Поделиться

Расчет кластерного анализа в среде STATISTICA 6.0.
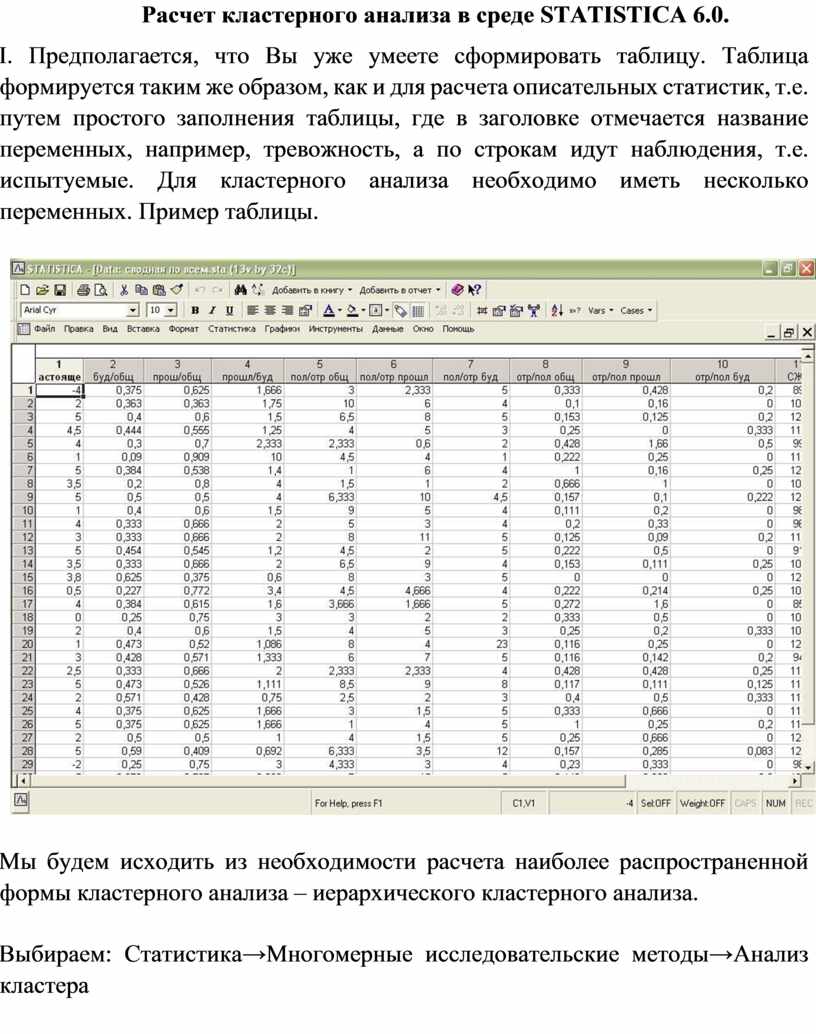
І. Предполагается, что Вы уже умеете сформировать таблицу. Таблица формируется таким же образом, как и для расчета описательных статистик, т.е. путем простого заполнения таблицы, где в заголовке отмечается название переменных, например, тревожность, а по строкам идут наблюдения, т.е. испытуемые. Для кластерного анализа необходимо иметь несколько переменных. Пример таблицы.
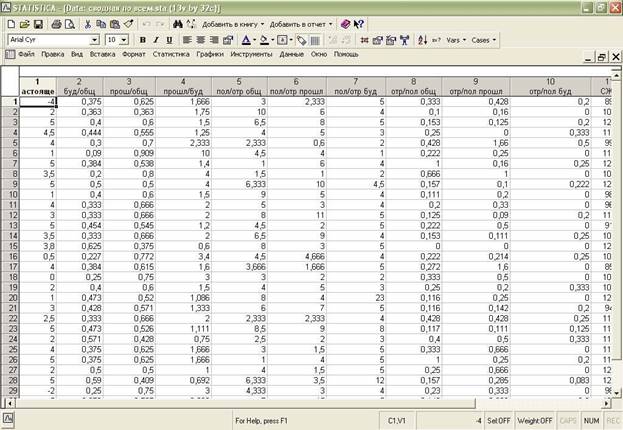
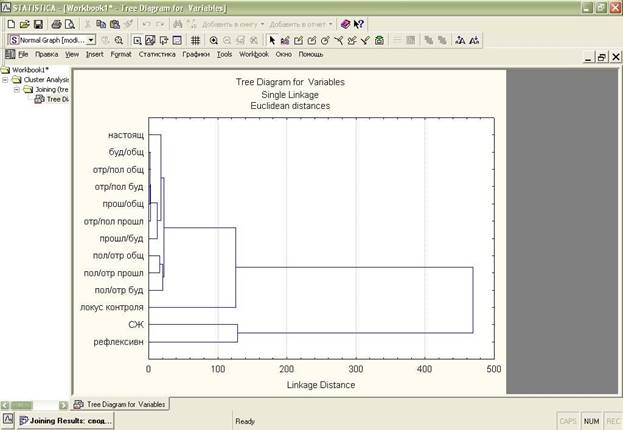
Мы будем исходить из необходимости расчета наиболее распространенной формы кластерного анализа – иерархического кластерного анализа.
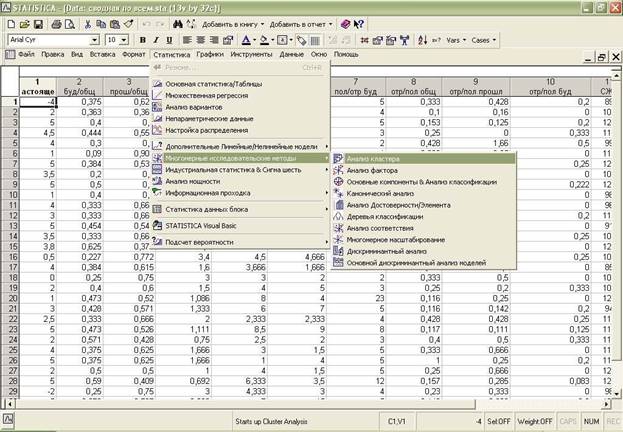
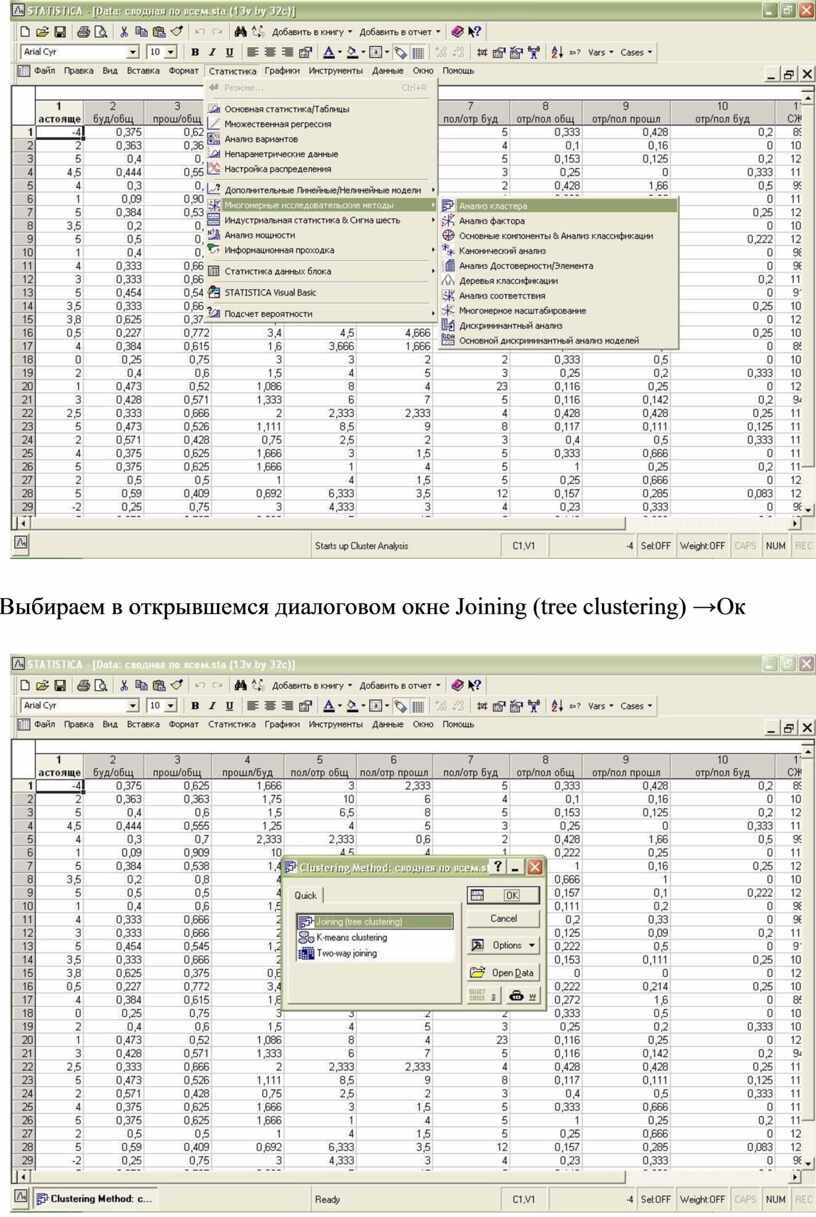
Выбираем: Статистика→Многомерные исследовательские методы→Анализ кластера
Выбираем в открывшемся диалоговом окне Joining (tree clustering) →Ок
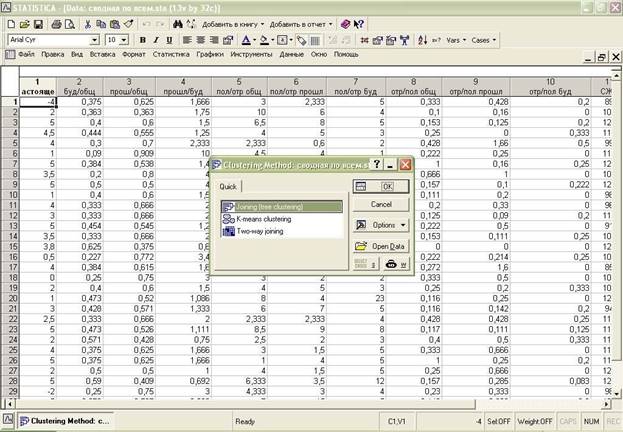
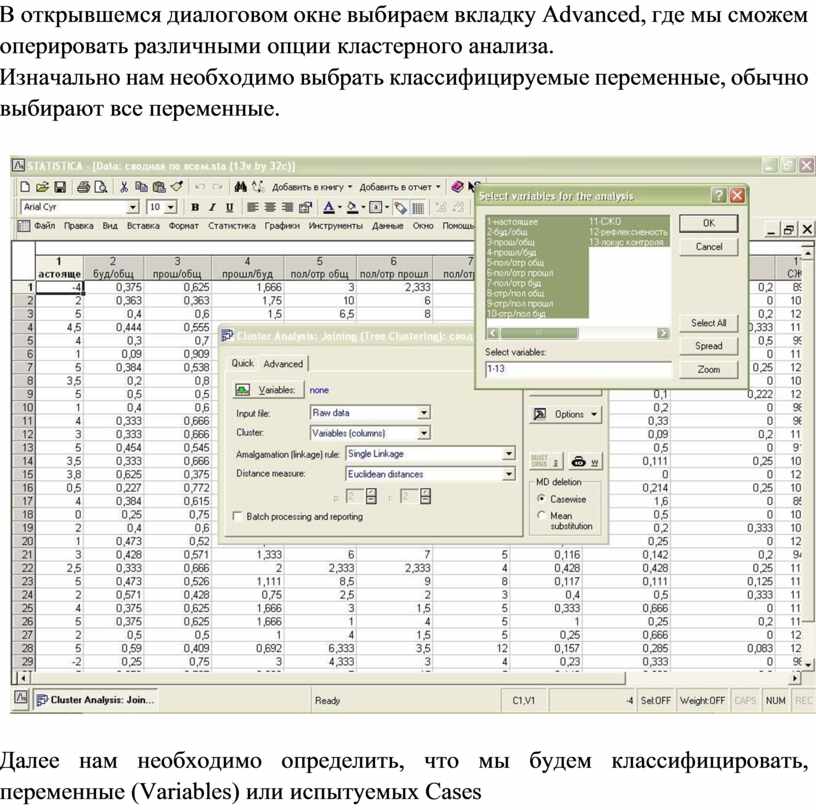
В открывшемся диалоговом окне выбираем вкладку Advanced, где мы сможем оперировать различными опции кластерного анализа.
Изначально нам необходимо выбрать классифицируемые переменные, обычно выбирают все переменные.
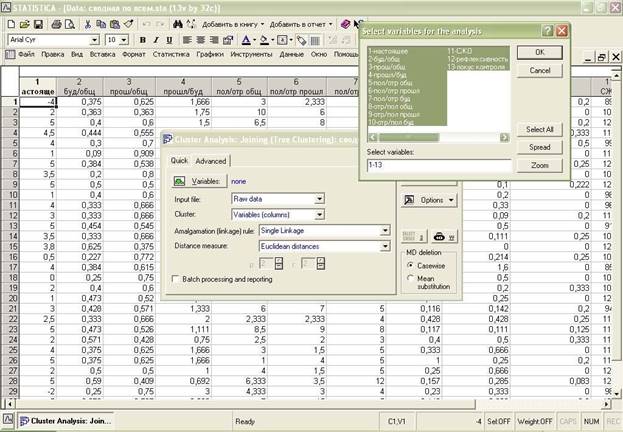
Далее нам необходимо определить, что мы будем классифицировать, переменные (Variables) или испытуемых Cases
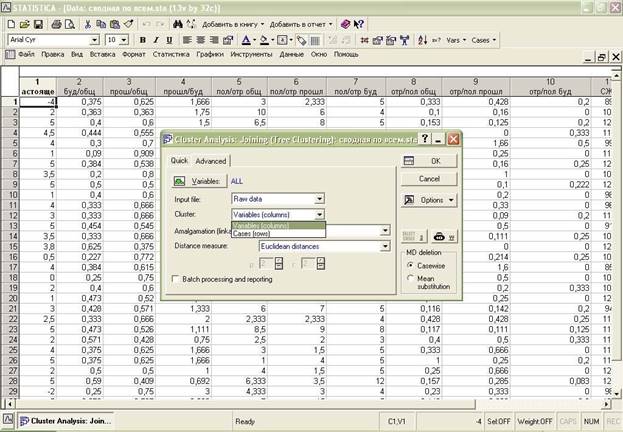
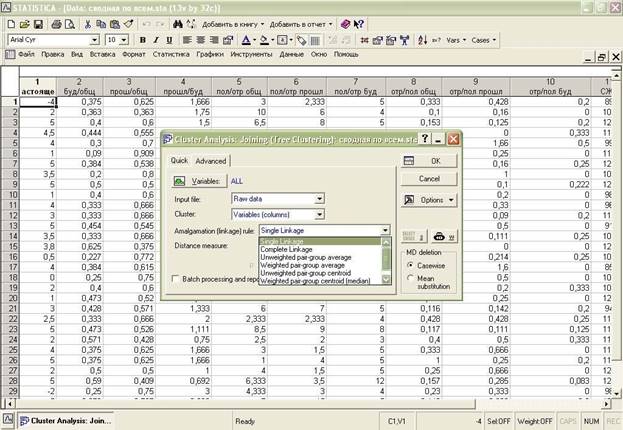
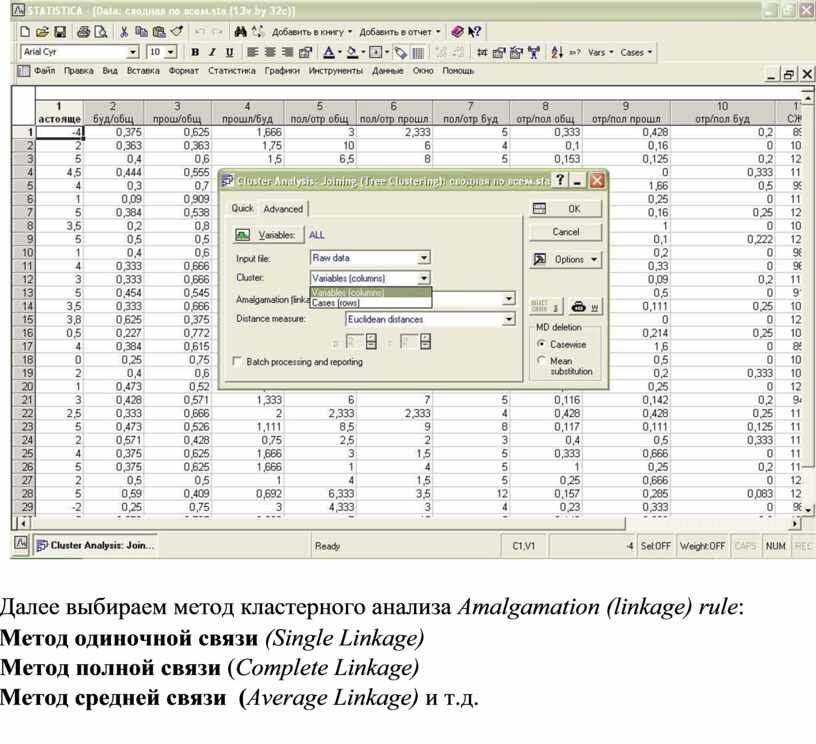
Далее выбираем метод кластерного анализа Amalgamation (linkage) rule:
Метод одиночной связи (Single Linkage) Метод полной связи (Complete Linkage)
Метод средней связи (Average Linkage) и т.д.
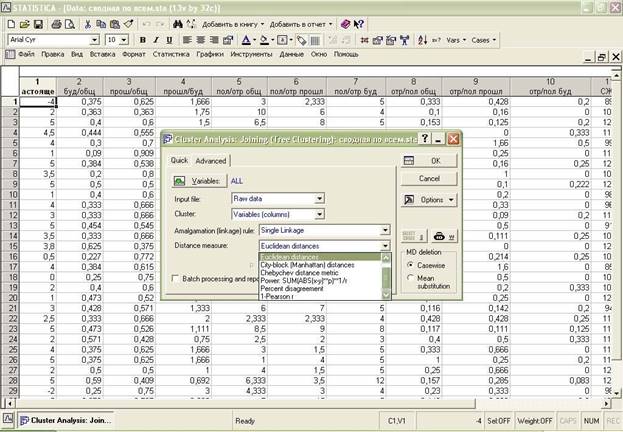
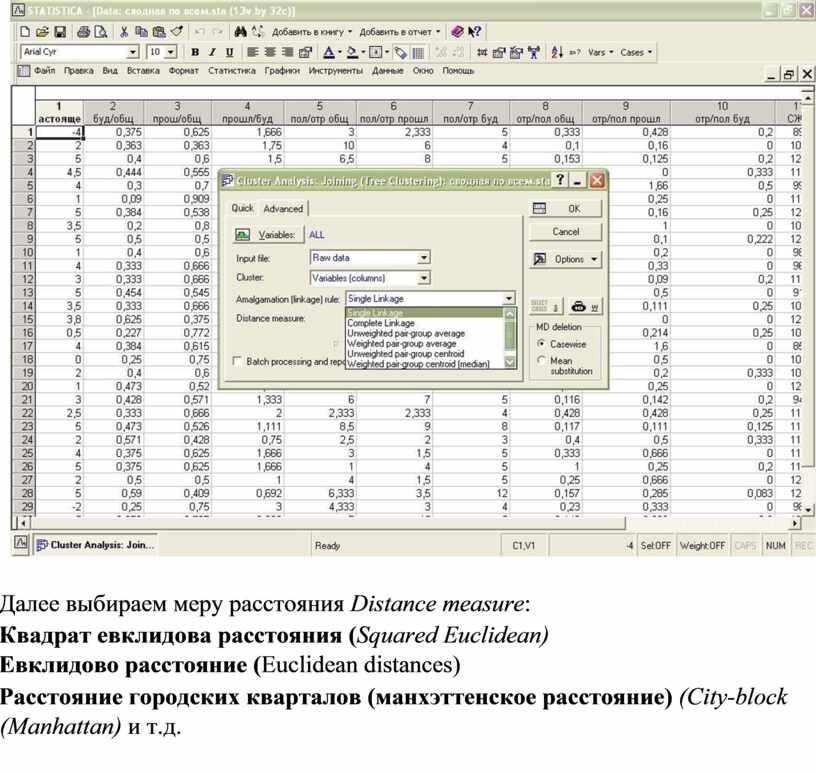
Далее выбираем меру расстояния Distance measure:
Квадрат евклидова расстояния (Squared Euclidean)
Евклидово расстояние (Euclidean distances)
Расстояние городских кварталов (манхэттенское расстояние) (City-block (Manhattan) и т.д.
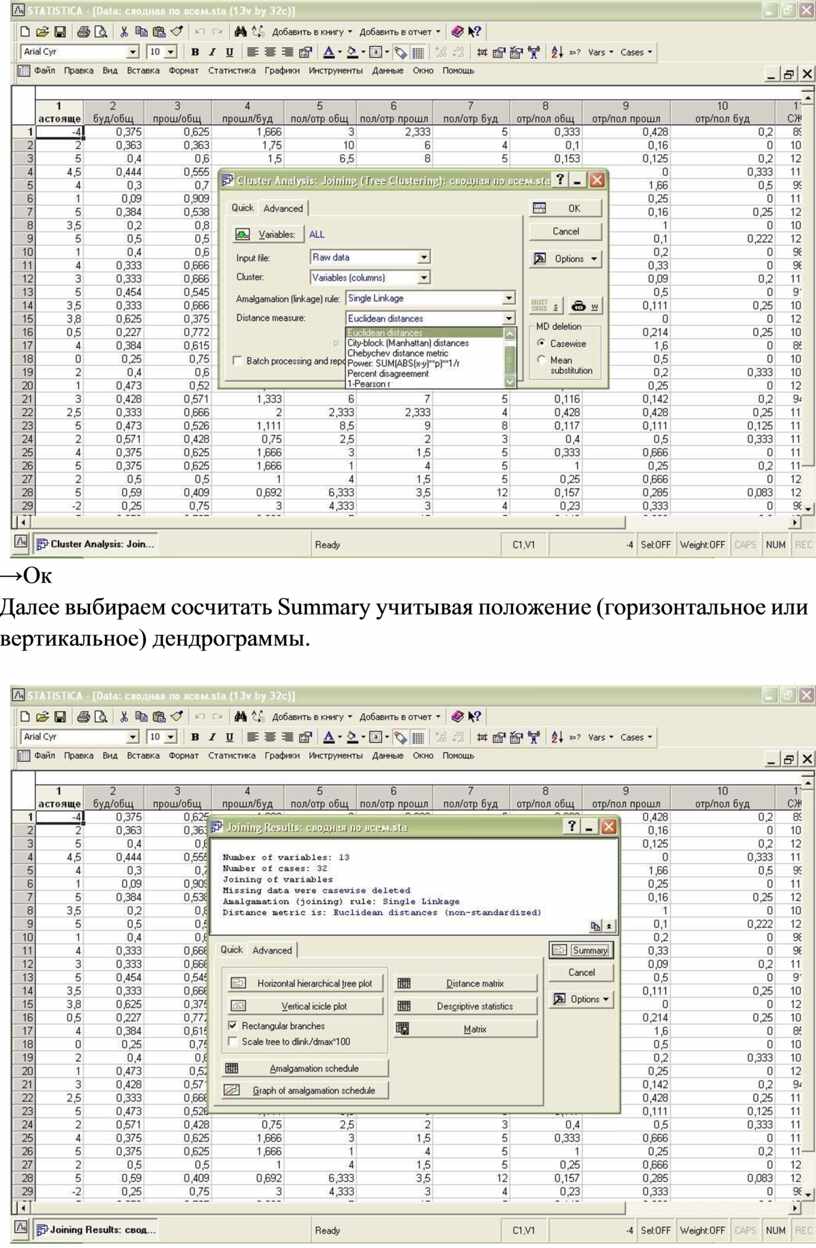
→Ок
Далее выбираем сосчитать Summary учитывая положение (горизонтальное или вертикальное) дендрограммы.
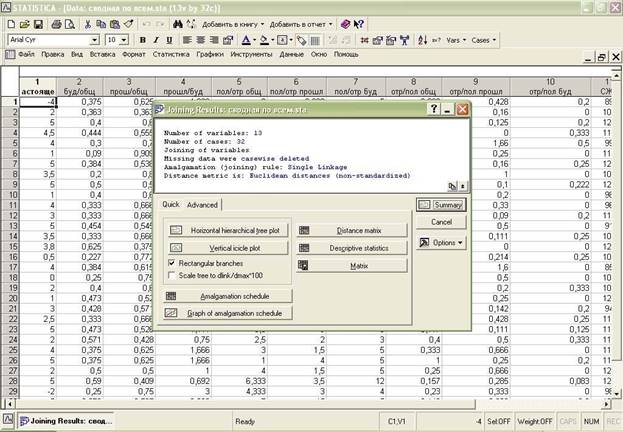
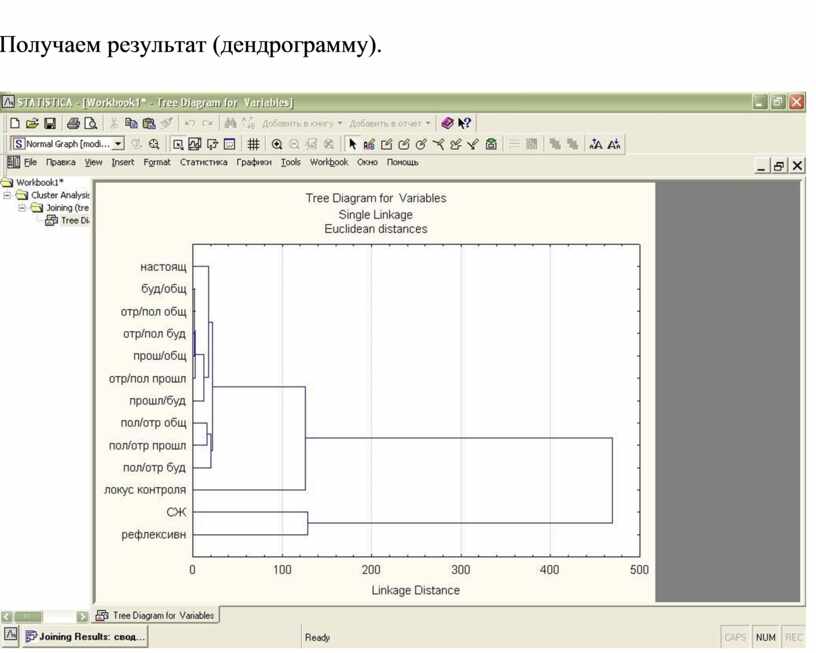
Получаем результат (дендрограмму).
Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.