Поделиться

Вопрос 8.
Одной из важнейших прикладных областей информатики являются информационные системы. Информационной системой можно назвать любую организационную структуру, задача которой состоит в работе с информацией. Примеры таких структур: библиотека, справочная служба железных дорог, СМИ (редакция газеты, телецентр, радиостудия). В этом смысле информационными системами являются все подразделения управленческой структуры предприятия: бухгалтерия, отдел кадров, отдел научно-технической информации и пр. Все эти службы существовали и до появления компьютеров, существуют и сейчас. Разница в том, что раньше они использовали «бумажные» технологии работы с информацией, простые средства механизации обработки данных, а сейчас все шире используют компьютеры.
Информационная система (ИС) — это система, построенная на базе компьютерной техники, предназначенная для хранения, поиска, обработки и передачи значительных объемов информации, имеющая определенную практическую сферу применения.
Классификация информационных систем.
Многочисленные и разнообразные информационные системы, которые существуют сегодня, можно классифицировать по разным принципам.
Первый принцип классификации — используемая техническая база.
1) Простейшая ИС работает на одном компьютере. Это может быть персональный компьютер, а также мини-ЭВМ или большая ЭВМ. Вся информация сосредоточена в памяти этой машины и на ней же функционирует все программное обеспечение системы.
2) ИС на базе локальной сети. Обычно это информационные системы, обслуживающие учреждение, предприятие, фирму. В такой системе информация может передаваться по сети между разными пользователями; разные части общедоступных данных могут храниться на разных компьютерах сети.
3) Информационные системы на базе глобальных компьютерных сетей. Все известные службы Интернета можно рассматривать как такие ИС.
4) Корпоративные ИС. Они объединяют между собой ИС, функционирующие на базе локальных сетей предприятий одного ведомства, региона и пр. например, при покупке железнодорожных билетов или авиабилетов на дальние расстояния, используются услуги транспортной информационной системы, работающей на базе специализированной глобальной сети.
Второй принцип классификации информационных систем — классификация по назначению, то есть по выполняемым функциям.
1) Наиболее старым и традиционным видом ИС являются информационно-справочные, или информационно-поисковые системы (ИПС). Основная цель в использовании таких систем — оперативное получение ответов на запросы пользователей в диалоговом режиме. Характерным свойством ИПС является большой объем хранимых данных, их постоянная обновляемость. Хранилище информации, с которой работает ИПС, называется базой данных. Примером справочной системы является ИПС крупной библиотеки, позволяющая определить наличие в библиотеке нужной книги или произвести подборку литературы по заданной тематике. Поисковые серверы Интернета — это информационно-справочные системы сетевых ресурсов.
2) Управляющие информационные системы. Основное назначение таких систем — выработка управляющих решений. Управляющие системы бывают полностью автоматическими или автоматизированными. Системы автоматического управления (САУ) работают без участия человека. Это системы управления техническими устройствами, производственными установками, технологическими процессами. Например, САУ используются для управления работой ускорителей элементарных частиц в физических лабораториях, химического реактора или автоматической линии на производственном предприятии. В таких системах реализована кибернетическая схема управления с обратной связью. Роль системы управления выполняет компьютер, который работает по программе, составленной программистами. Управление в САУ происходит в режиме реального времени. Это значит, что управляющие команды вырабатываются синхронно с управляемым физическим процессом. Поэтому с ростом скорости работы управляемого объекта должно повышаться быстродействие управляющего компьютера.
Автоматизированные системы управления (АСУ) можно назвать человеко-машинными системами. В них компьютер выступает в роли помощника человека-управляющего. В АСУ задача компьютера состоит в оперативном предоставлении человеку необходимой информации для принятия решения. При этом компьютер может выполнять достаточно сложную обработку данных на основании заложенных в него математических моделей. Это могут быть технологические или экономические расчеты, то есть компьютер берет на себя определенные инженерные функции. Крупные АСУ обеспечивают управление предприятиями, энергосистемами и даже целыми отраслями производства.
3) Обучающие информационные системы на базе ЭВМ. Простейший вариант такой системы — обучающая программа на ПК, с которой пользователь работает в индивидуальном режиме. Более сложными являются обучающие системы, использующие возможности компьютерных сетей. В локальной сети можно организовывать обучение с элементами взаимодействия обучающихся между собой, используя соревновательную форму или форму деловой игры. Наиболее сложными и масштабными обучающими системами являются системы дистанционного обучения, работающие в глобальных сетях. Дистанционное образование называют образованием XXI века. Уже существуют дистанционные отделения во многих ведущих вузах страны, формируется международная система дистанционного образования. Такие системы открывают доступ к качественному образованию для всех людей, независимо от их места жительства, возраста, возможных физических ограничений. Высокоскоростные системы связи в сочетании с технологией мультимедиа позволяют организовывать обучение в режиме реального времени (on line), проводить дистанционные лекции, семинары, конференции, принимать зачеты и экзамены.
4) Экспертные системы, основанные на моделях знаний из определенных предметных областей. Экспертные системы относятся к разделу информатики, который называется «Искусственный интеллект». Экспертная система заключает в себе знания высококвалифицированного специалиста в определенной предметной области и используется для консультаций, помощи в принятии сложных решений, для решения плохо формализуемых задач. Примерами проблем, которые решаются с помощью экспертных систем, являются: установление диагноза болезни; определение причин неисправности сложной техники (например, космического корабля); выдача рекомендаций по ликвидации неисправности и т. д.
Список рассмотренных информационных систем далеко не полный. Существуют еще автоматизированные системы научных исследований (АСНИ), системы автоматизированного проектирования (САПР), геоинформационные системы (ГИС) и другие.
СУБД может быть ориентирована на программистов или на пользователей. Любые действия, выполняемые с базой данных, производятся на ЭВМ с помощью программ СУБД, ориентированные на программистов, фактически являются системами программирования со своим специализированным языком, в среде которых программисты создают программы обработки баз данных. Затем с этими программами работают конечные пользователи. К числу СУБД такого типа относятся FoxPro, Paradox и другие.
СУБД Microsoft Access (MS Access) относится к системам, ориентированным на пользователя. Она позволяет пользователю, не прибегая к программированию, выполнять основные действия с базой данных: создание БД, редактирование и манипулирование данными. MS Access работает в операционной среде Windows, может использоваться как на автономном ПК, так и в локальной компьютерной сети. С помощью Access создаются и эксплуатируются личные базы данных (иногда говорят — «настольные»), а также БД организаций с относительно небольшим объемом данных. Для создания крупных промышленных информационных систем MS Access не годится.
СУБД Access предназначена для работы с реляционными базами данных (РБД).
1. Сортировка и индексирование баз данных.
Сортировка данных.
Один из способов организации данных в таблицах — сортировка записей. По умолчанию порядок отображения записей на экране определяется индексом, автоматически созданным программой Access на основе первичного ключа таблицы. Если первичного ключа у таблицы нет, записи будут отображаться в порядке их ввода в таблицу.
Сортировка позволяет изменить порядок следования записей в таблице и отображать их с учетом значений некоторого определенного поля, т.е. выстроить все записи таблицы в порядке следования значений в этом поле.
Порядок сортировки может быть организован по возрастанию значений (например, от А до Я (от А до Z), или от 1 до 100). Может быть использован и обратный порядок, по убыванию значений (например, от я до А, от Z до а, или от 100 до 1).
Сортировка может быть простой или более сложной, когда записи упорядочиваются не по одному, а по нескольким полям, например, сначала по полю Страна, а затем — Город. Напомним, что ускорить выполнение сложных операций сортировки помогают составные индексы.
Сортировку записей таблицы можно выполнить как в Режиме таблицы, так и в Режиме формы.
Самый простой способ отсортировать записи таблицы (по одному полю или смежным полям) — воспользоваться командой Сортировка. Доступ к ней можно получить как через главное меню (Записи => Сортировка), так и воспользовавшись кнопками Сортировка по возрастанию и Сортировка по убыванию, расположенными на панели инструментов Таблица в режиме таблицы.
Если сортировку необходимо выполнить по нескольким полям, они обязательно должны быть смежными. Кроме того, важным является то, в какой последовательности эти поля расположены, так как составная сортировка будет выполняться в естественном порядке следования выделенных полей — т.е. слева направо. В случае необходимости нужное поле (или поля) можно перетащить на новую позицию в таблице. Чтобы выделить несколько смежных полей, щелкните на заголовке столбца первого нужного поля и, удерживая нажатой левую кнопку мыши, перетащите указатель по заголовкам остальных столбцов.
Если возникает необходимость отсортировать числа, которые хранятся в полях текстового типа, следует помнить о том, что программа Access воспринимает эти значения как строки символов. Поэтому условием корректной сортировки таких значений является их одинаковая длина (для сравнения таких "чисел", как, например, 2 и 11, следует дополнить строковое представление числа 2 незначащим нулем: 02).
Чтобы восстановить первоначальный порядок размещения записей в таблице, выберите команду главного меню Записи =>Удалить фильтр.
Командой Сортировка можно воспользоваться и при просмотре в режиме таблицы связанных записей из подчиненной таблицы. Чтобы отсортировать связанные записи, выберите нужное поле дочерней таблицы, а затем щелкните на кнопке Сортировка по возрастанию или Сортировка по убыванию.
Индексирование.
Хотя технология хеширования (это технология быстрого прямого доступа к хранимой записи на основе заданного значения некоторого поля, которое может быть даже не ключевым) и может дать высокую эффективность, но для ее реализации не всегда удается найти соответствующую функцию, поэтому при организации доступа к данным широко используются индексные файлы.
Основное назначение индексов состоит в обеспечении эффективного прямого доступа к записи таблицы по ключу. Различают индексированный файл и индексный файл (рис. 1). Индексированный файл — это основной файл, содержащий данные отношения, для которого создан индексный файл.

Индексный файл — это файл особого типа, в котором каждая запись состоит из двух значений: данных и указателя. Данные представляют поле, по которому производится индексирование, а указатель осуществляет связывание с соответствующим кортежем индексированного файла. Если индексирование осуществляется по ключевому полю, то индекс называется первичным. Такой индекс к тому же обладает свойством уникальности, т. е. не содержит дубликатов ключа.
Обычно индекс определяется для одного отношения, и ключом является значение простого или составного атрибута.
Основное преимущество использования индексов заключается в значительном ускорении процесса выборки данных, а основной недостаток — в замедлении процесса обновления данных. Действительно, при каждом добавлении новой записи в индексированный файл потребуется также добавить новый индекс (а это дополнительное время) в индексный файл. Поэтому при выборе поля индексирования всегда важно уточнить, который из двух показателей важнее: скорость выборки или скорость обновления.
Индексы позволяют:
Поскольку при выполнении многих операций языкового уровня требуется сортировка отношений в соответствии со значениями некоторых атрибутов, полезным свойством индекса является обеспечение последовательного просмотра кортежей отношения в диапазоне значений ключа в порядке возрастания или убывания значений ключа.
В зависимости от организации индексной и основной областей различают два типа файлов: индексно-прямые файлы и индексно-последовательные файлы.
Индексно-прямые файлы.
В индексно-прямых файлах основная область содержит последовательность записей одинаковой длины, расположенных в произвольном порядке, а индексная запись содержит значение первичного ключа и порядковый номер записи в основной области, которая имеет данное значение первичного ключа.
Так как индексные файлы строятся для первичных ключей, однозначно определяющих запись, то в индексно-прямых файлах для каждой записи в основной области существует только одна запись из индексной области. Такой индекс называется плотным. Все записи в индексной области упорядочены по значению ключа, поэтому можно применить более эффективные способы поиска в упорядоченном пространстве.
Наиболее эффективным алгоритмом поиска на упорядоченном массиве является бинарный поиск. При этом все пространство поиска разбивается пополам, и так как оно строго упорядочено, то сначала определяется, не является ли срединный элемент искомым, а если нет, то дается оценка в какой половине его надо искать. Далее установленная половина также делится пополам, и производятся аналогичные действия, и так до тех пор, пока не будет обнаружен искомый элемент.
В данном случае двоичный алгоритм поиска применяется к индексному файлу, а потом путем прямой адресации происходит обращение к основной области уже по конкретному номеру записи.
Операция добавления осуществляет запись в конец основной области. В индексной области при этом производится занесение информации так, чтобы не нарушать упорядоченности. Поэтому вся индексная область файла разбивается на блоки и при начальном заполнении в каждом блоке остается свободная область (процент расширения) (рис. 2).
Блок, в который должен быть занесен индекс, копируется в оперативную память, где производится вставка новой записи, и измененный блок записывается обратно на диск.
Естественно, в процессе добавления новых записей процент расширения постоянно уменьшается. Когда исчезает свободная область, возникает переполнение индексной области. В этом случае возможны два решения: либо перестроить заново индексную область, либо организовать область переполнения для индексной области, в которой будут храниться не поместившиеся в основную область записи. Однако первый способ потребует дополнительного времени на перестройку индексной области, а второй увеличит время на доступ к произвольной записи и потребует организации дополнительных ссылок в блоках на область переполнения.
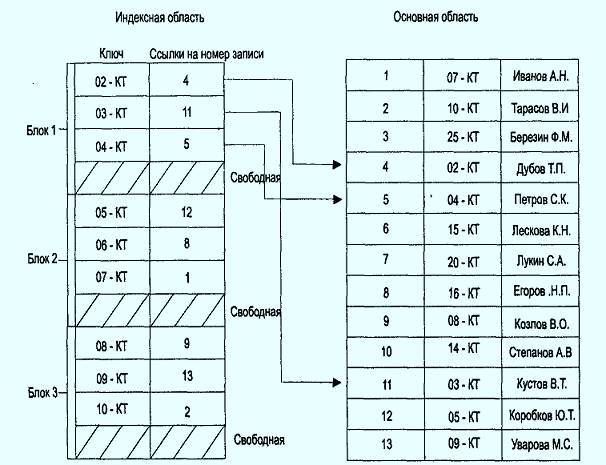
Рис. 2 Организация индекно - прямой адресации.
Именно поэтому при проектировании физической базы данных так важно заранее как можно точнее определить объемы хранимой информации, спрогнозировать ее рост и предусмотреть соответствующее расширение области хранения.
При удалении записи возникает следующая последовательность
действий:
запись в основной области помечается как удаленная, в индексной области
соответствующий индекс уничтожается
физически, то есть записи индексного
файла, следующие за удаленной записью, перемещаются на ее место, и блок, в
котором хранился данный индекс, заново записывается на диск.
При этом количество обращений к диску
для этой операции такое же, как и
при добавлении новой записи.
Индексно-последовательные файлы.
Если файлы поддерживаются в отсортированном состоянии с момента их создания, то для работы с ними может быть использован другой подход с технологией построения индексного файла, несколько отличной от вышерассмотренной. Принципы внутреннего упорядочения и блочности построения таких файлов позволяют уменьшить количество хранимых индексов за счет того, что в индексном файле не содержатся указатели на все записи индексированного файла. Таким образом, в этом случае индекс получается неплотным или разреженным.
Одним из преимуществ неплотных индексов является их малый размер по сравнению с плотными индексами, так как они содержат меньшее число записей. Это позволяет просматривать содержимое базы данных с большей скоростью.
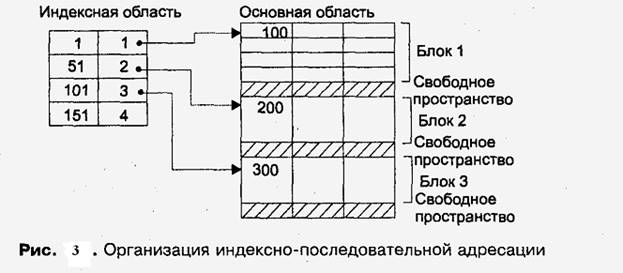
Индексная запись для таких файлов должна содержать: значение ключа первой записи блока и номер блока с этой записью.
Теперь по заданному значению первичного ключа в индексной области требуется отыскать уже нужный блок. Так как все записи упорядочены, то значение первой записи блока позволяет быстро определить, в каком блоке находится искомая запись. Все остальные действия происходят в основной области (рис. 3). При переходе к неплотному индексу время доступа уменьшается практически в полтора раза.
При таком подходе новая запись должна заноситься сразу в требуемый блок на требуемое место. Данное занесение осуществляется в оперативной памяти, куда считывается блок основной памяти, который вследствие упорядоченности записей по значению ключа должен принять эту запись. Содержимое считанного блока корректируется, и затем он снова записывается на диск на старое место. Естественно, что для добавления записей уже блок основной области должен иметь свободное место. При внесении новой записи индексная область не корректируется.
Уничтожение записи происходит путем ее физического удаления из основной области, при этом индексная область обычно не корректируется, даже если удаляется первая запись блока.
Однако следует отметить:
o с помощью одного неплотного индекса нельзя выполнить проверку наличия некоторого значения;
o в данном хранимом файле может быть, по крайней мере, один неплотный индекс, который организуется по полю, по которому этот файл отсортирован, а остальные индексы обязательно должны быть плотными.
2. Создание отчетов.
Создание отчетов.
Отчеты обеспечивают наиболее гибкий способ просмотра и распечатки итоговой Информации, позволяет отображать и печатать её с любой степенью детализации.
В отчете можно получить результаты сложных расчетов, статистических сравнений, а так же поместить рисунки и диаграммы.
Организация процесса создания отчетов является одним из главных достоинств Access. Широкие возможности по изменению свойств позволяют создавать самые разнообразные отчеты. В новой версии появилась возможность создания безбумажных отчетов. В Access все отчеты подразделяются на шесть категорий:
1. Одностолбцовые отчеты. В одном длинном столбце перечисляются значения всех полей таблицы или запроса.
2. Ленточные отчеты. Значения каждой записи помещаются в отдельную строку.
3.
Многостолбцовые
отчеты. Они создаются
из одностолбцовых отчетов.
Информация, не
помещающаяся в первый столбец, переходит в верхнюю
часть второго столбца и
т. д.
4. Отчеты с группировкой данных. Позволяют вычислять итоговые значения для групп записей и представляют информацию в удобном для использования виде.
5. Почтовые наклейки. Используются для печати имен и адресов.
6. Свободные отчеты. Содержат подчиненные отчеты, при этом каждый подчиненный отчет создается на основе независимых источников данных.
Существует два способа создания отчетов:
1) Создание отчета в режиме конструктора;
2) Создание отчета с помощью мастера.
Открываем закладку Отчет, затем входим в раздел «Создание отчета с помощью мастера», откроется окно, в котором нужно указать
¾ имя таблицы, которую хотим использовать;
¾ добавить поля таблицы, которые должны быть отображены в отчете;
¾ отсортировать поля, если это надо;
Затем выбрать вид макета и требуемый стиль печати, после завершения работы мастера будет показан отчет с введенными данными.
С помощью конструктора можно перестроить поля, и внешний вид, добавить другие компоненты.
Перед печатью отчета, его можно просмотреть – Просмотр отчета.








Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.