Поделиться

Департамент образования Ярославской области
Государственное профессиональное образовательное учреждение
Рыбинский полиграфический колледж
Составитель: С. В. Ермолычева
Основы теории информации
Учебное пособие
Рыбинск
2019
Рецензент:
Н. Н. Ботвинова, преподаватель высшей квалификационной категории Рыбинского филиала ФГБОУ ВО «Московская государственная академия водного транспорта»
Дизайн и иллюстрации: В. М. Гамбург
Основы теории информации : учеб. пособие / Сост. : С. В. Ермолычева. – Рыбинск : Изд-во Рыбинского полиграфического колледжа, 2019. – 94 с. : ил.
© ГПОУ ЯО
«Рыбинский полиграфический колледж», 2019
Введение
Теорией информации называется наука, изучающая количественные закономерности, связанные с получением, передачей, обработкой и хранением информации. Возникнув в 40-х годах прошлого века из практических задач теории связи, теория информации в настоящее время становится необходимым математическим аппаратом при изучении всевозможных процессов управления.
Настоящее учебное пособие предназначено для студентов, обучающихся по специальности 09.02.02 «Компьютерные сети». Целью пособия является начальное ознакомление с основными понятиями теории информации, ее целями и задачами.
Учебная дисциплина «Основы теории информации» входит в профессиональный цикл как общепрофессиональная дисциплина, дающая базовый уровень знаний для освоения смежных общепрофессиональных дисциплин и профессиональных модулей по специальности.
В результате освоения дисциплины обучающийся должен знать и понимать:
A виды и формы представления информации;
A методы и средства определения количества информации;
A принципы кодирования и декодирования информации;
A способы передачи цифровой информации;
A методы повышения помехозащищенности передачи и приема данных;
A основы теории сжатия данных.
Также обучающийся должен уметь:
A применять закон аддитивности информации; A применять теорему Котельникова; A использовать код Шеннона—Фано.
Пособие состоит из отдельных глав, каждая из которых снабжена краткими теоретическими сведениями, примерами, решениями задач. В конце каждого подраздела размещены вопросы и задания для проверки
знаний, выполнения внеаудиторной самостоятельной работы. При самостоятельном изучении учебной дисциплины или отдельных ее разделов все вопросы и задания условно разделены на три уровня:
A первый уровень — базовый, требующий от обучающегося понимания существенных сторон учебной информации, владения общими принципами поиска алгоритма;
A второй уровень — повышенный, требующий от обучающегося преобразовывать алгоритмы к условиям, отличающимся от стандартных, умение вести эвристический поиск;
A третий уровень — творческий, предполагающий наличие самостоятельного критического оценивания учебной информации, умение решать нестандартные задания, владение элементами исследовательской деятельности.
Данное пособие может найти широкое применение
на лекционных и практических занятиях по дисциплине «Основы теории информации»,
при самостоятельном изучении курса, подготовке к зачету или итоговой контрольной
работе.
Современная наука исследует строение и функционирование очень сложных объектов в биологии, технике, обществе. Однако особенности поведения таких систем оказалось невозможно детально описать только на языке вещественно-энергетических моделей. Людям всегда была свойственна потребность выразить и запомнить информацию об окружающем мире, благодаря чему появилась устная речь, письменность, книгопечатание, живопись, радио, телевидение. В истории человечества произошло несколько информационных революций.
Первая революция связана с изобретением письменности.
Вторая революция (середина XVI века) вызвана изобретением книгопечатания.
Третья революция (конец XIX века) произошла благодаря открытию электричества.
Четвертая революция (середина XX века) связана с изобретением компьютера.
Таким образом, к концу XX века стала складываться информационная картина мира, которая рассматривает окружающий мир под информационным углом зрения, не противопоставляя себя вещественно-энергетической картине мира, а дополняя ее.
![]()
Информация — это фундаментальное понятие науки, очень емкое и глубокое, которое невозможно определить однозначно.
![]()
Ученые пользуются не определением информации, а понятием информации. Понятия отличаются от определений тем, что не даются однозначно, а вводятся на примерах, причем каждая наука делает это по-своему, вкладывая в понятие только те компоненты, которые соответствуют ее предмету и задачам.
Философы говорят о том, что информация, как зеркало, отражает мир (реальный или вымышленный). Биологи рассматривают информационные процессы в живой природе. Социологи изучают ценность и полезность информации в человеческом обществе. Специалистов по компьютерной технике в первую очередь интересует представление информации в виде знаков.
Попробуем посмотреть на информацию с разных сторон и попытаться выявить некоторые ее свойства.
Прежде всего информация «бестелесна», или нематериальна, она не имеет формы, размеров, массы. С этой точки зрения информация — это то содержание, которое человек с помощью своего сознания «выделяет» из окружающей среды.
Давайте сравним два изображения одинакового размера, представленных на рисунке 1.1. На первом из них пусто, а на втором мы видим фотографию. Вряд ли кто-то способен долго разглядывать чистый лист, а на фотографию можно долго смотреть, открывая все новые и новые детали. Почему так?
Первый рисунок разглядывать неинтересно, там все одинаково — везде белый цвет. На втором рисунке есть разнообразие, он неоднороден. Поэтому можно сказать, что он содержит больше информации, чем первый.

![]()
Информация характеризует разнообразие (неоднородность) в окружающем мире.
![]()
Зачем вообще нам нужна информация? Дело в том, что наше знание всегда в чем-то неполно, в нем есть неопределенность. Например, вы стоите на остановке и не знаете, на каком именно автобусе вам нужно ехать в гости к другу (его адрес известен). Неопределенность мешает вам решить свою задачу. Нужный номер автобуса можно определить, например, по карте с маршрутами транспорта. Очевидно, что при этом вы получите новую информацию, которая увеличит знание и уменьшит неопределенность.
Многие выдающиеся ученые ХХ века (Н. Винер, У. Эшби, К. Шеннон, А. Урсул, А. Моль, В. М. Глушков) давали свое определение информации, но ни одно из них не стало общепринятым. Дело в том, что слово «информация» используется в самых разных ситуациях для обозначения того общего, что есть в разговоре людей, обмене письмами, чтении книги, прослушивании музыки, передаче сообщения через компьютерную сеть и т. д. Поэтому дать строгое определение информации не удается, можно только объяснить значение этого слова на примерах и сравнить с другими понятиями. Норберт Винер, создатель кибернетики — науки об управлении и связи — писал: «Информация есть информация, а не материя и не энергия».
Человек получает информацию через свои органы чувств: глаза, уши, рот, нос и кожу. Поэтому получаемую нами информацию можно разделить на следующие виды:
A зрительная информация (визуальная, от англ. visual) — поступает через глаза (по разным оценкам, это 80–90 % всей получаемой нами информации);
A звуковая информация (аудиальная, от англ. audio) — поступает через уши;
A вкусовая информация — поступает через язык;
A обонятельная информация (запахи) — поступает через нос; A тактильная информация — мы ее получаем с помощью осязания (кожи), «на ощупь».
Еще выделяют информацию, получаемую с помощью «мышечного чувства» (человеческий мозг получает импульсы от мышц и суставов при перемещении частей тела).
Некоторые животные чувствуют магнитное поле Земли и используют его для выбора направления движения.
Информация может быть представлена (зафиксирована, закодирована) в различных формах:
A текстовая информация — последовательность символов (букв, цифр, других знаков); в тексте важен порядок их расположения, например, КОТ и ТОК — два разных текста, хотя они состоят из одинаковых символов;
A числовая информация;
A графическая информация (рисунки, картины, чертежи, карты, схемы, фотографии и т. п.);
A звуковая информация (звучание голоса, мелодии, шум, стук, шорох и т. п.);
A мультимедийная информация объединяет несколько форм представления информации (например, видеоинформация).
Обратим внимание, что одна и та же информация может быть представлена по-разному. Например, результаты измерения температуры в течение недели можно сохранить в виде текста, чисел, таблицы, диаграммы, и т. д.
Обо всех изменениях в окружающем мире человек узнает с помощью своих органов чувств: сигналы от них («первичная» информация) постоянно поступают в мозг. Чтобы понять эти сигналы, то есть извлечь информацию, человек использует знания — свои представления о природе, обществе, самом себе. Знания позволяют человеку принимать решения, определяют его поведение и отношения с другими людьми.
Можно считать, что знания — это модель мира, которая есть у человека. Получив информацию («поняв» сигналы, поступившие от органов чувств), он корректирует эту модель, дополняет свои знания.
Очевидно, что полученная информация не всегда обогащает наши знания. Сообщение увеличивает знания человека, если оно понятно и содержит новые сведения. Например, информация о том, что 2 ∙ 2 = 4 вряд ли увеличит ваши знания, потому что вы это уже знаете, эта информация для вас не нова. Однако она будет новой для тех, кто изучает таблицу умножения. Это значит, что изменение знаний при получении сообщения зависит от того, что человек знал до этого момента. Если он знает все, что было в полученном сообщении, знания не изменяются.
Вместе с тем сообщение «Учет вибронных взаимодействий континуализирует моделирование диссипативных структур» (или сообщение на неизвестном языке) также не увеличивает знания, потому что эта фраза, скорее всего, вам непонятна. Иначе говоря, имеющихся знаний не хватает для того, чтобы воспринять новую информацию.
Эти идеи послужили основой семантической (смысловой) теории информации, предложенной в 60-х годах ХХ века советским математиком Ю. А. Шрейдером. На рисунке 1.2 показано, как зависит количество полученных знаний I от того, какая доля информации q в сообщении уже известна получателю.
 К сожалению, «измерить»
смысл информации, оценить его числом, довольно сложно. Поэтому для оценки количества
информации используют другие подходы, о которых вы узнаете чуть позже.
К сожалению, «измерить»
смысл информации, оценить его числом, довольно сложно. Поэтому для оценки количества
информации используют другие подходы, о которых вы узнаете чуть позже.
Когда человек хочет поделиться с кем-то своим знанием, он может сказать: «Я знаю, что...»
или «Я знаю, как...». Это говорит о том, что есть Рисунок 1.2 два разных вида знаний. В первом случае зна-
ния — это некоторый известный факт, например: «Я знаю, что Луна вращается вокруг Земли». Такие знания называются декларативными, человек выражает их словами (декларирует). Декларативные знания — это факты, законы, принципы.
Второй тип знаний («Я знаю, как...») называют процедурными. Они выражаются в том, что человек знает, как нужно действовать в той или иной ситуации. К процедурным знаниям относятся алгоритмы решения различных задач.
Для того чтобы сохранить знания и передать другим людям, нужно выразить их на каком-то языке (например, рассказать, записать, нарисовать и т. п.). Только после этого их можно хранить, обрабатывать, передавать, причем с этим может справиться и компьютер. В научной литературе информацию, зафиксированную (закодированную) в какой-то форме, называют данными, имея в виду, что компьютер может выполнять с ними какие-то операции, но не способен понимать смысл.
Для того чтобы данные стали информацией, их нужно понять и осмыслить, а на это способен только человек. Если человек, получающий сообщение, знает язык, на котором оно записано, он может понять смысл этого сообщения, то есть получить информацию. Обрабатывая и упорядочивая информацию, человек выявляет закономерности — получает знания. Мы увидели, что в науке существуют достаточно тонкие различия между понятиями «данные», «информация», «знания». Тем не менее на практике чаще всего все это называется общим термином «информация».
Понятие «информация» используется многими научными дисциплинами, имеет большое количество разнообразных свойств, но каждая дисциплина обращает внимание на те свойства информации, которые для нее наиболее важны. Рассмотрим следующие свойства информации:
1. Дуализм информации характеризует ее двойственность. С одной стороны, информация объективна в силу объективности данных, с другой — субъективно, в силу субъективности применяемых методов. Иными словами, методы могут вносить в большей или меньшей степени субъективный фактор и таким образом влиять на информацию в целом. Например, два человека читают одну и ту же книгу и получают подчас весьма разную информацию, хотя прочитанный текст, то есть данные, были одинаковы. Более объективная информация применяет методы с меньшим субъективным элементом.
2. Полнота информации характеризует степень достаточности данных для принятия решения или создания новых данных на основе имеющихся. Неполный набор данных оставляет большую долю неопределенности, то есть большое число вариантов выбора, а это потребует применения дополнительных методов, например, экспертных оценок, бросание жребия и т. п. Избыточный набор данных затрудняет доступ к нужным данным, создает повышенный информационный шум, что также вызывает необходимость дополнительных методов, например, фильтрацию, сортировку. И неполный, и избыточный наборы затрудняют получение информации и принятие адекватного решения.
3. Достоверность информации — это свойства, характеризующее степень соответствия информации реальному объекту с необходимой точностью. При работе с неполным набором данных достоверность информации может характеризоваться вероятностью: например, можно сказать, что при бросании монеты с вероятностью 50 % выпадет герб.
4. Адекватность информации выражает степень соответствия создаваемого с помощью информации образа реальному объекту, процессу, явлению. Полная адекватность достигается редко, так как обычно приходится работать с не самым полным набором данных, то есть присутствует неопределенность, затрудняющая принятие адекватного решения. Получение адекватной информации также затрудняется при недоступности адекватных методов.
5. Доступность информации — это возможность получения информации при необходимости. Доступность складывается из двух составляющих: из доступности данных и доступности методов. Отсутствие хотя бы одного из них дает неадекватную информацию.
6. Актуальность информации. Информация существует во времени, так как все информационные процессы существуют во времени. Информация, актуальная сегодня, может стать совершенно ненужной по истечении некоторого времени. Например, программа телепередач на эту неделю будет неактуальна для телезрителей на следующей неделе.
1. Как связана неопределенность знания с получением информации?
2. Как связана информация и сложность объекта?
3. Объясните, почему термин «информация» трудно определить.
4. Согласны ли вы с «определением» информации, которое дал Н. Винер?
Как вы его понимаете?
5. Как человек воспринимает информацию?
6. Чем отличается текст от набора символов?
7. К какому виду информации относятся видеофильмы?
8. Что такое тактильная информация?
9. Всякая ли информация увеличивает знания? Почему?
10. Какими свойствами должна обладать «идеальная» информация?
11. Приведите примеры необъективной, непонятной, бесполезной, недостоверной, неактуальной и неполной информации.
12. Может ли информация быть достоверной, но бесполезной? Достоверной, но необъективной? Объективной, но недостоверной? Актуальной, но непонятной?
13. Приведите примеры обработки информации в технических устройствах.
Как мы уже знаем, информация сама по себе нематериальна. Поэтому она может существовать только тогда, когда связана с каким-то объектом или средой, то есть с носителем.
![]()
Материальный носитель — это объект или среда, которые могут содержать информацию.
![]()
Изменения, происходящие с информацией (то есть изменения свойств носителя), называются информационными процессами. Все эти процессы можно свести к двум основным:
A передача информации (данные передаются между носителями); A обработка информации (данные изменяются).
Часто информационными процессами называют также и многие другие операции с информацией (например, копирование, удаление и др.), но они, в конечном счете, сводятся к двум названным процессам.
Для хранения информации тоже используется какой-то носитель. Однако при этом никаких изменении не происходит, поэтому хранение информации нельзя назвать процессом.
При передаче информации всегда есть два объекта — источник и приемник информации. Эти роли могут меняться, например, во время диалога каждый из участников выступает то в роли источника, то в роли приемника информации.
Информация проходит от источника к приемнику через канал связи, в котором она должна быть связана с каким-то материальным носителем. Данный процесс иллюстрирует схема, представленная на рисунке 1.3. Для передачи информации свойства материального носителя должны изменяться со временем. Например, если включать и выключать лампочку, то можно передавать разную информацию, например, с помощью азбуки Морзе.

Рисунок 1.3
При разговоре людей носитель информации — это звуковые волны в воздухе. В компьютерах информация передается с помощью электрических сигналов или радиоволн (в беспроводных устройствах). Информация может передаваться с помощью света, лазерного луча, телефонной или почтовой связи, компьютерной сети и др.
Информация поступает по каналу связи в виде сигналов, которые приемник может обнаружить с помощью своих органов чувств (или датчиков) и «понять» (раскодировать).
![]()
Сигнал — это изменение свойств носителя, которое используется для передачи информации.
![]()
Примеры сигналов — это изменение частоты и громкости звука, вспышки света, изменение напряжения на контактах и т. п.
Человек может принимать сигналы только с помощью своих органов чувств. Чтобы передавать и принимать информацию, например, с помощью радиоволн, нужны вспомогательные устройства: радиопередатчик, преобразующий звук в радиоволны, и радиоприемник, выполняющий обратное преобразование. Они позволяют расширить возможности человека.
С помощью одного сигнала (одного изменения) невозможно передать много информации. Поэтому чаще всего используется не одиночный сигнал, а последовательность сигналов, которая называется сообщением. Важно понимать, что сообщение — это только «оболочка» для передачи информации, а информация — это содержание сообщения. Приемник должен сам «извлечь» (раскодировать) информацию из полученной последовательности сигналов. Можно принять сообщение, но не принять информацию, например, услышав речь на незнакомом языке или перехватив шифровку.
Одна и та же информация может быть передана с помощью сообщений, имеющих разные физические носители (например, через устную речь, с помощью записки или с помощью флажного семафора, который используется на флоте) или с помощью разных сообщений. В то же время одно и то же сообщение может нести разную информацию для разных приемников. Так фраза «В Сантьяго идет дождь», переданная в 1973 г. на военных радиочастотах, для сторонников генерала Пиночета послужила сигналом к началу государственного переворота в Чили.
К сожалению, в реальном канале связи всегда действуют помехи: посторонние звуки при разговоре, шумы радиоэфира, электрические и магнитные поля. Помехи могут полностью или частично искажать сообщение, вплоть до полной потери информации (например, телефонные разговоры при перегрузке сети).
Чтобы содержание сообщения, искаженного помехами, можно было восстановить, оно должно быть избыточным, то есть в нем должны быть «лишние» элементы, без которых смысл все равно восстанавливается. Например, в сообщении «Влг впдт в Кспск мр» многие угадают фразу «Волга впадает в Каспийское море», из которой убрали все гласные. Этот пример говорит о том, что естественные языки содержат много «лишнего», их избыточность оценивается в 60–80 % (если удалить 60–80 % текста, его смысл все равно удается восстановить).
![]()
Обработка — это изменение информации: ее формы или содержания.
![]()
Среди важнейших видов обработки можно назвать:
A создание новой информации, например, решение задачи с помощью вычислений или логических рассуждений;
A кодирование — запись информации с помощью некоторой системы знаков для передачи и хранения; один из вариантов кодирования — шифрование, цель которого — скрыть смысл (содержание) информации от посторонних;
A поиск информации, например, в книге, в библиотечном каталоге, на схеме или в интернете;
A сортировка — расстановка элементов списка в заданном порядке, например, расстановка чисел по возрастанию или убыванию, расстановка слов по алфавиту; задача сортировки — облегчить поиск и анализ информации.
Для обработки информации человек использует в первую очередь свой мозг. Нейроны (нервные клетки) коры головного мозга «переключаются» примерно 200 раз в секунду — значительно медленнее, чем элементы памяти компьютеров. Однако человек практически безошибочно отличает собаку от кошки, а для компьютеров эта задача пока неразрешима. Дело, по-видимому, в том, что мозг решает такие задачи не «в лоб», не путем сложных вычислений, а как-то иначе (как — пока никто до конца не знает).
Компьютер позволяет «усилить» возможности человека в тех задачах обработки информации, решение которых требует длительных расчетов по известным алгоритмам. Однако, в отличие от человека, для компьютера недоступны фантазия, размышления, творчество.
Для хранения информации человек, прежде всего, использует свою память. Можно считать, что мозг — это одно из самых совершенных хранилищ информации, во многом превосходящее компьютерные средства.
К сожалению, человек многое забывает. Кроме того, необходимо передавать знания другим людям, в том числе и следующим поколениям. Поэтому в древности люди записывали информацию на камне, папирусе, бересте, пергаменте, затем — на бумаге. В XX веке появились новые средства хранения информации: перфокарты и перфоленты, магнитные ленты и магнитные диски, оптические диски, флешпамять.
В любом случае информация хранится на каком-то носителе, который обладает «памятью», то есть может находиться в разных состояниях, переходить из одного состояния в другое при каком-то внешнем воздействии, и сохранять свое состояние.
При записи информации свойства носителя меняются: на бумагу наносятся текст и рисунки; на магнитных дисках и лентах намагничиваются отдельные участки; на оптических дисках образуются области, по-разному отражающие свет. При хранении эти свойства остаются неизменными, что позволяет потом читать (получать) записанную информацию.
Отметим, что процессы записи и чтения — это процессы передачи информации.
1. Кто (что) может быть источником (приемником) информации? Приведите примеры.
2. Что такое сигнал? Приведите примеры сигналов.
3. Что такое сообщение? Чем отличается получение информации от получения сообщения?
4. Приведите примеры, когда прием сообщения не означает прием информации.
5. Приведите примеры, когда одна и та же информация может быть передана с помощью разных сообщений.
6. Приведите примеры, когда одно и то же сообщение несет разную информацию для разных людей.
7. Расскажите, как помехи влияют на передачу информации. Приведите примеры.
8. Что такое избыточность? Почему она полезна при передаче информации?
9. Представьте, что придумали язык, в котором нет избыточности. В чем будет его недостаток?
10. Как вы думаете, какой вариант русского языка обладает наибольшей избыточностью: разговорный, литературный, юридический, язык авиадиспетчеров?
11. В каком из перечисленных выше языков наиболее важна помехоустойчивость? За счет чего она достигается?
12. Какие виды обработки информации вы знаете?
13. При каких видах обработки информации меняется ее содержание?
14. При каких видах обработки информации меняется только форма ее представления?
15. К какому виду обработки можно отнести шифрование? Почему?
16. Работники удаленной метеостанции каждые 3 часа измеряют температуру и влажность воздуха и передают данные по рации в районный метеоцентр. Там эти данные сводят в таблицу и отправляют по электронной почте в Гидрометцентр, где мощные компьютеры составляют прогноз погоды. Выделите здесь процессы, связанные с обработкой и передачей информации.
17. Ученик нашел в старой книге сведения о населении Москвы в XIX веке, составил таблицу по этом данным, построил диаграмму и сделал доклад на школьной конференции. Выделите здесь процессы, связанные с обработкой и передачей информации.
18. Зачем человек записывает информацию?
19. В чем преимущества и недостатки человеческой памяти по сравнению с компьютерной?
Любая наука рано или поздно приходит к необходимости как-то измерять то, что она изучает. Измерение информации — это одна из важнейших задач теоретической информатики.
Для человека информация — это, прежде всего, смысл, заключенный в сигналах и данных. Как измерить смысл? На этот вопрос пока нет однозначного ответа.
Вспомним, что компьютеры не могут обрабатывать смысл, они работают только с данными (а не с информацией). При этом возникают чисто практические задачи: определить, сколько места займет на диске текст, рисунок или видеофильм; сколько времени потребуется на передачу файла по компьютерной сети и т. п. Поэтому чаще всего используется объемный подход к измерению информации. Он заключается в том, что количество информации оценивается просто по числу символов, используемых для ее кодирования. С этой точки зрения стихотворение А. С. Пушкина и случайный набор букв могут содержать одинаковое количество информации. Конечно, такой подход не универсален, но он позволяет успешно решать практические задачи, связанные с компьютерной обработкой и хранением данных.
Рассмотрим электрическую лампочку, которая может находиться в двух состояниях: «горит» и «не горит». Тогда на вопрос «Горит ли сейчас лампочка» есть два возможных варианта ответа, которые можно обозначить цифрами 1 («горит») и 0 («не горит»), как показано на рисунке 1.4. Поэтому ответ на этот вопрос (полученная информация) может быть записан как 0 или 1[1].
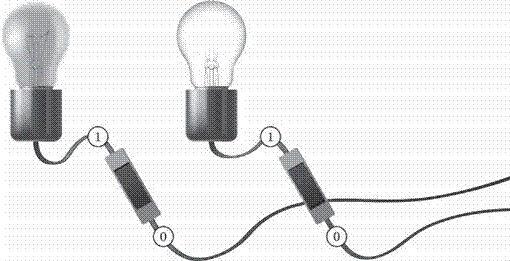
Рисунок 1.4
Цифры 0 и 1 называют двоичными, и с этим связано название единицы измерения количества информации — бит. Английское слово bit — это сокращение от выражения binarу digit — «двоичная цифра». Впервые слово «бит» в этом значении использовал американский инженер и математик Клод Шеннон в 1948 г.
![]()
Бит — это количество информации, которую можно записать (закодировать) с помощью одной двоичной цифры.
![]()
Конечно, нужно договориться, что означают 0 и 1 (1 — это «горит» или «не горит»?), но для измерения количества информации это не важно.
Например, в сообщении «подброшенная монета упала гербом» содержится 1 бит информации, потому что монета могла упасть гербом (обозначим это через 0) или «решкой» (1). Сообщение «Дверь открыта» тоже содержит 1 бит, если считать, что дверь может быть в двух состояниях: открыта (0) или закрыта (1). Вот еще пример диалога, в котором получена информация в 1 бит:
— Вы будете чай или кофе?
— Кофе, пожалуйста.
![]() А если возможных вариантов
не два, а больше? Понятно, что в этом случае количество информации будет больше,
чем 1 бит. Представим себе, что на вокзале стоят 4 одинаковых поезда, показанных
на рисунке 1.5, причем только один из них проследует в Москву. Сколько битов понадобится
для того, чтобы записать информацию о номере платформы, где стоит поезд на Москву?
А если возможных вариантов
не два, а больше? Понятно, что в этом случае количество информации будет больше,
чем 1 бит. Представим себе, что на вокзале стоят 4 одинаковых поезда, показанных
на рисунке 1.5, причем только один из них проследует в Москву. Сколько битов понадобится
для того, чтобы записать информацию о номере платформы, где стоит поезд на Москву?

Рисунок 1.5
Очевидно, что одного бита недостаточно, так как с помощью одной двоичной цифры можно закодировать только два варианта — коды 0 и 1. А вот два бита дают как раз 4 разных сообщения: 00, 01, 10 и 11. Теперь нужно сопоставить эти коды номерам платформ, например, так: 1 — 00, 2 — 01, 3 — 10, 4 — 11. Тогда сообщение 10 говорит о том, что поезд на Москву стоит на платформе № 3. Это сообщение несет 2 бита информации.
Три бита дают уже 8 вариантов: 000, 001, 010, 011, 100, 101, 110 и 111. Таким образом, каждый бит, добавленный в сообщение, увеличивает количество вариантов в 2 раза, как показано в таблице 1.1.
Таблица 1.1
|
I, битов |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
N, вариантов |
2 |
4 |
8 |
16 |
32 |
64 |
128 |
256 |
512 |
1024 |
Наверно, вы заметили, что все числа в нижней строчке таблицы — это степени числа 2: N = 2i.
Осталось выяснить, чему равно количество информации, если выбор делается, скажем, из пяти возможных вариантов (или из любого количества, не являющегося степенью числа 2). С точки зрения приведенного выше рассуждения случаи выбора из 5, 6, 7 и 8 вариантов не различаются — для кодирования двух двоичных цифр мало, а трех — достаточно. Поэтому использование трех битов для кодирования одного из пяти возможных вариантов избыточно, ведь три бита позволяют закодировать целых 8 вариантов! Значит, выбор из пяти вариантов дает меньше трех битов информации.
Чтобы количественно измерить разницу между, скажем, 5 и 8 вариантами, придется допустить, что количество информации в битах может быть дробным числом. При этом информация, полученная при выборе из пяти вариантов, больше, чем 2 бита, но меньше, чем 3 бита. Точную формулу для ее вычисления получил в 1928 г. американский инженер Ральф Хартли.
Вы можете оценить количество информации при выборе из пяти вариантов. Допустим, на завтрак в лагере отдыха каждый день дают кашу одного из пяти видов. Чтобы закодировать вид каши, которую дают в понедельник, нужно, как мы знаем, 3 бита. Но меню на два дня может быть составлено 25 разными способами (5 ∙ 5), поэтому для его кодирования достаточно пяти битов, ведь 25 < 32 = 25! Тогда получается, что количество информации при выборе информации из пяти вариантов меньше, чем 5/2 = 2,5 бита. Но и эту оценку можно уточнить. Для трех дней получаем 5 ∙ 5 ∙ 5 = 125 вариантов. Так как 125 < 128 = 27, количество информации при выборе из пяти вариантов составляет не больше, чем 7/ 3 = 2,33 бита. И так далее. Попробуйте самостоятельно показать, что при выборе из пяти вариантов количество информации больше 2,25 бита. Верно ли, что при выборе из шести вариантов количество информации менее 2,5 бита?
Считать большие объемы информации в битах неудобно хотя бы потому, что придется работать с очень большими числами (миллиардами, триллионами и т. д.). Поэтому стоит ввести более крупные единицы.
Слово «байт [2]» (англ. byte) имеет второе значение — так называют наименьший блок (ячейку) памяти, который процессор компьютера может считать и обработать за один раз. Для современных компьютеров он состоит из 8 элементов, каждый из которых хранит 1 бит данных. Это связано с тем, что до недавнего времени при обработке текста использовался набор из 256 символов, так что для кодирования каждого символа было нужно 8 битов.
![]()
1 байт = 8 битов.
![]()
Объемы данных, с которыми работают компьютеры, нередко измеряются миллионами и миллиардами байтов. В таких случаях используют единицы, образованные с помощью приставок:
![]()
1 Кбайт (килобайт) = 1024 байта = 210 байта = 213 битов.
1 Мбайт (мегабайт) = 1024 Кбайт = 210 Кбайт = 220 байтов = 223 битов.
1 Гбайт (гигабайт) = 1024 Мбайт. 1 Тбайт (терабайт) = 1024 Гбайт.
![]()
Так сложилось исторически, что при измерении количества информации приставка «кило-» обозначает, в отличие от международной системы единиц СИ, увеличение не в 1000 раз, а в 1024 = 210 раз. Аналогично «мега-» — это увеличение в 10242 = 220 = 1 048 576 раз, а не в 1 млн = = 10002 раз.
Строго говоря, нужно называть такие кило- (мега-, гига-, ...) байты двоичными, поскольку множитель 1024 — это 210. Стандарт Международной электротехнической комиссии (МЭК) предлагает называть их «кибибайт», «мебибайт», «гибибайт» и «тебибайт», но эти названия на практике не прижились.
Для перевода количества информации из одних единиц в другие нужно использовать приведенные выше соотношения. При переводе из крупных единиц в мелкие числа умножают на соотношение между единицами. Например:
2 Кбайт = 2 ∙ (1 Кбайт) = 2 ∙ 1024 байтов = 2048 байтов = = 2048 ∙ (1 байт) = 2048 ∙ 8 битов = 16 384 бита.
2 Кбайт = 2 ∙ 210 байтов = 211 байтов = 211 ∙ 23 битов = 214 битов.
В последней строке все расчеты сделаны через степени числа 2, очень часто так бывает проще.
При переводе количества информации из мелких единиц в крупные нужно делить на соотношение между единицами. Например:
8192 бита = 8192 ∙ (1/ 8 байта) = 8192 : 8 байтов = 1024 байта = = 1024 ∙ (1/ 1024 Кбайт) = 1024 : 1024 Кбайт = 1 Кбайт.
8192 бита = 213 битов = 213 ∙ (1/ 23 байта) = 210 байтов = = 210 ∙ (1/ 210 Кбайт) = 1 Кбайт.
1. Дайте определение минимальной единицы измерения количества информации.
2. Приведите примеры сообщений, количество информации в которых равно 1 биту.
3. Что такое двоичные цифры?
4. Объясните, почему все числа во второй строке таблицы 1.1 — это степени числа 2.
5. Какие единицы используют для измерения больших объемов информации?
6. Что означают приставки «кило-», «мега-», «гига-» и «тера-» при измерении количества информации?
7. Какие приставки рекомендует МЭК для обозначения двоичных килобайта и мегабайта? Как вы думаете, почему они редко используются?
8. Какими не могут быть меры?
9. Какие два параметра измерения информации существуют?
10. Как называют числовую характеристику сигнала, отражающую ту степень неопределенности, которая исчезает после получения сообщения в виде данного сигнала?
11. Как называется минимальная единица количества информации?
12. Сколько в 1 килобайте байтов?
Связь между количеством информации и числом состояний системы устанавливается формулой Хартли (1.1):
i = log2N, (1.1)
где i — количество информации в битах; N — число возможных состояний.
Ту же формулу можно представить иначе, в виде выражения (1.2):
N = 2i. (1.2)
Пусть имеется N состояний системы S или N опытов с различными, равновозможными, последовательными состояниями системы. Если каждое состояние системы закодировать, например, двоичными кодами определенной длины d, то эту длину необходимо выбрать так, чтобы число всех различных комбинаций было бы не меньше, чем N. Наименьшее число, при котором это возможно, называется мерой разнообразия множества состояний системы и задается формулой Р. Хартли (1.3):
H = klogaN, (1.3)
где k — коэффициент пропорциональности (масштабирования, в зависимости от выбранной единицы измерения меры);
а — основание системы меры.
Если измерение ведется в экспоненциальной системе, то k = 1, H = = lnN (нат); если измерение было произведено в двоичной системе, то k = 1/ ln2, H = log2N (бит); если измерение было произведено в десятичной системе, то k = 1/ ln10, H = lgN (дит).
Например, чтобы узнать положение точки в системе из двух клеток, то есть получить некоторую информацию, необходимо задать один вопрос (Левая или правая клетка?). Узнав положение точки, мы увеличиваем суммарную информацию о системе на 1 бит (I = log22). Для системы из четырех клеток необходимо задать 2 аналогичных вопроса, а информация равна двум битам (I = log24). Если же система имеет n различных состояний, то максимальное количество информации будет определяться по формуле: I = log2n.
Справедливо утверждение Хартли: если в некотором
множестве X = {х1, х2, …, хn} необходимо выделить произвольный элемент хi ![]() X, то для
того, чтобы выделить (найти) его, необходимо получить не менее logan (единиц) информации.
X, то для
того, чтобы выделить (найти) его, необходимо получить не менее logan (единиц) информации.
Если N — число возможных равновероятных исходов, то величина klnN представляет собой меру нашего незнания о системе.
По Хартли, для того, чтобы мера информации имела практическую ценность, она должна быть такова, чтобы отражать количество информации пропорционально числу выборов.
Формула Хартли отвлечена от семантических и качественных индивидуальных свойств рассматриваемой системы (качества информации в проявлениях системы с помощью рассматриваемых N состояний системы). Это основная и положительная сторона формулы. Но имеется основная и отрицательная ее сторона: формула не учитывает различимость и различность рассматриваемых N состояний системы.
Уменьшение (увеличение) H может свидетельствовать об уменьшении (увеличении) разнообразия состояний N системы. Обратное, как это следует из формулы Хартли (так как основание логарифма больше единицы), — также верно.
Закон аддитивности информации выражается формулой (1.4):
log2 (N1 ∙ N2) = log2N1 + log2N2 , (1.4)
что совпадает с хорошо известным свойством логарифмической функции. Это закон аддитивности информации.
Например, имеется 27 монет: 26 настоящих и одна фальшивая, она легче настоящих. Сколько взвешиваний необходимо произвести, чтобы определить фальшивую монету?
Фальшивой может оказаться любая из монет, следовательно, по формуле Хартли количество недостающей информации равно log227 битов. Любое взвешивание имеет три исхода и может дать нам только log23 битов информации. Если мы производим X взвешиваний, то они дадут X ∙ log23 битов информации.
Итак, X ∙ log23 ≥ log227 = log233 = 3 ∙ log23.
Следовательно, X ≥ 3. На самом деле достаточно ровно трех взвешиваний: первое по 9 монет, второе по 3 монеты из найденной группы и, наконец, по одной монете из найденной группы по 3 монеты.
Чтобы найти элемент множества, состоящего из семи элементов, необходимо задать три вопроса, а чтобы найти элемент множества, состоящего из девяти элементов, — 4 вопроса, то есть по формуле Хартли получить log27 + log29 битов информации. Но если необходимо отгадать пару элементов из этих множеств, то требуется получить log2(7 ∙ 9) битов информации, а это меньше шести вопросов. Противоречия нет:
log2 (7 ∙ 9) = log27 + log29 = 5,97728 < 6.
1. Запишите формулу Хартли.
2. В чем суть закона аддитивности информации?
3. Пассажир не знает, какой (только один!) из 8 поездов, стоящих на вокзале, проследует в Санкт-Петербург. В справочном бюро он задает 8 вопросов: «Поезд на первой платформе проследует в Санкт-Петербург?», «Поезд на второй платформе проследует в Санкт-Петербург?» и т. д. На первые 7 вопросов он получает ответ «нет», а на последний — «да». Пассажир считает, что он получил 8 битов информации. Прав он или нет? Почему?
4. В зоопарке содержится 10 обезьян, причем одна из них выступает в цирке. Обезьяны сидят в двух вольерах, в первом — 8 животных, а во втором — два. Посетитель зоопарка считает, что сообщение «Обезьяна, выступающая в цирке, сидит во втором вольере» содержит 1 бит информации. Прав он или нет? Рассмотрите разные варианты уточнения постановки задачи.
5. В горах, рядом с которыми живет племя Тумба-Юмба, есть 4 пещеры. В каждой из них может быть (а может не быть) клад. Можно ли закодировать сведения о том, где есть клады, используя 3 бита? 4 бита? 5 битов?
6. Известно, что ровно в двух пещерах из четырех есть клады. Сколько битов нужно, чтобы закодировать информацию о расположении кладов?
7. Известно, что дверь с двумя замками открывается двумя из четырех имеющихся ключей. Оцените количество информации в сообщении «Дверь открывается ключами № 2 и № 4». Закодируйте его, используя наименьшее количество двоичных цифр.
8. Известно, что дверь открывается двумя из пяти имеющихся ключей. Оцените количество информации в сообщении «Верхний замок открывается ключом № 1, а нижний — ключом № 4». Закодируйте его, используя наименьшее количество двоичных цифр.
9. Вася задумал число от 1 до 100. Нужно отгадать это число за наименьшее число попыток, задавая Васе вопросы, на которые он отвечает только «да» и «нет». За сколько вопросов вы беретесь угадать число? Как нужно задавать вопросы, чтобы их число было минимальным даже в худшем случае?
10. Даниил задумал число от 20 до 83. Сколько битов информации содержится в сообщении «Даниил задумал число 77»? Закодируйте это сообщение, используя наименьшее количество двоичных цифр.
11. Двое играют в «крестики-нолики» на поле размером 4 × 4 клетки. Какое количество информации получил второй игрок, узнав первый ход соперника?
12. На вокзале поселка Сосново три платформы, у каждой из них стоит поезд. Девушка в справочном окне отвечает на все вопросы только «да» и «нет». За какое минимальное число вопросов можно узнать, в каком порядке отходят поезда?
13. В составе поезда 16 вагонов. Среди них есть вагоны купейные и плацкартные. Сообщение о том, что ваш знакомый приезжает в купейном вагоне несет 2 бита информации. Определите, сколько в поезде купейных вагонов?
14. В очереди за билетами на концерт стоит 16 человек. Сколько бит информации вы получаете в сообщении, что ваш знакомый стоит в этой очереди второй с конца?
15. Переведите 1 Мбайт во все изученные единицы измерения количества информации.
16. Переведите 226 битов во все изученные единицы измерения количества информации.
17. Сколько килобайтов содержится в 32 768 битах?
18. Сколько битов в 8 Кбайтах?
19. Сколько битов содержит 1/ 16 Кбайт?
20.
Сколько битов содержит 1/ 512 Мбайт?
![]()
Система счисления — способ представления любого числа с помощью некоторого алфавита символов, называемых цифрами. Существуют различные системы счисления. От их особенностей зависят наглядность представления числа при помощи цифр и сложность выполнения арифметических операций.
Двоичная единица — единица измерения энтропии и количества информации.
![]()
Энтропию в 1 бит имеет источник с двумя равновероятными сообщениями. Количество двоичных единиц указывает (с точностью до единицы) среднее число двоичных знаков, необходимое для записи сообщений данного источника в двоичном коде. Употребляются также десятичные единицы. Переход от одних единиц к другим соответствует изменению основания логарифмов в определении энтропии и количества информации (10 вместо 2).
1. Непозиционная система счисления (римская) имеет сложный способ записи чисел и громоздкие правила выполнения арифметических операций.
2. Позиционная система счисления одной и той же цифре присваивает различное значение, определяющееся позицией в последовательности цифр, изображающей число. Это значение меняется в однозначной зависимости от позиции, занимаемой цифрой, по некоторому закону. Позиционной является десятичная система, используемая в повседневной жизни. Помимо десятичной, существуют другие позиционные системы. Некоторые из них нашли применение в вычислительной технике.
В позиционной системе с основанием s любое число х может быть представлено в виде полинома от основания s:
x = εrsr + εr−1sr−1 + ... + ε1s1 + ε0s0 + ε−1s−1 + ε−2s−2 + ... , (2.1)
где в качестве коэффициентов εi , могут стоять любые из s цифр, ис-
пользуемых в системе счисления.
Принято представлять числа в виде последовательности цифр:
x = εrεr−1 ...ε1ε0 , ε−1ε−2... . (2.2)
В этой последовательности запятая отделяет целую часть числа от дробной (коэффициенты при положительных степенях чисел, включая ноль, от коэффициентов при отрицательных степенях чисел). Запятая опускается, если нет отрицательных степеней. Позиции цифр, отсчитываемые от точки, называют разрядами.
1. Десятичная система счисления — система счисления, построенная на позиционном принципе записи чисел с основанием 10, то есть в ней один и тот же знак (цифра) имеет различные значения в зависимости от того места, где он расположен. Предполагают, что выбор основания ведет свое начало от счета на пальцах. Единица каждого следующего разряда в 10 раз больше единицы предыдущего. В основании системы (d) счисления использованы 10 символов (0, 1, 2, 3, 4, 5, 6, 7, 8, 9). Для записи числа определяют, сколько в нем содержится единиц наивысшего разряда; затем определяют в остатке число единиц разряда, на единицу меньшего, и т. д. Полученные цифры записывают рядом, например: 4 ∙ 102 + 7 ∙ 101 + 3 ∙ 100 = 473.
2. Двоичная система счисления — система счисления, построенная на позиционном принципе записи чисел с основанием 2. В системе имеются только два знака — цифры 0 и 1. Число 2 считается единицей 2-го разряда и записывается в виде 10 (читается: «один — ноль»). Каждая единица следующего разряда в 2 раза больше преды дущей, то есть эти единицы составляют последовательность чисел 2, 4, 8, 16, ... , 2n, ... . Для того чтобы число, записанное в десятичной системе счисления, записать в двоичной системе счисления, его делят последовательно на 2 и записывают получающиеся остатки 0 и 1 в порядке от последнего остатка к первому. В этой системе особенно просто выполняются все арифметические действия (например: таблица умножения сводится к равенству 1 ∙ 1 = 1). Но эта система неудобна тем, что запись числа в ней очень громоздка.
3. Восьмеричная система использует 8 цифр: 0, 1, 2, 3, 4, 5, 6, 7. Например, восьмеричное число (703,04)8 = 7 ∙ 82 + 0 ∙ 81 + 3 ∙ 80 + 0 ∙ 8−1 + + 4 ∙ 8−2 = (451,0625)10.
4. Шестнадцатеричная система — для изображения чисел употребляется 16 цифр: от 0 до 15, при этом, чтобы одну цифру не изображать двумя знаками, приходится вводить специальные обозначения для цифр, больших девяти. Обозначим первые десять цифр этой системы цифрами от 0 до 9, а старшие пять цифр — латинскими буквами: 10 — A, 11 — B, 12 — C, 13 — D, 14 — E, 15 — F. Например, шестнадцатеричное число
(B2E,4)16 = 11 ∙ 162 + 2 ∙ 161 + 14 ∙ 160+4 ∙ 16−1 = (2862,25)10.
В большинстве ЭВМ используются двоичная система и двоичный алфавит для представления и хранения чисел, команд и другой информации, а также при выполнении арифметических и логических операций.
Шестнадцатеричная и восьмеричная системы применяются в текстах программ для более короткой и удобной записи двоичных кодов команд, адресов и операндов.
Так как базовые ЭЦВТ устойчивы только в двух состояниях, то для поиска решения целевой функции необходимо использовать законы математических операций над двоичными числами.
Перевод чисел между двоичной, восьмеричной и шестнадцатеричной системами счисления туда и обратно можно осуществлять с помощью поразрядового метода перевода чисел.
Для перевода из двоичной системы счисления в восьмеричную:
A число от запятой вправо и влево разбивается на группы по 3 разряда (триады);
A недостающие разряды в дробной части числа дополняются нулями;
A каждая триада двоичных цифр заменяется одной восьмеричной цифрой в соответствии с таблицей перекодировки.
При обратном переводе каждая восьмеричная цифра заменяется тройкой двоичных цифр (триадой).
Перевод из двоичной в шестнадцатеричную систему счисления делается аналогично, но вместо триад используются тетрады — группы цифр по четыре разряда.
При обратном переводе каждая шестнадцатеричная цифра заменяется четверкой двоичных цифр (тетрадой).
Таблица систем счисления представлена в приложении А.
1. Из двоичной системы в десятичную систему.
Пример: (10101)2
Записать исходное число с интервалами. 1 0 1 0 1 Под каждым символом исходного числа поставить вес позиционного места, записанного символами десятичной системы счисления.
16 8 4 2 1
Найти сумму весовых эквивалентов позиционных мест исходного числа, в которых записана «1».
16 0 4 0 1
Результат: 16 + 4 + 1 = 21.
2. Из десятичной системы в двоичную систему.
Пример: (21)10
Записать числовой ряд весов позиционных мест двоичной системы счисления до числа, вес которого больше исходного.
16 8 4 2 1
Выделить символы, сумма которых равна исходному числу.
16 4 1
Использованным местам присвоить «1», неиспользованным — «0».
1 0 1 0 1
Результат: 10101.
3. Из шестнадцатеричной системы в двоичную систему. Пример: 15
Записать исходное число с интервалами.
1 5
Под каждым знакоместом поставить тетраду двоичного эквивалента.
0001 0101
Объединить символы в единое слово.
00010101
Результат: 10101.
4. Из шестнадцатеричной системы в десятичную систему. Пример: 15
Записать исходное число с интервалами.
1 5
Под каждым символом исходного числа поставить вес позиционного места, записанного символами десятичной системы счисления.
16 1
Найти истинный вес каждой позиции умножением символа на вес места.
1 ∙ 16 5 ∙ 1
Сумма произведений будет равна искомому числу. Результат: 16 + 5 = 21.
5. Из восьмеричной системы в двоичную.
Пример: (25)8
Записать исходное число с интервалами.
2 5
Под каждым знакоместом поставить триаду двоичного эквивалента.
010 101
Объединить символы в единое слово.
010101
Результат: 10101.
1. Что такое система счисления?
2. Как называется единица измерения количества информации?
3. Какая система счисления одной и той же цифре присваивает различное значение, определяющееся позицией в последовательности цифр, изображающей число?
4. Какая система счисления построена на позиционном принципе записи чисел с основанием 10?
5. Какая система счисления построена на позиционном принципе записи чисел с основанием 8?
6. Что такое триада? Где она используется?
7. Что такое тетрада? Где она используется?
8. В чем различие между триадой и тетрадой?
9. Сложить числа в шестнадцатеричной системе счисления: 2ADEC и FAEDA.
10. Умножить числа в восьмеричной системе счисления: 761 и 205.
11. Переведите число 703,04 из восьмеричной системы счисления в десятичную.
12. Переведите число B2E,4 из шестнадцатеричной системы счисления в десятичную.
13. Переведите в двоичную и восьмеричную системы числа 7F1A16, C73B16,
2FE116, A11216.
14. Переведите в двоичную и шестнадцатеричную системы числа 61728,
53418, 77118, 12348.
15. Переведите в восьмеричную и шестнадцатеричную системы числа
а) 11101111010102; в) 1111001101111101012;
б) 10101011010101102; г) 1101101101011111102.
16. Переведите числа 29, 43, 54, 120, 206 в шестнадцатеричную, восьмеричную и двоичную системы счисления.
17. Переведите числа 738, 1348, 2458, 3568 и 4678 в шестнадцатеричную, десятичную и двоичную системы счисления.
18. Запишите числа 101101012, 11101002, 10001112, 101111102 в шестнадцатеричной, восьмеричной и десятичной системах счисления.
19. Переведите числа 49,6875 и 52,9 в шестнадцатеричную систему счисления.
Арифметические операции над двоичными числами представлены в таблице 2.1.
Таблица 2.1
|
Сложение |
Вычитание |
Умножение |
Деление |
|
0 + [3] = 0 0 + [4] = 1 1 + 0 = 1 1 + 1 = 0 и «1» переноса в ст. разряд суммы |
0 − 0 = 0 1 − 0 = 1 1 − 1 = 0 10 − 1 = 1 необходима «1» замена из ст. разряда |
0 ∙ 0 = 0 0 ∙ 1 = 0 1 ∙ 0 = 0 1 ∙ 1 = 1 |
0 : 1 = 0 1 : 1 = 1 |
1. Сложение. Рассмотрим сложение чисел в двоичной системе счисления. В его основе лежит таблица сложения одноразрядных двоичных чисел: 0 + 0 = 0
0 + 1 = 1
1 + 0 = 1
1 + 1 = 10
Важно обратить внимание на то, что при сложении двух единиц происходит переполнение разряда и производится перенос в старший разряд. Переполнение разряда наступает тогда, когда величина числа в нем становится равной или большей основания.
Сложение многоразрядных двоичных чисел происходит в соответствии с вышеприведенной таблицей сложения с учетом возможных переносов из младших разрядов в старшие. В качестве примера сложим в столбик двоичные числа 1102 и 112:
![]()
2. Вычитание. Рассмотрим вычитание двоичных чисел. В его основе лежит таблица вычитания одноразрядных двоичных чисел. При вычитании из меньшего числа (0) большего (1) производится заем из старшего разряда. Заем обозначен единицей с чертой: 0 − 0 = 0
Вычитание многоразрядных двоичных чисел происходит в соответствии с вышеприведенной таблицей вычитания с учетом возможных заемов из старших разрядов. В качестве примера произведем вычитание двоичных чисел 1102 и 112:
![]()
3. Умножение. В основе умножения лежит таблица умножения одноразрядных двоичных чисел:
0 ∙ 0 = 0
0 ∙ 1 = 0
1 ∙ 0 = 0
1 ∙ 1 = 1
Умножение многоразрядных двоичных чисел происходит в соответствии с вышеприведенной таблицей умножения по обычной схеме, применяемой в десятичной системе счисления, с последовательным умножением множимого на цифры множителя. В качестве примера произведем умножение двоичных чисел 1102 и 112:
![]()
4. Деление. Операция деления выполняется по алгоритму, подобному алгоритму выполнения операции деления в десятичной системе счисления. В качестве примера произведем деление двоичного числа 1102 на 112:
![]()
В примерах для получения результата при умножении и сложении чисел применение таблиц «Сложение» и «Умножение» начинается с младших разрядов. При делении чисел использование таблицы «Вычитание» начинается со старших разрядов.
Любая математическая операция над двоичными числами требует выполнения команд «сложить», «вычесть», «сдвинуть» (вправо или влево).
Можно выполнять арифметические действия в восьмеричной и шестнадцатеричной системах счисления. Необходимо только помнить, что величина переноса в следующий разряд при сложении и заем из старшего разряда при вычитании, определяются величиной основания системы счисления:
![]()
![]()
Для проведения арифметических операций над числами, выраженными в различных системах счисления, необходимо предварительно перевести их в одну и ту же систему. Примеры арифметических операций над двоичными числами представлены в таблице 2.2.
Таблица 2.2
Примеры арифметических операций над двоичными числами
|
Сложение |
Умножение |
Деление |
|
|
|
|
1. Какие три команды выполняются при любых математических операциях над двоичными числами?
2. Вычислите значения следующих выражений:
а) 3AF16 + 1CBE16; г) 1CFB16 − 22F16;
б) 1EA16 + 7D716; д) 22F16 − CFB16;
в) A8116 + 37716; е) 1AB16 − 2CD16.
3. Вычислите значения следующих выражений, запишите результат в двоичной, восьмеричной, десятичной и шестнадцатеричной системах счисления:
а) 4F16 + 1111102; г) 1101112 + 1358;
б) 5A16 + 10101112; д) 1216 + 128 ∙ 112;
в) 2568 + 2C16; е) 358 + 2C16 ∙ 1012.
4. Вычислите значения следующих выражений, запишите результат в двоичной, восьмеричной, десятичной и шестнадцатеричной системах счисления:
а) 1516 ∙ 1102; в) 3416 : 328;
б) 2A16 ∙ 128; г) 7408 : 1816.
Поскольку в современных компьютерах информация всех видов представлена в двоичном коде, нужно разобраться, как закодировать символы в виде цепочек нулей и единиц. Например, можно предложить способ, основанный на системе Брайля для незрячих людей. В нем каждый символ кодируется с помощью шести точек, расположенных в два столбца. В каждой точке может быть выпуклость, которая чувствуется на ощупь. Обозначив выпуклость единицей, а ее отсутствие — нулем, можно закодировать первые буквы русского алфавита так, как показано на рисунке 3.1.
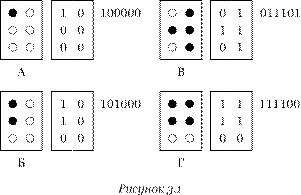
Здесь двоичный код строится так: строки полученной таблицы, состоящей из цифр 0 и 1, выписываются одна за другой в строчку. Так как используются всего 6 точек, количество символов, которые можно закодировать, равно 26 = 64 (в реальной системе Брайля 63 символа, потому что символ, в коде которого нет ни одной выпуклости, невозможно обнаружить на ощупь).
Понятно, что совершенно не обязательно использовать код Брайля. Главное — каждому используемому символу как-то сопоставить цепочку нулей и единиц, например, составить таблицу «символ — код». На практике поступают следующим образом:
A определяют, сколько символов нужно использовать (обозначим это число через N);
A определяют нужное количество k двоичных разрядов так, чтобы с их помощью можно было закодировать не менее N разных последовательностей (то есть 2k ≥ N);
A составляют таблицу, в которой каждому символу сопоставляют код
(номер) — целое число в интервале от 0 до 2k − 1;
A коды символов переводят в двоичную систему счисления.
В текстовых файлах (которые не содержат оформления, например, в файлах с расширением txt) хранятся не изображения символов, а их коды. Откуда же компьютер берет изображения символов, когда выводит текст на экран? Оказывается, при этом с диска загружается шрифтовой файл (он может иметь, например, расширение fon, ttf, otf), в котором хранятся изображения, соответствующие кодам [5]. Именно эти изображения и выводятся на экран. Это значит, что при изменении шрифта текст, показанный на экране, может выглядеть совсем по-другому. Например, многие шрифты не содержат изображений русских букв. Поэтому, когда вы передаете (или пересылаете) кому-то текстовый файл, нужно убедиться, что у адресата есть использованный вами шрифт. Современные текстовые процессоры умеют внедрять шрифты в файл; в этом случае файл содержит не только коды символов, но и шрифтовые файлы. Хотя файл увеличивается в объеме, адресат гарантированно увидит его в таком же виде, что и вы.
Для того чтобы упростить передачу текстовой информации, разработаны стандарты, которые закрепляют определенные коды за общеупотребительными символами. Основным международным стандартом является 7-битная кодировка ASCII (англ. American Standard Code for Information Interchange — американский стандартный код для обмена информацией), в которую входят 27 = 128 символов с кодами от 0 до 127:
A служебные (управляющие) символы с кодами от 0 до 31;
A символ «пробел» с кодом 32;
A цифры от «0» до «9» с кодами от 48 до 57;
A латинские буквы: заглавные, от «A» до «Z» (с кодами от 65 до 90) и строчные, от «a» до «z» (с кодами от 97 до 122); A знаки препинания: . , : ; ! ?
A скобки: [ ] { } ( )
A математические символы: + − * / = < >
A некоторые другие знаки: “ ‘ # $ % & ^ | @ \ _ ~
В современных компьютерах минимальная единица памяти, имеющая собственный адрес, — это байт (8 битов). Поэтому для хранения кодов ASCII в памяти можно добавить к ним еще один (старший) нулевой бит, таким образом, получая 8-битную кодировку. Кроме того, дополнительный бит можно использовать: он дает возможность добавить в таблицу еще 128 символов с кодами от 128 до 255. Такое расширение ASCII часто называют кодовой страницей. Первую половину кодовой страницы (коды от 0 до 127) занимает стандартная таблица ASCII, а вторую — символы национальных алфавитов (например, русские буквы). Этот принцип показан на рисунке 3.2.
0 127 128 255
|
ASCII |
|
Национальные алфавиты |
|
|
Кодовая страница |
|
Рисунок 3.2
Для русского языка существуют несколько кодовых страниц, которые были разработаны для разных операционных систем. Наиболее известные из них:
A кодовая страница Windows-1251 (СР-1251) — в системе Windows;
A кодовая страница KOI8-R — в системе Unix;
A альтернативная кодировка (СР-866) — в системе MS DOS; A кодовая страница MacCyrillic — на компьютерах фирмы Apple (Макинтош и др.).
Проблема состоит в том, что, если набрать русский текст в одной кодировке (например, в Windows-1251), а просматривать в другой (например, в KOI8-R), текст будет невозможно прочитать. Результат отображения текста с использованием разных кодировок приведен в таблице 3.1.
Таблица 3.1
|
Windows-1251 |
KOI8-R |
|
Привет, Вася! |
оПХБЕР, бЮЯЪ! |
|
рТЙЧЕФ, чБУС! |
Привет, Вася! |
Для веб-страниц в интернете часто используют кодировки Windows-1251 и KOI8-R. Браузер после загрузки страницы пытается автоматически определить ее кодировку. Если ему это не удается, вы видите странный набор букв вместо понятного русского текста. В этом случае нужно сменить кодировку вручную с помощью меню Вид браузера.
Любая 8-битная кодовая страница имеет серьезное ограничение — она может включать только 256 символов. Поэтому не получится набрать в одном документе часть текста на русском языке, а часть — на китайском. Кроме того, существует проблема чтения документов, набранных с использованием другой кодовой страницы. Все это привело к принятию в 1991 г. нового стандарта кодирования символов — UNICODE, который позволяет записывать знаки любых существующих (и даже некоторых «мертвых») языков, математические и музыкальные символы и др.
Если мы хотим расширить количество используемых знаков, необходимо увеличивать место, которое отводится под каждый символ. Вы знаете, что компьютер работает сразу с одним или несколькими байтами, прочитанными из памяти. Например, если увеличить место, отводимое на каждый символ, до двух байтов, то можно закодировать 216 = 65 536 символов в одном наборе. В современной версии UNICODE можно кодировать до 1 112 064 различных знаков, однако реально используются немногим более 100 000 символов.
В системе Windows используется кодировка UNICODE, называемая UTF-16 (от англ. UNICODE Transformation Format — формат преобразования UNICODE). В ней все наиболее важные символы кодируются с помощью 16 битов (двух байтов), а редко используемые — с помощью четырех байтов.
В Unix-подобных системах, например, в Linux, чаще применяют кодировку UTF-8. В ней все символы, входящие в таблицу ASCII, кодируются в виде 1 байта, а другие символы могут занимать от 2 до 4 байтов. Если значительную часть текста составляют латинские буквы и цифры, такой подход позволяет значительно уменьшить объем файла по сравнению с UTF-16. Текст, состоящий только из символов таблицы ASCII, кодируется точно так же, как и в кодировке ASCII. По данным поисковой системы Google, на начало 2010 г. около 50 % сайтов в интернете использовали кодировку UTF-8.
Кодировки стандарта UNICODE позволяют использовать символы разных языков в одном документе. За это приходится «расплачиваться» увеличением объема файлов.
1. Вы хотите использовать в тексте придуманный собственный символ, которого нет ни в одном шрифте. Какими путями это можно сделать?
2. Вы сами разработали шрифт и хотите переслать другу документ, в котором этот шрифт используется. Какими способами это можно сделать?
3. В чем недостатки и преимущества внедрения шрифтов в документ?
4. Что представляет собой кодировка ASCII? Сколько символов включает эта кодировка?
5. Почему в современных компьютерах используются кодировки, в которых каждый символ занимает целое число байтов?
6. Что такое кодовая страница?
7. Назовите основные кодовые станицы, содержащие русские буквы.
8. Почему использование кодовых страниц для кодирования текста может привести к проблемам?
9. Что делать, если вы видите непонятный набор символов на веб-странице?
10. В чем состоит ограничение 8-битных кодировок?
1. Сколько символов можно закодировать с помощью 5-битного кода? 9-битного?
2. Сколько битов нужно выделить на символ для того, чтобы использовать в одном документе 100 разных символов? 200? 500?
3. Какой символ имеет код 100 в кодировке ASCII?
4. Определите, чему равен информационный объем следующего высказывания Рене Декарта, закодированного с помощью 16-битной кодировки UNICODE: Я мыслю, следовательно, существую.
5. При перекодировке сообщения на русском языке из 16-битного кода UNICODE в 8-битную кодировку KOI8-R оно уменьшилось на 480 битов. Какова длина сообщения в символах?
6. При перекодировке сообщения из 8-битного кода в 16-битную кодировку UNICОDE его объем увеличился на 2048 байтов. Каков был информационный объем сообщения до перекодировки?
7. В таблице 3.2 представлена часть кодовой таблицы ASCII. Каков шестнад цатеричный код символа «q»?
Таблица 3.2
|
Символ |
1 |
5 |
A |
B |
Q |
a |
b |
|
Десятичный код |
49 |
53 |
65 |
66 |
81 |
97 |
98 |
|
Шестнадцатеричный код |
31 |
35 |
41 |
42 |
51 |
61 |
62 |
![]()
Кодирование — процесс преобразования информационных сообщений в комбинацию дискретных сигналов.
Код — совокупность правил, по которым производится данное преобразование.
Кодовая комбинация — последовательность элементов, составленная из некоторых условных символов.
![]()
На рисунке 3.3 представлены характеристики кода.

Представление чисел в памяти компьютера имеет специфическую особенность, связанную с тем, что в памяти компьютера они должны располагаться в байтах — минимальных по размеру адресуемых (то есть к ним возможно обращение) ячейках памяти. Очевидно, адресом числа следует считать адрес первого байта. В байте может содержаться произвольный код из восьми двоичных разрядов, и задача представления состоит в том, чтобы указать правила, как в одном или нескольких байтах записать число.
Действительное число многообразно в своих «потребительских свойствах». Числа могут быт целые точные, дробные точные, рациональные, иррациональные, дробные приближенные, числа могут быть положительными и отрицательными. Числа могут быть «карликами», например, масса атома, «гигантами», например, масса Земли, реальными, например, количество студентов в группе, возраст, рост. И каждое из перечисленных чисел потребует для оптимального представления в памяти свое количество байтов.
Очевидно, единое оптимальное представление для всех действительных чисел создать невозможно, поэтому создатели вычислительных систем пошли по пути разделения единого по сути множества чисел на типы (например, целые в диапазоне от ... до ... , приближенные с плавающей точкой с количеством значащих цифр и т. д.). Для каждого в отдельности типа создается собственный способ представления.
Целые положительные числа от 0 до 255 можно представить непосредственно в двоичной системе счисления (двоичном коде), как показано в таблице 3.3. Такие числа будут занимать 1 байт в памяти компьютера.
Таблица 3.3
|
Число |
Двоичный код |
|
0 |
0000 0000 |
|
1 |
0000 0001 |
|
2 |
0000 0010 |
|
3 |
0000 0011 |
|
… |
… |
|
255 |
1111 1111 |
В такой форме представления легко реализуется на компьютерах двоичная арифметика.
Если нужны и отрицательные числа, то знак числа может быть закодирован отдельным битом, обычно это старший бит; ноль интерпретируется как плюс, единица как минус. В таком случае одним байтом могут быть закодированы целые числа в интервале от −127 до +127, причем двоичная арифметика будет несколько усложнена, так как в этом случае существуют два кода, изображающие число ноль: 0000 0000 и 1000 0000, и в компьютерах на аппаратном уровне это потребуется предусмотреть. Рассмотренный способ представления целых чисел называется прямым кодом.
Положение с отрицательными числами несколько упрощается, если использовать так называемый дополнительный код. В дополнительном коде положительные числа совпадают с положительными числами в прямом коде, отрицательные же числа получаются в результате вычитания из 1 000 000 соответствующего положительного числа. Например, −3 получит следующий код:
![]() .
.
В дополнительном коде хорошо реализуется арифметика, так как каждый последующий код получается из предыдущего прибавлением единицы с точностью до бита в девятом разряде. Например, 5 − 3 = 5 + (−3).
![]() ,
,
то есть отбрасывая подчеркнутый старший разряд, получим 2.
Аналогично целые числа от 0 до 65 536 и целые числа от −32 768 до 32 767 в двоичной (шестнадцатеричной) системе счисления представляются в двухбайтовых ячейках. Существуют представления целых чисел и в четырехбайтовых ячейках.
Действительные числа в математике представляются конечными или бесконечными дробями, то есть точность представления чисел не ограничена. Однако в компьютерах числа хранятся в регистрах и ячейках памяти, которые представляют собой последовательность байтов с ограниченным количеством разрядов. Следовательно, бесконечные или очень длинные числа усекаются до некоторой длины и в компьютерном представлении выступают как приближенные. В большинстве систем программирования в написании действительных чисел целая и дробная части разделяются не запятой, а точкой.
Для представления действительных чисел, как очень маленьких, так и очень больших, удобно использовать форму записи чисел в виде произведения, как показано в формуле (3.1).
Такой способ записи чисел называется представлением чисел с плавающей точкой.
X = m ∙ q p, (3.1)
где m — мантисса числа; q — основание системы счисления; p — целое число, называемое порядком.
То есть число 1234,56 может быть записано в одном из видов:
1234,56 = 123,456 ∙ 101 = 12,3456 ∙ 102 = 1,23456 ∙ 103 = = 0,123456 ∙ 104.
Очевидно, такое представление не однозначно. Если мантисса для десятичной системы счисления отвечает условию (3.2):
1/ q ≤ |m| < q (0,1 ≤ |m| < 1), (3.2)
то представление числа становится однозначным, а такая форма называется нормализованной. Если «плавающая» точка расположена в мантиссе перед первой значащей цифрой, то при фиксированном количестве разрядов, отведенных под мантиссу, обеспечивается запись максимального количества значащих цифр числа, то есть максимальная точность.
Действительные числа в компьютерах различных типов записываются по-разному, тем не менее существует несколько международных стандартных форматов, различающихся по точности, но имеющих одинаковую структуру. Рассмотрим это на примере 4-байтного числа, представленного на рисунке 3.4.
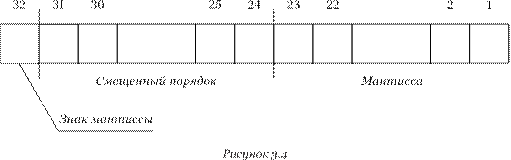
Первый разряд представления используется для записи знака мантиссы. За ним следует группа разрядов, определяющих порядок, а остальные разряды определяют абсолютную величину мантиссы. Размеры обеих групп разрядов фиксируются.
Так как порядок может быть положительным или отрицательным, нужно решить проблему его знака. Величина порядка представления с избытком, то есть вместо истинного значения порядка хранится число, называемое характеристикой (или смещенным порядком). Для получения характеристики необходимо к порядку прибавить смещение. Например, при использовании для хранения порядка 8 бит и значений от −128 до +127 используется смещение 128. Тогда для представления порядка будут использоваться значения от 0 до +255, то есть только неотрицательные числа.
Так как мантисса нормализованного числа всегда равна единице, некоторые схемы представления ее лишь подразумевают, используя лишний разряд для повышения точности представления мантиссы.
Использование смещенной формы позволяет производить операции сравнения, сложения и вычитания порядков, а также упрощает операцию сравнения самих нормализованных чисел.
Чем больше разрядов отводится под запись мантиссы, тем выше точность представления числа. Чем больше разрядов занимает порядок, тем шире диапазон от наименьшего отличного от нуля числа до наибольшего числа, представимого в компьютере при заданном формате.
Как и в случае целых чисел, в программных системах могут использоваться несколько типов данных, реализующих модель с плавающей точкой. Например, в языке Си применяются три типа данных с разной «длиной». Шестнадцатиразрядные компиляторы для IBM-совместимых ПК реализуют эти типы следующим образом:
A Float — 4 байта, из них 23 разряда мантиссы и 8 битов порядка (обеспечивает точность с 7 значащими цифрами);
A Double — 8 байтов, из них 52 разряда мантиссы и 11 битов порядка (обеспечивает точность с 15 знаками);
A Long double — 10 байтов, из них 65 разрядов мантиссы и 14 битов порядка (обеспечивает точность с 19 знаками).
Положительные числа в прямом, обратном и дополнительном кодах изображаются одинаково — двоичными кодами с цифрой 0 в знаковом разряде. Например:
Число 110 = 12 Число 12710 = 11111112
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
|
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
![]()
![]()
Знак числа «+» Знак числа «−»
Отрицательные числа в прямом, обратном и дополнительном кодах имеют разное изображение.
1. Прямой код. В знаковый разряд помещается цифра 1, а в разряды цифровой части числа — двоичный код его абсолютной величины.
Например:
Прямой код числа −1 Прямой код числа −127
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
![]()
![]()
Знак числа «−» Знак числа «−»
2. Обратный код. Получается инвертированием всех цифр двоичного кода абсолютной величины числа, включая разряд знака: нули заменяются единицами, а единицы — нулями. Например:
Число: −1 Число: −127
Код модуля числа: 0 0000001 Код модуля числа: 0 1111111
Обратный код числа: 1 1111110 Обратный код числа: 1 0000000
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
3. Дополнительный код. Получается образованием обратного кода с последующим прибавлением единицы к его младшему разряду.
Например:
Дополнительный код числа −1 Дополнительный код числа −127
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
1 |
0 |
0 |
0 |
0 |
0 |
0 |
1 |
Обычно отрицательные десятичные числа при вводе в машину автоматически преобразуются в обратный или дополнительный двоичный код и в таком виде хранятся, перемещаются и участвуют в операциях. При выводе таких чисел из машины происходит обратное преобразование в отрицательные десятичные числа.
1. Что называется кодом?
2. Дайте определение кодовой комбинации. 3. Что понимают под прямым кодом числа?
4. Как образуется обратный код целого положительного числа?
5. Как образуется обратный код целого отрицательного числа?
6. Каков алгоритм сложения чисел в прямом коде?
7. Каков алгоритм сложения чисел в обратном коде?
8. Запишите числа X и Y в прямом, обратном и дополнительном кодах. Выполните сложение в обратном и дополнительном кодах. Результат переведите в прямой код. Полученный результат проверьте, используя правила двоичной арифметики. а) Х = −110101, Y = 11101;
б) Х = −1000011, Y = 10011;
в) Х = −1010111, Y = 11100;
г) X = 111000, Y = 101010;
д) X = 100001, Y = 110011.
Рисунок состоит из линий и закрашенных областей. В идеале нам нужно закодировать все особенности этого изображения так, чтобы его можно было в точности восстановить из кода (например, распечатать на принтере).
И линия, и область состоят из бесконечного числа точек. Цвет каждой из этих точек нам нужно закодировать. Если их бесконечно много, мы сразу приходим к выводу, что для этого нужно бесконечно много памяти. Поэтому «поточечным» способом изображение закодировать не удастся. Однако эту идею все-таки можно использовать.
Начнем с черно-белого изображения, показанного на рисунке 3.5. Представим себе, что на изображение ромба наложена сетка, которая разбивает его на квадратики. Такая сетка называется растром. Теперь для каждого квадратика определим цвет (черный или белый). Для тех квадратиков, в которых часть оказалась закрашена черным цветом, а часть — белым, выберем цвет в зависимости от того, какая часть (черная или белая) больше.
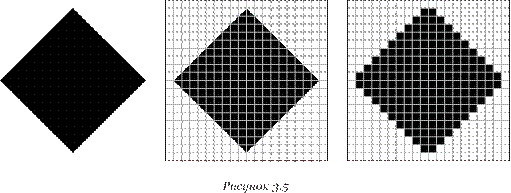
У нас получился так называемый растровый рисунок, состоящий из квадратиков-пикселей.
![]()
Пиксель (англ. pixel — picture element, элемент рисунка) — это наименьший элемент рисунка, для которого можно независимым образом задать свой цвет.
![]()
Разбив «обычный» рисунок на квадратики, мы выполнили его дискре тизацию — разделили единый объект на отдельные элементы. Действительно, у нас был единый рисунок — изображение ромба. В результате мы получили дискретный объект — набор пикселей.
Двоичный код для черно-белого рисунка, полученного в результате дискретизации, можно построить следующим образом: A заменяем белые пиксели нулями, а черные — единицами; A выписываем строки таблицы одну за другой.
Покажем это на простом примере, представленном на рисунке 3.6.
|
|
|
|
|
|
|
|
|
|
0 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
|
|
|
|
|
|
|
|
|
0 |
0 |
1 |
0 |
0 |
1 |
1 |
0 |
|
|
|
|
|
|
|
|
|
|
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
|
|
|
|
|
|
|
|
|
|
1 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
|
|
|
|
|
|
|
|
|
0 |
1 |
0 |
0 |
0 |
0 |
1 |
0 |
|
|
|
|
|
|
|
|
|
|
0 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
|
|
|
|
|
|
|
|
|
|
0 |
1 |
0 |
1 |
1 |
0 |
1 |
0 |
|
|
|
|
|
|
|
|
|
|
0 |
1 |
1 |
1 |
1 |
1 |
1 |
0 |
Рисунок 3.6
Ширина этого рисунка — 8 пикселей, поэтому каждая строка таблицы состоит из 8 двоичных разрядов — битов. Чтобы не писать очень длинную цепочку нулей и единиц, удобно использовать шестнадцатеричную систему счисления, закодировав 4 соседних бита (тетраду) одной шестнадцатеричной цифрой. Например, для первой строки получаем код 1А16 (рисунок 3.7), а для всего изображения: 1A2642FF425A5A7E16.
|
0 |
0 |
0 |
1 |
1 |
0 |
1 |
0 |
116 A16
Рисунок 3.7
Очень важно понять, что мы приобрели и что потеряли в результате дискретизации. Самое важное: мы смогли закодировать рисунок в двоичном коде. Однако при этом рисунок исказился — вместо ромба мы получили набор квадратиков. Причина искажения в том, что в некоторых квадратиках части исходного рисунка были закрашены разными цветами, а в закодированном изображении каждый пиксель обязательно имеет один цвет. Таким образом, часть исходной информации при кодировании была потеряна. Это наглядно проявится, например, при увеличении рисунка — квадратики увеличатся, и рисунок еще больше исказится.
Чтобы уменьшить потери информации, нужно уменьшать размер пикселя, то есть увеличивать разрешение.
Разрешение обычно измеряется в пикселях на дюйм. Используется английское обозначение ppi — pixels реr inch. Например, разрешение 254 ppi означает, что на дюйм (25,4 мм) приходится 254 пикселя, так что каждый пиксель «содержит» квадрат исходного изображения размером 0,1 × 0,1 мм. Если провести дискретизацию рисунка размером 10 × 15 см с разрешением 254 ppi, высота закодированного изображения будет 100/ 0,1 = 1000 пикселей, а ширина — 1500 пикселей.
![]()
Разрешение — это количество пикселей, приходящихся на единицу линейного размера изображения.
![]()
Чем больше разрешение, тем точнее кодируется рисунок (меньше информации теряется), однако одновременно растет и объем файла.
Что делать, если рисунок цветной? В этом случае для кодирования цвета пикселя уже не обойтись одним битом. Например, в представленном на рисунке 3.8, а, изображении российского флага 4 цвета: черный, синий, красный и белый. Для кодирования одного из четырех вариантов нужно 2 бита, поэтому код каждого цвета (и код каждого пикселя) будет состоять из двух битов. Пусть 00 обозначает черный цвет, 01 — красный, 10 — синий и 11 — белый. Получаем таблицу, которая показана на рисунке 3.8, б.
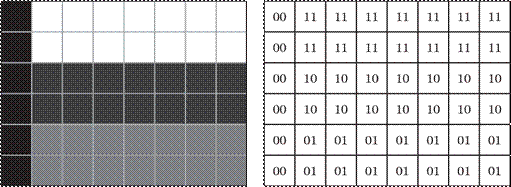
а б
Рисунок 3.8
Проблема только в том, что при выводе на экран нужно как-то определить, какой цвет соответствует тому или другому коду. То есть информацию о цвете для вывода на экран нужно выразить в виде числа (или набора чисел).
Человек воспринимает свет как множество электромагнитных волн. Определенная длина волны соответствует некоторому цвету. Например, волны длиной 500–565 нм — это зеленый цвет. Так называемый «белый» свет на самом деле представляет собой смесь волн, длины которых охватывают весь видимый диапазон.
 Согласно современному
представлению о цветном зрении (теории Юнга—Гельмгольца), глаз человека содержит
чувствительные элементы (рецепторы) трех типов. Каждый из них воспринимает весь
поток света, но первые наиболее чувствительны в области красного цвета, вторые
— в области зеленого цвета, третьи — в области синего цвета. Цвет — это результат
возбуждения всех трех типов рецепторов. Поэтому считается, что любой цвет (то есть
ощущения человека, воспринимающего волны определенной длины) можно имитировать,
используя только три световых луча (красный, зеленый и синий) разной яркости. Следовательно,
любой цвет (в том числе и «белый») приближенно раскладывается на три составляющих
— красную, Рисунок 3.9 зеленую и синюю. Меняя силу
этих составляющих, можно составить любые цвета. Эта модель цвета получила название
RGB по начальным буквам английских слов «red» (красный), «green» (зеленый)
и «blue» (синий). Результат смешения базовых цветов цветовой модели RGB представлен
на рисунке 3.9 и рисунке Б.1 приложения Б.
Согласно современному
представлению о цветном зрении (теории Юнга—Гельмгольца), глаз человека содержит
чувствительные элементы (рецепторы) трех типов. Каждый из них воспринимает весь
поток света, но первые наиболее чувствительны в области красного цвета, вторые
— в области зеленого цвета, третьи — в области синего цвета. Цвет — это результат
возбуждения всех трех типов рецепторов. Поэтому считается, что любой цвет (то есть
ощущения человека, воспринимающего волны определенной длины) можно имитировать,
используя только три световых луча (красный, зеленый и синий) разной яркости. Следовательно,
любой цвет (в том числе и «белый») приближенно раскладывается на три составляющих
— красную, Рисунок 3.9 зеленую и синюю. Меняя силу
этих составляющих, можно составить любые цвета. Эта модель цвета получила название
RGB по начальным буквам английских слов «red» (красный), «green» (зеленый)
и «blue» (синий). Результат смешения базовых цветов цветовой модели RGB представлен
на рисунке 3.9 и рисунке Б.1 приложения Б.
В модели RGB яркость каждой составляющей (или, как говорят, каждого канала) чаще всего кодируется целым числом от 0 до 255. При этом код цвета — это тройка чисел (R, G, B) — яркости отдельных каналов. Цвет (0, 0, 0) — это черный цвет, а (255, 255, 255) — белый. Если все составляющие имеют равную яркость, получаются оттенки серого цвета: от черного до белого.
Чтобы сделать светло-красный (розовый) цвет, нужно при максимальной яркости красного цвета (255, 0, 0) одинаково увеличить яркость зеленого и синего каналов, например, цвет (255, 150, 150) — это розовый. Равномерное уменьшение яркости всех каналов создает темный цвет, например, цвет с кодом (100, 0, 0) — темно-красный.
При кодировании цвета на веб-страницах также используется модель RGB, но яркости каналов записываются в шестнадцатеричной системе счисления (от 0016 до FF16 ), а перед кодом цвета ставится знак #. Например, код красного цвета записывается как #FF0000, а код синего — как #0000FF. Коды некоторых цветов приведены в таблице 3.4.
Всего есть по 256 вариантов яркости каждого из трех основных цветов. Это позволяет закодировать 2563 = 16 777 216 оттенков, что более чем достаточно для человека. Так как 256 = 28, каждая из трех составляющих занимает в памяти 8 битов, или 1 байт, а вся информация о каком-то цвете — 24 бита (3 байта). Эта величина называется глубиной цвета.
![]()
Глубина цвета — это количество битов, используемое для кодирования цвета пикселя.
![]()
Таблица 3.4
|
Цвет |
Код (R, G, B) |
Код на веб-странице |
|
Красный |
(255, 0, 0) |
#FF0000 |
|
Зеленый |
(0, 255, 0) |
#00FF00 |
|
Синий |
(0, 0, 255) |
#0000FF |
|
Белый |
(255, 255, 255) |
#FFFFFF |
|
Черный |
(0, 0, 0) |
#000000 |
|
Серый |
(128, 128, 128) |
#808080 |
|
Пурпурный |
(255, 0, 255) |
#FF00FF |
|
Голубой |
(0, 255, 255) |
#00FFFF |
|
Желтый |
(255, 255, 0) |
#FFFF00 |
|
Темно-пурпурный |
(128, 0, 128) |
#800080 |
|
Светло-желтый |
(255, 255, 128) |
#FFFF80 |
24-битовое кодирование цвета часто называют режимом истинного цвета (англ. True color — истинный цвет). Для вычисления объема рисунка в байтах при таком кодировании нужно определить общее количество пикселей (перемножить ширину и высоту) и умножить результат на 3, так как цвет каждого пикселя кодируется тремя байтами. Например, рисунок размером 20 × 30 пикселей, закодированный в режиме истинного цвета, будет занимать 20 ∙ 30 ∙ 3 = 1800 байтов. Конечно, здесь не учитывается сжатие (уменьшение объема файлов с помощью специальных алгоритмов), которое применяется во всех современных форматах графических файлов. Кроме того, в реальных файлах есть заголовок, в котором записана служебная информация (например, размеры рисунка).
Кроме режима истинного цвета используется также 16-битное кодирование (англ. High Color — «высокий» цвет), когда на красную и синюю составляющие отводится по 5 битов, а на зеленую, к которой челове ческий глаз более чувствителен, — 6 битов. В режиме High Color можно закодировать 216 = 65 536 различных цветов. В мобильных телефонах иногда применяют 12-битное кодирование цвета (4 бита на канал, 4096 цветов).
Как правило, чем меньше цветов используется, тем больше будет искажаться цветное изображение. Таким образом, при кодировании цвета тоже есть неизбежная потеря информации, которая «добавляется» к потерям, вызванным дискретизацией. Однако при увеличении количества используемых цветов растет объем файла. Например, в режиме истинного цвета файл получится в два раза больше, чем при 12-битном кодировании.
Очень часто (например, в схемах, диаграммах и чертежах) количество цветов в изображении невелико (не более 256). В этом случае применяют кодирование с палитрой.
![]()
Цветовая палитра — это таблица, в которой каждому цвету, заданному в виде составляющих в модели RGB, сопоставляется числовой код.
![]()
Кодирование с палитрой выполняется следующим образом:
A выбирается количество цветов N (как правило, не более 256);
A из палитры истинного цвета (16 777 216 цветов) выбираются любые N цветов и для каждого из них находятся составляющие в модели RGB;
A каждому из выбранных цветов присваивается номер (код) от 0 до N − 1;
A составляется палитра: сначала записываются RGB-составляющие цвета, имеющего код 0, затем — составляющие цвета с кодом 1 и т. д.;
A цвет каждого пикселя кодируется не в виде значений RGBсоставляющих, а как номер цвета в палитре.
Например, при кодировании изображения российского флага были выбраны 4 цвета:
A черный: RGB-код (0, 0, 0); двоичный код 002;
A красный: RGB-код (255, 0, 0); двоичный код 012;
A синий: RGB-код (0, 0, 255); двоичный код 102;
A белый: RGB-код (255, 255, 255); двоичный код 112.
Таблица 3.5
|
0 |
0 |
0 |
255 |
0 |
0 |
0 |
0 |
255 |
255 |
255 |
255 |
|
цвет 0 = 002 |
цвет 1 = 012 |
цвет 2 = 102 |
цвет 3 = 112 |
||||||||
Поэтому палитра, которая обычно записывается в специальную служебную область в начале файла (эту область называют заголовком файла), представляет собой четыре трехбайтных блока, как показано в таблице 3.5. Код каждого пикселя занимает всего 2 бита.
Чтобы примерно оценить информационный объем рисунка с палитрой, включающей N цветов, нужно:
A определить размер палитры: 3 ∙ N байтов, или 24 ∙ N битов;
A определить глубину цвета (количество битов на пиксель), то есть найти наименьшее натуральное число k, такое, что 2k ≥ N;
A вычислить общее количество пикселей M, перемножив размеры рисунка;
A определить информационный объем рисунка (без учета палитры): М ∙ k битов.
В таблице 3.6 приведены данные по некоторым вариантам кодирования с палитрой.
Таблица 3.6
|
Количество цветов |
Размер палитры, байтов |
Глубина цвета, битов на пиксель |
|
2 |
6 |
1 |
|
4 |
12 |
2 |
|
16 |
48 |
4 |
|
256 |
768 |
8 |
Палитры с количеством цветов более 256 на практике не используются.
RGB-кодирование лучше всего описывает цвет, который излучается некоторым устройством, например, экраном монитора или ноутбука, как показано на рисунке 3.10, а и рисунке Б.3, а приложения Б. Когда же мы смотрим на изображение, напечатанное на бумаге, ситуация совершенно другая. Мы видим не прямые лучи источника, воспринимающиеся глазом, а отраженные от поверхности. «Белый свет» от какогото источника (солнца, лампочки), содержащий волны во всем видимом диапазоне, попадает на бумагу, на которой нанесена краска. Краска поглощает часть лучей (их энергия уходит на нагрев), а оставшиеся воспринимаются глазом, это и есть тот цвет, который мы видим.
Например, если краска поглощает красные лучи, остаются только синие и зеленые — мы видим голубой цвет, как показано на рисунке 3.10, б и рисунке Б.3, б приложения Б. В этом смысле красный и голубой цвета дополняют друг друга, так же как и пары зеленый — пурпурный и синий — желтый. Действительно, если из белого цвета (его RGB-код #FFFFFF) «вычесть» зеленый, то получится цвет #FF00FF (пурпурный), а если «вычесть» синий, то получится цвет #FFFF00 (желтый).
На трех дополнительных цветах — голубом, пурпурном и желтом — строится цветовая модель CMY (англ. Cyan — голубой, Magenta — пурпурный, Yellow — желтый), которая применяется для вывода изображения на печать. Значения С = М = Y = 0 говорят о том, что на белую бумагу не наносится никакая краска, поэтому все лучи отражаются, мы видим белый цвет. Если нанести на бумагу голубой цвет, красные лучи будут поглощаться, останутся только синие и зеленые. Если сверху нанести еще желтую краску, которая поглощает синие лучи, останется только зеленый цвет. Результат смешения базовых цветов цветовой модели CMYK представлен на рисунке 3.11 и рисунке Б.2 приложения Б.

Рисунок 3.10
При наложении голубой, пурпурной и желтой красок теоретически должен получиться черный цвет, все лучи поглощаются. Однако на практике все не так просто. Краски не идеальны, поэтому вместо черного цвета получается грязно-коричневый. Кроме того, при печати черных областей приходится «выливать» тройную порцию краски в одно место. Нужно также учитывать, что обычно на принтерах часто распечатывают черный текст, а цветные чернила значительно дороже черных.
Чтобы решить эту проблему, в набор красок добавляют черную краску, это так называемый ключевой цвет (англ. Kеу color), поэтому получившуюся модель обозначают СМYK. Изображение, которое печатает большинство
![]() принтеров, состоит из точек этих четырех цветов, которые расположены
в виде узора очень близко друг к другу. Это создает иллюзию того, что в рисунке
есть разные цвета.
принтеров, состоит из точек этих четырех цветов, которые расположены
в виде узора очень близко друг к другу. Это создает иллюзию того, что в рисунке
есть разные цвета.
Кроме цветовых моделей RGB и СМY (СМYK) существуют и другие модели. Наиболее интересная из них — модель НSВ [6] (англ. Нuе — тон, оттенок; Saturation — насыщенность, Brightness — яркость), которая ближе всего к естественному восприятию человека. Тон — это, например, си-
ний, зеленый, желтый. Насыщенность — это чи- Рисунок 3.11
стота тона, при уменьшении насыщенности до нуля получается серый цвет. Яркость определяет, насколько цвет светлый или темный. Любой цвет при снижении яркости до нуля превращается в черный.
Строго говоря, цвет, кодируемый в моделях RGB, СМYK и НSВ, зависит от устройства, на котором этот цвет будет изображаться. Для кодирования «абсолютного» цвета применяют модель Lab (англ. Lightness — светлота, а и b — параметры, определяющие тон и насыщенность цвета), которая является международным стандартом. Эта модель используется, например, для перевода цвета из модели RGB в модель CMYK и обратно.
Обычно изображения, предназначенные для печати, готовятся на компьютере (в режиме RGB), а потом переводятся в цветовую модель CMYK. При этом стоит задача — получить при печати такой же цвет, что и на мониторе. И вот тут возникают проблемы. Дело в том, что при выводе пикселей на экран монитор получает некоторые числа (RGB-коды), на основании которых нужно «выкрасить» пиксели тем или иным цветом. Отсюда следует важный вывод.
![]()
Цвет, который мы видим на мониторе, зависит от характеристик и настроек монитора.
![]()
Это значит, что, например, красный цвет (R = 255, G = В = 0) на разных мониторах будет разным. Наверняка вы видели этот эффект в магазине, где продают телевизоры и мониторы, — одна и та же картинка на каждом из них выглядит по-разному. Что же делать?
Во-первых, выполняется калибровка монитора — настройка яркости, контрастности, белого, черного и серого цветов. Во-вторых, профессионалы, работающие с цветными изображениями, используют цветовые профили мониторов, сканеров, принтеров и других устройств. В профилях хранится информация о том, каким реальным цветам соответствуют различные RGB-коды или СМYK-коды. Для создания профиля используют специальные приборы — калибраторы (колориметры), которые «измеряют» цвет с помощью трех датчиков, принимающих лучи в красном, зеленом и синем диапазонах. Современные форматы графических файлов (например, формат PSD программы Adobe Photoshop) вместе с кодами пикселей хранят и профиль монитора, на котором создавался рисунок.
Для того чтобы результат печати на принтере был максимально похож на изображение на мониторе, нужно (используя профиль монитора) определить «абсолютный» цвет (например, в модели Lab), который видел пользователь, а потом (используя профиль принтера) найти СМYK-код, который даст при печати наиболее близкий цвет.
Проблема состоит в том, что не все цвета RGB-модели могут быть напечатаны. В первую очередь это относится к ярким и насыщенным цветам. Например, ярко-красный цвет (R = 255, G = В = 0) нельзя напечатать, ближайший к нему цвет в модели CMYK (C = 0, М = Y = 255, K = 0) при обратном переводе в RGB может дать значения [7] в районе R = 237, G = 28, B = 26. Поэтому при преобразовании ярких цветов в модель CMYK (и при печати ярких рисунков) они становятся тусклее. Это обязательно должны учитывать профессиональные дизайнеры.
Итак, при растровом кодировании рисунок разбивается на пиксели (дискре тизируется). Для каждого пикселя определяется единый цвет, который чаще всего кодируется с помощью RGB-кода. На практике эти операции выполняет сканер (устройство для ввода изображений) или цифровой фотоаппарат.
Растровое кодирование имеет достоинства:
A универсальный метод (можно закодировать любое изображение);
A единственный метод для кодирования и обработки размытых изображений, не имеющих четких границ, например, фотографий;
и недостатки:
A при дискретизации всегда есть потеря информации;
A при изменении размеров изображения искажается цвет и форма объектов на рисунке, поскольку при увеличении размеров надо както восстановить недостающие пиксели, а при уменьшении — заменить несколько пикселей одним;
A размер файла не зависит от сложности изображения, а определяется только разрешением и глубиной цвета; как правило, растровые рисунки имеют большой объем.
Существует много разных форматов хранения растровых рисунков. В большинстве из них используют сжатие, то есть уменьшают размер файла с помощью специальных алгоритмов. В некоторых форматах применяют сжатие без потерь, при котором исходный рисунок можно в точности восстановить из сжатого состояния. Еще большую степень сжатия можно обеспечить, используя сжатие с потерями, при котором незначительная часть данных (почти не влияющая на восприятие рисунка человеком) теряется.
Чаще всего встречаются следующие форматы файлов:
A BMP (англ. bitmap — битовая карта; файлы с расширением bmp) — стандартный формат растровых изображений в операционной системе Windows; поддерживает кодирование с палитрой и в режиме истинного цвета;
A JPEG (англ. Joint Photographic Experts Group — объединенная группа фотографов-экспертов; файлы с расширением jpg или jpeg) — формат, разработанный специально для кодирования фотографий; поддерживает только режим истинного цвета; для уменьшения объема файла используется сильное сжатие, при котором изображение немного искажается, поэтому не рекомендуется использовать его для рисунков с четкими границами;
A GIF (англ. Graphics Interchange Format — формат для обмена изображениями; файлы с расширением gif) — формат, поддерживающий только кодирование с палитрой (от 2 до 256 цветов); в отличие от предыдущих форматов, части рисунка могут быть прозрачными, то есть на веб-странице через них будет «просвечивать» фон; в современном варианте формата GIF можно хранить анимированные изображения; используется сжатие без потерь, то есть при сжатии изображение не искажается;
A PNG (англ. Portable Network Graphics — переносимые сетевые изображения; файлы с расширением png) — формат, поддерживающий как режим истинного цвета, так и кодирование с палитрой; части изображения могут быть прозрачными и даже полупрозрачными (32-битное кодирование RGBA, где четвертый байт задает прозрачность); изображение сжимается без искажения; анимация не поддерживается.
Свойства рассмотренных форматов сведены в таблицу 3.7.
Таблица 3.7
|
Формат |
Истинный цвет |
С палитрой |
Прозрачность |
Анимация |
|
BMP |
Да |
Да |
— |
— |
|
JPEG |
Да |
— |
— |
— |
|
GIF |
— |
Да |
Да |
Да |
|
PNG |
Да |
Да |
Да |
— |
Вы уже знаете, что все виды информации хранятся в памяти компьютера в виде двоичных кодов, то есть цепочек из нулей и единиц. Получив такую цепочку, абсолютно невозможно сказать, что это — текст, рисунок, звук или видео. Например, код 110010002 может обозначать число 200, код буквы «И», одну из составляющих цвета пикселя в режиме истинного цвета, номер цвета в палитре для рисунка с палитрой 256 цветов, цвета 8 пикселей черно-белого рисунка и т. п. Как же компьютер разбирается в двоичных данных? В первую очередь нужно ориентироваться на расширение имени файла. Например, чаще всего файлы с расширением txt содержат текст, а файлы с расширениями bmp, gif, jpg, png — рисунки.
Однако расширение файла можно менять как угодно. Например, можно сделать так, что текстовый файл будет иметь расширение bmp, а рисунок в формате JPEG — расширение txt. Поэтому в начало всех файлов специальных форматов (кроме простого текста — txt) записывается заголовок, по которому можно «узнать» тип файла и его характеристики. Например, файлы в формате ВМР начинаются с символов «ВМ», а файлы в формате GIF — с символов «GIF». Кроме того, в заголовке указывается размер рисунка и его характеристики, например, количество цветов в палитре, способ сжатия и т. п. Используя эту информацию, программа «расшифровывает» основную часть файла и выводит данные на экран.
Для чертежей, схем, карт применяется другой способ кодирования, который позволяет не терять качество при изменении размеров изображения. Рисунок строится из простейших геометрических фигур (графических примитивов): линий, многоугольников, сглаженных кривых, окружностей, эллипсов. Такой рисунок называется векторным.
![]()
Векторный рисунок — это рисунок, построенный из простейших геометрических фигур, параметры которых (размеры, координаты вершин, углы наклона, цвет контура и заливки) хранятся в виде чисел.
![]()
При векторном кодировании для отрезка хранятся координаты его концов, для прямоугольников и ломаных — координаты вершин. Окружность и эллипс можно задать координатами прямоугольника, в который вписана фигура. Сложнее обстоит дело со сглаженными кривыми. На рисунке 3.12 изображена линия с опорными точками А, Б, В, Г и Д.
У каждой из этих точек есть «рычаги» (управляющие линии), перемещая концы этих рычагов, можно регулировать наклон касательной и кривизну всех участков кривой. Если оба рычага находятся на одной прямой, получается сглаженный узел (Б и Г ), если нет, то угловой узел (В). Таким образом, форма этой кривой полностью задается координатами опорных точек и координатами рычагов. Кривые, заданные таким образом, называют кривыми Безье в честь их изобретателя — французского инженера Пьера Безье.
Векторный рисунок можно «разобрать» на части, растащив мышью его элементы, а потом снова собрать полное изображение, как показано на рисунке 3.13.
Рисунок 3.13
Сделать что-то подобное с растровым рисунком не удастся.
Векторный рисунок можно рассматривать как программу, в соответствии с которой строится изображение на конкретном устройстве вывода, с учетом особенностей этого устройства (например, разрешения экрана).
Векторный способ кодирования рисунков обладает значительными преимуществами по сравнению с растровым:
A при кодировании нет потери информации, если изображение может быть полностью разложено на простейшие геометрические фигуры (например, чертеж, схема, карта, диаграмма);
A объем файлов напрямую зависит от сложности рисунка — чем меньше элементов, тем меньше места занимает файл; как правило, векторные рисунки значительно меньше по объему, чем растровые;
A при изменении размера векторного рисунка не происходит никакого искажения формы элементов, при увеличении наклонных линий не появляются «ступеньки», как при растровом кодировании. Разницу в качестве увеличенных векторного и растрового изображений можно увидеть на рисунке 3.14.
Самый главный недостаток этого метода — он практически непригоден для кодирования изображений, в которых объекты не имеют четких границ, например, для фотографий.
Среди форматов векторных рисунков отметим следующие:
A WMF (англ. Windows Metafi le — метафайл Windows; файлы с расширением wmf и emf) — стандартный формат векторных рисунков в операционной системе Windows;
A CDR (файлы с расширением cdr) — формат векторных рисунков программы CorelDRAW;
A AI (файлы с расширением ai) — формат векторных рисунков программы Adobe Illustrator;
A SVG (англ. Scalable Vector Graphics — масштабируемые векторные изображения; файлы с расширением svg) — векторная графика для веб-страниц в интернете.
1. Какие два принципа кодирования рисунков используются в компьютерной технике?
2. Почему не удается придумать единый метод кодирования рисунков, пригодный во всех ситуациях?
3. В чем состоит идея растрового кодирования? Что такое растр?
4. Что такое пиксель?
5. Что такое дискретизация? Почему она необходима?
6. Что теряется при дискретизации? Почему?
7. Как уменьшить потерю информации при дискретизации? Что при этом ухудшается?
8. Что такое разрешение? В каких единицах оно измеряется?
9. Что такое режим истинного цвета (True Color)?
10. Что такое кодирование с палитрой? В чем его принципиальное отличие от режима истинного цвета?
11. Какие устройства используются для ввода изображений в компьютер?
12. В чем состоят достоинства и недостатки растрового кодирования?
13. В чем особенность основных современных форматов кодирования растровых рисунков?
14. Какие форматы поддерживают рисунки с прозрачными и полупрозрачными областями?
15. В каких форматах целесообразно сохранять фотографии? Рисунки с четкими границами?
16. Как можно уменьшить объем файла растрового формата, в котором хранится рисунок? Чем при этом придется пожертвовать?
17. Как компьютер определяет, что находится в файле — текст, рисунок, звук или видео?
18. Что такое кривые Безье?
19. Почему при увеличении растрового рисунка появляются «ступеньки»?
20. Что такое векторное кодирование? В чем его отличие от растрового? Каковы преимущества и недостатки растрового и векторного кодирования?
21. В каких задачах используют векторное кодирование?
22. Какие форматы векторных рисунков вы знаете? Приведите примеры.
1. Постройте двоичные коды для изображений, представленных на рисунке 3.15, и запишите их в шестнадцатеричной системе счисления.

Какие сложности у вас возникли? Как их можно преодолеть?
2. Постройте черно-белый рисунок шириной 8 пикселей, закодированный шестнадцатеричной последовательностью 2466FF662416.
3. Постройте черно-белый рисунок шириной 5 пикселей, закодированный шестнадцатеричной последовательностью 3А53F8816.
4. Рисунок размером 10 × 15 см кодируется с разрешением 300 ppi. Оцените количество пикселей в этом рисунке.
5. Постройте шестнадцатеричный код для цветов, имеющих RGB-коды
(100, 200, 200), (30, 50, 200), (60, 180, 20), (220, 150, 30).
6. Как бы вы назвали цвета, заданные на веб-странице в виде кодов #СССССС, #FFCCCC, #ССССFF, #000066, #FF66FF, #CCFFFF, #992299, #999900, #99FF99? Найдите десятичные значения составляющих RGB-кода.
7. Что такое глубина цвета? Как связаны глубина цвета и объем файла?
8. Какова глубина цвета, если в рисунке используется 65 536 цветов? 256 цветов? 16 цветов?
9. Для желтого цвета найдите красную, зеленую и синюю составляющие при 12-битном кодировании.
10. Сколько места в файле занимает палитра, в которой используются 64 цвета? 128 цветов?
11. Сколько байтов будет занимать код рисунка размером 40 × 50 пикселей в режиме истинного цвета? При кодировании с палитрой 256 цветов? При кодировании с палитрой 16 цветов? В черно-белом варианте (два цвета)?
12. Сколько байтов будет занимать код рисунка размером 80 × 100 пикселей в кодировании с глубиной цвета 12 битов на пиксель?
13. Для хранения растрового изображения размером 32 × 32 пикселя отвели 512 байтов памяти. Каково максимально возможное число цветов в палитре изображения?
14. Для хранения растрового изображения размером 128 × 128 пикселей отвели 4 Кбайта памяти. Каково максимально возможное число цветов в палитре изображения?
15. В процессе преобразования растрового графического файла количество цветов уменьшилось с 1024 до 32. Во сколько раз уменьшился информационный объем файла?
16. В процессе преобразования растрового графического файла количество цветов уменьшилось с 512 до 8. Во сколько раз уменьшился информационный объем файла?
17. Разрешение экрана монитора — 1024 × 768 точек, глубина цвета — 16 битов. Какой объем памяти требуется для хранения полноэкранного изображения в данном графическом режиме?
18. После преобразования растрового 256-цветного графического файла в черно-белый формат (2 цвета) его размер уменьшился на 70 байтов. Каков был размер исходного файла (без учета заголовка)?
19. Сколько памяти нужно для хранения 64-цветного растрового графического изображения размером 32 × 128 точек?
20. Какова ширина (в пикселях) прямоугольного 64-цветного растрового изображения, информационный объем которого 1,5 Мбайт, если его высота вдвое меньше ширины?
21. Какова ширина (в пикселях) прямоугольного 16-цветного растрового изображения, информационный объем которого 1 Мбайт, если его высота вдвое больше ширины?
Звук — это колебания среды (воздуха, воды), которые воспринимает человеческое ухо. На рисунке 3.16 показано, как с помощью микрофона звук преобразуется в аналоговый электрический сигнал. В любой момент времени аналоговый сигнал на выходе микрофона (ток или напряжение) может принимать любое значение в некотором интервале.

Как вы знаете, современные компьютеры обрабатывают только дискретные сигналы (двоичные коды). Поэтому для работы со звуком необходима звуковая карта [8] — специальное устройство, которое преобразует аналоговый сигнал, полученный с микрофона, в двоичный код, то есть в цепочку нулей и единиц. Эта процедура называется оцифровкой.
![]()
Оцифровка — это преобразование аналогового сигнала в цифровой код.
![]()
Ситуация напоминает ту, с которой мы столкнулись при кодировании рисунка: любая линия состоит из бесконечного числа точек, поэтому, чтобы закодировать «по точкам», нужна бесконечная память. Здесь тоже придется использовать дискретизацию — представить аналоговый сигнал в виде набора чисел, то есть записать в память только значения сигнала в отдельных точках, взятых с некоторым шагом T по времени, как показано на рисунке 3.17.
Число T называется интервалом дискретизации, а обратная ему величина 1/ T — частотой дискретизации. Частота дискретизации обозначается буквой f и измеряется в герцах (Гц) и килогерцах (кГц). Один герц — это один отсчет в секунду, а 1 кГц — 1000 отсчетов в секунду.
Чем больше частота дискретизации, тем точнее мы записываем сигнал, тем меньше информации теряем. Однако при этом возрастает количество отсчетов, то есть информационный объем закодированного звука.
Для кодирования звука в компьютерах чаще всего используются частоты дискретизации 8 кГц (минимальное качество, достаточное для распознавания речи), 11 кГц, 22 кГц, 44,1 кГц (звуковые компакт-диски), 48 кГц (фильмы в формате DVD), а также 96 кГц и 192 кГц (высококачественный звук в формате DVD-audio).
Выбранная частота влияет на качество цифрового звука. Дело в том, что наушники и звуковые колонки — это аналоговые (не цифровые) устройства, и при проигрывании звука через звуковую карту компьютеру нужно как-то восстановить исходный аналоговый сигнал и передать его на наушники или звуковые колонки. В памяти есть только значения, снятые с интервалом T, остальная информация была потеряна при кодировании. В простейшем случае по ним можно восстановить ступенчатый сигнал, который будет существенно отличаться от исходного (до кодирования). Диаграмма оцифрованного сигнала представлена на рисунке 3.18. В современных звуковых картах для повышения качества звука ступенчатый сигнал сглаживается с помощью специальных фильтров.
Для повышения качества звука, то есть для большего соответствия между сигналом, принятым микрофоном, и сигналом, выведенным из компьютера на колонки, нужно увеличивать частоту дискретизации, однако при этом, как вы уже знаете, увеличивается и объем файла. Как же выбрать оптимальную частоту при кодировании? Ответ на этот вопрос во многом зависит от свойств звука, который нужно закодировать.
Согласно теореме Котельникова, непрерывный сигнал с ограниченным спектром частот может быть полностью восстановлен по его дискретным отсчетам, взятым через интервалы времени Tд ≤ 1/ 2Fмакс , если соблюдается условие (3.3):
Fд ≥ 2Fмакс , (3.3)
где Fд — частота дискретизации;
Fмакс — максимальная частота спектра сигнала.
К примеру, при передаче сигналов, занимающих диапазон частот 0,3–3,4 кГц, частота дискретизации не должна быть менее 6,8 кГц, то есть в одну секунду должно передаваться 6,8 тысяч отсчетов. Качество передачи речи при этом оказывается вполне удовлетворительным.
Теорема Котельникова указывает условия, при которых непрерывный сигнал может быть точно восстановлен по соответствующему ему сигналу с дискретным временем.
В реальных сигналах содержатся колебания с очень высокими частотами, так что частота дискретизации, полученная с помощью теоремы Котельникова, будет также высока и объем файла — недопустимо велик. Однако средний человек слышит только звуки с частотами от 16 Гц до 20 кГц, поэтому все частоты выше 20 кГц можно «потерять» практически без ухудшения качества звука (человек не почувствует разницу). Удвоив эту частоту (по теореме Котельникова), получаем оптимальную частоту дискретизации около 40 кГц, которая обеспечивает наилучшее качество, различимое на слух. Поэтому при высококачественном цифровом кодировании звука на компакт-дисках и в видеофильмах чаще всего используют частоты 44,1 и 48 кГц. Более низкие частоты применяют тогда, когда важно всячески уменьшать объем звуковых данных (например, для трансляции радиопередач через интернет), даже ценой ухудшения качества.
Кроме того, что при кодировании звука выполняется дискретизация с потерей информации, нужно учитывать, что на хранение одного отсчета в памяти отводится ограниченное место. При этом вносятся дополнительные ошибки.
Представим себе, что на один отсчет выделяется 3 бита. При этом код каждого отсчета — это целое число от 0 до 7. Данный график представлен на рисунке 3.19. Весь диапазон возможных значений сигнала, от 0 до максимально допустимого, делится на 8 полос, каждой из которых присваивается номер (код). Все отсчеты, попавшие в одну полосу, получают одинаковый код.
Преобразование измеренного значения сигнала в целое число называется дискретизацией по уровню или квантованием. Эту операцию выполняет аналого-цифровой преобразователь (АЦП) — специальный блок звуковой карты.
![]()
Разрядность кодирования — это число битов, используемое для хранения одного отсчета.
![]()
Недорогие звуковые карты имеют разрядность 16–18 битов, большинство современных — 24 бита, что позволяет использовать 224 = 16 777 216 различных уровней.
Объем данных, полученный после оцифровки звука, зависит от разрядности кодирования и частоты дискретизации. Например, если используется 16-разрядное кодирование с частотой 44 кГц, то за одну секунду выполняется 44 000 измерений сигнала, и каждое из измеренных значений занимает 16 битов (2 байта). Поэтому за 1 секунду накапливается 44 000 × × 2 = 88 000 байтов данных, а за 1 минуту: 88 000 ∙ 60 = 5 280 000 байтов ≈ ≈ 5 Мбайт.
Если записывается стереозвук (левый и правый каналы), это число нужно удвоить.
С помощью оцифровки можно закодировать любой звук, который принимает микрофон. В частности, это единственный способ кодирования человеческого голоса и различных природных звуков (шума прибоя, шелеста листвы и т. п.).
Однако у этого метода есть и недостатки:
A при оцифровке звука всегда есть потеря информации (из-за дискретизации);
A звуковые файлы имеют, как правило, большой размер, поэтому в большинстве современных форматов используется сжатие.
Среди форматов оцифрованных звуковых файлов наиболее известны:
A WAV (англ. Waveform Audio File Format; файлы с расширением wav) — стандартный формат звуковых файлов в операционной системе Windows; сжатие данных возможно, но используется редко;
A MP3 (файлы с расширением mp3) — самый популярный формат звуковых файлов, использующий сжатие с потерями: для значительного уменьшения объема файла снижается качество кодирования для тех частот, которые практически неразличимы для человеческого слуха;
A WMA (англ. Windows Media Audio; файлы с расширением wma) — формат звуковых файлов, разработанный фирмой Microsoft; чаще всего используется сжатие для уменьшения объема файла;
A Ogg Vorbis (файлы с расширением ogg) — свободный (не требующий коммерческих лицензий) формат сжатия звука с потерями.
Все эти форматы являются потоковыми, то есть можно начинать прослушивание до того момента, как весь файл будет получен (например, из интернета).
Существует еще один, принципиально иной способ кодирования звука, который можно применить только для кодирования инструментальных мелодий. Он основан на стандарте MIDI (англ. Musical Instrument Digital Interfасе — цифровой интерфейс музыкальных инструментов). В отличие от оцифрованного звука в таком формате хранятся последовательность нот, коды инструментов (можно использовать 128 мелодических и 47 ударных инструментов), громкость, тембр, время затухания каждой ноты и т. д. Фактически это программа, предназначенная для проигрывания звуковой картой, в памяти которой хранятся образцы звуков реальных инструментов (волновые таблицы, англ. wave tables).
Современные звуковые карты поддерживают многоканальный звук, то есть в звуковом файле может храниться несколько «дорожек», которые проигрываются одновременно. Таким образом, получается полифония — многоголосие, возможность проигрывать одновременно несколько нот. Количество голосов для современных звуковых карт может достигать 1024.
Звук, закодированный с помощью стандарта МIDI, хранится в файлах с расширением mid. Существуют специальные клавиатуры, которые позволяют вводить звук и сразу сохранять его в формате mid.
Для проигрывания MIDI-файла используют синтезаторы — электронные устройства, имитирующие звук реальных инструментов. Простейшим синтезатором является звуковая карта компьютера.
Главные достоинства инструментального кодирования:
A кодирование мелодии (нотной записи) происходит без потери информации;
A файл имеет значительно меньший объем по сравнению с оцифрованным звуком той же длительности.
Однако произвольный звук (например, человеческий голос) в таком формате закодировать невозможно. Кроме того, производители сами выбирают образцы звуков (так называемые сэмплы, от англ. samples — образцы), которые записываются в память звуковой карты (нет единого стандарта). Поэтому звучание MIDI-файла может немного отличаться на разной аппаратуре.
Для того чтобы сохранить видео в памяти компьютера, нужно закодировать звук и изменяющееся изображение, причем требуется обеспечить их синхронность (одновременность). Для кодирования звука чаще всего используют оцифровку с частотой 48 кГц. Изображение состоит из отдельных растровых рисунков, которые меняются с частотой не менее 25 кадров в секунду, так что глаз человека воспринимает смену кадров как непрерывное движение. Это значит, что для каждой секунды видео нужно хранить в памяти 25 изображений.
Если используется размер 768 × 576 точек (стандарты PAL/SECAM) и глубина цвета 24 бита на пиксель, то закодированная 1 секунда видео (без звука) будет занимать примерно 32 Мбайт, а 1 минута — около 1,85 Гбайт. Это недопустимо много, поэтому в большинстве форматов видео изображений используется сжатие с потерями. Это значит, что некоторые незначительные детали теряются, но «обычный» человек (непрофессионал) не почувствует существенного ухудшения качества. Основная идея такого сжатия заключается в том, что за короткое время изображение изменяется очень мало, поэтому можно запомнить базовый кадр, а затем сохранять только изменения. Как только изображение существенно изменится, выбирается новый базовый кадр.
В последние годы часто используются форматы видео высокой четкости (англ. НD — High Defi nition) — 1280 × 720 точек и 1920 × 1080 точек, предназначенные для просмотра на широкоформатных экранах с соотношением сторон 16 : 9.
Наиболее известны следующие видеоформаты:
A AVI (англ. Audio Video Interleave — чередующиеся звук и видео; файлы с расширением avi) — формат видеофайлов, разработанных фирмой Microsoft для системы Windows; может использовать разные алгоритмы сжатия;
A WMV (англ. Windows Media Video; файлы с расширением wmv) — система кодирования видео, разработанная фирмой Microsoft; может использовать разные алгоритмы сжатия;
A MPEG (файлы с расширением mpg, mpeg) — формат кодирования видеоинформации, использующий один из лучших алгоритмов сжатия, который разработала экспертная группа по вопросам движущегося изображения (англ. Motion Picture Experts Group);
A MP4 (файлы с расширением mp4) — формат видеофайлов, позволяющий хранить несколько потоков видео высокой четкости, а также субтитры;
A MOV (англ. Quick Time Моvie; файлы с расширением mov) — формат видеофайлов, разработанный фирмой Apple;
A WebM — открытый (не требующий оплаты лицензии) видеоформат, который поддерживается в современных браузерах без установки дополнительных модулей.
1. Что такое аналоговый сигнал?
2. Какие вы знаете аналоговые приборы?
3. Почему аналоговые компьютеры были вытеснены цифровыми?
4. Что такое оцифровка? Почему при оцифровке есть потеря информации?
5. Что такое интервал дискретизации и частота дискретизации?
6. Как связаны частота дискретизации с потерей информации и объемом файла?
7. Какие частоты дискретизации сейчас используются?
8. От чего зависит выбор частоты дискретизации?
9. Почему частоты дискретизации более 48 кГц применяются очень редко?
10. Как происходит вывод закодированного звукового сигнала на колонки или наушники?
11. Что такое дискретизация по уровню?
12. Какое устройство выполняет дискретизацию при записи звука?
13. Что такое разрядность кодирования звука? На что она влияет?
14. В чем достоинства и недостатки оцифровки?
15. Какие форматы файлов для хранения оцифрованного звука вы знаете?
16. Что такое потоковый звук?
17. Что такое инструментальное кодирование?
18. Что такое волновая таблица?
19. Что такое многоканальный звук?
20. Что такое синтезатор?
21. В чем достоинства и недостатки инструментального кодирования звука?
22. В файлах с каким расширением хранится звук, закодированный с помощью стандарта MIDI?
23. Почему MIDI-файлы могут звучать по-разному на разной аппаратуре?
24. Что такое синхронность?
25. Какая частота дискретизации звука чаще всего используется при кодировании видеофильмов?
26. Почему при кодировании видео используется частота не менее 25 кадров в секунду?
27. Почему компьютерные фильмы чаще всего хранятся в сжатом виде?
28. Что означает сжатие с потерями? В чем состоит его основная идея при кодировании видео?
29. Какие форматы видео вы знаете?
30. Составьте сравнительную характеристику известных вам звуковых форматов.
1. Заполните пустые ячейки таблицы 3.8, вычислив объемы звуковых файлов (без сжатия).
Таблица 3.8
|
Частота дискретизации, кГц |
8 |
8 |
11 |
11 |
22 |
22 |
44,1 |
44,1 |
48 |
48 |
|
Глубина кодирования, битов |
8 |
8 |
16 |
16 |
16 |
8 |
24 |
8 |
8 |
24 |
|
Моно/стерео |
моно |
стерео |
моно |
стерео |
моно |
стерео |
моно |
стерео |
стерео |
стерео |
|
Время звучания, с |
16 |
8 |
64 |
32 |
32 |
32 |
256 |
128 |
4 |
4 |
|
Объем файла, Кбайт |
|
|
|
|
|
|
|
|
|
|
2. Заполните пустые ячейки таблицы 3.9, вычислив время звучания записи (объемы файлов приведены без учета сжатия).
Таблица 3.9
|
Частота дискретизации, кГц |
8 |
8 |
11 |
11 |
22 |
22 |
44,1 |
44,1 |
48 |
48 |
|
Глубина кодирования, битов |
16 |
24 |
8 |
8 |
8 |
24 |
16 |
24 |
16 |
16 |
|
Моно/стерео |
моно |
стерео |
моно |
стерео |
моно |
стерео |
моно |
стерео |
моно |
стерео |
|
Объем файла, Кбайт |
125 |
375 |
1375 |
1375 |
6875 |
4125 |
11025 |
33075 |
375 |
1875 |
|
Время звучания, с |
|
|
|
|
|
|
|
|
|
|
3. Заполните пустые ячейки таблицы 3.10, вычислив глубину кодирования звука (объемы файлов приведены без учета сжатия).
Таблица 3.10
|
Частота дискретизации, кГц |
8 |
8 |
11 |
11 |
22 |
22 |
44,1 |
44,1 |
48 |
48 |
|
Моно/стерео |
моно |
стерео |
моно |
стерео |
моно |
стерео |
моно |
стерео |
моно |
моно |
|
Время звучания, с |
16 |
4 |
238 |
64 |
320 |
16 |
256 |
64 |
40 |
80 |
|
Объем файла, Кбайт |
375 |
125 |
4125 |
4125 |
20625 |
1375 |
11025 |
11025 |
1875 |
11250 |
|
Глубина кодирования, битов |
|
|
|
|
|
|
|
|
|
|
4. Заполните пустые ячейки таблицы 3.11, вычислив частоту дискретизации звука (объемы файлов приведены без учета сжатия).
Таблица 3.11
|
Глубина кодирования, битов |
16 |
8 |
16 |
24 |
16 |
16 |
8 |
24 |
16 |
24 |
|
Моно/стерео |
моно |
стерео |
стерео |
стерео |
стерео |
моно |
моно |
стерео |
моно |
стерео |
|
Время звучания, с |
64 |
4 |
64 |
64 |
16 |
128 |
320 |
8 |
4 |
4 |
|
Объем файла, Кбайт |
1375 |
375 |
11025 |
4125 |
1375 |
11025 |
6875 |
375 |
375 |
1125 |
|
Частота дискретизации, кГц |
|
|
|
|
|
|
|
|
|
|
5. Кадры видеозаписи закодированы в режиме истинного цвета (24 бита на пиксель) и сменяются с частотой 25 кадров в секунду, запись содержит стереофонический звук. Остальные параметры для разных вариантов заданы в таблице 3.12. Оцените объем 1 минуты видеозаписи в мегабайтах (с точностью до десятых). Сколько минут такой записи поместится на стандартный CD-диск объемом 700 Мбайт?
Таблица 3.12
|
Ширина кадра, пиксели |
320 |
320 |
640 |
640 |
720 |
720 |
720 |
720 |
1920 |
1920 |
|
Высота кадра, пиксели |
240 |
240 |
480 |
480 |
480 |
480 |
576 |
576 |
1080 |
1080 |
|
Частота дискретизации, кГц |
11 |
48 |
48 |
48 |
22 |
48 |
22 |
48 |
48 |
48 |
|
Глубина кодирования звука, битов |
24 |
16 |
24 |
16 |
16 |
16 |
24 |
24 |
16 |
24 |
|
Степень сжатия |
10 |
8 |
6 |
4 |
10 |
12 |
8 |
6 |
8 |
10 |
|
Объем файла, Мбайт |
|
|
|
|
|
|
|
|
|
|
|
Поместится на CD-диск, минут |
|
|
|
|
|
|
|
|
|
|
![]()
Скорость передачи данных — это количество битов (байтов, Кбайт и т. д.), которое передается по каналу связи за единицу времени (например, за 1 секунду).
![]()
Пропускная способность любого реального канала связи ограничена. Это значит, что есть некоторая наибольшая возможная скорость передачи данных, которую принципиально невозможно превысить.
Основная единица измерения скорости — биты в секунду (бит/с, англ. bps — bits per second). Для характеристики быстродействующих каналов применяют килобиты в секунду (Кбит/с) и мегабиты в секунду (Мбит/с), иногда используют байты в секунду (байт/с) и килобайты в секунду (Кбайт/с).
Информационный объем I данных, переданных по каналу за определенное время, t, вычисляется по формуле (4.1):
I = v ∙ t, (4.1)
где v — скорость передачи данных.
Например, если скорость передачи данных равна 512 000 бит/с, за
1 минуту можно передать файл объемом
512 000 бит/с ∙ 60 с = 30 720 000 битов = 3 840 000 байтов = = 3075 Кбайт.
В реальных каналах связи всегда присутствуют помехи, искажающие сигнал. В некоторых случаях ошибки допустимы, например, при прослушивании радиопередачи через интернет небольшое искажение звука не мешает понимать речь. Однако чаще всего требуется обеспечить точную передачу данных. Для этого в первую очередь нужно определить факт возникновения ошибки и, если это произошло, передать блок данных еще раз.
Представьте себе, что получена цепочка нулей и единиц 1010101110, причем все биты независимы. В этом случае нет абсолютно никакой возможности определить, верно ли передана последовательность. Поэтому необходимо вводить избыточность в передаваемое сообщение (включать в него «лишние» биты) только для того, чтобы обнаружить ошибку.
Простейший вариант — добавить 1 бит в конце блока данных, который будет равен 1, если в основном сообщении нечетное число единиц, и равен 0 для сообщения с четным числом единиц. Этот дополнительный бит называется битом четности. Бит четности используется при передаче данных в сетях, проверка четности часто реализуется аппаратно (с помощью электроники).
Например, пусть требуется передать два бита данных. Возможны всего 4 разных сообщения: 00, 01, 10 и 11. Первое и четвертое из них содержат четное число единиц (0 и 2), значит, бит четности для них равен 0. Во втором и третьем сообщениях нечетное число единиц (1), поэтому бит четности будет равен 1. Таким образом, сообщения с добавленным битом четности будут выглядеть так:
000, 011, 101, 110.
Первые два бита несут полезную информацию, а третий (подчеркнутый) — вспомогательный, он служит только для обнаружения ошибки. Обратим внимание, что каждое из этих 3-битных сообщений содержит четное число единиц.
Подумаем, сколько ошибок может обнаружить такой метод. Если при передаче неверно передан только один из битов, количество единиц в сообщении стало нечетным, это и служит признаком ошибки при передаче. Однако исправить ошибку нельзя, потому что непонятно, в каком именно разряде она случилась.
Если же изменилось два бита, четность не меняется, и такая ошибка не обнаруживается. В длинной цепочке применение бита четности позволяет обнаруживать нечетное число ошибок (1, 3, 5, ...), а ошибки в четном количестве разрядов остаются незамеченными.
Контроль с помощью бита четности применяется для небольших блоков данных (чаще всего — для каждого отдельного байта) и хорошо работает тогда, когда отдельные ошибки при передаче независимы одна от другой и встречаются редко.
Для обнаружения искажений в передаче файлов, когда может сразу возникнуть множество ошибок, используют другой метод — вычисляют контрольную сумму с помощью какой-нибудь хэш-функции. Чаще всего для этой цели применяют алгоритмы CRC (англ. Cyclic Redundancy Code — циклический избыточный код), а также криптографические хэшфункции MD5, SHA-1 и другие. Если контрольная сумма блока данных, вычисленная приемником, не совпадает с контрольной суммой, записанной передающей стороной, то произошла ошибка.
Значительно сложнее исправить ошибку сразу (без повторной передачи), однако в некоторых случаях и эту задачу удается решить. Для этого требуется настолько увеличить избыточность кода (добавить «лишние» биты), что небольшое число ошибок все равно позволяет достаточно уверенно распознать переданное сообщение. Например, несмотря на помехи в телефонной линии, обычно мы легко понимаем собеседника. Это значит, что речь обладает достаточно большой избыточностью, и это позволяет исправлять ошибки «на ходу».
Пусть, например, нужно передать один бит, 0 или 1. Утроим его, добавив еще два бита, совпадающих с первым. Таким образом, получаются два «правильных» сообщения:
000 и 111.
Теперь посмотрим, что получится, если при передаче одного из битов сообщения 000 произойдет ошибка и приемник получит искаженное сообщение 001. Заметим, что оно отличается одним битом от 000 и двумя битами от второго возможного варианта — 111. Значит, скорее всего, произошла ошибка в последнем бите и сообщение нужно исправить на 000. Если приемник получил 101, можно точно сказать, что произошли ошибка, однако попытка исправить ее приведет к неверному варианту, так как ближайшая «правильная» последовательность — это 111. Таким образом, такой код обнаруживает одну или две ошибки. Кроме того, он позволяет исправить одну ошибку, то есть является помехоустойчивым.
![]()
Помехоустойчивый код — это код, который позволяет исправлять ошибки, если их количество не превышает некоторого уровня.
![]()
Выше мы фактически применили понятие «расстояния» между двумя кодами. В теории передачи информации эта величина называется расстоянием Хэмминга в честь американского математика Р. Хэмминга.
Например, расстояние d между кодами 001 и 100 равно d (001, 100) = 2, потому что они различаются в двух битах (эти биты подчеркнуты). В приведенном выше примере расстояние между «правильными» последовательностями (словами) равно d (000, 111) = 3. Такой код позволяет обнаружить одну или две ошибки и исправить одну ошибку.
В общем случае, если минимальное расстояние между «правильными» словами равно d, можно обнаружить от 1 до d − 1 ошибок, потому что при этом полученный код будет отличаться от всех допустимых вариантов. Для исправления r ошибок необходимо, чтобы выполнялось условие (4.2):
d ≥ 2r + 1. (4.2)
Это значит, что слово, в котором сделано r ошибок, должно быть ближе к исходному слову, чем к любому другому.
Рассмотрим более сложный пример. Пусть нужно передавать три произвольных бита, обеспечив обнаружение двух любых ошибок и исправление одной ошибки. В этом случае можно использовать, например, такой код с тремя контрольными битами (они подчеркнуты):
000 000 100 101
001 111 101 010
010 011 110 110
011 100 111 001
Расстояние Хэмминга между любыми двумя словами в таблице не менее 3, поэтому код обнаруживает две ошибки и позволяет исправить одну.
Предположим, что было получено кодовое слово 011011. Определив расстояние Хэмминга до каждого из «правильных» слов, находим единственное слово 010011, расстояние до которого равно 1 (расстояния до остальных слов больше). Значит, скорее всего, это слово и было передано, но исказилось из-за помех.
![]()
Расстояние Хэмминга — это количество позиций, в которых различаются два закодированных сообщения одинаковойдлины.
![]()
На практике используют несколько более сложные коды, которые называются кодами Хэмминга. В них информационные и контрольные биты перемешаны, и за счет этого можно сразу, без перебора, определить номер бита, в котором произошла ошибка. Наиболее известен 7-битный код, в котором 4 бита — это данные, а 3 бита — контрольные. В нем минимальное расстояние между словами равно 3, поэтому он позволяет обнаружить две ошибки и исправить одну.
1. В каких единицах измеряют скорость передачи данных?
2. Какой код называют помехоустойчивым?
3. Как определить количество дополнительных разрядов?
4. Почему для любого канала связи скорость передачи данных ограничена?
5. Как вычисляется информационный объем данных, который можно передать за некоторое время?
6. В каких случаях при передаче данных допустимы незначительные ошибки?
7. Что такое избыточность сообщения? Для чего ее можно использовать? Приведите примеры.
8. Как помехи влияют на передачу данных?
9. Что такое бит четности? В каких случаях с помощью бита четности можно обнаружить ошибку, а в каких — нельзя?
10. Можно ли исправить ошибку, обнаружив неверное значение бита четности?
11. Для чего используется метод вычисления контрольной суммы?
12. Каково должно быть расстояние Хэмминга между двумя кодами, чтобы можно было исправить две ошибки?
13. Как исправляется ошибка при использовании помехоустойчивого кода?
14. Сколько ошибок обнаруживает 7-битный код Хэмминга, описанный в конце параграфа, и сколько ошибок он позволяет исправить?
1. Через соединение со скоростью 128 000 бит/с передают файл размером 625 Кбайт. Определите время передачи файла в секундах.
2. Передача файла через соединение со скоростью 512 000 бит/с заняла 1 минуту. Определите размер файла в килобайтах.
3. Скорость передачи данных равна 64 000 бит/с. Сколько времени займет передача файла объемом 375 Кбайт по этому каналу?
4. У Васи есть доступ к интернету по высокоскоростному одностороннему радиоканалу, обеспечивающему скорость получения им информации 256 000 бит/с. У Пети нет скоростного доступа к интернету, но есть возможность получать информацию от Васи по низкоскоростному телефонному каналу со средней скоростью 32 768 бит/с. Петя договорился с Васей, что тот будет скачивать для него данные объемом 5 Мбайт по высокоскоростному каналу и ретранслировать их Пете по низкоскоростному каналу. Компьютер Васи может начать ретрансляцию данных не раньше, чем им будут получены первые 375 Кбайт этих данных. Каков минимально возможный промежуток времени (в секундах) с момента начала скачивания Васей данных до полного их получения Петей?
5. Определите максимальный размер файла в килобайтах, который может быть передан за 8 минут со скоростью 32 000 бит/с.
6. Сколько секунд потребуется, чтобы передать 400 страниц текста, состоящего из 30 строк по 60 символов каждая по линии со скоростью 128 000 бит/с, при условии, что каждый символ кодируется 1 байтом?
7. Передача текстового файла по каналу связи со скоростью 128 000 бит/с заняла 1,5 мин. Определите, сколько страниц содержал переданный текст, если известно, что он был представлен в 16-битной кодировке UNICODE, а на одной странице — 400 символов.
8. Передача текстового файла через соединение со скоростью 64 000 бит/с заняла 10 с. Определите, сколько страниц содержал переданный текст, если известно, что он был представлен в 16-битной кодировке UNICODE и на каждой странице — 400 символов.
9. Сколько секунд потребуется, чтобы передать цветное растровое изображение размером 1280 × 800 пикселей по линии со скоростью 256 000 бит/с при условии, что цвет каждого пикселя кодируется 24 битами?
10. Сколько секунд потребуется, чтобы передать цветное растровое изображение размером 1000 × 800 пикселей по линии со скоростью 128 000 бит/с при условии, что цвет каждого пикселя кодируется 24 битами?
11. Через некоторый канал связи за 2 минуты был передан файл, размер которого — 3750 Кбайт. Определите минимальную скорость, при которой такая передача возможна.
12. Модем, передающий информацию со скоростью 256 000 бит/с, передал файл с несжатой стереофонической музыкой за 2 минуты 45 секунд. Найдите разрядность кодирования этой музыки, если известно, что ее продолжительность составила 1 минуту и оцифровка производилась с частотой 22 000 Гц.
13. Найдите расстояние между кодами 11101 и 10110, YUIX и YAIY.
14. Найдите все пятизначные двоичные коды, расстояние от которых до кода 11101 равно 1. Сколько всего может быть таких слов для n-битного кода?
15. Для передачи восьмеричных чисел используется помехоустойчивый 6-битный код, приведенный в тексте параграфа. Раскодируйте сообщение, исправив ошибки: 001 101 011 011 011 101 110 101 101 011.
Для того чтобы сэкономить место на внешних носителях (жестких дисках, флэш-дисках) и ускорить передачу данных по компьютерным сетям, нужно сжать данные — уменьшить информационный объем, сократить длину двоичного кода. Это можно сделать, устранив избыточность исполь зованного кода.
Например, пусть текстовый файл объемом 10 Кбайт содержит всего четыре различных символа: латинские буквы «A», «B», «C» и пробел. Вы знаете, что для кодирования одного из четырех возможных вариантов достаточно двух битов, поэтому использовать для его передачи обычное 8-битное кодирование символов невыгодно. Можно присвоить каждому из четырех символов двухбитные коды, например, так:
A — 00, B — 01, C — 10, пробел — 11.
Тогда последовательность «ABA CABABA», занимающая 10 байтов в однобайтной кодировке, может быть представлена как цепочка из 20 битов: 00010011100001000100.
Таким образом, нам удалось уменьшить информационный объем текста в 4 раза, и передаваться он будет в 4 раза быстрее. Однако непонятно, как раскодировать это сообщение, ведь получатель не знает, какой код был использован. Выход состоит в том, чтобы включить в сообщение служебную информацию — заголовок, в котором каждому коду будет сопоставлен ASCII-код символа. Условимся, что первый байт заголовка — это количество используемых символов N, а следующие N байтов — это ASCII-коды этих символов. В данном случае заголовок занимает 5 байтов и выглядит так, как показано в таблице 4.1.
Таблица 4.1
|
000001002 |
010000012 |
010000102 |
010000112 |
001000002 |
|
4 символа |
А (код 65) |
В (код 66) |
С (код 67) |
пробел (код 32) |
Файл, занимающий 10 Кбайт в 8-битной кодировке, содержит 10 240 символов. В сжатом виде каждый символ кодируется двумя битами, кроме того, есть 5-байтный заголовок. Поэтому сжатый файл будет иметь объем
5 + 10 240 ∙ 2/ 8 байтов = 2565 байтов.
![]()
Коэффициент сжатия — это отношение размеров исходного и сжатого файлов.
![]()
В данном случае удалось сжать файл почти в 4 раза, коэффициент сжатия равен k = 10 240/ 2565 ≈ 4.
Если принимающая сторона «знает» формат файла (заголовок и закодированные данные), она сможет восстановить в точности его исходный вид. Такое сжатие называют сжатием без потерь. Оно используется для упаковки текстов, программ, данных, которые ни в коем случае нельзя иска жать.
![]()
Сжатие без потерь — это такое уменьшение объема закодированных данных, при котором можно восстановить их исходный вид из кода без искажений.
![]()
За счет чего удалось сжать файл? Только за счет того, что в файле была некоторая закономерность, избыточность — использовались только 4 символа вместо полного набора.
При сжатии данных, в которых есть цепочки одинаковых кодов, можно применять еще один простой алгоритм, который называется кодированием цепочек одинаковых символов (англ. RLE — Run Length Encoding). Представим себе файл, в котором записаны сначала 100 русских букв «А», а потом — 100 букв «Б», как показано на рисунке 4.1.
1 100 101 200
|
АА... … … … … … … … … … … …АА |
БББ... … … … … … … … … … … …ББ |
Рисунок 4.1
При использовании алгоритма RLE сначала записывается количество повторений первого символа, затем — сам первый символ, затем — количество повторений второго символа, затем — второй символ и т. д. Пример данного алгоритма представлен в таблице 4.2. В этом случае весь закодирован ный файл занимает 4 байта:
Таблица 4.2
|
011001002 |
110000002 |
011001002 |
110000012 |
|
100 |
А (код 192) |
100 |
Б (код 193) |
Таким образом, мы сжали файл в 50 раз за счет того, что в нем снова была избыточность — цепочки одинаковых символов. Это сжатие без потерь, потому что, зная алгоритм упаковки, исходные данные можно точно восстановить из кода.
Очевидно, что такой подход будет приводить к увеличению (в 2 раза) объема данных в том случае, когда в файле нет соседних одинаковых символов. Чтобы улучшить результаты RLE-кодирования даже в этом наихудшем случае, алгоритм модифицировали следующим образом. Упакованная последовательность содержит управляющие байты, за каждым управляющим байтом следует один или несколько байтов данных. Если старший бит управляющего байта равен 1, то следующий за управляющим байт данных при распаковке нужно повторить столько раз, сколько записано в оставшихся 7 битах управляющего байта. Если же старший бит управляющего байта равен 0, то надо взять несколько следующих байтов данных без изменения. Сколько именно — записано в оставшихся 7 битах управляющего байта. Например, управляющий байт 100001112 говорит о том, что следующий за ним байт надо повторить 7 раз, а управляющий байт 000001002 — о том, что следующие за ним 4 байта надо взять без изменений. Например, последовательность, представленная в таблице 4.3, распаковывается в 17 символов: АААААААААААААААБВ.
Таблица 4.3
|
100011112 |
110000002 |
000000102 |
110000012 |
110000102 |
|
повтор 15 |
А (код 192) |
2 |
Б (код 193) |
В (код 194) |
Алгоритм RLE успешно использовался для сжатия рисунков, в которых большие области закрашены одним цветом, и некоторых звуковых данных. Сейчас вместо него применяют более совершенные, но более сложные методы. Один из них (алгоритм Хаффмана) мы рас смотрим далее. Алгоритм RLE используется, например, на одном из этапов кодирования рисунков в формате JPEG. Возможность использования RLE-сжатия есть также в формате ВМР (для рисунков с палитрой 16 или 256 цветов).
В азбуке Морзе для уменьшения длины сообщения используется неравномерный код — часто встречающиеся буквы (А, Е, М, Н, Т) кодируются короткими последовательностями, а редко встречающиеся — более длинными. Такой код можно представить в виде структуры, которая называется деревом (вспомните дерево каталогов).
На рисунке 4.2 показано неполное дерево кода Морзе, построенное только для символов, коды которых состоят из одного и двух знаков (точек и тире). Дерево состоит из узлов (большая черная точка и кружки с символами алфавита) и соединяющих их направленных ребер, стрелки указывают направление движения. Верхний узел (в который не входит ни одна стрелка) называется корнем дерева. Из корня и из всех промежуточных узлов (кроме конечных узлов — листьев) выходят две стрелки, левая помечена точкой, а правая — знаком «тире». Чтобы найти код символа, нужно пройти по стрелкам от корня дерева к нужному узлу, выписывая метки стрелок, по которым мы переходим. В дереве нет циклов (замкнутых путей), поэтому кодовое слово для каждого символа определяется единственным образом.
По этому дереву можно построить такие кодовые слова:
Е • И • • А • – Т – Н – • М – –
Это неравномерный код, в нем символы имеют коды разной длины. При этом всегда возникает проблема разделения последовательности на отдельные кодовые слова. В коде Морзе она решена с помощью символа-разделителя — паузы. Однако можно не вводить дополнительный символ, если выполняется условие Фано: ни одно из кодовых слов не является началом другого кодового слова. Это позволяет однозначно раскодировать сообщение в реальном времени, по мере получения очередных символов.
![]()
Префиксный код — это код, в котором ни одно кодовое слово не является началом другого кодового слова (условие Фано).
![]()
Для использования этой идеи в компьютерной обработке данных нужно было разработать алгоритм построения префиксного кода. Впервые эту задачу решили, независимо друг от друга, американские математики и инженеры Клод Шеннон и Роберт Фано (код Шеннона—Фано). Они использовали избыточность сообщений, состоящую в том, что символы в тексте имеют разные частоты встречаемости. В этом случае для построения кода нужно читать данные исходного файла два раза: на первом проходе определяется частота встречаемости каждого символа, затем строится код с учетом этих данных, и на втором проходе символы текста заменяются на их коды.
Пусть, например, текст состоит только из букв «О», «Е», «Н», «Т» и пробела. Известно, сколько раз они встретились в тексте: пробел — 179, О — 89, Е — 72, Н — 53 и Т — 50 раз. Делим символы на 2 группы так, чтобы общее количество найденных в тексте символов первой группы было примерно равно общему количеству символов второй группы. В нашем случае лучший вариант — это объединить пробел и букву «Т» в первую группу (сумма 179 + 50 = 229), а остальные символы — во вторую (сумма 89 + 72 + 53 = 214).
Символы первой группы будут иметь коды, которые начинаются с нуля, а остальные — с единицы. В первой группе всего два символа, у одного из них, например, у пробела, вторая цифра кода будет 0 (и полный код 00), а у второго — 1 (код буквы «Т» — 01).
Во второй группе три символа, поэтому продолжаем
деление на две группы, примерно равные по количеству символов в тексте. В первую
выделяем одну букву, которая чаще всего встречается — это буква «О» (ее код будет
10), а во вторую — буквы «Е» и «Н» (они получают коды 110 и 111). Код Шеннона—Фано,
построенный для этого случая, можно нарисовать в виде дерева, как показано на рисунке
4.3. Символ ![]() на
этой схеме обозначает пробел.
на
этой схеме обозначает пробел.
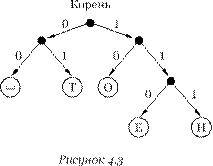
Легко проверить, что для этого кода выполняется условие Фано. Это можно сразу определить по построенному дереву. В нем все символы располагаются в листьях, а не в промежуточных узлах. Это значит, что «по пути» от корня дерева до любого символа никаких других символов в промежуточных узлах не встречается (сравните с деревом кода Морзе).
Для раскодирования очередного символа последовательности мы просто спускаемся от корня дерева, выбирая левую ветку, если очередной бит — 0, и правую, если этот бит равен 1. Дойдя до листа дерева, мы определяем символ, а затем снова начинаем с корня дерева, чтобы раскодировать следующий символ, и т. д. Например, пусть получена следующая последовательность:
01100110001101111001.
Результат ее раскодирования — «ТОТО ЕНОТ».
Было доказано, что в некоторых случаях кодирование Шеннона—Фано дает неоптимальное решение, и можно построить код, который еще больше уменьшит длину кодовой последовательности. Например, в предыдущем примере (код Шеннона—Фано) пробел и буква «Т» имеют коды одинаковой длины, хотя буква «Т» встречается в 3,5 раза реже пробела. Через несколько лет Дэвид Хаффман, ученик Фано, разработал новый алгоритм кодирования и доказал его оптимальность.
Построим код Хаффмана для того же самого примера. Сначала отсортируем буквы по увеличению частоты встречаемости (рисунок 4.4):
![]()
Рисунок 4.4
Затем берем две самые первые буквы, они становятся листьями дерева, а в узел, с которым они связаны, записываем сумму их частот (рисунок 4.5):

Рисунок 4.5
Таким образом, буквы, которые встречаются реже всего, получили самый длинный код. Снова сортируем буквы по возрастанию частоты, но для букв «Т» и «Н» используется их суммарная частота (рисунок 4.6):

Рисунок 4.6
Повторяем ту же процедуру для букв «Е» и «О», частоты которых оказались минимальными, и сортируем по возрастанию частоты (рисунок 4.7):

Рисунок 4.7
Теперь объединяем уже не отдельные буквы, а пары, и снова сортируем (рисунок 4.8):
На последнем шаге остается объединить символ «пробел» с деревом, которое построено для остальных символов. У каждой стрелки, идущей влево от какого-то узла, ставим код 0, а у каждой стрелки, идущей вправо — код 1 (рисунок 4.9).
По этому дереву, спускаясь от корня к листьям-символам, получаем коды Хаффмана, обеспечивающие оптимальное сжатие с учетом частоты встречаемости символов:
![]() — 0, Т — 100, О
— 111, Е — 110, Н — 101.
— 0, Т — 100, О
— 111, Е — 110, Н — 101.
Легко проверить, что этот код также удовлетворяет условию Фано.
Сравним эффективность рассмотренных выше методов. Для алфавита из 5 символов при равномерном кодировании нужно использовать 3 бита на каждый символ, так что число битов в сообщении равно (179 + 89 + 72 + 53 + 50) ∙ 3 = 1329 битов. При кодировании методом Шеннона—Фано получаем 179 ∙ 2 + 89 ∙ 2 + 72 ∙ 3 + 53 ∙ 3 + + 50 ∙ 2 = 1011 битов, коэффициент сжатия составляет 1329/1011 ≈ 1,31. Использование кода Хаффмана дает последовательность длиной 179 ∙ 1 + + 89 ∙ 3 + 72 ∙ 3 + 53 ∙ 3 + 50 ∙ 3 = 971 бит, коэффициент сжатия равен 1,37. В сравнении со случаем, когда для передачи используется однобайтный код (8 битов на символ), выигрыш получается еще более весомым: кодирование Хаффмана сжимает данные примерно в 3,65 раза. Обратим внимание, что сжать данные удалось за счет избыточности: мы использовали тот факт, что некоторые символы встречаются чаще, а некоторые — реже.
Алгоритм кодирования Хаффмана и сейчас широко применяется благодаря своей простоте, высокой скорости кодирования и отсутствию патентных ограничений (он может быть использован свободно). Например, он применяется на некоторых этапах при сжатии рисунков (в формате JPEG) и звуковой информации (в формате МР3).
Выше мы рассмотрели методы сжатия без потерь, при которых можно в точности восстановить исходную информацию, зная алгоритм упаковки.
В некоторых случаях небольшие неточности в передаче данных несущественно влияют на решение задачи. Например, небольшие помехи в телефонном разговоре или радиопередаче, которая транслируется через интернет, не мешают пониманию речи. Некоторое дополнительное размытие уже и без того размытого изображения (фотографии) непрофессионал даже не заметит. Еще в большей степени это относится к видеофильмам. Поэтому иногда можно немного пожертвовать качеством изображения или звука ради того, чтобы значительно сократить объем данных. В этих случаях используется сжатие с потерями.
![]()
Сжатие с потерями — это такое уменьшение объема закодированных данных, при котором распакованный файл может отличаться от оригинала.
![]()
Самые известные примеры сжатия с потерями — это алгоритмы JPEG (для изображений), МР3 (для упаковки звука) и все алгоритмы упаковки видеофильмов (MJPEG, МРЕG4, DivX, XviD).

|
8 битов на пиксель (256 цветов) |
4 бита на пиксель (16 цветов) Рисунок 4.10 |
2 бита на пиксель (4 цвета) |
Простейший метод сжатия рисунков — снижение глубины цвета. На рисунке 4.10 показаны три изображения с различной глубиной цвета.
Третье из них занимает при кодировании в 4 раза меньше места, чем первое, хотя воспринимается уже с трудом.
Алгоритм JPEG (англ. Joint Photographic Experts Group — объединенная группа экспертов по фотографии) — один из наиболее эффективных методов сжатия с потерями для изображений. Он довольно сложен, поэтому мы опишем только основные идеи этого алгоритма.
Из классической RGB-модели (красный, зеленый, синий) цвет переводится в модель YCbCr, где Y — яркость, Cb — «синева», Cr — «краснота»:
Y = 0,299 ∙ R + 0,587 ∙ G + 0,114 ∙ В; Cb = 128 − 0,1687 ∙ R − 0,3313 ∙ G + 0,5 ∙ В; Cr = 128 + 0,5 ∙ R − 0,4187 ∙ G − 0,0813 ∙ В.
В этих расчетах R, G и B обозначают красную, зеленую и синюю составляющие цвета в RGB-модели. Черно-белое изображение (точнее, оттенки серого), содержит только Y-составляющую, компоненты цвета Cb и Cr равны 128 и не несут полезной информации.
|
Y1 Cb1 Cr1 |
Y2 Cb2 Cr2 |
|
Y3 Cb3 Cr3 |
Y4 Cb4 Cr4 |
![]() Y1, Y2, Y3, Y4, Cb, Cr
Y1, Y2, Y3, Y4, Cb, Cr
Рисунок 4.11
Основная идея сжатия основана на том, что человеческий глаз более чувствителен к изменению яркости, то есть составляющей Y. Поэтому на синюю и красную составляющие, Сb и Сr, приходится меньше полезной информации, и на этом можно сэкономить. Рассмотрим квадрат размером 2 × 2 пикселя. Можно, например, сделать так: запомнить Y-компоненту для всех пикселей изображения (4 числа) и по одной компоненте Cb и Cr на все 4 пикселя (рисунок 4.11). Для определения сохраняемых значений Сb и Cr можно использовать, например, усреднение — принять
Сb = (Сb1 + Сb2 + Сb3 + Сb4)/4, Cr = (Сr1 + Cr2 + Сr3 + Сr4)/4.
Таким образом, вместо 12 чисел мы должны хранить всего 6, данные сжаты в 2 раза. Однако мы не сможем восстановить обратно исходный рисунок, потому что информация о том, какие были значения Сb и Cr для каждого пикселя, безвозвратно утеряна, есть только некоторые средние значения. При выводе такого изображения на экран можно, например, считать, что все 4 пикселя имели одинаковые значения Сb и Cr. Более сложные алгоритмы используют информацию о соседних блоках, сглаживая резкие переходы при изменении этих составляющих. Поэтому при кодировании с помощью алгоритма JPEG изображение несколько размывается.
Но это еще не все. После этого к оставшимся коэффициентам применяется сложное дискретное косинусное преобразование, с помощью которого удается выделить информацию, которая мало влияет на восприятие рисунка человеком, и отбросить ее. На последнем этапе для сжатия оставшихся данных используются алгоритмы RLE и Хаффмана.
На рисунке 4.12 вы видите результат сжатия изображения шарика в формате JРЕG с разным качеством.
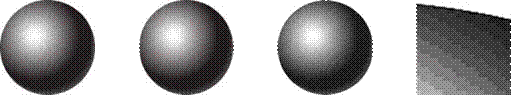
Качество 12 Качество 6 Качество 0 Фрагмент
(8400 байтов) (3165 байтов) (1757 байтов) (качество 0)
Рисунок 4.12
Рисунки, сохраненные с качеством 12 и 6, практически не отличаются внешне, однако второй из них занимает в 2,65 раза меньше места. При снижении качества до минимального явно заметны искажения (артефакты), вызванные потерей информации при сжатии. Кажется, что рисунок построен из квадратов размером 8 × 8 пикселей (в действительности именно такие квадраты использует алгоритм в качестве базовых ячеек). Кроме того, искажения особенно заметны там, где происходит резкий переход от одного цвета к другому.
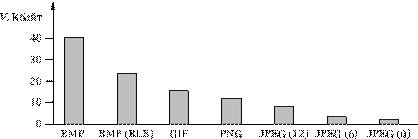
Рисунок 4.13
Тот же самый рисунок был сохранен в форматеВМР без сжатия и с RLEсжатием, а также в форматах GIF (сжатие без потерь с помощью алгоритма LZW) и РNG (сжатие без потерь с помощью алгоритма DEFLATE). Размеры полученных файлов (в килобайтах) сравниваются на рисунке 4.13.
По диаграмме видно, что наибольшее сжатие (наименьший объем файла) обеспечивается алгоритмом JPEG. Заметим, что особенность этого рисунка — плавные переходы между цветами.

Теперь рассмотрим рисунок 4.14, в котором есть большие области одного цвета и четкие границы объектов. Здесь ситуация несколько меняется. Размеры данного изображения после сжатия в различных форматах представлены на рисунке 4.15.
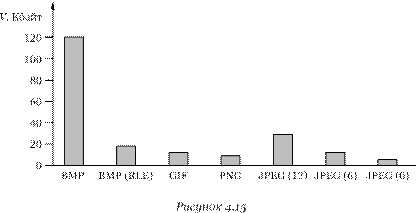
Форматы GIF и PNG обеспечивают степень сжатия, сравнимую с алгоритмом JPEG среднего качества. Учитывая, что JPEG приводит к искажению изображения, а GIF и РNG — нет, для таких рисунков не рекомендуется использовать формат JPEG.
Другой известный пример сжатия с потерями — алго ритм МРЕG-1 Layer 3, который более известен как МР3. В нем отбрасываются некоторые компоненты звука, которые практически неразличимы для большинства людей. Такой подход называется кодированием восприятия, потому что он основан на особенностях восприятия звука человеком.
Одна из главных характеристик сжатия звукового файла — битрейт (англ. bitrate — темп поступления битов). Битрейт — это число битов, используемых для кодирования 1 секунды звука. Формат МР3 поддерживает разные степени сжатия, с битрейтом от 8 до 320 Кбит/с.
Звук, закодированный с битрейтом 256 Кбит/с и выше, даже профессионал вряд ли отличит от звучания компакт-диска. Можно подсчитать, что 1 секунда звука занимает на компакт-диске (частота дискретизации 44 кГц, глубина кодирования 16 битов, стерео)
2 ∙ 88 000 = 176 000 байтов = 1 408 000 битов = 1375 Кбит.
Таким образом, формат МР3 обеспечивает степень сжатия 1375/ 256 ≈ ≈ 5,4 при сохранении качества звучания для человека (хотя часть информации, строго говоря, теряется).
Для сжатия видео может использоваться алгоритм MJPEG (англ. Motion JPEG — JРЕG в движении), когда каждый кадр сжимается по алгоритму JPEG. Кроме того, широко применяют стандарт МРЕG-4, разработанный специально для сжатия цифрового звука и видео.
Программы (и устройства), которые выполняют кодирование и декодирование звука и видео, называют кодеками (англ. codec — coder/decoder — кодировщик/декодировщик). Наиболее известные аудиокодеки (программы для преобразования звука) — МР3, Ogg Vorbis (OGG) и ААС. Среди видеокодеков чаще всего используются кодеки стандарта МРЕG-4 (DivX, Xvid, H.264, QuickTime) и кодек WMV (Windows Media Video). Самые популярные свободные (англ. ореn source) и бесплатные (англ. freeware) кодеки собраны в пакет K-Lite Codec Pack (codecguide. com).
Мы рассмотрели различные алгоритмы сжатия информации. Все они основаны на том, что в информации есть некоторая избыточность, закономерность, которую можно использовать для уменьшения объема данных. Хорошо сжимается информация, в которой большая избыточность:
A документы — тексты с оформлением и, возможно, вставленными рисунками, таблицами и т. п.; электронные таблицы (файлы с расширениями doc, docx, xls);
A тексты, в которых повторяются одинаковые слова и символы имеют разные частоты встречаемости (файлы с расширениями txt, doc, docx);
A рисунки, имеющие большие области одного цвета и записанные без сжатия (файлы bmp);
A несжатый звук (файлы wav); A несжатое видео (файлы avi)[9].
Плохо сжимаются данные, где избыточность маленькая или ее совсем нет:
A архивы, упакованные со сжатием (zip, rаr, 7z и др.);
A сжатые рисунки (файлы gif, jpg, png, tif и др.);
A сжатый звук (файлы mp3, wma); A сжатое видео (файлы mpg, wmv, mp4); A программы (файлы ехе).
Данные невозможно сжать, если в них нет никаких закономерностей. Поэтому хуже всего сжимаются случайные числа, например, полученные на компьютере. Современным программам-упаковщикам иногда удается их немного сжать, но не более, чем на 1–2 %. Это происходит потому, что в последовательности псевдослучайных чисел, которые выдает компьютерная программа-генератор, все же можно выявить какие-то закономерности.
Заметим, что не всегда нужно стремиться к полному устранению избыточности кода. Как вы знаете из предыдущего параграфа, именно избыточность позволяет обнаруживать и исправлять ошибки при передаче данных.
1. За счет чего удается сжать данные без потерь? Когда это сделать принципиально невозможно?
2. Какие типы файлов сжимаются хорошо, а какие — плохо? Почему?
3. Текстовый файл, записанный в однобайтной кодировке, содержит только 33 заглавные русские буквы, цифры и пробел. Ответьте на следующие вопросы:
A какое минимальное число битов нужно выделить на символ при передаче, если каждый символ кодируется одинаковым числом битов?
A сколько при этом будет занимать заголовок пакета данных?
A при какой минимальной длине текста коэффициент сжатия будет больше 1?
4. На чем основан алгоритм сжатия RLE? Когда он работает хорошо?
Когда нет смысла его использовать?
5. Что такое префиксный код?
6. В каких случаях допустимо сжатие с потерями?
7. Опишите простейшие методы сжатия рисунков с потерями. Приведите примеры.
8. На чем основан алгоритм JPEG? Почему это алгоритм сжатия с потерями?
9. Что такое артефакты?
10. Для каких типов изображений эффективно сжатие JPEG? Когда его не стоит применять?
11. На чем основано сжатие звука в алгоритме МР3?
12. Что такое битрейт? Как он связан с качеством звука?
13. Какое качество звука принимается за эталон качества на непрофессиональном уровне?
14. Какие методы используются для сжатия видео?
1. С помощью алгоритма RLE закодируйте сообщение «ВААААВАААРРРРРРРРРР».
2. После кодирования методом RLE получилась следующая последовательность байтов (первый байт — управляющий):
10000011 10101010 00000010 10101111 11111111 10000101 10101010 Сколько байтов будет содержать данная последовательность после распаковки?
3. После кодирования методом RLE получилась следующая последовательность байтов (первый байт — управляющий):
00000011 10101010 00000010 10101111 10001111 11111111
Сколько байтов будет содержать данная последовательность после распаковки?
4. Раскодируйте сообщение, которое закодировано с помощью приведенного в тексте кода Шеннона—Фано: 11111000011011111001001101111001.
5. Постройте дерево, соответствующее коду А — 0, Б — 1, В — 00, Г — 01, Д — 10, Е — 11. Является ли этот код префиксным? Как это определить, посмотрев на дерево?
6. Постройте дерево Хаффмана для фразы «МАМА МЫЛА РАМУ». Найдите коды всех входящих в нее символов и закодируйте сообщение. Чему равен коэффициент сжатия в сравнении с равномерным кодом минимальной длины? С однобайтной кодировкой?
1. Маскаева А. М. Основы теории информации : учеб. пособие. – М. : ФОРУМ: ИНФРА-М, 2014. – 96 с.
2. Поляков К. Ю., Еремин Е. А. Информатика. Углубленный уровень : учебник для 10 класса : в 2 ч. Ч 1. – М. : БИНОМ. Лаборатория знаний, 2013. – 344 с. : ил.
3. Поляков К. Ю., Еремин Е. А. Информатика. Углубленный уровень : учебник для 11 класса : в 2 ч. Ч 1. – М. : БИНОМ. Лаборатория знаний, 2013. – 340 с. : ил.
4. Соколова О. Л. Универсальные поурочные разработки по информатике: 10 класс. – М. : ВАКО, 2007. – 400 с.
5. Тема 1.1.1. Принцип временного разделения каналов ; Тема 1.1.2. Выбор частоты дискретизации сигналов // Лекции.ком [Электронный ресурс]. – Режим доступа: http://lektsii.com/2-31010.html, свободный.
6. Теорема Котельникова // Основы теории информации [Электронный ресурс] : электрон. пособие / Сост. : М. С. Плотникова. – Пермь : Издво «Пермский авиационный техникум им. А. Д. Швецова. – Режим доступа: http://museum-pat.narod.ru/date/teo_tk.html, свободный.

91

Рисунок Б.1. Результат смешения базовых цветов цветовой модели RGB
Рисунок Б.2. Результат смешения базовых цветов цветовой модели CMYK
а б
Рисунок Б.3. Излучаемый и отражаемый свет
92
Содержание
Глава 1. Информация и информационные процессы . . . . . . . . . . 5
1.1. Информация . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
Как получают информацию . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
Формы представления информации . . . . . . . . . . . . . . . . . . . . . . . 7
Человек, информация, знания . . . . . . . . . . . . . . . . . . . . . . . . . . 8
Свойства информации . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
1.2. Информационные процессы . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 Передача информации . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
Обработка информации . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
Хранение информации . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
1.3. Измерение информации . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 Что такое бит? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 2 бита, 3 бита... . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 Другие единицы . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
1.4. Формула Хартли. Закон аддитивности информации . . . . . . . . . . . . . 20 Закон аддитивности информации . . . . . . . . . . . . . . . . . . . . . . . . 22
Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
Глава 2. Системы счисления . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
2.1. Представление чисел в разных системах счисления . . . . . . . . . . . . . 25
Таблицы систем счисления . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
Перевод чисел из одной системы счисления в другую . . . . . . . . . . . . 27
Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
2.2. Правила недесятичной арифметики . . . . . . . . . . . . . . . . . . . . . . . 30 Аксиомы двоичной арифметики . . . . . . . . . . . . . . . . . . . . . . . . . 30
Арифметические операции над двоичными числами . . . . . . . . . . . . 31
Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
Глава 3. Способы кодирования информации . . . . . . . . . . . . . . . . 33
3.1. Кодирование символов . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 Кодировка ASCII и ее расширения . . . . . . . . . . . . . . . . . . . . . . . . 34
Стандарт UNICODE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36 Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
Задачи . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.2. Кодирование числовой информации . . . . . . . . . . . . . . . . . . . . . . 38 Кодирование цифровых и буквенных символов . . . . . . . . . . . . . . . . 38
Целые числа . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
Действительные числа . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
93
3.3. Кодирование графической информации . . . . . . . . . . . . . . . . . . . . 44 Растровое кодирование . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
Кодирование цвета . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
Растровое кодирование: итоги . . . . . . . . . . . . . . . . . . . . . . . . . . 53
Векторное кодирование . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
Задачи . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.4. Кодирование звуковой и видеоинформации . . . . . . . . . . . . . . . . . . 60
Оцифровка звука . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
Инструментальное кодирование звука . . . . . . . . . . . . . . . . . . . . . 64 Кодирование видеоинформации . . . . . . . . . . . . . . . . . . . . . . . . . 65 Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
Задачи . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
Глава 4. Сжатие и передача данных . . . . . . . . . . . . . . . . . . . . . . 69
4.1. Передача данных . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69 Обнаружение ошибок . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69 Помехоустойчивые коды . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
Задачи . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
4.2. Сжатие данных . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74 Основные понятия . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74 Алгоритм RLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76 Префиксные коды . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77 Алгоритм Хаффмана . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80
Сжатие с потерями . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
Выводы . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
Вопросы и задания . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 87
Задачи . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 88
Список используемых источников . . . . . . . . . . . . . . . . . . . . . . . 89
Приложение А . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91 Приложение Б . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 92
94
Учебное издание
Основы теории информации
Учебное пособие
для студентов, обучающихся по специальности
09.02.02 «Компьютерные сети»
Составитель:
Светлана Владимировна Ермолычева
Редактор, корректор: В. М. Гамбург
Технический редактор: В. М. Гамбург
Художественный редактор: В. М. Гамбург Компьютерная верстка: В. М. Гамбург
Подписано в печать 17.06.2019. Формат 75 × 90/ 16 Гарнитуры: Georgia, Helvetica. Усл. печ. л. 7,5. Цифровая печать. Тираж 15 экз. Заказ № 001
ГПОУ ЯО «Рыбинский полиграфический колледж»
152900, г. Рыбинск, ул. Расплетина, 47
[1] Конечно, вместо 0 и 1 можно использовать два любых знака.
[2] Впервые его использовал американский инженер В. Бухгольц в 1956 г.
[3] − 1 = 11 1 − 0 = 1
[4] − 1 = 0
[5] Существуют специальные программы, позволяющие создавать и редактировать шрифты, например, Fontlab Studio: http://www.fontlab.com/font-editor/fontlab-studio/
[6] Или НSV (англ. Huе — тон, оттенок; Saturatiоn — насыщенность, Value — величина).
[7] Как вы понимаете, точные цифры зависят от профилей монитора и принтера.
[8] В современных персональных компьютерах функции звуковой карты часто выполняет специальная микросхема материнской платы — аппаратный аудиокодек.
[9] Файлы с расширением avi могут хранить как сжатое, так и несжатое видео.











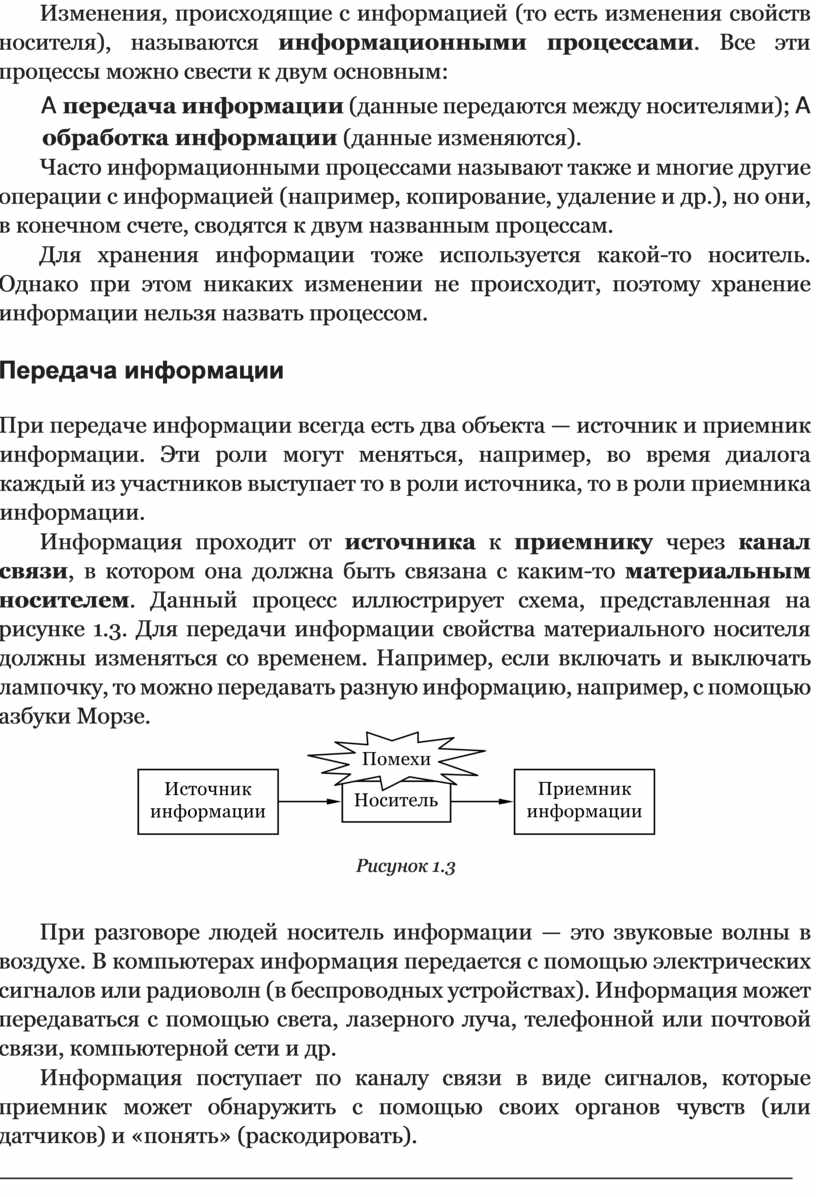




















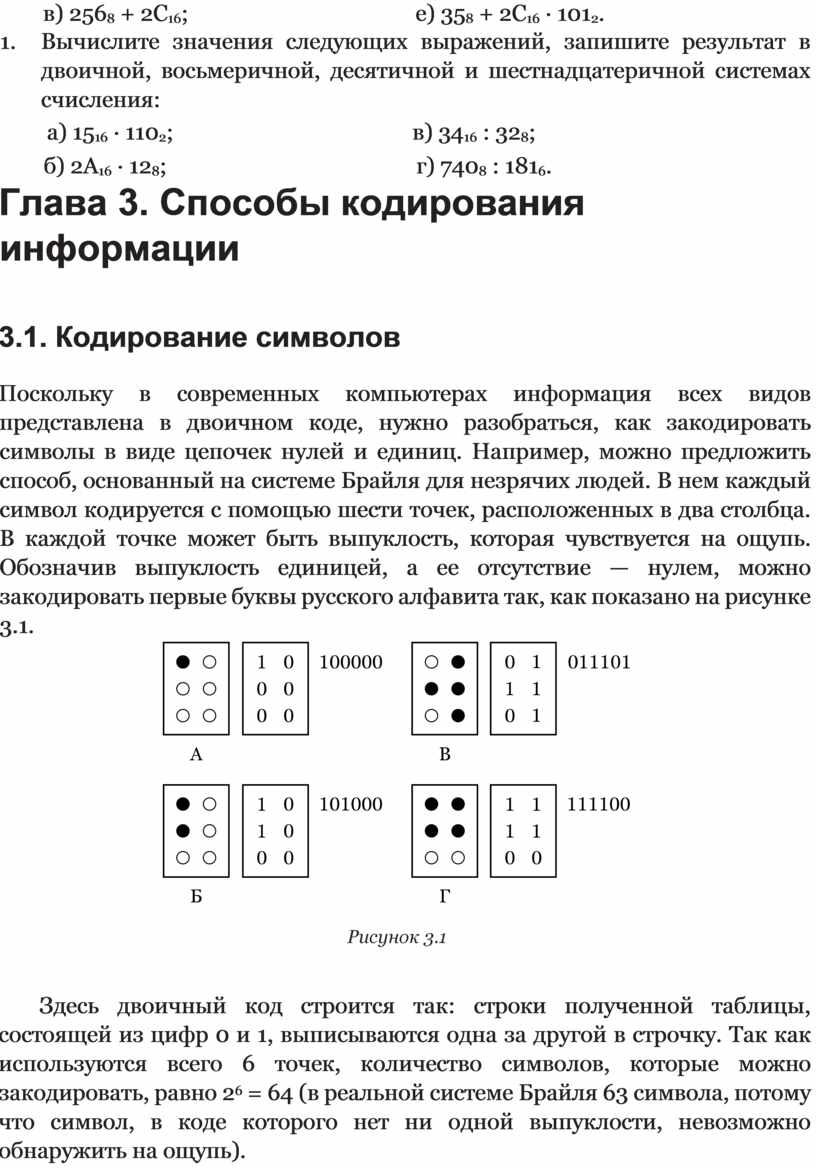




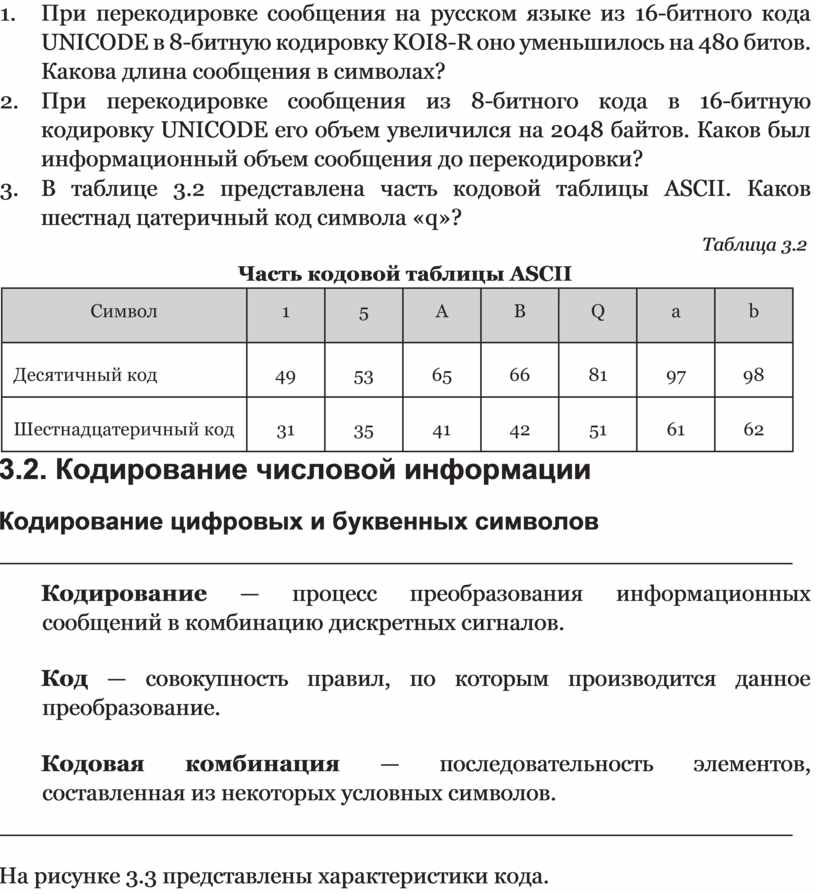
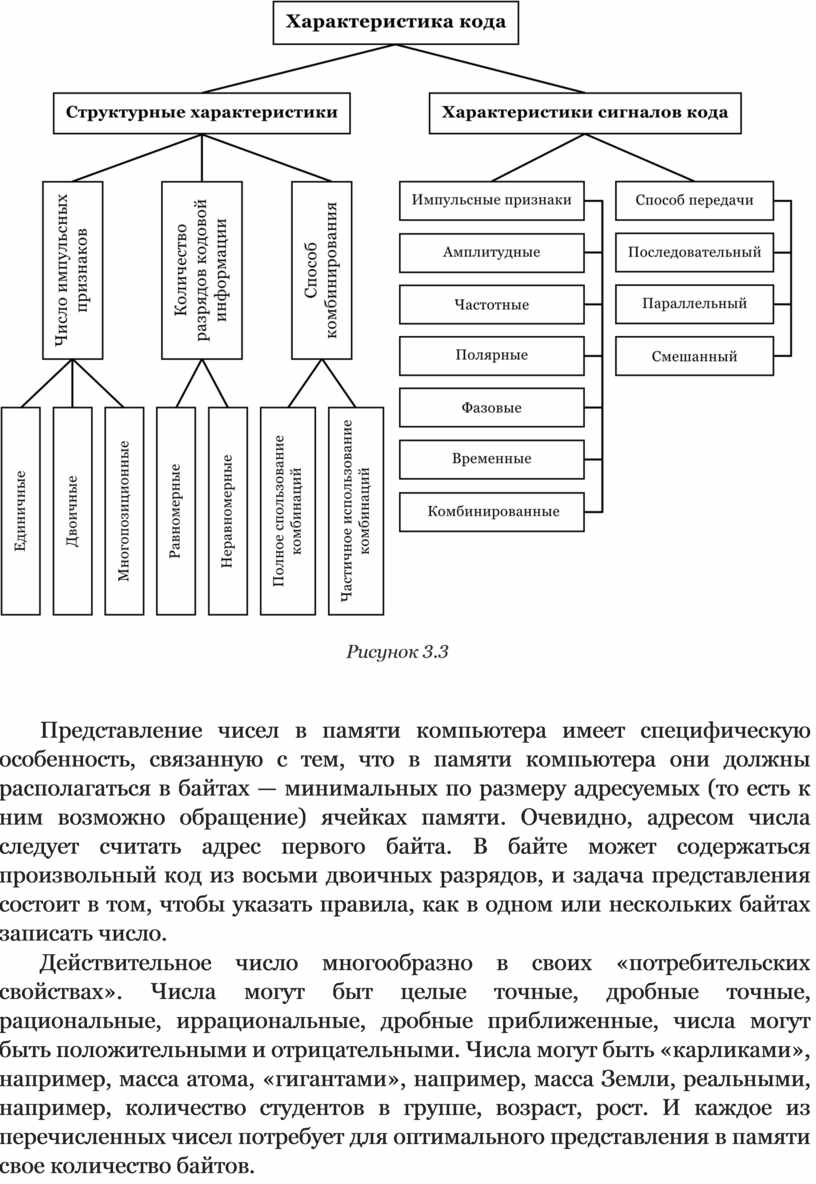
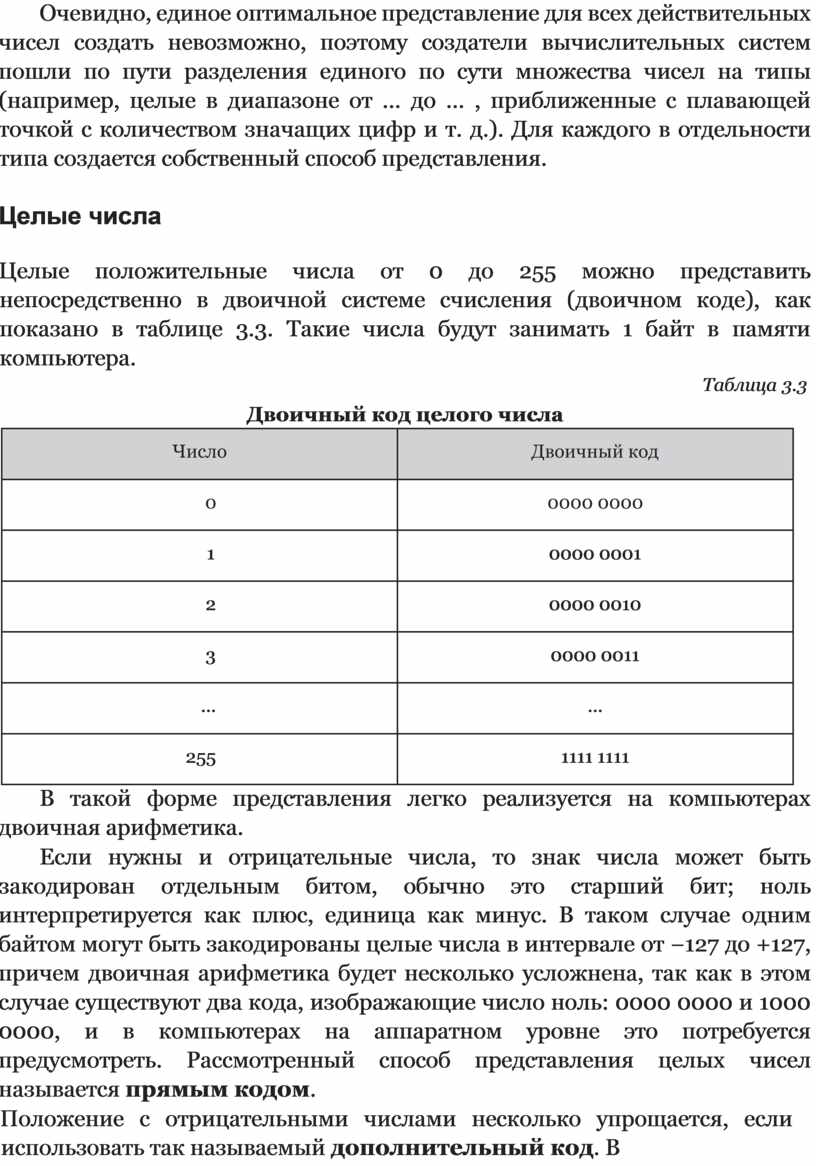







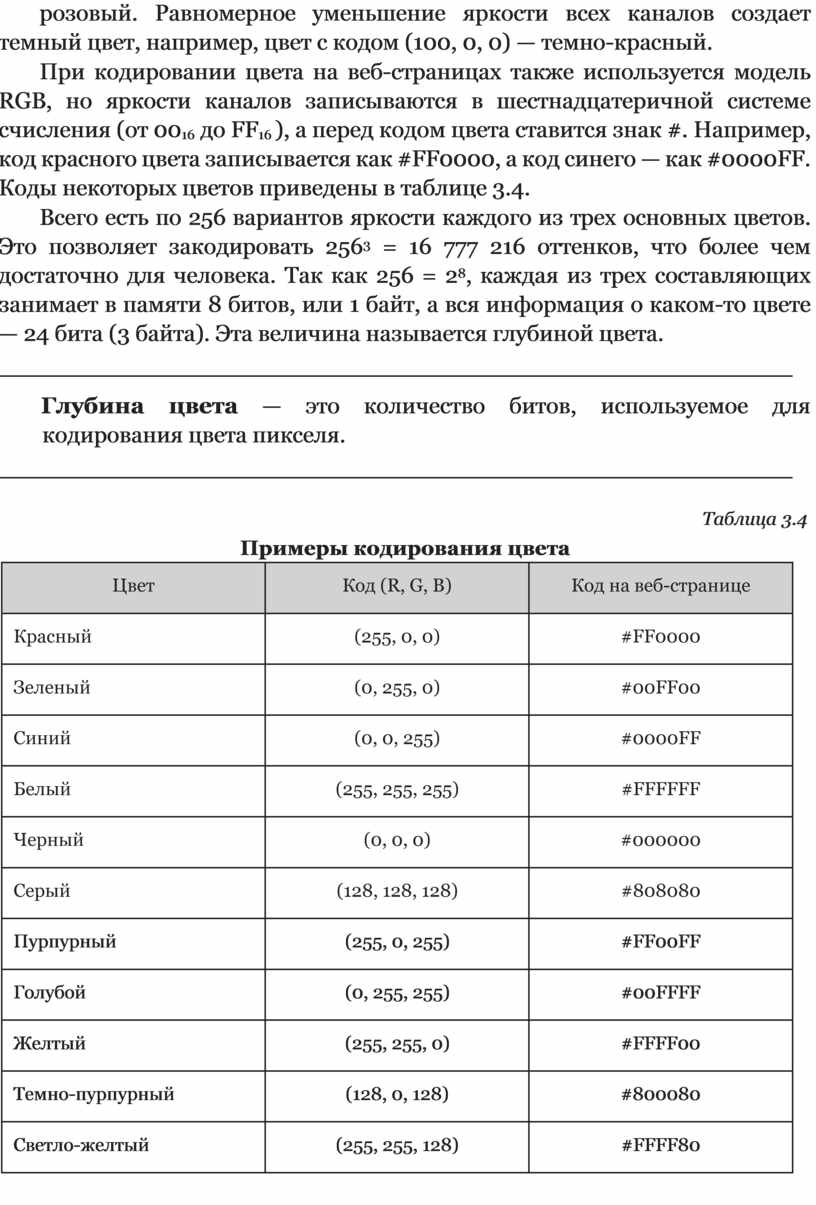
Материалы на данной страницы взяты из открытых источников либо размещены пользователем в соответствии с договором-офертой сайта. Вы можете сообщить о нарушении.

