Поделиться

«Базы данных»
Лекция 1
§1. Основные понятия.
Объект - это нечто существующее и различимое. Объектами могут быть материальные предметы, а также абстрактные понятия, например, произведения искусства.
Данное - это некоторый показатель, который характеризует объект и принимает для конкретного экземпляра объекта некоторое числовое или текстовое значение.
Пример: Объектом является продукция, производимая фирмой. Данными вида продукции являются его код, название, показатели, себестоимость и т. д.
NB: Необходимо различать имя данного и значение данного. Имя данного - только одно, а значение данного может изменяться (хотя и необязательно) при переходе от одного объекта к другому.
Пример: Два объекта «груша» характеризуются данным «вес»; имя данного для них одно и то же, но значение данного будет разным.
Информацию об объектах можно и нужно структурировать, т.к. структурированную информацию легче обрабатывать.
Структурирование информации - введение каких-то соглашений о способах представления данных (процесс приспособления форматов и значений данных к нуждам автомата, т. е. устранение произвола в представлении длины и (или) значений).
Структуризация нужна для эффективной обработки данных автоматом, в частности ЭВМ.
§2. Информационные системы.
Информационная система (ИС) - совокупность тем или иным образом структурированных данных и комплекса аппаратно - программных средств для хранения данных и манипулирования ими.
Классификация ИС:
1. Информационно-поисковые (Ориентация на поиск данных из общего множества по определенному поисковому критерию. Пользователь интересуется не столько обработкой информации, сколько самой извлекаемой информацией).
2. Обработки данных (Позволяют обрабатывать данные, причем вывод может либо отсутствовать, либо представлять результат обработки данных, а не сами данные):
Функции ИС:
1. Хранение информации.
2. Просмотр и поиск.
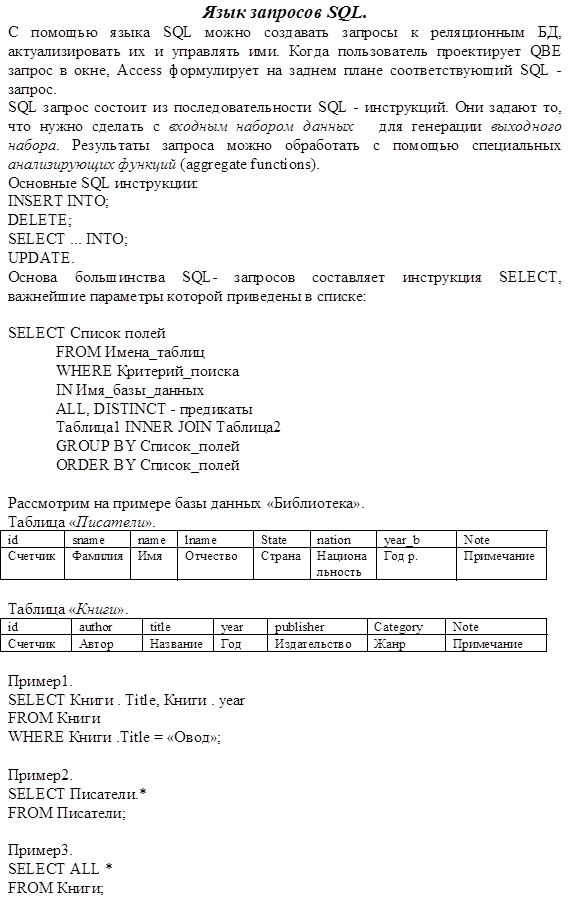
3. Выборка.
4. Ввод и редактирование информации.
5. Отчеты.
6. Контроль правильности информации.
§3. Части ИС.
ИС условно можно разбить на части:
База данных - поименованная совокупность взаимосвязанных данных, находящихся под управлением СУБД.
Отличительной чертой БД следует считать совместное хранение данных и их описаний (которые называются метаданными). Важнейший компонент ИС - СУБД, которая состоит из ядра и сервисных программ.
СУБД - программно-аппаратный пакет, который позволяет обеспечить пользователю простой доступ к базе данных.
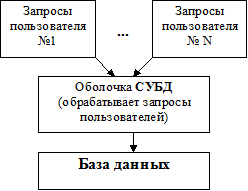
Архитектура СУБД:
|
|
Более широкое понятие - Банк данных.
Банк данных - система баз данных, программных, технических, языковых, организационно-методических средств, предназначенных для обеспечения централизованного накопления и коллективного многоцелевого использования данных (т.е. Банк данных включает в себя БД, СУБД, соответствующее оборудование и персонал).
§4. Модели данных СУБД.
Предметная область БД - часть реального мира, подлежащая изучению с целью управления и автоматизации.
При работе с БД СУБД поддерживает в памяти компьютера некоторую модель предметной области, называемую моделью данных, т.е. модель данных определяется типом СУБД.
Классификация моделей данных:
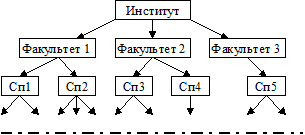
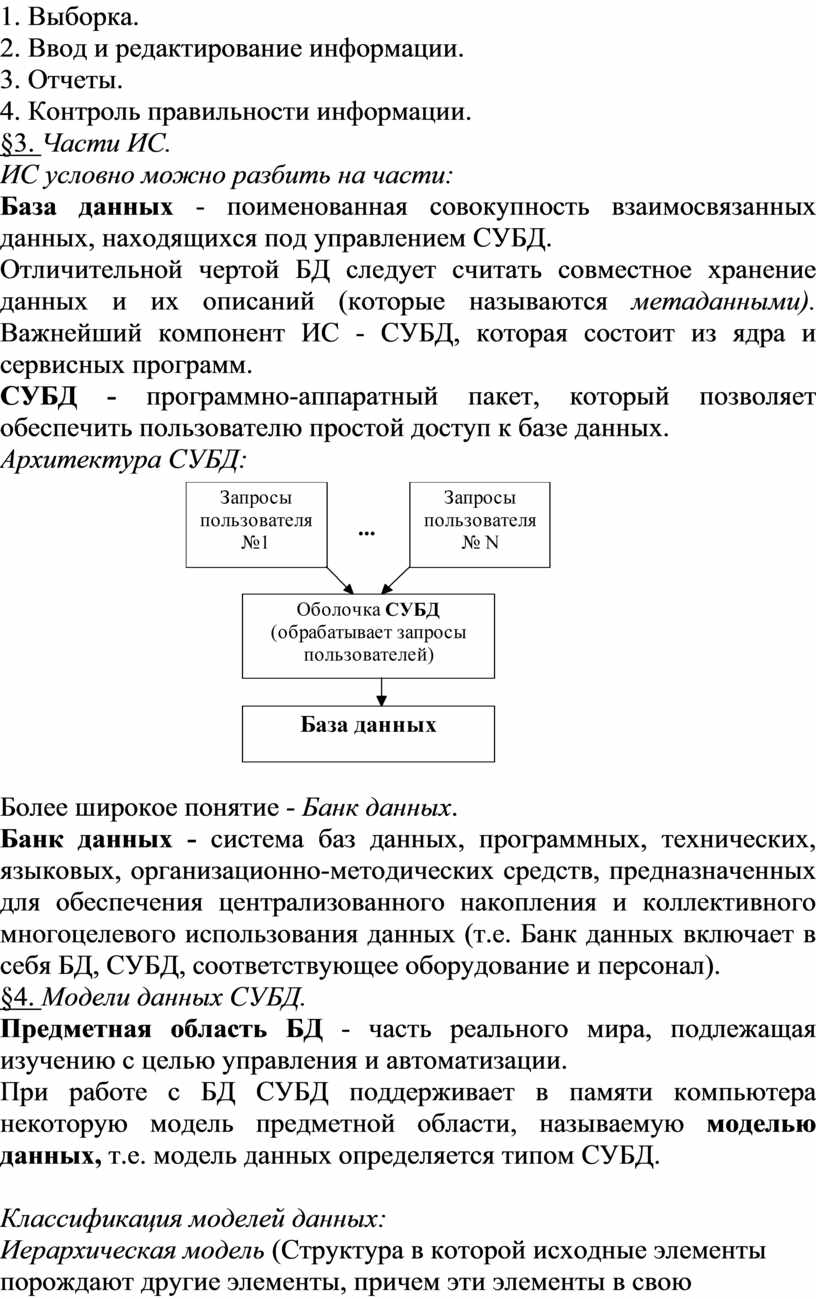
1. Иерархическая модель (Структура в которой исходные элементы порождают другие элементы, причем эти элементы в свою очередь порождают следующие элементы. Каждый порожденный элемент имеет только один порождающий элемент).
Структура института.
Сп1, ... Сп5 - специальности соответствующих факультетов.
|
|
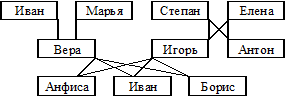
2. Сетевая модель (Отличается от иерархической тем, что каждый порожденный элемент имеет более одного порождающего элемента)
Генеалогическое древо.
|
|
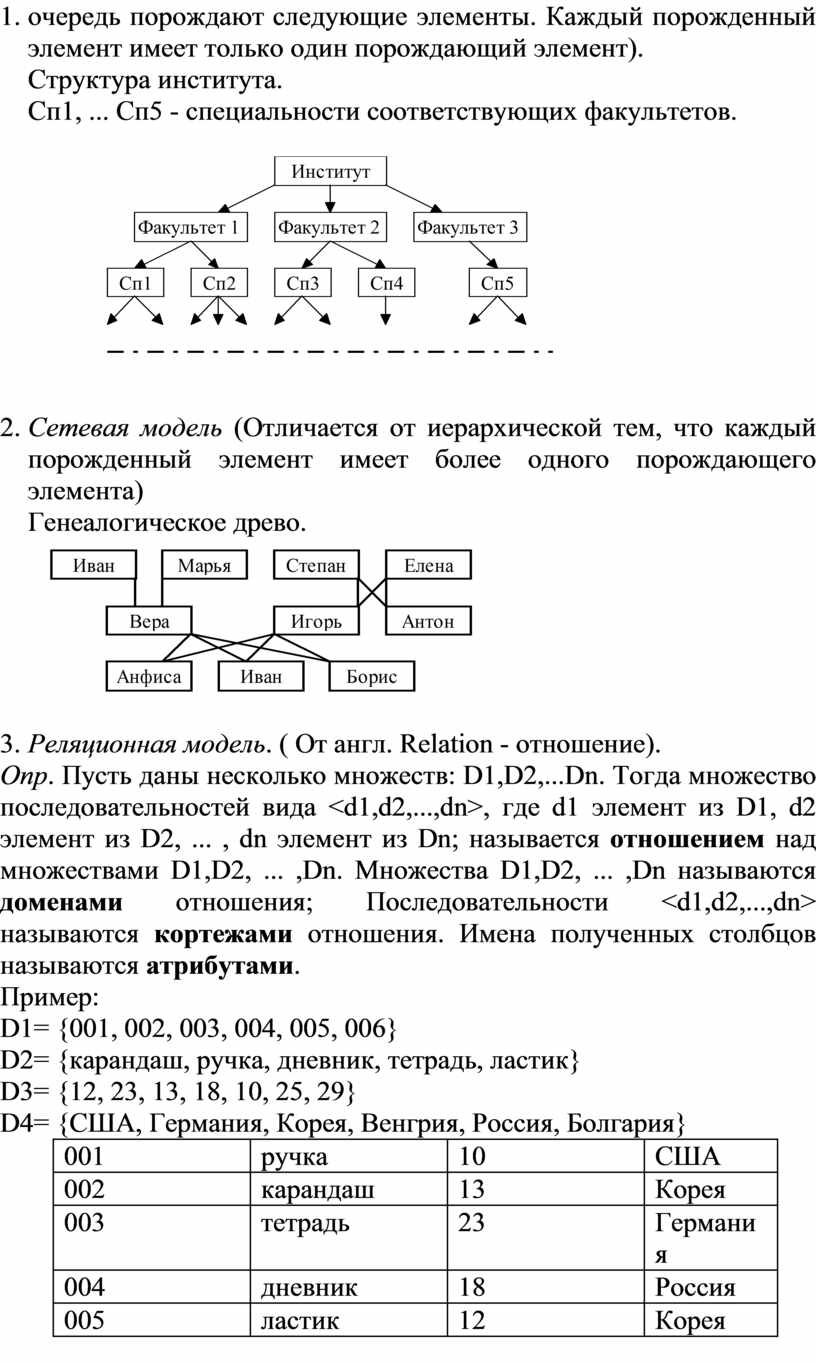
3. Реляционная модель. ( От англ. Relation - отношение).
Опр. Пусть даны несколько множеств: D1,D2,...Dn. Тогда множество последовательностей вида <d1,d2,...,dn>, где d1 элемент из D1, d2 элемент из D2, ... , dn элемент из Dn; называется отношением над множествами D1,D2, ... ,Dn. Множества D1,D2, ... ,Dn называются доменами отношения; Последовательности <d1,d2,...,dn> называются кортежами отношения. Имена полученных столбцов называются атрибутами.
Пример:
D1= {001, 002, 003, 004, 005, 006}
D2= {карандаш, ручка, дневник, тетрадь, ластик}
D3= {12, 23, 13, 18, 10, 25, 29}
D4= {США, Германия, Корея, Венгрия, Россия, Болгария}
|
001 |
ручка |
10 |
США |
|
002 |
карандаш |
13 |
Корея |
|
003 |
тетрадь |
23 |
Германия |
|
004 |
дневник |
18 |
Россия |
|
005 |
ластик |
12 |
Корея |
Обратите внимание на порядок элементов в кортеже: первый элемент каждого кортежа выбран из D1, второй из D2 и т.д.
§5. Реляционная модель.
Атрибут, значение которого идентифицирует кортежи, называется главным ключом. В некоторых отношениях кортежи идентифицируются соединением нескольких атрибутов и наз. составным ключом.
Главный ключ должен обладать двумя свойствами:
1. Однозначная идентификация записи: запись должна однозначно определяться значением ключа.
2. Отсутствие избыточности: никакое поля нельзя удалить из ключа, не нарушая при этом свойства однозначной идентификации.
Каждое значение главного ключа в пределах таблицы должно быть уникальным. Указание главного ключа - единственный способ отличить один экземпляр объекта от другого.
Примеры: Отношение служащих небольшой организации, выбрать главный ключ, структуру атрибутов.
Операции над данными:
· Обновление отношения (запоминание новых кортежей, удаление ненужных кортежей).
· Объединение двух отношений (если они односхемные, т.е. имеют одну и ту же структуру кортежей).
· Выборка (На входе - отношение, на выходе отношение с такой же схемой, все кортежи которого удовлетворяют условиям выборки).
· Обработка отношений (создание новых, создание новых на основе существующих, удаление ненужных).
§6. Реляционные СУБД.
Реляционная БД представляет собой совокупность отношений, содержащих всю информацию, которая должна храниться в БД.
Отношение в реляционной теории есть не что иное, как таблица БД, кортеж называются записью, атрибут - полем.
В простейшем случае БД представляет собой единственную таблицу.
При проектировании для каждого поля таблиц необходимо определить тип хранимого результата. Возможные типы данных определяются используемой СУБД. Возможные типы: текстовый, целый, вещественный, дата, логический, текстовый произвольной длины(memo), двоичный произвольной длины(general).
Примеры таблиц. Таблица, хранящая сведения о студентах: номере дома, номере комнаты проживания, телефоне.
§7. Проектирование БД.
Прежде чем приступать к проектированию таблиц для БД необходимо выяснить цели проектирования:
1. Возможность хранить все необходимые данные в БД.
2. Исключение избыточности данных.
3. Свести количество хранимых отношений (таблиц) к минимуму.
Универсальное отношение - отношение, в которое включаются все представляющие интерес атрибуты и оно может содержать все данные, которые предполагается разместить в БД в будущем.
Примеры. Таблица заказов, хранятся сведения о заказчике и заказе. Один заказчик может делать множество заказов. Проблемы, связанные с УО (вставка, обновление, удаление).
Лекция 2
§8 Нормализация.
В реляционных БД любые совокупности данных представляются в виде двумерных таблиц. Вся предметная область может быть представлена в виде одной универсальной таблицы. Недостатки этого способа хранения устраняются при помощи нормализации. Процесс представления произвольной структуры данных в виде простых двумерных таблиц называется нормализацией.
Е. Кодд предложил в рамках реляционной теории аппарат называемый нормализацией отношений. Было выделено пять форм нормальных отношений. Был предложен механизм перехода от формы к форме.
Достоинства нормализации:
· Исключение избыточности данных
· Обеспечение целостности данных
Недостатки:
· Возможное снижение скорости выполнения операций.
§9 Пример нормализации отношений.
Задание.
Требуется спроектировать БД, в которой содержится следующая информация:
Номер заказа, дата заказа, заказанные продукты (код и название), общая сумма заказа.
Строим универсальное отношение:
|
Заказ № |
Дата |
Товар 1 |
Товар 2 |
Товар 3 |
Товар 4 |
Сумма заказа |
|
00006 |
08.04.97 |
а111 |
б222 |
в333 |
д444 |
10000 |
|
|
|
|
|
|
|
|
Главным ключом является поле «Заказ №».
Эта структура работает нормально до тех пор, пока клиент не закажет более 4-х видов товаров за раз. Возникает необходимость в первой нормальной форме, в замене повторяющихся полей одним полем, при этом создается несколько записей.
1-ая нормальная форма:
· Таблица не должна иметь повторяющихся записей.
· Таблица не должна иметь повторяющихся групп полей.
|
Заказ № |
Дата заказа |
Код товара |
Название товара |
Сумма заказа |
|
00006 |
08.04.97 |
а111 |
авторучка |
10000 |
|
00006 |
08.04.97 |
б222 |
карандаш |
10000 |
|
00006 |
08.04.97 |
в333 |
тетрадь |
10000 |
|
00006 |
08.04.97 |
д444 |
альбом |
10000 |
Поле «Заказ №» перестает быть уникальным, значит, требуется введение нового главного ключа. Им становится составной ключ «Заказ №» + «Код товара». Наличие главного ключа исключает повторение записей. Но и здесь структура таблицы далека от совершенства. Возникает необходимость во второй нормальной форме.
2-ая нормальная форма:
· Таблица удовлетворяет условиям 1-ой НФ.
· Любое неключевое поле однозначно идентифицируется полным набором ключевых полей.
Для нашей таблицы это не так. Поле «Дата заказа» однозначно идентифицируется лишь частью главного ключа, а именно полем «Заказ №».
Изменим структуру таблиц.
|
Заказ № |
Дата заказа |
Сумма заказа |
|
Заказ № |
Код товара |
Название товара |
Счетчик товара |
|
00006 |
08.04.97 |
10000 |
|
00006 |
а111 |
авторучка |
0001 |
|
00007 |
23.05.87 |
20000 |
|
00006 |
б222 |
карандаш |
0002 |
|
|
|
|
|
00006 |
в333 |
тетрадь |
0003 |
|
|
|
|
|
00006 |
д444 |
альбом |
0004 |
|
|
|
|
|
00007 |
ж666 |
фломастер |
0001 |
Чтобы связать информацию в двух таблицах, необходимо определить связь между ними, в частности на основе поля «Заказ №».
Типы связей между таблицами:
· Один - к - Одному (В одной таблице хранятся сведения о школьниках, в другой сведения о прохождении школьниками прививок).
· Один - ко - Многим (В одной таблице сведения об учителях, в другой сведения о школьниках, у которых эти учителя - классные руководители).
· Много - к - Одному (То же что и предыдущий случай, только наоборот, смотря с какой стороны смотреть).
· Много - ко - Многим (В одной таблице хранятся заказы, в другой - фирмы, исполняющие заказы, причем выполнять один заказ могут корпоративно несколько фирм).
Схемки нарисовать.
В данном случае отношение «Один - ко - Многим», т.к. каждой записи в первой таблице соответствует несколько записей во второй таблице.
Главный ключ первой таблицы - на основе поля «Заказ №»; второй таблицы - на основе связки полей «Заказ №» + «Счетчик товара».
Эта структура тоже не идеал. Поэтому движемся дальше - к третьей нормальной форме.
3-ая нормальная форма:
· Таблица удовлетворяет условиям второй НФ.
· Ни одно из неключевых полей не идентифицируется с помощью другого неключевого поля.
Обратим внимание на вторую таблицу. Здесь неключевое поле «Название товара» идентифицируется с помощью другого неключевого поля «Код товара». Примем меры.
Первая таблица останется без изменений, а вот вторая преобразуется в две.
|
Заказ № |
Код товара |
Счетчик товара |
|
Код товара |
Название товара |
|
00006 |
а111 |
0001 |
|
а111 |
авторучка |
|
00006 |
б222 |
0002 |
|
б222 |
карандаш |
|
00006 |
в333 |
0003 |
|
в333 |
тетрадь |
|
00006 |
д444 |
0004 |
|
д444 |
альбом |
|
00007 |
ж666 |
0001 |
|
ж666 |
фломастер |
Главный ключ второй таблицы остается без изменений: «Заказ №» + «Счетчик товара», главный ключ третьей таблицы: «Код товара». Связь между второй и третьей таблицами осуществляется по полю «Код товара».
Мы сделали это. В смысле, спроектировали!!!
Существуют 4-ая и 5-ая НФ, которые накладывают более жесткие требования на таблицы, но на практике применяют НФ по 3-ую формы включительно.
Дополнительной проблемой нормализации является т.н. «ссылочная целостность»(Referential Integrity).
Например, в третьей таблице может не оказаться записи для кода товара, который значится в заказе в таблице второй (его случайно удалили). Это довольно неприятная ситуация. В таких случаях, при удалении из третьей таблицы записи, необходимо проверять: не ссылается ли какая-нибудь запись второй таблицы на ту, которую мы хотим удалить. Обязанность поддержания этой целостности в зависимости от используемой СУБД ложится либо на систему, либо на плечи программиста.
Лекция 3
§9 Поиск. Индексация.
Как уже отмечалось ранее, одними из функций ИС являются просмотр и поиск, а также выборка информации. Поиск можно осуществлять по значению конкретного поля. Пример.
Скорость поиска по полю можно увеличить в сотни и тысячи раз, если упорядочить записи в таблице по этому полю. В этом случае используется специальный алгоритм поиска.
Упорядочить записи по выбранному полю можно двумя способами:
· Физически изменить порядок записей внутри таблицы (т.е. перезаписать таблицу).
Но на перезапись всей таблицы тратится время и дисковое пространство. Поэтому обычно идут другим путем.
· Виртуальная сортировка при помощи индекса (таблицы мы не трогаем, но создаем для них т.н. «индексы»).
|
|
|
0001 |
25 |
зеленый |
|
|
|
0002 |
33 |
красный |
|
25 |
|
0003 |
19 |
белый |
|
33 |
|
0004 |
03 |
рыжий |
Индекс Таблица
Индекс - таблица, с которой связана процедура, получающая на входе информацию о некоторых значениях атрибутов и выдающая на выходе информацию, помогающую найти запись или группу записей, которые имеют заданные значения атрибутов.
Основной индекс получает в качестве входной информации главный ключ. Индексный файл - файл, в котором хранится индекс.
Способы поиска в индексном файле:
1. Последовательное сканирование файла (Самый неэффективный).
2. Блочный поиск (Определяется величина блока, записи группируются в блоки и каждый блок проверяется по одному разу до тех пор, пока не будет найден нужный блок, затем поиск идет внутри найденного блока).
3. Двоичный поиск (Рассматривается запись, находящаяся в середине области, в которой выполняется поиск и ее ключ сравнивается с поисковым ключом. Затем поисковая область делится пополам и процесс повторяется).
При поиске система быстро находит в индексном файле требуемое значение ключа, а затем читает искомую запись по ее номеру.
Таблица, для которой существует индекс, называется индексированной. Система индексирования образует мощный аппарат поиска и просмотра в базах данных.
Индексные файлы применяются не только для быстрого поиска конкретных записей, но и для многих других целей. Например, с помощью индексных файлов мы можем просматривать таблицы в любом порядке.
§10. Запросы.
Запрос(Query) - это ряд вопросов к имеющимся данным, результатом выполнения которого является некоторое подмножество данных. Запросы позволяют просматривать данные из полей одной или нескольких таблиц, отвечающих определенным критериям.
Например, работая с таблицей, содержащей информацию о продажах, можно задать следующие вопросы:
· Каков общий объем продаж за неделю, месяц, год?
· Каких товаров продано больше всего?
· Как продажи распределяются по штатам?
И многие другие.
Способы создания запросов:
1. Использование средств QBE (Query By Example), запрос по образцу - способ, наиболее привлекательный для начинающих программистов. QBE - интерактивная среда, в котором запрос формируется в основном при помощи мыши, перетаскивая нужные вам поля в определенные области диалогового окна.
2. Использование команд SQL (Structured Query Language), язык структурных запросов - стандартизованное ANSI средство манипуляции данными. Различные СУБД поддерживают свои собственные диалекты SQL. К тому же, в зависимости от того, какая СУБД выбрана, существуют различные пути ввода команды SQL в память компьютера.
Обзор рынка СУБД:
1. СУБД, предназначенные непосредственно для разработки локальных пользовательских приложений БД, т.е. приложений, работающих на одном локальном компьютере, либо в компьютерной сети. При этом БД может располагаться на файл-сервере (или нескольких файл-серверах), в качестве которого может использоваться наиболее мощная из ПЭВМ, объединенных в сеть. Функции файл-сервера заключаются, в основном, в хранении БД и обеспечении доступа к ним пользователей, работающих на различных компьютерах. Эти функции обеспечиваются, как правило, той же СУБД, которая работает и на компьютерах пользователей. Эта схема работает при не очень больших объемах данных. При увеличении числа компьютеров в сети или ростом БД производительность резко падает. Это связано с увеличением данных, передаваемых по сети, так как вся обработка происходит на компьютере пользователя. Например, если нужны пара строк в большой таблице на сервере, то сначала вся таблица перекачивается на компьютер пользователя, а затем СУБД отбирает нужные записи.
Примеры:
Microsoft Visual FoxPro, Microsoft Access, Paradox for Windows, Borland Delphi, dBase for Windows.
2. СУБД, выполняющие функции управления базами данных архитектуры клиент - сервер. Они являются источником генерации и управления нужными данными.
Примеры:
Microsoft SQL Server, Oracle, IBM DB2, Sybase.
Основы технологии клиент - сервер:
Приложение разделяется на две части Front-End (клиентская часть) обеспечивает графический интерфейс и находится на компьютере пользователя. Back-End (сервер) обеспечивает управление данными, разделение информации, администрирование и безопасность и находится на специально выделенных компьютерах или мэйнфреймах. При технологии клиент-сервер клиентское приложение (front-end) формулирует запрос к серверу (back-end), на котором выполняются все команды. Результаты команд посылаются затем клиенту для использования и просмотра.
Microsoft SQL Server является на сегодняшний день одним из наиболее мощных серверов БД.
Важным этапом в построении приложения клиент-сервер является установка связи клиентского приложения с источником данных, находящимся на сервере БД. Различные средства разработки используют несколько технологий обеспечения доступа к данным. Одним из стандартов является ODBC (Open Database Connectivity) - открытый доступ к данным, общее определение языка и набор протоколов. ODBC позволяет клиентскому приложению, написанному, например на Access, работать с командами и функциями, поддерживаемыми сервером. В качестве сервера может выступать любой сервер БД, имеющий драйвер ODBC(MS SQL Server, Oracle и т. д.). ODBC определяет минимальный набор SQL команд и набор функций вызова, механизм для вызова специфических для сервера возможностей.












Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.