МНОГОВАРИАНТНОСТЬ
Конфигурационные построения, разбиравшиеся в предшествующих главах, могут использоваться практически всюду, где требуется разработка достаточно сложных программ. Область применения вариантного программирования, о котором пойдет речь в данной главе, также весьма широка. (Достаточно вспомнить вариантные фрагменты, настраивающие приложение на ту или иную вычислительную платформу, — с ними, вероятно, многим доводилось иметь дело.) Но относительный вес манипуляций над вариантами в общем объеме работ зачастую оказывается не таким уж заметным, из-за чего потребности в рациональном их оформлении отодвигаются на задний план.
Существует, однако, важный класс задач, для которого эффективное обеспечение многовариантности совершенно необходимо, более того, оно превращается в центральную проблему организации программирования. Этот класс задач — вычислительный эксперимент.
Вычислительный эксперимент. Построение математической модели
МНОГОВАРИАНТНОСТЬ
Конфигурационные построения, разбиравшиеся в предшествующих главах, могут
использоваться практически всюду, где требуется разработка достаточно сложных
программ. Область применения вариантного программирования, о котором пойдет речь в
данной главе, также весьма широка. (Достаточно вспомнить вариантные фрагменты,
настраивающие приложение на ту или иную вычислительную платформу, — с ними,
вероятно, многим доводилось иметь дело.) Но относительный вес манипуляций над
вариантами в общем объеме работ зачастую оказывается не таким уж заметным, изза чего
потребности в рациональном их оформлении отодвигаются на задний план.
Существует, однако, важный класс задач, для которого эффективное обеспечение
многовариантности совершенно необходимо, более того, оно превращается в центральную
проблему организации программирования. Этот класс задач — вычислительный
эксперимент.
4.1. Вычислительный эксперимент
Вычислительный эксперимент — метод изучения устройств или физических
процессов с помощью математического моделирования. Он предполагает, что вслед за
построением математической модели проводится ее численное исследование, позволяющее
«проиграть» поведение исследуемого объекта в различных условиях или в различных
модификациях [Самарский, 1979; ГорбуновПосадов, 1990].
Численное исследование модели дает возможность определять разнообразные
характеристики процессов, оптимизировать конструкции или режимы функционирования
проектируемых устройств. Более того, случается, что в ходе вычислительного
эксперимента исследователь неожиданно открывает новые процессы и свойства, о которых
ему ранее ничего не было известно.
4.1.1. Сфера применения. Вычислительный эксперимент занимает промежуточное
положение между натурным экспериментом и аналитическим исследованием.
Натурный (физический) эксперимент при надлежащей постановке может, вообще
говоря, дать исчерпывающие и надежные результаты. И все же во многих случаях
предпочтение отдается вычислительному эксперименту.
Дело в том, что в вычислительном эксперименте в роли опытной установки выступает
не конкретное физическое устройство, а программа. Ее построение и последующиемодификации, как правило, требуют существенно меньших затрат, чем подобные
манипуляции над реальным объектом.
Кроме того, в опытной установке нередко просто невозможно бывает воссоздать
некоторые критические режимы или экстремальные условия. Поэтому математическое
моделирование может оказаться практически единственно возможным способом
исследования.
При аналитическом подходе так же, как и в вычислительном эксперименте, строится
математическая модель. Но исследуется эта модель исключительно посредством
аналитических выкладок, без привлечения какихлибо численных методов. Если
аналитических выкладок оказывается достаточно, то данный подход приводит к строгому
точному решению.
Однако на практике, как это ни парадоксально, аналитическому подходу обычно
отводится роль инструмента для (сравнительно быстрого) получения грубых оценок.
Объясняется это тем, что аналитическими выкладками удается ограничиться только для
несложных, сильно упрощенных моделей реальных процессов. Получаемое тут строгое
аналитическое решение на самом деле в силу исходного огрубления модели оказывается
весьма далеким от совершенства. Напротив, численные методы, применяемые в
вычислительном эксперименте, дают возможность изучать более сложные модели,
достаточно полно и точно отражающие исследуемые процессы.
Отмеченные достоинства вычислительного эксперимента вывели его в число основных
методов исследования таких крупных физических и инженернотехнических проблем, как
задачи ядерной энергетики, освоения космического пространства и др. Программные
комплексы, обслуживающие вычислительный эксперимент, объемны и сложны, в их
создание вовлечен многочисленный отряд программистов. Поэтому особую актуальность
приобретает изучение возникающих здесь конфигурационных построений, которые, как
будет видно из дальнейшего изложения, постоянно находятся в центре внимания
участников такого рода разработок.
4.1.2. Цикл вычислительного эксперимента. В цикле вычислительного эксперимента
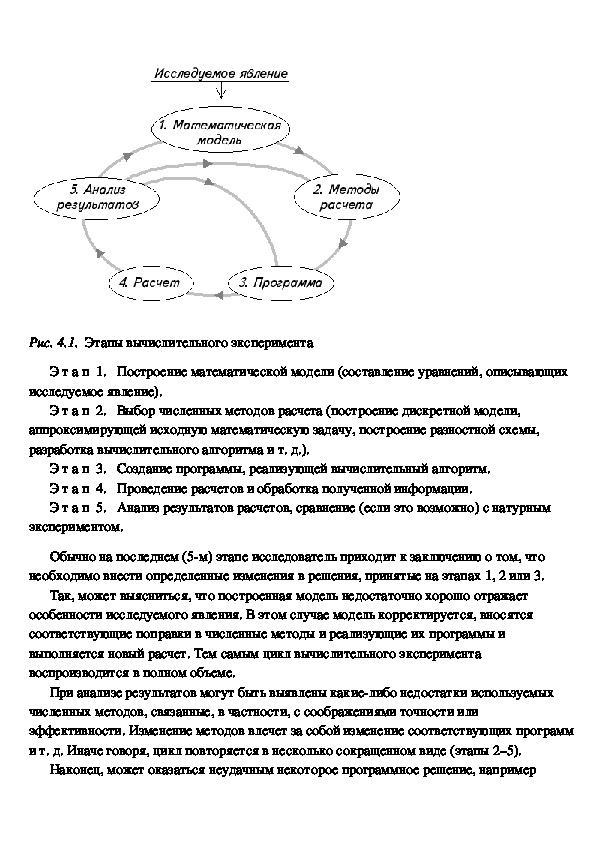
можно выделить следующие этапы (рис. 4.1).Рис. 4.1. Этапы вычислительного эксперимента
Э т а п 1. Построение математической модели (составление уравнений, описывающих
исследуемое явление).
Э т а п 2. Выбор численных методов расчета (построение дискретной модели,
аппроксимирующей исходную математическую задачу, построение разностной схемы,
разработка вычислительного алгоритма и т. д.).
Э т а п 3. Создание программы, реализующей вычислительный алгоритм.
Э т а п 4. Проведение расчетов и обработка полученной информации.
Э т а п 5. Анализ результатов расчетов, сравнение (если это возможно) с натурным
экспериментом.
Обычно на последнем (5м) этапе исследователь приходит к заключению о том, что
необходимо внести определенные изменения в решения, принятые на этапах 1, 2 или 3.
Так, может выясниться, что построенная модель недостаточно хорошо отражает
особенности исследуемого явления. В этом случае модель корректируется, вносятся
соответствующие поправки в численные методы и реализующие их программы и
выполняется новый расчет. Тем самым цикл вычислительного эксперимента
воспроизводится в полном объеме.
При анализе результатов могут быть выявлены какиелибо недостатки используемых
численных методов, связанные, в частности, с соображениями точности или
эффективности. Изменение методов влечет за собой изменение соответствующих программ
и т. д. Иначе говоря, цикл повторяется в несколько сокращенном виде (этапы 2–5).
Наконец, может оказаться неудачным некоторое программное решение, напримервыбранный способ работы с внешней памятью. Пересмотр таких решений приводит к
повторению этапов 3–5.
4.1.3. Особенности программирования. Разумеется, циклы, подобные циклу
вычислительного эксперимента, возникают практически в любом маломальски сложном
программном проекте. Самая первая версия программы обычно чемнибудь не
удовлетворяет разработчика или заказчика, и приходится уточнять постановку задачи,
улучшать отдельные алгоритмы и т. д. Однако в большинстве случаев достаточно бывает
выполнить несколько циклов, требующих сравнительно небольших усилий, и программа
обретает желаемый вид.
Совершенно иначе обстоит дело в вычислительном эксперименте. Здесь программа
мыслится как экспериментальная установка, от первых опытов с которой вряд ли следует
ожидать скольконибудь интересных результатов. Данные первых опытов послужат всего
навсего отправной точкой длительного процесса изменений и усовершенствований
установки, который только и способен привести к достаточно обоснованным заключениям
об исследуемом объекте.
Таким образом, появление первоначальной версии программы лишь в самых общих
чертах намечает направление исследований. Основная же работа по программированию
еще впереди — она связана с многократными модификациями программы, отражающими
эволюцию математической модели и методов ее расчета. Число циклов вычислительного
эксперимента, каждый из которых сопряжен с модификацией расчетной программы,
нередко достигает десятков тысяч. Поэтому рациональная организация таких
модификаций — ключ к эффективному программированию данного класса задач.
Продолжая параллель с натурным экспериментом, можно заметить, что там обычно не
спешат выбрасывать на свалку отдельные узлы, изъятые или замененные в
экспериментальной установке при проведении очередного опыта: они еще не раз могут
пригодиться впоследствии. Аналогично и решения (а вместе с ними и соответствующие им
фрагменты программ), пересматриваемые на очередном цикле вычислительного
эксперимента, как правило, не отбрасываются и могут использоваться затем для других
расчетов. Например, метод, оказавшийся непригодным для одной модели, вполне может
подойти для расчета следующей модели и т. д.
Итак, главное направление деятельности программиста, занятого вычислительным
экспериментом, — не создание новых, а развитие существующих программ. Это развитие
осуществляется, как правило, не за счет замены имеющихся модулей их более
совершенными версиями, а за счет расширения: включения в программный фонд все новых
и новых модулей, отражающих различные решения, принимаемые в ходе эксперимента.
Накапливаемые модули могут затем комбинироваться в самых разнообразных
сочетаниях, позволяя тем самым провести достаточно систематическое и глубокоеисследование. Потребность в подобных манипуляциях над модулями регулярно возникает
в связи с тем, что исследователь постоянно конструирует новые варианты модели,
сочетающие в себе те или иные выполнявшиеся когдалибо изменения или уточнения.
Таким образом, интересующая нас многовариантностьпрограмм вычислительного
эксперимента является закономерным следствием изначальной многовариантности модели.
Сложность реализуемых математических моделей, а также необходимость хранения
многочисленных вариантных модулей приводят к тому, что характерные размеры
программного фонда вычислительного эксперимента оказываются довольно
внушительными. Число участвующих в расчетах модулей здесь нередко достигает
нескольких тысяч, а суммарная длина текстов программ — сотен тысяч строк.
Организовать эффективное функционирование и развитие столь обширного, сложного и
специфичного программного хозяйства очень нелегко. Тем не менее жизнь показала, что
все возникающие здесь трудности вполне преодолимы — методом вычислительного
эксперимента были успешно решены многие важные практические задачи. История
программирования задач вычислительного эксперимента насчитывает свыше трех
десятилетий, и за это время накоплен весьма значительный опыт, позволяющий говорить о
существовании определенной технологииработы с многовариантными программами. Эта
технология оказалась достаточно надежной и эффективной; именно добротностью
применявшейся технологии объясняется жизнестойкость известных программных
реализаций вычислительного эксперимента.
В задачах вычислительного эксперимента в полной мере проявляются практически все
специфические особенности многовариантных программ. В то же время вычислительный
эксперимент является наиболее крупным потребителем технологии многовариантности.
Поэтому выражения «программирование задач вычислительного эксперимента» и
«создание многовариантных программ» иногда будут использоваться как синонимы.
4.2. Эксперимент с материалом
Для того чтобы начать изучение технологии многовариантности, потребуются кое
какие сведения из предшествующих глав. Освежить в памяти эти сведения поможет
небольшой пример.
4.2.1. Постановка задачи. Пусть с помощью вычислительного эксперимента
исследуется поведение некоторого устройства в зависимости от материала, из которого
оно изготовлено. И пусть решено на начальной стадии эксперимента в качестве материала
использовать сталь или медь, а затем исследовать другие материалы. Будем считать, что
применение того или иного материала приводит к определенным изменениям в
конструкции устройства и поэтому для исследования каждого нового материала требуетсяновый фрагмент моделирующего алгоритма.
Для облегчения эксплуатации и развития программного фонда здесь желательно, во
первых, упростить переключение расчетов с одного известного материала на другой и, во
вторых, минимизировать изменения существующих частей программы при появлении
нового материала и соответственно нового фрагмента алгоритма. Как в этом случае
следует сконструировать программу моделирования?
4.2.2. Традиционный подход. Приемы традиционного программирования, возможно,
приведут к следующему решению. Прежде всего нужно подумать о надлежащей
модуляризации. Необходимо добиться того, чтобы все части программы, зависящие от
специфики того или иного материала, были собраны в одном месте. Затем в этом месте
записывается (к примеру, на Паскале) оператор выбора следующего вида:
• • •
case материал of
сталь
:
моделирование_стал
и ;
медь : моделирование_меди
end { case }
• • •
Первая из поставленных целей тут достигнута. Переключение с одного материала на
другой происходит достаточно легко: присваивая с помощью исходных данных расчета
переменной материал значения сталь или медь, можно направлять алгоритм по той или
иной ветви. С точки же зрения второй цели — упрощения последующих изменений —
результат заключается лишь в том, что в программе неявно, но относительно четко
определено место для размещения новых фрагментов алгоритма, моделирующих поведение
новых материалов: такие фрагменты записываются в виде новых ветвей оператора выбора.
Рассмотренное решение можно упрекнуть за то, что в нем непроизводительно
расходуется оперативная память, поскольку в программу включаются все имеющиеся
ветви выбора, а фактически в любом расчете используется лишь одна из них. Однако такой
упрек довольно легко парировать: достаточно, например, превратить оператор выбора в
конструкцию периода компиляции.
Главный же технологический изъян применения в подобной ситуации конструкции
выбора несколько менее очевиден, но хорошо знаком нам по предыдущим главам. Он
заключается в нарушении выдвинутого нами требования безболезненности внесения
регулярных изменений. В самом деле, добавление новой ветви выбора означаетредактирование текста существующей программы, что, как известно, нередко приводит к
потере ее работоспособности.
4.2.3. Параллель с оформлением варианта. Разумеется, использование оператора
выбора — далеко не единственное решение, возможное в рамках традиционного
программирования. Некоторые другие подходы для смежной задачи оформления варианта
подробно разбирались в гл. 1. Там было показано, что любая схема, опирающаяся на
неприспособленную штатную операционную среду, страдает серьезными технологическими
недостатками. Выйти из положения удается только путем создания специализированных
системных средств оформления варианта.
Задачи оформления варианта и проведения эксперимента, действительно, во многом
схожи, и это позволяет, в частности, распространить на случай эксперимента основные
технологические заключения, сделанные ранее по отношению к оформлению варианта.
Имеются, однако, и определенные отличия.
Вопервых, проблемы, возникающие при программировании эксперимента с
материалами, в определенном смысле проще проблем оформления варианта. В постановке
задачи оформления варианта предполагалось, что потребность в образовании
альтернативного фрагмента алгоритма возникла неожиданно, свалившись как снег на
голову в то время, когда программа уже написана. В случае же эксперимента о
надвигающихся сложностях известно заранее, до начала непосредственного
программирования, и поэтому имеются все возможности для того, чтобы позаботиться о
надлежащем оформлении проектируемой программы.
Вовторых, в плане актуальности задача оформления варианта выглядит намного
скромнее. Ведь оформление варианта рассматривалось как разовая работа, потребность в
которой возникает сравнительно нечасто. Изза этого попытки применения здесь
специализированных системных средств коекем могли быть восприняты просто как
дорогостоящий каприз эстетов от программирования.
Напротив, обстоятельства программирования эксперимента в самом деле весьма
драматичны. Пополнение программного фонда фрагментами, моделирующими все новые и
новые исследуемые материалы, на долгое время становится основной работой
программистаэкспериментатора. Тут уже никому не приходит в голову экономить на
тщательной проработке технологии: внедряемые технологические усовершенствования
способны принести заметную пользу, поскольку применяться они будут многократно, на
каждом цикле эксперимента.
Более того, в реальном вычислительном эксперименте участвуют обычно десятки, а
нередко и сотни варьируемых факторов, подобных материалу в нашем примере. Любая,
даже незначительная технологическая несуразность будучи умножена на число таких
факторов может оказаться губительной для судьбы программы в целом. Поэтому тут ненужно никого агитировать, все разработчики в полной мере осознают целесообразность
создания специализированных системных средств, способных существенно обезопасить
постоянно идущий процесс пополнения программного фонда.
4.2.4. Специализированные средства. Вернемся к эксперименту с материалами. Как
можно улучшить рассмотренное решение, если не поскупиться на специализированные
системные средства?
Первый шаг — модуляризация — остается таким же, как и при традиционном
программировании. В проектируемой программе вычленяется часть, реализующая
изменяемый фактор — исследуемый материал. Однако оформляется эта часть не в виде
оператора выбора, а в виде вариантного гнезда (см. разд. 1.8, 3.6.2), в которое при сборке
расчетной программы будет подставлен тот или иной сменный модуль, моделирующий
поведение конкретного материала.
Два сменных модуля, моделирующие сталь и медь, реализуются и попадают в
программный фонд сразу. Затем в ходе эксперимента по мере необходимости
дописываются новые модулиматериалы. Их размещение в программном фонде
происходит безболезненно, не затрагивая ни текстов, ни работоспособности окружающих
модулей.
Можно было бы усмотреть преимущество оператора выбора в том, что его ветви
помещаются непосредственно в окружение объемлющей программы, а сменные модули
формируются как относительно самостоятельные объекты вне отведенного для них места
(вариантного гнезда). Но средства системной поддержки без труда обеспечат ввод и
просмотр текста сменного модуля в контексте окружения гнезда. Более того, в этом
случае сменный модуль визуально будет находиться ближе к окружению, так как между
ним и окружением не громоздятся соседние ветви оператора выбора.
В тексте объемлющей программы вариантное гнездо может быть представлено какой
либо специальной конструкцией, например предложением #VARIANT вида
• • •
#VARIANT МАТЕРИА
Л
• • •
(Символ «#» здесь и далее используется для указания того, что помеченная им
конструкция обрабатывается конфигурационным препроцессором.)
Предложение #VARIANT размещается там же, где при традиционном подходе
размещался бы оператор выбора. При сборке программы конфигурационный препроцессор
подставит на место гнезда соответствующий сменный модуль. Для указания требующегосясменного модуля в описание конкретной конфигурации собираемой программы
помещается назначение
МАТЕРИАЛ <– СТАЛЬ
где МАТЕРИАЛ — имя вариантного гнезда, указанное в предложении#VARIANT,
а СТАЛЬ — имя сменного модуля.
Конструкция назначения, помещаемая в описание конкретной конфигурации, ничуть не
сложнее программной конструкции, которая присваивает начальное значение переменной,
управляющей оператором выбора. Таким образом, переходя на специализированные
средства, мы по меньшей мере ничего не прогадываем и в отношении простоты
переключения с одного известного материала на другой.
4.3. Проект OLYMPUS
4.3.1. Каркасный подход к обеспечению многовариантности. В крупномасштабном
вычислительном эксперименте число изменяемых факторов, подобных материалу из
рассмотренного в предыдущем разделе примера, может оказаться довольно большим.
Каждому из таких факторов в программе соответствует вариантное гнездо. С появлением
нескольких вариантных гнезд постоянная часть расчетной программы превращается
вкаркас (см. разд. 3.6), заполняемый той или иной комбинацией сменных модулей в
зависимости от требующегося сочетания значений изменяемых факторов.
В этом случае создаваемый программный фонд, в свою очередь, превращается в пакет
программ, основанный на каркасном подходе. Многолетняя практика показала, что
такой пакет является весьма продуктивным конфигурационным ориентиром для
многовариантных задач, и в частности для задач вычислительного эксперимента.
4.3.2. Соглашения проекта OLYMPUS. Одной из первых крупных программных
разработок, уделивших серьезное внимание проблемам многовариантности и решивших эти
проблемы с помощью каркасного подхода, явился проект OLYMPUS [Робертс, 1974].
Авторам этого проекта удалось вычленить каркас, охватывающий широкий класс задач
математической физики.
Архитектура проекта OLYMPUS служит прекрасной иллюстрацией продуктивности
применения каркасного подхода к задачам вычислительного эксперимента (см. разд. 4.1).
Соглашениями проекта для каждого из выделенных вариантных гнезд каркаса определены
его функциональное предназначение и интерфейс с окружением; гнездам присвоены имена.
Для любого из гнезд пишется, вообще говоря, несколько различных сменных модулей, из
которых в любом конкретном расчете будет участвовать лишь один.
В результате очередной цикл вычислительного эксперимента сводится, с точки зренияпрограммной реализации, к назначению другого сменного модуля (модулей), который
вытесняет из вариантного гнезда (гнезд) своего предшественника, назначенного на
предыдущем цикле. Если принятое на данном цикле решение реализуется впервые,
сменный модуль пишется заново и помещается (безболезненно!) в программный фонд. Если
же требуется применить уже принимавшееся ранее решение, то можно воспользоваться
модулем, написанным для него в свое время и предусмотрительно сохраненным в
программном фонде.
4.3.3. Обмен программными материалами. Однако простота переключения с
варианта на вариант и безболезненность развития программного фонда были не
единственным, а возможно, и не самым важным результатом разработки соглашений
проекта OLYMPUS. Эти соглашения позволили также сделать серьезный шаг в
направлениимногократного использования (см. разд. 2.4.3) программных материалов.
Чем обычно обменивались программисты до появления проекта OLYMPUS? Наиболее
характерным объектом обмена был законченный программный продукт, например
выполняемая программа, обслуживающая конкретную практическую задачу или класс
задач. Часто передавались библиотеки, составленные из подпрограмм, решающих типовые
алгоритмические подзадачи и имеющих относительно широкую сферу применимости.
Соглашения OLYMPUS открыли совершенно новую возможность: они позволили
обмениваться узко специализированными фрагментами программ, конечно, при условии,
что и производитель, и потребитель используют один и тот же каркас. Так, например,
объектом обмена стали служить сменные модули, обеспечивающие ввод и
предварительную обработку исходных данных, расчет уравнения энергии, и вообще
реализующие любую часть алгоритма, предусмотренную вариантными гнездами каркаса.
Разумеется, для обеспечения подобного обмена прилагаются и дополнительные усилия.
Все программы, работающие в системе соглашений OLYMPUS, пишутся на диалекте
Фортрана, воспринимаемом большинством существующих трансляторов. Кроме того,
немобильные части программ, зависящие от особенностей конкретной операционной среды,
фиксированным образом выделяются и документируются. Но все же главная опора
интенсивного обмена программными материалами — применение всеми участниками
единого каркаса расчетной программы.
4.3.4. Опыт применения. Проект OLYMPUS получил широкое международное
признание. Журнал Computer Physics Communication регулярно публиковал алгоритмы,
разработанные в рамках этого проекта, которые использовались многими организациями не
только за рубежом, но и в нашей стране.
Для того чтобы в полной мере почувствовать преимущества соглашений OLYMPUS,
требуются развитые средства системной поддержки. Однако авторы проекта применилидля сборки конкретных конфигураций программы имевшийся в их распоряжении
общецелевой текстовый процессор, способный выполнять множество разнообразных
преобразований текста, но не самым удачным образом решавший специфические задачи
сборки. В результате размер задания на сборку неоправданно увеличивался, нередко
достигая нескольких сотен строк.
В то же время имеется опыт реализации специализированных средств поддержки
многовариантных программ [ГорбуновПосадов, 1983]. Благодаря таким средствам
удается, в частности, достичь высоких показателей надежности и эффективности при
эксплуатации программ, созданных в рамках соглашений OLYMPUS.
Теперь, убедившись на примере проекта OLYMPUS в продуктивности каркасного
подхода к построению многовариантных программ, перейдем к более детальному изучению
технологических особенностей этого подхода.
4.4. Однофакторность гнезд
Одним из наиболее существенных технологических свойств проектируемого
вариантного гнезда каркаса многовариантной программы является число изменяющихся
факторов, влияющих на содержимое гнезда. Весьма нежелательно
появление многофакторных гнезд, которые, в отличие от однофакторных, вызывают
серьезные технологические затруднения.
Однофакторность, как и многие другие свойства гнезда, закладывается на самой ранней
фазе работ по обеспечению многовариантности — на фазе модуляризации, или, точнее, на
фазе проектирования каркаса.
4.4.1. Проектирование каркаса. Доминирующим побудительным мотивом
модуляризации многовариантных программ являетсяизменяемость (см. разд. 2.4.4).
Каждый цикл вычислительного эксперимента включает в себя модификацию расчетной
программы, такие модификации поглощают львиную долю времени программиста
экспериментатора, и поэтому основные усилия при модуляризации должны быть
направлены на упрощение процесса выполнения изменений.
Прежде всего необходимо попытаться предвосхитить как можно больше вероятных
направлений модификации расчетной программы, т. е. выявить изменяемые в ходе
эксперимента факторы. Такими факторами могут оказаться, например: те или иные
конструкторские решения, принимаемые при моделировании установки; различные
способы отражения элементов установки в математической модели; методы, используемые
при расчете; геометрия (прямоугольная, сферическая), в которой выполняется расчет;
точность вычислений; организация работы с таблицами и внешней памятью и т. д.
Каждому выявленному изменяемому фактору желательно сопоставить точку роста —вариантное гнездо проектируемого каркаса расчетной программы. Хорошо, когда все
вариантные гнезда оформляются еще на стадии проектирования. Если же сразу
сформировать постоянный каркас не удалось и некоторый полезный изменяемый фактор
предложен только в ходе эксперимента, когда многие программы уже написаны, то для
создания соответствующего нового гнезда каркаса можно воспользоваться техникой
оформления варианта, подробно разобранной в гл. 1.
Каркас позволяет упростить и обезопасить основные технологические моменты
вычислительного эксперимента: переключение с одного реализованного значения
изменяемого фактора на другое осуществляется путем переназначения сменного модуля, а
появление нового значения изменяемого фактора реализуется как безболезненное
расширение набора сменных модулей. Проектирование такого каркаса — весьма непростая
задача, требующая творческого подхода. Некоторые ее аспекты уже рассматривались нами
в гл. 2 при изучении проблемы более общей — модуляризации программного фонда.
Каркасы многовариантных программ могут иметь самые разнообразные формы. Лучше,
если выделяемые гнезда каркаса будутодносвязными (см. разд. 3.6.2), но не надо
пренебрегать и многосвязнымигнездами — нередко они оказываются ничуть не менее
наглядными и технологичными.
4.4.2. Причины многофакторности гнезд. Главная опасность, подстерегающая
разработчика при проектировании каркаса, — появление многофакторных гнезд, т. е.
гнезд, содержимое которых зависит от нескольких изменяемых в ходе эксперимента
факторов. Можно указать следующие два источника многофакторности.
Вопервых, с существованием многофакторных гнезд иногда мирятся изза
соображений эффективности. Действительно, изредка удается добиться некоторого
увеличения скорости выполнения расчетной программы, тесно переплетая части
алгоритма, зависящие от различных факторов. Однако получаемый таким образом
выигрыш в эффективности обычно настолько мал, что он никак не окупает усилий,
затрачиваемых затем на борьбу с последствиями рыхлой структуры многовариантной
программы.
Вовторых, причиной появления многофакторных гнезд может послужить наличие
какойлибо зависимости между некоторыми из выделенных изменяющихся факторов. В
этом случае два или более связанных значений зависимых факторов будут образовывать
устойчивые сочетания, каждому из которых, повидимому, надо сопоставить сменный
модуль одного совокупного многофакторного гнезда.
Для того чтобы избавиться от многофакторных гнезд, отражающих устойчивые
сочетания значений, приходится анализировать и корректировать понятийный базис
решаемой задачи, добиваясь первичности и независимости выделяемых изменяющихсяфакторов и обеспечивая тем самым базисность и ортогональность (см. разд. 2.4.4)
реализующих эти факторы модулей. Подобный анализ задачи, помимо очевидной
технологической пользы, часто оказывается весьма плодотворным, позволяя выявить
глубинные свойства исследуемой проблемы.
4.4.3. Технологические трудности. Указанные выше объективные причины
многофакторности на практике встречаются нечасто. В подавляющем большинстве случаев
многофакторные гнезда возникают просто вследствие грубых ошибок проектирования, и
при известном навыке изгнание их из каркаса не составляет особого труда. Если все же
избежать появления таких гнезд не удалось, то разработчик сталкивается с множеством
технологических трудностей.
Прежде всего, программирование для многофакторных гнезд сопряжено с излишними
трудозатратами. Поясним это простыми арифметическими выкладками. Пусть некоторое
вариантное гнездо заполняется сменными модулями, зависящими от двух изменяющихся
факторов, каждый из которых в ходе вычислительного эксперимента принимает 10
различных значений. Тогда для реализации всех возможных комбинаций этих факторов
потребуется 10 x 10 = 100 сменных модулей. В то же время, если бы удалось расчленить
эти факторы, заведя для каждого отдельное гнездо, то потребовалось бы всего 10 + 10 = 20
сменных модулей. При этом размер однофакторного модуля будет, грубо говоря, вдвое
меньше размера двухфакторного, поскольку задачи, решаемые двухфакторным модулем,
поделятся между двумя однофакторными. Таким образом, однофакторная схема
оказывается здесь в десять раз экономичнее, чем двухфакторная!
Однако дело даже не в количестве и не в размерах модулей, хотя и они достаточно
убедительно свидетельствуют в пользу однофакторных гнезд. Беда в том, что
многофакторный модуль имеет размытую структуру. Изучая его текст, трудно распознать,
где начинаются и заканчиваются фрагменты, реализующие отдельные охватываемые им
факторы.
Кроме того, использование многофакторных модулей неизбежно ведет к дублированию
текстов, негативные последствия которого подробно разбирались в разд. 1.3. Ведь
различные значения изменяемых факторов комбинируются в эксперименте в самых
разнообразных сочетаниях, в результате чего регулярно появляются модули с
совпадающими значениями некоторых факторов. При единообразной реализации тексты
таких модулей будут содержать сходные фрагменты. Но это сходство, а нередко и
идентичность текстов никак не будут проявлены, что, разумеется, технологически
неприемлемо.
Многофакторные гнезда сильно проигрывают однофакторным в отношении простоты и
наглядности описания конкретной конфигурации программы. Сменный модуль для
однофакторного гнезда имеет лишь один сборочный атрибут — значение фактора.Назначение модуля на роль заполнителя гнезда в собираемой расчетной программе
производится посредством довольно простой конструкции
имя_гнезда <– имя_сменного_модуля
(1)
Если же назвать гнездо именем изменяющегося фактора, а модуль — именем значения
фактора, то конструкция примет весьма удобочитаемыйнепроцедурный (см. разд. 3.6.1)
вид
фактор <– значение_фактора
(2)
Ничего подобного сделать с многофакторным гнездом не удается. Можно, конечно,
задать значения всех факторов, охватываемых гнездом, посредством конструкций вида (2),
а затем поручить средствам системной поддержки отыскать соответствующий сменный
модуль. С точки зрения непроцедурности все будет в порядке, чего нельзя, к сожалению,
сказать о наглядности и компактности.
Фрагмент описания конкретной конфигурации, определяющий посредством группы
значений факторов содержимое многофакторного гнезда, внешне весьма далек от таких
стоящих за ним программных объектов, как вариантное гнездо и подставляемый в него
сменный модуль. Иначе говоря, тут теряется наглядность построения программы,
свойственная однофакторным гнездам благодаря интерпретации (1) элемента описания.
Кроме того, использование целой группы значений в качестве сборочного атрибута
сменного модуля выглядит существенно тяжеловеснее, чем единственное значение для
однофакторного случая.
4.4.4. Атрибуты модуля в описании конфигурации. Даже когда удалось добиться
однофакторности всех гнезд спроектированного каркаса, нельзя расслабиться, полагая, что
все опасности уже позади. Время от времени разработчику начинает казаться, что
имеющиеся в его распоряжении формы задания конкретной конфигурации собираемой
программы слишком бедны. Появляется желание в некоторых случаях при назначении
сменного модуля, заполняющего гнездо, указывать не имя этого модуля и не значение
изменяющегося фактора (как предписывают правые части выражений (1) или (2) ), а
некоторые другие атрибуты требующегося модуля.
Атрибутов у каждого модуля довольно много: дата создания, дата последнего
редактирования, автор, язык программирования (транслятор) и др. Наличие большого
набора атрибутов существенно облегчает ведение программного хозяйства, позволяя
рассматривать имеющийся программный фонд под разными углами зрения.
Однако использование подобных атрибутов в описании конкретной конфигурации
многовариантной программы вызывает решительные возражения, хотя на первый взглядпредставляется вполне невинной затеей. Не всегда удается сразу разглядеть
надвигающуюся многофакторность гнезд, сталкиваясь с вопросами, подобными
следующему: «почему, собственно, нельзя сначала построить одну конкретную
конфигурацию, выбирая из программного фонда наилучшие с точки зрения времени
выполнения сменные модули, а затем, опираясь на тот же каркас и тот же программный
фонд, построить другую конкретную конфигурацию, исходя из совершенно иных
побуждений, например, отдавая предпочтение сменным модулям, запрограммированным,
скажем, Ивановым?»
Данному вопросу можно, вообще говоря, придать совершенно корректную
однофакторную интерпретацию. В программе могут быть выделены (и оформлены в виде
многосвязного вариантного гнезда) части, в наибольшей степени влияющие на скорость
выполнения. Затем программируются два многосвязных модуля: БЫСТРЫЙ, который
записывается на ассемблере, и более медленный, но МОБИЛЬНЫЙ, записываемый на
языке высокого уровня.
Кроме того, могут сосуществовать, скажем, две методики вычислений, одна из которых
предложена и реализована Ивановым, а другая — Петровым. В каркасе заводится
вариантное гнездо МЕТОДИКА, а творения Иванова и Петрова превращаются в сменные
модули с соответствующими именами (хотя для идентификации методик лучше
использовать не фамилии разработчиков, а функциональные характеристики, по которым
они отличаются).
Тогда чтобы получить быструю версию выполняемой программы, в описании
конкретной конфигурации достаточно указать многосвязный модуль БЫСТРЫЙ,
задающий включение в формируемую программу ассемблерных компонентов. Все
остальные реализации вариантных гнезд, в том числе и методика вычислений, выбираются
по умолчанию.
Для расчетов по методике Иванова задается только назначение
МЕТОДИКА <– ИВАНОВ
в результате чего гнездо МЕТОДИКА заполняется модулем с именемИВАНОВ, а по
умолчанию выбирается БЫСТРЫЙ или МОБИЛЬНЫЙмодуль.
Но в сформулированном выше вопросе обычно подразумевается несколько иное
построение программы, по существу противоречащее однофакторности гнезд каркаса.
Предполагается, что все атрибуты модуля программного фонда равноправны в том смысле,
что каждый из них наравне с основным сборочным атрибутом (т. е. значением
изменяющегося фактора) может, вообще говоря, фигурировать в описании конкретной
конфигурации.
Например, для одного и того же гнезда каркаса Сидоров мог написать на ассемблеремодуль, имеющий атрибуты (БЫСТРЫЙ, СИДОРОВ), а Иванов — на Фортране модуль с
атрибутами (МОБИЛЬНЫЙ, ИВАНОВ). Тогда в первую запрошенную конкретную
конфигурацию программы будет включен первый из модулей изза наличия у него
атрибутаБЫСТРЫЙ, а во вторую — второй изза атрибута ИВАНОВ.
Закономерно возникает вопрос: а каково же всетаки предназначение заполняемого
этими модулями вариантного гнезда? Неясно, служит ли оно для разрешения противоречия
«быстрый — мобильный» или же для того, чтобы дать возможность проявиться творческой
индивидуальности Иванова и Сидорова. Такое построение размывает функциональную
структуру программы, чрезвычайно затрудняя ее изучение и последующее развитие.
Единственный вид дополнительных атрибутов, включение которых в описание
конкретной конфигурации иногда действительно может быть в какойто мере оправдано,
связан с отражением выполняемых время от времени реорганизаций текста модуля или
программы, т. е. с такими понятиями, как «поколение» или «поставка». Об этих понятиях
речь пойдет далее, в разд. 4.12.
4.5. Имена гнезд и модулей
Как уже упоминалось, в производственных многовариантных программах, решающих
задачи вычислительного эксперимента, обычно содержится от нескольких десятков до
нескольких сотен вариантных гнезд. Для задания конкретной конфигурации программы
необходимо, вообще говоря, каждому вариантному гнезду назначить размещаемый в нем
сменный модуль. В простейших случаях такое назначение выполняется посредством
множества предложений вида (1) или (2), рассмотренных в предыдущем разделе. Однако
нередко оказываются полезными и другие языковые конструкции.
При проектировании средств описания конкретных конфигураций многовариантной
программы необходимо прежде всего выработать соглашения об именах гнезд и сменных
модулей. Отдельные соглашения такого рода уже рассматривались ранее, но в более узком
контексте: применительно к оформлению одиночного варианта (разд. 1.8.4) и к
компонентам многосвязных гнезд и модулей (разд. 3.6.2). Большинство приведенных там
соображений применимо к случаю многовариантных программ, однако здесь имеются и
некоторые особенности.
Разработчик многовариантной программы практически не может позволить себе не
именовать гнезда или сменные модули, как это допускалось в случае оформления
единичного варианта. Ведь если имен нет, то при задании конкретной конфигурации
многовариантной программы придется многократно спускаться на уровень исходного
текста, вспоминая предназначение очередного гнезда, и подыскивать для гнезда сменный
модуль, опятьтаки перебирая исходные тексты модулей. В то время как для одногодвух
вариантных гнезд с двумятремя сменными модулями подобная схема иногда оказываетсяудобной, для многовариантных программ, где счет и гнездам, и сменным модулям идет на
десятки и сотни, она становится неприемлемо трудоемкой.
Строго говоря, для того чтобы избавиться от обращений к уровню исходного текста,
гнезда именовать не обязательно — достаточно присвоить имена только сменным модулям.
Поскольку каждый сменный модуль всегда приписан к некоторому гнезду, можно
полностью описать конкретную конфигурацию, указывая только имена модулей вместо
назначений «гнездо <– модуль». Однако схема с именованными гнездами и назначениями
«гнездо <– модуль» представляется более удобной и наглядной. Кроме того, при наличии
именованных гнезд не требуется уникальности имен сменных модулей по отношению ко
всему архиву программных материалов (см. разд. 1.8.4), что также нередко оказывается
немаловажным.
Разумеется, широкое использование имен отнюдь не означает, что разработчик,
составляющий описание конкретной конфигурации многовариантной программы, должен
быть принудительно отгорожен от исходных текстов. Напротив, создавая
специализированные средства поддержки процесса задания конкретной конфигурации,
желательно предусмотреть возможность просмотра (а иногда и редактирования)
сопутствующих фрагментов исходного текста: и окрестностей местоположения очередного
заполняемого гнезда, и текстов сменных модулей, предназначенных для подстановки в
данное гнездо, и даже результата подстановки модуля в гнездо. Но к обращениям на
уровень исходных текстов прибегают все же относительно редко — задание содержимого
основной массы вариантных гнезд производится обычно на уровне имен.
Имена вариантных гнезд записываются прямо в исходном тексте содержащих их
программ, например, с помощью предложений #VARIANTвида
• • •
#VARIANT имя_гнезд
а
• • •
Если требуется разместить вариантное гнездо внутри строки, то для того, чтобы
конструкция не слилась с окружающим текстом, можноимя_гнезда заключить в скобки:
. . . #VARIANT ( имя_гнезда ) . . .
Для односвязных компонентов многосвязного гнезда также можно воспользоваться
предложениями #VARIANT, задавая в них составные имена:
#VARIANT имя_многосвязного_гнезда . имя_компонентаСходным образом именуются и компоненты сменных многосвязных модулей (см.
разд. 3.6.2):
имя_многосвязного_модуля . имя_компонента
Такой способ именования многосвязных гнезд и модулей позволяет при задании
конкретной конфигурации применять не только для односвязного, но и для многосвязного
случая уже не раз встречавшуюся конструкцию назначения
имя_гнезда <– имя_сменного_модуля
4.6. Задание конфигурации, подчиненное сборке
Каким образом задается совокупность назначений сменных модулей, определяющая
формируемую конкретную конфигурацию многовариантной программы? Конечно, можно
явно выписать одно за другим все требующиеся назначения. Тем самым задача будет
решена, однако решение это весьма нетехнологично. Вновь напомним, что в реальных
программах число вариантных гнезд часто достигает нескольких десятков, а то и сотен.
Работа по заданию содержимого столь внушительного количества гнезд безусловно
заслуживает системной поддержки.
Но прежде чем перейти к последовательному изучению средств поддержки задания
конкретных конфигураций многовариантной программы, рассмотрим одну простую схему,
в известной мере облегчающую отдельные этапы такого задания. Разобравшись в довольно
очевидных слабостях этой схемы, легче будет двигаться дальше, к более совершенным
решениям.
В основе схемы лежит наблюдение о том, что потребителем описания конкретной
конфигурации является в конечном итоге алгоритм сборки выполняемой программы.
Предлагается решительно сократить дистанцию между заданием конфигурации и
выполнением алгоритма сборки, подчинив этому алгоритму диалог с задающим
конфигурацию пользователем.
Можно считать, что сборка текста конкретной конфигурации многовариантной
программы выполняется следующим образом. Алгоритм сборки просматривает
предложение за предложением текст некоторого программного модуля. Основная масса
предложений механически переносится в формируемую программу. Однако, встретив
среди просматриваемых предложений вариантное гнездо, алгоритм должен вставить на его
место сменный модуль, назначенный данному гнезду. Для этого необходимо прежде всего
выяснить имя вставляемого сменного модуля.
Вот в этот момент и включается диалог с пользователем. На экран выводится имя
заполняемого вариантного гнезда и, возможно, список имен созданных для данного гнездасменных модулей. Пользователю предлагается так или иначе указать сменный модуль,
который, по его мнению, должен занять предъявленное вариантное гнездо.
Узнав от пользователя имя сменного модуля, алгоритм сборки продолжает работу,
добирается до очередного вариантного гнезда, запрашивает для него сменный модуль и
т. д. Таким образом в ходе сборки текста выясняются все необходимые сведения о
требуемой конкретной конфигурации.
Практически единственное, хотя и немаловажное достоинство рассмотренной схемы
задания конфигурации — простота реализации. Но этому достоинству, к сожалению,
противостоит внушительное множество недостатков.
Пользователю навязывается определенная последовательность задания конфигурации.
С навязываемой последовательностью можно было бы скрепя сердце смириться, если бы ее
проектировал разработчик программы, стремящийся к тематической близости вводимых
друг за другом значений. Но здесь пользователь вынужден заполнять вариантные гнезда в
хаотическом (с точки зрения их функционального назначения) порядке, определяемом не
разработчиком, а особенностями алгоритма сборки.
Значительные сложности вызывает откат, реализация которого лишила бы данную
схему ее главного преимущества — простоты. Дело в том, что после ввода, скажем, десяти
имен сменных модулей пользователь может захотеть изменить пятое имя, оставив в силе
остальные девять. Такие манипуляции очень непросто вписать в рассматриваемый
механизм диалога.
Список недостатков схемы можно продолжать довольно долго. Мы ограничимся
упоминанием лишь еще одного, наиболее серьезного из них: с точки зрения пользователя
чрезвычайно неудобно неявно подразумеваемое здесь выделение задания конкретной
конфигурации в самостоятельный, изолированный этап подготовки выполнения
программы. Как будет видно из последующего изложения, особенно неприятен совершенно
неестественный разрыв между заданием конфигурации и вводом исходных данных.
Теперь, приобретя некоторый (пока в основном негативный) опыт в области
строительства схем задания конкретных конфигураций, перейдем к более
систематическому изучению этой области. Сначала рассмотрим, за счет чего удается
уменьшить размеры описания конфигурации.
4.7. Модуль типа направление
Если для каждого вариантного гнезда явно указывать его содержимое, то для описания
конкретной конфигурации многовариантной программы потребуется задать несколько
десятков, а то и сотен назначений сменных модулей. Число явных назначений можно
несколько сократить, введя механизм умолчания для заполнения не упомянутых вописании гнезд. Например, можно полагать, что по умолчанию в вариантное гнездо
подставляется сменный модуль, имя которого совпадает с именем вариантного гнезда.
Дальнейшего сокращения размеров описания конфигурации можно достичь, заметив,
что значительная часть назначений довольно консервативна. На каждом очередном цикле
вычислительного эксперимента обычно меняется содержимое одногодвух гнезд, а
остальные сменные модули остаются на своих местах. Если же проанализировать
конкретные конфигурации программы, использовавшиеся в нескольких десятках
следовавших друг за другом циклов, то скорее всего окажется, что и в этих конфигурациях
большая часть назначений сменных модулей оставалась неизменной.
4.7.1. Технология направлений. Закономерно возникает желание, оперевшись на эти
наблюдения, вычленить консервативную группу назначений и оформить ее в виде
самостоятельного первичного объекта программного фонда, который мы будем называть
модулем типанаправление. Располагая таким модулем, в описании очередной конкретной
конфигурации достаточно будет сослаться на него, после чего потребуется лишь задать
ряд недостающих назначений для гнезд, не упомянутых в этом модуле.
Почему для обозначения типа модуля выбран термин «направление»? Дело в том, что в
ходе вычислительного эксперимента, как правило, формируется несколько относительно
независимых направлений проводимого исследования. Каждое из направлений
характеризуется определенной совокупностью принятых решений. Принятое решение
отражается в программе как фиксация содержимого вариантного гнезда. Совокупности
решений, характеризующей направление исследования, в программном фонде будет
соответствовать модуль типа направление, а нескольким направлениям исследования —
несколько таких модулей.
Каркасный подход обеспечивает практически полную независимость работ,
выполняемых на различных направлениях. Все направления опираются на общий каркас
многовариантной программы и, кроме того, возможно, совместно используют некоторые
сменные модули. Деятельность по развитию программы в рамках каждого из направлений,
как правило, заключается только в подключении к программному фонду новых сменных
модулей и в построении конкретных конфигураций с участием новых модулей. Такие
действия выполняются безболезненно для работоспособности, т. е. никак не могут
повредить работам, ведущимся на соседних направлениях.
Тут нередки ситуации, совершенно невероятные при других подходах. Например, в
Институте прикладной математики им. М.В.Келдыша РАН в течение полугода на базе
единого программного фонда каркасного пакета Сафра [ГорбуновПосадов, 1983]
выполнялись ответственные производственные расчеты и в то же время отлаживали свои
(разумеется, изобилующие разнообразнейшими ошибками) программы студентычетверокурсники. И хотя оба направления работ сопровождались многочисленными
модификациями программного фонда (включавшего несколько десятков тысяч строк
исходного текста), никаких коллизий между ними так ни разу и не возникло.
Благодаря чему оказалось возможным мирное сосуществование, казалось бы,
несочетаемых групп разработчиков? Вопервых, все совместно использовавшиеся
материалы фонда прошли перед этим многолетнюю проверку практикой и потому ни разу
не потребовали какойлибо доработки. Вовторых, подключение вновь создаваемых
материалов происходило безболезненно, никак не затрагивая разделяемые части программ.
Таким образом, деятельность каждой из групп ничем не угрожала работоспособности
конкретных конфигураций программ, собираемых ее соседями, хотя их программы
произрастали из общего корня и имели множество точек соприкосновения.
4.7.2. Происхождение направлений. Интуитивно причины сосуществования различных
направлений исследования сложной проблемы достаточно очевидны. Можно, однако,
попытаться пояснить их и с позиций математики. Для этого сначала придется обратиться к
некоторым особенностям задач вычислительного эксперимента, и в частности задач
проектирования новых изделий.
Процесс вычислительного эксперимента в глазах математика прежде всего
ассоциируется с решением некоторой оптимизационной задачи. В качестве варьируемых
параметров здесь выступают изменяемые факторы. Что же касается понятия
оптимальности того или иного решения, то дать скольколибо формальное его определение
для достаточно сложного проектируемого изделия обычно не удается.
Поэтому здесь не работают широко распространенные математические методы
оптимизации, требующие, чтобы оптимизируемая функция была единственной и строго
заданной. Несколько лучше отражают специфику рассматриваемой задачи методы
многокритериальной оптимизации[Соболь, 1981], однако обычно и они оказываются
непригодными в силу слишком большого числа варьируемых факторов, а также изза
дискретности и неупорядоченности значений этих факторов.
Более того, границы пространства поиска окончательно определяются только в ходе
вычислительного эксперимента. Для ранних стадий эксперимента весьма характерна
ситуация, когда не только не реализована значительная часть исследуемых значений
изменяемых факторов (т. е. не написана часть сменных модулей), но даже и мысль о самой
возможности исследования некоторых новых значений просто еще не приходила в голову
разработчику.
Таким образом, можно заключить, что вычислительный эксперимент — плохо
формализуемый процесс, требующий от участников постоянных творческих усилий. С
точки зрения математика, этот процесс представляет собой целенаправленное движение в
пространстве изменяемых факторов, позволяющее постепенно приближаться к искомомуоптимуму. Поскольку толкование оптимальности здесь весьма нетривиально, следует
ожидать, что в ходе вычислительного эксперимента будет обнаружено несколько
представляющих интерес окрестностей локальных оптимумов. Одновременное изучение
таких окрестностей можно интерпретировать как несколько сосуществующих направлений
исследования. С точки же зрения программной реализации, каждой изучаемой окрестности
сопоставляется модуль типа направление.
4.8. Среда подготовки расчета
4.8.1. Совмещение описания конфигурации и данных. После знакомства с
приведенными в предыдущем разделе околоматематическими рассуждениями о
содержании понятия «направление исследования» у читателя, вероятно, возникло
определенное недоумение: почему при рассмотрении оптимизационной задачи речь идет
только о параметрах, реализуемых в виде вариантных фрагментов алгоритма? Неужели в
вычислительном эксперименте среди значений варьируемых параметров никогда не
встречаются привычные всем числа, массивы и другие подобные им данные?
Конечно же, изменяющиеся факторы с числовыми значениями имеют ничуть не меньше
прав на существование, чем факторы, отображаемые в сменных программных модулях.
Более того, в реальных расчетах количество таких числовых факторов обычно в несколько
раз превосходит количество вариантных гнезд каркаса.
Тем не менее на страницах книги манипуляциям над данными отведено относительно
скромное место. В явном виде данные всплывают лишь в тех редких случаях (подобных
рассматриваемому в настоящем разделе), когда они непосредственно соприкасаются с
конфигурационными построениями. Недостаток внимания к числовым факторам
объясняется, разумеется, только относительно узкой тематической направленностью
книги, а отнюдь не желанием както противопоставить данные программам.
В то же время многие конструкции, описанные в предыдущих главах, не делают
различия между программами и данными. Программы и данные тут практически
сливаются, образуя единое пространство. В частности, обычно предполагается, что и
программные материалы, и исходные данные, и результаты расчетов хранятся в едином
программном фонде с общим механизмом просмотра и модификации информации.
Единое пространство программ и данных желательно сформировать и при подготовке
расчета. Граница, нередко разделяющая два компонента такой подготовки — описание
конкретной конфигурации и вводимые исходные данные, — весьма условна и связана
скорее не с существом решаемых задач, а с особенностями их программной реализации.
Существо же задачи, напротив, диктует необходимость организации единой среды
подготовки расчета, где процессы задания и конфигурации, и данных идут рука об руку, не
спотыкаясь постоянно об искусственно проведенную между ними границу. Ведь прианализе хода эксперимента и при выборе перспективных направлений исследования
предпочтительнее отвлечься от таких технических подробностей, как алгоритмическое или
числовое воплощение очередного изменяемого фактора. (Вообще говоря, обычно имеет
смысл погрузить в единую среду не только подготовку расчета, но и изучение его
результатов. Однако эта сторона дела существенно дальше отстоит от интересующих нас
конфигурационных проблем, и поэтому она не будет затрагиваться.)
Изложенные соображения в пользу единства среды подготовки расчета практически
полностью применимы и к введенным в предыдущем разделе модулям типа направление.
Эти модули наряду со сведениями о содержимом консервативной части вариантных гнезд
должны включать в себя и некоторую консервативную часть вводимых числовых данных.
Такое расширенное толкование содержания модулей существенно ближе к понятию
«направление исследования».
Другими словами, изучаемая окрестность локального оптимума характеризуется в
равной мере как алгоритмическими, так и числовыми вариантными параметрами.
Использование модуля, содержащего лишь искусственно выделенную алгоритмическую
(конфигурационную) часть этих параметров, повлекло бы за собой неоправданные
технологические неудобства.
4.8.2. Техника ввода данных. Итак, ввод описания конкретной конфигурации должен
осуществляться совместно с вводом данных в единой среде подготовки расчета. Ввод
данных имеет определенные традиции, ломать которые даже изза потребностей единства
среды было бы весьма нежелательно. Поэтому, прежде чем приступать к проектированию
средств задания конфигурации (чему будет посвящен следующий раздел), имеет смысл
окинуть взглядом некоторые характерные особенности организации ввода данных.
Современные представления о среде подготовки расчета базируются на
технике гипертекста, упоминавшейся в разд. 2.3.3. Материалы среды расчленяется на
связанные гиперссылками страницы (панели), которые в данном случае отражают
отдельные вовлеченные в расчет понятия.
На страницах располагаются гнезда ввода, позволяющие задавать как элементы
описания конкретной конфигурации программы, так и исходные данные для расчета.
Например, участок страницы, отведенный для ввода значения скорости, мог бы иметь вид:
где рамкой обведено гнездо ввода, содержащее сначала значение скорости по умолчанию.
Перемещаясь по страницам с помощью гиперссылок и заполняя встречающиеся гнезда
ввода необходимыми значениями, можно задать всю необходимую для расчета
информацию.Иногда (в особенности на заключительной стадии подготовки расчета) может оказаться
неудобным вручную разыскивать еще не заполненные гнезда ввода. В таком случае
пользуются функциональной клавишейСледующий ввод, которая делает текущим
очередное незаполненное гнездо, после чего можно сразу приступать к вводу в него
значения. Последовательность перебора гнезд ввода, определяемая клавишейСледующий
ввод, задается разработчиком среды подготовки расчета; обычно разработчик стремится
отразить в ней рекомендуемый рациональный порядок ввода исходных данных.
4.8.3. Вновь о близости программ и данных. Если в расчетной программе
выполняется ввод массива или другого крупного агрегата данных, то нередко требуется не
вводить каждый раз все элементы заново, а накопить несколько сменных наборов значений
элементов и затем от расчета к расчету только переключать ввод с одного набора на
другой. Подготовка и использование таких сменных наборов выглядят практически так же,
как и работа со сменными программными модулями в многовариантной программе.
Наборы значений элементов оформляются как самостоятельные объекты программного
фонда. И массиву, и отдельным наборам присваиваются имена, после чего при подготовке
расчета назначение конкретного сменного набора для массива выполняется подобно
назначению сменного модуля для вариантного гнезда:
массив <– сменный_набор
Не существует и четкой границы между вводом единичных значений и вводом
фрагментов текста программы. Нередко отдельные изменяемые части программы удобнее
задавать так же, как и числа, т. е. не путем конфигурационных назначений заранее
подготовленных сменных модулей, а с помощью непосредственного ввода текста
фрагмента в соответствующее гнездо ввода.
Например, фрагмент страницы среды подготовки расчета для программы,
вычисляющей значение определенного интеграла, мог бы иметь вид, изображенный на
рис. 4.2.
Рис. 4.2. Фрагмент страницы среды подготовки расчета.
— гнезда вводаНазначение и тип гнезд очевидным образом определяются их расположением на
странице. Два гнезда, задающие пределы интегрирования, обеспечивают ввод
действительных чисел. В третье гнездо непосредственно вводится выражение, задающее
интегрируемую функцию.
Выражение задается в соответствии с требованиями синтаксиса определенного языка
программирования. Его текст будет подставлен в формируемую расчетную программу,
которая после трансляции, сборки и выполнения выдаст искомое значение интеграла.
Разработчик вправе выбрать один из двух способов передачи в свою программу
введенных пользователем значений пределов интегрирования. С одной стороны, можно
включить в программу оператор ввода, принимающий записанные в гнезде значения. С
другой стороны, можно поступить с пределами интегрирования так же, как и с
подынтегральным выражением, т. е. вставить их тексты непосредственно в исходный текст
программы в виде литеральных констант.
В зависимости от выбранного способа передачи значений поразному распределяются
обязанности между средствами контроля вводимых значений среды подготовки расчета,
интерпретирующим и компилирующим компонентами транслятора. Но для нас интересны
не эти технологические подробности, а то, что второй способ передачи числового значения
— литеральная константа — вплотную смыкается с вводом фрагментов программы.
4.8.4. Гнезда среды и гнезда программы. В программном фонде материалы среды
подготовки расчета занимают промежуточное положение между собственно программными
материалами (текстами алгоритмов, исходными данными и т. п.) и сопроводительной
документацией. Расположенный на страницах среды текст и гипертекстовые связи
относятся скорее к документации, а информация, заносимая в гнезда ввода, ближе к
программным материалам.
Как уже не раз упоминалось, и программные материалы, и документация могут быть
построены на основе каркасного подхода. По существу тот же подход применим и в
рассматриваемой среде подготовки расчета. Здесь в качестве каркаса (т. е. постоянной
части среды) выступают тексты страниц и гипертекстовые связи, а роль гнезд
(обслуживающих переменную часть — разнообразные подготавливаемые наборы данных)
играют гнезда ввода.
Продолжая аналогию с программной, можно говорить обезболезненности подготовки
расчетов. Для того чтобы изменение значения какоголибо изменяемого фактора не
повлекло за собой редактирования текста, содержащего соседние значения, следует, как и
в случае многовариантных программ, сопоставить каждому такому фактору
самостоятельное гнездо ввода. «Изменяемые факторы» трактуются тут несколько шире,
чем ранее: помимо факторов, влияющих на конкретную конфигурацию, к ним отнесены и
факторы, отражаемые в форме исходных данных.Если в проводимых расчетах используется лишь ограниченный набор значений
некоторого фактора, то отвечающее этому фактору гнездо ввода становится по сути
вариантным или наборным (см. разд. 3.6.2). Вариантное гнездо появляется, если в каждом
конкретном расчете требуется ровно одно значение из выделенного ограниченного набора,
а наборное гнездо — если таких значений требуется несколько. Имеет смысл оснастить
среду подготовки расчета не только надлежащими средствами указания требуемых в
расчете значений, но и средствами длябезболезненных изменений состава используемого
ограниченного набора.
Помимо родственных механизмов, обеспечивающих вариантность среды подготовки
расчета и программных материалов, совместного рассмотрения заслуживают также
применяемые там средства навигации. Среди таких средств наиболее заметное место
отводится гипертексту. Гнезда гипертекста (гиперссылки), размещаемые на страницах
среды подготовки расчета, позволяют свободно перемещаться со страницы на страницу. В
то же время, как отмечалось в разд. 2.3.3, техника гипертекста как нельзя лучше подходит
для организации перемещений с модуля на модуль при изучении или редактировании
текстов программ.
Тот или иной механизм навигации необходим на различных фазах подготовки расчета.
Наряду с вводом исходных данных здесь производится и задание конкретной
конфигурации программы, в ходе которого (см. разд. 4.5) может понадобиться
просмотреть и даже отредактировать исходные тексты. Переключения с ввода исходных
данных на работу с исходными текстами программы и обратно заметно облегчатся, если
навигация повсюду будет опираться на единообразные средства гипертекста.
4.9. Задание конфигурации
Как мы только что убедились, задание требуемой конкретной конфигурации
программы имеет смысл выполнять в рамках единой среды подготовки расчета. Напомним,
что первичный элемент описания конкретной конфигурации многовариантной программы
назначает сменный модуль, заполняющий одно из вариантных гнезд каркаса:
имя_вариантного_гнезда <– имя_сменного_модуля
Как спроецировать эту конструкцию на страницу среды подготовки расчета?
4.9.1. Окружение гнезда ввода. От расчета к расчету меняется только имя
назначаемого в вариантное гнездо сменного модуля. Поэтому ясно, что гнездо ввода
следует образовать на месте этого имени, т. е. на месте правой части конструкции
назначения. Тогда имя вариантного гнезда и, возможно, некоторая сопроводительная
информация попадут в обрамляющий гнездо текст страницы (рис. 4.3).Рис. 4.3. Окрестность гнезда ввода имени сменного модуля.
— гнездо ввода
Пользователя среды подготовки расчета, заполняющего конструкцию назначения, надо
снабдить средствами получения дополнительной справочной информации, и в частности
дать возможность добраться до исходных текстов программ, сопряженных с задаваемым
назначением. Для этого можно, например, образовать на месте имени вариантного гнезда
гиперссылку. Обращение к ссылке позволит посмотреть на исходный текст программы,
содержащий вариантное гнездо, или получить исчерпывающую справку о предназначении,
спецификациях вариантного гнезда (или сразу и то, и другое, если спецификации гнезда
внедрены в текст программы).
4.9.2. Меню сменных модулей. Как правило, конкретный сменный модуль назначается
из числа созданных для заполнения данного гнезда модулей, уже имеющихся в
программном фонде. Поэтому центральное место среди рассматриваемых сервисных
средств занимает меню, составленное из имен таких сменных модулей.
Желательно, чтобы формирование меню происходило автоматически. Разработчик
среды подготовки расчета в этом случае указывает только имя вариантного гнезда,
заполняемого с помощью гнезда ввода. Далее сервисные средства самостоятельно
оперируют над программным фондом, выявляя все приписанные к указанному вариантному
гнезду сменные модули и составляя из их имен искомое меню.
Иногда разработчик среды подготовки расчета по какимлибо причинам желает
ограничить возможности выбора. В меню включается не вся совокупность созданных для
заданного гнезда сменных модулей, а только определенное подмножество данной
совокупности. Указание необходимого подмножества и в этом случае лучше выполнить с
помощью сервисных средств. Разработчик снабжает отобранные им для меню сменные
модули определенным атрибутом и этот ассоциативновысекающий требуемое
подмножество атрибут указывает при описании гнезда ввода.
Допустимы различные способы организации процесса первоначального задания
подмножества сменных модулей. Например, его можно задать, помечая имена включаемыхв подмножество модулей в выведенном на экран полном меню, в результате чего
помеченные модули приобретают соответствующий атрибут. Главное — избежать
достаточно очевидной, но иногда еще встречающейся ошибки: если при планируемых
изменениях программного фонда состав подмножества может изменяться, то ни в коем
случае нельзя допустить появления нового самостоятельного первичного объекта,
содержащего непосредственное перечисление имен модулей, вошедших в подмножество.
Как было показано в разд. 3.4.3, присутствие в программном фонде явного
перечисления оказывается губительным для безболезненности последующего развития. В
самом деле, здесь приходится вручную заботиться о поддержании целостности пары
«состав программного фонда — состав перечисления». А именно, при включении в фонд
или при исключении из фонда некоторого сменного модуля нужно вручную
скорректировать (отредактировать) первичный объект — перечисление. Такая организация
изменений программного фонда означала бы утрату важного завоевания каркасного
подхода — выполнения измененийбезболезненно для окружения.
4.9.3. Ручное задание имени. Помимо основного механизма — задания имени
сменного модуля с помощью меню — надо предусмотреть и возможность явного (ручного)
задания имени. Оформление тут вполне традиционно: окрестность гнезда ввода
приобретает вид, подобный изображенному на рис. 4.3, где первая строка гнезда ввода
отведена для ручного ввода имени.
Существуют две характерные ситуации, где явное задание имени оказывается
предпочтительным. Первая из них общеизвестна: при достаточно больших размерах меню
ручное задание выполняется быстрее.
Вторая такая ситуация возникает, когда, размышляя о заполнении очередного
вариантного гнезда, пользователь среды подготовки расчета приходит к выводу о том, что
ни один из имеющихся сменных модулей его не удовлетворяет. Это означает, что
предстоит реализовать новый сменный модуль. В качестве первого шага на пути к созданию
и использованию нового модуля пользователь придумывает для него имя и вручную
записывает это имя в гнездо ввода (находящееся в данный момент на экране перед его
глазами).
Ручное задание имени сменного модуля иногда вызывает некоторые возражения. Дело в
том, что указание имени посредством меню — процедура, в определенном смысле более
надежная, чем ручной ввод. При автоматическом ассоциативном формировании меню за
любым включенным в меню именем всегда стоит хранящийся в программном фонде
сменный модуль. Если сборка опирается только на такие меню, то тем самым удается
исключить источник распространенных ошибок типа «Отсутствует указанный сменный
модуль». Если же допустить возможность ручного ввода имени, то появление подобныхошибок становится весьма вероятным.
И все же доводы в пользу ручного ввода представляются более весомыми. Прежде
всего, при завершении ручного ввода можно проверять не только синтаксическую
корректность имени, но и наличие в программном фонде сменного модуля с данным
именем.
Кроме того, полностью избежать появления диагностики «Отсутствует сменный
модуль» все равно не удается. Не исключено, что в промежутке времени между
завершением подготовки расчета и началом сборки выполняемой программы некоторые из
сменных модулей, выбранных ранее посредством указания их имен в меню, будут удалены
из программного фонда. Разумеется, при попытке удаления такого используемого в
расчете модуля выдается диагностика «Удаляемый модуль используется в расчете». Но
диагностика эта всего лишь предупредительная. Нельзя же, в самом деле, лишать
разработчика права уничтожения написанного им модуля только изза того, что ктото
пытается этот модуль использовать. Ведь удаление модуля может быть вызвано
обнаружением трудно устранимых ошибок, и в этом случае чем раньше такой модуль будет
удален, тем лучше для всех.
Наконец, последний, наиболее серьезный аргумент. Из запрета ручного задания имени
следовало бы, что пользователю среды подготовки расчета навязывается жесткая
последовательность действий: сначала надо реализовать сменный модуль (в результате чего
имя модуля появится в меню), и лишь затем разрешается планировать его применения
(указывая его имя в описании конфигурации). Такой диктат следует признать чрезмерным.
К тому же тут возникает некоторое противоречие с популярной стратегией разработки
программ «сверху вниз», которая пропагандирует обратную последовательность действий.
4.9.4. Другие сервисные средства. Механизмы меню и ручного ввода имени сменного
модуля составляют основу системной поддержки назначения содержимого вариантного
гнезда. Однако помимо них в среде подготовки расчета могут быть предусмотрены и
некоторые вспомогательные сервисные средства.
Полезно, в частности, разрешить просматривать (или редактировать) текст сменного
модуля, имя которого задано текущей строкой меню. Просмотр будет более наглядным,
если он выполняется «в рабочем контексте», т. е. в окружении текста, содержащего
заполняемое вариантное гнездо. Такие средства, наряду с уже упоминавшимися
средствами доступа к окрестности обслуживаемого вариантного гнезда, обеспечивают
необходимые связи между средой подготовки расчета и сопряженными с ней исходными
текстами программ.
Наращивание мощности сервисных средств можно было бы легко продолжить. Но мы
предпочтем здесь остановиться, поскольку в наши намерения вовсе не входит построениезаконченного механизма задания конкретной конфигурации. На этих страницах мы
стремились лишь проиллюстрировать основные проблемы, связанные с таким построением.
4.9.5. Синтаксис. В рассмотренных сервисных средствах относительно мал вес чисто
языковых решений — синтаксис всех упомянутых конструкций крайне прост. Зато на
первый план выдвигается задача увязки создаваемых средств задания конкретной
конфигурации с их соседями, со средой подготовки расчета.
Например, модуль типа направление (отражающий определенное направление
исследований) фиксирует некоторую консервативную часть вводимых числовых данных и
назначений для вариантных гнезд. Для пользователя такой модуль предстает прежде всего
в виде среды подготовки расчета, в которой некоторое подмножество гнезд ввода уже
заполнено конкретными, не допускающими изменений значениями. Разумеется, модуль
типа направление может приобретать и другие формы, проектирование синтаксиса
которых потребует определенных усилий. Так, для распечатки этого модуля на принтере,
возможно, придется придать ему вид компактного линейного текста. Однако подобные
формы представления модуля типа направление имеют вторичный характер, используются
сравнительно редко, и поэтому рассматриваться тут они не будут.
4.9.6. Вариантный ввод. Существует еще одна важная связь между элементами
описания конфигурации и исходными данными, соседствующими в среде подготовки
расчета. Дело в том, что различные сменные модули, подставляемые в вариантное гнездо,
могут, вообще говоря, требовать ввода различного состава исходных данных. Такой ввод,
зависящий от конкретной конфигурации многовариантной программы, будем
называть вариантным вводом.
Пусть, например, для заполнения вариантного гнездаДОСТУП_К_ТАБЛИЦЕ может
быть назначен либо сменный модульХЕШИРОВАНИЕ, либо сменный
модуль ЛИНЕЙНЫЙ_ПОИСК. МодульХЕШИРОВАНИЕ требует в качестве исходных
данных имя используемой хешфункции (функции расстановки). Если же для заполнения
данного гнезда назначить сменный модуль ЛИНЕЙНЫЙ_ПОИСК, то, конечно, никакой
хешфункции задавать не потребуется.
Ввод для модуля ХЕШИРОВАНИЕ может быть организован поразному. Если
переключение с одной хешфункции на другую оформлено в виде оператора выбора, то для
ввода имени понадобится гнездо ввода данных. Если же хешфункции, в свою очередь,
сопоставлено вариантное гнездо, то понадобится гнездо ввода имени сменного модуля. Но
сейчас для нас существен не тип гнезда ввода, а то, что его заполнение требуется лишь в
случае, когда назначен сменный модуль ХЕШИРОВАНИЕ; т. е. здесь мы имеем дело с
вариантным вводом.
Вероятно, неверно было бы запретить пользователю среды подготовки расчета сначалаввести имя хешфункции и только потом сказать, что способ организации доступа к
таблице — хеширование (хотя обратная последовательность представляется обычно более
естественной). Ведь «пользователь всегда прав», и если ему почемуто покажется более
удобной какаялибо последовательность заполнения гнезд ввода, он должен иметь
возможность применить именно ее.
Таким образом, можно заключить, что пользователю среды подготовки расчета всегда
должны быть доступны все существующие гнезда ввода, даже если часть из них он заполнит
напрасно, т. е. если их содержимое никак не отразится ни на составлении, ни на
выполнении расчетной программы. Разумеется, параллельно надо принять меры для того,
чтобы доступность гнезд не повредила надежности процесса их заполнения. Пользователь
имеет право в любой момент потребовать показать ему все гнезда ввода, заполненные им
«вхолостую». Кроме того, при желании он может легко избежать опасности заполнения
«холостых» гнезд: для этого достаточно регулярно пользоваться клавишей Следующий
ввод (см. разд. 4.8.2).
4.9.7. Пополнение среды подготовки расчета. С точки зрения разработчика среда
подготовки расчета — такой же равноправный компонент программного фонда, как и
собственно программы. Поэтому, говоря о безболезненности подключения сменных
модулей, необходимо иметь в виду и их влияние на среду подготовки расчета. Как мы
только что видели (см. разд. 4.9.6), вновь появившийся сменный модуль может включать в
себя вариантный ввод, т. е. может, вообще говоря, потребовать дополнения среды
подготовки расчета новыми гнездами ввода для своих специфических исходных данных.
Безболезненность тут приобретает более широкую трактовку. Теперь надо заботиться не
только о том, чтобы появление нового модуля не затронуло соседние программы, но и о
том, чтобы безболезненно прошло подключение к среде подготовки расчета новых гнезд
ввода.
Интересно, что отвергнутая нами ранее (см. разд. 4.6) схема задания конфигурации,
подчиненного сборке, обеспечивает в какойто мере безболезненность расширения среды
подготовки расчета. Алгоритм данной схемы автоматически охватывает все вариантные
гнезда, входящие в собираемую конкретную конфигурацию программы. Поэтому если
вновь подключенный сменный модуль содержит новое вариантное гнездо, то содержимое
этого гнезда непременно рано или поздно будет запрошено в ходе диалога с пользователем.
Но если новый модуль требует специфического ввода данных, то буквальное обращение к
данной схеме ничего не дает: ввод данных не входит в ее компетенцию.
Впрочем, область действия рассматриваемого алгоритма задания конфигурации можно
расширить, распространив ее на интересующий нас сейчас ввод данных. Для этого
придется специальным образом оформить содержащиеся в программе запросы ввода
данных, что сделает их доступными для этого алгоритма. Теперь при заданииконфигурации пользователь будет наряду с именами сменных модулей вводить и исходные
данные, причем те и только те из них, запросы на которые содержатся в собираемой
конкретной конфигурации. Тем самым проблема вариантного ввода
будет безболезненно решена.
К сожалению, данное решение весьма несовершенно. Оно опирается на задание
конфигурации, подчиненное сборке, а эта схема была вполне заслуженно подвергнута в
разд. 4.6 жесткой критике. Напомним главный недостаток схемы: пользователю
навязывается строго линейная последовательность ввода, которая к тому же диктуется не
логикой стоящей перед ним задачи, а особенностями работы алгоритма сборки.
Избавление от линейной последовательности приходит с применением гипертекста. Но
тут мы вынуждены вернуться к проблеме безболезненной реализации вариантного ввода:
традиционная гипертекстовая среда плохо поддается изменениям. Во многих популярных
реализациях гипертекста предполагается, что разработчик полностью, «до последнего
пиксела» проектирует все страницы среды. В таком случае подключение к среде нового
элемента, обслуживающего вариантный ввод, потребует, вообще говоря, редактирования
какойлибо из существующих страниц, т. е. будет нарушено требование безболезненности.
Чтобы сделать гипертекстовую среду более податливой, нужно разгрузить
разработчика от ее окончательной компоновки, перепоручив формирование страниц среды
системным средствам. Разработчик создает лишь составные части страниц, отвечающие за
ввод элементов описания конфигурации или отдельных данных. Создаваемые части
снабжаются атрибутами, характеризующими тематическую принадлежность вводимого
параметра расчета. Опираясь на эти атрибуты, системные средства формируют страницы
гипертекста, стараясь объединить близкие по теме части (т. е. решая задачу кластерного
анализа).
Появляющиеся таким образом составные части страниц гипертекстовой среды
подготовки расчета привязываются к порождающим их конструкциям программы: к
вариантным гнездам или к запросам ввода данных. Тогда гипертекстовая среда становится
производной от текущего состояния программного фонда — в нее включаются те части
страниц, которые привязаны к хранящимся в фонде программам. Благодаря этому
решению и достигается безболезненность подключения фрагментов программ,
содержащих запросы на новые части страниц.
В самом деле, пусть требуется добавить в программный фонд новый вариантный
фрагмент, содержащий специфический, не встречавшийся ранее в среде подготовки
расчета запрос на ввод некоторого параметра. Разработчик готовит обслуживающую запрос
часть страницы гипертекста и помещает ее наряду с новым вариантным фрагментом в
программный фонд. Кроме того, он задает привязку новой части гипертекста к новому
программному фрагменту. Далее все заботы по безболезненному подключению берут насебя системные средства. Они обратят внимание на новое поступление и автоматически
расширят среду подготовки расчета.
Забегая вперед, отметим, что для сборки среды подготовки расчета из разбросанных по
программному фонду вариантных гнезд и запросов на ввод потребуются
конфигурационные механизмы, не похожие на рассматриваемый нами сейчас аппарат
многовариантности. Такие механизмы будут предложены в гл. 6.
4.10. Сборка выполняемой программы
В традиционной общецелевой операционной среде превращение подготовленных
текстов алгоритмов в выполняемую программу происходит, как правило, в два этапа.
Сначала производится трансляция, в результате которой получают объектные модули, а
затем — компоновка, связывающая эти модули между собой. Если же операционная среда
предполагает обслуживать расширяемый программный фонд, и в частности поддерживать
многовариантность, то аппарат сборки несколько усложняется.
Необходимость привлечения дополнительных системных средств объясняется тем, что
в наших построениях используется более свободная трактовка понятия «модуль» (см.
разд. 2.1). В традиционной среде на стадии сборки программы в качестве модулей
выступают обычно единицы алгоритмического языка, допускающие автономную
трансляцию. Границы же модулей в многовариантных программах обычно не совпадают с
границами автономно транслируемых единиц. Модуль многовариантности может включать
в себя несколько таких единиц, или же может представлять собой фрагмент текста на
алгоритмическом языке, вставляемый в формируемый текст модуля трансляции.
Использование в качестве модулей вставляемых фрагментов приводит к тому, что для
подготовки трансляции требуется, вообще говоря, выполнять препроцессирование, т. е.
строить из текстов модулей многовариантности текст модуля трансляции. Таким образом,
сборка выполняемой программы в многовариантном случае включает не два, а три этапа:
препроцессирование, трансляцию и компоновку.
Однако отличия в обслуживании многовариантных программ не сводятся к
подключению препроцессирования. Здесь придется немного скорректировать всю
совокупность представлений об организации сборки, о чем и пойдет речь в настоящем
разделе.
4.10.1. Препроцессирование, трансляция и компоновка. Итак, описание требуемой
конкретной конфигурации составлено. Что же происходит дальше? Конечно, было бы по
меньшей мере непоследовательно сначала вооружить разработчика многовариантной
программы развитыми средствами поддержки составления описания конфигурации, а
затем, на завершающем этапе, оставить его один на один с теми скудными возможностямидля организации препроцессирования, трансляции и компоновки, которые предоставляет
обычно общецелевая операционная среда.
С одной стороны, совокупность материалов, используемых для построения
многовариантной программы, довольно обширна и сложна, что сильно затрудняет ручное
выполнение многих рутинных операций. (Этим операциям в традиционной среде не
уделяется должного внимания, поскольку они не требуют скольконибудь заметных усилий
при работе с программами небольшого объема.) Поясним, например, изза чего возникают
трудности в области экономии трансляции. Автономно транслируемая программная
единица (модуль трансляции) может содержать несколько вариантных гнезд. Каждая
комбинация сменных модулей, заполняющих (при препроцессировании) эти гнезда, требует
самостоятельной трансляции. Хранение и учет множества объектных модулей,
появляющихся в результате таких трансляций, превращаются для многовариантных
программ в самостоятельную, весьма трудоемкую проблему.
С другой стороны, как было видно из предшествующего изложения, обеспечение среды
для эффективного задания конкретных конфигураций многовариантной программы
включает в себя хранение в программном фонде разнообразной информации, касающейся
связей между отдельными модулями. Эта информация составляет необходимый базис,
благодаря которому средства системной поддержки могли бы, получив от пользователя
описание конфигурации, практически полностью избавить его от подавляющего
большинства забот по препроцессированию, трансляции и компоновке. Точнее говоря, от
пользователя потребуется только заполнить все гнезда ввода в среде подготовки расчета
— затем он нажмет функциональную клавишу Выполни и, не задумываясь о произведенной
средствами поддержки рутинной работе, по завершении сборки заданной программы и ее
выполнения приступит к анализу полученных результатов.
Разумеется, совсем забыть о существовании препроцессирования, трансляции и
компоновки пользователю не удастся. Но вспоминать о них он будет только при
обнаружении какихлибо ошибок, появление которых, к сожалению, неизбежно при
достаточно энергичной работе по развитию программного фонда.
С исправлением ошибок связан еще один важный технологический момент.
Редактирование исходного текста программы в традиционной среде должно повлечь за
собой уничтожение объектного модуля, порожденного ранее в результате трансляции этого
текста. В многовариантной среде текст (точнее, модуль многовариантности), как правило,
так или иначе участвует в порождении уже не одного, а нескольких объектных модулей,
причем проследить вручную все имеющиеся связи «исходный текст — объектный модуль»
оказывается далеко не просто. В задачу средств системной поддержки входит выявление и
уничтожение всех устаревших объектных модулей, порожденных с участием
отредактированного исходного текста.В традиционной среде иногда для подобных манипуляций применяются штатные
универсальные средства, подобные make в системе UNIX. Обращаться к ним для
организации сборки версий многовариантной программы, повидимому, нецелесообразно.
Прежде всего, подобным средствам обычно недоступны некоторые функции, выполняемые
конфигурационным препроцессором.
Кроме того, связи между компонентами многовариантной программы довольно сложны
и о всех этих связях надо поставить в известность подключаемое средство. Поэтому
соответствующее описание оказалось бы излишне громоздким и, главное, дублирующим
уже имеющуюся в программном фонде информацию. В то же время для
специализированных средств поддержки многовариантности отслеживание соответствия
между исходными текстами и порожденными объектными модулями не составит особого
труда. Немаловажно и то, что многие из задач, стоящих перед средствами поддержки,
решаются существенно проще, если к манипуляциям над программным фондом не
допускаются инородные программные системы.
4.10.2. Распространенные схемы компоновки. Несмотря на отмеченные выше
препятствия, в цепочке «препроцессирование — трансляция — компоновка»,
осуществляющей сборку многовариантных программ, первые два звена реализуются
относительно легко. Конфигурационный препроцессор напоминает макропроцессор: в роли
макровызовов выступают гнезда каркаса, а в роли библиотеки макроопределений —
программный фонд, содержащий сменные модули. Главное отличие заключается в том, что
помимо исходного текста и сменных модулей в работе препроцессора на равных правах
участвует еще и третья сторона — описание конкретной конфигурации, назначающее
содержимое гнезд. Второе звено сборки — трансляция — выглядит практически так же,
как и в общецелевой среде.
Основные сложности связаны с организацией компоновки, к изучению которой мы и
переходим. Прежде всего рассмотрим, какие схемы компоновки используются в
традиционных операционных средах. Наиболее широко распространены перечислительная,
корневая и комбинированная схемы.
При перечислительной схеме в описании конкретной конфигурации явно
перечисляются все составляющие собираемую программу автономно транслируемые
программные единицы — модули трансляции. (И сейчас еще попадаются операционные
среды, где перечисляются не первичные объекты с исходными текстами, а вторичные —
объектные модули. Но, как было показано в разд. 2.2, явное указание вторичных объектов
влечет за собой множество неудобств, и поэтому подобные решения мы здесь и в
дальнейшем рассматривать не будем.) В ходе компоновки разрешаются внешние связи, но
они никак не влияют на состав включаемых в собираемую программу модулей.При корневой схеме в описании конфигурации явно указывается только головной
(корневой) модуль трансляции, а все остальные включаются в собираемую программу в
ходе разрешения внешних связей (запросов импорта). Считается, что в распоряжении
компоновщика (называемого также редактором связей) находится вся совокупность
модулей программного фонда и для каждого модуля известны все его входные точки и
внешние ссылки. Компоновщик, разрешая очередную внешнюю ссылку, находит в
программном фонде модуль с соответствующей входной точкой и включает этот модуль в
собираемую программу. Тем самым, с одной стороны, возможно, разрешается еще
несколько внешних ссылок, но, с другой стороны, могут добавиться новые неразрешенные
ссылки из числа внешних ссылок подключаемого модуля.
Наконец, третья, комбинированная схема обладает отдельными чертами
перечислительной и корневой. Подобно перечислительной схеме тут задается перечень
имен головной группы модулей, которые безусловно включаются в собираемую программу.
Кроме того, в компоновке участвуют одна или несколько библиотек. Хранящиеся в них
модули подключаются к собираемой программе уже избирательно, по корневой схеме
разрешая оставшиеся внешние ссылки головной группы. Комбинированная схема,
сочетающая в себе достоинства (о которых речь пойдет ниже) корневой и
перечислительной, является сейчас, повидимому, наиболее популярной.
Три упомянутые схемы компоновки встречаются в самых различных модификациях.
Кроме того, существуют и несколько иные подходы. В частности, самостоятельную ветвь
образует инкрементальная сборка программ (см. разд. 2.3.2), позволяющая при внесении
изменений не повторять весь процесс компоновки заново, а ограничиться коррекцией
небольших участков загружаемого кода. Но широкого распространения подобные решения
пока не получили, и мы не будем на них останавливаться.
Рассмотрим теперь достоинства и недостатки указанных схем. Попытаемся разобраться
в том, какие из этих схем могут служить в качестве основы при сборке многовариантных
программ.
4.10.3. Перечислительная компоновка. На первый взгляд, перечислительная схема
безнадежно проигрывает корневой. Действительно, с какой стати программиста
принуждают явно составлять какойто перечень модулей трансляции, когда всю эту работу
может с успехом проделать за него компоновщик? Или, скажем, пусть создатель
многомодульной программы на очередном этапе решил расчленить на два модуля
некоторый периферийный модуль трансляции. Почему при этом он обязан (подобно
перечислительной сборке — см. разд. 3.4.3) вручную отредактировать стоящий на вершине
программной иерархии первичный объект, содержащий перечень модулей?
Неужели разработчики штатного обеспечения не заметили этих очевидных слабостейили поленились реализовать более рациональную схему? Конечно же, видеть причину
распространенности перечислительной схемы всего лишь в нерадивости разработчиков
штатного обеспечения было бы неверно. Если принять версию нерадивости, то в самой
популярной, комбинированной схеме ее перечислительный компонент будет
восприниматься как чисто избыточный, не обязательный для реализации. Но разработчики
тем не менее почемуто упорно не пытаются сэкономить здесь свои усилия.
Интерес к перечислительной схеме не ослабевает, повидимому, не в последнюю
очередь изза потребностей вариантного программирования. В частности, именно
перечислительная схема компоновки требуется для реализации одного из описанных в
первой главе (см. разд. 1.3) простейших способов оформления варианта — размножения
окрестности вариантного фрагмента.
Напомним постановку задачи и основные шаги этого способа. Пусть неожиданно
потребовалось наряду с имеющимся алгоритмом получить его модификацию, причем все
отличия между двумя версиями алгоритма заключены в четко очерченном фрагменте
исходного текста. И пусть имеющаяся операционная среда не располагает
специализированными средствами поддержки оформления варианта. Для определенности
предположим кроме того, что вариантный фрагмент содержится непосредственно в тексте
модуля трансляции.
Тогда оформление варианта может быть выполнено следующим образом. Сначала
создается (под другим именем) копия исходного текста модуля трансляции. Затем в ней с
помощью обычного редактора старый вариантный фрагмент заменяется новым. И наконец,
при формировании задания на компоновку в перечень модулей трансляции включается, в
зависимости от потребности, старый или новый модуль.
Легко заметить, что для данного способа оформления варианта жизненно необходимо
ручное формирование перечня модулей трансляции. В нем теперь можно даже усмотреть
творческий момент: требуется не просто механически перечислить модули, разрешающие
транзитивное замыкание внешних ссылок корневого модуля, а на какомто этапе
сознательно выбрать одну из двух возможных модификаций модуля, содержащего
вариантный фрагмент.
В условиях отсутствия специализированных средств поддержки вариантности
отказываться от перечислительной схемы, повидимому, нецелесообразно. Ведь при
корневой схеме компоновки осуществить подобный способ оформления варианта можно
было бы, только до предела расширив размножаемую окрестность. Дублировать придется
не единичный модуль трансляции, а весь программный фонд. Или, по крайней мере, надо
будет образовать новый программный фонд, включив в него все материалы, используемые
при сборке данной конкретной конфигурации программы. Столь масштабные мероприятия
необходимы, поскольку здесь указание корневого модуля полностью задает весьпоследующий ход компоновки. Следовательно, если содержащий вариант модуль не
корневой, применить размножение окрестности как способ оформления варианта в
пределах одного программного фонда не удается.
Теперь становится понятным, изза чего библиотеки модулей (в особенности
библиотеки общего назначения) подключаются при комбинированной компоновке по
корневой схеме. Дело в том, что в существующих библиотеках, как правило, отсутствует
вариантность, а без нее в явном перечислении модулей просто нет необходимости. Тут уже
преимущества корневой схемы (в первую очередь компактность описания конфигурации)
становятся неоспоримыми, благодаря чему она решительно вытесняет перечислительную.
Итак, мы определили место перечислительной схемы в традиционном
«маловариантном» программировании. Вернемся к многовариантным программам.
Способна ли работать эта схема компоновки в контексте многовариантности?
Применение перечислительной схемы сильно облегчило бы жизнь разработчикам
средств системной поддержки многовариантности, избавив их от многих забот по поиску
модулей трансляции для разрешения внешних ссылок. На их долю осталась бы только
сравнительно несложная работа — препроцессирование отдельных модулей трансляции,
т. е. заполнение вариантных гнезд сменными модулями в соответствии с имеющимся
описанием конкретной конфигурации.
Допустимость перечислительной компоновки (подобно допустимости
перечислительного механизма сборки — см. разд. 3.4.3) существенно зависит от того,
насколько динамично меняется состав модулей, задаваемый перечнем. На практике
встречаются задачи вычислительного эксперимента, где состав модулей трансляции,
включаемых в конкретные конфигурации многовариантной программы, относительно
стабилен. В таком случае применение перечислительной компоновки не так уж
катастрофично, поскольку пользователь составляет требующийся перечень модулей один
раз и затем лишь изредка его корректирует.
Чаще, однако, изменения состава модулей трансляции носят регулярный характер.
Здесь нередки ситуации, где нетехнологичность перечислительной компоновки явно
бросается в глаза. Пусть, например, для одного из вариантных гнезд созданы два сменных
модуля, один из которых содержит обращение к некоторому вспомогательному модулю
трансляции, а второй — нет. Тогда каждый раз при переназначении этих сменных модулей
надо будет, вообще говоря, редактировать перечень составляющих компонуемую
программу модулей трансляции, нарушая таким образом безболезненность переключения
сменных модулей. Дело осложняется еще и тем, что злополучный вспомогательный модуль
трансляции нельзя механически выбросить из перечня при переключении на второй
сменный модуль, так как к этому вспомогательному модулю могут быть обращения из
других (в свою очередь, возможно, вариантных) частей компонуемой программы.Иногда из положения удается выйти, составив перечень компоновки «с запасом», т. е.
включив в него на всякий случай все потенциально полезные модули трансляции. Но чаще
такое решение не проходит, в частности, изза соображений компактности выполняемого
кода.
В итоге попытку применения перечислительной схемы компоновки к многовариантным
программам, повидимому, придется признать неудачной. Посмотрим теперь, что может
дать здесь корневая схема.
4.10.4. Корневая компоновка. В многовариантной среде корневая компоновка
протекает следующим образом. Прежде всего препроцессор формирует текст корневого
модуля трансляции. Точнее, сначала выясняется, не транслировался ли ранее корневой
модуль в той же конфигурации, т. е. при том же составе включаемых в него сменных
модулей. Если транслировался, то соответствующий объектный модуль уже готов и он
просто извлекается из программного фонда. Если заданная комбинация сменных модулей
встретилась впервые, то формируется полный текст модуля и выполняется трансляция.
Так или иначе, в результате мы имеем объектный модуль для корневого модуля
трансляции. Атрибутами объектного модуля являются его внешние связи, из которых
выясняются необходимые для разрешения этих связей модули трансляции. Каждый из
затребованных таким образом модулей включается в собираемую программу, с ним
производятся те же действия: сначала либо извлечение имеющегося объектного модуля,
либо (иначе) препроцессирование и трансляция, а затем выяснение из внешних ссылок
необходимых модулей трансляции. Новые модули трансляции в свою очередь пополняют
собой собираемую программу. Сборка завершается, когда таким образом обработаны все
потребовавшиеся модули трансляции.
Описанный алгоритм сборки подкупает своей простотой и очевидностью. Хотя изза
некоторых особенностей распространенных языков программирования реальная сборка
может оказаться несколько тяжеловеснее, тем не менее никаких принципиальных
сложностей здесь не возникает.
Существует единственное ограничение, накладываемое на структуру программы для
упрощения корневой сборки, и заключается оно в следующем. Входные точки модуля
трансляции не должны определяться в сменных модулях, подставляемых прямо или
косвенно в его гнезда. Только приняв это ограничение, можно считать, что любая внешняя
связь однозначно определяет модуль трансляции, содержащий отвечающую ей входную
точку. Неоднозначность определения модуля трансляции привела бы к весьма
значительному усложнению алгоритма сборки. Но, к счастью, сформулированное
ограничение выглядит достаточно естественным и на практике никак не стесняет
разработчика.4.10.5. Модуль трансляции и сменный модуль. На этих страницах постоянно
сталкиваются два понятия: модуль трансляции и сменный модуль. Эти типы модулей
заметно отличаются друг от друга.
Модуль трансляции — общепризнанный объект операционной среды. Он должен
обладать достаточной степенью самостоятельности, позволяющей ему автономно
транслироваться и затем участвовать в компоновке. Самостоятельность модуля
трансляции обеспечивается прежде всего посредством включения в его текст
спецификаций интерфейса. Присутствие спецификаций облегчает, кроме того, независимое
изучение текста модуля.
Сменный модуль — объект специализированной операционной среды, поддерживающей
многовариантность. Все его собратья, принадлежащие одному и тому же вариантному
гнезду, имеют идентичный интерфейс. Очевидно, нет необходимости размножать
спецификации этого интерфейса в тексте каждого из «братских» сменных модулей — их
следует «вынести за скобки», записав в единственном экземпляре, например, в
окружающем гнездо тексте. При изучении текста сменного модуля средства поддержки
многовариантности покажут его в контексте окружения гнезда, так что разработчик
сможет увидеть записанные там спецификации.
Итак, модуль трансляции обязан иметь спецификации интерфейса — иначе он окажется
изолированным от остальной программы. Напротив, сменный модуль, или, иначе, модуль
изменяемости, обязан вынести эти спецификации вовне. Отсюда следует, что границы этих
модулей не совпадают.
Что лучше: модуль трансляции или сменный модуль? Вопрос, вообще говоря,
некорректный — каждый хорош на своем месте. Однако отсутствие или слабость средств
поддержки многовариантности нередко вынуждают разработчика превращать сменные
модули в модули трансляции, дублируя их спецификации. И это весьма огорчительно.
Беда здесь не только в потенциальном источнике нарушения целостности фонда изза
неизбежных рассогласований при синхронном редактировании нескольких копий, но и в
том, что идентичность интерфейсов модулей трансляции может быть кемто впоследствии
воспринята не как функциональное родство, а всего лишь как случайное совпадение.
Любопытно, что проблема объявления принадлежности модуля определенному
однородному семейству эффективно решается на глобальном уровне. Для многократно
используемых модулей каждый интерфейс вправе централизовано получить уникальный
(среди всех программистов Земли) идентификатор — в эпоху повсеместного
распространения Интернета не составляет труда смастерить общедоступный генератор
идентификаторов интерфейсов. И действительно, такие генераторы реализованы и активно
используются.
Но получение глобального идентификатора для каждого вариантного гнездамноговариантной программы представляется нелепым расточительством. К тому же такой
подход решил бы лишь незначительную часть проблем поддержки многовариантного
программирования, к обсуждению которых мы возвращаемся в следующем разделе.
4.10.6. Предупреждение повторения сборочных работ. Заканчивая разговор о
возможных схемах сборки многовариантных программ, вновь подчеркнем, что при любой
схеме имеет смысл предусмотреть средства предупреждения повторных
препроцессирования, трансляции и компоновки.
Каждый раз перед препроцессированием и трансляцией надо проверить, не
формировался и не транслировался ли раньше данный модуль в той же конфигурации, т. е.
с тем же составом вставляемых сменных модулей. И если модуль когдалибо
обрабатывался, то, конечно, сэкономить время: ни препроцессирования, ни трансляции
выполнять не нужно, а следует извлечь из программного фонда ранее полученный
объектный модуль.
Те же соображения применимы и к загрузочному модулю. Если поступает запрос на
сборку программы с не изменившейся после проведенной ранее сборки конкретной
конфигурацией, то теперь уже все этапы сборки (т. е. препроцессирование, трансляция и
компоновка) не повторяются, а из программного фонда извлекается готовый загрузочный
модуль.
При создании системных средств для предупреждения повторения сборочных работ
должны быть так или иначе учтены следующие два аспекта сопутствующего обслуживания
вторичных объектов.
Вопервых, при внесении изменений в первичный объект надо выявить и исключить из
программного фонда все зависящие от него вторичные объекты, т. е. все объектные и
загрузочные модули, порожденные в свое время с участием данного исходного текста.
Вовторых, имеет смысл предусмотреть какойлибо алгоритм отсева части хранящихся
в программном фонде вторичных объектов, и автоматически или вручную запускать его,
если этих объектов расплодилось слишком много. Проще всего в этом алгоритме удалять
из фонда вторичные объекты, к которым долго не было обращений.
4.11. Межмодульная навигация
Программный фонд крупных размеров, каковым, в частности, является обычно
программный фонд вычислительного эксперимента, требует развитых технических средств
обслуживания. Некоторые из этих средств (такие, например, как служба объектных
модулей — см. разд. 4.10.6) уже в какойто мере изучены нами, другие (организация
передачи готовых продуктов во внешние организации, защита от несанкционированного
доступа к отдельным материалам и т. п.) выходят за тематические рамки настоящей книги.Но пока относительно мало внимания уделялось организации поиска и просмотра объектов
программного фонда, хотя эта проблема достаточно тесно соприкасается с
интересующими нас конфигурационными построениями. Теперь мы попытаемся
восполнить данный пробел.
Ранее (см. разд. 4.8, 4.9) были довольно подробно рассмотрены средства доступа к
отдельным страницам среды подготовки расчета и предложен аппарат для поддержки
связей между средой подготовки расчета и сопряженными исходными текстами программ.
Однако обращение к исходным текстам из среды подготовки расчета — относительно
редкое явление, разработчику чаще требуется напрямую выйти на то или иное место
программы. В этом случае доступ к модулям программного фонда опирается на два
взаимодополняющих механизма: на использование каталогов модулей и на
непосредственную навигацию между модулями.
4.11.1. Каталоги модулей. Аппарат каталогов модулей имеется в подавляющем
большинстве операционных сред. Он обычно позволяет высекать подмножество модулей по
заданному значению (диапазону значений) указанного атрибута, упорядочивать модули в
каталоге по возрастанию или убыванию значений указанного атрибута и производить
многие другие операции, традиционно предоставляемые системами управления базами
данных.
Фигурирующие в каталоге атрибуты модулей имеют различное происхождение. Среди
них можно выделить две группы.
Атрибуты первой группы формируются в определенном смысле без участия
разработчика: даты создания, последнего редактирования и последнего использования,
автор, размер и др. Отдельные атрибуты автоматически извлекаются из текста модуля при
включении его в программный фонд: имена вариантных гнезд из предложений #VARIANT,
внешние связи из соответствующих конструкций языка программирования и т. п.
Атрибуты второй группы непосредственно вводятся разработчиком. Одни атрибуты
(«имя», «тип») каждый раз запрашиваются у него при создании модуля, другие — задаются
по его инициативе. Часть из них («язык программирования», «отлажен» и др.) может
использоваться системными средствами, а часть интересна только самому разработчику.
При организации каталога важно поставить дело так, чтобы все атрибуты независимо от
их происхождения могли бы на равных правах включаться в любые запросы и в любые
форматы вывода.
Выбрав в каталоге требующийся модуль, разработчик переходит к просмотру или
редактированию его текста. Впоследствии, закончив действия над текстом, он вправе вновь
вернуться в режим работы с каталогом. Однако такой возврат может оказаться излишним,
поскольку разработчику порой нужно всего лишь перейти к соседнему модулю, а для этогововсе не обязательно подниматься на уровень каталога — существенно более короткий
путь предлагает механизм непосредственной межмодульной навигации.
4.11.2. Непосредственная навигация. Удобство и масштабы применения механизма
непосредственной межмодульной навигации определяются прежде всего тем, насколько
широко трактуется здесь понятие «соседний модуль» или, точнее, сколько поддерживается
различных полезных толкований этого понятия. Одна из очевидных интерпретаций
«соседнего модуля» — модуль, который просматривался или редактировался перед
текущим. В самом деле, возвращаться к предыдущему модулю приходится достаточно
часто, и поэтому имеет смысл поддержать такой возврат, посвятив ему, скажем,
специальную функциональную клавишу.
Другой простой пример непосредственной навигации — последовательный просмотр
текстов выделенной группы модулей. Тут (наряду с клавишей возврата к предыдущему)
потребуется клавиша перехода к следующему модулю. Пусть, например, в каталоге
выделено некоторое подмножество модулей программного фонда, скажем, все модули,
написанные на языке Си. Тогда для того чтобы быстро последовательно просмотреть
тексты всех выделенных модулей, удобнее не возвращаться многократно к уровню
каталога, а, не покидая уровня исходного текста, воспользоваться для межмодульных
переходов названными функциональными клавишами. Средства последовательного
просмотра полезно дополнить также возможностью сквозного контекстного поиска в
выделенной группе модулей.
Подобные незатейливые способы непосредственной межмодульной навигации
безусловно полезны, но играют чисто вспомогательную роль: они лишь незначительно
упрощают некоторые часто встречающиеся манипуляции над модулями и каталогами. С
точки же зрения крупных многовариантных программ существенно больший интерес
представляет непосредственная навигация, опирающаяся на разнообразные
зафиксированные в программном фонде межмодульные связи. Подобно тому как во многих
предметных областях организация работы на основе гипертекста оказывается
предпочтительнее использования систем управления базами данных, в программном фонде
непосредственная навигация, основанная на межмодульных связях, во многих случаях
оказывается проще, нагляднее и эффективнее, чем обращение к каталогам модулей.
Межмодульные связи, отраженные в программном фонде, весьма разнообразны, и
практически любая из них может послужить для непосредственной навигации. Мы не
будем пытаться охватить все возможные виды связей, а ограничимся тем, что наметим пути
навигационной реализации всего лишь для двух из них: для внешних ссылок и для аппарата
вариантных гнезд.4.11.3. Внешние ссылки. Какой программист не мечтал подвести курсор к
идентификатору вызываемой внешней процедуры и, нажав соответствующую
функциональную клавишу, перейти в модуль, содержащий описание этой процедуры! И
обратно, оттолкнувшись от описания процедуры, быстро пробежаться по всем имеющимся
в программном фонде модулям, содержащим обращения к данной процедуре!
К сожалению, подобные роскошества непосредственной межмодульной навигации
доступны пока не в каждой операционной среде. Если же, однако, такая навигация
реализована, то опирается она на результаты синтаксического и семантического анализа
исходного текста, а это означает, что среда располагает весьма подробной информацией о
структуре и об отдельных объектах программы. Поэтому здесь нетрудно превратить
рассыпанные по тексту идентификаторы каждого маломальски интересного объекта в
гиперссылки. Активировав подобную гиперссылку, с помощью соответствующих
функциональных клавиш можно будет пройтись по разнообразным родственным связям
объекта.
4.11.4. Обслуживание многовариантности. Для многовариантных программ особое
значение приобретает непосредственная навигация, обслуживающая аппарат вариантных
гнезд и сменных модулей. Число различных требующихся для этой навигации
межмодульных связей невелико, и, повидимому, все они должны быть поддержаны
гипертекстовыми механизмами.
Так, прежде всего следует образовать гиперссылку на месте вариантного гнезда: либо
сделать гиперссылкой всю конструкцию#VARIANT, либо превратить в нее только
содержащийся там идентификатор вариантного гнезда. Раскрыв такую гиперссылку, можно
получить список всех сменных модулей, предназначенных для подстановки в вариантное
гнездо, и начать их последовательный просмотр. Полезна и обратная операция,
позволяющая из текста сменного модуля подняться наверх, к его вариантному гнезду, а
точнее, к модулю, содержащему это гнездо.
Для многосвязного вариантного гнезда надо предусмотреть операцию, позволяющую
последовательно обойти все составляющие его односвязные гнезда. Аналогично, для
многосвязного сменного модуля обеспечивается последовательный обход его односвязных
компонентов.
Механизм непосредственной навигации по межмодульным связям играет определенную
консолидирующую роль в формировании программного фонда. В частности,
исключительно важно предоставить разработчику возможность образовывать
гипертекстовые связи между хранящимися в фонде программными материалами и
сопроводительной документацией.
Весьма полезным оказывается механизм непосредственной навигации и для других,