Поделиться

Билет № 3
1. Дискретное представление информации: двоичные числа; двоичное кодирование текста в памяти компьютера. Информационный объем текста.
Человек способен воспринимать и хранить информацию в форме образов (зрительных, звуковых, осязательных, вкусовых и обонятельных). Зрительные образы могут быть сохранены в виде изображений (рисунков, фотографий и так далее), а звуковые — зафиксированы на пластинках, магнитных лентах, лазерных дисках и так далее.
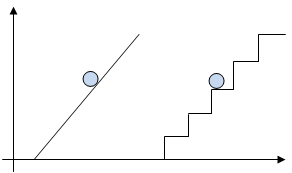 Информация,
в том числе графическая и звуковая, может быть представлена в аналоговой или
дискретной форме. При аналоговом представлении физическая величина
принимает бесконечное множество значений, причем ее значения изменяются
непрерывно. При дискретном представлении физическая величина принимает конечное
множество значений, причем ее величина изменяется скачкообразно.
Информация,
в том числе графическая и звуковая, может быть представлена в аналоговой или
дискретной форме. При аналоговом представлении физическая величина
принимает бесконечное множество значений, причем ее значения изменяются
непрерывно. При дискретном представлении физическая величина принимает конечное
множество значений, причем ее величина изменяется скачкообразно.
Примером аналогового представления графической информации может служить, например, живописное полотно, цвет которого изменяется непрерывно, а дискретного — изображение, напечатанное с помощью струйного принтера и состоящее из отдельных точек разного цвета. Примером аналогового хранения звуковой информации является виниловая пластинка (звуковая дорожка изменяет свою форму непрерывно), а дискретного — аудиокомпакт-диск (звуковая дорожка которого содержит участки с различной отражающей способностью).
Современный компьютер может обрабатывать числовую, текстовую, графическую, звуковую и видео информацию. Все эти виды информации в компьютере представлены в двоичном коде, т. е. используется алфавит мощностью два (всего два символа 0 и 1). Связано это с тем, что удобно представлять информацию в виде последовательности электрических импульсов: импульс отсутствует (0), импульс есть (1). Такое кодирование принято называть двоичным, а сами логические последовательности нулей и единиц - машинным языком.
Каждая цифра машинного двоичного кода несет количество информации равное одному биту.
Данный вывод можно сделать, рассматривая цифры машинного алфавита, как равновероятные события. При записи двоичной цифры можно реализовать выбор только одного из двух возможных состояний, а, значит, она несет количество информации равное 1 бит. Следовательно, две цифры несут информацию 2 бита, четыре разряда --4 бита и т. д. Чтобы определить количество информации в битах, достаточно определить количество цифр в двоичном машинном коде.
Кодирование текстовой информации
Традиционно для того чтобы закодировать один символ используют количество информации равное 1 байту, т. е. I = 1 байт = 8 бит. При помощи формулы, которая связывает между собой количество возможных событий К и количество информации I, можно вычислить сколько различных символов можно закодировать (считая, что символы - это возможные события):
К = 2I = 28 = 256, т. е. для представления текстовой информации можно использовать алфавит мощностью 256 символов.
Суть кодирования заключается в том, что каждому символу ставят в соответствие двоичный код от 00000000 до 11111111 или соответствующий ему десятичный код от 0 до 255.
Необходимо помнить, что в настоящее время для кодировки русских букв используют пять различных кодовых таблиц (КОИ - 8, СР1251, СР866, Мас, ISO), причем тексты, закодированные при помощи одной таблицы не будут правильно отображаться в другой кодировке. Наглядно это можно представить в виде фрагмента объединенной таблицы кодировки символов.
Одному и тому же двоичному коду ставится в соответствие различные символы.
|
Двоичный код |
Десятичный код |
КОИ8 |
СР1251 |
СР866 |
Мас |
ISO |
|
11000010 |
194 |
б |
В |
- |
- |
Т |
Впрочем, в большинстве случаев о перекодировке текстовых документов заботится на пользователь, а специальные программы - конверторы, которые встроены в приложения.
Начиная с 1997 г. последние версии Microsoft Windows&Office поддерживают новую кодировку Unicode, которая на каждый символ отводит по 2 байта, а, поэтому, можно закодировать не 256 символов, а 65536 различных символов.
Чтобы определить числовой код символа можно или воспользоваться кодовой таблицей, или, работая в текстовом редакторе Word 2003. Для этого в меню нужно выбрать пункт "Вставка" - "Символ", после чего на экране появляется диалоговая панель Символ. В диалоговом окне появляется таблица символов для выбранного шрифта. Символы в этой таблице располагаются построчно, последовательно слева направо, начиная с символа Пробел (левый верхний угол) и, кончая, буквой "я" (правый нижний угол).
Скачано с www.znanio.ru


Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.
