Поделиться

КОНЦЕПЦИИ ТРАДИЦИОННОГО ПРОГРАММИРОВАНИЯ
В этом разделе мы рассмотрим некоторые основные концепции, положенные в основу императивных и объектно- ориентированных языков программирования. Для этого рассмотрим примеры программ на языках Ada, С, C++, FORTRAN, Java и Pascal. FORTRAN, Pascal и С – императивные языки программирования третьего поколения, тогда как C++ – объект- но-ориентированный язык, который является расширением языка С. Java – это объектно-ориентированный язык, производ- ный от С и C++. Язык Ada изначально был разработан как императивный язык третьего поколения, обладающий многими объектно-ориентированными свойствами. Однако более поздние версии этого языка больше соответствуют объектно- ориентированной парадигме, чем императивной.
В приложении Г содержится краткое описание каждого из этих языков программирования, дополненное примером того, как алгоритм сортировки по методу вставки может быть реализован в каждом из них. Вы можете обращаться к этому прило- жению по мере чтения данного раздела. Помните, однако, что в данном случае наша цель – понять основные свойства язы- ков программирования. Приводимые здесь примеры предназначены просто для иллюстрации того, как обсуждаемые функции практически реализуются в существующих языках программирования, поэтому вам не следует слишком углубляться в их рас- смотрение.
Операторы в языках программирования обычно подразделяются на три категории: операторы объявления, выполняе- мые операторы и комментарии. Операторы объявления (declarative statements) задают способ представления, тип и структуру данных, которые в дальнейшем будет использоваться в программе. Выполняемые операторы (imperative statements) описы- вают шаги применяемого алгоритма, а комментарии (comments) повышают читабельность программы, поясняя ее специфи- ческие особенности в более удобной для пользователя форме. Этот раздел мы начнем с изучения понятий, связанных с опе- раторами объявления, затем перейдем к обсуждению выполняемых операторов и закончим рассмотрением примера доку- ментирования программы.
Переменные, константы и литералы. В разделе 5.1 говорилось о том, что языки программирования высокого уровня позволяют обращаться к ячейкам памяти через символьные имена, а не через числовые адреса. Такие имена называются пе- ременными (variable), тем самым подчеркивается тот факт, что при изменении значения, хранящегося в ячейке памяти, изме- няется и значение, присвоенное переменной.
Однако иногда в программе необходимо использовать фиксированное, заранее определенное значение. Например, про- грамма управления воздушными полетами в окрестности некоторого аэропорта может содержать многочисленные ссылки на высоту аэропорта над уровнем моря. При создании подобной программы можно конкретно указывать это значение (скажем, 645 футов), когда оно потребуется. Такое явное указание конкретного значения для данных называется литералом (literal). Использование литералов приводит к появлению в программах операторов, подобных приведенному ниже:
EffectiveAlt ← Altimeter+645,
где EffectiveAlt и Altimeter являются переменными, а значение 645 – литералом.
Как правило, применение литералов не считается лучшим стилем программирования, поскольку они затрудняют пони- мание тех выражений, в которых используются. Например, как читающий программу сможет узнать, что именно означает число 645? Кроме того, литералы могут усложнить модификацию программы, когда это станет необходимым. Если потре- буется использовать данную программу управления воздушным движением для другого аэропорта, то значение высоты аэ- ропорта над уровнем моря придется изменить. Если в программе для ссылки на эту высоту используется литерал 645, то каждую такую ссылку в программе нужно найти и изменить. Задача еще более усложнится, если окажется, что литерал 645 в некоторых случаях представляет также и другую величину, а не только высоту аэропорта над уровнем моря. Как тогда уз- нать, какой из литералов следует изменить, а какой оставить неизменным?
Традиции в языках программирования. Как и при использовании естественных языков, пользователи различных языков программирования стремятся выработать собственные традиции, отличающие их от остальных программистов, и часто вступают в дебаты по поводу преимуществ, присущих, по их мнению, тем воззрениям, которых они придержи- ваются. Иногда отличия могут быть очень существенными, особенно при использовании различных парадигм, в других же случаях они оказываются совершенно незначительными. Например, несмотря на различия, существующие между процедурами и функциями (подробно о них рассказывается в разделе 5.3), пользователи языка С называют оба конст- рукта функциями. Происходит это по той причине, что в языке С процедура рассматривается как функция, не возвра- щающая никакого значения. Аналогичный пример можно привести в отношении пользователей языка C++, которые ссылаются на функции, входящие в состав объектов, как на функции-члены, тогда как в объектно-ориентированной па- радигме для них используется термин "метод". Это расхождение имеет место по той причине, что C++ был разработан как расширение языка С.
Другим примером подобных расхождений является то, что в программах на языках Pascal и Ada зарезервированные слова принято выделять полужирным шрифтом, тогда как пользователи языков С, C++, Fortran и Java не придержива- ются этой традиции.
Текст этой книги выдержан в нейтральном стиле благодаря использованию классической терминологии, применяемой теоретиками. Однако каждый конкретный пример представлен в форме, совместимой с традициями данного языка. Встретив подобный пример, читатель должен помнить, что это всего лишь образец того, как теоретические идеи реализованы в реаль- ном языке программирования, и он вовсе не предназначен для обучения читателя особенностям работы с тем или иным язы- ком программирования.
Для решения подобных проблем языки программирования позволяют давать описательные имена конкретным постоян- ным величинам. Такое имя называется именованной константой или просто константой (constant). Например, рассмотрим следующий оператор объявления языка Pascal:
const AirportAlt = 645;
Этот оператор связывает идентификатор AirportAlt с фиксированным значением, равным 645. Аналогичные дейст- вия в языке Java записываются в виде следующего оператора:
final int AirportAlt = 645;
В результате подобного объявления имя AirportAlt можно будет использовать вместо литерала 645. Используя та- кую константу в нашем псевдокоде, мы можем переписать оператор
EffectiveAlt ← Altimeter + 645
в виде
EffectiveAlt ← Altimeter + AirportAlt.
Последний вариант лучше представляет смысл программы. Кроме того, если в программе вместо литералов использу- ются подобные именованные константы и эту программу потребуется перенести в другой аэропорт, расположенный на вы- соте 267 футов над уровнем моря, то все, что нужно сделать, для того чтобы присвоить всем ссылкам на высоту аэропорта новые значения, – это изменить одно-единственное объявление следующим образом:
const AirportAlt = 267;
Типы данных. Операторы объявления, с помощью которых данным присваиваются имена, обычно одновременно оп- ределяют и их тип. Тип данных (data type) определяет как область допустимых значений, так и операции, которые можно с ними выполнять. К основным типам данных относятся integer (целый), real (действительный), character (символьный) и Boo- lean (логический, или булев). Тип integer используется для обозначения числовых данных, являющихся целыми числами. В памяти они чаще всего представляются с помощью двоичной нотации с дополнением. С данными типа integer можно выпол- нять обычные арифметические операции и операции сравнения. Тип real предназначен для представления числовых данных, которые могут содержать нецелые величины. В памяти они обычно хранятся как двоичные числа с плавающей точкой. Опе- рации, которые можно выполнять с данными типа real, аналогичны операциям, выполняемым с данными типа integer. Одна- ко заметим, что манипуляции, которые следует выполнить, чтобы сложить два элемента данных типа real, отличаются от манипуляций, необходимых для выполнения аналогичных действий с переменными типа integer.
Тип character используется для данных, состоящих из символов, которые хранятся в памяти в виде кодов ASCII или UNICODE. Данные этого типа можно сравнивать друг с другом (определять, какой из двух символов предшествует другому в алфавитном порядке); проверять, является ли одна строка символов частью другой, а также объединять две строки в одну, более длинную строку, дописывая одну из них после другой (операция конкатенации).
Тип Boolean относится к данным, которые могут принимать только два значения: true (истина) и false (ложь). Примером таких данных может служить результат выполнения операции сравнения двух чисел. Операции с данными типа Boolean включают проверку, является ли текущее значение переменной true или false.
Другие типы данных, которым пока не соответствуют какие-либо общепринятые элементарные конструкции в основных языках программирования, – это аудио- и видеоданные. Встроенные средства для обработки таких данных имеются в среде про- граммирования языка Java.
В большинстве языков программирования требуется, чтобы операторы объявления не только вводили новую перемен- ную в программу, но и определяли ее тип. На рис. 5.4 приведены примеры таких объявлений в языках Pascal, С, C++, Java и FORTRAN. В каждом случае переменным Length и Width присвоен тип real, а переменным Price, Tax и Total – тип integer. Обратите внимание, что в языках С, C++ и Java для ссылки на тип данных real используется ключевое слово float, поскольку данные этого типа представляются в машине как числа с плавающей точкой.
В разделе 5.5 мы увидим, как транслятор использует сведения о типах данных при переводе программы с языка высоко- го уровня на машинный. Заметим, что эту информацию можно использовать и для обнаружения ошибок. Например, попытка сложить два значения типа character или выполнить операцию, манипулирующую данными разных типов, может вызвать у транслятора подозрение.
Структура данных. Другим понятием, связанным с операторами объявления, является структура данных (data struc- ture), определяющая общую форму представления данных. Например, текст обычно рассматривается как длинная строка символов, тогда как информация о продажах может рассматриваться как прямоугольная таблица с числовыми значениями, каждое из которых представляет число сделок, заключенных определенным работником в определенный день.
|
Описание переменных в var языке Pascal Length, Width: real; Price, Tax, Total: in teger; Symbol: char; |
|
Описание переменных в float Length, Width; языках C, C++ и Java int Price, Tax, Total; char Symbol; |
|
Описание переменных в REAL Length, Width языке FORTRAN INTEGER Price, Tax, Total CHARAKTER Symbol |
 Рис.
5.4. Объявление переменных в языках Pascal, C, C++, Java и FORTRAN
Рис.
5.4. Объявление переменных в языках Pascal, C, C++, Java и FORTRAN
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Рис. 5.5. Объявление двухмерного массива в языках C, C++, Java и Pascal
Одной из общих структур данных является однородный массив (homogeneous array), который представляет собой блок значений одного типа, например линейный список, двухмерную таблицу из строк и столбцов или таблицу более высокой размерности. Для объявления такого массива в большинстве языков программирования используются специальные операто- ры объявления, содержащие указания о длине каждой размерности массива. Например, на рис. 5.5 представлены операторы языков С, Java и Pascal, объявляющие переменную Scores как двухмерный массив целых чисел из двух строк и девяти столбцов.
Объявив однородный массив, мы можем ссылаться на него по имени в любом месте программы, а доступ к отдельным элементам массива можно получить с помощью индексов (indices), указывающих номер нужной строки, столбца и т.д. На- пример, в программе на языке Pascal элемент, находящийся на пересечении второй строки и четвертого столбца массива Scores, обозначается как Scores[2,4]; тогда как в языках С, C++ и Java этот же элемент массива будет обозначаться как Scores[1][3]. В этих языках нумерация строк и столбцов начинается с нуля, т.е. элемент, находящийся на пересечении первой строки и первого столбца массива, обозначается как Scores[0][0].
В противоположность однородному массиву, в котором все элементы имеют один и тот же тип, неоднородный массив
(heterogeneous array) представляет собой блок данных, в котором отдельные элементы могут иметь разный тип. Например, блок данных, относящийся к некоторому работнику, может содержать элемент Name типа character, элемент Age типа integer, а также элемент SkillRating типа real.
В языках Pascal и С такой тип массива называется соответственно записью (record) и структурой (structure). Ниже пока- зано, как можно объявить такой массив в языках С и Pascal.
![а) Объявления в языках C и C++
struct
{ char Name[8]; int Age;
float SkillRating;
} Employee;
б) Объявление в языке Pascal
var
Employee: record
Name: packed array[1..2,1..9] of char; Age: integer;
SkillRating: real; end;
в) Вид структуры, объявляемой в каждом из приведенных выше примеров
Employee](https://fs.znanio.ru/8c0997/f6/73/f3aeac622fbd4b48ff24516246e521d16a.png)
|
|
|
|
![]()
 Рис. 5.6. Объявление неоднородного массива в языках С, C++ и Pascal
Рис. 5.6. Объявление неоднородного массива в языках С, C++ и Pascal
При ссылке на компоненты неоднородного массива обычно указывают имя массива и имя элемента, разделенные точкой. Например, в языках С, C++, Java и Pascal для доступа к элементу Age массива Employee, показанного на рис. 5.6, можно исполь- зовать имя Employee.Age.
В главе 7 мы увидим, как концептуальные структуры, подобные массивам, реализуются в компьютерах. В частности, будет показано, что относящиеся к массиву данные могут быть распределены по большой области основной памяти или внешнего запоминающего устройства. Вот почему мы рассматриваем структуры данных как концептуальные формы их представления. В действительности же "реальная" форма представления данных в запоминающих устройствах машины мо- жет совершенно отличаться от теоретической формы.
Типы данных, определяемые пользователем. Часто удобнее описывать алгоритм, если используемые в нем типы данных отличаются от базовых типов данного языка программирования. Поэтому большинство современных языков про- граммирования предоставляет пользователю возможность определять дополнительные типы данных, используя в качестве строительных блоков базовые типы и структуры. Такие "самодельные" типы данных принято называть типами, определяе- мыми пользователем (user-defined types).
В качестве примера рассмотрим разработку программы, в которой будет использоваться множество переменных, имеющих одинаковую смешанную структуру, состоящую из имени, возраста и показателя квалификации некоторого работ- ника. Один из подходов может состоять в повторном объявлении состава этой структуры при каждом обращении к ней. На- пример, для создания переменной Employee, имеющей указанную смешанную структуру, работающий на языке С програм- мист мог бы написать следующий оператор (см. рис. 5.6 в главе 5):
Struct
{char Name[8]; // Имя
int Age; // Возраст
float SkillRating; // Показатель квалификации
} Employee; // Структура "Работник"
При таком подходе проблема состоит в том, что если описание структуры повторяется слишком часто, то программа увеличивается в размерах и чтение ее становится затруднительным. Лучше было бы описать структуру лишь однажды и присвоить ей описательное имя, а затем использовать его каждый раз при ссылке на данную структуру. Язык С позволяет программисту сделать это с помощью оператора typedef (сокращение от type definition, определение типа):
typedef struct
{char Name[8]; // Имя
int Age; // Возраст
float SkillRating; // Показатель квалификации
} EmployeeType; // Тип данных "Работник"
Этот оператор определяет новый тип данных, EmployeeType, который можно использовать при объявлении перемен- ных наряду с базовыми типами языка. Например, переменная Employee теперь может быть объявлена с помощью следую- щего оператора:
EmployeeType Employee;
Преимущество использования таких пользовательских типов очевидно при объявлении множества переменных этого типа. С помощью приведенного ниже оператора программист на языке С может объявить, что переменные Sleeve, Waist и Neck относятся к базовому типу "действительный":
float Sleeve, Waist, Neck;
Аналогично этому, после определения пользовательского типа EmployeeType, с помощью следующего оператора можно объявить, что переменные DistManager, SalesRepl и SalesRep2 относятся к данному типу:
EmployeeType DistManager, SalesRepl, SalesRep2;
Важно отличать определенные пользователем типы данных и сами элементы данных этих типов. Последние рассматри- ваются как реализации (instance) данного типа. Тип, определенный пользователем, по сути, является шаблоном, используе- мым при создании экземпляров данных этого типа. Он описывает свойства, которые имеют все реализации данного типа, но сам не является реальным представителем этого типа. В предыдущем примере тип пользователя EmployeeType использо- вался для создания трех реализаций этого типа: DistManager, SalesRepl и SalesRep2.
Указатели. Вспомните, что ячейки в оперативной памяти машины идентифицируются числовыми адресами. Эти чи- словые значения можно также хранить в ячейках памяти. Указатель (pointer) – это ячейка (или блок ячеек) памяти, содер- жащая адрес другой ячейки памяти. Применительно к структурам данных, указатели используются для записи адресов эле- ментов данных. Таким образом, элемент данных может храниться в какой-либо ячейке памяти, а адрес этой ячейки – в указа- теле, при помощи которого можно позже получить эти данные. То есть значение указателя сообщит нам, где искать данные. В некотором смысле указатель указывает на данные, отчего и получил такое название.
Мы уже встречались с концепцией указателей в контексте счетчика команд процессора, который содержит адрес оче- редной инструкции для выполнения. Фактически, другое название счетчика команд – указатель команд (instruction pointer). Адреса, также называемые URL, которые используются для связи гипертекстовых документов, также могут служить приме- ром концепции указателей, но они указывают местоположения в сети Интернет, а не в оперативной памяти компьютера.
Во многих современных языках программирования указатели включены в набор основных типов данных. Можно объ- являть, выделять память и манипулировать указателями так же, как целыми числами или строками. При помощи такого язы- ка программист может создавать развитые сети элементов данных в памяти машины, где каждый блок ячеек памяти содер- жит указатели на другие блоки. Следуя указателям, можно проследить эти пути от блока к блоку.
В качестве примера давайте представим, что в компьютерной памяти хранится список рассказов, отсортированный в алфавитном порядке по названию. Такая организация удобна во многих приложениях, но одновременно затрудняет поиск всех рассказов, написанных одним автором, так как они беспорядочно разбросаны по списку. Для решения этой проблемы можно зарезервировать в каждом блоке ячеек памяти, представляющем один рассказ, отдельную ячейку типа указатель. То- гда в каждом из этих указателей можно хранить адрес другого блока, представляющего произведение того же автора, и все рассказы одного автора будут связаны в замкнутую цепь. Отыскав один рассказ заданного автора, мы можем найти и все остальные, переходя по указателям от книги к книге.
Проблема указателей. Известно, что использование блок-схем может привести к путанице при разработке алгоритмов (см. главу 4), а беспорядочное использование команд безусловного перехода goto ведет к созданию плохо спроектированных программ (см. главу 5). Точно так же бессистемное использование указателей, как оказалось, может привести к созданию необоснованно сложных и потенциально приводящих к ошибкам структур данных. Чтобы внести некоторый порядок в этот хаос, многие языки программиро- вания ограничивают допустимую гибкость использования указателей. Например, в языке Java не разрешается использовать указатели общего вида. Допускается применение только ограниченных типов указателей – так называемых ссылок. Одно из отличий между ссылками и указателями состоит в том, что значение ссылки нельзя модифицировать с помощью арифметических операций. Напри- мер, если программист, работающий на языке Java, хочет переместить ссылку Next к следующему элементу массива, он должен ис- пользовать инструкцию, эквивалентную следующему выражению:
переадресовать ссылку Next к следующему элементу массива
Тогда как программист, работающий на языке С, может использовать инструкцию, эквивалентную следующей:
присвоить ссылке Next значение Next + 1
Заметим, что инструкция на языке Java лучше отражает назначение производимого действия. Более того, для выполнения инструк- ции языка Java необходимо, чтобы существовал еще один элемент массива. Однако если ссылка Next уже указывает на последний элемент массива, то выполнение инструкции языка С приведет к тому, что она будет указывать на нечто, находящееся вне массива, – распростра- ненная ошибка начинающих (и не только начинающих) программистов.
Операторы присваивания. Наиболее важным выполняемым оператором является оператор присваивания (assignment statement), предназначенный для присвоения переменной некоторого значения. Синтаксически форма этого оператора обыч- но состоит из имени переменной, символа операции присваивания и выражения, определяющего то значение, которое долж- но быть присвоено переменной. Семантика этого оператора заключается в вычислении выражения, стоящего в его правой части, и присвоении полученного результата переменной, указанной в левой части оператора. Например, в языках С, C++ и Java в результате выполнения приведенного ниже оператора, переменной Total присваивается сумма значений переменных Price и Tax:
Total = Price + Tax;
В языках Ada и Pascal эквивалентный оператор записывается в следующем виде:
Total := Price + Tax;
Обратите внимание, что эти операторы отличаются только синтаксисом операции присваивания, которая в языках С, C++ и Java обозначается просто знаком равенства, а в языках Ada и Pascal перед знаком равенства ставится двоеточие. Воз- можно, более удачное обозначение операции присваивания используется в языке APL (А Programming Language – язык про- граммирования), разработанном Кеннетом Иверсеном (Kenneth E. Iverson) в 1962 году. В этом языке для представления опе- рации присваивания используется стрелка. Таким образом, предыдущий оператор присваивания в языке APL (как и в нашем псевдокоде) будет записан следующим образом:
Total <— Price + Tax
"Мощь" оператора присваивания определяется диапазоном выражений, допустимых в правой части оператора. Как пра- вило, разрешается использовать любые алгебраические выражения с арифметическими операциями сложения, вычитания, умножения и деления, обычно обозначаемые символами +, –, * и /, соответственно. Однако языки программирования по- разному интерпретируют подобные выражения. Например, при вычислении выражения 2*4+6/2 справа налево получим результат 14, а слева направо – значение 7. Во избежание таких неоднозначностей обычно устанавливаются приоритеты операций (operator precedence), определяющие порядок выполнения операций в выражениях. Традиционно умножение и де- ление имеют более высокий приоритет, чем сложение и вычитание. Таким образом, операции умножения и деления должны выполняться до сложения и вычитания. В соответствии с этим при вычислении приведенного выше выражения получим ре- зультат 11. В большинстве языков программирования для изменения порядка выполнения операций используются скобки. В этом случае вычисление выражения 2*(4+6)/2 даст результат 10.
Выражения в операторах присваивания могут содержать не только обычные алгебраические операции. Например, пусть
First и Last – переменные, имеющие тип строки символов. Рассмотрим следующий оператор языка FORTRAN:
Both = First // Last
В результате его выполнения переменной Both в качестве значения будет присвоена строка символов, полученная по- средством конкатенации строк из переменных First и Last. Таким образом, если переменные First и Last содержат строки abra и cadabra, соответственно, то переменная Both будет иметь значение abracadabra.
Многие языки программирования позволяют использовать один и тот же символ для обозначения нескольких типов операций. В таких случаях значение символа определяется типом операндов. Например, символ + обычно означает опера- цию сложения, если операнды являются числами, но в некоторых случаях, например в языке Java, этот символ означает опе- рацию конкатенации, если операндами являются строки символов. Такое многозначное использование символов операций называется перегрузкой (overloading).
Управляющие операторы. Управляющие операторы (control statement) предназначены для изменения порядка выпол- нения программы. Из всех операторов именно они привлекают к себе наибольшее внимание и порождают большинство спо- ров. Главным виновником этого является самый простой из всех управляющих операторов – оператор goto. Он позволяет изменить порядок выполнения программы путем перехода к другому месту программы, обозначенному специально для этой цели именем или числом. Таким образом, этот оператор является ничем иным, как прямым применением машинной команды передачи управления в другое место программы. Проблема оператора goto заключается в том, что в языках программиро- вания высокого уровня он позволяет программисту писать очень запутанные тексты, пронизанные операциями перехода, как крысиными норами:
goto 40
20 Total = Price + 10
goto 70
40 if Price < 50 then goto 60
goto 20
60 Total = Price + 5 70 ...
Однако эти же действия можно выполнить с помощью буквально двух следующих операторов:
if (Price < 50)
then Total = Price + 5
else Total = Price + 10
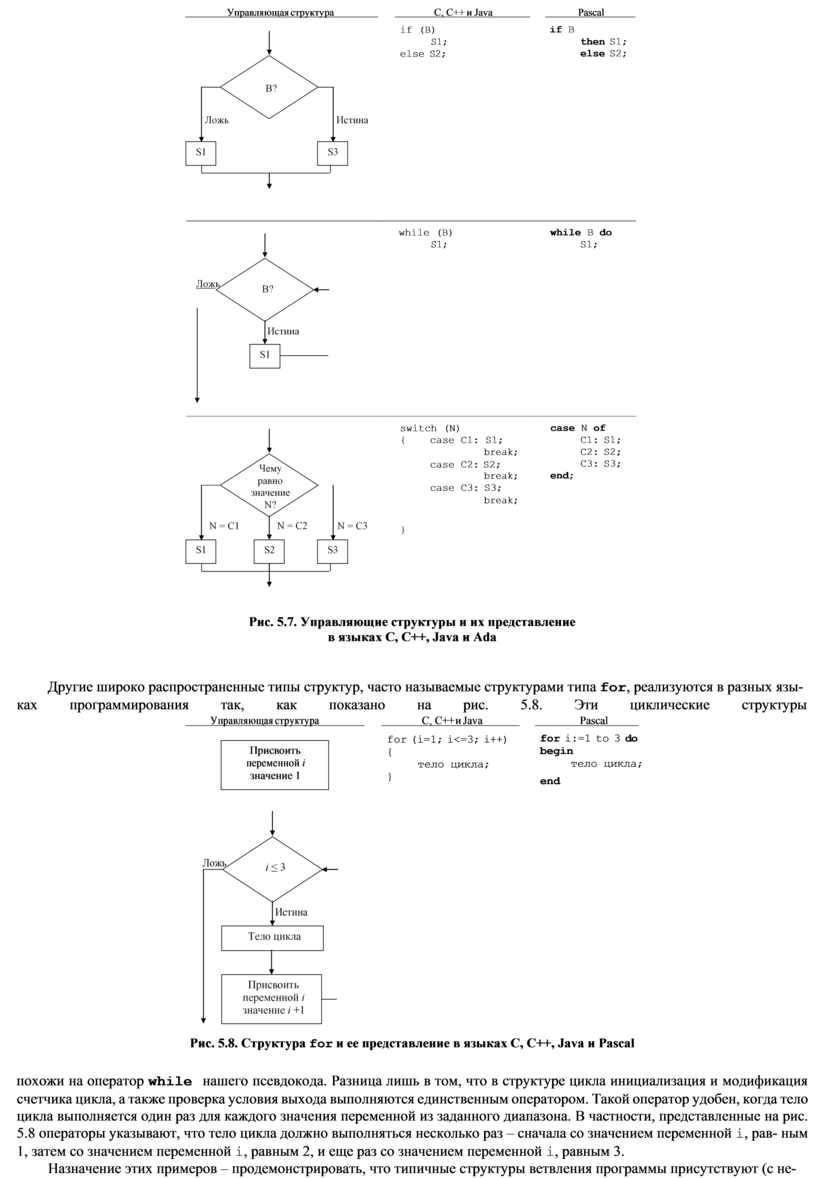
Чтобы избежать подобных ситуаций, современные языки программирования включают более продуманный набор управляющих операторов, позволяющий представлять разветвленные структуры с помощью единственного оператора. На рис. 5.7 показаны некоторые наиболее распространенные структуры ветвления и соответствующие управляющие операторы, используемые в различных языках программирования для их представления. Заметим, что первые два типа структур уже упоминались в главе 4. В нашем псевдокоде они представляются операторами if-then-else и while. Третью структуру, известную под названием "оператор case", можно рассматривать как обобщение структуры if-then-else. В то время как структура if-then-else допускает выбор только из двух возможностей, оператор case позволяет сделать выбор од- ного из многих описанных вариантов.
Управляющая структура C, C++ и Java Pascal
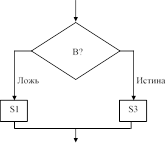 if (B)
if (B)
S1;
else S2;
if B
then S1;
else S2;
![]()
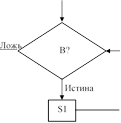 while (B)
while (B)
S1;
while B do
S1;
![]()
![]()
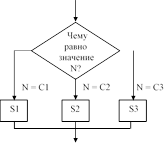 switch (N)
switch (N)
{ case C1: S1; break;
case C2: S2;
break; case C3: S3;
break;
case N of
C1: S1;
C2: S2;
C3: S3;
end;
}
Рис. 5.7. Управляющие структуры и их представление в языках C, C++, Java и Ada
Другие широко распространенные типы структур, часто называемые структурами типа for, реализуются в разных язы- ках программирования так, как показано на рис. 5.8. Эти циклические структуры
Управляющая структура C, C++ и Java Pascal
![]() for (i=1;
i<=3; i++)
for (i=1;
i<=3; i++)
{
тело цикла;
}
for i:=1 to 3 do begin
тело цикла;
end
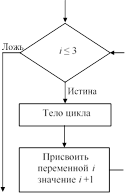
Рис. 5.8. Структура for и ее представление в языках С, С++, Java и Pascal
похожи на оператор while нашего псевдокода. Разница лишь в том, что в структуре цикла инициализация и модификация счетчика цикла, а также проверка условия выхода выполняются единственным оператором. Такой оператор удобен, когда тело цикла выполняется один раз для каждого значения переменной из заданного диапазона. В частности, представленные на рис. 5.8 операторы указывают, что тело цикла должно выполняться несколько раз – сначала со значением переменной i, рав- ным 1, затем со значением переменной i, равным 2, и еще раз со значением переменной i, равным 3.
Назначение этих примеров – продемонстрировать, что типичные структуры ветвления программы присутствуют (с не-
значительными отличиями) во всех существующих императивных и объектно-ориентированных языках программирования. Однако, хотя это может показаться несколько неожиданным, с теоретической точки зрения компьютерной науки лишь не- многие из этих структур являются действительно необходимыми для записи алгоритма решения любой задачи на некотором языке программирования. Мы обсудим это позже, в главе 11. Пока же просто отметим, что изучение языка программирования не сводится к бесконечному изучению различных управляющих операторов. В действительности большинство управляющих структур, имеющихся в современных языках программирования, по сути, являются лишь вариантами тех структур, которые мы уже рассмотрели здесь.
Выбор набора управляющих структур, предназначенных для включения в язык программирования, является одним из аспектов его разработки. Задача состоит не только в том, чтобы обеспечить язык средствами выражения алгоритмов в наи- более удобной форме, но и в том, чтобы помочь программисту действительно достичь этого. Для достижения этой цели не- обходимо отказаться от использования тех языковых конструкций, которые допускают небрежное программирование, и по- ощрить применение более продуманных проектных решений. Результатом такого подхода стала разработка часто неверно трактуемой методологии, известной как структурное программирование (structured programming). Она объединяет в себе строгие требования к организации проектирования с соответствующим использованием управляющих структур языка про- граммирования. Назначение этого подхода заключается в создании понятных и хорошо организованных программ, полно- стью отвечающих требованиям своих спецификаций.
Комментарии. Как показывает практика, независимо от того, насколько хорошо разработан язык программирования и насколько правильно использованы его возможности, всякий раз, когда человек пытается разобраться в программе сколько- нибудь значительного размера, дополнительная информация о ней оказывается либо полезной, либо просто необходимой. Поэтому в языках программирования предусмотрены синтаксические конструкции для вставки в программу поясняющих операторов, называемых комментариями (comments). Документация, составленная из таких комментариев, называется внутренней, поскольку она заключена внутри программы, а не в отдельном документе.
Транслятор игнорирует внутреннюю документацию, поэтому ее наличие или отсутствие с машинной точки зрения ни- как не влияет на саму программу. Машинная версия программы, созданная транслятором, будет одной и той же, независимо от того, содержит исходный код комментарии или нет. Однако содержащаяся в этих комментариях информация является важной частью программы с точки зрения человека. Без такого документирования большие и сложные программы часто превышают пределы понимания программиста.
Существуют два способа выделения комментариев из остального текста программы. Первый состоит в том, чтобы по- метить весь комментарий специальными маркерами, поставив один из них в начале, а второй – в конце текста комментария. Другой способ – отметить начало комментария и считать, что он занимает всю оставшуюся часть строки справа от маркера. Оба способа применяются в языках C, C++ и Java. В них комментарий может размещаться между парами символов /* и */ и содержать более одной строки, или начинаться символами // и продолжаться до конца текущей строки. Таким образом, в языках C, C++ и Java оба приведенные ниже варианта оператора комментария являются правильными:
/* Это комментарий. */
// Это тоже комментарий.
Скажем несколько слов о том, что следует считать осмысленным комментарием. Начинающие программисты при вне- сении комментариев в целях создания внутренней документации обычно делают это следующим образом:
Total := Price + Tax; // Вычисляем Total, складывая Price и Tax
Подобные комментарии совершенно излишни и скорее просто увеличивают размер программы, нежели проясняют ее суть. Запомните, что задача внутренней документации – объяснить другому программисту смысл программы, а не просто перефразировать выполняемые в ней действия. Более приемлемым комментарием для приведенного выше оператора было бы краткое пояснение, зачем вычисляется значение Total, если это не очевидно из предыдущего текста. Например, ком- ментарий "Переменная Total используется ниже при вычислении значения переменной GrandTotal и после этого будет не нужна" будет более полезен, чем предыдущий.
Кроме того, программа, в которой комментарии беспорядочно разбросаны среди выполняемых операторов, может быть
еще более непонятной, чем программа вовсе без комментариев. Лучше собрать все относящиеся к некоторому модулю про- граммы комментарии в одном месте, например в начале модуля, где читатель программы сможет найти объяснения. Здесь также целесообразно будет описать задачу и общие свойства данного программного модуля. Если это принять для всех мо- дулей, то получится единообразно выполненная программа, каждая часть которой будет состоять из блока поясняющих комментариев и следующих за ними выполняемых операторов. Такое единообразие программы существенно улучшает ее читабельность.
1. Почему использование констант вместо литералов считается лучшим стилем программирования?
2. В чем разница между оператором объявления и выполняемым оператором?
3. Перечислите некоторые из наиболее распространенных типов данных.
4. Назовите некоторые из наиболее распространенных управляющих структур, существующих в императивных и объ- ектно-ориентированных языках программирования.
5. Чем отличаются однородные и неоднородные массивы?








Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.