Урок № 13
Тема урока: “Кодирование текстовой информации”.
Тип урока: Обучающий.
Цели урока:
Познакомить учащихся со способами кодирования информации в компьютере;
Рассмотреть примеры решения задач;
Способствовать развитию познавательных интересов учащихся.
Воспитывать выдержку и терпение в работе, чувства товарищества и взаимопонимания.
Задачи урока:
Формировать знания учащихся по теме “Кодирование текстовой (символьной) информации”;
Содействовать формированию у школьников образного мышления;
Развить навыки анализа и самоанализа;
Формировать умения планировать свою деятельность.
Оборудование:
рабочие места учеников (персональный компьютер),
рабочее место учителя,
интерактивная доска,
мультимедийный проектор,
мультимедийная презентация,
Ход урока
Презентация
I. Организационный момент.
На интерактивной доске первый слайд мультимедийной презентации с темой урока.
Учитель: Здравствуйте, ребята. Садитесь. Дежурный, доложите об отсутствующих. (Доклад
дежурного). Спасибо.
II. Работа над темой урока.
1. Объяснение нового материала.
Объяснение нового материала проходит в форме эвристической беседы с одновременным показом
мультимедийной презентации на интерактивной доске (Приложение 1).
Учитель: Кодирование какой информации мы изучали на предыдущих занятиях?
Ответ: Кодирование графической и мультимедийной информации.
Учитель: Перейдём к изучению нового материала. Запишите тему урока “Кодирование текстовой
информации” (слайд 1). Рассматриваемые вопросы (слайд 2):
исторический экскурс;
двоичное кодирование текстовой информации;
расчет количества текстовой информации.
Исторический экскурс
Человечество использует шифрование (кодировку) текста с того самого момента, когда появилась
первая секретная информация. Перед вами несколько приёмов кодирования текста, которые были
изобретены на различных этапах развития человеческой мысли (слайд 3) [4]:
криптография – это тайнопись, система изменения письма с целью сделать текст непонятным для
непосвященных лиц;
азбука Морзе или неравномерный телеграфный код, в котором каждая буква или знак
представлены своей комбинацией коротких элементарных посылок электрического тока (точек) и
элементарных посылок утроенной продолжительности (тире);
сурдожесты – язык жестов, используемый людьми с нарушениями слуха.
Вопрос: Какие примеры кодирования текстовой информации можно привести еще?
Учащиеся приводят примеры (дорожные знаки, электрические схемы, штрихкод товара).
Учитель: (Показ слайда 4). Один из самых первых известных методов шифрования носит имя
римского императора Юлия Цезаря (I век до н.э.) [4]. Этот метод основан на замене каждой буквы
шифруемого текста, на другую, путем смещения в алфавите от исходной буквы на фиксированное
количество символов, причем алфавит читается по кругу, то есть после буквы я рассматривается а.
Так слово байт при смещении на два символа вправо кодируется словом гвлф. Обратный процесс
расшифровки данного слова – необходимо заменять каждую зашифрованную букву, на вторую
слева от неё.
(Показ слайда 5) Расшифруйте фразу персидского поэта Джалаледдина Руми “кгнусм ёогкг фесл
тцфхя фзужщз фхгрзх ёогксп”, закодированную с помощью шифра Цезаря. Известно, что каждаябуква исходного текста заменяется третьей после нее буквой. В качестве опоры используйте буквы
русского алфавита, расположенные на слайде.
Вопрос: Что у вас получилось?
Ответ учащихся:
Закрой глаза свои пусть сердце станет глазом
Ответ сравнивается с появившемся на слайде 5 правильным ответом.
Двоичное кодирование текстовой информации
Информация, выраженная с помощью естественных и формальных языков в письменной форме,
называется текстовой информацией (слайд 6).
Какое количество информации необходимо, чтобы закодировать каждый знак, можно вычислить по
формуле: N = 2I.
Вопрос: В каком из перечисленных приёмов кодирования используется двоичный принцип
кодирования информации?
Ответ учащихся: В азбуке Морзе.
Учитель: В компьютере также используют принцип двоичного кодирования информации. Только
вместо точки и тире используют 0 и 1 (слайд 7) [1].
Традиционно для кодирования одного символа используется 1 байт информации.
Вопрос: Какое количество различных символов можно закодировать? (напомнить, что 1 байт=8 бит)
Ответ учащихся: N = 2I = 28 = 256.
Учитель: Верно. Достаточно ли этого для представления текстовой информации, включая
прописные и строчные буквы русского и латинского алфавита, цифры и другие символы?
Дети подсчитывают количество различных символов:
33 строчные буквы русского алфавита + 33 прописные буквы = 66;
для английского алфавита 26 + 26 = 52;
цифры от 0 до 9 и т.д.
Учитель: Ваш вывод?
Вывод учащихся: Получается, что нужно 127 символов. Остается еще 129 значений, которые
можно использовать для обозначения знаков препинания, арифметических знаков, служебных
операций (перевод строки, пробел и т.д.. Следовательно, одного байта вполне хватает, чтобы
закодировать необходимые символы для кодирования текстовой информации.
Учитель: В компьютере каждый символ кодируется уникальным кодом.
Принято интернациональное соглашение о присвоении каждому символу своего уникального кода.
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for
Information Interchange) (слайд 8).
В этой таблице представлены коды от 0 до 127 (буквы английского алфавита, знаки
математических операций, служебные символы и т.д.), причем коды от 0 до 32 отведены не
символам, а функциональным клавишам. Запишите название этой кодовой таблицы и диапазон
кодируемых символов.
Коды с 128 по 255 выделены для национальных стандартов каждой страны. Этого достаточно для
большинства развитых стран.
Для России были введены несколько различных стандартов кодовой таблицы (коды с 128 по 255).
Вот некоторые из них (слайд 910). Рассмотрим и запишем их названия:
КОИ8Р, СР1251, СР866, Мас, ISO.
Откройте практикум по информатике на стр. 6566 и прочитайте про эти кодировочные таблицы.
Учитель: В текстовом редакторе MS Word чтобы вывести на экране символ по его номеру кода,
необходимо удерживая на клавиатуре клавишу “ALT” набрать код символа на дополнительной
цифровой клавиатуре (слайд 11):
Понятие кодировки Unicode
(слайд 12) В мире существует примерно 6800 различных языков. Если прочитать текст,
напечатанный в Японии на компьютере в России или США, то понять его будет нельзя. Чтобы
буквы любой страны можно было читать на любом компьютере, для их кодировки стали
использовать два байта (16 бит).
Вопрос: Сколько символов можно закодировать двумя байтами? (N=2I=216=65536)
Ответ учащихся: 65536
Такая кодировка называется Unicode и обозначается как UCS2. Этот код включает в себя все
существующие алфавиты мира, а также множество математических, музыкальных, химических
символов и многое другое. Существует кодировка и UCS4, где для кодирования используют 4
байта, то есть можно кодировать более 4 млрд. символов.Расчет количества текстовой информации
Так как каждый символ кодируется 1 байтом, то информационный объем текста можно узнать,
умножив количество символов в тексте на 1 байт.
Проверим это на практике. Включите монитор, создайте текстовый документ в редакторе Блокнот
и напечатайте в нём пословицу (слайд 12): “Ученье – атаман, а неученье – комар”. [3]. Сколько в
ней символов?
Ответ: 36
Учитель: Сохраните и закройте файл. Определите его объем в байтах. Каков он?
Ответ: 36 байт.
Учитель: Ваш вывод?
Ученики обсуждают и делают выводы.
2. Практическая работа.
Учитель: В операционной системе Linux запустите текстовый редактор Open Office.org Writer.
Откройте стр.198 учебника по информатике и информационным технологиям.
Определим числовой код символа в текстовом редакторе Open Office.org Writer.
В текстовом редакторе Open Office.org Writer ввести команду /Вставка – Специальные
символы…/ …(выполнение практической работы).
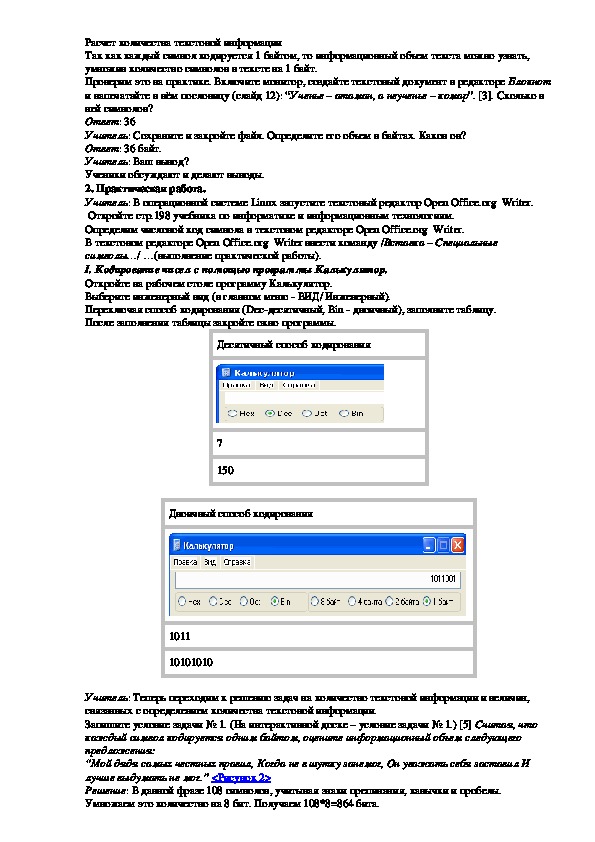
I. Кодирование чисел с помощью программы Калькулятор.
Откройте на рабочем столе программу Калькулятор.
Выберите инженерный вид (в главном меню ВИД/ Инженерный).
Переключая способ кодирования (Decдесятичный, Bin двоичный), заполните таблицу.
После заполнения таблицы закройте окно программы.
Десятичный способ кодирования
7
150
Двоичный способ кодирования
1011
10101010
Учитель: Теперь переходим к решению задач на количество текстовой информации и величин,
связанных с определением количества текстовой информации.
Запишите условие задачи № 1. (На интерактивной доске – условие задачи № 1.) [5] Считая, что
каждый символ кодируется одним байтом, оцените информационный объем следующего
предложения:
“Мой дядя самых честных правил, Когда не в шутку занемог, Он уважать себя заставил И
лучше выдумать не мог.” <Рисунок 2>
Решение: В данной фразе 108 символов, учитывая знаки препинания, кавычки и пробелы.
Умножаем это количество на 8 бит. Получаем 108*8=864 бита.Учитель: Рассмотрим задачу № 2. (Условие выводится на интерактивной доске).<Рисунок
3>Запишите её условие: Лазерный принтер Canon LBP печатает со скоростью в среднем 6,3 Кбит в
секунду. Сколько времени понадобится для распечатки 8ми страничного документа, если
известно, что на одной странице в среднем по 45 строк, в строке 70 символов (1 символ – 1 байт)
(см. рис. 2).
Решение:
1) Находим количество информации, содержащейся на 1 странице:
45 * 70 * 8 бит = 25200 бит
2) Находим количество информации на 8 страницах:
25200 * 8 = 201600 бит
3) Приводим к единым единицам измерения. Для этого Кбиты переводим в биты:
6,3*1024=6451,2 бит/сек.
4) Находим время печати: 201600: 6451,2 = 31,25 секунд.
III. Обобщение
Вопросы учителя (слайд 14):
1. Какой принцип кодирования текстовой информации используется в компьютере?
2. Как называется международная таблица кодировки символов?
3. Перечислите названия таблиц кодировок для русскоязычных символов.
4. В какой системе счисления представлены коды в перечисленных вами таблицах кодировок?
Мы кодировали символы, звук и графику. А можно закодировать эмоции?
Демонстрируется слайд 14.
IV. Итог урока. Домашнее задание
§ 2.1,задача 2.1, записи в тетрадях.