Поделиться

Глава 2. Базы данных
Основные понятия
Теория баз данных достаточно хорошо разработана специалистами. Наша задача – взять из нее самые необходимые понятия, способствующие пониманию и грамотному проектированию баз данных.
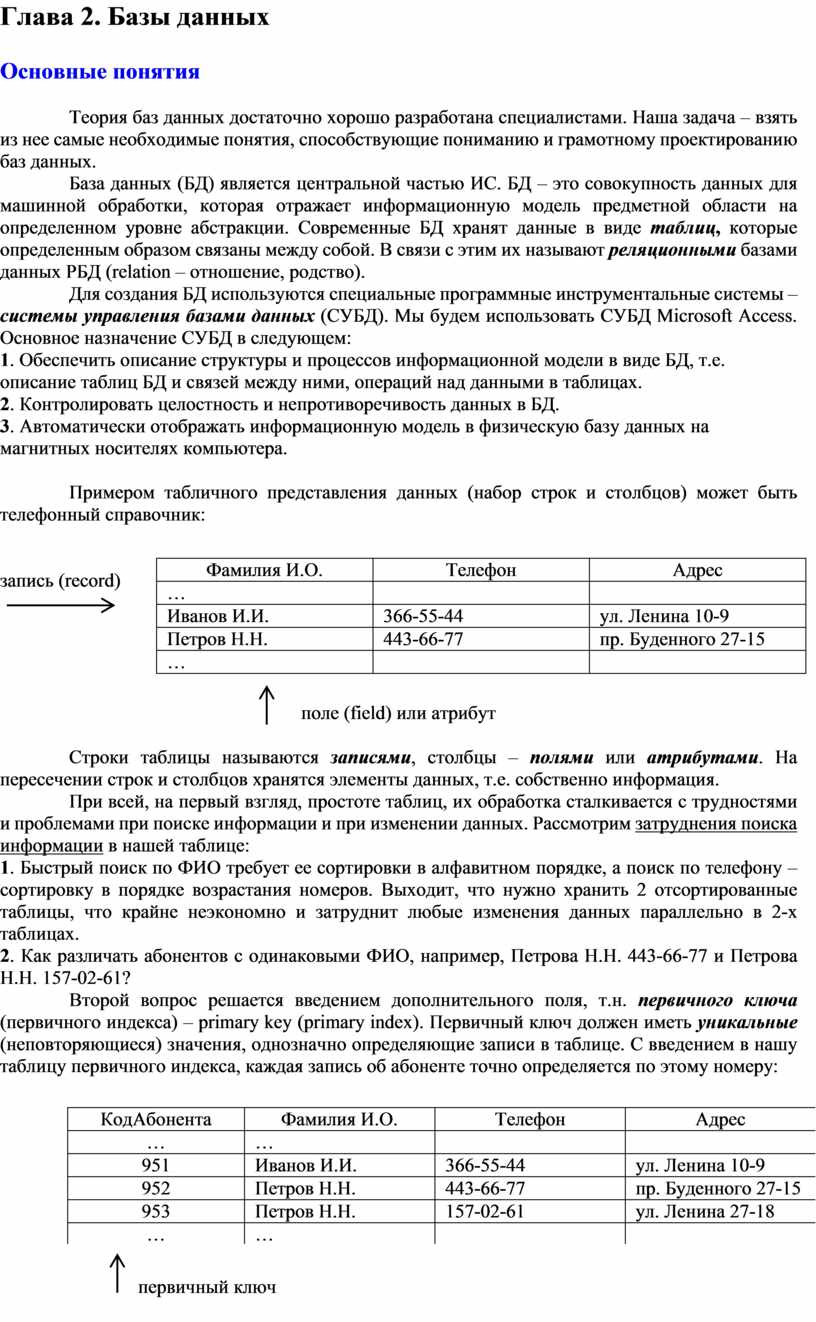
База данных (БД) является центральной частью ИС. БД – это совокупность данных для машинной обработки, которая отражает информационную модель предметной области на определенном уровне абстракции. Современные БД хранят данные в виде таблиц, которые определенным образом связаны между собой. В связи с этим их называют реляционными базами данных РБД (relation – отношение, родство).
Для создания БД используются специальные программные инструментальные системы – системы управления базами данных (СУБД). Мы будем использовать СУБД Microsoft Access. Основное назначение СУБД в следующем:
1. Обеспечить описание структуры и процессов информационной модели в виде БД, т.е. описание таблиц БД и связей между ними, операций над данными в таблицах.
2. Контролировать целостность и непротиворечивость данных в БД.
3. Автоматически отображать информационную модель в физическую базу данных на магнитных носителях компьютера.
![]() Примером
табличного представления данных (набор строк и столбцов) может быть телефонный
справочник:
Примером
табличного представления данных (набор строк и столбцов) может быть телефонный
справочник:
|
запись (record)
поле (field) или атрибут
Строки таблицы называются записями, столбцы – полями или атрибутами. На пересечении строк и столбцов хранятся элементы данных, т.е. собственно информация.
При всей, на первый взгляд, простоте таблиц, их обработка сталкивается с трудностями и проблемами при поиске информации и при изменении данных. Рассмотрим затруднения поиска информации в нашей таблице:
1. Быстрый поиск по ФИО требует ее сортировки в алфавитном порядке, а поиск по телефону – сортировку в порядке возрастания номеров. Выходит, что нужно хранить 2 отсортированные таблицы, что крайне неэкономно и затруднит любые изменения данных параллельно в 2-х таблицах.
2. Как различать абонентов с одинаковыми ФИО, например, Петрова Н.Н. 443-66-77 и Петрова Н.Н. 157-02-61?
Второй вопрос решается введением дополнительного поля, т.н. первичного ключа (первичного индекса) – primary key (primary index). Первичный ключ должен иметь уникальные (неповторяющиеся) значения, однозначно определяющие записи в таблице. С введением в нашу таблицу первичного индекса, каждая запись об абоненте точно определяется по этому номеру:

первичный ключ
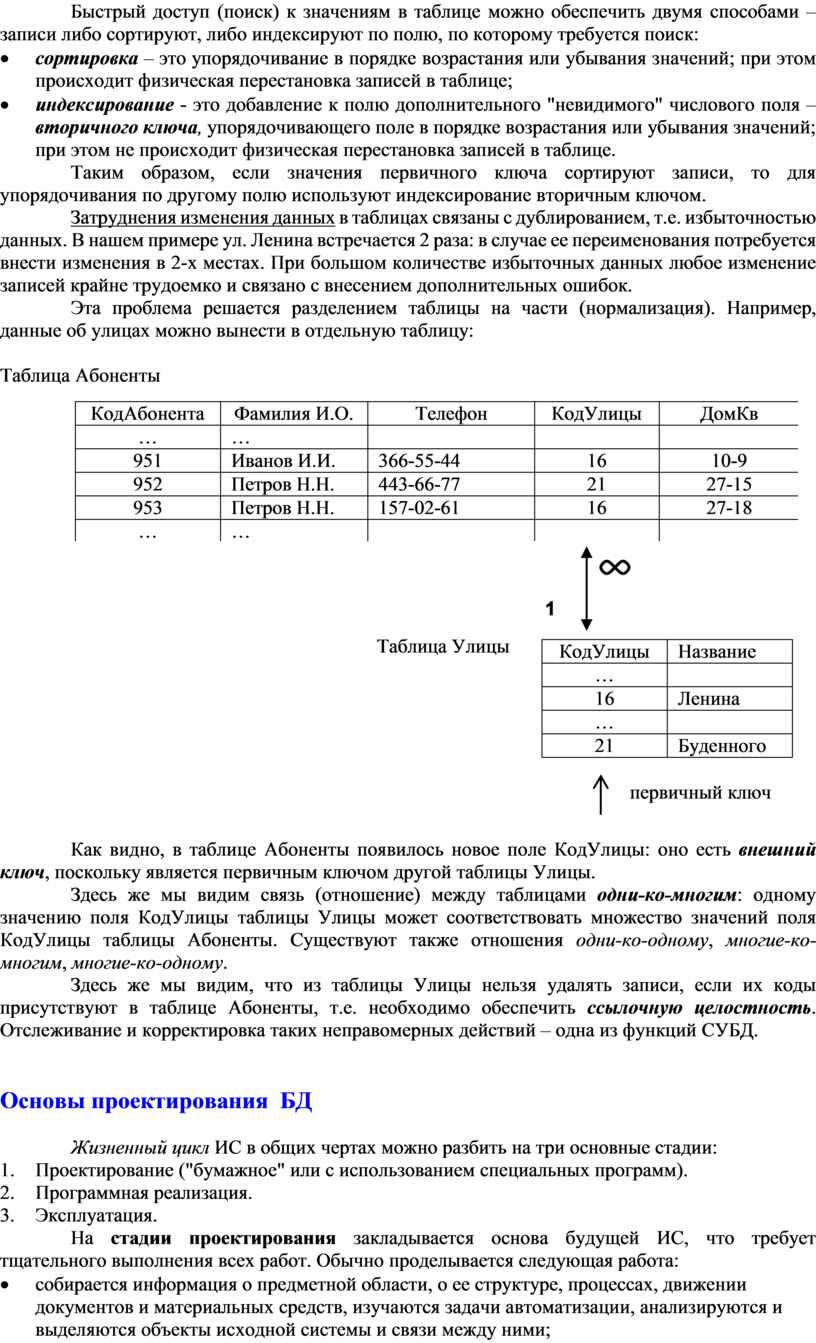
Быстрый доступ (поиск) к значениям в таблице можно обеспечить двумя способами – записи либо сортируют, либо индексируют по полю, по которому требуется поиск:
· сортировка – это упорядочивание в порядке возрастания или убывания значений; при этом происходит физическая перестановка записей в таблице;
· индексирование - это добавление к полю дополнительного "невидимого" числового поля – вторичного ключа, упорядочивающего поле в порядке возрастания или убывания значений; при этом не происходит физическая перестановка записей в таблице.
Таким образом, если значения первичного ключа сортируют записи, то для упорядочивания по другому полю используют индексирование вторичным ключом.
Затруднения изменения данных в таблицах связаны с дублированием, т.е. избыточностью данных. В нашем примере ул. Ленина встречается 2 раза: в случае ее переименования потребуется внести изменения в 2-х местах. При большом количестве избыточных данных любое изменение записей крайне трудоемко и связано с внесением дополнительных ошибок.
Эта проблема решается разделением таблицы на части (нормализация). Например, данные об улицах можно вынести в отдельную таблицу:
Таблица Абоненты
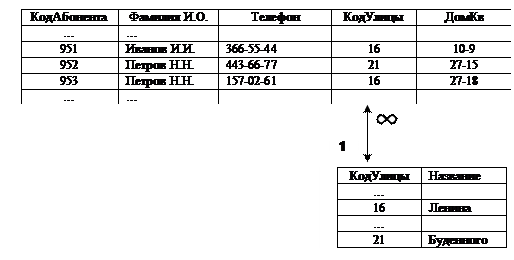 |
Таблица Улицы
Как видно, в таблице Абоненты появилось новое поле КодУлицы: оно есть внешний ключ, поскольку является первичным ключом другой таблицы Улицы.
Здесь же мы видим связь (отношение) между таблицами одни-ко-многим: одному значению поля КодУлицы таблицы Улицы может соответствовать множество значений поля КодУлицы таблицы Абоненты. Существуют также отношения одни-ко-одному, многие-ко-многим, многие-ко-одному.
Здесь же мы видим, что из таблицы Улицы нельзя удалять записи, если их коды присутствуют в таблице Абоненты, т.е. необходимо обеспечить ссылочную целостность. Отслеживание и корректировка таких неправомерных действий – одна из функций СУБД.
Основы проектирования БД
Жизненный цикл ИС в общих чертах можно разбить на три основные стадии:
1. Проектирование ("бумажное" или с использованием специальных программ).
2. Программная реализация.
3. Эксплуатация.
На стадии проектирования закладывается основа будущей ИС, что требует тщательного выполнения всех работ. Обычно проделывается следующая работа:
· собирается информация о предметной области, о ее структуре, процессах, движении документов и материальных средств, изучаются задачи автоматизации, анализируются и выделяются объекты исходной системы и связи между ними;
· для каждого объекта выясняются свойства и характеристики, которым назначаются поля (атрибуты), составляются исходные таблицы (отношения) БД;
· для каждого объекта назначаются первичные ключи (поля) и проводится нормализация (разбиение, декомпозиция) исходных таблиц;
· проверяется корректность проекта; проект (все выделенные объекты, их атрибуты и описываемые процессы) должен адекватно, на требуемом уровне детальности, отображать предметную область, требующие решения задачи.
Стадия реализации связана с разработкой приложения на компьютере. Необходимо выполнить следующие основные пункты:
· описать полученные таблицы средствами СУБД и ввести их в компьютер:
· для пользователей ИС разработать интерфейсы работы с БД, т.е. экранные формы для ввода и отображения данных, отчеты для печати сводных данных на бумагу, запросы для отбора данных, макросы и подпрограммы, обеспечивающие выполнение всех функций приложения;
· выработать порядок (технологию) ведения и поддержания базы данных в рабочем состоянии, работы конечных пользователей;
· заполнить ИС отладочными данными и отладить ее, провести тестирование, составить инструкции по работе с ИС и обучить персонал.
Стадия эксплуатации начинается с наполнения ИС реальными данными, после чего происходит непосредственно ее использование, при необходимости доработка. Сопровождение ИС здесь играет важную роль, поскольку развитие и изменение предметной области в реальной жизни всегда требует совершенствования ИС и разработку новых приложений.
При разработке крупных интегрированных систем управления предприятием присутствует стадия моделирования и анализа предметной области. Она выполняется с использованием специальных программных средств (CASE средств), которые позволяют промоделировать (построить диаграммы) потоки данных, процессы и функции предприятия, выявить узкие места и дать рекомендации по эффективной организации структуры и бизнес процессов на предприятии. К таким средствам моделирования относятся Bpwin (для непрограммистов) и Erwin (для программистов) компании Platinum/Logic Works, Rational Rose фирмы Rational Software, ARIS компании IDS Sheer AG и другие.
Кроме построения моделей текущего состояния предприятия и анализа, программные средства моделирования позволяют сформировать спецификации и построить проект будущей ИС. Более того, может быть получен программный код для наиболее распространенных СУБД. Таким образом, стадия моделирования может захватывать этап проектирования и часть этапа реализации ИС.
Отметим также, что при коммерческой разработке ИС под заказ возникает ряд дополнительных организационных мероприятий и необходимость документальной фиксации обязательств и действий в виде договоров, приложений, технического задания, технического проекта, спецификаций, актов этапов выполнения, документов об оплате и т.д.
Нормализация БД
Нормализация является ответственной частью стадии проектирования ИС, поскольку позволяет привести исходные таблицы к виду для наиболее эффективной обработки в будущем. Нормализация это пошаговый процесс разбиения исходных таблиц на более простые, которые должны удовлетворять 2-м основных требованиям:
· между полями таблицы не должно быть нежелательных функциональных зависимостей;
· группировка полей в таблицах должна обеспечивать минимальное дублирование данных, эффективный (без трудностей) поиск, обработку и обновление данных.
Сегодня определено 5 основных нормальных форм (НФ). Каждая НФ снимает определенные зависимости между полями и устраняет определенные трудности обработки данных.
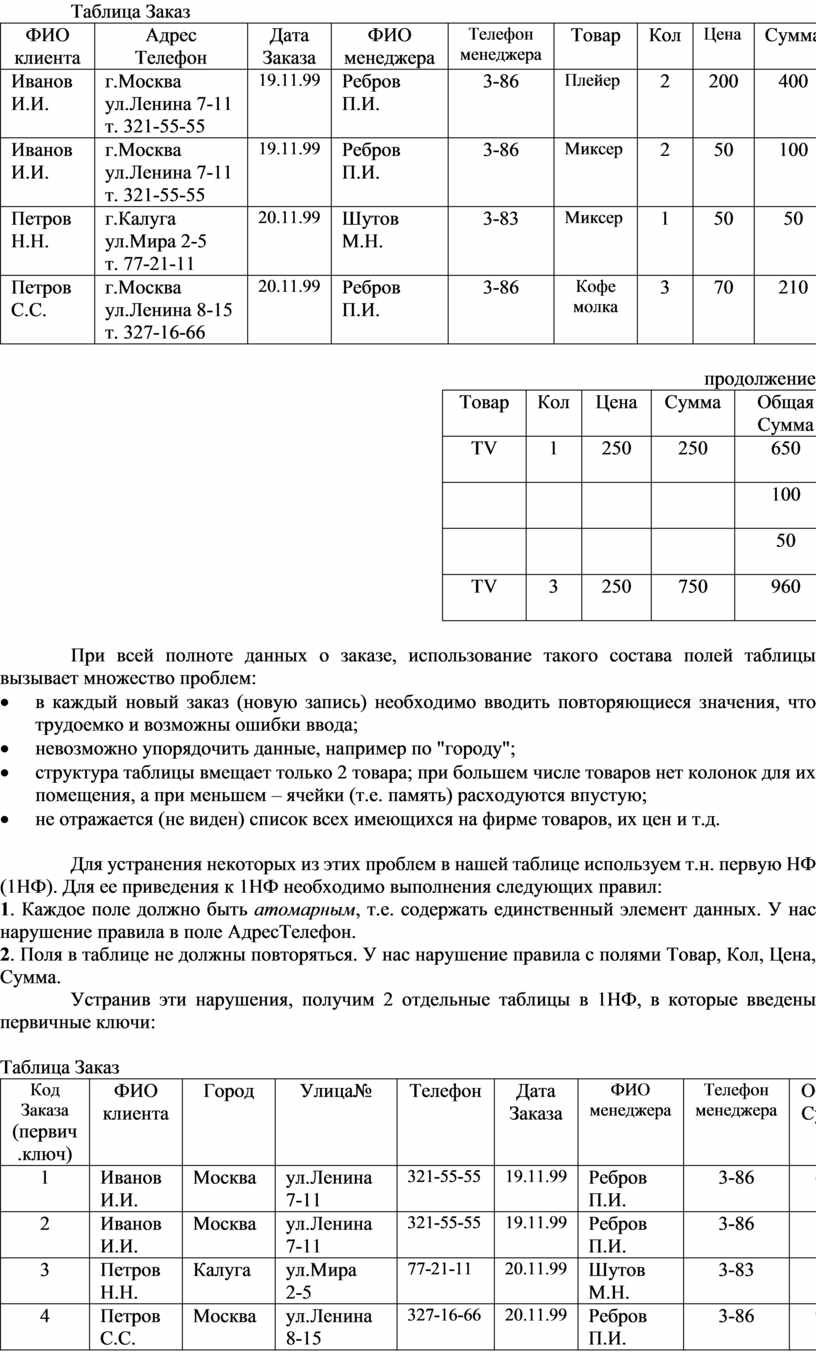
Процесс нормализации разберем на следующем примере. Этот пример будет реализован далее средствами СУБД Access в виде учебной информационной системе "Заказы". Пусть существует некоторая фирма, торгующая некоторым товаром по заказам. Составим таблицу для размещения заказа от клиента, как это обычно делается в электронной таблице Excel:
Таблица Заказ
|
ФИО клиента |
Адрес Телефон |
Дата Заказа |
ФИО менеджера |
Телефон менеджера |
Товар |
Кол |
Цена |
Сумма |
|
Иванов И.И. |
г.Москва ул.Ленина 7-11 т. 321-55-55 |
19.11.99 |
Ребров П.И. |
3-86 |
Плейер |
2 |
200 |
400 |
|
Иванов И.И. |
г.Москва ул.Ленина 7-11 т. 321-55-55 |
19.11.99 |
Ребров П.И. |
3-86 |
Миксер |
2 |
50 |
100 |
|
Петров Н.Н. |
г.Калуга ул.Мира 2-5 т. 77-21-11 |
20.11.99 |
Шутов М.Н. |
3-83 |
Миксер |
1 |
50 |
50 |
|
Петров С.С. |
г.Москва ул.Ленина 8-15 т. 327-16-66 |
20.11.99 |
Ребров П.И. |
3-86 |
Кофе молка |
3 |
70 |
210 |
продолжение
|
Товар |
Кол |
Цена |
Сумма |
Общая Сумма |
|
TV |
1 |
250 |
250 |
650
|
|
|
|
|
|
100
|
|
|
|
|
|
50
|
|
TV |
3 |
250 |
750 |
960
|
При всей полноте данных о заказе, использование такого состава полей таблицы вызывает множество проблем:
· в каждый новый заказ (новую запись) необходимо вводить повторяющиеся значения, что трудоемко и возможны ошибки ввода;
· невозможно упорядочить данные, например по "городу";
· структура таблицы вмещает только 2 товара; при большем числе товаров нет колонок для их помещения, а при меньшем – ячейки (т.е. память) расходуются впустую;
· не отражается (не виден) список всех имеющихся на фирме товаров, их цен и т.д.
Для устранения некоторых из этих проблем в нашей таблице используем т.н. первую НФ (1НФ). Для ее приведения к 1НФ необходимо выполнения следующих правил:
1. Каждое поле должно быть атомарным, т.е. содержать единственный элемент данных. У нас нарушение правила в поле АдресТелефон.
2. Поля в таблице не должны повторяться. У нас нарушение правила с полями Товар, Кол, Цена, Сумма.
Устранив эти нарушения, получим 2 отдельные таблицы в 1НФ, в которые введены первичные ключи:
Таблица Заказ
|
Код Заказа (первич.ключ) |
ФИО клиента |
Город |
Улица№ |
Телефон |
Дата Заказа |
ФИО менеджера |
Телефон менеджера |
ОбщаяСумма |
|
1 |
Иванов И.И. |
Москва |
ул.Ленина 7-11 |
321-55-55 |
19.11.99 |
Ребров П.И. |
3-86 |
650
|
|
2 |
Иванов И.И. |
Москва |
ул.Ленина 7-11 |
321-55-55 |
19.11.99 |
Ребров П.И. |
3-86 |
100
|
|
3 |
Петров Н.Н. |
Калуга |
ул.Мира 2-5 |
77-21-11 |
20.11.99 |
Шутов М.Н. |
3-83 |
50
|
|
4 |
Петров С.С. |
Москва |
ул.Ленина 8-15 |
327-16-66 |
20.11.99 |
Ребров П.И. |
3-86 |
960
|
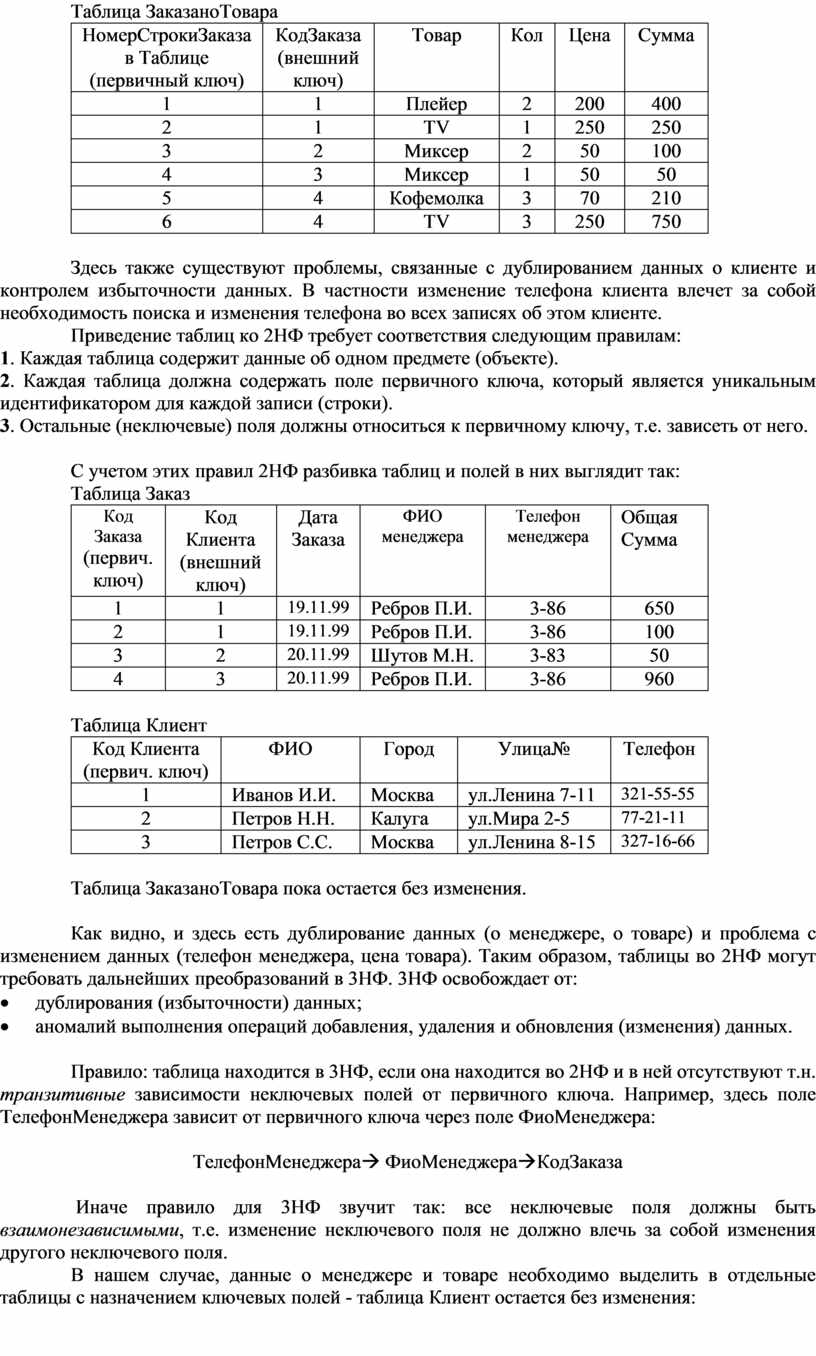
Таблица ЗаказаноТовара
|
НомерСтрокиЗаказа в Таблице (первичный ключ) |
КодЗаказа (внешний ключ) |
Товар |
Кол |
Цена |
Сумма |
|
1 |
1 |
Плейер |
2 |
200 |
400 |
|
2 |
1 |
TV |
1 |
250 |
250 |
|
3 |
2 |
Миксер |
2 |
50 |
100 |
|
4 |
3 |
Миксер |
1 |
50 |
50 |
|
5 |
4 |
Кофемолка |
3 |
70 |
210 |
|
6 |
4 |
TV |
3 |
250 |
750 |
Здесь также существуют проблемы, связанные с дублированием данных о клиенте и контролем избыточности данных. В частности изменение телефона клиента влечет за собой необходимость поиска и изменения телефона во всех записях об этом клиенте.
Приведение таблиц ко 2НФ требует соответствия следующим правилам:
1. Каждая таблица содержит данные об одном предмете (объекте).
2. Каждая таблица должна содержать поле первичного ключа, который является уникальным идентификатором для каждой записи (строки).
3. Остальные (неключевые) поля должны относиться к первичному ключу, т.е. зависеть от него.
С учетом этих правил 2НФ разбивка таблиц и полей в них выглядит так:
Таблица Заказ
|
Код Заказа (первич.ключ) |
Код Клиента (внешний ключ) |
Дата Заказа |
ФИО менеджера |
Телефон менеджера |
Общая Сумма |
|
|
1 |
1 |
19.11.99 |
Ребров П.И. |
3-86 |
650 |
|
|
2 |
1 |
19.11.99 |
Ребров П.И. |
3-86 |
100 |
|
|
3 |
2 |
20.11.99 |
Шутов М.Н. |
3-83 |
50 |
|
|
4 |
3 |
20.11.99 |
Ребров П.И. |
3-86 |
960 |
|
Таблица Клиент
|
Код Клиента (первич. ключ) |
ФИО
|
Город |
Улица№ |
Телефон |
|
1 |
Иванов И.И. |
Москва |
ул.Ленина 7-11 |
321-55-55 |
|
2 |
Петров Н.Н. |
Калуга |
ул.Мира 2-5 |
77-21-11 |
|
3 |
Петров С.С. |
Москва |
ул.Ленина 8-15 |
327-16-66 |
Таблица ЗаказаноТовара пока остается без изменения.
Как видно, и здесь есть дублирование данных (о менеджере, о товаре) и проблема с изменением данных (телефон менеджера, цена товара). Таким образом, таблицы во 2НФ могут требовать дальнейших преобразований в 3НФ. 3НФ освобождает от:
· дублирования (избыточности) данных;
· аномалий выполнения операций добавления, удаления и обновления (изменения) данных.
Правило: таблица находится в 3НФ, если она находится во 2НФ и в ней отсутствуют т.н. транзитивные зависимости неключевых полей от первичного ключа. Например, здесь поле ТелефонМенеджера зависит от первичного ключа через поле ФиоМенеджера:
ТелефонМенеджераà ФиоМенеджераàКодЗаказа
Иначе правило для 3НФ звучит так: все неключевые поля должны быть взаимонезависимыми, т.е. изменение неключевого поля не должно влечь за собой изменения другого неключевого поля.
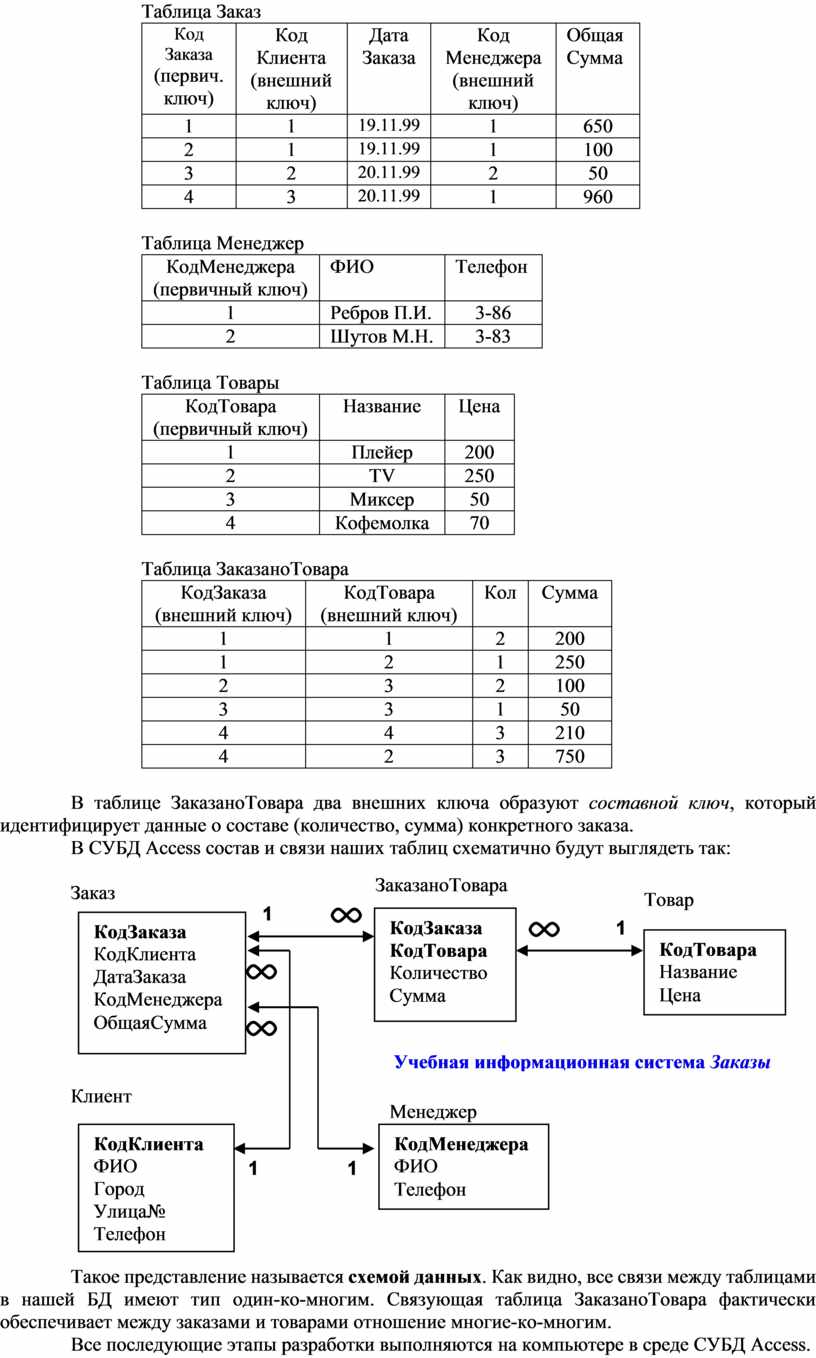
В нашем случае, данные о менеджере и товаре необходимо выделить в отдельные таблицы с назначением ключевых полей - таблица Клиент остается без изменения:
Таблица Заказ
|
Код Заказа (первич.ключ) |
Код Клиента (внешний ключ) |
Дата Заказа |
Код Менеджера (внешний ключ) |
Общая Сумма |
|
1 |
1 |
19.11.99 |
1 |
650 |
|
2 |
1 |
19.11.99 |
1 |
100 |
|
3 |
2 |
20.11.99 |
2 |
50 |
|
4 |
3 |
20.11.99 |
1 |
960 |
Таблица Менеджер
|
КодМенеджера (первичный ключ) |
ФИО |
Телефон |
|
1 |
Ребров П.И. |
3-86 |
|
2 |
Шутов М.Н. |
3-83 |
Таблица Товары
|
КодТовара (первичный ключ) |
Название |
Цена |
|
1 |
Плейер |
200 |
|
2 |
TV |
250 |
|
3 |
Миксер |
50 |
|
4 |
Кофемолка |
70 |
Таблица ЗаказаноТовара
|
КодЗаказа (внешний ключ) |
КодТовара (внешний ключ) |
Кол |
Сумма |
|
1 |
1 |
2 |
200 |
|
1 |
2 |
1 |
250 |
|
2 |
3 |
2 |
100 |
|
3 |
3 |
1 |
50 |
|
4 |
4 |
3 |
210 |
|
4 |
2 |
3 |
750 |
В таблице ЗаказаноТовара два внешних ключа образуют составной ключ, который идентифицирует данные о составе (количество, сумма) конкретного заказа.
В СУБД Access состав и связи наших таблиц схематично будут выглядеть так:
|
|||
|
|||
1
Заказ
 |
Менеджер
Клиент
 |
 |
||
Такое представление называется схемой данных. Как видно, все связи между таблицами в нашей БД имеют тип один-ко-многим. Связующая таблица ЗаказаноТовара фактически обеспечивает между заказами и товарами отношение многие-ко-многим.
Все последующие этапы разработки выполняются на компьютере в среде СУБД Access.
Пример проектирования упрощенного фрагмента
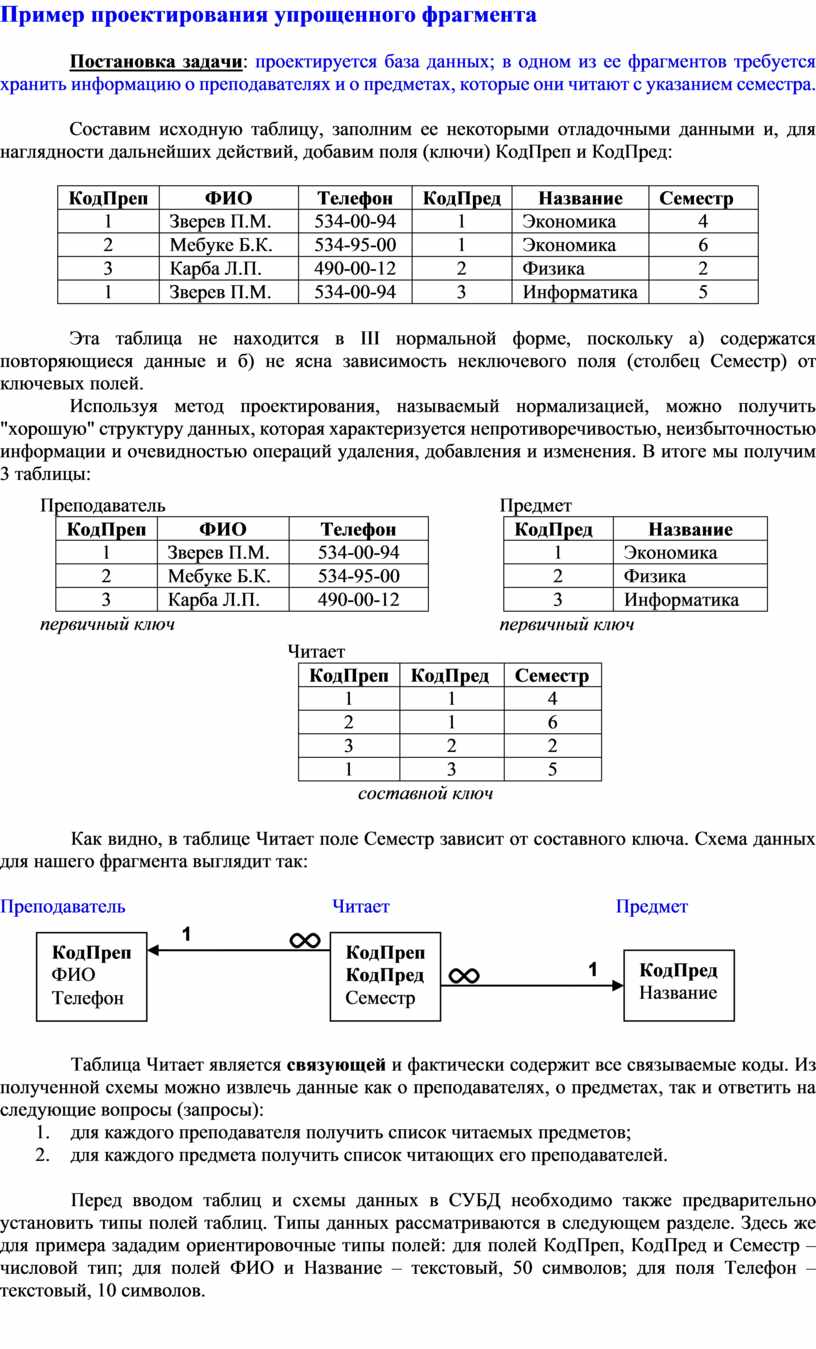
Постановка задачи: проектируется база данных; в одном из ее фрагментов требуется хранить информацию о преподавателях и о предметах, которые они читают с указанием семестра.
Составим исходную таблицу, заполним ее некоторыми отладочными данными и, для наглядности дальнейших действий, добавим поля (ключи) КодПреп и КодПред:
|
КодПреп |
ФИО |
Телефон |
КодПред |
Название |
Семестр |
|
1 |
Зверев П.М. |
534-00-94 |
1 |
Экономика |
4 |
|
2 |
Мебуке Б.К. |
534-95-00 |
1 |
Экономика |
6 |
|
3 |
Карба Л.П. |
490-00-12 |
2 |
Физика |
2 |
|
1 |
Зверев П.М. |
534-00-94 |
3 |
Информатика |
5 |
Эта таблица не находится в III нормальной форме, поскольку а) содержатся повторяющиеся данные и б) не ясна зависимость неключевого поля (столбец Семестр) от ключевых полей.
 Используя
метод проектирования, называемый нормализацией, можно получить
"хорошую" структуру данных, которая характеризуется
непротиворечивостью, неизбыточностью информации и очевидностью операций
удаления, добавления и изменения. В итоге мы получим 3 таблицы:
Используя
метод проектирования, называемый нормализацией, можно получить
"хорошую" структуру данных, которая характеризуется
непротиворечивостью, неизбыточностью информации и очевидностью операций
удаления, добавления и изменения. В итоге мы получим 3 таблицы:


ФИО Телефон
Как видно, в таблице Читает поле Семестр зависит от составного ключа.
Схема данных для нашего фрагмента выглядит так:
КодПреп
1
Преподаватель
Читает Предмет
 |
Таблица Читает является связующей и фактически содержит все связываемые коды. Из полученной схемы можно извлечь данные как о преподавателях, о предметах, так и ответить на следующие вопросы (запросы):
1. для каждого преподавателя получить список читаемых предметов;
2. для каждого предмета получить список читающих его преподавателей.
Перед вводом таблиц и схемы данных в СУБД необходимо также предварительно установить типы полей таблиц. Типы данных рассматриваются в следующем разделе. Здесь же для примера зададим ориентировочные типы полей: для полей КодПреп, КодПред и Семестр – числовой тип; для полей ФИО и Название – текстовый, 50 символов; для поля Телефон – текстовый, 10 символов.
ER-метод
Нелишне упомянуть еще один метод проектирования, называемый ER-методом. ER-метод многим может показаться ближе для восприятия и использования на начальных этапах проектирования, поскольку использует наглядное графическое представление структуры информации о предметной области. К тому же он широко используется в средствах программного моделирования информационных систем.
ER-метод использует схемы "сущность-связь" (entity-relationship, ER), из которых получают итоговые таблицы в требуемых нормальных формах. Сущности, есть объекты, о которых следует хранить информацию. В предыдущем примере сущностями являются объекты Преподаватель и Предмет. Они связаны связью Читает, т.е. можно составить предложение Преподаватель Читает Предмет.
Сущности и связи изображают графически с помощью ER-диаграмм
|
||||||||
|
||||||||
![]()
![]()
![]()
![]()
![]()
![]() Читает
Читает
и диаграмм ER-экземпляров:
Преподаватель Читает Предмет
|

 |
Как видно, ER-диаграмма соответствует полученной в предыдущем примере схеме данных. Связь Читает обеспечивает между сущностями отношение многие-ко-многим, т.е. преподаватель может читать несколько предметов, а предмет может читаться несколькими преподавателями. На основе ER-диаграмм получают нормализованные таблицы (как, здесь не рассматривается): каждая сущность и каждая связь выделяется в отдельную таблицу. Таблица, отражающая сущность, хранит экземпляры сущности, т.е. записи. Свойства сущности, называемые атрибутами, хранятся в полях (столбцах) сущность-таблицы. Таблица, отражающая связь, хранит связи между конкретными экземплярами сущностей.
В заключении в обобщенном виде изобразим последовательность этапов реализации в Access приложения с базой данных:
|
Этап 1 |
Этап 2 |
Этап 3 |
Этап 4 |
Этап 5 |
|
Обследование предметной области, постановка задачи, подготовка технического задания |
Получение исходных таблиц (выделение объектов, их свойств, связей). Нормализация таблиц. |
Определение типов полей и ввод описаний таблиц. Создание схемы данных. Ввод первичных отладочных данных. |
Определение всех форм, отчетов, запросов, макросов, модулей, их конструирование и отладка. |
Сборка форм, отчетов в единую систему, тестирование на отладочных данных, настройка системы. Подготовка руководства для пользователя. |
|
Выполняется на бумаге |
Выполняется на бумаге или с использованием CASE-средств |
Выполняется на компьютере |
Выполняется на компьютере |
Выполняется на компьютере |


Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.
