Цель работы:
1) познакомиться с новыми способами шифрования, влияние чисел на судьбу и характер человека;
2) применять полученные знания для решения задач;
3) развивать такое важное умение, как выполнение заданного алгоритма;
4) изучить основные принципы нынешнего варианта нумерологии для последующего использования их в повседневной жизни.
Содержание.
Введение
Глава 1 Теоретическая часть
1.1 Историческая справка
1.2 Криптографические системы
1.3 Транспозиция
1.4 Подстановочные системы
1.5 Шифрование с помощью простых чисел
1.6 Число имени
1.7 Число дома
1.8 Число жизни
1.9 Что день грядущий нам готовит?
1.10 Квадрат Пифагора
1.11 Заключительные замечания
Глава 2 Практическая часть. Мои способы шифрования
2.1 Замещение согласных
2.2 Сдвинутый алфавит
2.3 Секретные перестановки
2.4«Золотой жук»
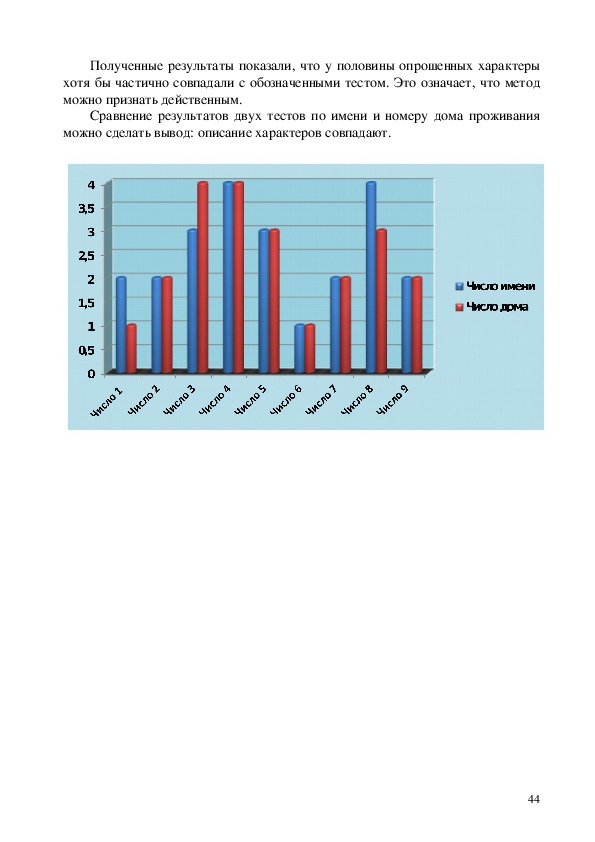
2.5 Влияние даты рождения имени и номера дома на
судьбу и характер личности.
Заключение
Приложения
Литература
страница
2
3
4
5
11
20
21
25
27
29
32
37
38
38
38
39
40
42
43
49Введение.
Два человека обмениваются письмами, в которых содержится очень
важная и опасная для них обоих информация. Могут ли они так зашифровать
свои послания, чтобы некто другой не смог их прочитать? Императоры, купцы,
шпионы задавали себе подобные вопросы на протяжении 25 веков, с момента
появления первых шифров. И отвечали на них поразному. Шерлок Холмс,
например, полагал, что ему по силам любой шифр. Такое самомнение, конечно,
простительно выдуманному герою, но само по себе убеждение было не лишено
оснований. Многие кодировки, считавшиеся недоступными, в конце концов,
были благополучно разгаданы.
Так возможно ли создать абсолютно надежный шифр?
В прошлом году я уже работал над темой шифрования текстов,
рассматривал матричные способы шифрования. Но, когда на областной
конференции мне задали вопрос о криптографии, я решил, что это и есть тема
для моей будущей работы. А теперь я хочу познакомить вас с тем, что у меня
получилось.
Целью моей работы стало:
1) познакомиться с новыми способами шифрования текста, влияние чисел на
судьбу и характер человека;
2) применять полученные знания для решения задач кодирования, узнавания
судьбы и характера человека;
3) развивать такое важное умение, как выполнение заданного алгоритма;
4) изучить основные принципы нынешнего варианта нумерологии для
последующего использования их в повседневной жизни.
Задачи:
изучить литературу по данному вопросу, познакомиться с способами
шифрования текста и влияние чисел на характер и судьбу человека;
научиться применять полученные знания, при решении задач;
познакомить одноклассников со способами шифрования текста и
влияние чисел на характер и судьбу человека на кружковых занятиях по
математике;
изучить основные принципы нынешнего варианта нумерологии для
последующего использования их в повседневной жизни.
Гипотеза: проверить возможность усвоения учащимся понятий некоторых
транспозиций, перестановок, подстановочных систем и умения применять
полученные знания в изменённых условиях.
2Объектом исследования стали криптографические системы и изучение
влияния чисел на судьбу и характер человека.
Глава 1.Теоретическая часть. Тайнопись.
1.1 Историческая справка.
Потребность в таком способе письма, который скрывал бы смысл
написанного от постороннего взгляда и делал бы его доступным лишь для
немногих посвященных, существует у людей с древних пор. Отсюда и возникло
искусство секретного письма, разросшееся в наши дни чуть ли не до размеров
целой науки – криптографии (от греческого тайнопись). Одни тексты
создавались для всех, как, скажем законы вавилонского царя Хамураппи,
написанные почти за два тысячелетия до нашей эры: царь повелел выбить текст
этих законов на каменной стеле, чтобы каждый мог узнать о них (см.
приложение 1). Другие тексты надо было держать в строжайшей тайне. О
тайнописи упоминает еще Геродот (см. приложение 7) и даже приводит образцы
таких писем, которые понятны лишь адресату. По свидетельству Плутарха, у
спартанцев были в употреблении специальные механические приборы для
записывания и прочтения тайных посланий. Для записывания религиозных тайн
жрецы пользовались особыми письменами, непонятными для непосвященных.
Известно, что к криптографии прибегал Юлий Цезарь (см. приложение 2, 3) в
своем дневнике о войне в Галии, он сам изобрел шифр, довольно простой, с
моей точки зрения: «сдвинул» алфавит на три буквы вверх, так что букве «А»
латинского алфавита соответствовала буква «Д» и так далее. Дешифровка
записей Цезаря очень проста. То же можно сказать о шифре другого
императора – Карла Великого. Тот пользовался выдуманным алфавитом с
начертанием букв совсем иным, чем в общеупотребительном.
В средние века над изобретением и усовершенствованием криптографических
систем работали многие выдающиеся умы, как например, философ Бекон
Веруламский, математик Виета, историк Гуго Гроцкий и др.
Но высшего развития криптография достигла лишь в новое время.
Криптография была продуктом выдумки и опыта авторов секретной
информации. Поначалу она развивалась усилиями людей, которым была
необходима, дипломатов, военных, разведчиков, изобретателей (до
оформления патента им надо было сохранить изобретение в тайне) и т.д. И
только в наше время, когда в жизнь вошли компьютеры, и когда в 1945 году
была опубликована «Теория связи в секретных системах», разработанная
американским математиком Шенноном (см. приложение 6), криптография
получила статус науки. Под «секретными системами» понимаются такие, где
3смысл сообщения скрывается при помощи определенного кода. Но не следует
думать, что с появлением компьютеров и теоретических основ, созданных
Шенноном, старая классическая криптография перестала быть помощницей в
тайных серьезных делах. Вы сами можете судить, насколько много в
криптографии «математики». Но, если математике здесь принадлежит
довольно скромная роль, то, во всяком случае, легко убедиться, что свободное
пользование тайнописью требует все же запаса сообразительности и остроумия.
1.2 Криптографические системы.
Каждый метод превращения исходного незашифрованного текста в
секретное сообщение состоит из двух частей: 1 основной, неизменный метод,
называемый общей системой, и 2 переменный элемент «ключ», обычно
представляющий собой слово, предложение или последовательность чисел,
называемый специальным ключом данной системы шифрования. Как правило,
предполагается, что противник (любое лицо, которое может за владеть чужим
сообщением и попытаться его расшифровать) знает, какая общая система
применена, это предложение основано на том, что ни при такой достаточно
обширной системе передачи сообщений нельзя надеяться, что удастся долго
сохранять общий метод в тайне, часто же менять его невозможно, ибо обучение
персонала новому методу сопряжено с большими трудностями. При таких
условиях уровень надежности используемой криптографической системы
естественно считать пропорциональным времени, которое требуется для
раскрытия специального ключа. Обычно нереально менять ключ чаще, чем раз в
день; поэтому, если противнику удается перехватить все сообщения (или хотя
бы одно из них), то у него может оказаться несколько сотен сообщений для
определения данного специального ключа. Это часто упускают из виду –
многим системам с весьма низким уровнем надежности их создатели придают
неоправданно большое значение лишь на основании того, что эти системы очень
трудно или даже невозможно расшифровать, располагая всего лишь одним
сообщением.
Общие криптографические системы делятся на два основных класса в
соответствии с тем, как при их использовании поступают с исходным текстом,
если буквы незашифрованного текста только меняют местами (не изменяя их)
т.е. осуществляют их перестановку, то система называется транспозицией.
Если сами буквы заменяют некоторыми эквивалентами – другими буквами,
цифрами или какимилибо знаками, но их порядок при этом остается
неизменным, то соответствующая система называется перестановкой. В одной
криптограмме можно сочетать обе системы, применяя одну из них к результату,
полученному с помощью другой.
Ограничусь описанием классических систем зашифровки сообщений,
добавив в каждом случае несколько слов о методе их расшифровки. Обратите
внимание на различие понятий дешифровка и расшифровка. Первое из них
относится к процедуре, выбираемой адресатом сообщения, который посвящен
4во все детали системы и при дешифровке просто выполняет в обратном
порядке шаги, предпринятые при шифровке сообщения. Второе касается
метода, который используется противником, перехватившим чужое сообщение,
и состоит в применении принципов науки, называемой криптографическим
анализом.
1.3 Транспозиция.
Каждая транспозиция использует некую геометрическую фигуру, в
которую исходный текст вписывается по ходу одного «маршрута», а затем по
ходу другого списывается с нее.
Рассмотрю пример зашифровки по системе, обычно называемой
маршрутной транспозицией. Пусть нужно передать фразу:
Мне необходимо еще восемьсот рублей.
Предположим, что общая система использует целиком заполненный
прямоугольник с восьмью столбцами, так что если число букв сообщения не
кратно 8, то следует добавить «нерабочие» буквы. Добавим две такие буквы
УУ в конце сообщения – тогда получим 32 буквы. Далее для описания
сообщения выберем такой маршрут: будем двигаться по горизонтали, начиная,
с левого верхнего угла поочередно слева на право и справа налево. Получается
такое расположение:
Е Н Е О Б Х
М Н
Е Щ Е О М И Д О
С О
В
У
Т
С Е М Ь
Е Л Б У Р
О
Й
Если списывать буквы по вертикали, начиная с верхнего правого угла
и двигаясь поочередно сверху вниз и снизу вверх, то получим окончательно
зашифрованное сообщение, готовое для передачи; оно выглядит так:
хоотр сдбои ьубмм еноел есеей ощнме ву.
Обращение описанных шагов при дешифровке не представляет
трудности. Окончательный текст криптограмм обычно разбивают на группы по
5букв.
Системы такого типа отличаются очень низкой степенью надежности
и малой гибкостью (они плохо приспособлены к изменениям). Даже если
регулярно менять размеры прямоугольника и маршруты для вписывания и
5списывания, не составит большого труда расшифровать послания. Расшифровка
по существу производится «методом проб и ошибок», но число возможностей
здесь столь ограничено, что при определенном опыте ее можно осуществить за
достаточно короткое время.
Широко распространена разновидность маршрутной транспозиции,
называемая постолбцовой транспозицией. В этой системе снова используется
прямоугольник, но сообщение вписывается в него обычным способом.
Списываются буквы по вертикали, а столбцы при этом берутся в порядке,
определяемом числовым ключом. Пусть, например, этот ключ таков: 32714
65, и с его помощью надо зашифровать сообщение;
ПЛЕННЫЕ ЗАВЛАДЕЛИ ЖЕЛЕЗНОДОРОЖНОЙ СТАНЦИЕЙ.
Прежде всего, нужно вписать сообщение в прямоугольник, столбцы которого
помечены сверху ключевыми числами:
3 2 7 1 4 6 5
П
З
Л
Н
Н
Ц
Л Е Н Н Ы Е
А В Л А Д Е
И Ж Е Л Е
З
О Д О Р О Ж
О Й С Т А Н
И Е Й
Нецелесообразно заполнять последнюю строку прямоугольника
«нерабочими» буквами, т.к. это дало бы противнику сведения о длине ключа.
Теперь, списывая столбцы в порядке, указанном числовым ключом, и
одновременно подготавливая послание к передаче, т.е. разбивая его на группы
из 5 букв, получаем такой текст:
НЛЕОС ЙЛАИО ОИПЗЛ ННЦНА ЛРТЕЕ ЗЖНЫД ЕОАЕВ ЖДЙЕ.
При дешифровке в первую очередь надо определить число длинных столбцов,
т.е. число букв в последней строке прямоугольника. Для этого нужно разделить
число букв в сообщении на длину ключа. Остаток от деления и будет искомым
числом. Когда оно определено, буквы криптограммы можно водворить на их
собственные места – и сообщение будет восстановлено.
В случае, когда ключ довольно длинный и не рекомендуется его записывать,
числовую последовательность удобно извлекать из какогото легко
запоминающегося ключевого слова или предложения.
Наиболее распространенный способ состоит в том, чтобы
приписывать буквам числа в соответствии с обычным алфавитным порядком
букв. Например, пусть ключевым словом будет КРИПТОГРАФИЯ. Тогда,
буква А получает номер 1. далее, поскольку букв Б и В в этом слове нет, буква
Г получает номер 2, если какаято буква входит несколько раз, то ее появления
нумеруются последовательно слева направо. Поэтому первое появление
следующей по алфавиту буквы И получает номер 3, а второе – 4 и т.д. Процесс
6продолжается до тех пор, пока все буквы не получат номера. Таким образом,
возникает следующий полный числовой ключ:
К Р И П Т О Г Р А Ф И Я
5 8 3 7 10 6 2 9 1 11 4 12
Процедура расшифровки постолбцовой транспозиции основана на
том, что буквы каждого столбца списываются как единое целое. Первый шаг –
соединить две группы последовательных букв так, чтобы они образовали
хорошие с точки зрения обычного текста комбинации. Для этого используется
наиболее распространенный из двухбуквенных сочетаний (диаграмм), которые
можно составить из букв рассматриваемого шифрованного текста. Если для
первой пробы выбрано, скажем сочетание АБ, то мы можем по очереди
приписывать к каждой букве А из рассматриваемого текста каждую букву Б из
него; при этом несколько букв, стоящих до и после данной буквы А, и
несколько букв, стоящих до и после данной буквы Б, соединяются в пары, т.е.
получается два столбца букв, записанные рядом. Конечно, мы не знаем длины
столбцов, но некоторые ограничения на них можно получить, используя
положение конкретных букв. Так, столбцы должны иметь одинаковую длину
или первый столбец может быть длиннее второго на одну букву, но тогда это –
последняя буква сообщения. Если приписываемые друг к другу буквы
разделены, скажем, только двумя буквами, то, как легко видеть, мы можем
составить не более трех пар, и длина столбца сообщения не превышает четырех.
Кроме того, ограничением может послужить появление невозможной пары
(например, гласная – мягкий знак).
Для выбранного сочетания АБ получается по одной паре столбцов
для каждого конкретного выбора букв А и Б из сообщения, и из них надо
выбрать ту, которая содержит наиболее часто встречающиеся комбинации букв.
Относительные частоты появления отдельных букв,
двухбуквенных,
трехбуквенных и многобуквенных сочетаний можно считать постоянными
свойствами этих комбинаций в обычном нешифрованном тексте, т.к. их
определяют по текстам очень большого объема. Если приписать каждому
двухбуквенному сочетанию вес, равный относительной частоте его появления,
то очень просто отобрать ту пару столбцов, которая дает наибольший средний
вес. Появление одного сочетания с низкой частотой может указать на то, что
столбец надо ограничить.
Описанная процедура сильно упрощается, когда известны конкретные
слова, которые с большой вероятностью могут оказаться в рассматриваемом
сообщении.
На практике в распоряжении расшифровщика может оказаться много
сообщений, зашифрованных одним ключом. В этих случаях для быстрой
расшифровки можно использовать несколько методов.
7Рассмотрим метод, который применим к любым транспозиционным
системам. Допустим, что к двум или более сообщениям одинаковой длины
применяется одна и та же транспозиция. Тогда буквы, которые находились на
одинаковых местах в незашифрованных текстах, окажутся на одинаковых
местах и в зашифрованных. Пусть зашифрованные сообщения выписаны одно
под другим так, что первые буквы всех сообщений находятся в первом столбце,
вторые – во втором и т. д. в таком случае, если предположить, что две
конкретные буквы в одном из сообщений идут одна за другой в нешифрованном
тексте, то буквы, стоящие на тех же местах в каждом из остальных сообщений,
соединяются подобным же образом. Значит, они могут служить проверкой
правильности первого предположения, подобно тому, как комбинации, которые
дают два столбца при системе постолбцовой транспозиции, позволяют
проверить, являются ли соседними две конкретные буквы из этих столбцов. К
каждому из указанных двухбуквенных сочетаний можно добавить третью букву
для образования трехбуквенного сочетания (триграммы) и т.д. Это по
существу, составление анаграммы, где роль букв играют столбцы букв из
сообщений, выписанных друг под другом, при анализе здесь может быть
полезен математический метод суммирования частот.
Часто хороших результатов удается достичь, если для начала выбрать
какую нибудь комбинацию из двух букв, часто встречающихся вместе, скажем
СТ или КО. Если одна из двух букв двухбуквенного сочетания попадается
сравнительно редко, как, например, буква Щ в паре ЩЕ, то число
возможностей значительно уменьшается. Если располагать не менее чем
четырьмя сообщениями одинаковой длины, то можно с уверенностью
гарантировать их расшифровку. Однако не всегда эта расшифровка позволит
тотчас же прочитать еще одно сообщение другой длины. Чтобы добиться
этого, необходимо извлечь из уже расшифрованных сообщений некоторую
информацию о системе и ключе.
Вторая процедура,
очень плодотворная при расшифровке
постолбцовых транспозиций, применима к двум или более сообщениям,
содержащим длинные совпадающие куски текста. Такие куски нередко
встречаются в сообщениях, где используется стереотипная фразеология.
Чтобы лучше оценить эту процедуру, зашифруем с помощью числового ключа
86415327 два послания, содержащие одно и тоже выражение: ПЕРВАЯ И
ОДИННАДЦАТАЯ ДИВИЗИИ.
8 6 4 1
К
К
А Ю Т П Е
Я
Д
В
5 3 2 7
А К О Й П Р И
А З П О Л У Ч
В А
И О Д И Н Н А
Ц А Т А Я Д И
И З И И
Р
8Р
8 6 4 1 5 3 2 7
Е
П
В А Я И О
Д
И Н Н А Д Ц А
А Я Д И В И З
Т
И В Ы С Т У П
И
А Ю Т Ч Е
З
Ч
А С
Р
Е
В распоряжение лица, занимающегося расшифровкой, поступают
криптограммы:
1. оппдт ирувн дплвтр якзто азйое иаиаа юиции чааик каявд;
2. вндыч ициуе ядврт рнявт сааис ееиаи юаоаз пзпдт иач.
Совпадающие куски текста выделены курсивом.
Посмотрим, каким образом буквы, составляющие эти куски,
появляются в обоих сообщениях. Число частей, на которые они разбиты, равно
числу столбцов в прямоугольнике, и цифра над каждой частью – это ключевое
число, стоящее над соответствующим столбцом. Буквы ЯДВ в первом
зашифрованном сообщении находятся в конце своего столбца. Они указывают,
что совпадающий кусок расположен в конце соответствующего
незашифрованного сообщения. С другой стороны, буквы ВНД, с которых
начинается содержащий их столбец во втором зашифрованном сообщении,
показывают, что совпадающий кусок находится в начале соответствующего
незашифрованного
сообщения. Эта информация позволяет тотчас же
установить длину каждого столбца. В первом сообщении, например, столбец 1
содержит буквы ОППДТИ, столбец 2 буквы РУВНД и т.д. Во втором
сообщении столбец 1 содержит буквы ВНДЫЧ, столбец 2 – буквы ИЦИУЕ и
т.д. таким образом, мы можем выяснить, какие столбцы в каждом из сообщений
длинные и какие короткие.
В дополнение к полученным сведениям (которые и сами по себе
достаточно ценны) с помощью этих совпадающих кусков можно почти всегда
определить какиелибо части ключа, а иногда и весь ключ. Чтобы лучше
разобраться, как это делается, временно предположим, что исходные
прямоугольники нам известны. Заметим, что буква П – первая буква
совпадающего куска появляется в четвёртом столбце первого сообщения и в
первом столбце второго. Значит, произвольная буква этого куска в первом
сообщении будет располагаться на три столбца правее, чем во втором
(столбцы следуют друг за другом в циклическом порядке).
Буквы ВНД, которыми начинается второе шифровальное сообщение,
должны приходить из столбца с ключевым номером 1. Буквы ВНД первого
сообщения приходят из столбца с ключевым номером 2. Значит, ключ содержит
последовательность 1??2. Часть совпадающего куска, которая появляется во
9втором сообщении в столбце с ключевым номером 2, это ИЦИ, а в первом
сообщении эти буквы входят в столбец с ключевым номером 6. Следовательно,
по тем же соображениям,
что и выше, ключ должен содержать
последовательность 15?2??6?.
3
П
Л
Р
Н
Я
2
Р
У
В
Н
Д
7
И
Ч
А
А
И
6
А
А
И
Ц
И
5
Й
О
Е
И
А
И
4
8
К
К
З
К
А Ю Т
О
Я
Д
А
З
В
Продолжая таким же образом, мы построим весь ключ 15327864,
который является циклической перестановкой правильного ключа. Применив
это к первому шифрованному сообщению, получим
1
О
П
П
Д
Т
И
истинное начало сообщения (цикла) сразу можно определить внимательным
просмотром. Другой способ определить начало цикла – просмотреть, как
зашифрованное сообщение разбито на длинные и короткие столбцы. Поскольку
в исходном прямоугольнике все столбцы, имеющие лишнюю букву, стоят слева,
цикл должен начинаться с первого длинного столбца, который следует за
коротким. Т.о. мы смогли найти весь ключ благодаря тому, что величина
относительного сдвига соответствующих букв в совпадающих кусках и длина
ключа взаимно просты. Если бы эти два числа не были взаимно просты, то ключ
разбился бы на несколько частичных циклов – их число совпадало бы с
наибольшим общим делителем рассматриваемых двух чисел. Затем нам
пришлось бы соединить эти «подциклы» в полный ключ, что определило бы
несколько возможных расшифровок; однако сравнительно короткая проверка
позволила бы нам выяснить, какая из них правильная.
В описанной процедуре предполагалось, что нам известна величина
относительного сдвига. Иногда это так и бывает. Рассмотрим, например, два
сообщения с одинаковыми концами. После того как с помощью числа частей,
на которые разбиты совпадающие куски посланий, определена, длинна ключа,
становится известным,
сколько длинных столбцов в каждом из
прямоугольников. Разность между этими числами и есть искомый сдвиг. В
рассмотренном выше примере тоже определить относительный сдвиг, так как в
одном сообщении совпадающий кусок расположен вначале, а в другом в
конце. Поскольку этот кусок содержит 26 букв, его последняя буква должна
находиться во втором столбце второго сообщения. Кроме того, эта буква
лежит в последнем длинном столбце (пятом) первого сообщения, т.е. сдвиг в
данном случае – это сдвиг на 3 столбца.
Если же совпадающие куски в обоих сообщениях расположены на
одном и том же месте, так что величина сдвига равна нулю – как, например, в
10случае если оба сообщения начинаются с этого куска, то мы ничего не можем
узнать о настоящем числовом ключе описанным способом.
В тех случаях, когда величина относительного сдвига неизвестна, правильный
ответ можно получить с помощью сравнительно небольшого числа проб,
поочередно допуская каждую из возможностей.
Надежность постолбцовой транспозиции существенно возрастает,
если получившуюся криптограмму подвергнуть еще одной постолбцовой
транспозиции. На этом втором шаге можно использовать либо тот же самый,
либо какойто иной числовой ключ. Такую систему шифрования называют
двойной транспозицией.
В качестве последнего примера метода транспозиции упомянем о
классической системе шифрования, называемой решеткой. В этой системе
используется карточка с отверстиями, при зашифровке буквы с сообщениями
вписываются в эти отверстия. При дешифровке сообщение вписывается в
диаграмму нужных размеров, затем налагается решетка – и на виду
оказываются только нужные буквы незашифрованного сообщения. Если число
клеток на стороне решетки нечетно, то ее центральная клетка не вырезается.
(это пример поворотной решетки).
Во всех рассмотренных выше транспозиционных системах
шифрования единицей криптографической обработки служила отдельная
буква, однако, она может быть заменена группами букв или слогов или даже
целыми словами.
Простейшим примером подстановочной
1.4 Подстановочные системы.
системы служит такая, где каждая буква незашифрованного текста всегда
заменяется одним и тем же эквивалентом. Это, по всей видимости, самый
известный тип шифра и первое, что обычно приходит в голову новичку в
криптографии. Очевидно, что выбор эквивалента не играет принципиальной
роли. Но как это не удивительно, многие люди считают, что использование
сложных случайных символов обеспечивает системе большую надежность,
нежели применение букв и цифр.
Простейший способ реализации такой системы – выписать эквиваленты в
форме подстановочного алфавита,
который состоит из исходной и
шифровальной последовательностей, расположенных одна над другой. Букву
незашифрованного текста нужно найти в первой последовательности и заменить
соответствующим знаком из второй. Например, если пользоваться
подстановочным алфавитом,
Исходная последовательность
АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЩЪЫЬЭЮЯ
Шифровальная последовательность
АГЖЙМТХШЫЮБДЗКНРУЦЩЯВЕИЛОСФЧЪЭ,
11То предложение ВОЗВРАЩАЙСЯ ДОМОЙ ВСЕ ЗАБЫТО зашифровывается
так: ЖКХЖР АЛАЫУ ЭМКДК ЫЖУПХ АГСЦК.
Обычно в подстановочном алфавите подстановочная последовательность – это
нормальный алфавит. В этих случаях для определения всего подстановочного
алфавита достаточно задания одной шифровальной последовательности. В
зависимости от способа, которым стоится шифровальная последовательность,
подстановочные алфавиты делятся на три класса.
1. Стандартные алфавиты. Здесь шифровальная последовательность –
циклическая перестановка нормального алфавита или
обращенного
нормального алфавита. Это самый старый из известных типов подстановочных
алфавитов. Иногда такие системы шифрования системами Юлия Цезаря.
Однако, Цезарь использовал лишь один из возможных стандартных алфавитов;
у него шифровальной последовательностью всегда был нормальный алфавит,
начинающийся с буквы D.
2. Систематически перемешанные алфавиты. Неудобство использования
стандартных алфавитов очевидно: ведь здесь для определения всего алфавита
достаточно идентифицировать один или два символа. Чтобы обойти эту
трудность и при этом избежать необходимости выписывать шифровальную
последовательность,
нужно использовать некоторую систематическую
процедуру переупорядочения нормально алфавита.
Пусть в качестве ключевого выбрано слово без повторяющихся букв, скажем
РЫБАКИ. Впишем в прямоугольную таблицу все остальные буквы алфавита
по порядку под ключевым словом:
Р
В
Й
С
Ч
Ю
Ы
Г
Л
Т
Ш
Я
Б
Д
М
У
Щ
А
Е
Н
Ф
Ъ
К
И
Ж З
П
О
Ц
Х
Ь
Э
Переставим столбцы этой фигуры согласно числовому ключу,
основанному на слове РЫБАКИ, и перепишем их поочередно. Получится
шифровальная последовательность
АЕНФЪБДМУЩИЗПЦЭКЖОХЬРВЙСЧЫГЛТШЯ.
3.Случайные алфавиты. Здесь буквы шифровальной последовательности
расставляются случайным образом при таком методе шифрования текста
никакие ранее идентифицированные буквы не помогают определить
неизвестные буквы. Единственное неудобство последовательностей такого
12типа, заключается в том, что их слишком трудно запомнить и поэтому
приходится записывать.
Метод расшифровки систем, использующих только один
подстановочный алфавит, или как мы их будем называть, одноалфавитных
систем, довольно хорошо известен. Он основан на учете относительной
частоты появления отдельных букв алфавита или их сочетаний. Дальнейшую
помощь оказывает (1) определение гласных как часто встречающихся букв,
которые редко попадаются в комбинации друг с другом, так что, как правило,
между ними имеются определенные «средние интервалы»; (2) выбор особых
комбинаций букв, которые наводят на мысль об определенных словах или
выражениях обычного, нешифрованного текста ( примеры: ТО, ЧТО,
СКОЛЬКО, КОТОРОЕ и т. п.; они выделяются в шифрованном тексте
посредством интервалов между повторяющимися буквами – в этом случае
говорят о словоподобных структурах); (3) поиск вероятных слов, которые
всегда очень полезны при криптографическом анализе.
Относительно низкая надежность одноалфавитной системы
объясняется тем, что каждая буква незашифрованного текста имеет лишь один
эквивалент. Если мы требуем, чтобы этот эквивалент не мог представлять
никакую другую букву, и в то же время хотим обеспечить отдельные буквы
дополнительными эквивалентами, то нам необходимо располагать более чем
32 шифровальными знаками. Если, например, в качестве шифровальной
единицы мы возьмем двузначное число, то получим 100 возможных
эквивалентов: если же в качестве шифровальной единицы берется комбинация
из двух букв, то получается 1024 возможных эквивалентов. С введением
дополнительных эквивалентов становится возможным представлять каждую
букву незашифрованного текста одним из нескольких различных значений.
Если число эквивалентов
для каждой буквы пропорционально ее
относительной частоте появления ее в обычном тексте, то получающаяся
система
имеет гораздо более высокую надежность, чем обычная
одноалфавитная.
Однако и таким образом зашифрованный текст можно расшифровать
без особого труда. Процесс расшифровки состоит в том, чтобы свести
шифровальный текст к одноалфавитной форме, определив, какие из
шифровальных знаков эквивалентны друг другу. Это делается двумя
способами. 1. Сравнением относительных частот можно установить, что
некоторые из знаков комбинируются со всеми остальными одинаковым
образом; подобным исследованием всех их проявлений будет установлена
эквивалентность этих знаков, которые представляют одну и ту же букву
исходного текста. 2. Тщательное изучение повторений позволяет обнаружить
места, где стоит одно и то же слово, но по – разному зашифрованное. Можно,
например, обнаружить такие вхождения:
11 22 27 75 89 16 31
11 22 27 61 89 16 31
1311 22 45 75 82 16 31
Очевидный вывод: 27 и 45, 75 и 61, 82 и 89 – пары эквивалентных знаков.
Широкое исследование в этих двух направлениях даст существенную
информацию, и, прежде чем большое количество эквивалентов, для получения
идентификаций с незашифрованным текстом можно воспользоваться данными о
частотах и словоподобными структурами.
Система шифрования при которой, одна буква незашифрованного сообщения
заменяется комбинацией двух или более знаков, называется многобуквенной.
Код Морзе – пример многобуквенной системы, в которой шифровальные
эквиваленты имеют разную длину.
Скрывать истинную частоту появления можно более эффективным
способом, чем введение различных эквивалентов; это делается
путем
использования нескольких подстановочных алфавитов. Такие системы часто
называют многоалфавитными; они бывают двух совершенно различных типов
в зависимости от того, как в них используются алфавиты: периодически или
нет.
Чтобы привести простой пример системы первого типа, предположим,
что лица, ведущие секретную переписку, построили пять разных случайных
алфавитов
А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я
1 Г Е Й С Т Р У Б И Д Х А Ш Д Ъ Я Ь Б М Э К Ф Ю О Ж Щ Н Ы Ч З П Ц
2 Ф О Ч Ц П Л Х У Щ М Н Е Т Г С А Ю Э Ъ З Ь И Р Я Ы Б К Й В Ж Д Ш
3 М Б Я У Н Ъ А С Л Г Р Й В Ч Ц О Ы И Д Ъ Х Ф Щ К Щ Е Ю З Т П Ж Э
4 Б М Ф Л Ж С Р Ц З Х Щ Г У Ъ Я П А О Т Ы И Э Ь Д К Ю Ч В Н И Ш Е
5 К П Б Т Л У В Ч Р Ъ Щ С Й М Щ И Я Ф З Е Ы Ц Н Ь Г Ю Д Э Ж Х О А
ИСХОД
НАЯ
ПОСЛЕ
ДОВАТ
ЕЛЬНО
СТЬ
ШИФРО
ВАЛЬН
АЯ
ПОСЛЕ
ДОВАТ
ЕЛЬНО
СТЬ
Незашифрованное сообщение записывается в пять столбцов, и первый
алфавит применяется для зашифровки букв из первого столбца, второй для
зашифровки букв второго столбца и т.д. В результате с помощью аго алфавита
14шифруются буквы, которые в незашифрованном тексте имеют порядковый
номер вида 5к + а. При выписанных выше алфавитах предложение СЕГОДНЯ
ТОПЛЫВАЮТ ТРИ КОРАБЛЯ зашифровывается так: БЛУЯЛ ЛШЦТИ
АЙБО МЪЫЗШ ЪЮММС Ц.
Вместо того чтобы использовать фиксированное число алфавитов,
корреспонденты могут менять алфавиты регулярным изменением ключевого
слова. Объясним подробнее один из способов достижения этой цели. Такую
систему называют двойным ключом. Одно ключевое слово, например
НУМЕРАЦИЯ, используется для построения диаграммы, известной как
квадрат Винежера. Если рассматривать каждую строку квадрата, как
шифровальную последовательность, а выписанный над ним нормальный
алфавит – как исходную последовательность, то такая диаграмма дает 32
подстановочных алфавита. Пусть каждый из этих алфавитов обозначается
буквой, стоящей в первом столбце. Тогда второе ключевое слово, скажем,
АВГУСТ, применяется, чтобы выбрать конкретные алфавиты и порядок их
использования. Первый подстановочный алфавит алфавит А; он применяется
для зашифровки букв, порядковые номера которых в незашифрованном
сообщении имеют вид 6к+1. Вторым будет подстановочный алфавит В – сего
помощью шифруются буквы с порядковыми номерами вида 6к+2 и т.д. В
результате получается шифр с шестью алфавитами.
При указанных двух
СРОЧНО
НЕОБХОДИМО ПОДКРЕПЛЕНИЕ зашифруем так: ФЩШЧУ ЕОЙШМ
БЕБОХ ЙЕЕБС ЪЦЕНВ ХПЦ (см. приложение 4).
ключевых словах сообщение
Первый шаг расшифровки периодических многоалфавитных систем –
определение числа алфавитов. Чтобы понять, как это делается, предположим,
что в сообщении несколько раз повторяется одно и тоже слово. Любые два его
появления, находящиеся в одной и той же позиции по отношению к ключу,
дадут одинаковый шифрованный текст. Два появления, поразному
расположенные относительно ключа, не дадут повторения в шифрованном
тексте.
длина интервала между повторяющимися
шифровальными кусками кратна длине ключа. Точная длина ключа равна
наибольшему общему делителю длин всех интервалов между такими
повторяющимися кусками. Значит, если сообщение расписано по столбцам,
число которых равно длине ключевого слова, то все буквы любого из этих
столбцов будут зашифрованы одним подстановочным алфавитом.
Следовательно,
Второй шаг расшифровки – анализ отдельных одно алфавитных
шифров. Это в сущности та же процедура, которую мы описывали в связи с
одноалфавитными системами. Если некоторые из алфавитов совпадают, то это
можно обнаружить статистическими методами и объединить соответствующие
куски для частотного анализа. Кроме того, если разные алфавита связаны, как
в квадрате Виженера, то можно воспользоваться чему идентификации в одном
алфавите приводят к идентификациям в другом.
15Изучение непериодических многоалфавитных систем завело бы нас
далеко «в дебри» криптографического анализа, поэтому мы употребляем лишь
две системы такого типа.
1. Пусть построен квадрат Виженера, дающий 32 алфавита, каждый из
которых помечен одной буквой. Тогда ключом могут служить буквы самого
исходного незашифрованного сообщения. Например, условимся, что первым
будет алфавит А. Тогда первая буква шифруется с помощью этого алфавита.
После этого каждая последующая буква шифруется алфавитом, обозначенным
предшествующей ей буквой исходного сообщения. Такая система называется
самоключевой. Если квадрат Виженера основан на слове нумерация и в
качестве первого берется подстановочный алфавит А, то сообщение МОСТ
ВЗОРВАН примет вид ЛКЕЦХ ЛЫМЦВ О.
2. Система с бегущим ключом похожа на предыдущую, за тем лишь
исключением, что в качестве ключа здесь берется не само сообщение, а совсем
другой текст, например, отрывок из какойнибудь книги или журнала,
начинающийся с заранее оговоренной страницы и строки, или случайный набор
букв, копию которого имеет каждый из корреспондентов.
Непериодические системы первого из описанных типов имеют серьезный
недостаток с точки зрения их реализации. Если по какой либо причине в
сообщение внесена ошибка, в результате которой будет неправильно принята
всего одна буква, то при дешифровке это скажется на всех последующих
буквах. Поскольку среднее количество ошибок при передаче сообщения может
достигать 5%, это затрудняет, а иногда делает вообще невозможным прочтение
шифрованного сообщения.
Повышенная надежность многоалфавитных систем обусловлена тем, что при
их использовании маскируются частоты появления, характерные для
одноалфавитных систем. Однако эти частоты вновь проявляются, если тому,
кто занимается расшифровкой, удастся разбить сообщение на его одно
алфавитные компоненты. Такая возможность всегда имеется, если за единицу
криптографической обработки принята одна буква, как это было во всех
описанных выше подстановочных системах. Таким образом, мы пришли к идее
многосимвольной подстановки – замены сочетания букв из незашифрованного
текста шифровальной группой из стольких же букв.
В качестве первого примера опишем классическую двухсимвольную
систему, называемую шифром Плейфера. 30 ячеек располагают в виде (5×6)
прямоугольника и заполняются буквами алфавита в заранее предписанном
порядке (две буквы, скажем й и ъ, опускаются). Приведенный
ниже
прямоугольник содержит систематически перемешанную последовательность,
основанную на слове МАНЧЕСТЕР.
М А
Т
Р
Н
Б
Ч
В
Е
Г
С
Д
16Ж З
П
У
Щ Ы
И
Ф
Ь
К
Х
Э
Л
О
Ц Ш
Ю Я
Незашифрованное сообщение делится на пары букв, а чтобы не
допустить пар, состоящих из двух одинаковых букв, добавляется, когда это
необходимо, «нерабочая» буква, например, Х. таким образом, если сообщение
начинается словом РАССКАЗ, то оно разобьется на пары следующим образом:
РА СХ СК АЗ. Если обе буквы данной пары лежат в одной строке (или одном
столбце) прямоугольника, то при шифровании каждая из них заменяется
соседней справа (или снизу), причем совокупность букв в каждой строке и в
каждом столбце рассматривается как цикл. Если буквы пары не лежат на одной
строке или в одном столбце, то они обязательно лежат в противоположных
углах некоторого прямоугольника – тогда они заменяются буквами, стоящими
в двух других противоположных углах этого прямоугольника, причем каждая
из них заменяется той, которая находится в одной строке с ней. Сообщение НА
РАССВЕТЕ ВЫСТУПАЕМ записывается в виде НА РА СХ СВ ЕТ ЕВ ЫС ТУ
ПА ЕМ. С помощью приведенного прямоугольника оно шифруется так: ЧНЗРЧ
ШЧДМГ ЧГЯЛР ПУМСА.
Надежность этой и, по правде говоря, любой другой двухсимвольной
системы довольно низка. Относительные частоты двухбуквенных сочетаний
достаточно сильно различаются между собой, чтобы лицо, занятое
расшифровкой, могло извлечь большое количество информации из
рассмотрения одних лишь частот. Правильная идентификация всего лишь
нескольких двухбуквенных сочетаний обеспечивает расшифровку всего
сообщения. Кроме того, немалую пользу можно извлечь из вероятных слов и
словоподобных структур. Что касается последних, то здесь, тот, кто
занимается расшифровкой,
основанными на
двухбуквенных сочетаниях, например: РЕ ФЕ РЕ НД УМ, КА ЛЬ КА, МА ТЕ
МА ТИ КА.
ограничен структурами,
При использовании шифра Плейфера помогают еще и следующие
соображения. Если установлено, что СК заменяется на ЧО, то КС заменяется
на ОЧ. Вообще, если А1А2 = Б1Б2 , то А2А1 = Б2Б1. Кроме того, если известно,
что четыре буквы
А1, А2, Б1, Б2 расположены в углах некоторого
прямоугольника, то сразу же получаются следующие дополнительные
идентификации: Б1Б2 = А1А2; Б2Б1 = А2А1. Эти факты весьма полезны при
некоторых исследованиях частот – например, для различения эквивалентов
сочетания с высокой частотой типа СТ, обратное (ТС) к которому имеет
низкую частоту, и сочетания типа ОК, обратное (КО) к которому встречается
часто. Можно подчеркнуть, что весь прямоугольник при шире Плейфера
восстанавливается с помощью совсем небольшого числа идентификаций.
17Надежность многосимвольных подстановок очень быстро возрастает с
увеличением размера единицы криптографической обработки. Когда эта
единица состоит из пяти или шести букв, степень надежности очень высока. К
сожалению, на этом пути возникают серьезные практические трудности.
Ошибка в одной букве шифровальной группы приводит к неправильной
зашифровке целой единицы исходного текста, в результате чего искажаются
пять или шесть букв сразу. Поскольку при такой системе нельзя указать
способа исправления ошибок, то четыре или пять ошибок при передаче могут
сделать все сообщение совершенно непонятным. Это служит серьезным
препятствием для использования такого рода систем.
Во всех рассмотренных нами системах шифрования рассмотренный
текст не был короче исходного. Главной заботой была секретность, а
соображения экономичности не принимались в расчет. Однако эти соображения
часто приобретают первостепенное значение, что и привело к развитию
подстановочных систем с очень высокой степенью специализации, называемых
кодами. При использовании таких систем каждый из корреспондентов имеет
экземпляр словаря кода, содержащего длинный список слов, выражений и
предложений, рядом с каждым из которых стоит произвольный буквенный
эквивалент. В качестве эквивалентов здесь чаще всего используются группы из
пяти букв, хотя иногда применяются правильные сочетания меньшего числа
букв или (реже) группы цифр. Чтобы обеспечить обработку слов, которых
может не оказаться в словарном запасе кода, каждой отдельной букве
алфавита и большинству часто встречающихся слогов также сопоставляются
эквиваленты. В словарный запас кода включаются часто употребляемые
длинные выражения, и даже целые предложения, которые заменяют одной
кодовой группой. В результате, закодированное сообщение обычно оказывается
в четырепять раз короче исходного. Подобная сжатость сопряжена с
осложнениями, так как изза ошибки в одной кодовой группе может оказаться
утраченной значительная часть исходного текста. Чтобы избежать
необходимости повторных сообщений, приняты меры, обеспечивающие
исправление ошибок. Кодовые группы выбираются с помощью специальных
таблиц для построения кодов, которые гарантируют, что любые две кодовые
группы будут различаться, по крайней мере, двумя буквами. Тогда кодовая
группа полностью определится любыми четырьмя буквами. Если при этом одна
из букв искажена при передаче, то полученной группы не окажется в словаре
кода, и дешифровщик, таким образом, будет предупрежден и наличии ошибки.
Неправильной может быть любая из букв, поэтому имеется не более пяти
возможностей декодировать искаженное слово, и из контекста становится ясно,
какой из вариантов правильный. Эта процедура основана на предположении,
что в неправильно принятой группе только одна неверная буква. К счастью,
почти всегда так и бывает.
Дальнейшее усовершенствование таблиц для построения кодов,
помогают исправлять ошибки, гарантирует, что любые два кодовых слова из
18