Поделиться

Сховища даних і бази знань
Основні проблеми, пов'язані з аналізом інформації, як правило, обумовлені розрізненістю даних у першоджерелах, їх якістю та рівнем готовності (відсутністю агрегатів, обчислюємих показників) для рішення аналітичних задач. Тому на сьогоднішній день найбільш затребуваною технологією, використовуваною при реалізації аналітичної інформаційної системи, є Сховища даних, за допомогою яких вирішуються задачі збору, очищення і перетворення первинних даних.
Основними ідеями, що лежать в основі концепції сховища даних, є:
- інтеграція роз'єднаних деталізованих даних, які описують деякі конкретні факти, властивості, тощо у єдиному сховищі;
- поділ наборів даних і додатків на використовувані для оперативної обробки й застосовувані для рішення за дач аналізу.
На початку вісімдесятих років минулого століття в період бурхливого розвитку реєструючих ІС виникло розуміння обмеженості можливостей застосування БД для цілей аналізу даних і побудови на їх основі систем підтримки прийняття рішень. IC створювалися для автоматизації рутинних операцій по веденню бізнесу - виписка рахунків, оформлення договорів, перевірка стану складу і т.д. Користувачами таких систем був в основному лінійний персонал. Основні вимоги, які пред'являлися до систем - забезпечення транзакційності внесених змін і максимізація швидкості їх виконання. Саме ці вимоги визначили вибір реляционных СУБД і відповідної моделі подання даних у якості основних використовуваних технічних рішень при побудові реєструючих систем.
Для менеджерів і аналітиків були потрібні системи, які б дозволяли:
- аналізувати інформацію в тимчасовому аспекті;
- формувати довільні запити до системи;
- обробляти більші обсяги даних;
- інтегрувати дані з різних реєструючих систем.
Очевидно, що реєструючі системи не задовольняли жодній з вищевказаних вимог. У реєструючих системахінформація актуальна тільки на момент звертання до бази даних, у наступний момент часу за тим же запитом можна одержати зовсім інший результат. Інтерфейс реєструючих систем розрахований на проведення жорстко певних операцій і можливості одержання результатів на нерегламентований запит сильно обмежені. Можливість обробки більших масивів даних також мала через настроювання СУБД на виконання коротких транзакцій і неминучого вповільнення роботи інших користувачів.
Відповіддю на виниклу потребу стала поява нової технології організації баз даних - технології сховищ даних.
Сховище даних (СД) — це система, що містить несуперечливу інтегровану предметно-предметно-орієнтовану сукупність історичних даних великої корпорації або іншої організації з метою підтримки прийняття стратегічних рішень [27] .
Інформаційні ресурси СД формуються шляхом витягу моментальних знімків БД операційної ІС організації й різних зовнішніх джерел. СД збирає, очищає, завантажує, агрегирует, зберігає дані й надає до них швидкий доступ.
При ефективному використанні СД може бути одним з основних джерел достовірної інформації для керівників і фахівців всіх підрозділів організації. Це забезпечить погодженість, своєчасність і обґрунтованість прийняття управлінських рішень, полегшить вивірку обов'язкової звітності, випуск управлінської звітності.
Про сховище даних можна говорити як про сукупність джерела даних (структура зв'язаних таблиць - це і є сховище), де збирається інформація для подальшої обробки, і процедур витягу, перетворення й завантаження даних (ETL - extractіon, transformatіon, loadіng).
Фізично сховище даних являє собою реляционную базу даних. Однак на відміну від БД корпоративних інформаційних систем (КІС) сховище має принципово іншу структуру. Наприклад, сховище містить агрегированные дані, що обчислюються показники, зберігає історичні накопичені дані по конкретних об'єктах (період зберігання інформації - тривалий). На відміну від СД бази даних КІС містять деталізовані дані, період їхнього зберігання відносно короткий.
Класична архітектура СД складається з наступних елементів: реляционная, багатомірна, або гібридна БД, засобу витягу, очищення й завантаження даних, засобу візуалізації даних і генерації звітів ( OLAP-Клієнти). Реляционная БД будується по архітектурі "зірка", у якій з однією таблицею фактів зв'язані кілька таблиць вимірів (довідників), або "сніжинка", що відрізняється наявністю ієрархічних довідників. Це робиться для оптимізації швидкості виконання об'ємних запитів (останнім часом з'явилося багато статей, що критикують цей підхід за його спрощеність і неможливість рішення винятково в рамках "зірки" усього різноманіття завдань сД). У багатомірної БД будуються "куби" - специфічні структури, аналогічні за змістом реляционным "сніжинкам", але обчислені агрегати, що зберігають, на всіх перетинаннях вимірів.
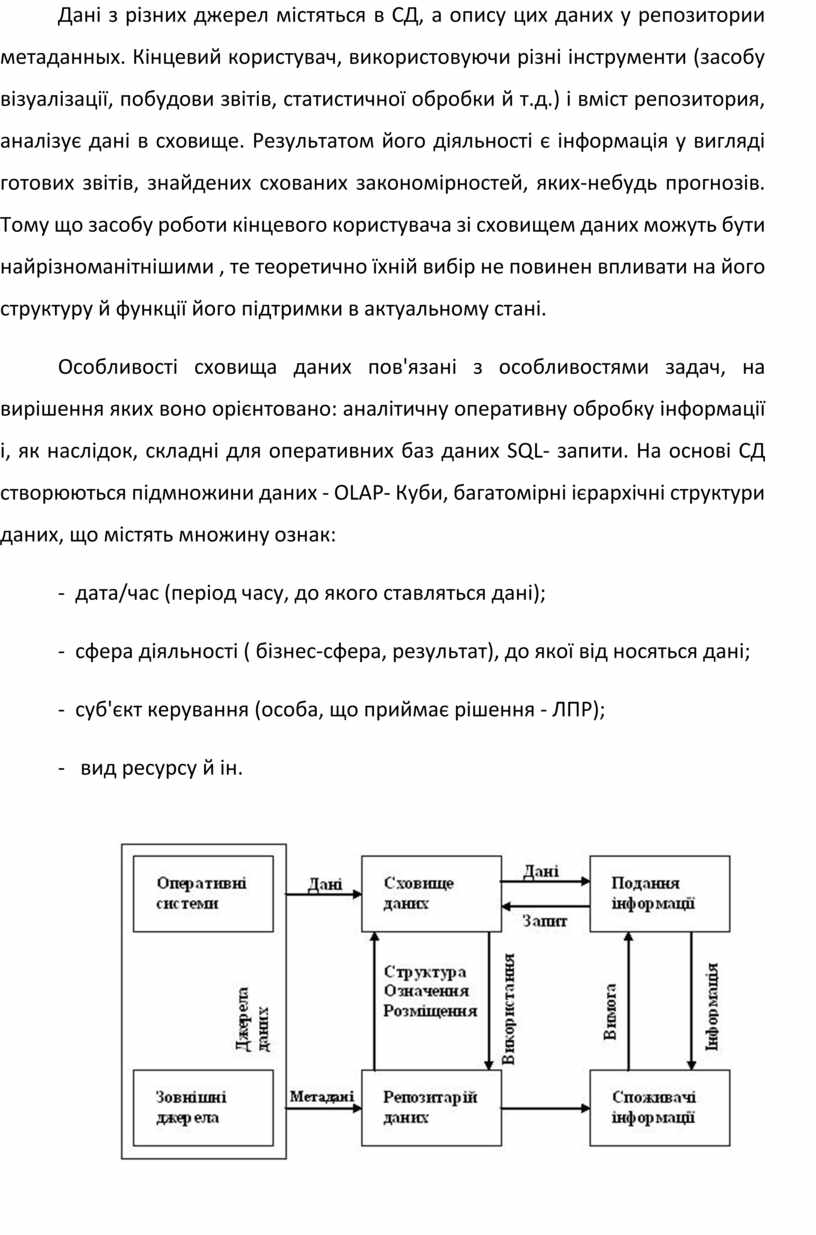
Концептуально модель сховища даних можна представити у вигляді схеми, показаної на рис. 2.9.
Дані з різних джерел містяться в СД, а опису цих даних у репозитории метаданных. Кінцевий користувач, використовуючи різні інструменти (засобу візуалізації, побудови звітів, статистичної обробки й т.д.) і вміст репозитория, аналізує дані в сховище. Результатом його діяльності є інформація у вигляді готових звітів, знайдених схованих закономірностей, яких-небудь прогнозів. Тому що засобу роботи кінцевого користувача зі сховищем даних можуть бути найрізноманітнішими , те теоретично їхній вибір не повинен впливати на його структуру й функції його підтримки в актуальному стані.
Особливості сховища даних пов'язані з особливостями задач, на вирішення яких воно орієнтовано: аналітичну оперативну обробку інформації і, як наслідок, складні для оперативних баз даних SQL- запити. На основі СД створюються підмножини даних - OLAP- Куби, багатомірні ієрархічні структури даних, що містять множину ознак:
- дата/час (період часу, до якого ставляться дані);
- сфера діяльності ( бізнес-сфера, результат), до якої від носяться дані;
- суб'єкт керування (особа, що приймає рішення - ЛПР);
- вид ресурсу й ін.

Рис. 2.9. - Концептуальна модель сховища даних
Ці ознаки дозволяють агреговати дані шляхом довільного сполучення ознак і обчислення статистичних оцінок. У результаті аналізу інформації створюється нове знання, корисне для цілей керування. Дані в сховище попадають з оперативних систем ( OLTP-Систем), які призначені для автоматизації бізнес- процесів. Крім того, сховище може поповнюватися за рахунок зовнішніх джерел, наприклад статистичних звітів.
На питання "Навіщо будувати сховища даних - адже вони містять свідомо надлишкову інформацію, що і так є присутнім у БД або файлах оперативних систем?", можна відповісти, що аналізувати дані оперативних систем прямо неможливо або дуже складно. Це пояснюється різними причинами, у тому числі розрізненістю даних, зберіганням їх у форматах різних СУБД і в різних "куточках" корпоративної мережі. Але навіть якщо на підприємстві всі дані зберігаються на центральному сервері БД, аналітик майже напевно не розбереться в їх складних, часом заплутаних структурах.
QLAP ( On-Lіne Analytіcal Processіng) не являє собою необхідний атрибут сховища даних, але він все частіше і частіше застосовується для аналізу накопичених у цьому сховищі відомостей.
![]() Оперативні дані збираються з різних
джерел, очищуються, інтегруються і складаються в реляційне сховище. При цьому вони вже
доступні для аналізу за допомогою різних засобів побудови звітів. Потім дані
(повністю або частково) підготовляються для OLAP- Аналізу. Вони можуть бути завантажені в спеціальну БД OLAP або
залишені в
Оперативні дані збираються з різних
джерел, очищуються, інтегруються і складаються в реляційне сховище. При цьому вони вже
доступні для аналізу за допомогою різних засобів побудови звітів. Потім дані
(повністю або частково) підготовляються для OLAP- Аналізу. Вони можуть бути завантажені в спеціальну БД OLAP або
залишені в ![]()
![]()
реляційному сховищі. Найважливішим його елементом є метадані, тобто інформація про структуру, розміщення й трансформацію даних. Завдяки їм
забезпечується ефективна взаємодія різних компонентів сховища. Таким чином, задача сховища - надати "сировину" для аналізу в одному місці у простій, зрозумілій структурі.
Є й ще одна причина, що виправдує появу окремого сховища. Складні аналітичні запити до оперативної інформації гальмують поточну роботу компанії, надовго блокуючи таблиці і захоплюючи ресурси сервера.
Основними причинами, що спонукають організації впроваджувати сховища даних, є:
- необхідність виконання аналітичних запитів і генерації звітів на не задіяних основними ІС обчислювальних ресурсах;
- необхідність використання моделей даних і технологій, що прискорюють процес виконання запитів, але не призначені для обробки транзакцій;
- створення середовища, у якому навіть невеликих знань щодо СУБД досить для створення запитів і підготування звітів, що означає скорочення часу, необхідного для персоналу ІТ- відділу для супроводу системи;
- створення джерела з попереднього очищення информації;
- спрощення процесу підготовки звітів на основі информації з декількох транзакційних систем і/або зовнішніх джерел даних і/або даних, використовуваних винятково для генерації звітів;
- створення виділеного джерела в тих випадках, коли можливості операційної системи не відповідають необхідному бізнесом строку зберігання даних і/або необхідно мати можливість підготовки звітів на певні моменти часу в минулому;
- захист кінцевих користувачів від необхідності в який би то не було ступеня вникати в структуру й логіку роботи БД реєструємої системи.
Перехід від даних до знань - логічний наслідок розвитку й ускладнення інформаційно-логічних структур, оброблюваних за допомогою комп'ютера. Активно розвиваємою областю використання сучасних комп'ютерів є створення баз знань (БЗ) і їх застосування в різних галузях науки й техніки.






Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.
