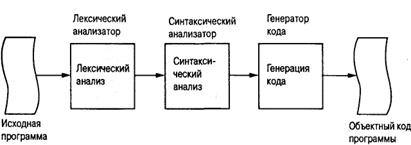
Рис. 5.12. Процесс трансляции программы
В процессе лексического анализа распознаются цепочки символов, которые представляют собой отдельные элементы. Например, символы '153' должны интерпретироваться транслятором не как совокупность цифр, состоящая из единицы, пя- терки и тройки, а как единое числовое значение, равное ста пятидесяти трем. Аналогично этому, слова в программе пред- ставляют собой самостоятельные и неразделимые единицы текста, хотя и состоят из отдельных символов. Большинство лю- дей выполняют лексический анализ без каких-либо видимых усилий. И действительно, когда нас просят прочитать текст вслух, мы произносим целые слова, а не те отдельные буквы, из которых они состоят.
Таким образом, лексический анализатор символ за символом считывает текст исходной программы, определяя, какие группы символов образуют самостоятельные единицы текста. Затем эти единицы классифицируются, чтобы выяснить, что они собой представляют – числа, слова, арифметические операторы и т.д. Как только единица текста классифицирована, лексический анализатор генерирует ее битовый образ, называемый лексемой (token), и передает его синтаксическому анали- затору. При выполнении этого процесса лексический анализатор игнорирует все комментарии, содержащиеся в тексте ис- ходной программы.
Реализация языка Java. При использовании анимированной Web-страницы управляющее анимацией программное обеспечение передается через Internet вместе с самой страницей. Если программное обеспечение представляет собой исходный текст программы, то при просмотре страницы возникает дополнительная задержка, связанная с трансляцией программы в соответствующий машинный язык. Однако если это программное обеспечение пересылать сразу на машинном языке, то может оказаться, что для разных типов ма- шин потребуются различные версии программы.
Фирма Sun Microsystems решила эту проблему, разработав универсальный "машинный язык", названный байт-кодом, на который переводятся исходные тексты программ, написанные на языке Java. Хотя байт-код не является настоящим машинным языком, под- ходящий интерпретатор сможет выполнить его достаточно быстро. В настоящее время такие интерпретаторы уже стали стандартной частью любых Web-броузеров. Поэтому, если управляющее Web-страницей программное обеспечение написано на языке Java и переве- дено в байт-код, то эту байт-кодовую версию программы можно передавать любому броузеру, что гарантирует эффективную анимацию изображений при просмотре данной Web-страницы.
Из сказанного выше можно прийти к заключению, что синтаксический анализатор анализирует программу в терминах лексических единиц (лексем), а не отдельных символов. Задачей синтаксического анализатора является объединение этих единиц в операторы. Действительно, в процессе синтаксического анализа производится идентификация грамматической структуры программы и распознавание роли каждого ее компонента. Это – техническая сторона синтаксического разбора, которая может привести к некоторой задержке при чтении следующего предложения.
Человек, которого лошадь, проигравшая скачки, сбросила, не был ранен.
Чтобы упростить процесс синтаксического разбора, ранние языки программирования требовали, чтобы каждый опера- тор программы размещался в определенном месте бланка исходного текста. Такие языки называются языками с фиксирован- ным форматом (fixed-format languages). В настоящее время большинство языков программирования являются языками со свободным форматом. Это означает, что расположение операторов в тексте не имеет значения. Преимущество свободного формата состоит в том, что программист теперь может писать программу так, чтобы человеку было легко ее читать. В таких программах принято использовать отступы, чтобы помочь читателю понять внутреннюю структуру оператора. Например, рассмотрим следующий оператор:
if Cost < Cash on hand then pay with cash else use credit card
При использовании свободного формата программист может записать этот же оператор в более удобном виде:
if Cost < Cash on hand then pay with cash else use credit card
Для того чтобы машина могла выполнять синтаксический анализ программы, написанной на языке со свободным фор- матом, синтаксис языка следует разрабатывать таким образом, чтобы структуру программы можно было идентифицировать, не обращая внимания на пробелы в исходном тексте программы. По этой причине во многих языках со свободным форматом для обозначения конца оператора используются знаки пунктуации (например, точка с запятой), а также ключевые слова (key words), такие, как if, then и else, предназначенные для выделения начала отдельных фраз. Эти ключевые слова обычно называют зарезервированными словами (reserved words), чтобы подчеркнуть, что программист не может использовать их в своей программе для иных целей.
Процесс синтаксического анализа базируется на совокупности правил, определяющих синтаксис языка программирова- ния. Один из способов представления этих правил состоит в использовании синтаксических диаграмм (syntax diagram), на-
 |
Рис. 5.13. Синтаксическая диаграмма оператора if-then-else
Эта диаграмма показывает, что структурно оператор if-then-else начинается с ключевого слова if, за которым следует Логическое выражение. Затем указывается ключевое слово then, после которого должен присутствовать выполняемый Оператор. Эта комбинация ключевых слов может дополняться (но необязательно) ключевым словом else и еще одним элементом Оператор. Обратите внимание, что члены выражения, или термы, которые действительно присутствуют в опе- раторе if-then-else, заключены в овалы, а те термы, которые подлежат дальнейшему уточнению, например Логиче- ское выражение или Оператор, помещены в прямоугольники. Термы, подлежащие дальнейшему уточнению (т.е. те, которые заключены в прямоугольники), называются нетерминальными (nonterminals), а термы, окруженные овалами, – тер- минальными (terminals). В полном описании синтаксиса языка программирования нетерминальные термы описываются до- полнительными диаграммами.
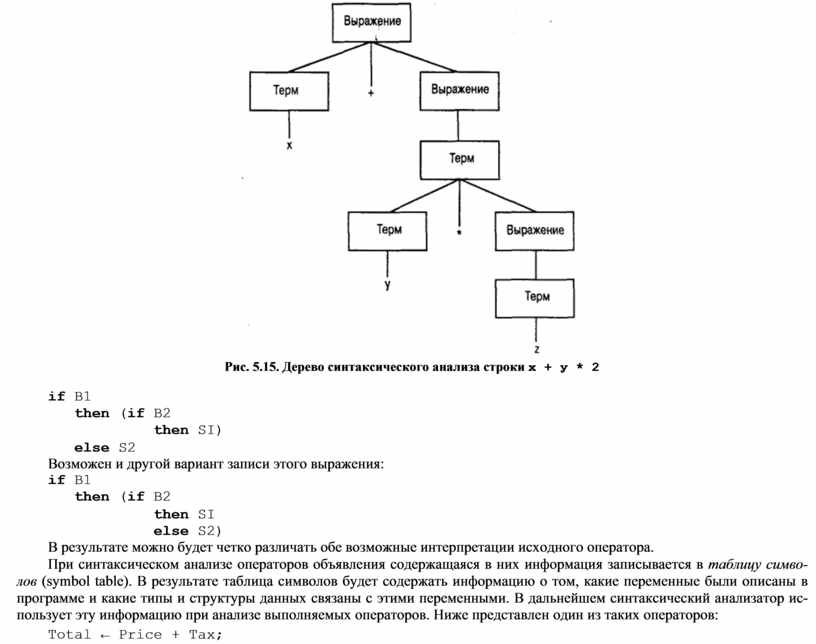
На рис. 5.14 представлен набор синтаксических диаграмм, описывающих синтаксис структуры Выражение, являющей- ся структурой простого арифметического выражения. Первая диаграмма описывает структуру Выражение как состоящую из компонента Терм, за которым могут вначале следовать (но необязательно) символы + или -, а затем другой компонент Выражение. Вторая диаграмма описывает структуру компонента Терм как состоящую из отдельных символов х, у и z или другого компонента Терм, за которым следует один из символов * или /, а потом идет некоторый компонент Выражение.
Метод, с помощью которого отдельная строка программы проверяется на соответствие некоторой совокупности син- таксических диаграмм, можно наглядно представить с помощью дерева синтаксического анализа (parse tree) (рис. 5.15). На нем приведено дерево синтаксического анализа следующей строки:
x + у * 2
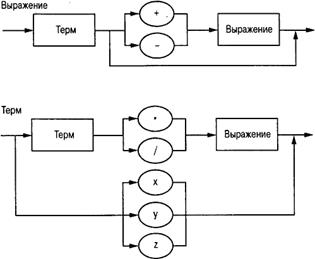 |
Рис. 5.14. Синтаксическая диаграмма, описывающая структуру простого алгебраического выражения
Процесс синтаксического анализа программы, по сути, сводится к построению дерева синтаксического анализа для ее исходного текста. Фактически дерево синтаксического анализа отражает, как синтаксический анализатор понял грамматиче- скую структуру программы. По этой причине синтаксические правила, описывающие эту грамматическую структуру, не должны допускать построения двух разных деревьев синтаксического анализа для одной и той же строки, поскольку это приведет к неоднозначности. Такие неточности могут быть практически незаметными. И действительно, показанное на рис.
5.13 синтаксическое правило содержит подобную неточность. Оно допускает построение двух разных деревьев синтаксиче- ского анализа для одного и того же оператора, показанного ниже, что отражено на рис. 5.16:
if Bl then if В2 then S1 else S2
Заметим, что эти интерпретации существенно отличаются друг от друга. Первая предполагает, что оператор S2 будет выполнен, если выражение В1 окажется ложным. Из второй интерпретации следует, что оператор S2 должен выполняться только тогда, когда выражение В1 истинно, а выражение В2 ложно.
Синтаксические определения формальных языков программирования разрабатываются так, чтобы избежать подобных неоднозначностей. В нашем псевдокоде этой проблемы можно избежать за счет применения скобок. В частности, этот опе- ратор следовало бы записать следующим образом:
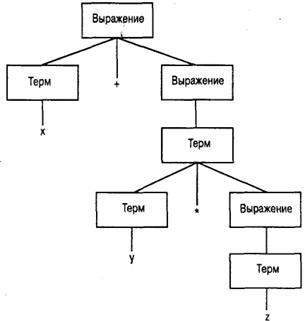
Рис. 5.15. Дерево синтаксического анализа строки x + у * 2
if B1
then (if B2
then SI)
else S2
Возможен и другой вариант записи этого выражения:
if B1
then (if B2
then SI
else S2)
В результате можно будет четко различать обе возможные интерпретации исходного оператора.
При синтаксическом анализе операторов объявления содержащаяся в них информация записывается в таблицу симво- лов (symbol table). В результате таблица символов будет содержать информацию о том, какие переменные были описаны в программе и какие типы и структуры данных связаны с этими переменными. В дальнейшем синтаксический анализатор ис- пользует эту информацию при анализе выполняемых операторов. Ниже представлен один из таких операторов:
Total ← Price + Tax;
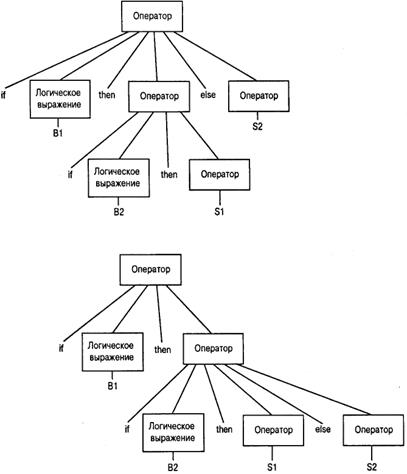
Рис. 5.16. Два варианта дерева синтаксического анализа оператора if Bl then if В2 then S1 else S2
Действительно, чтобы определить значение символа +, синтаксический анализатор должен знать, какой тип данных связан с переменными Price и Tax. Если переменная Price имеет тип real, а переменная Tax – тип character, то операция суммирования переменных Price и Tax не имеет смысла; ее появление должно рассматриваться как ошибка. Если обе пе- ременные Price и Tax имеют тип integer, то синтаксический анализатор потребует от генератора кода создать на машин- ном языке команду с кодом операции сложения двух целых чисел. Если эти переменные имеют тип real, то синтаксический анализатор потребует использовать операцию сложения двух чисел с плавающей точкой.
Предыдущий оператор имеет смысл и в некоторых из тех случаев, когда входящие в него переменные имеют разный тип. Например, если переменная Price имеет тип integer, а переменная Tax – тип real, то вполне возможно применить опе- рацию сложения. В этом случае синтаксический анализатор может предложить генератору кода предварительно преобразо- вать одну из переменных в другой тип и после этого выполнить требуемое сложение. Такое неявное преобразование типов называется приведением типов (coercion).
Неявное приведение типов не одобряется многими разработчиками языков. Они считают, что неявное приведение типов свидетельствует о неправильной разработке программы и что синтаксический анализатор ни в коем случае не должен по- крывать эти недостатки. В результате большинство современных языков программирования являются строго типизирован- ными (strongly typed), т.е. они требуют, чтобы все операции в программе выполнялись над данными согласованных типов без необходимости неявного приведения типов. Синтаксические анализаторы этих языков рассматривают любые несоответствия типов как ошибку.
Последняя стадия процесса трансляции программы – это генерация кода, т.е. создание команд машинного языка, вы- полняющих выражения, распознанные синтаксическим анализатором. Этот процесс включает множество различных аспек- тов, один из которых – повышение эффективности генерируемого кода. Например, рассмотрим задачу трансляции последо- вательности из двух следующих операторов:
x ← у + z; w ← x + z;
Эти операторы могут быть оттранслированы по отдельности. Однако это не позволит достичь высокой эффективности результата. Генератор кода должен суметь распознать, что, когда первый оператор будет выполнен, переменные х и z уже будут находиться в регистрах общего назначения центрального процессора и, следовательно, нет необходимости снова за- гружать их из памяти перед выполнением второго оператора. Реализация подобных нюансов в построении программы назы- вается оптимизацией кода (code optimization) и является важной задачей генератора кода.
Этапы лексического анализа, синтаксического анализа и генерации кода никогда не выполняются в указанной строгой последовательности. На самом деле они тесно переплетаются между собой. Лексический анализатор начинает с чтения сим- волов текста исходной программы и идентификации первых лексем. Затем он передает эти лексемы синтаксическому анализа- тору.
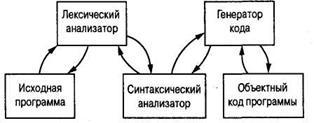
Рис. 5.17. Объектно-ориентированный подход к процессу трансляции программы
Каждый раз, когда синтаксический анализатор получает очередную лексему, он анализирует считываемую в данный момент грамматическую структуру. В результате он может запросить у лексического анализатора следующую лексему либо, если он распознал законченную фразу или оператор, обратиться к генератору кода для порождения соответствующих машинных инструкций. Каждый поступивший запрос вынуждает генератор кода строить соответствующие машинные команды и до- бавлять их к объектному коду программы. Как можно заметить, задача перевода программы с одного языка на другой есте- ственно согласуется с объектно-ориентированной парадигмой. Поэтому исходный текст программы, лексический анализа- тор, синтаксический анализатор, генератор кода и объектный код могут рассматриваться как объекты, которые взаимодействуют, посылая друг другу сообщения по мере выполнения своих функций (рис. 5.17).
Связывание и загрузка. Объектный код программы, полученный в результате ее трансляции, хотя и записан на ма- шинном языке, но чаще всего еще не имеет той формы, которая необходима для выполнения машиной. Одной из причин этого является то, что многие средства программирования позволяют разрабатывать программы в виде отдельных модулей, транслируемых в разное время (это способствует приданию программному обеспечению модульной структуры). Поэтому объектный код, полученный в результате отдельного процесса трансляции, чаще всего представляет собой всего лишь неко- торую составную часть программы, которая должна быть связана с другими ее частями для решения задач, стоящих перед всей системой в целом. Даже если вся программа разработана и оттранслирована в виде единственного модуля, ее объект- ный код все же не готов для выполнения машиной, поскольку любой программе, как правило, требуются функции, выпол- няемые другими программами или же операционной системой. Поэтому объектный код программы в действительности представляет собой программу на машинном языке, обычно содержащую несколько неразрешенных ссылок; эту программу необходимо связать с другими программами, прежде чем можно будет получить полноценный выполняемый модуль.
Связывание объектного кода программы с другими модулями выполняет программа, называемая редактором связей (linker). Ее задача – связать между собой несколько объектных модулей (полученных в результате предшествующих незави- симо выполненных процедур трансляций), программ операционной системы и другое программное обеспечение в целях по- лучения завершенного выполняемого модуля (иногда называемого загрузочным модулем), который представляет собой файл, размещаемый во внешней памяти машины.
Наконец, чтобы выполнить оттранслированную программу, ее загрузочный модуль должен быть размещен в основной памяти машины с помощью специальной программы, называемой загрузчиком (loader). Загрузчик обычно является частью программы-планировщика операционной системы (см. раздел 3.3). Важность этого этапа особенно велика в многозадачных системах. В подобных системах любая программа вынуждена использовать память совместно с другими параллельно вы- полняемыми процессами, причем набор параллельно выполняемых процессов изменяется при каждом выполнении програм- мы. Поэтому точное расположение выделяемого для некоторой программы участка памяти остается неизвестным, вплоть до ее вызова на выполнение. Таким образом, задачей загрузчика является считывание программы в указанную операционной системой область памяти и выполнение в ней всех необходимых настроек, которые невозможно осуществить, пока не будет известно точное расположение данной программы в памяти. (Команды перехода в программе должны выполнять переход на правильные адреса внутри программы.) Желание минимизировать объем выполняемой загрузчиком окончательной настрой- ки привело к разработке таких способов программирования, в которых запрещается использовать явные ссылки на адреса памяти в программе. В результате появились перемещаемые модули (relocatable module), которые выполняются правильно независимо от их размещения в памяти.
 |
Рис. 5.18. Полный цикл подготовки программы к выполнению
Пакеты разработки программного обеспечения. В настоящее время прочно укрепилась тенденция объединять транс- лятор с другими элементами программного обеспечения в общий пакет, функционирующий как единая интегрированная программная система. В соответствии со схемой классификации, предложенной в разделе 3.2, такую систему следует отне- сти к прикладному программному обеспечению. Используя такой программный пакет, программист получает удобный дос- туп к текстовому редактору, предназначенному для написания программ, транслятору, необходимому для перевода про-
граммы на машинный язык, и разнообразным инструментам отладки программ, позволяющим отслеживать выполнение не- правильно работающих программ и обнаруживать имеющиеся в них ошибки.
Такая интегрированная система имеет много достоинств. Вероятно, наиболее важное из них – возможность легко пере- ходить от текстового редактора к отладчику и обратно при написании и проверке программ. Более того, многие пакеты раз- работки программ позволяют связывать разрабатываемые программные модули таким образом, что доступ к ним заметно упрощается. Некоторые пакеты обеспечивают ведение записей, относящихся к тем программным единицам в группе взаимо- связанных модулей, которые были изменены со времени последнего сеанса проверки их функционирования. Подобные сред- ства очень удобны при разработке больших программных систем, в состав которых входит множество отдельных модулей, разрабатываемых разными программистами.
Кроме того, текстовые редакторы обычно настроены для работы с тем языком программирования, который использует- ся в данном пакете. Например, текстовые редакторы в пакетах для разработки программного обеспечения обычно позволяют автоматически применять отступы строк, что фактически уже стало стандартом для большинства языков программирования. В некоторых случаях текстовый редактор способен распознавать и автоматически дописывать ключевые слова сразу же по- сле того, как программист введет лишь несколько их первых букв.
Во многих пакетах для разработки программ используют графический интерфейс, что позволяет программистам созда- вать программы из заранее написанных блоков, представленных на экране пиктограммами. Отдельные блоки могут допол- нительно настраиваться в среде текстового редактора. Разработка подобных пакетов отражает общую тенденцию к созданию программ из больших, заранее заготовленных блоков, вместо обычного покомандного программирования.
1. Опишите три основных этапа процесса трансляции.
2. Что такое таблица символов?
3. Исходя из синтаксических диаграмм, представленных на рис. 5.14, нарисуйте дерево синтаксического разбора для вы- ражения
х * у + х + z.
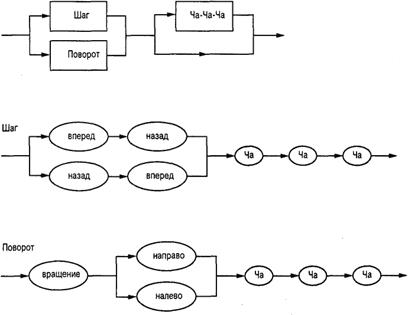
4. Напишите несколько строк, формат которых будет соответствовать структуре Ча-Ча-Ча, определенной с помощью следующих синтаксических диаграмм.
 |






Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.