Поделиться

Хранимые в базе данные имеют определенную логическую структуру – модель представления данных, поддерживаемых СУБД. К числу классических относятся:
· иерархическая;
· сетевая;
· реляционная.
В последнее время появились и активно внедряются следующие модели:
· постреляционная;
· многомерная;
· объектно-ориентированная.
В иерархической модели связи между данными можно описать с помощью упорядоченного графа (или дерева). Упрощенно представление связей между данными в иерархической модели показан на рис. 2.1.
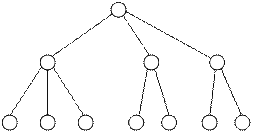
Рис. 2.1. Представление связей в иерархической модели
Для описания структуры на некотором языке программирования используется тип «дерево», который является основным. Он включает в себя подтипы («поддеревья»), каждый из которых, в свою очередь, является типом «дерево». Каждый из типов «дерево» состоит их из одного «корневого» типа и упорядоченного набора (возможно и пустого) подчиненных типов. Каждый из элементарных типов, включенных в тип «дерево», является простым или составным типом «запись». Простая «запись» состоит из одного типа, а составная «запись» объединяет некоторую совокупность типов. Пример типа «дерево» показан на рис. 2.2.
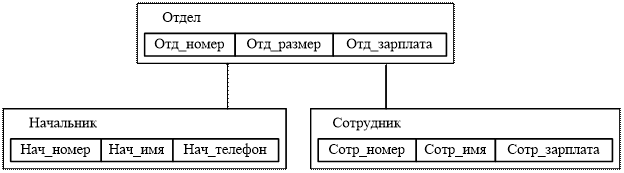
Рис. 2.2. Пример типа «дерево»
Корневым называется тип, который имеет подчиненные типы и сам не является подтипом. Подчиненный тип (подтип) является потомком по отношению к типу, который выступает для него в роли предка (родителя). Потомки одного и того же типа являются близнецами по отношению друг к другу.
В целом тип «дерево» представляет собой иерархически организованный набор типов «запись».
Иерархическая БД представляет собой упорядоченную совокупность экземпляров данных типа «дерево», содержащих экземпляры типа «запись». Обход всех элементов иерархической БД производится сверху вниз или слева направо.
Для организации физического размещения иерархических данных в памяти ЭВМ могут использоваться следующие группы методов:
· представление линейным списком с последовательным распределением памяти;
· представление связными линейными списками.
К основным операциям манипулирования иерархически организованными данными относятся следующие:
· поиск указанного экземпляра БД;
· переход от одного дерева к другому;
· переход от одной записи к другой внутри дерева;
· вставка новой записи в указанную позицию;
· удаление текущей записи и т.д.
В соответствии с определением типа «дерево» между предками и потомками автоматически поддерживается контроль целостности связей. Основное правило: потомок не может существовать без предка, а у некоторых предком может не быть потомков.
Достоинства: эффективное использование памяти ЭВМ и неплохие показатели времени выполнения основных операций над данными.
Недостатки: громоздкость для обработки информации с достаточно сложными логическими связями, сложность понимания для обыкновенного пользователя.
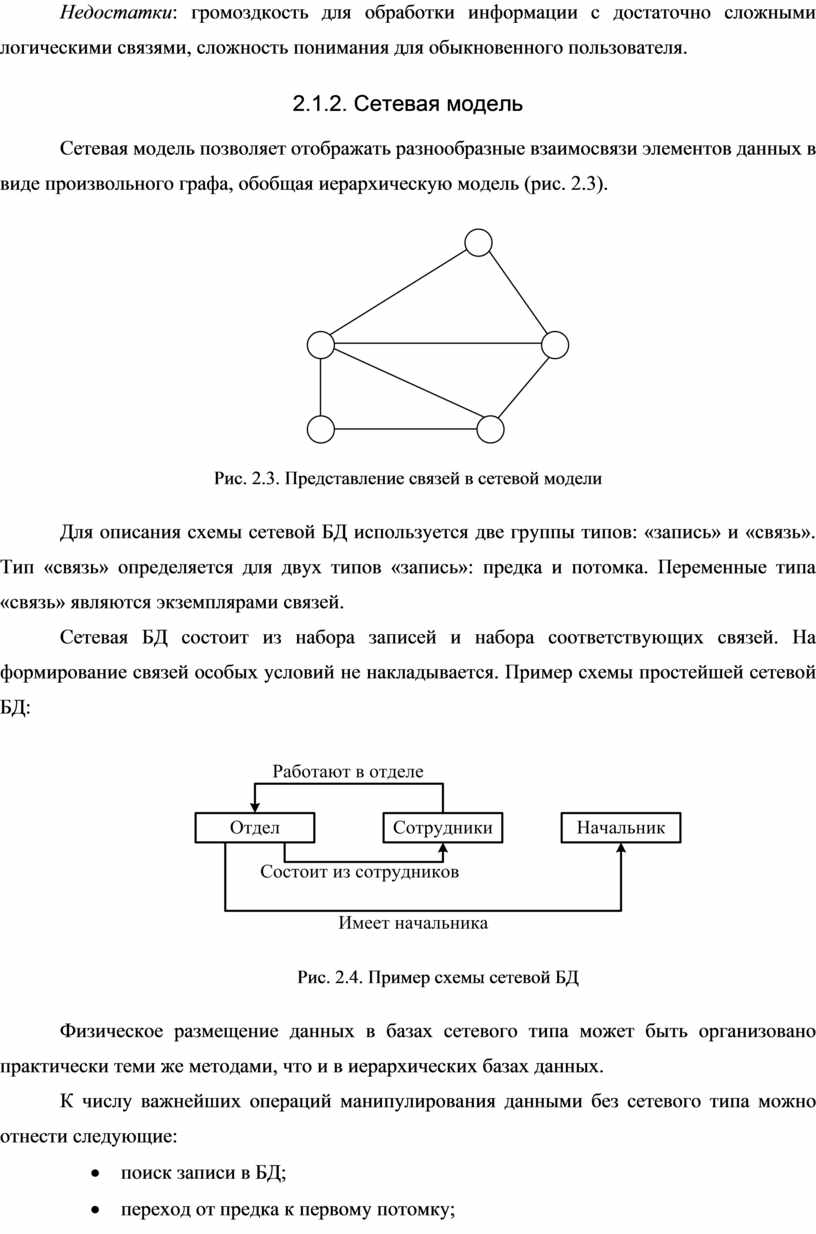
Сетевая модель позволяет отображать разнообразные взаимосвязи элементов данных в виде произвольного графа, обобщая иерархическую модель (рис. 2.3).
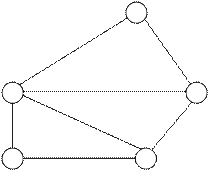
Рис. 2.3. Представление связей в сетевой модели
Для описания схемы сетевой БД используется две группы типов: «запись» и «связь». Тип «связь» определяется для двух типов «запись»: предка и потомка. Переменные типа «связь» являются экземплярами связей.
Сетевая БД состоит из набора записей и набора соответствующих связей. На формирование связей особых условий не накладывается. Пример схемы простейшей сетевой БД:

Рис. 2.4. Пример схемы сетевой БД
Физическое размещение данных в базах сетевого типа может быть организовано практически теми же методами, что и в иерархических базах данных.
К числу важнейших операций манипулирования данными без сетевого типа можно отнести следующие:
· поиск записи в БД;
· переход от предка к первому потомку;
· переход от потомка к предку;
· создание новой записи;
· удаление текущей записи;
· обновление текущей записи;
· включение записи в связь;
· исключение записи из связи;
· изменение связей и т.д.
Достоинства: эффективная реализация по показателям затрат памяти и оперативности.
Недостатки: высокая сложность схемы БД, построенной на ее основе, сложность для понимания, ослаблен показатель целостности связей.
Реляционная модель основывается на понятии отношение.
Отношение представляет собой множество элементов, называемых кортежами. Наглядной формой представления реляционной модели является двумерная таблица.
Таблица имеет строки (записи) и столбцы (колонки). Каждая строка имеет одинаковую структуру и состоит из полей. Строками таблицы соответствуют кортежи, а столбцами – аргументы отношений.
С помощью одной таблицы удобно описывать простейший вид связей между данными, а именно деление одного объекта, информация о котором хранится в таблице, на множество подобъектов, каждому из которых соответствует строка или запись таблицы. При этом каждый их подобъектов имеет одинаковую структуру или свойства, описываемые соответствующими значениями полей записей. Например, журнал группы.
Физическое размещение данных осуществляется с помощью обычных файлов.
Достоинства: простота, удобна в физической реализации на ЭВМ.
Недостатки: отсутствие стандартных средств идентификации отдельных записей, сложность описания иерархических и сетевых связей.
Классическая реляционная модель предполагает неделимость хранимых данных. Существует ряд случаев, когда ограничение на неделимость мешает эффективной работе приложений.
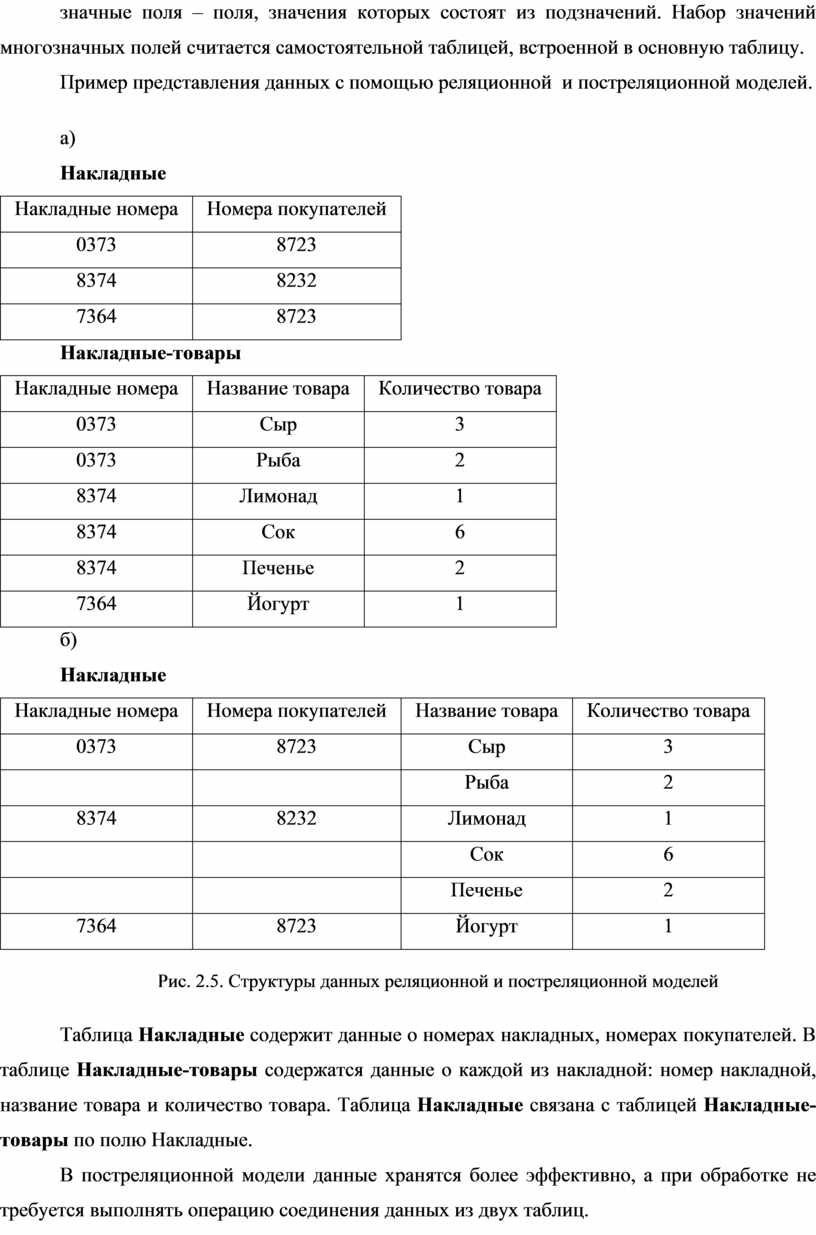
Постреляционная модель представляет собой расширенную реляционную модель, снимающую ограничение неделимости данных. Постреляционная модель допускает многозначные поля – поля, значения которых состоят из подзначений. Набор значений многозначных полей считается самостоятельной таблицей, встроенной в основную таблицу.
Пример представления данных с помощью реляционной и постреляционной моделей.
а)
Накладные
|
Накладные номера |
Номера покупателей |
|
0373 |
8723 |
|
8374 |
8232 |
|
7364 |
8723 |
Накладные-товары
|
Накладные номера |
Название товара |
Количество товара |
|
0373 |
Сыр |
3 |
|
0373 |
Рыба |
2 |
|
8374 |
Лимонад |
1 |
|
8374 |
Сок |
6 |
|
8374 |
Печенье |
2 |
|
7364 |
Йогурт |
1 |
б)
Накладные
|
Накладные номера |
Номера покупателей |
Название товара |
Количество товара |
|
0373 |
8723 |
Сыр |
3 |
|
|
|
Рыба |
2 |
|
8374 |
8232 |
Лимонад |
1 |
|
|
|
Сок |
6 |
|
|
|
Печенье |
2 |
|
7364 |
8723 |
Йогурт |
1 |
Рис. 2.5. Структуры данных реляционной и постреляционной моделей
Таблица Накладные содержит данные о номерах накладных, номерах покупателей. В таблице Накладные-товары содержатся данные о каждой из накладной: номер накладной, название товара и количество товара. Таблица Накладные связана с таблицей Накладные-товары по полю Накладные.
В постреляционной модели данные хранятся более эффективно, а при обработке не требуется выполнять операцию соединения данных из двух таблиц.
Помимо обеспечения вложенности полей постреляционная модель поддерживает ассоциированные многозначные поля. Совокупность ассоциированных полей называется ассоциацией. При этом в строке первое значение одного столбца ассоциации соответствует первым значениям всех других столбцов ассоциации. На длину полей и количество полей не накладывается требование постоянства. Это значит, что структура данных и таблиц имеет большую гибкость.
Так как постреляционная модель допускает хранение в таблицах ненормализованных данных, возникает проблема обеспечения целостности и непротиворечивости данных. Эта проблема решается включением в СУБД механизмов, подобных хранимым процедурам в клиент-серверных системах.
Достоинства: возможность представления совокупности связанных реляционных таблиц одной постреляционной таблицы. Это обеспечивает высокую наглядность представления информации и повышение эффективности ее обработки.
Недостатки: сложность решения проблемы обеспечения целостности и непротиворечивости хранимых данных.
Многомерные СУБД являются узкоспециализированными СУБД, предназначенными для интерактивной аналитической обработки информации.
Агрегируемость данных означает рассмотрение информации на различных уровнях ее обобщения. В информационных системах степень детальности представления информации для пользователя зависит от его уровня: аналитик, пользователь-оператор, руководитель.
Историчность данных предполагает обеспечение высокого уровня статичности собственно данных и их взаимосвязей, а также обязанность привязки данных ко времени.
Статичность данных позволяет использовать при их обработке специализированные методы загрузки, хранения, индексации и выборки.
Временная привязка данных необходима для частого выполнения запросов, имеющих значения времени и даты в составе выборки. Необходимость упорядочения данных по времени в процессе обработки и представления данных пользователю накладывает требования на механизмы хранения и доступа к информации.
Прогнозируемость данных подразумевает задание функций прогнозирования и применение их к различным временным интервалам.
Многомерность модели данных означает не многомерность визуализации цифровых данных, а многомерное логическое представление структуры информации при описании и в операциях манипулирования данными.
Рассмотрим основные понятия многомерных моделей.
Измерение (Dimension) – множество однотипных данных, образующих одну из граней гиперкуба. В многомерной модели данные измерения играют роль индексов, служащих для идентификации конкретных значений в ячейках гиперкуба.
Ячейка (Cell) или показатель – это поле, значение которого однозначно определяется фиксированным набором измерений. Тип поля чаще всего определяется как цифровой. В зависимости от того, как формируются значения некоторой ячейки, обычно она может быть переменной, либо формулой.
В существующих МСУБД используются два основных варианта организации данных: гиперкубическая и поликубическая.
В поликубической схеме предполагается, что в БД может быть определено несколько гиперкубов с различной размерностью и с различными измерениями в качестве граней.
В гиперкубической схеме предполагается, что все показатели определяются одним и тем же набором измерений. Это означает, что при наличии нескольких гиперкубов БД все они имеют одинаковую размерность и совпадающие измерения.
Достоинства: удобство и эффективность аналитической обработки больших объемов данных.
Недостатки: громоздкость для простейших задач.
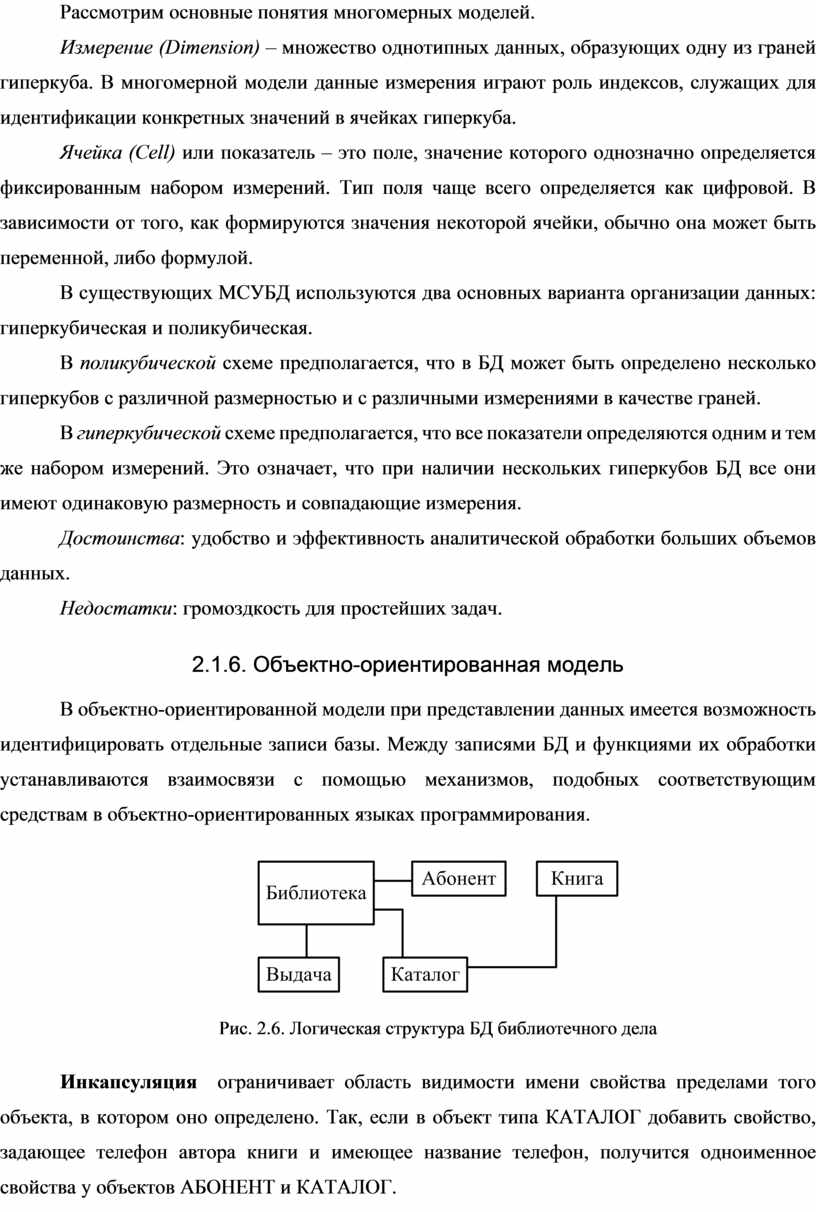
В объектно-ориентированной модели при представлении данных имеется возможность идентифицировать отдельные записи базы. Между записями БД и функциями их обработки устанавливаются взаимосвязи с помощью механизмов, подобных соответствующим средствам в объектно-ориентированных языках программирования.
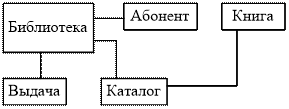
Рис. 2.6. Логическая структура БД библиотечного дела
Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено. Так, если в объект типа КАТАЛОГ добавить свойство, задающее телефон автора книги и имеющее название телефон, получится одноименное свойства у объектов АБОНЕНТ и КАТАЛОГ.
Наследование, распространяет область видимости свойства на всех потомков объекта. Всем объекта типа КНИГА можно приписать свойства объекта-родителя.
Полиморфизм означает способность одного и того же программного кода работать с разнотипными данными. Объекты класса КНИГА, имеющие разных родителей из класса КАТАЛОГ, могут иметь разный набор свойств.
Достоинства: возможность отображения информации о сложных взаимосвязях объектов.
Недостатки: высокая понятийная сложность, неудобство обработки данных и низкая скорость выполнения запросов.
Вернутся в содержание.
Скачано с www.znanio.ru





Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.