Эконометрика– молодая наука, которая своим происхождение обязана развитию статистики и совершенствованию ее методов с одной стороны. С другой стороны эконометрика многим обязана в своем становлении и развитии укреплению позиций системного подхода в современной науке в целом и особенно усовершенствованию математических методов и моделей в экономике. Формирование эконометрики в качестве самостоятельной науки (а не просто раздела статистики) относится к первой трети 20 века и окончательное ее утверждение в виде важного самостоятельного направления в экономических исследованиях относят к середине 20 века.Эконометрика– молодая наука, которая своим происхождение обязана развитию статистики и совершенствованию ее методов с одной стороны. С другой стороны эконометрика многим обязана в своем становлении и развитии укреплению позиций системного подхода в современной науке в целом и особенно усовершенствованию математических методов и моделей в экономике. Формирование эконометрики в качестве самостоятельной науки (а не просто раздела статистики) относится к первой трети 20 века и окончательное ее утверждение в виде важного самостоятельного направления в экономических исследованиях относят к середине 20 века.
рассматривает модели реальных экономических систем, которые значительно ближе к реальным рыночным процессам, чем модели экономической теории и в то же время характеризуются значительно большей целостностью (Эконометрика общесистемным подходом) по сравнению с старыми статистическими моделями. Последние нередко представляли эклектический набор разрозненных методов, искусственно собранных вместе и не объединенных одной интегрирующей идеей. Сами эконометрические модели – это по сути своей математические модели, а именно, уравнения (уравнения регрессии), не учитывающие упорядоченности данных во времени; математические соотношения, известные как временные ряды и фактически тоже своеобразные уравнения, описывающие процессы с дискретным временем, развитие их в хронологически упорядоченной последовательности; наконец, системы уравнений (системы эконометрических уравнений), которые успешно применяются для описания макроэкономических процессов и систем.
Несколько конкретнее эконометрика - это существенно междисциплинарная наука, возникшая на стыке экономики, высших методов статистики, математической статистики и в самое последнее время информационных технологий, эффективно реализующих интеграцию этих наук. От первых простейших попыток применения точных количественных методов математики к экономическим проблемам она довольно быстро перешла к использованию методов математической статистики для решения задач экономики и успешно развивает применение математической статистики и даже теории нечетких множеств и нечеткой логики к исследованию сложных процессов социально-экономической природы.
Еще в рамках статистики – способствуя зарождению эконометрики – ученые-экономисты и статистики занимались исследованием макроэкономических проблем на основе временных рядов таких показателей, как валютные курсы и пр. Изучался рынок труда, разрабатывались методы статистической проверки теории производительности организации труда на производстве. Приблизительно в это время (19 век) метод множественной регрессии был применен для оценки функции спроса.
Следующим важным этапом стали работы по применению основных методов математической статистики (корреляционно-регрессионного анализа, анализа временных рядов, метода множественной регрессии) для изучения социально-экономических явлений и процессов, включая оценку функции спроса. Тогда же (первая половина XX века) выполнялись исследования по циклическим процессам в экономике и выделению бизнес-циклов. Так изучение динамики временных рядов и экстраполяция подмеченных закономерностей в сочетании с использованием некоторых базовых теоретических предпосылок привело к построению экономических барометров (гарвардский барометр). Концепция экономического барометра использует следующую важную идею: в динамике различных компонентов экономического процесса имеются такие показатели, изменение которых опережает изменение других компонентов. Таким образом, показатели, изменение которых опережает в своем развитии изменение других показателей, являются в некотором роде предвестниками последних. Конкретно для гарвардского барометра имеется 5 групп показателей. Они затем сводятся в три отдельные кривые: одна характеризует фондовый рынок, другая – товарный рынок, третья кривая – денежный рынок. В основу прогноза с использованием гарвардского барометра было положено свойство каждой отдельной кривой повторять движение остальных кривых в определенной последовательности и с определенным отставанием.
Однако в конце первой трети двадцатого века эффективность подобных методов стала снижаться и их применение сошло на нет. Это связано с существенным изменением структуры мировых экономических отношений и изменением природы регулирующих факторов в экономике, в частности переходом к кейнсианской модели воздействия на экономику со стороны государства. Одновременно пытались применить методы Фурье-анализа и периодограмм к эконометрическим построениям.
Необходимость использования моделирования (в эконометрике это особенно очевидно), а не простого совершенствования вычислительных методов определяется тем, что многие объекты (или проблемы, относящиеся к этим объектам) непосредственно исследовать или вовсе невозможно, или же это исследование требует много времени и средств. Процесс моделирования включает три элемента: 1) субъект (исследователь), 2) объект исследования, 3)модель, опосредствующую отношения познающего субъекта и познаваемого объекта. Модель сначала строится – первый этап; затем исследуется – второй этап; после этого полученные знания аккуратно переносятся на исследуемую реальную систему – третий этап. Только после этого переходят к практической проверке и использованию полученных выводов (знаний) в реальной жизни, например, решению задачи прогноза – четвертый этап.
На этапе построения модели используются гипотезы о виде статистической зависимости и определяются неизвестные (на этом этапе) коэффициенты (параметры) моделей при помощи метода наименьших квадратов (МНК). Далее модель исследуется с применением методов математической статистики (проверки гипотез) – второй этап. На третьем этапе выполняются наиболее сложные и тонкие процессы переноса полученных знаний о модели на реальную систему – они требуют особого внимания и аккуратности. Затем наступает наиболее ответственный четвертый этап проверки полученных выводов в реальных условиях и их соответствующего применения, которые не выполняются автоматически, а требуют особого внимания к границам применимости этих выводов.
ЛЕКЦИЯ 1. ПОСТРОЕНИЕ МОДЕЛИ: ОПРЕДЕЛЕНИЕ
ПАРАМЕТРОВ МОДЕЛИ (МНК).
Вернемся к первому этапу. После формирования гипотезы о виде зависимости (функционального вида правой части уравнения регрессии) необходимо выполнить определение входящих в уравнение коэффициентов – подбор параметров зависимости - и тем самым установить окончательно модель явления. Это осуществляется методом наименьших квадратов (МНК). Получающаяся модель проверяется на значимость с помощью различных критериев, представляющих основу статистической проверки гипотез, например, если
yi = f(xi) + εi , где f(xi)=ao + a1x (1.2)
то коэффициенты определяются по МНК условием обращения в минимум функции
∑(yi-ao-a1x)2→min, (1.3)
где требование минимизации квадратов отклонений приводит к системе нормальных уравнений (линейные алгебраические уравнения особого вида) для нахождения из нее коэффициентов ai.
В экономике и, следовательно, в эконометрике исследуемые явления и характеризующие их величины это сложные случайные процессы и случайные величины, параметры этих процессов. Случайные величины в процессе анализа представляются состоящими из постоянной компоненты и случайной компоненты. При этом постоянная составляющая это математическое ожидание, или среднее арифметическое (среднее) значение исходной случайной величины:
= (1.4)
Если же данные не сгруппированы, то все частоты f равны 1 и получаем формулу простого среднего:
(1.5)
Среднее случайной компоненты, или остатка равно нулю. Если бы это оказалось не так, то это ненулевое значение следовало бы включить в среднее значение исходной случайной величины и, таким образом, все свелось бы к предыдущему. Мера разброса (вариации) случайной величины, или, что то же, ее распределения, - это дисперсия.
Первоначально дисперсия определяется как среднее квадрата разности между самой случайной величиной и средним этой случайной величины:
Var(χ) = 2 = (1.6)
В этом выражении коэффициенты ƒ не что иное как веса, или весовые коэффициенты значений величины χ . Это попросту величины, показывающие сколько раз входят те или иные значения в данное эмпирическое распределение величины χ для дискретных распределений или же в данный интервал (данную группу) для непрерывных распределений.
Часто при расчетах используют выражение для дисперсии в виде разности среднего от квадрата исходной случайной величины и квадрата среднего от нее:
σ2 = - (1.7)
Тогда окончательно для дисперсии исходной случайной величины получаем, что она равна дисперсии остатка, поскольку вся вариация исходной случайной величины равна вариации остатка, просто по самому определению остатка.
В действительности, кроме самых простых и редких случаев, неизвестно распределение случайной величины и даже основные характеристики изучаемой генеральной совокупности. Требуется получить информацию о случайной величине, характеризующей данное явление или процесс или соответственно генеральной совокупности, из результатов наблюдений. Совокупность результатов наблюдений представляет собой выборку из генеральной совокупности и по этим данным (выборки) с применением подходящей формулы и методов оценивания (прежде всего метода наименьших квадратов) получают приближенное значение неизвестной характеристики (параметра) исследуемой случайной величины или в терминах статистики генеральной совокупности.
Эконометрика использует для изучения различных явлений и процессов признаки, характеризующие эти явления и процессы. Признаки могут быть количественными и атрибутивными, не поддающимися непосредственно количественному измерению. Эконометрика сосредоточена преимущественно на исследовании явлений и процессов, характеризующихся количественными признаками. Тем не менее, она способна исследовать и взаимосвязи между атрибутивными (не количественными) признаками. Сами количественные признаки это фактически случайные величины, которые описываются своими распределениями (совокупностью принимаемых значений и совокупностью вероятностей, с которыми эти значения принимаются). Соответственно для признаков определяются средние, а сами случайные величины могут быть представлены в виде суммы средней и остатка, характеризующего случайные флуктуации.
у = + ε, (1.8)
где средняя (первое слагаемое) может быть приближена или просто заменена некоторой функцией, например линейной:
= ao + a1x (1.9)
Это представление имеет глубокий смысл и будет неоднократно использоваться и обсуждаться далее. Далее помимо среднего для признака как для случайной величины определяется дисперсия, которая служит мерой вариации признака в целом (интегральная характеристика колеблемости признака).
D=σ2= (1.10)
Эконометрика исследует взаимозависимости между признаками и динамику их изменения во времени. Признаки, зависящие от других называются зависимыми, или объясняющими. Признаки от которых зависят первые (зависимые) называются независимыми, или факторами, или регрессорами. Далее мы увидим, что их так называемая независимость друг от друга отнюдь не носит абсолютный характер. Тем не менее понятие независимости факторов является весьма важным и весьма полезным начальным предположением. После исследования соответствующих базовых моделей начального уровня удается строить и изучать более сложные и более совершенные модели, в которых возможно учитывать частичную зависимость факторов.
Также естественно, что в качестве начальных базовых моделей используются простейшие зависимости, например линейные. После этого рассматривают модели, которые можно преобразовать к линейным. И наконец, только после этого существенно нелинейные модели. О том, каков точный смысл этих понятий речь пойдет в следующих лекциях.
Прежде всего, необходимо определить остаток (иначе отклонения, или погрешности) для каждого конкретного наблюдения. Этот остаток после принятия гипотезы линейной зависимости определяется как разность между фактическим значением наблюденной зависимой величины у и ее расчетным значением, получаемым по значению фактора х и формуле линейной зависимости у от х.
Линия графика (линейной зависимости), или линия регрессии должна быть такова, чтобы указанные остатки являлись минимальными. Как понимать требование минимальности именно всех остатков? Ведь уменьшая одни остатки, мы всегда с необходимостью будем увеличивать другие. Наилучший способ это потребовать минимизации суммы квадратов остатков. Остатки еще называют отклонения. В этом случае говорят о минимизации суммы квадратов отклонений. Это одно и то же. Наилучшее соответствие кривой точкам наблюдений получилось бы в предельном случае абсолютно точного соответствия, когда кривая (в нашем случае прямая) пройдет точно через все точки. Но это нереально для линии регрессии, ввиду наличия случайного члена и ошибок наблюдений.
Именно описанный только что принцип минимизации квадратов остатков и его реализация называются методом наименьших квадратов (МНК). Поскольку существует также модификация и развитие его, то говорят также о традиционном, или обычном МНК. В математике (математической статистике и теории приближенных вычислений) МНК рассматривается в качестве одного из наиболее важных и эффективных методов приближенных вычислений и методов оценивания. По существу именно ситуации, когда система алгебраических линейных уравнений не имеет точного решения, является наиболее общей и важной с практической точки зрения. И в большинстве случаев удается найти содержательные приближенные решения, дающие ответ на вопросы, поставленные в данной задаче.
Важно понимать, что в МНК переменные и коэффициенты как бы меняются местами. Из требования минимизации суммы квадратов остатков вытекает довольно простая система линейных алгебраических уравнений. Она называется нормальная система, или система нормальных уравнений. В этой системе уравнений в качестве известных величин выступают величины, получаемые в результате перемножения, возведения в квадрат и последующего суммирования наблюденных значений переменных. Надо отчетливо понимать, что, несмотря на свой нередко относительно громоздкий вид, это всего лишь известные величины, играющие теперь роль коэффициентов системы. С другой стороны сами исходные коэффициенты линейной зависимости (параметры) неизвестны. Именно их и надо определить из системы нормальных уравнений.
Для решения системы алгебраических линейных уравнений существуют различные методы от простого исключения переменных до использования определителей и обратных матриц, метод Гаусса, систематизирующий и обобщающий исключение переменных и называемый поэтому методом последовательного исключения неизвестных. Для случая двух переменных эти формулы нахождения решения системы нормальных уравнений довольно просты. Для множественной регрессии, когда рассматриваются зависимости от множества факторов такие формулы становятся более громоздкими.
Важно то, что в очень большом количестве исследуемых ситуаций выборочная дисперсия весьма близка к генеральной дисперсии и является хорошим приближением и тем самым хорошей оценкой для генеральной дисперсии, кроме отдельных специальных случаев. В то же время выборочное среднее не является достаточно хорошей оценкой, а служит всего лишь грубым первоначальным приближением к оценке генерального среднего, которое уточняется с помощью формул, использующих выборочную дисперсию.
Итак, оценки – это приближения к неизвестным величинам с некоторыми важными хорошими свойствами. Опираясь на оценки важнейших характеристик случайных величин, выявляют и исследуют связи между ними, определяют величину этих связей, исходя из важнейших показателей, характеризующих статистические зависимости между величинами и процессами. Мерой взаимосвязи между переменными является выборочная ковариация, которая для последовательности наблюдений двух переменных представляет среднее произведений разностей результатов наблюдений и их соответствующих средних. Есть другая форма вычисления ковариации, когда она представляется в виде среднего попарных произведений соответствующих результатов наблюдений этих двух переменных, из которого вычитается произведение средних этих двух переменных:
Cov(x,y)=å(x-`x)(y-`y)/n=[(∑xy)/n] – [ ] (1.11)
Ковариация легко вычисляется, но при всей ее простоте она вовсе не является наилучшим измерителем взаимосвязи между величинами. Более точно характеризует зависимость коэффициент корреляции. Выборочный коэффициент корреляции, или просто выборочная корреляция это просто частное от деления выборочной ковариации на произведение выборочных дисперсий соответствующих переменных. Преимущество коэффициента корреляции перед ковариацией заключается в том, что ковариация зависит от единиц, в которых измеряются переменные, коэффициент корреляции это величина безразмерная.
r=Cov(x,y)/Övar(x)var(y) (1.12)Два из этих отрезков образуют зону неопределенности. Три других отрезка соответственно дают, что нет оснований отклонять гипотезу об отсутствии автокорреляции, есть положительная автокорреляция, есть отрицательная автокорреляция. При попадании в зону неопределенности практически считают, что имеется существование автокорреляции остатков и поэтому отклоняют гипотезу об отсутствии автокорреляции остатков.
ЭКОНОМЕТРИКА ДЛЯ ЗАОЧНИКОВ.
КРАТКОЕ ИСТОРИЧЕСКОЕ ВВЕДЕНИЕ
Эконометрика– молодая наука, которая своим происхождение обязана
развитию статистики и совершенствованию ее методов с одной стороны. С
другой стороны эконометрика многим обязана в своем становлении и
развитии укреплению позиций системного подхода в современной науке в
целом и особенно усовершенствованию математических методов и моделей в
экономике. Формирование эконометрики в качестве самостоятельной науки (а
не просто раздела статистики) относится к первой трети 20 века и
окончательное ее утверждение в виде важного самостоятельного направления
в экономических исследованиях относят к середине 20 века.
Эконометрика рассматривает модели реальных экономических систем,
которые значительно ближе к реальным рыночным процессам, чем модели
экономической теории и в то же время характеризуются значительно большей
целостностью (общесистемным подходом) по сравнению с старыми
статистическими моделями. Последние нередко представляли эклектический
набор разрозненных методов, искусственно собранных вместе и не
объединенных одной интегрирующей идеей. Сами эконометрические модели –
это по сути своей математические модели, а именно, уравнения (уравнения
регрессии), не учитывающие упорядоченности данных во времени;
математические соотношения, известные как временные ряды и фактически
тоже своеобразные уравнения, описывающие процессы с дискретным
временем, развитие их в хронологически упорядоченной последовательности;
наконец, системы уравнений (системы эконометрических уравнений), которые
успешно применяются для описания макроэкономических процессов и
систем.
это
Несколько конкретнее эконометрика
существенно
междисциплинарная наука, возникшая на стыке экономики, высших
методов статистики, математической статистики и в самое последнее
время информационных технологий,
эффективно реализующих
интеграцию этих наук. От первых простейших попыток применения точных
количественных методов математики к экономическим проблемам она
довольно быстро перешла к использованию методов математической
статистики для решения задач экономики и успешно развивает применение
1математической статистики и даже теории нечетких множеств и
нечеткой логики к исследованию сложных процессов социально
экономической природы.
статистики
Еще в рамках статистики – способствуя зарождению эконометрики –
ученыеэкономисты и
исследованием
макроэкономических проблем на основе временных рядов таких показателей,
как валютные курсы и пр. Изучался рынок труда, разрабатывались методы
статистической проверки теории производительности организации труда на
производстве. Приблизительно в это время (19 век) метод множественной
регрессии был применен для оценки функции спроса.
занимались
Следующим важным этапом стали работы по применению основных
методов математической статистики (корреляционнорегрессионного анализа,
анализа временных рядов, метода множественной регрессии) для изучения
социальноэкономических явлений и процессов, включая оценку функции
спроса. Тогда же (первая половина XX века) выполнялись исследования по
циклическим процессам в экономике и выделению бизнесциклов. Так
изучение динамики временных рядов и экстраполяция подмеченных
закономерностей в сочетании с использованием некоторых базовых
теоретических предпосылок привело к построению экономических
барометров (гарвардский барометр). Концепция экономического барометра
использует следующую важную идею: в динамике различных компонентов
экономического процесса имеются такие показатели, изменение которых
опережает изменение других компонентов. Таким образом, показатели,
изменение которых опережает в своем развитии изменение других
показателей, являются в некотором роде предвестниками последних.
Конкретно для гарвардского барометра имеется 5 групп показателей. Они
затем сводятся в три отдельные кривые: одна характеризует фондовый
рынок, другая – товарный рынок, третья кривая – денежный рынок. В
основу прогноза с использованием гарвардского барометра было положено
свойство каждой отдельной кривой повторять движение остальных
кривых в определенной последовательности и с определенным
отставанием.
Однако в конце первой трети двадцатого века эффективность подобных
методов стала снижаться и их применение сошло на нет. Это связано с
существенным изменением структуры мировых экономических
отношений и изменением природы регулирующих факторов в экономике,
в частности переходом к кейнсианской модели воздействия на экономику
со стороны государства. Одновременно пытались применить методы Фурье
анализа и периодограмм к эконометрическим построениям.
Необходимость использования моделирования (в эконометрике это
особенно очевидно), а не простого совершенствования вычислительных
методов определяется тем, что многие объекты (или проблемы, относящиеся
2к этим объектам) непосредственно исследовать или вовсе невозможно, или же
это исследование требует много времени и средств. Процесс моделирования
включает три элемента: 1) субъект (исследователь), 2) объект исследования,
3)модель, опосредствующую отношения познающего субъекта и познаваемого
объекта. Модель сначала строится – первый этап; затем исследуется –
второй этап; после этого полученные знания аккуратно переносятся на
исследуемую реальную систему – третий этап. Только после этого
переходят к практической проверке и использованию полученных выводов
(знаний) в реальной жизни, например, решению задачи прогноза – четвертый
этап.
На этапе построения модели используются гипотезы о виде
статистической зависимости и определяются неизвестные (на этом этапе)
коэффициенты (параметры) моделей при помощи метода наименьших
квадратов (МНК). Далее модель исследуется с применением методов
математической статистики (проверки гипотез) – второй этап. На третьем
этапе выполняются наиболее сложные и тонкие процессы переноса
полученных знаний о модели на реальную систему – они требуют особого
внимания и аккуратности. Затем наступает наиболее ответственный
четвертый этап проверки полученных выводов в реальных условиях и их
соответствующего применения, которые не выполняются автоматически, а
требуют особого внимания к границам применимости этих выводов.
ЛЕКЦИЯ 1. ПОСТРОЕНИЕ МОДЕЛИ: ОПРЕДЕЛЕНИЕ
ПАРАМЕТРОВ МОДЕЛИ (МНК).
Вернемся к первому этапу. После формирования гипотезы о виде
зависимости (функционального вида правой части уравнения регрессии)
необходимо выполнить определение входящих в уравнение коэффициентов –
подбор параметров зависимости и тем самым установить окончательно
модель явления. Это осуществляется методом наименьших квадратов (МНК).
Получающаяся модель проверяется на значимость с помощью различных
критериев, представляющих основу статистической проверки гипотез,
например, если
yi = f(xi) + εi , где f(xi)=ao + a1x (1.2)
то коэффициенты определяются по МНК условием обращения в минимум
функции
∑(yiaoa1x)2→min, (1.3)
где требование минимизации квадратов отклонений приводит к системе
нормальных уравнений (линейные алгебраические уравнения особого вида)
для нахождения из нее коэффициентов ai.
3В экономике и, следовательно, в эконометрике исследуемые явления и
характеризующие их величины это сложные случайные процессы и случайные
величины, параметры этих процессов. Случайные величины в процессе
анализа представляются состоящими из постоянной компоненты и случайной
компоненты. При этом постоянная составляющая это математическое
ожидание, или среднее арифметическое (среднее) значение исходной
случайной величины:
х =
хf
f
(1.4)
Если же данные не сгруппированы, то все частоты f равны 1 и получаем
формулу простого среднего:
х
n
х
(1.5)
Среднее случайной компоненты, или остатка равно нулю. Если бы это
оказалось не так, то это ненулевое значение следовало бы включить в среднее
значение исходной случайной величины и, таким образом, все свелось бы к
предыдущему. Мера разброса (вариации) случайной величины, или, что то же,
ее распределения, это дисперсия.
Первоначально дисперсия определяется как среднее квадрата разности
между самой случайной величиной и средним этой случайной величины:
Var(χ) = 2 =
x
x
f
2
f
(1.6)
В этом выражении коэффициенты ƒ не что иное как веса, или весовые
. Это попросту величины, показывающие
коэффициенты значений величины
сколько раз входят те или иные значения в данное эмпирическое
распределение величины
для дискретных распределений или же в данный
интервал (данную группу) для непрерывных распределений.
χ
χ
Часто при расчетах используют выражение для дисперсии в виде
разности среднего от квадрата исходной случайной величины и квадрата
среднего от нее:
σ2 =
2х
2х (1.7)
Тогда окончательно для дисперсии исходной случайной величины
получаем, что она равна дисперсии остатка, поскольку вся вариация исходной
случайной величины равна вариации остатка, просто по самому определению
остатка.
В действительности, кроме самых простых и редких случаев, неизвестно
распределение случайной величины и даже основные характеристики
изучаемой генеральной совокупности. Требуется получить информацию о
случайной величине, характеризующей данное явление или процесс или
соответственно генеральной совокупности, из результатов наблюдений.
Совокупность результатов наблюдений представляет собой выборку из
генеральной совокупности и по этим данным (выборки) с применением
4подходящей формулы и методов оценивания (прежде всего метода
наименьших квадратов) получают приближенное значение неизвестной
характеристики (параметра) исследуемой случайной величины или в терминах
статистики генеральной совокупности.
Эконометрика использует для изучения различных явлений и процессов
признаки, характеризующие эти явления и процессы. Признаки могут быть
количественными и атрибутивными, не поддающимися непосредственно
количественному измерению. Эконометрика сосредоточена преимущественно
на исследовании явлений и процессов, характеризующихся количественными
признаками. Тем не менее, она способна исследовать и взаимосвязи между
атрибутивными (не количественными) признаками. Сами количественные
признаки это фактически случайные величины, которые описываются своими
распределениями (совокупностью принимаемых значений и совокупностью
вероятностей, с которыми эти значения принимаются). Соответственно для
признаков определяются средние, а сами случайные величины могут быть
представлены в виде суммы средней и остатка, характеризующего случайные
флуктуации.
ε
у = у +
, (1.8)
где средняя (первое слагаемое) может быть приближена или просто заменена
некоторой функцией, например линейной:
= ao + a1x (1.9)
у
Это представление имеет глубокий смысл и будет неоднократно
использоваться и обсуждаться далее. Далее помимо среднего для признака
как для случайной величины определяется дисперсия, которая служит мерой
вариации признака в целом (интегральная характеристика колеблемости
признака).
D=σ2=
2
f
y
y
yf
(1.10)
Эконометрика исследует взаимозависимости между признаками и
динамику их изменения во времени. Признаки, зависящие от других
называются зависимыми, или объясняющими. Признаки от которых зависят
первые (зависимые) называются независимыми, или факторами, или
регрессорами. Далее мы увидим, что их так называемая независимость друг от
друга отнюдь не носит абсолютный характер. Тем не менее понятие
независимости факторов является весьма важным и весьма полезным
начальным предположением. После исследования соответствующих базовых
моделей начального уровня удается строить и изучать более сложные и более
совершенные модели, в которых возможно учитывать частичную зависимость
факторов.
Также естественно, что в качестве начальных базовых моделей
используются простейшие зависимости, например линейные. После этого
5рассматривают модели, которые можно преобразовать к линейным. И
наконец, только после этого существенно нелинейные модели. О том, каков
точный смысл этих понятий речь пойдет в следующих лекциях.
Прежде всего, необходимо определить остаток (иначе отклонения, или
погрешности) для каждого конкретного наблюдения. Этот остаток после
принятия гипотезы линейной зависимости определяется как разность между
фактическим значением наблюденной зависимой величины у и ее расчетным
значением, получаемым по значению фактора х и формуле линейной
зависимости у от х.
Линия графика (линейной зависимости), или линия регрессии должна
быть такова, чтобы указанные остатки являлись минимальными. Как понимать
требование минимальности именно всех остатков? Ведь уменьшая одни
остатки, мы всегда с необходимостью будем увеличивать другие. Наилучший
способ это потребовать минимизации суммы квадратов остатков. Остатки еще
называют отклонения. В этом случае говорят о минимизации суммы квадратов
отклонений. Это одно и то же. Наилучшее соответствие кривой точкам
наблюдений получилось бы в предельном случае абсолютно точного
соответствия, когда кривая (в нашем случае прямая) пройдет точно через все
точки. Но это нереально для линии регрессии, ввиду наличия случайного
члена и ошибок наблюдений.
Именно описанный только что принцип минимизации квадратов остатков и
его реализация называются методом наименьших квадратов (МНК).
Поскольку существует также модификация и развитие его, то говорят также о
традиционном, или обычном МНК. В математике (математической статистике
и теории приближенных вычислений) МНК рассматривается в качестве
одного из наиболее важных и эффективных методов приближенных
вычислений и методов оценивания. По существу именно ситуации, когда
система алгебраических линейных уравнений не имеет точного решения,
является наиболее общей и важной с практической точки зрения. И в
большинстве случаев удается найти содержательные приближенные решения,
дающие ответ на вопросы, поставленные в данной задаче.
Важно понимать, что в МНК переменные и коэффициенты как бы
меняются местами. Из требования минимизации суммы квадратов остатков
вытекает довольно простая система линейных алгебраических уравнений. Она
называется нормальная система, или система нормальных уравнений. В
этой системе уравнений в качестве известных величин выступают величины,
получаемые в результате перемножения, возведения в квадрат и
последующего суммирования наблюденных значений переменных. Надо
отчетливо понимать, что, несмотря на свой нередко относительно громоздкий
вид, это всего лишь известные величины, играющие теперь роль
коэффициентов системы. С другой стороны сами исходные коэффициенты
линейной зависимости (параметры) неизвестны. Именно их и надо определить
из системы нормальных уравнений.
6Для решения системы алгебраических линейных уравнений существуют
различные методы от простого исключения переменных до использования
определителей и обратных матриц, метод Гаусса, систематизирующий и
обобщающий исключение переменных и называемый поэтому методом
последовательного исключения неизвестных. Для случая двух переменных эти
формулы нахождения решения системы нормальных уравнений довольно
просты. Для множественной регрессии, когда рассматриваются зависимости
от множества факторов такие формулы становятся более громоздкими.
Важно то, что в очень большом количестве исследуемых ситуаций
выборочная дисперсия весьма близка к генеральной дисперсии и является
хорошим приближением и тем самым хорошей оценкой для генеральной
дисперсии, кроме отдельных специальных случаев. В то же время выборочное
среднее не является достаточно хорошей оценкой, а служит всего лишь
грубым первоначальным приближением к оценке генерального среднего,
которое уточняется с помощью формул, использующих выборочную
дисперсию.
Итак, оценки – это приближения к неизвестным величинам с
некоторыми важными хорошими свойствами. Опираясь на оценки важнейших
характеристик случайных величин, выявляют и исследуют связи между ними,
определяют величину этих связей, исходя из важнейших показателей,
характеризующих статистические зависимости между величинами и
Мерой взаимосвязи между переменными является
процессами.
выборочная ковариация, которая для последовательности наблюдений
двух переменных представляет среднее произведений разностей
результатов наблюдений и их соответствующих средних. Есть другая
форма вычисления ковариации, когда она представляется в виде среднего
попарных произведений соответствующих результатов наблюдений этих двух
переменных, из которого вычитается произведение средних этих двух
переменных:
Cov(x,y)=(x x)(y y)/n=[(∑xy)/n] – [ х у ] (1.11)
Ковариация легко вычисляется, но при всей ее простоте она вовсе не
является наилучшим измерителем взаимосвязи между величинами. Более
точно характеризует зависимость коэффициент корреляции. Выборочный
коэффициент корреляции, или просто выборочная корреляция это просто
частное от деления выборочной ковариации на произведение выборочных
дисперсий соответствующих переменных. Преимущество коэффициента
корреляции перед ковариацией заключается в том, что ковариация зависит от
единиц, в которых измеряются переменные, коэффициент корреляции это
величина безразмерная.
Cov(x,y)/var(x)var(y) (1.12)
Построение модели парной регрессии
7Рассмотрим простой пример элементарного задания по эконометрике. В
соответствии с вариантом задания, используя статистический материал
необходимо.
1. Рассчитать параметры уравнения линейной парной регрессии.
2. Оценить тесноту связи с помощью показателей корреляции и
детерминации.
3. Используя коэффициент эластичности, определить степень связи
факторного признака с результативным.
4. Определить среднюю ошибку аппроксимации.
5. Оценить с помощью F – критерия Фишера статистическую
надежность моделирования.
Исходные данные для построения модели парной регрессии приведены в
таблице 1.
Линейное уравнение парной регрессии имеет вид
y
b
0
, (1.13)
b
1
x
y оценка условного математического ожидания y; b0, b1 –эмпирические
где
коэффициенты регрессии, подлежащие определению.
Таблица 1.1. Исходные данные
Область
№
п/п
1
2
3
4
5
6
Орловская
Рязанская
Смоленская
Тверская
Тульская
Ярославска
я
размер
Средний
назначенных
ежемесячных пенсий,
у.д.е., у
232
215
220
222
231
229
Прожиточный минимум в
среднем на одного пенсионера в
месяц, у.д.е., х
166
199
180
181
186
250
Эмпирические коэффициенты регрессии b0, b1 будем определять с
помощью инструмента «Регрессия» надстройки «Анализ данных»
табличного процессора MS Excel.
Алгоритм определения коэффициентов состоит в следующем .
1. Вводим исходные данные в табличный процессор MS Excel.
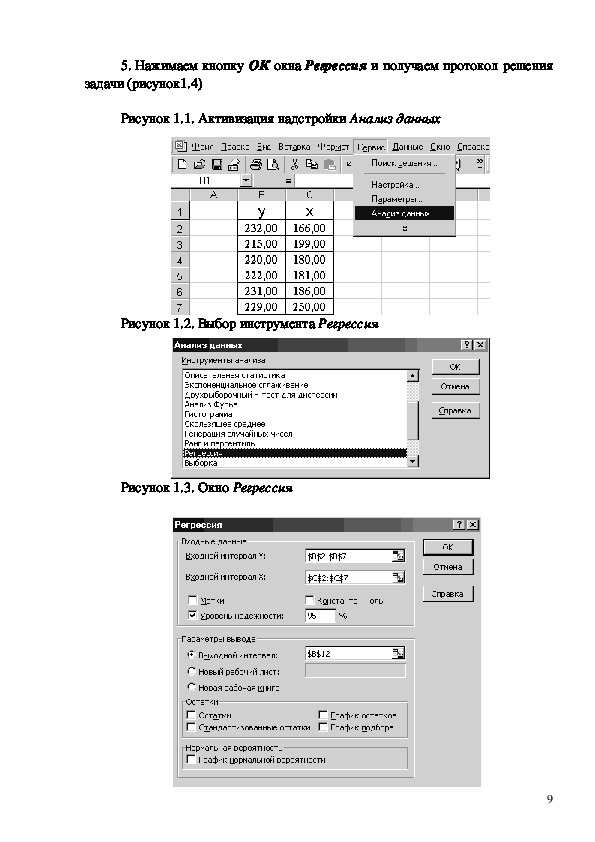
2. Вызываем надстройку Анализ данных (рисунок 1.1).
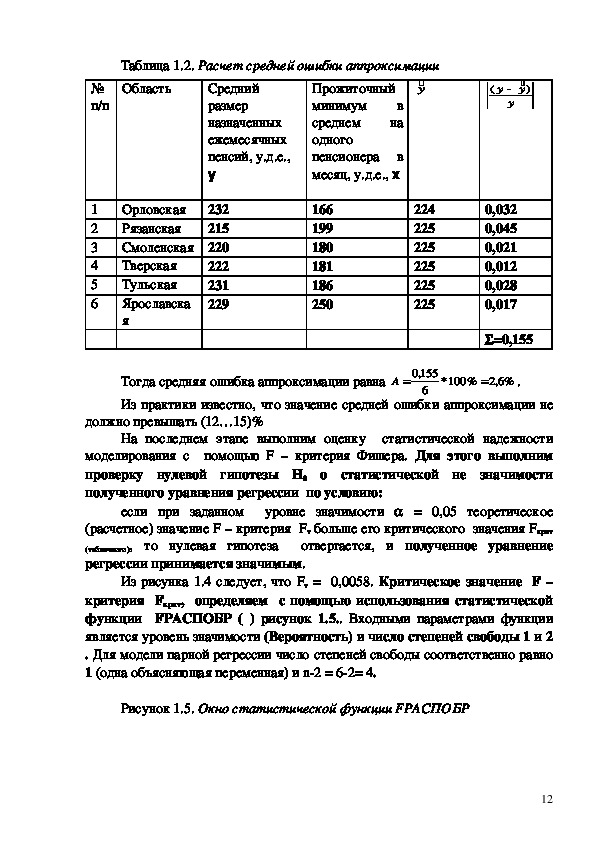
3. Выбираем инструмент анализа Регрессия (рисунок 1.2).
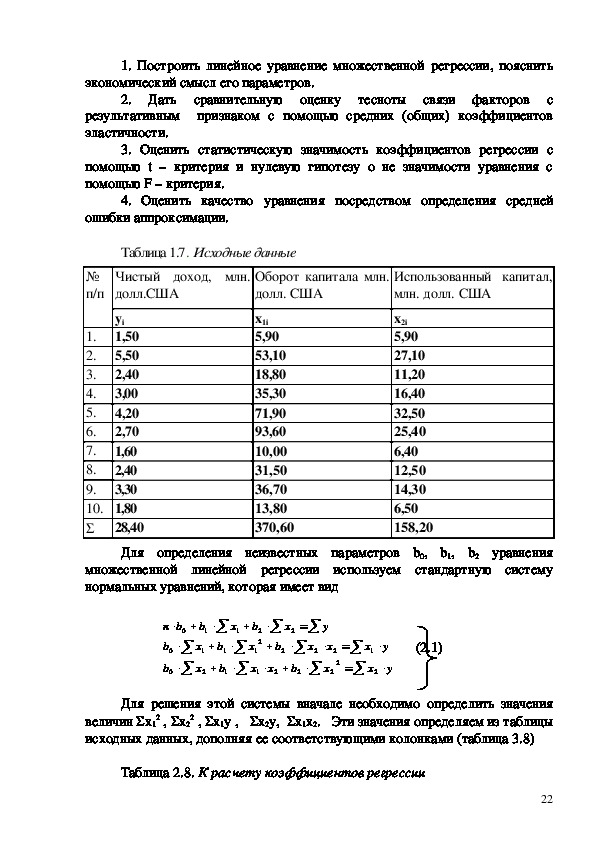
4. Заполняем соответствующие позиции окна Регрессия ( рисунок 1.3).
85. Нажимаем кнопку ОК окна Регрессия и получаем протокол решения
задачи (рисунок1.4)
Рисунок 1.1. Активизация надстройки Анализ данных
Рисунок 1.2. Выбор инструмента Регрессия
Рисунок 1.3. Окно Регрессия
9Рисунок 1.4. Протокол решения задачи
ВЫВОД ИТОГОВ
Регрессионная ст ат ист ика
Множественный R
Rквадрат
Нормированный Rквадрат
Стандартная ошибка
Наблюдения
0,038154922
0,001455798
0,248180252
7,65655705
6
Дисперсионный анализ
Регрессия
Остаток
Итого
Yпересечение
Переменная X 1
df
SS
0,34187
MS
0,34187
1
4 234,4915 58,62287
5 234,8333
F
0,00583168
Значимост ь F
0,94279539
Коэффициент ы
223,1210366
0,008841463
Из рисунка 1.4 видно, что эмпирические коэффициенты регрессии
соответственно равны b0 = 223, b1 = 0, 0088. См. две последние строки под
заголовком коэффициенты
10Тогда уравнение парной линейной регрессии, связывающая величину
ежемесячной пенсии у с величиной прожиточного минимума х, имеет вид
y
223
,0
0088
x
. (1.2)
Далее, в соответствии с заданием необходимо оценить тесноту
статистической связи между величиной прожиточного минимума х и
величиной ежемесячной пенсии у. Эту оценку можно сделать с помощью
коэффициента корреляции r yx . Величина этого коэффициента на
рисунке 1.4. обозначена как множественный R и соответственно равна
=0,038. Поскольку теоретически величина данного коэффициента находится в
пределах от –1 до +1, то можно сделать вывод о не существенности
статистической связи между величиной прожиточного минимума х и
величиной ежемесячной пенсии у.
Параметр «R – квадрат», представленный на рисунке 5 представляет
2 и называется коэффициентом
собой квадрат коэффициента корреляции r yx
детерминации. Величина данного коэффициента характеризует долю
дисперсии зависимой переменной у, объясненную регрессией (объясняющей
2 характеризует долю
переменной х). Соответственно величина 1 r yx
дисперсии переменной у, вызванную влиянием всех остальных, неучтенных
в эконометрической модели объясняющих переменных. Из рисунка 5
видно, что доля всех неучтенных в полученной эконометрической модели
объясняющих переменных приблизительно составляет 1 0,00145 = 0,998 или
99,8%.
На следующем этапе, в соответствии с заданием необходимо определить
степень связи объясняющей переменной х с зависимой переменной у,
используя коэффициент эластичности. Коэффициент эластичности для
модели парной линейной регрессии определяется в виде:
Э ух
1
b
. (1.3)
x
y
7,193
8,224
,0
ухЭ
Тогда
Следовательно, при изменении прожиточного минимума на 1% величина
000758
0088
%
,0
ежемесячной пенсии изменяется на 0,000758%.
Далее определяем среднюю ошибку аппроксимации по зависимости
А
(
y
1
y
n
y
%100
(1.4)
Для этого исходную таблицу 1 дополняем двумя колонками, в которых
рассчитанные с использованием зависимости (3.1.2)
определяем значения, у
у
у
и значения разности
у
.
)
(
11№
п/п
1
2
3
4
5
6
Таблица 1.2. Расчет средней ошибки аппроксимации
Область
у
Средний
размер
назначенных
ежемесячных
пенсий, у.д.е.,
у
Прожиточный
минимум
в
среднем на
одного
пенсионера в
месяц, у.д.е., х
Орловская
Рязанская
Смоленская
Тверская
Тульская
Ярославска
я
232
215
220
222
231
229
166
199
180
181
186
250
224
225
225
225
225
225
(
у
)
у
у
0,032
0,045
0,021
0,012
0,028
0,017
=0,155
Тогда средняя ошибка аппроксимации равна
Из практики известно, что значение средней ошибки аппроксимации не
%6,2%100
А
6
155,0
*
.
должно превышать (12…15)%
На последнем этапе выполним оценку статистической надежности
моделирования с помощью F – критерия Фишера. Для этого выполним
проверку нулевой гипотезы Н0 о статистической не значимости
полученного уравнения регрессии по условию:
если при заданном уровне значимости = 0,05 теоретическое
(расчетное) значение F – критерия Fт больше его критического значения Fкрит
отвергается, и полученное уравнение
(табличного), то нулевая гипотеза
регрессии принимается значимым.
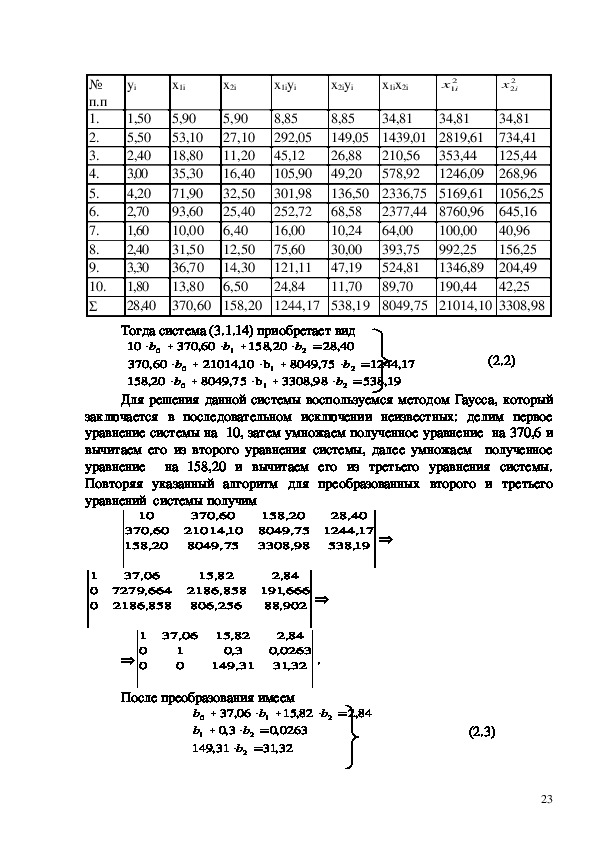
Из рисунка 1.4 следует, что Fт = 0,0058. Критическое значение F –
критерия Fкрит, определяем с помощью использования статистической
функции FРАСПОБР ( ) рисунок 1.5.. Входными параметрами функции
является уровень значимости (Вероятность) и число степеней свободы 1 и 2
. Для модели парной регрессии число степеней свободы соответственно равно
1 (одна объясняющая переменная) и n2 = 62= 4.
Рисунок 1.5. Окно статистической функции FРАСПОБР
12Из рисунка 1.5 видно, что критическое значение F – критерия Fкрит
=7,71.
Так как Fт Fкрит , то нулевая гипотеза не отвергается и полученное
регрессионное уравнение статистически незначимо.
Более сложное задание. Построение модели множественной
регрессии
В соответствии с вариантом задания, используя статистический
материал, необходимо.
1.
Построить линейное уравнение множественной регрессии
пояснить экономический смысл его параметров.
2.
Дать сравнительную оценку тесноты связи факторов с
результативным признаком с помощью средних (общих) коэффициентов
эластичности.
3.
Оценить статистическую значимость коэффициентов регрессии с
помощью t – критерия и нулевую гипотезу о значимости уравнения с
помощью F – критерия.
4. Оценить качество уравнения посредством определения средней ошибки
аппроксимации
Исходные данные для построения модели парной регрессии приведены в
таблице 1.3.
Таблица 1.3. Исходные данные
13№
п/п
1
2
3
4
5
6
7
8
9
10
Чистый доход, мл.
долл. США, у
6,6
2,7
1,6
2,4
3,3
1,8
2,4
1,6
1,4
0,9
Оборот капитала,
мл. долл. США, х1
6,9
93,6
10,0
31,5
36,7
13,8
64,8
30,4
12,1
31,3
Использованный капитал,
мл. долл. США, х2
83,6
25,4
6,4
12,5
14,3
6,5
22,7
15,8
9,3
18,9
Технология построения уравнения регрессии аналогична алгоритму,
изложенному в п.п.1.1. Протокол построения уравнения регрессии показан на
рисунке 1.6.
Рисунок 1.6. Протокол решения задачи
0,901759207
0,813169667
ВЫВОД ИТОГОВ
Регрессионная статистика
Множественный R
Rквадрат
Нормированный R
квадрат
0,759789572
Стандартная ошибка 0,789962026
Наблюдения
Дисперсионный
анализ
Регрессия
Остаток
Итого
Yпересечение
Переменная X 1
Переменная X 2
10
MS
9,50635999
0,624040003
df
2
7
9
Коэффициенты tстатистика
2,270238114
1,113140304
0,061275574
0,000592199
0,063902851
5,496523193
F
15,23357468 0,00281881
Значимость F
14Из рисунка 1.6 видно, что эмпирические коэффициенты регрессии
соответственно равны b0 = 1,11, b1 = 0, 0006, b2 = 0, 064.
Тогда уравнение множественной линейной регрессии, связывающая
величину чистого дохода у с оборотом капитала х1 и использованным
капиталом х2 имеет вид имеет вид.
y
11,1
. (1.5)
0006
x
1
,0
064
х
,0
2
На следующем этапе, в соответствии с заданием необходимо определить
степень связи объясняющих переменных х1 и х2 с зависимой переменной у,
используя коэффициенты эластичности. Коэффициенты эластичности для
модели множественной линейной регрессии определяется в виде:
Э
ухi
b
i
x
i
y
. (1.6)
Тогда
ухЭ
1
,0
0006
11,33
47,2
,0
%0008
. (1.7)
Следовательно, при изменении оборота капитала 1% величина чистого
дохода копании изменяется на 0,0008%.
ухЭ
,0
2
064
54,21
47,2
%56,0
.
При изменении использованного капитала на 1% величина чистого
дохода компании изменяется на 0,56%.
На третьем этапе исследования необходимо оценить статистическую
значимость коэффициентов регрессии с помощью t – критерия и нулевую
гипотезу о значимости уравнения с помощью F – критерия.
Технология оценки статистической значимости коэффициентов
регрессии также основывается на проверке нулевой гипотезы о не
значимости коэффициентов регрессии.
При этом проверяется
выполнение условия:
если tт tкрит , то нулевая гипотеза отвергается, и коэффициент
регрессии принимается значимым. Из рисунка 3.6 видно, что tт для первого
коэффициента регрессии равен 0,061, а для второго 5,5. Критическое
значение tкрит при уровне значимости = 0,05определяем с использованием
статистической функции СТЬЮДРАСПОБР ( ) рисунок. Входными
параметрами функции является уровень значимости (Вероятность) и число
степеней свободы. Для рассматриваемого примера число степеней свободы
соответственно равно n3 (так как, для двухфакторной модели
множественной регрессии оценивается три параметра b0 ,b1, b2 ) Тогда число
степеней свободы равно103=7.
15Рисунок 1.7. Окно статистической функции СТЬЮДРАСПОБР
Из рисунка 1.7 видно, что критическое значение tкрит =2,36.
Так как tт tкрит , для первого коэффициента регрессии (0,061 2,36) то
нулевая гипотеза не отвергается и объясняющая переменная х1 является
статистически незначимой и ее можно исключить из уравнения регрессии. И
наоборот, для второго коэффициента регрессии tт tкрит (5,5 2,36), и
объясняющая переменная х2 является статистически значимой.
Проверка значимости уравнения множественной регрессии в целом
с использованием F – критерия аналогична проверке уравнения парной
регрессии.
Из рисунка 3.6 следует, что Fт = 15,23. Критическое значение F –
критерия Fкрит, определяем с помощью использования статистической
функции FРАСПОБР ( ). Для модели множественной регрессии с двумя
переменными число степеней свободы соответственно равно 2
(две
объясняющие переменные х1 и х2) и nk –1(где k=2 – число объясняющих
переменных). И второе число степеней свободы равно103=7. Критическое
значение Fкрит = 4,74. Следовательно:
Fт Fкрит, (15,23 4,74), и уравнение регрессии в целом является
значимым.
На последнем этапе исследования необходимо оценить качество
уравнения посредством определения средней ошибки аппроксимации по
зависимости (1.4). С этой целью представим таблицу 1.3 в виде
вспомогательной таблицы 1.4. Тогда средняя ошибка аппроксимации
составит:
А
Таким образом:
98,2
10
*
%8,29%100
. (1.8)
161. Сформирована эконометрическая модель в виде линейного уравнения
парной регрессии, связывающая величину ежемесячной пенсии у с величиной
прожиточного минимума х:
223
y
0088
,0
x
.
2. На основании анализа численного значения коэффициента
корреляции r yx = 0,038 установлено отсутствие статистической связи между
величиной прожиточного минимума х и величиной ежемесячной пенсии у.
Показано, что доля всех неучтенных в полученной эконометрической модели
объясняющих переменных приблизительно составляет 99,8%.
3. Путем расчета коэффициента эластичности показано, что при
изменении прожиточного минимума на 1% величина ежемесячной пенсии
изменяется несущественно, всего на 0,000758%.
4. Рассчитана средняя ошибка аппроксимации статистических данных
линейным уравнением парной регрессии, которая составила 2,6%, что
является вполне допустимой величиной.
5. С использованием F критерия установлено, что полученное
уравнение парной регрессии в целом является статистически незначимым, и
не адекватно описывает изучаемое явление связи величины ежемесячной
пенсии у с величиной прожиточного минимума х.
6. Сформирована эконометрическая модель множественной линейной
регрессии, связывающая величину чистого дохода условной фирмы у с
х2:
оборотом капитала
y
11,1
и использованным капиталом
064,0
0006
,0
х
x
1
х1
.
2
7. Путем расчета коэффициентов эластичности показано, что при
изменении оборота капитала
1% величина чистого дохода копании
изменяется на 0,0008%, а при изменении использованного капитала на 1%
величина чистого дохода компании изменяется на 0,56%.
8. С использованием t – критерия выполнена оценка статистической
значимость коэффициентов регрессии Установлено, что объясняющая
переменная х1 является статистически незначимой и ее можно исключить из
уравнения регрессии в тоже время объясняющая переменная х2 является
статистически значимой.
9. С использованием F критерия установлено, что полученное
уравнение парной регрессии в целом является статистически значимым, и
адекватно описывает изучаемое явление связи величины чистого дохода
условной фирмы у с оборотом капитала х1 и использованным капиталом х2 .
10. Рассчитана средняя ошибка аппроксимации статистических данных
линейным уравнением множественной регрессии, которая составила 29,8%.
Показано, за счет какого наблюдения в статистической базе величина данной
ошибки превышает допустимое значение.
Построение модели парной регрессии «вручную»
17Используя статистический материал, приведенный в таблице 1.4 необходимо:
1. Рассчитать параметры уравнения линейной парной регрессии.
2. Оценить тесноту связи с помощью показателей корреляции и детерминации.
3. Используя коэффициент эластичности, определить степень связи
факторного признака с результативным.
4. Определить среднюю ошибку аппроксимации.
5. Оценить с помощью Fкритерия Фишера статистическую
надежность моделирования.
Таблица 1.4. Исходные данные.
Область
№
п.п
1. Калужская
2. Костромская
3. Орловская
Рязанская
4.
Смоленская
5.
ИТОГО:
Доля денежных доходов,
направленных на прирост
сбережений во вкладах,
займах, сертификатах и на
покупку валюты, в общей
сумме среднедушевого
денежного дохода, %, yi
8,4
6,1
9,4
11,0
6,4
41,3
Среднемесячная
начисленная заработная
плата, у.д.е., xi
343
356
289
341
327
1656
Для определения неизвестных параметров b0, b1 уравнения парной
линейной регрессии (1) используем стандартную систему нормальных
уравнений, которая имеет вид
bn
0
b
0
b
1
x
x
y
b
1
x
2
(1.9)
yx
Для решения этой системы вначале необходимо определить значения
величин х2 и ху. Эти значения определяем из таблицы исходных данных,
дополняя ее соответствующими колонками (таблица 3.5)
Таблица 1.5. К расчету коэффициентов регрессии
№
п.п
1.
2.
yi
xi
2
ix
x
i y
i
8,4
6,1
343
356
117649
126736
2881,2
2171,6
183.
4.
5.
83251
289
9,4
116281
11,0 341
6,4
106929
327
41,3 1656 551116
2716,6
3751,0
2092,8
13613,2
Тогда система (3.1.9) приобретает вид
b
5
0
1656
1656
b
0
b
1
551116
3,41
1b
13613,2
(1.10)
Выражая из первого уравнения b0 и подставляя полученное выражение ,
во второе уравнение получим
3,41
b
1
b
0
26,8
2,331
b
1
1656
5
13678
b
1
26,8(
b
1
)
2,331
551116
1656
Производя почленное умножение и раскрывая скобки, получим
56,
Откуда
b
1
1
b
13613
13613
13613
13678
2648
025
56,
2,
2,
8,
,0
2,
2648
8,
2648
36,65
8,
26,8
2,331
b
1
Тогда
b
0
Окончательно уравнение парной линейной регрессии, связывающее
величину доли денежных доходов населения, направленных на прирост
сбережений (у ) с величиной среднемесячной начисленной заработной платы
(х) имеет вид
26,8)025
,0(2,331
54,16
28,8
26,8
y
54,16
,0
025
x
(1.11)
Далее, в соответствии с заданием
тесноту
статистической связи зависимой переменной у с объясняющей переменной х с
помощью показателей корреляции и детерминации.
необходимо оценить
Так, как построено уравнение парной линейной регрессии, то определяем
линейный коэффициент корреляции по зависимости
r
xy
xy
xy
y
x
, (1.12)
xб значения среднеквадратических отклонений соответствующих
y
где
параметров.
Для расчета линейного коэффициента корреляции по зависимости
(1.12) выполним промежуточные расчеты
19xy
y
n
n
x
y
x
2
x
(
2
y
5
x
(
x
i
n
y
i
n
2
)
8,
2648
5
;76,529
2
y
)
95,16
;39,3
5
xy
n
13613
2,
5
2722
;64,
3,41
5
;26,8
1656
;2,331
x
76,529
2
x
2
y
Подставляя значения найденных параметров в выражение (1.12)
;02,23
.84,1
39,3
y
получим
2722
2,331
64,
84,102,23
26,8
.
31,0
xyr
Полученное значение линейного коэффициента корреляции
свидетельствует о наличии слабой обратной статистической связи между
величину доли денежных доходов населения, направленных на прирост
сбережений (у) и величины среднемесячной начисленной заработной платы
(х).
2
xyr
Коэффициент детерминации равен
что
означает, что только 9,6% объясняется регрессией объясняющей переменной
2 равная 90,4 %
х на величину у. Соответственно величина 1 r yx
характеризует долю дисперсии переменной у, вызванную влиянием всех
остальных,
неучтенных в эконометрической модели объясняющих
переменных.
)31,0(
0961
,0
,
2
Коэффициент эластичности определяется по зависимости (3.1.3) и
равен
x
y
2,331
26,8
b
1
,0
%1
025
Эух
Следовательно, при изменении величины среднемесячной начисленной
заработной платы на 1% величина величину доли денежных доходов
населения, направленных на прирост сбережений также снижается на 1%,
причем при увеличении заработной платы наблюдается снижении величины
доли денежных доходов населения, направленных на прирост сбережений
снижение. Данный вывод противоречит здравому смыслу и может быть
объяснен только некорректностью сформированной математической модели.
Для определения средней ошибки аппроксимации воспользуемся
зависимостью (1.4) . Для удобства расчетов преобразуем таблицу 1.4 к виду
рассчитаны текущие значения
таблица 1.6 В данной таблице в колонке у
объясняющей переменной с использованием зависимости (1.9).
20Таблица 1.6. К расчету средней ошибки аппроксимации
№
п./п
1.
2.
3.
4.
5.
yi
8,4
6,1
9,4
11,0
6,4
41,3
xi
343
356
289
341
327
1656
y
8,0
7,6
9,3
8,0
8,4
41,3
)
(
у
i
у
у
i
0,048
0,246
0,011
0,273
0,313
0,89
Тогда средняя ошибка аппроксимации равна
А
(
y
1
y
n
%100
89,0
1
5
%8,17%100
y
Полученное значение превышает (12…15)%, что свидетельствует о
существенности среднего отклонения расчетных данных от фактических, по
которым построена эконометрическая модель.
Надежность статистического моделирования выполним на основе F –
критерия Фишера. Технология использования данного критерия приведена в
п.п. 1.2.
Теоретическое значение
соотношения значений факторной
рассчитанных на одну степень свободы по формуле
факторная
критерия Фишера Fт определяется из
остD дисперсий,
и остаточной
D
; (1.13)
(
F
Т
y
m
2
y
)
1
(
y
mn
i
Dфакторная
D
ост
D
факторная
D
)
y
ост
2
.
67,1
1
;67,1
42,15
3
,67,5
где n число наблюдений; m
рассматриваемого примера m =1).
число объясняющих переменных (для
67,1
14,5
ТF
.32,0
Тогда
Критического значения Fкрит, определяется по статистическим таблицам
и для уровня значимости = 0, 05 равняется 10,13. Так как FТ Fкрит, то
нулевая гипотеза не отвергается, и
полученное уравнение регрессии
принимается статистически незначимым.
1.2. Построение модели множественной регрессии
Используя статистический материал, приведенный в таблице 1.7
необходимо:
211. Построить линейное уравнение множественной регрессии, пояснить
экономический смысл его параметров.
2. Дать сравнительную оценку тесноты связи факторов с
результативным признаком с помощью средних (общих) коэффициентов
эластичности.
3. Оценить статистическую значимость коэффициентов регрессии с
помощью t – критерия и нулевую гипотезу о не значимости уравнения с
помощью F – критерия.
4. Оценить качество уравнения посредством определения средней
ошибки аппроксимации.
№
п/п
Таблица 1.7. Исходные данные
Чистый доход, млн.
Использованный капитал,
долл.США
млн. долл. США
yi
x2i
1,50
5,90
1.
5,50
27,10
2.
2,40
11,20
3.
3,00
16,40
4.
4,20
32,50
5.
2,70
25,40
6.
1,60
6,40
7.
2,40
12,50
8.
3,30
14,30
9.
10. 1,80
6,50
28,40
158,20
Для определения неизвестных параметров b0,
Оборот капитала млн.
долл. США
x1i
5,90
53,10
18,80
35,30
71,90
93,60
10,00
31,50
36,70
13,80
370,60
b1, b2 уравнения
множественной линейной регрессии используем стандартную систему
нормальных уравнений, которая имеет вид
b
bn
0
b
0
0
b
1
b
1
x
1
x
b
1
2
x
1
b
x
1
2
2
x
1
b
2
x
2
x
2
x
b
2
2
y
x
2
2
x
2
x
1
x
y
(2.1)
y
2
Для решения этой системы вначале необходимо определить значения
2 , х1у , х2у, х1х2. Эти значения определяем из таблицы
величин х1
исходных данных, дополняя ее соответствующими колонками (таблица 3.8)
2 , х2
Таблица 2.8. К расчету коэффициентов регрессии
22yi
x1i
x2i
x1iyi
x2iyi
x1ix2i
2
1ix
2
2ix
34,81
34,81
5,90
27,10
11,20
16,40
32,50
25,40
6,40
12,50
14,30
6,50
8,85
292,05
45,12
105,90
301,98
252,72
16,00
75,60
121,11
24,84
210,56
578,92
8,85
149,05 1439,01 2819,61
353,44
26,88
49,20
1246,09
136,50 2336,75 5169,61
2377,44 8760,96
68,58
10,24
64,00
100,00
992,25
393,75
30,00
47,19
524,81
1346,89
190,44
89,70
11,70
34,81
734,41
125,44
268,96
1056,25
645,16
40,96
156,25
204,49
42,25
5,90
53,10
18,80
35,30
71,90
93,60
10,00
31,50
36,70
13,80
370,60 158,20 1244,17 538,19 8049,75 21014,10 3308,98
1,50
5,50
2,40
3,00
4,20
2,70
1,60
2,40
3,30
1,80
28,40
Тогда система (3.1.14) приобретает вид
40,28
10
0
b
60,370
75,
b
20,158
Для решения данной системы воспользуемся методом Гаусса, который
заключается в последовательном исключении неизвестных: делим первое
уравнение системы на 10, затем умножаем полученное уравнение на 370,6 и
вычитаем его из второго уравнения системы, далее умножаем полученное
уравнение на 158,20 и вычитаем его из третьего уравнения системы.
Повторяя указанный алгоритм для преобразованных второго и третьего
уравнений системы получим
60,370
b
b
0
b
1
21014
8049
75,
20,158
b
1
b
(2.2)
1244
,19
538
2
b
8049
3308
98,
10,
1
b
0
№
п.п
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
,17
2
2
10
60,370
20,158
60,370
21014
8049
10,
75,
20,158
75,
8049
3308
98,
40,28
1244
17,
19,538
1
0
0
06,37
82,15
84,2
7279
2186
664,
858,
2186
,806
858,
256
666
,191
902,88
1
0
0
06,37
82,15
1
0
3,0
31,149
84,2
0263
,0
32,31
.
После преобразования имеем
b
06,37
b
0
1
,0
b
3,0
b
1
31,149
b
32,31
2
82,15
0263
2
b
2
84,2
(2.3)
23b
2
Откуда
b
1
b
0
,0
84,2
0263
32,31
31,149
3,0
82,15
b
2
b
2
.21,0
0263
,0
06,37
b
1
21,03,0
84,2
82,15
038,0
.
21,0
06,37
038,0
916,0
.
Тогда окончательно зависимость чистого дохода от оборота капитала и
использованного капитала в виде линейного уравнения множественной
регрессии имеет вид
y
(2.4)
x
1
038,0
916,0
21,0
x
2
Из полученного эконометрического уравнения видно,
что с
увеличением используемого капитала чистый доход увеличивается и наоборот
с увеличением оборота капитала, чистый доход уменьшается. Кроме того, чем
больше величина
коэффициента регрессии, тем значительнее влияние
объясняющей переменной на зависимую переменную. В рассматриваемом
примере величина коэффициента регрессии
2b больше чем величина
коэффициента,
1b следовательно, используемый капитал оказывает
значительно большее влияние на чистый доход, чем оборот капитала. Для
количественной оценки указанного вывода определим частные коэффициенты
эластичности.
b
1
%5,0
038
Эx
1
,0
x
1
y
x
2
y
6,37
84,2
82,15
84,2
Эx
2
b
2
21,0
%17,1
Анализ полученных результатов так же показывает, что большее
влияние на чистый доход оказывает используемый капитал. Так в частности,
при увеличении используемого капитала на 1% чистый доход увеличивается
на 1,17%. В то же время с ростом оборота капитала на 1%, чистый доход
снижается на 0,5%.
Теоретическое значение критерия Фишера Fт
D
F
Т
факторная
D
ост
.
где
D
ост
Dфакторная
(
y
mn
i
87,5
34,0
y
(
m
y
)
1
2
382,2
12
10
.034
.26,17
(2.5)
2
y
)
74,11
2
;87,5
Величина критического значения Fкрит, определяется по статистическим
таблицам и для уровня значимости = 0, 05 равняется 4,74. Так как FТ
Fкрит, то нулевая гипотеза отвергается, и полученное уравнение регрессии
принимается статистически значимым.
Оценка статистической значимости коэффициентов регрессии 1b и
2b по tкритерию сводится к сопоставлению численного значения этих
24коэффициентов с величиной их случайных ошибок
зависимости
b
t
i
bi m
Рабочая формула для расчета теоретического значения t – статистики
1bm и
2bm
по
.
bi
имеет вид
b
i
t
bi
1
xi
y
2
r
xx
21
1
R
mn
1
(2.6)
2
yx
21
x
где парные коэффициенты корреляции и коэффициент множественной
корреляции рассчитываются по зависимостям:
82,15
06,37
98,8
84,2
975,804
xxr
21
,124
417
9,0
;
2
x
1
x
2
x
x
1
2
1
x
x
y
x
y
1
1
y
x
x
y
2
2
x
y
2
r
r
1
yx
yx
2
r
1
xx
21
2
y
2
x
1
r
yx
1
x
r
yx
2
2
r
R
yx
21
x
2
1
yx
98,26
06,37
18,198,26
84,2
82,15
18,198,8
2
r
xx
21
2
819,53
r
2
yx
6,0
;
84,0
;
2
6,0
84,0
84,06,02
2
9,01
2
9,0
83,0
.
Тогда фактические, они же
расчетные значения
t статистик
соответственно равны
,0
038
Т
bt
1
98,821,0
Т
bt
2
2
2
98,26
18,1
2
9,01
83,01
10
2
9,01
83,01
18,1
12
.3,3
10
12
,1
.798
Поскольку критическое значение t статистики, определенное по
статистическим таблицам для уровня значимости =0,05 равное tкрит =2,36
больше по абсолютной величине чем Т
bt 1 = 1,798, то нулевая гипотеза
не отвергается и объясняющая переменная х1
является статистически
незначимой и ее можно исключить из уравнения регрессии. И наоборот, для
bt 2 tкрит (3,3 2,36), и объясняющая
второго коэффициента регрессии
переменная х2 является статистически значимой.
Т
Для определения средней ошибки аппроксимации воспользуемся
зависимостью (3.1.4). Для удобства расчетов преобразуем таблицу 2.8 к виду
рассчитаны текущие значения
таблицы 2.9. В данной таблице в колонке у
объясняющей переменной с использованием зависимости (2.3).
Таблица 2.9. К расчету средней ошибки аппроксимации
25№ п.п
yi
x1i
x2i
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
1,50
5,50
2,40
3,00
4,20
2,70
1,60
2,40
3,30
1,80
28,40
5,90
27,10
11,20
16,40
32,50
25,40
6,40
12,50
14,30
6,50
5,90
53,10
18,80
35,30
71,90
93,60
10,00
31,50
36,70
13,80
370,60 158,20
y
1,93
4,59
2,55
3,02
5,01
2,69
1,88
2,34
2,55
1,76
28,30
)
(
у
i
у
у
i
0,286
0,165
0,0625
0,0006
0,193
0,0037
0,175
0,025
0,227
0,022
1,16
Тогда средняя ошибка аппроксимации равна
%100
16,1
1
10
%6,11%100
А
(
y
1
y
n
y
Полученное значение не превышает допустимого предела равного (12…
15)%.
ЛЕКЦИЯ 2. ОБОСНОВАНИЕ КРИТЕРИЕВ ПРОВЕРКИ
СТАТИСТИЧЕСКИХ ГИПОТЕЗ (ЗНАЧИМОСТИ РЕГРЕССИИ)
Вернемся теперь к обоснованию критериев проверки значимости
найденных по методу наименьших квадратов (МНК) параметров модели
регрессии ( и вообще методов проверки статистических гипотез). После того,
как найдено уравнение линейной регрессии, производится оценка значимости
как уравнения в целом, так и отдельных его параметров. Оценка значимости
уравнения регрессии в целом может выполняться с помощью различных
критериев. Достаточно распространенным и эффективным является
применение Fкритерия Фишера. При этом выдвигается нулевая гипотеза. Но,
что коэффициент регрессии равен нулю, т.е. b=0, и, следовательно, фактор х
не оказывает влияния на результат у. Непосредственному расчету Fкритерия
предшествует анализ дисперсии. Центральное место в нем занимает
разложение общей суммы квадратов отклонений переменной у от среднего
значения у на две части «объясненную» и «необъясненную»:
(
YY
2)
ˆ(
XY
2)
Y
(
XYY
ˆ
2)
(2.1)
26Общая сумма квадратов отклонений индивидуальных значений
результативного признака у от среднего значения у вызвана влиянием
множества факторов.
Условно разделим всю совокупность причин на две группы: изучаемый
фактор х и прочие факторы. Если фактор не оказывает влияния на результат,
то линия регрессии на графике параллельна оси ОХ и у=у. Тогда вся
дисперсия результативного признака обусловлена воздействием прочих
факторов и общая сумма квадратов отклонений совпадет с остаточной. Если
же прочие факторы не влияют на результат, то у связан с х функционально и
остаточная сумма квадратов равна нулю. В этом случае сумма квадратов
отклонений, объясненная регрессией, совпадает с общей суммой квадратов.
Поскольку не все точки поля корреляции лежат на линии регрессии, то всегда
имеет место их разброс как обусловленный влиянием фактора х, т.е.
регрессией у по х, так и вызванный действием прочих причин (необъясненная
вариация). Пригодность линии регрессии для прогноза зависит от того, какая
часть общей вариации признака у приходится на объясненную вариацию.
xy
r 2
Очевидно, что если сумма квадратов отклонений, обусловленная
регрессией, будет больше остаточной суммы квадратов, то уравнение
регрессии статистически значимо и фактор х оказывает существенное
воздействие на результату. Это равносильно тому, что коэффициент
детерминации
будет приближаться к единице. Любая сумма квадратов
отклонений связана с числом степеней свободы, т.е. числом свободы
независимого варьирования признака. Число степеней свободы связано с
числом единиц совокупности лис числом определяемых по ней констант.
Применительно к исследуемой проблеме число степеней свободы должно
показать, сколько независимых отклонений из п возможных [(у1у),(у2у),..(уп
у)] требуется для образования данной суммы квадратов. Так, для общей
суммы квадратов ∑(уу)2 требуется (п1) независимых отклонений, т.к. по
совокупности из п единиц после расчета среднего уровня свободно варьируют
лишь (п1) число отклонений. При расчете объясненной или факторной суммы
квадратов ∑(уу)2 используются теоретические (расчетные ) значения
результативного признака у*, найденные по линии регрессии: у(х)=а+bх.
Вернемся теперь к разложению общей суммы квадратов отклонений
результативного фактора от среднего этой величины. Эта сумма содержит две
уже определенные выше части: сумму квадратов отклонений, объясненную
регрессией и другую сумму, которая называется остаточная сумма
квадратов отклонений. С таким разложением связан анализ дисперсии,
который прямо отвечает на принципиальный вопрос: как оценить значимость
уравнения регрессии в целом и его отдельных параметров? Оно же в
значительной мере и определяет смысл этого вопроса. Для оценки значимости
уравнения регрессии в целом используется критерий Фишера (Fкритерий).
Согласно подходу, предложенному Фишером, выдвигается нулевая гипотеза
27оН : коэффициент регрессии равен нулю, т.е. величина b=0. Это означает,
что фактор х не оказывает влияния на результат у.
Вспомним, что практически всегда полученные в результате
статистического исследования точки не ложатся точно на линию регрессии.
Они рассеяны, будучи удалены более или менее сильно от линии регрессии.
Такое рассеяние обусловлено влиянием прочих, отличных от объясняющего
фактора х , факторов, не учитываемых в уравнении регрессии. При расчете
объясненной, или факторной суммы квадратов отклонений используются
теоретические значения результативного признака, найденные по линии
регрессии.
Для заданного набора значений переменных у и х расчетное значение
среднего величины у является в линейной регрессии функцией только одного
параметра – коэффициента регрессии. В соответствии с этим факторная
сумма квадратов отклонений имеет число степеней свободы, равное 1. А
число степеней свободы остаточной суммы квадратов отклонений при
линейной регрессии равно n2.
Следовательно разделив каждую сумму квадратов отклонений в
исходном разложении на свое число степеней свободы получаем средний
квадрат отклонений (дисперсию на одну степень свободы). Далее разделив
факторную дисперсию на одну степень свободы на остаточную дисперсию
на одну степень свободы получаем критерий для проверки нулевой гипотезы
так называемое Fотношение, или одноименный критерий. Именно, при
справедливости нулевой гипотезы факторная и остаточная дисперсии
оказываются просто равны друг другу.
Для отклонения нулевой гипотезы, т.е. принятия противоположной гипотезы,
которая выражает факт значимости (наличия) исследуемой зависимости, а
не просто случайного совпадения факторов, имитирующего зависимость,
которая фактически не существует необходимо использовать таблицы
критических значений указанного отношения. По таблицам выясняют
критическую (пороговую) величину критерия Фишера. Она называется также
теоретической. Затем проверяют сравнивая ее с вычисленным по данным
наблюдений соответствующим эмпирическим (фактическим) значением
критерия, превосходит ли фактическая величина отношения критическую
величину из таблиц.
Более подробно это делается так. Выбирают данный уровень
вероятности наличия нулевой гипотезы и находят по таблицам критическое
значение Fкритерия, при котором еще может происходить случайное
расхождение дисперсий на 1 степень свободы, т.е. максимальное такое
значение. Затем вычисленное значение отношения Fпризнается достоверным
(т.е. выражающим различие фактической и остаточной дисперсий), если это
отношение больше табличного. Тогда нулевая гипотеза отклоняется (неверно,
что отсутствуют признаки связи) и напротив приходим к заключению, что
28связь имеется и является существенной (носит неслучайный, значимый
характер).
В случае, если величина отношения оказывается меньше табличного, то
вероятность нулевой гипотезы оказывается выше заданного уровня (который
выбирался изначально) и нулевая гипотеза не может быть отклонена без
заметной опасности получить неверный вывод о наличии связи.
Соответственно уравнение регрессии считается при этом незначимым.
Сама величина Fкритерия связана с коэффициентом детерминации.
Помимо оценки значимости уравнения регрессии в целом оценивают также
значимость отдельных параметров уравнения регрессии. При этом
определяют стандартную ошибку коэффициента регрессии с помощью
эмпирического фактического среднеквадратичного отклонения и
эмпирической дисперсии на одну степень свободы. После этого используют
распределение Стьюдента для проверки существенности коэффициента
регрессии для расчета его доверительных интервалов.
Оценка значимости коэффициентов регрессии и корреляции с помощью
tкритерия Стьюдента выполняется посредством сопоставления значений этих
величин и величины стандартной ошибки. Величина ошибки параметров
линейной регрессии и коэффициента корреляции определяется по следующим
формулам:
mb
2
и
2
S
x
(
(2.2)
2
x
)
m
rxy
1
n
2
r
xy
2
, (2.3)
где S – среднеквадратичное остаточное выборочное отклонение, rxy –
коэффициент корреляции. Соответственно величина стандартной ошибки,
предсказываемой по линии регрессии, дается формулой:
2
m
yx
2
S
n
S
x
2
2
x
x
2
x
2
S
1
n
x
k
x
x
x
2
2
(2.4)
Соответствующие отношения значений величин коэффициентов
регрессии и корреляции к их стандартной ошибке образуют так называемую t
статистику, а сравнение соответствующего табличного (критического)
значения ее и ее фактического значения позволяет принять или отвергнуть
нулевую гипотезу. Нo далее для расчета доверительного интервала находится
предельная ошибка для каждого показателя как произведение табличного
значения статистики t на среднюю случайную ошибку соответствующего
показателя. По сути, чуть иначе мы уже фактически записали ее только что
выше. Затем получают границы доверительных интервалов: нижнюю границу
вычитанием из соответствующих коэффициентов (фактически средних)
29соответствующей предельной ошибки, а верхнюю границу – сложением
(прибавлением).
В линейной регрессии ∑(yxy)2=b2 ∑(xx)2. В этом нетрудно убедиться ,
σ σ
обратившись к формуле линейного коэффициента корреляции: rху=bit х/ у
r2xy=b2itσ2x/σ2y, где σ2
y общая дисперсия признака у; b2itσ2x дисперсия
признака у обусловленная фактором х. Соответственно сумма квадратов
отклонений , обусловленных линейной регрессией, составит: ∑σ (yxy)2=b2∑(x
x)2.
Поскольку при заданном объеме наблюдений по х и у факторная сумма
квадратов при линейной регрессии зависит только от одной константы
коэффициента регрессии b , то данная сумма квадратов имеет одну степень
свободы. Рассмотрим содержательную сторону расчетного значения признака
у т.е. ух. Величина ух определяется по уравнению линейной регрессии:
ух=а+bх.
Параметр а можно определить, как а=уbх. Подставив выражение параметра а
в линейную модель, получим: yx=ybx+bx=yb(xx).
При заданном наборе переменных у и х расчетное значение ух является в
линейной регрессии функцией только одного параметра коэффициента
регрессии. Соответственно и факторная сумма квадратов отклонений имеет
число степеней свободы, равное 1.
Существует равенство между числом степеней свободы общей,
факторной и остаточной суммами квадратов. Число степеней свободы
остаточной суммы квадратов при линейной регрессии составляет (п2).Число
степеней свободы для общей суммы квадратов определяется числом единиц, и
поскольку мы используем среднюю вычисленную по данным выборки, то
теряем одну степень свободы, т.е. (п1). Итак, имеем два равенства: для сумм
и для числа степеней свободы. А это в свою очередь возвращает нас опять к
сопоставимым дисперсиям на одну степень свободы, отношение которых и
дает критерий Фишера.
Аналогично отношению Фишера отношение величин параметров
уравнения или корреляционного коэффициента к величине стандартной
ошибки соответствующих коэффициентов образует критерий Стьюдента для
проверки значимости этих величин. Далее также используются таблицы
распределения Стьюдента и сравнение расчетных (фактических) значений с
критическими (табличными).
Однако, более того, проверка гипотез о значимости коэффициентов
регрессии и корреляции в нашем простейшем случае равносильна проверке
гипотезы о существенности линейного уравнения регрессии по Фишеру
(квадрат ткритерия Стьюдента равен критерию Фишера). Все описанное выше
справедливо пока величина коэффициента корреляции не близка к 1. Если
величина коэффициента корреляции близка к 1, то распределение его оценок
отличается от нормального распределения или от распределения Стьюдента.
30В этом случае согласно Фишеру для оценки существенности коэффициента
корреляции вводят новую переменную z для которой:
Z= (½)ln{(1+r)/(1r)} (2.5)
z
Эта новая переменная
изменяется в неограниченных пределах от –
бесконечности до + бесконечности и распределена уже весьма близко к
нормальному закону. Для этой величины имеются рассчитанные таблицы. И
поэтому удобно использовать ее для проверки значимости коэффициента
корреляции в указанном случае.
ЛЕКЦИЯ 3. НЕЛИНЕЙНАЯ РЕГРЕССИЯ
Линейная регрессия и методы ее исследования и оценки не имели бы
столь большого значения, если бы помимо этого весьма важного, но все же
простейшего случая, мы не получали с их помощью инструмента анализа
более сложных нелинейных зависимостей. Нелинейные регрессии могут быть
разделены на два существенно различных класса. Первым и более простым
является класс нелинейных зависимостей, в которых имеется нелинейность
относительно объясняющих переменных, но которые остаются линейными по
входящим в них и подлежащим оценке параметрам. Сюда входят полиномы
различных степеней и равносторонняя гипербола.
Такая нелинейная регрессия по включенным в объяснение переменным
простым преобразованием (заменой) переменных легко сводится к обычной
линейной регрессии для новых переменных. Поэтому оценка параметров в
этом случае выполняется просто по МНК, поскольку зависимости линейны по
параметрам. Так важную роль в экономике играет нелинейная зависимость,
описываемая равносторонней гиперболой:
y = a +
(3.1)
b
x
Ее параметры хорошо оцениваются по МНК и сама такая зависимость
характеризует связь удельных расходов сырья, топлива, материалов с
объемом выпускаемой продукции, временем обращением товаров и всех этих
факторов с величиной товарооборота. Например, кривая Филипса
характеризует нелинейное соотношение между нормой безработицы и
процентом прироста заработной платы.
Совершенно по другому обстоит дело с регрессией ,нелинейной по
оцениваемым параметрам, например, представляемой степенной функцией, в
которой сама степень (ее показатель) является параметром, или зависит от
параметра. Также это может быть показательная функция, где основанием
степени является параметр и экспоненциальная функция, в которой опять же
показатель содержит параметр или комбинацию параметров. Этот класс в
свою очередь делится на два подкласса: к одному относятся внешне
нелинейные , но по существу внутренне линейные. В этом случае можно
31привести модель к линейному виду с помощью преобразований. Однако, если
модель внутренне нелинейна, то она не может быть сведена к линейной
функции.
Таким образом, только модели внутренне нелинейные в регрессионном
анализе считаются действительно нелинейными. Все прочие, сводящиеся к
линейным посредством преобразований, таковыми не считаются и именно они
и рассматриваются чаще всего в эконометрических исследованиях . В то же
время это не означает невозможности исследования в эконометрике
существенно нелинейных зависимостей. Если модель внутренне нелинейна
по параметрам, то для оценки параметров используются итеративные
процедуры, успешность которых зависит от вида уравнения особенностей
применяемого итеративного метода.
Вернемся к зависимостям, приводимым к линейным. Если они
нелинейны и по параметрам и по переменным, например, вида у=а
умноженному на степень х, показатель которой и есть параметр – (бета):
y = a
bx
(3.2)
Очевидно, такое соотношение легко преобразуется в линейное уравнение
простым логарифмированием:
ba
ln
ln
ln
x
ln
y
.
После введения новых переменных, обозначающих логарифмы,
получается линейное уравнение. Тогда процедура оценивания регрессии
состоит в вычислении новых переменных для каждого наблюдения путем
взятия логарифмов от исходных значений.
Затем оценивается
регрессионная зависимость новых переменных. Для перехода к исходным
переменным следует взять антилогарифм, т. е фактически вернуться к самим
степеням вместо их показателей (ведь логарифм это и есть показатель
степени). Аналогично может рассматриваться случай показательных или
экспоненциальных функций.
Для существенно нелинейной регрессии невозможно применение
обычной процедуры оценивания регрессии, поскольку соответствующая
зависимость не может быть преобразована в линейную. Общая схема
действий при этом такова:
1. Принимаются некоторые правдоподобные исходные значения
параметров;
2. Вычисляются предсказанные значения у по фактическим значениям х с
использованием этих значений параметров;
3. Вычисляются остатки для всех наблюдений в выборке и затем сумма
квадратов остатков;
4. Вносятся небольшие изменения в одну или более оценку параметров;
5. Вычисляются новые предсказанные значения у, остатки и сумма
квадратов остатков;
326. Если сумма квадратов остатков меньше, чем прежде, то новые оценки
параметров лучше прежних и их следует использовать в качестве новой
отправной точки.
7. Шаги 4, 5 и 6 повторяются вновь до тех пор, пока не окажется
невозможным внести такие изменения в оценки параметров, которые
привели бы к изменению суммы остатков квадратов.
8. Делается вывод о том, что величина суммы квадратов остатков
минимизирована, и конечные оценки параметров являются оценками по
методу наименьших квадратов.
Среди нелинейных функций, которые могут быть приведены к линейному
виду, в эконометрике широко используется степенная функция. Параметр b в
ней имеет четкое истолкование, являясь коэффициентом эластичности. В
моделях, нелинейных по оцениваемым параметрам, но приводимых к
линейному виду, МНК применяется к преобразованным уравнениям.
Практическое применение логарифмирования и соответственно
экспоненты возможно тогда, когда результативный признак не имеет
отрицательных значений. При исследовании взаимосвязей среди функций,
использующих логарифм результативного признака, в эконометрике
преобладают степенные зависимости (кривые спроса и предложения,
производственные функции, кривые освоения для характеристики связи
между трудоемкостью продукции, масштабами производства, зависимость
ВНД от уровня занятости, кривые Энгеля).
Иногда используется так называемая обратная модель, являющаяся
внутренне нелинейной, но в ней в отличие от равносторонней гиперболы
преобразованию подвергается не объясняющая переменная, а результативный
признак у. Поэтому обратная модель оказывается внутренне нелинейной и
требование МНК выполняется не для фактических значений результативного
признака у, а для их обратных значений. Особого внимания заслуживает
исследование корреляции для нелинейной регрессии. В общем случае
парабола второй степени, также, как и полиномы более высокого порядка,
при линеаризации принимает вид уравнения множественной регрессии. Если
же нелинейное относительно объясняемой переменной уравнение регрессии
при линеаризации принимает форму линейного уравнения парной регрессии,
то для оценки тесноты связи может быть использован линейный коэффициент
корреляции.
Если преобразования уравнения регрессии в линейную форму связаны с
то линейный
зависимой переменной (результативным признаком),
коэффициент корреляции по преобразованным значениям признаков дает
лишь приближенную оценку связи и численно не совпадает с индексом
корреляции. Следует иметь в виду, что при расчете индекса корреляции
используются суммы квадратов отклонений результативного признака у, а
не их логарифмов. Оценка значимости индекса корреляции выполняется
также как и оценка надежности (значимости) коэффициента корреляции. Сам
33индекс корреляции как и индекс детерминации используется для проверки
значимости в целом уравнения нелинейной регрессии по Fкритерию Фишера.
Отметим, что возможность построения нелинейных моделей, как
посредством приведения их к линейному виду, так и путем использования
нелинейной регрессии с одной стороны повышает универсальность
регрессионного анализа. А с другой – существенно усложняет задачи
исследователя. Если ограничиваться парным регрессионным анализом, то
можно построить график наблюдений у и х как диаграмму разброса. Часто
несколько различных нелинейных функций приблизительно соответствуют
наблюдениям, если они лежат на некоторой кривой. Но в случае
множественного регрессионного анализа такой график построить невозможно.
При рассмотрении альтернативных моделей с одним и тем же
определением зависимой переменной процедура выбора сравнительно проста.
Можно оценивать регрессию на основе всех вероятных функций, которые
можно вообразить и выбирать функцию, в наибольшей степени объясняющую
изменения зависимой переменной. Понятно, что когда линейная функция
объясняет примерно 64% дисперсии у, а гиперболическая 99,9% , очевидно
следует выбирать последнюю модель. Но когда разные модели используют
разные функциональные формы, проблема выбора модели существенно
осложняется.
Более общим образом при рассмотрении альтернативных моделей с одним
и тем же определением зависимой переменной выбор прост. Разумнее всего
оценивать регрессию на основе всех вероятных функций, останавливаясь на
функции, в наибольшей степени объясняющей изменения зависимой
переменной. Если коэффициент детерминации измеряет в одном случае
объясненную регрессией долю дисперсии, а в другом – объясненную
регрессией долю дисперсии логарифма этой зависимой переменной, то выбор
делается без затруднений. Другое дело, когда эти значения для двух моделей
весьма близки и проблема выбора существенно осложняется.
Тогда следует применять стандартную процедуру в виде теста Бокса
Кокса. Если нужно всего лишь сравнить модели с использованием
результативного фактора и его логарифма в виде варианта зависимой
переменой, то применяют вариант теста Зарембки. В нем предлагается
преобразование масштаба наблюдений у, при котором обеспечивается
возможность непосредственного сравнения среднеквадратичной ошибки
(СКО) в линейной и логарифмической моделях. Соответствующая процедура
включает следующие шаги:
1. Вычисляется среднее геометрическое значений у в выборке,
совпадающее с экспонентой среднего арифметического значений
логарифма от у.
2. Пересчитываются наблюдения у, таким образом что они делятся на
полученное на первом шаге значение.
343. Оценивается регрессия для линейной модели с использованием
пересчитанных значений у вместо исходных значений у и для
логарифмической модели с использованием логарифма от
пересчитанных значений у. Теперь значения СКО для двух регрессий
сравнимы и поэтому модель с меньшей суммой квадратов отклонений
обеспечивает лучшее соответствие с истинной зависимостью
наблюденных значений.
4. Для проверки того, что одна из моделей не обеспечивает значимо
лучшее соответствие можно использовать произведение половины числа
наблюдений на логарифм отношения значений СКО в пересчитанных
регрессиях с последующим взятием абсолютного значения этой
величины. Такая статистика имеет распределение хиквадрат с одной
степенью свободы (обобщение нормального распределения).
ЛЕКЦИЯ 4 МНОЖЕСТВЕННАЯ РЕГРЕССИЯ
Парная регрессия может дать хороший результат при моделировании,
если влиянием других факторов, воздействующих на объект исследования,
можно пренебречь. Например, при построении модели потребления того или
иного товара от дохода исследователь предполагает, что в каждой группе
дохода одинаково влияние на потребление таких факторов, как цена товара,
размер семьи, ее состав. Вместе с тем исследователь никогда не может быть
уверен в справедливости данного предположения. Для того чтобы иметь
правильное представление о влиянии дохода на потребление, необходимо
изучить их корреляцию при неизменном уровне других факторов. Прямой
путь решения такой задачи состоит в отборе единиц совокупности с
одинаковыми значениями всех других факторов, кроме дохода. Он приводит
к планированию эксперимента методу, который используется в химических,
физических, биологических исследованиях.
Экономист в отличие от экспериментатораестественника лишен
возможности регулировать другие факторы.
Поведение отдельных
экономических переменных контролировать нельзя, т. е. не удается
обеспечить равенство всех прочих условий для оценки влияния одного
исследуемого фактора. В этом случае следует попытаться выявить влияние
других факторов, введя их в модель, т. е. построить уравнение
множественной регрессии:
y=a+b1*x1+b2*x2+…+bp*xp+ (9.1)
Множественная регрессия широко используется в решении проблем
спроса, доходности акций, при изучении функции издержек производства, в
макроэкономических расчетах и целого ряда других вопросов эконометрики.
В настоящее время множественная регрессия один из наиболее
распространенных методов в эконометрике. Основная цель множественной
35регрессии построить модель с большим числом факторов, определив при
этом влияние каждого из них в отдельности, а также совокупное их
воздействие на моделируемый показатель.
Построение уравнения множественной регрессии начинается с решения
вопроса о спецификации модели, Включает в себя два круга вопросов; отбор
факторов и выбор вида уравнения регрессии.
Включение в уравнение множественной регрессии того или иного набора
факторов связано прежде всего с представлением исследователя о природе
взаимосвязи моделируемого показателя с другими экономическими
явлениями. Факторы, включаемые во множественную регрессию, должны
отвечать следующим требованиям.
1. Они должны быть количественно измеримы. Если необходимо включить
в модель качественный фактор, не имеющий количественного
измерения, то ему нужно придать количественную определенность
(например, в модели урожайности качество почвы задается в виде
баллов; в модели стоимости объектов недвижимости учитывается место
нахождения недвижимости).
2. Факторы не должны быть интеркоррелированы и тем более находиться в
точной функциональной связи.
Если между факторами существует высокая корреляция, то нельзя
определить их изолированное влияние на результативный показатель и
параметры уравнения регрессии оказываются неинтерпретируемыми.
Включаемые во множественную регрессию факторы должны объяснить
вариацию независимой переменной. Если строится модель с набором р
факторов, то для нее рассчитывается показатель детерминации R2, который
фиксирует долю объясненной вариации результативного признака за счет
рассматриваемых в регрессии р факторов. Влияние других не учтенных в
модели факторов оценивается как 1 R2 с соответствующей остаточной
дисперсией S2.
При дополнительном включении в регрессию р + 1 фактора коэффициент
детерминации должен возрастать, а остаточная дисперсия уменьшаться
R2
p+1 R2
p (9.2)
и
S2
p+1 S2
p (9.3)
Если же этого не происходит и данные показатели практически мало
отличаются друг от друга, то включаемый в анализ фактор xp+1не улучшает
модель и практически является лишним фактором. Насыщение модели
лишними факторами не только не снижает величину остаточной дисперсии и
не увеличивает показатель детерминации, но и приводит к статистической
незначимости параметров регрессии по tкритерию Стьюдента.
36Таким образом, хотя теоретически регрессионная модель позволяет
учесть любое число факторов, практически в этом нет необходимости. Отбор
факторов производится на основе качественного теоретикоэкономического
анализа. Однако теоретический анализ часто не позволяет однозначно
ответить на вопрос о количественной взаимосвязи рассматриваемых
признаков и целесообразности включения фактора в модель. Поэтому отбор
факторов обычно осуществляется в две стадии: на первой подбираются
факторы исходя из сущности проблемы; на второй на основе матрицы
показателей корреляции определяют tстатистики для параметров регрессии.
корреляции между
объясняющими переменными) позволяют исключать из модели дублирующие
факторы.
Коэффициенты интеркорреляции (т.
е.
Если факторы явно коллинеарны, то они дублируют друг друга и один
из них рекомендуется исключить из регрессии. Предпочтение при этом
отдается не фактору, более тесно связанному с результатом, а тому фактору,
который при достаточно тесной связи с результатом имеет наименьшую
тесноту связи с другими факторами. В этом требовании проявляется
специфика множественной регрессии как метода исследования комплексного
воздействия факторов в условиях их независимости друг от друга.
По величине парных коэффициентов корреляции может
обнаруживаться лишь явная коллинеарность факторов. Наибольшие
трудности в использовании аппарата множественной регрессии возникают при
наличии мультиколлинеарности факторов, когда более чем два фактора
связаны между собой линейной зависимостью, т. е. имеет место совокупное
воздействие факторов друг на друга.
Наличие мультиколлинеарности факторов может означать, что
некоторые факторы будут всегда действовать в унисон. В результате
вариация в исходных данных перестает быть полностью независимой, и нельзя
оценить воздействие каждого фактора в отдельности. Чем сильнее
мультиколлинеарность факторов, тем менее надежна оценка распределения
суммы объясненной вариации по отдельным факторам с помощью метода
наименьших квадратов (МНК).
Если рассматривается регрессия для расчета параметров, применяя
МНК,
то предполагается
y=a+b*x+y*z+d*v+, (9.4)
равенство
Sy=Sфакт+S (9.5)
где Sy общая сумма квадратов отклонений
yiy
(объясненная) сумма квадратов отклонений
сумма квадратов отклонений
iyiy
2)
(
, а Sфакт факторная
2)
, S остаточная
2)
(
yiy
(
.
37В свою очередь, при независимости факторов друг от друга выполнимо
равенство:
Sфакт = Sx + Sz + Sv (9.6)
где Sx, Sz, Sv суммы квадратов отклонений, обусловленные влиянием
соответствующих факторов.
Если же факторы интеркоррелированы, то данное равенство
нарушается.
Включение в модель мультиколлинеарных факторов нежелательно в
силу следующих последствий:
затрудняется интерпретация параметров множественной регрессии как
характеристик действия факторов в "чистом" виде, ибо факторы
коррелированы; параметры линейной регрессии теряют экономический
смысл;
оценки параметров ненадежны, обнаруживают большие стандартные
ошибки и меняются с изменением объема наблюдений (не только по
величине, но и по знаку), что делает модель непригодной для анализа и
прогнозирования.
Для оценки мультиколлинеарности факторов может использоваться
определитель матрицы парных коэффициентов корреляции между факторами.
Если бы факторы не коррелировали между собой, то матрица парных
коэффициентов корреляции между факторами была бы единичной матрицей,
поскольку все не диагональные элементы были бы равны нулю.
Чем ближе к нулю определитель матрицы межфакторной корреляции,
тем сильнее мультиколлинеарность факторов и ненадежнее результаты
множественной регрессии. И, наоборот, чем ближе к единице определитель
матрицы межфакторной корреляции, тем меньше мультиколлинеарность
факторов.
Оценка значимости мультиколлинеарности факторов может быть
проведена методом испытания гипотезы о независимости переменных.
Через коэффициенты множественной детерминации можно найти
переменные, ответственные за мультиколлинеарность факторов. Для этого в
качестве зависимой переменной рассматривается каждый из факторов. Чем
ближе значение коэффициента множественной детерминации к единице, тем
сильнее проявляется мультиколлинеарность факторов. Сравнивая между
собой коэффициенты множественной детерминации факторов можно
выделить переменные,
за мультиколлинеарность,
следовательно, можно решать проблему отбора факторов, оставляя в
уравнении факторы с минимальной величиной коэффициента множественной
детерминации.
ответственные
Существует ряд подходов преодоления сильной межфакторной
корреляции. Самый простой путь устранения мультиколлинеарности состоит
в исключении из модели одного или нескольких факторов. Другой подход
38связан с преобразованием факторов, при котором уменьшается корреляция
между ними. Например, при построении модели на основе рядов динамики
переходят от первоначальных данных к первым разностям уровней, чтобы
исключить влияние тенденции, или используются такие методы, которые
сводят к нулю межфакторную корреляцию, т. е. переходят от исходных
переменных к их линейным комбинациям, не коррелированных друг с другом
(метод главных компонент).
Одним из путей учета внутренней корреляции факторов является
переход к совмещенным уравнениям регрессии, т. е. к уравнениям, которые
отражают не только влияние факторов, но и их взаимодействие.
Рассматривается уравнение, включающее взаимодействие первого порядка
(взаимодействие двух факторов). Возможно включение в модель и
взаимодействий более высокого порядка (взаимодействие второго порядка).
Как правило, взаимодействия третьего и более высоких порядков
оказываются статистически незначимыми, совмещенные уравнения регрессии
ограничиваются взаимодействиями первого и второго порядков. Но и эти
взаимодействия могут оказаться несущественными, поэтому нецелесообразно
полное включение в модель взаимодействий всех факторов и всех порядков.
Совмещенные уравнения регрессии строятся,
при
исследовании эффекта влияния на урожайность разных видов удобрений
(комбинаций азота и фосфора).
например,
Решению проблемы устранения мультиколлинеарности факторов может
помочь и переход к уравнениям приведенной формы. С этой целью в
уравнение регрессии производится подстановка рассматриваемого фактора
через выражение его из другого уравнения.
Пусть, например, рассматривается двухфакторная регрессия вида
ух=а+bi*xi+b2*X2, дня которой факторы, xi и Х2 обнаруживают высокую
корреляцию. Если исключить один из факторов, то мы придем к уравнению
парной регрессии. Вместе с тем можно оставить факторы в модели, но
исследовать данное двухфакторное уравнение регрессии совместно с другим
уравнением, в котором фактор рассматривается как зависимая переменная.
Отбор факторов, включаемых в регрессию, является одним из
важнейших этапов практического использования методов регрессии. Подходы
к отбору факторов на основе показателей корреляции могут быть разные. Они
приводят построение уравнения множественной регрессии соответственно к
разным методикам. В зависимости от того, какая методика построения
уравнения регрессии принята, меняется алгоритм ее решения на ЭВМ.
Наиболее широкое применение получили следующие методы
построения уравнения множественной регрессии:
метод исключения;
метод включения;
шаговый регрессионный анализ.
39Каждый из этих методов посвоему решает проблему отбора факторов,
давая в целом близкие результаты отсев факторов из полного его набора
(метод исключения), дополнительное введение фактора (метод включения),
исключение ранее введенного фактора (шаговый регрессионный анализ).
На первый взгляд может показаться, что матрица парных коэффициентов
корреляции играет главную роль в отборе факторов. Вместе с тем вследствие
взаимодействия факторов парные коэффициенты корреляции не могут в
полной мере решать вопрос о целесообразности включения в модель того или
иного фактора. Эту роль выполняют показатели частной корреляции,
оценивающие в чистом виде тесноту связи фактора с результатом.
Матрица частных коэффициентов корреляции наиболее широко
используется в процедуре отсева факторов. При отборе факторов
рекомендуется пользоваться следующим правилом: число включаемых
факторов обычно в 6 7 раз меньше объема совокупности, по которой
строится регрессия. Если это соотношение нарушено, то число степеней
свободы остаточной вариации очень мало. Это приводит к тому, что
параметры уравнения регрессии оказываются статистически незначимыми, а
Fкритерий меньше табличного значения.
По существу эффективность и целесообразность применения
эконометрических методов наиболее явно проявляются при изучении явлений
и процессов, в которых зависимая переменная (объясняемая) подвержена
влиянию множества различных факторов (объясняющих переменных).
Множественная регрессия это уравнение связи с несколькими
независимыми переменными. Позднее, правда, мы увидим, что эту
независимость не следует понимать абсолютно. Необходимо исследовать
какие объясняющие переменные можно считать независимыми в силу их
незначительной связи между собой, а для каких это несправедливо. Но в
качестве первого приближения, хорошо оправдывающегося во многих случаях
и необходимого для понимания дальнейшего, мы изучим сначала этот более
простой случай с независимыми объясняющими переменными
Каким образом отбираются факторы,
входящие в модель
множественной регрессии? Прежде всего, эти факторы должны поддаваться
количественному измерению. Может оказаться, что необходимо включить в
модель (уравнение) некий качественный фактор, который не имеет
количественного измерения. В этом случае следует добиться количественной
определенности такого качественного фактора, т.е. ввести некоторую шкалу
оценки данного фактора и по ней оценить его. Далее факторы не должны
иметь явно выраженной и к тому же сильной взаимосвязи (имеется в виду
общая стохастическая связь,
не быть
интеркоррелированы.
или корреляция),
т.е.
Тем более, не допустимо наличие между факторами явной
функциональной связи! В случае факторов с высокой степенью
40